高图像质量的一图藏两图方法
2023-02-28胡欣珏付章杰
胡欣珏,付章杰
1.南京信息工程大学 计算机学院、网络空间安全学院,南京 210044
2.南京信息工程大学 数字取证教育部工程研究中心,南京 210044
以图藏图是一种将秘密图像通过嵌入算法隐藏到自然载体图像中,再由接收方通过提取算法提取出秘密图像的技术,是实现大容量隐蔽通信的有效方法。当前以图藏图隐写算法大多采用基于载体嵌入式的深度学习隐写模型[1],即秘密信息的发送者及接受者可利用训练好的编码-解码网络在载体图像上完成秘密图像的隐藏和提取,秘密信息的发送者及接受者均不需要具备关于图像隐写方面的先验知识。
2017年,Baluja[2]发表了首个以图藏图隐写模型,将一张彩色图像成功隐藏到了另一张同尺寸的彩色图像中。该模型包括预处理网络、编码网络和解码网络。编码网络将经过预处理的秘密图像隐藏进载体图像中,并通过解码网络将秘密图像提取出来。但由于该模型的网络结构仅为简单的几层卷积及激活操作,并未针对隐写任务设计特征提取能力较强的结构,因此过多的信息嵌入导致了该模型生成的含密图像存在明显的嵌入失真,重构的秘密图像平滑区域噪点较多。为进一步提高图像质量,Wu等[3]在2018年提出了Stegnet,通过增加方差损失,使噪声在图像中均匀分布,解决了平滑区域噪点明显的问题。同时,该模型在编码网络和解码网络中均设计了可分离卷积模块,有效降低了训练参数量,但在训练过程中并未正确学习到颜色特征,使得含密图像依旧存在颜色失真的问题。2019 年,Duan 等[4]将U-Net结构型网络作为编码器,借助其对称的上采样、下采样操作以及跳跃连接方法,有效将深、浅层次的特征融合,从而使生成的含密图像质量更高。同年,Duan等[5]又提出了一种基于FC-DenseNets 的隐写算法。该算法的编码网络采用图像分割领域经典的FC-DenseNets结构,通过几个Dense 模块以及跳跃连接操作高效提取图像特征,使含密图像达到了较高的图像质量。同时,与U-Net结构相比,FC-DenseNets 结构参数量较少,有效节省了训练时间。
