基于3DMine的矿化域模型构建与资源量估算:以南美洲某浅成低温热液型金矿为例
2023-02-28王智纲杨晋升张瑞忠
王智纲, 杨晋升, 张瑞忠
(1. 招金有色矿业有限公司,山东烟台265400; 2. 招金矿业股份有限公司,山东烟台265400)
0 引 言
三维模型构建在地质资源储量估算、找矿预测方面的应用越来越广泛和规范(余牛奔等,2015;覃鹏等,2016;中华人民共和国自然资源部,2020;邹进超等,2021)。传统地质块段法采用边界品位、最低工业品位等指标圈定矿体及估算资源储量,割裂了矿体的空间相关性,降低了资源估算的效率及找矿预测的准确性,削弱了资源储量动态估算的优势。目前,对于斑岩型、热液脉型矿床,国内外采用低于边界品位的矿化域模型进行资源储量估算,不仅能大幅提高工作效率,而且能客观反映矿化的空间分布规律,有利于找矿预测(杜菊民等,2022)。
通过对南美洲某浅成低温热液型金矿样品进行统计分析,提出基于矿化域模型的资源量估算法和三维可视化表达,为资源储量管理提供参考。
1 区域及矿床地质
安第斯成矿带是全球重要的Cu、Au、Fe产区,根据地理位置可划分为北、中、南安第斯成矿带(卢民杰等,2016)。研究区地处北安第斯成矿带北部的尼加拉瓜—哥斯达黎加金成矿带,构造单元划分属于活动大陆边缘的内岩浆弧,是环太平洋火山岛弧的一部分,由科科斯(Cocos)板块俯冲到加勒比板块之下而形成,该火山弧带自墨西哥南部经萨瓦尔多、危地马拉、洪都拉斯、尼加拉瓜、哥斯达黎加至巴拉马中部,长约2 000 km,产出众多的斑岩型铜矿床和浅成低温热液型金矿床。
矿区出露地层为:中新—上新统Aguacate群安山质与玄武质火山岩、火山碎屑岩,Guacimal群中酸性侵入杂岩,上新—更新统Monteverde组含角闪石斑状英安岩和流纹岩。金矿体赋存在Aguacate群中酸性火山岩中,主要岩性为英安岩与长英质陆源火山碎屑岩、凝灰岩、角砾岩(图1)。

图1 研究区区域地质图(a)与矿床地质图(b)1-第四系冲积物;2-更新—全新统安山质角砾岩;3-更新统熔岩流、凝灰岩和火山角砾岩;4-上新—更新统Monteverde组含角闪石斑状英安岩和流纹岩;5-上新统Guacimal群中酸性侵入杂岩;6-中新—上新统Aguacate群安山质与玄武质火山岩、火山碎屑岩;7-花岗岩;8-火山泥流;9-矿化体;10-断层线;11-断层带;12-熔岩流动方向;13-金矿床(点);14-研究区Fig. 1 Regional geological map (a) and deposit geological map (b) of study area