部分研究者为了减少大容量的秘密图像对载体的影响,将秘密图像由三通道的彩色图像更换为单通道的灰度图像。2018 年,Rehman 等[6]第一次实现了彩色图像对灰度图像的隐藏,该模型采用编码-解码网络实现图像的隐藏及提取,并结合图像质量和网络权重设计了新的损失函数。但同样由于其网络结构仅为简单的几层卷积及激活操作,导致该模型生成的含密图像质量不佳。此后,Zhang 等[7]提出的ISGAN 将彩色载体图像分为Y/U/V三通道,秘密灰度图像仅嵌入在载体图像的Y通道中。之后再将Y通道含密图像与U、V通道进行拼接,生成彩色含密图像。此项操作有效避免了U、V 通道中亮度和色彩信息的丢失。提高了含密图像的生成质量。2020 年,Chen 等[8]提出的模型运用了与ISGAN相近的思路,考虑到人眼对B 通道的较低敏感性,该模型将秘密灰度图像嵌入到彩色载体图像的B通道中,并在模型中加入隐写分析网络以提高生成含密图像的安全性。与ISGAN 相比,该模型生成的含密图像及重构秘密图像的PSNR 均提高了2 dB 左右。考虑到现有隐写模型对网络稳健性鲜有研究,Zhu 等[9]构建了一个含有双重GAN 网络的模型DGANS。该模型运用第二层GAN 网络对经过了裁剪、缩放等操作的增强数据进行训练,从而使模型具有抵抗小幅度几何攻击的能力。但由于双重GAN 网络的训练不稳定,该模型结构的训练难以达到最优的纳什均衡,导致生成的图像质量较差。
此后,从增加隐写容量的角度出发,Baluja提出“一图藏两图”的模型[10],使得模型的嵌入容量达到48 bpp,同时通过隐藏多张图像的方式混淆真正的秘密信息,从而提升了含密图像的安全性。但该模型结构与文献[2]相同,仅根据一图藏两图任务修改了秘密图像输入通道,因此该模型生成的含密图像及重构的秘密图像失真明显。
本文针对一图藏两图模型生成的含密图像以及重构的秘密图像质量较差的问题,为进一步增强一图藏两图技术的实用性,提出基于富特征分支网络的高图像质量的一图藏两图方法。该方法依旧采用编码-解码网络结构,但在编码网络结构、解码网络结构以及损失函数方面均设计了更适合隐写任务的改进,具体工作包括:
(1)设计了Res2Net-Inception 模块,极大提升了双分支编码网络的特征学习能力和特征融合能力,从而保证含密图像质量。
(2)设计了W-Net 网络结构,利用其长短连接结合的特点,同时提取图像深层和浅层特征,从而实现秘密图像的高质量提取。
(3)提出了一种MS-SSIM+MAE+MSE混合损失函数,同时考虑两张图像像素之间的差异以及图像整体的差异,提高含密图像及重构秘密图像的质量。
1 相关工作
1.1 Res2Net残差模块