区域上,一系列平行排列的NW-SE向弧形断裂(Liz断层)的主要控矿断裂整体倾向82°,倾角85°,断面整体平直,局部形成S形弯曲,断层带内充填火山岩角砾。根据火山熔岩流动方向以及出现的火山角砾可知,矿区所处位置可能为火山活动中心,矿区侵入岩为细粒花岗岩、花岗闪长岩,多以脉状产出,是与区内火山岩同源但不同形式的产物。
矿区矿化以金矿化为主,发育构造裂隙型热液蚀变矿化和充填交代型细脉-浸染状矿化,围岩蚀变类型有绢云母化、硅化、青磐岩化、黄铁矿化,硅化通常伴随着贵金属矿化,其两侧通常为伊利石-绢云母和黏土蚀变带,形态上呈面状、透镜状和囊状,矿床成因类型为低硫化浅成低温热液型金矿床。
2 数据库建立与样品统计
2.1 钻孔数据库建立
钻孔数据库是按照地质数据结构来存储和管理的库,是矿山开采设计、资源量估算和找矿预测评价的基础(周邓等,2017)。基于三维地质建模技术,采用3DMine软件建立钻孔空间数据库。①在保持原始数据完整性和准确性的基础上,对收集到的地质图、勘探线剖面图、原始编录数据进行整理,形成基础地质资料。②依次提取工程定位表、测斜数据表、样品分析结果表、地质要素表等。其中,工程定位表包含钻孔的空间位置信息,测斜数据表包含钻孔的方位、倾角、终止孔深等;样品分析结果表包含样品编号、采样起止孔深、样长、品位及其他;地质要素表主要包含岩性、断层、蚀变等信息,是矿化域圈连与解释的重要依据。通过钻孔编号对上述文件建立关联。③进行钻孔数据库的录入、检查和显示。检查内容主要为定位表与其他数据是否匹配、测斜表是否完整、样品长度超限与采样位置叠置等,数据检查无误后在图形界面显示(图2)。

图2 钻孔三维空间位置示意图Fig. 2 Schematic Diagram of 3D spatial location of drill holes
参与数据库建库的钻孔共1 451个,孔深在36~500 m之间,采集Au化学分析样品36 387件。
2.2 样品统计分析
分别对原始样品和矿化域样品进行品位频数和对数品位频数统计,形成品位分布直方图和曲线图(图3),对数直方图总体呈正态分布。原始样品Au品位最小值为0.01 g/t,最大值为182 g/t。品位平均值(1.303 71 g/t)与西舍尔估值(1.302 17 g/t)接近,但偏度(16.32)相对较大,需进行特异值处理。