神经网络会随着不同感受野的卷积操作提取不同层次的特征,因此网络结构越深,表达能力越好。但当模型达到饱和后,精度会开始退化,一味加深网络结构会导致较高的训练误差。为解决上述问题,He 等提出了残差网络结构ResNet[11],2020 年,Cheng 等对ResNet进行改进,提出了Res2Net[12]残差网络结构,如图1所示。
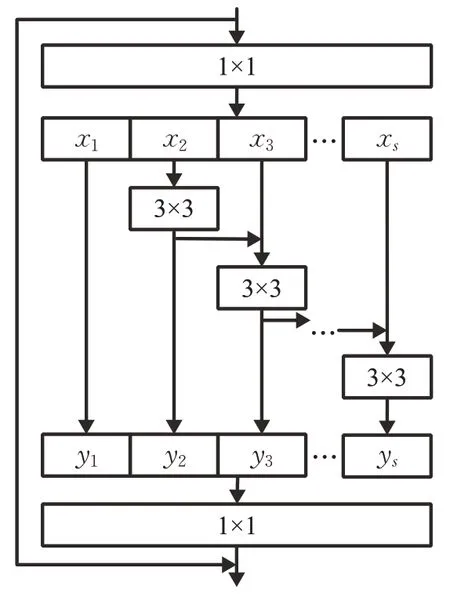
图1 Res2Net残差模块Fig.1 Res2Net residual module
与传统的残差块相比,Res2Net 对经过1×1 卷积后的特征按通道数均分为s块,每块为xi,i∈{1,2,…,s}。每一个xi均经过一个3×3 卷积,卷积操作用ki表示。经卷积操作后的输出用yi表示。则yi可以表示为:
不同的yi会得到不同感受野的特征图,最后将s个特征图合并再经过1×1 卷积得到输出。此种先将通道拆分提取特征再合并的操作可以更高效地学习图像特征。
1.2 Inception模块
Inception[13]模块属于2014 年ILSVRC 冠军算法GoogLeNet 的系列模型,包括1×1 卷积层、3×3 卷积层、5×5卷积层和3×3最大池化层,如图2所示。Inception模块运用不同大小的卷积核提取特征,并在后期将不同感受野大小的特征进行融合,提高了网络对尺寸的适应性。同时,在3×3卷积层前、5×5卷积层前以及最大池化层后均添加了1×1 卷积层,有效降低了特征图厚度,提高网络效率。
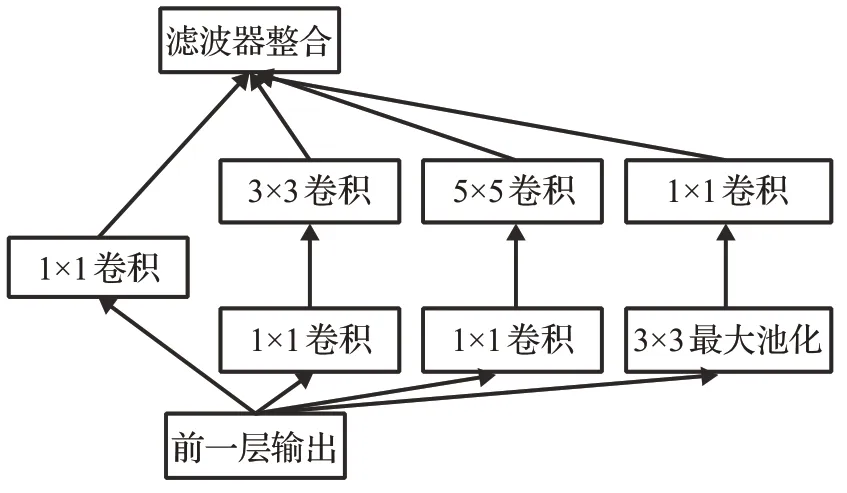
图2 Inception模块Fig.2 Inception module
1.3 一图藏两图模型
Baluja 提出的一图藏两图模型中,通过预处理网络、编码网络和解码网络完成了两张彩色图像的隐藏和提取,其模型结构如图3所示。两张秘密图像经过通道合并后输入预处理网络,预处理网络将其基于色彩的像素转换为有利于编码的特征;编码网络将经过处理的两张秘密图像隐藏进载体图像生成含密图像,解码网络从含密图像中将两张秘密图像提取出来。预处理网络、编码网络和解码网络的具体网络结构如表1所示。
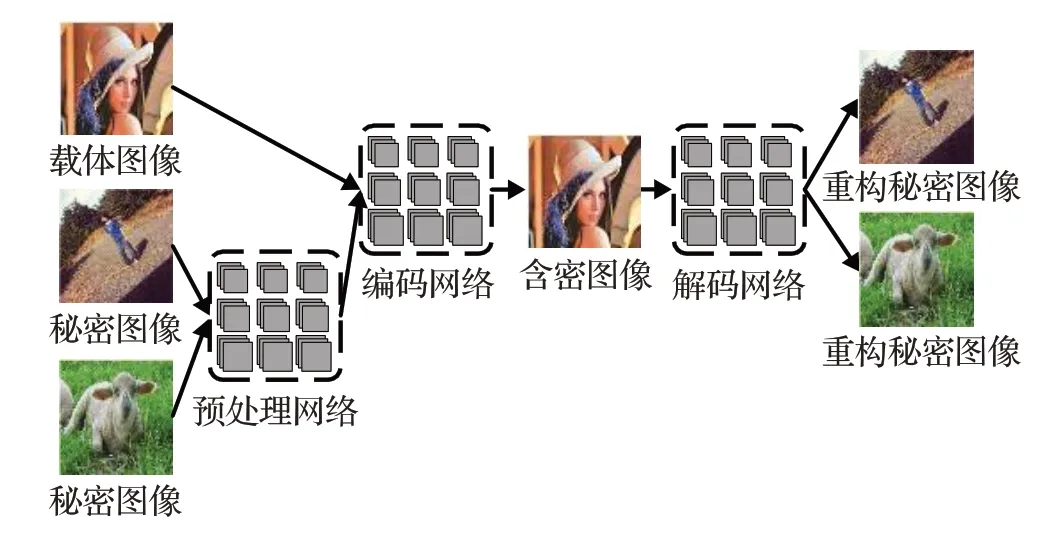
图3 Baluja一图藏两图模型结构Fig.3 Baluja’s model of hiding two images
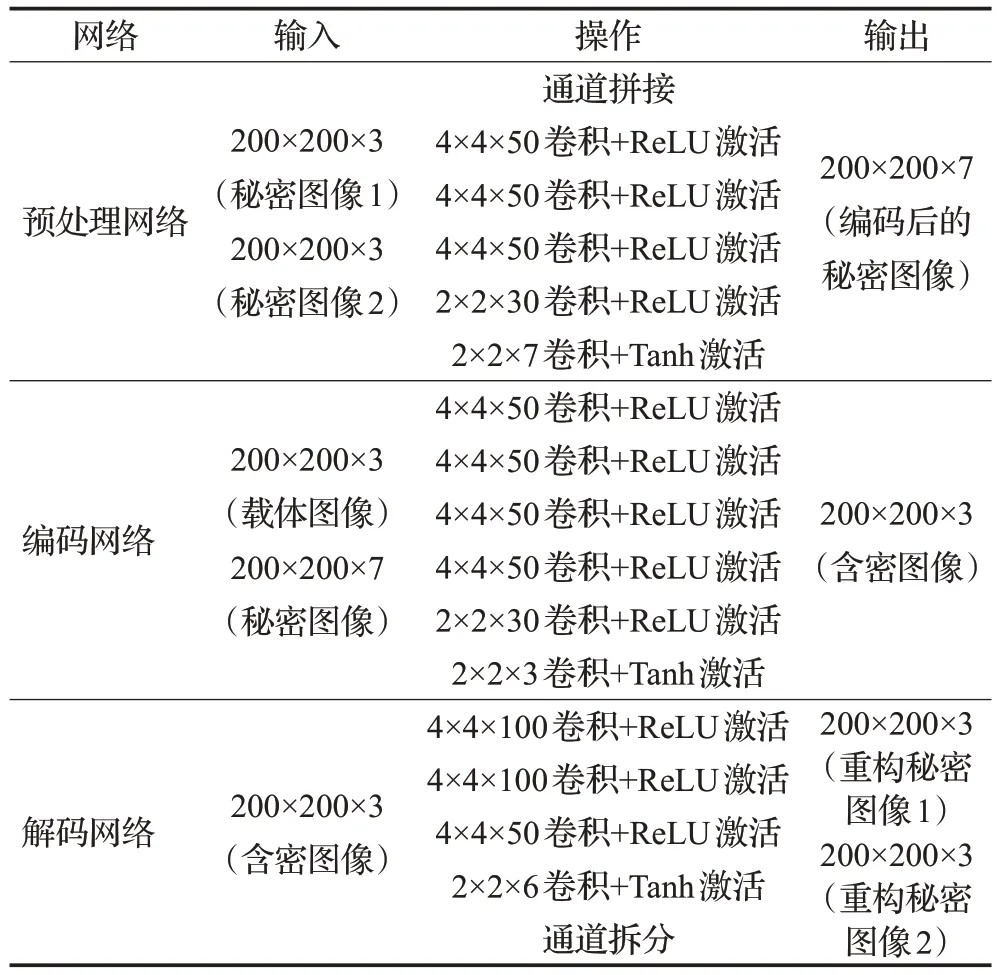
表1 Baluja一图藏两图模型网络结构Table 1 Network architectures of hiding two images
在模型训练过程中,Baluja 使用均方误差(mean square error,MSE)作为损失函数,如式(2)所示。
其中,C表示载体图像,C′表示含密图像,S表示秘密图像,S′表示重构出的秘密图像。该模型采用端到端的训练方式,前半部分计算的载体图像和含密载体的差异仅影响编码器网络的训练;后半部分计算的重构秘密图像和原始秘密图像的差异值则会同时影响编码网络和解码网络的参数。参数β用于权衡含密图像生成真实性与秘密图像提取准确率,β越大,恢复出的秘密图像质量更好。
然而,针对编码-解码网络结构而言,Baluja 的模型结构较为简单,无法提取出足够的特征用于含密图像及重构秘密图像的生成。此外,针对损失函数而言,MSE损失仅仅是逐像素比较差异,没有考虑到人类的视觉感知,即忽略了图像亮度、结构性等信息。
因此,本文受Baluja工作的启发,依旧采用编码-解码网络进行秘密图像的隐写和提取。但针对编码网络设计了特征提取能力更强的Res2Net-Inception模块,针对解码网络设计了全尺度特征捕捉网络W-Net,针对损失函数设计了更符合人类视觉感知的混合损失函数。
2 基于富特征分支网络的高图像质量的一图藏两图方法
2.1 一图藏两图模型整体框架
本文提出了基于富特征分支网络的高图像质量的一图藏两图模型,如图4所示,由编码网络、解码网络两部分组成。编码网络中,设计Res2Net-Inception 模块,以提高含密载体的质量;解码网络中,设计W-Net 网络结构,长短连接结合抓取不同层次的特征,保证提取出的秘密图像的真实性。
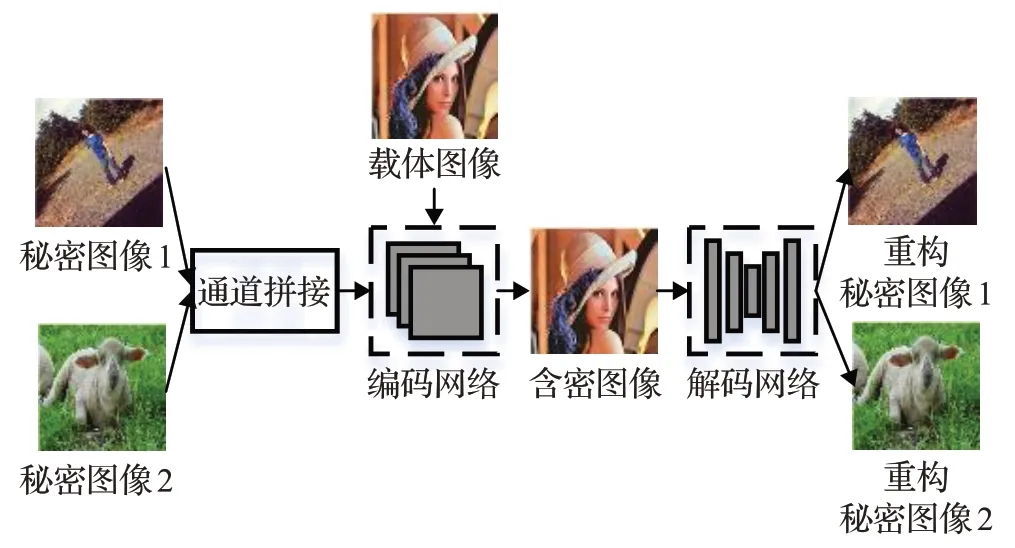
图4 一图藏两图模型整体框架Fig.4 Overall architecture of hiding two images
2.2 基于Res2Net-Inception模块的双分支编码网络
2.2.1 Res2Net-Inception模块
本文将Res2Net模块中的两个1×1卷积替换为3×3卷积,将通道拆分后的3×3 卷积替换为Inception 模块,并在最后的3×3 卷积后加入通道注意力机制层,构成Res2Net-Inception模块,其结构如图5所示。
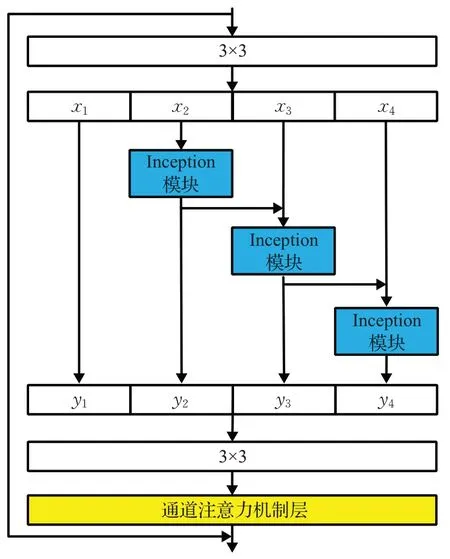