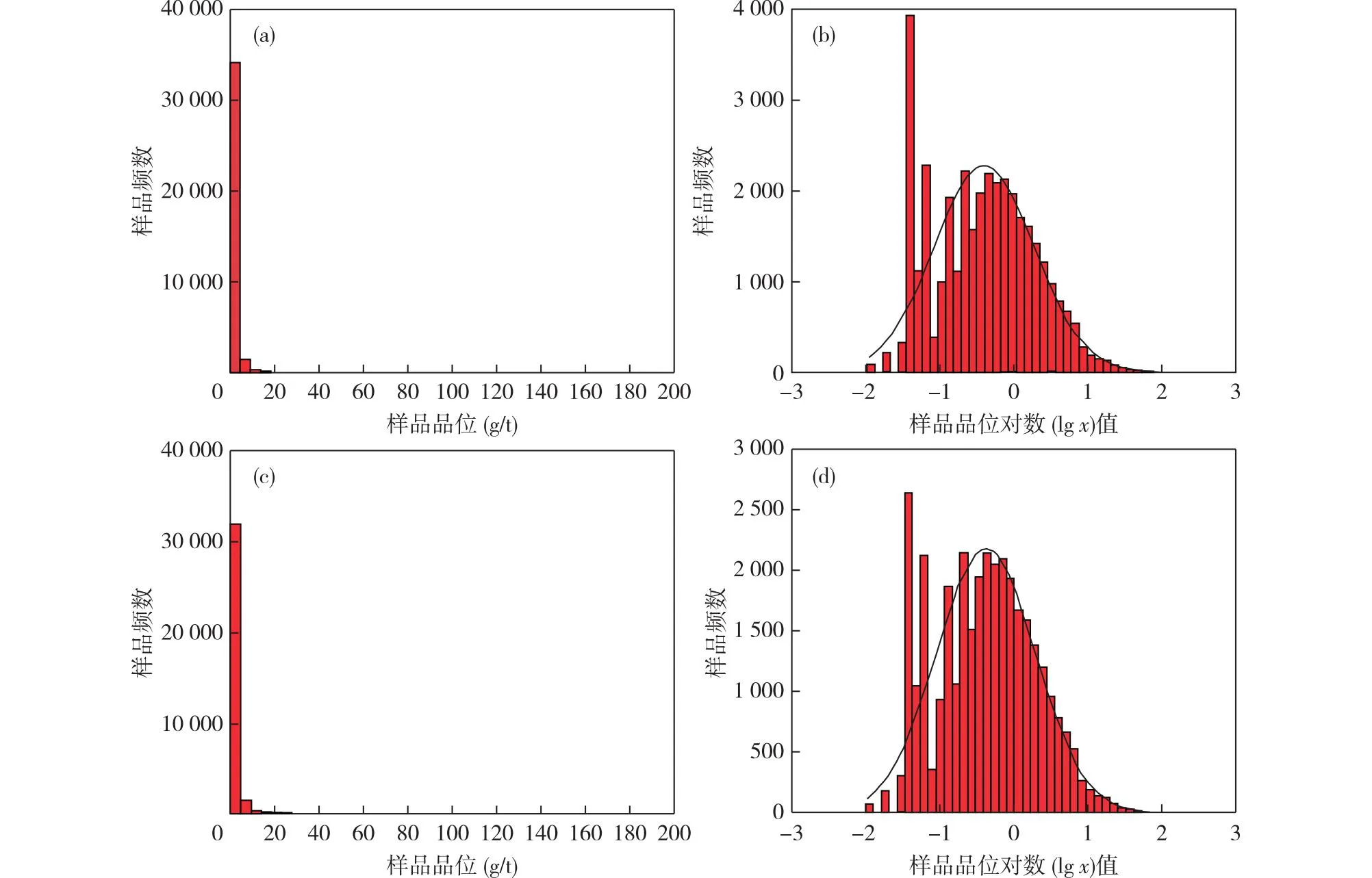
图3 原始与矿化域样品品位分布直方图和曲线图(a) 原始样品品位频数;(b) 原始样品对数品位频数;(c) 矿化域样品品位频数;(d) 矿化域样品对数品位频数Fig. 3 Histograms and graphs of the grade distribution of samples in the original and mineralized domains(a) Grade frequency for original sample; (b) Logarithmic grade frequency for original sample; (c) Grade frequency for mineralized domain sample; (d) Logarithmic grade frequency for mineralized domain sample
2.3 矿化域边界品位确定
为保证矿化域在形态上的完整性和连续性,需确定合理的边界品位。根据原始与矿化域样品品位分位数对比(表1),样品在对数值-1.2左右存在微小拐点,对应的分位值接近20%,原始样品品位接近0.07 g/t,大于该品位的样品数占总数的80%,表明拐点之后的样品金矿化连续性好,因此选取矿化域的边界品位为0.07 g/t。
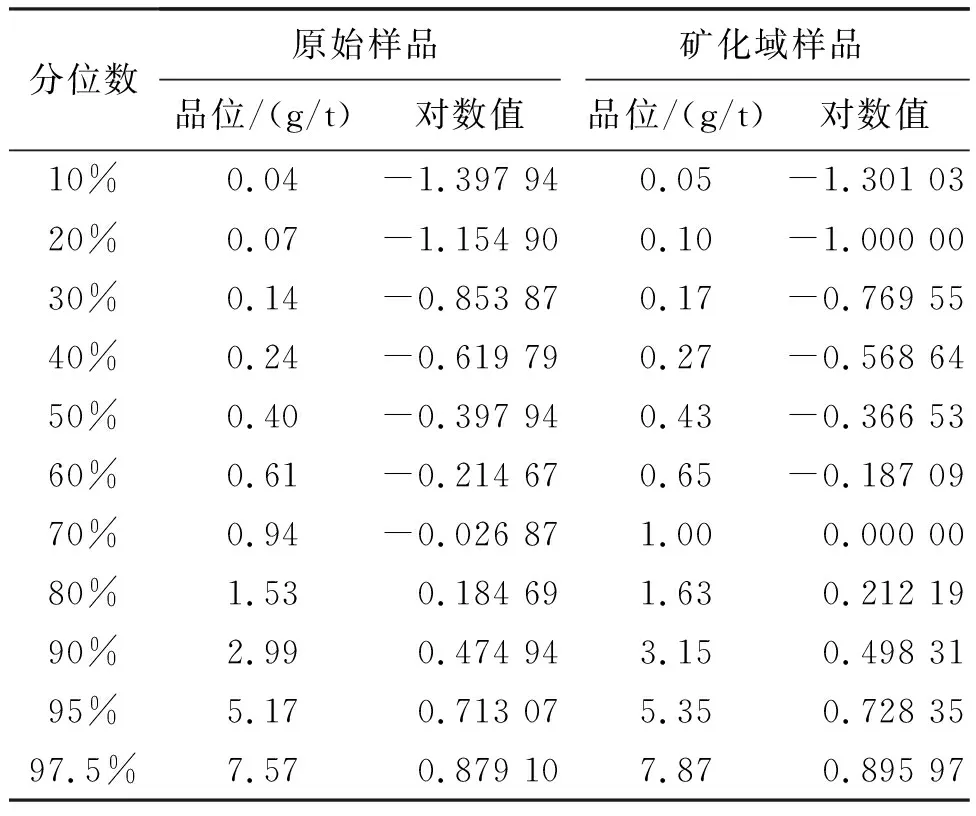
表1 原始与矿化域样品品位分位数对比
3 矿化域模型构建
3.1 实体模型
矿化域实体建模的方案可概括为“平面+剖面”。根据地质规律和实际情况,结合钻孔数据库品位品级划分与可视化表达结果,通过封闭的多段线在平面或剖面上圈定矿化域边界,再将各剖面或平面之间的封闭多段线进行连接,建立矿化域实体模型。在各项连接过程中,采用NURBS圆滑工具对矿化域边界进行平滑处理,验证矿化域实体模型,确保模型无开放边、自相交边和无效边,最终形成实体模型(图4a)。

图4 矿化域实体模型与块体模型(a) 实体模型;(b) 块体模型Fig. 4 Schematic diagram of entity model and block model of mineralized domain(a) Entity model; (b) Block model
3.2 块体模型
块体模型是品位赋值和资源储量估算的基础(马东林等,2022)。单元块体尺寸取决于矿体类型、规模、产状、最小可采厚度、开采方式及勘探线网度等因素(滕正双等,2015;刘晓宁等,2019;张磊等,2021),本次确立块体尺寸为5 m×3 m×2 m,次分块尺寸为2.5 m×1.5 m×1.0 m。为块体模型建立相应关联属性,如资源类别、矿石密度、Au品位等。由于矿化形态呈面状、透镜状,故无需建立旋转块体。图4b为实体模型约束下最终形成的矿化域块体模型,可以直观地展示矿体在三维空间的形态及其变化特征,是矿化变化结构分析的基础。
4 矿化变化结构分析
矿化变化结构分析是基于已建立的实体模型与块体模型进行三维空间结构变化、品位分布及变化的分析,包括特异值的识别与处理、变异函数拟合。特异值指特高与特低品位,由于特高品位对品位均值、方差等影响较大,会引起品位高估,因此在变异函数拟合前需对特高品位进行识别与处理。
4.1 特异值识别与处理
特异值的存在会影响变量的分布特征,进而导致变异函数的平稳性下降。传统识别方法有2种:①采用均方差的倍数确定特异值,即特高品位≥m+3σ(m为均值,σ为3倍均方差);②按照样品品位变化系数来识别特异值。以分布密度曲线函数上拐点对应值作为特异值的下限(林吉飞等,2011),根据基本统计图3c、d可知,样品在高品位区间连续性相对较好,在对数值2附近出现拐点,该处对应的品位为91.85 g/t,因此将91.85 g/t作为特异值的下限。特异值确定后,观察其所在空间位置,如果特异值样品成带分布,则将特异值样品所在矿化域作为单独的“富矿块”对待。
特异值处理时应以构建的矿化域模型内部样品点为对象,一般采用平均品位代替特异值的样品品位,此次采用品位分布直方图上出现不连续拐点处的品位代替特异值品位。特异值处理后需再次检查,若平均值与西舍尔估值较接近,且偏度大幅减小,则特异值处理合理(杨丰铭等,2022),此次特异值处理后的平均值为1.368 59,西舍尔估值为1.368 85,偏度降为10.51,相对较合理。
4.2 变异函数拟合
变异函数是表示矿化范围内区域化变量的相关关系和空间结构的数学工具(王炯辉等,2013),是普通克里格法估值的基础与前提,地质统计学研究首先要进行区域化变量的结构分析,需确定的参数主要有块金值、基台值和变程:块金值代表样品变化的随机成分;基台值是变异函数趋于平稳状态时达到的值;变程是变异函数趋于稳定时对应向量的长度,即各向异性影响范围(宣良瑞等,2022)。
变异函数拟合前需进行样品组合。为避免局部样品分割过大或过小导致产生额外地质信息或过度平滑的情况,需综合考虑组合样品长度,原始样长、最小可采厚度、勘探类型与网度以及块体模型尺寸等均会影响组合样长的选择(黄松等,2019)。矿化域内样品长度基本统计结果显示,样品长度多为1、2、4 m,平均值1.82 m,选择2 m为组合样品长度。通过样品组合促使参与变异函数拟合的样品平均值与西舍尔估值更为接近。
综合考虑矿化域模型形态和组合样品点的统计分析特征,采用球状模型,设置16个扇区,依次确定矿化域品位具有最好连续性的主轴、次轴、短轴方向。通过不断调整参数进行拟合,最终确立块金值、基台值和最大变程等球状模型参数,优选变异函数模型。变异函数曲线特征(图5)显示,Au元素在3个方向上的变异函数在原点附近表现为块金效应,反映Au品位在各方向呈随机性变化。在一定范围内,变异函数随滞后距的增加而呈正相关,说明Au品位在此区间内是连续、有规律的,具有结构特性;超过此范围,变异函数值在极限方差附近表现出小范围波动,并最终趋于稳定。从变异函数拟合曲线可知,Au品位沿走向、倾向和厚度方向的基台值均为1.21,沿各方向变程有所差异,表现出基台值相同而变程不同的几何各向异性。

图5 变异函数拟合曲线Fig. 5 Variogram fitting graph(a) Principal axis; (b) Secondary axis; (c) Short axis
4.3 交叉验证
目前,校验变异函数拟合较为广泛的方法有离散方差检验、交叉验证等(赵向东等,2021),在3DMine中提供利用地质统计学进行校验的交叉验证法,其实质是比较克里格估值与原始值的偏差(施宝生等,2021)。因此,为确保理论变异函数在矿化域模型的适应性和可靠程度,需对拟合的变异函数模型进行交叉验证(马恒等,2019;景永波等,2021)。
表2和图6为此次验证结果。表2数据显示,误差均值(-0.005 6)与方差(0.436 6)趋近0,符合变异函数交叉验证的判别依据,而克里格方差(0.928 4)与均值(1.150 7)趋近1,说明Au元素在矿床内具有恒定的变异性,因此统计的变异函数参数对矿化域进行品位赋值是合理、无偏的。图6显示,Au品位残差分布聚集基本趋于0,直方图显示呈典型的正态分布,置信区间高于所要求的90%,说明在变异函数计算中并未出现系统的估值误差。

表2 各向异性交叉验证结果
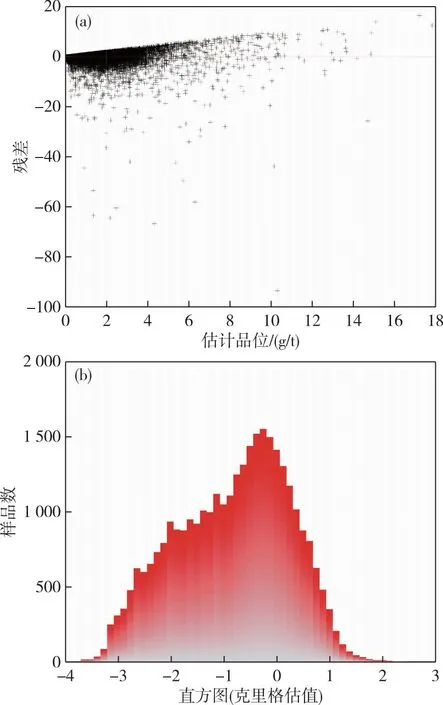
图6 交叉验证残差图(a)与克里格估值直方图(b)Fig. 6 Cross validation residual graph (a) and Kriging estimation histogram (b)
5 资源量估算与可视化
5.1 普通克里格估值
普通克里格法是资源估算最常用的方法之一(刘佶林等,2019),与距离幂次反比法相比,具有引入各向异性、充分考虑局部变异性的优点。经过详细勘探,矿化域内控制程度较高,样品基本统计结果具正态分布特征,可以采用普通克里格法(王珂等,2019)。搜索椭球体参数的设置,一部分采用搜索椭球体拟合的变异函数确定,其中主轴代表矿体方向,由矿床地质可知:矿体走向为NW-SE向,主轴方位159°,与矿体方向一致;次轴倾角90°,接近直立,与控矿断裂产状基本一致;主轴倾伏角为9.3°,矿体存在小角度倾伏。此外,主轴/次轴与主轴/短轴可参考变异函数取值(表3),结合实体模型沿矿体方向的测量长度,最终确定比例分别为2.56、2.14,反映矿化的分布呈带状特征。

表3 普通克里格估值参数
Au品位属性赋值时,主轴搜索半径需考虑工程间距和变程。最少与最多样品数的设置可以减少样品的聚集,提高估值精度,考虑到矿区工程控制程度相对较高、矿体厚度差异较大的特点,选择最少样品数为3,最多样品数为12。品位赋值后进行块体约束,将边界品位(0.2 g/t)以上的块体确定为矿体。
5.2 资源量可视化
资源量的三维可视化表达可为矿体的定量预测和评价提供指导(毛先成等,2016),资源量的分类通过块体模型的属性字段着色来实现。根据资源地质可靠程度分类,地质统计学资源储量分类需综合考虑单个矿种勘查规范中推荐的探矿工程间距,通过设置搜索椭球体的半径来实现,可直观地描述矿体内部资源类别、品位变化及不同品级的分布特征(牛聪聪等,2022)。
根据工程控制程度,将资源量分为控制和推断两类,不同级别的资源量对应的勘探间距不同。研究区低温热液型金矿表现为带状矿化,形态复杂,走向、倾向和厚度方向的变程值分别为185、86、102 m。通常工程间距在矿体变化最大的方向上布设较小,工程间距小于变程方可有效控制矿体的变化,因此将基本工程间距设置为50 m×50 m,低于该工程控制间距下的资源级别为控制资源量,而推断资源的工程间距则相应放大1倍,即低于100 m×100 m的间距、高于50 m×50 m的控制间距。
Au品位赋值时,通常根据设置搜索半径和参与估值的工程数对资源类别进行划分。对控制资源量与推断资源量按照资源类型级别由高到低分别进行,其对应的椭球体搜索半径分别为50、100 m,对应的工程数分别为≥3、≥2,得出分类结果(图7a)。结果显示:靠近地表和浅部位置的工程控制程度较高,对应资源级别也较高;深部控制程度低,推断级别资源占比较少。在走向上矿化连续性较高,这与构造裂隙型热液蚀变金矿化和充填交代型细脉-浸染状型金矿化的实际情况相吻合。
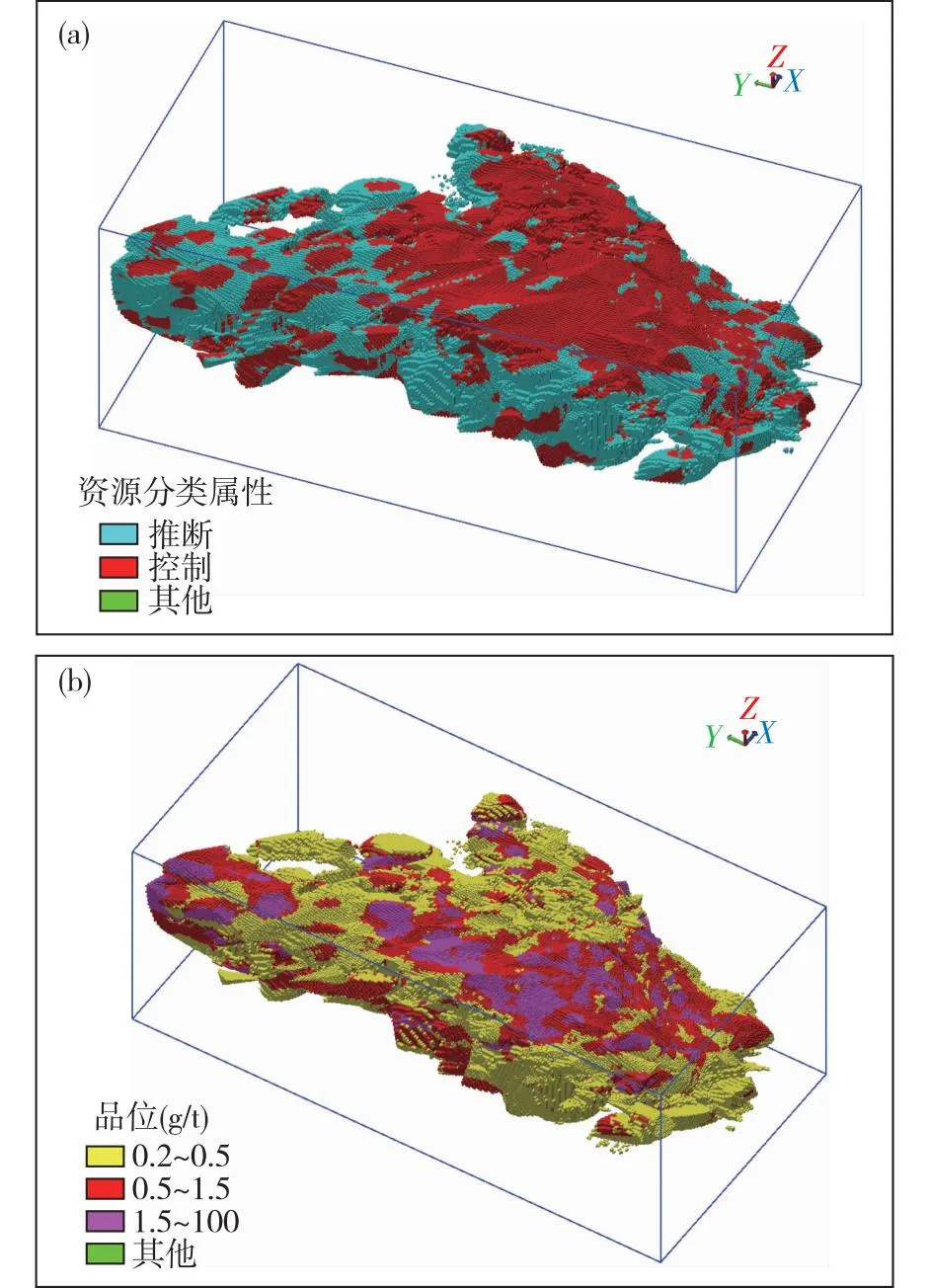
图7 资源量分类结果示意图(a) 按资源类别分类;(b) 按品位品级分类Fig. 7 Schematic diagram of resource classification results(a) Classification by resource category; (b) Classification by content grade
根据边界品位、最低工业品位等工业指标对资源进行分类,划分为低品位Au资源(0.2~0.5 g/t)、中等品位Au资源(0.5~1.5 g/t)和高品位Au资源(>1.5 g/t)。品位区间统计结果(图7b)显示,Au资源具有低品位连续性好而高品位连续性差的特征,存在明显的聚集趋势,可划分为大小2个聚集区,可能为两处不同热液活动的中心。此外,根据资源分布可知三维空间存在小角度侧伏,说明成矿作用呈南高北低的特征,矿体北侧及倾向延伸方向为重要找矿靶区,上述认识有利于进行成矿预测和开采管理。
6 结 论
通过分析南美洲某金矿区矿床地质特征,结合三维可视化理论,建立浅成低温热液型金矿矿化域三维模型,在对样品基本统计的基础上,采用地质统计学方法对资源量进行了估算和可视化表达。
(1)基本统计分析是矿化域模型构建和资源量估算的前提和基础,可为特异值处理、矿化域边界品位的选取等关键步骤提供充分依据。
(2)矿化域模型的建立保证了矿化的完整性和连续性,展示了矿化的空间形态品位分布,有利于复杂矿化体的资源量估算。对矿化域模型生成的块体模型按照资源级别或品位品级进行分类以及按不同要素进行分类,可根据可视化表达效果对资源量进行科学管理。
(3)通过变异函数的拟合和交叉验证、特异值的优化等方法能够确保普通克里格估算的合理性和准确性。相较于传统方法,普通克里格估算可节省大量的估算时间,降低估算过程的误差率,在数字化矿山建设中具有较好的示范作用和应用前景。