图5 Res2Net-Inception模块Fig.5 Res2Net-Inception module
此时yi可以表示为:
其中,IC(·)为Inception模块。相比于原始的3×3卷积操作,Inception 模块可以同时从不同感受野提取xi的特征,特征学习能力更强。
在最后的3×3卷积后,本方案加入了通道注意力机制[14]层(简称为SE层)。该层可以通过建模各通道之间的关系来自动学习每一个特征通道的重要程度,即自动为每一个通道分配一个对应的权值。模型通过不断训练,抑制与隐写任务关系不大的特征,提升重要特征通道的权值,从而达到更好的隐写效果。
假设特征图合并并经过3×3卷积后,得到的特征为z。首先,SE层会将该特征的每一个通道上的空间特征编码为一个全局特征,计算方法为:
其中,H、W和C分别是图像的高、宽和通道。
得到了每通道特征的全局描述后,通过降维-ReLU激活-恢复维度-Sigmoid激活的操作,学习各个通道之间的依赖关系,从而得到属于每一个特征通道的权重系数ec:
最后,将学习到的通道权值乘上原始特征,得到最终特征F:
2.2.2 编码器结构
编码器结构如图6所示,包括特征提取阶段和特征融合阶段。在特征提取阶段,编码器运用其双分支结构分别独立地提取载体图像和秘密图像的特征。每个分支上的Res2Net-Inception 模块负责对经过卷积操作后的特征在同一分辨率进行不同尺度的特征提取和通道重要性学习。然后,在特征融合阶段,编码器运用拼接操作和反卷积操作将提取到的特征进行融合,最后得到含密图像。
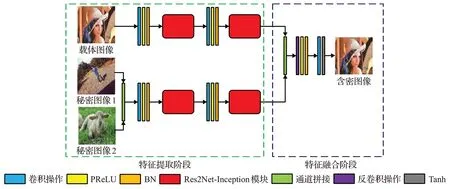
图6 编码器结构Fig.6 Encoder architecture
2.3 W-Net解码网络
为实现对两张秘密图像的无损提取,应设计特征提取能力较强的双分支输出网络作为解码网络。已有方法常使用U-Net结构型网络,通过多层下采样及上采样操作提取深层次抽象的图像信息,但在该过程中,一些图像细节易被丢失。为了全尺度捕捉图像细粒度细节和粗粒度语义,设计W-Net 结构作为解码网络,在普通U-Net结构型网络中设计双输出分支及跳跃连接操作。其结构示意图如图7所示。
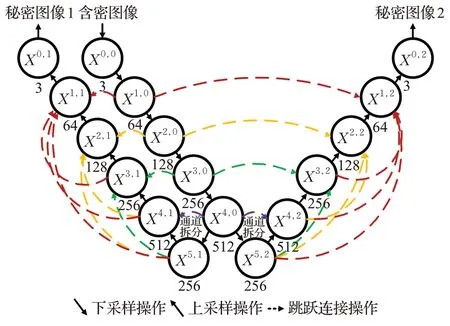
图7 W-Net解码网络Fig.7 Decoder network W-Net
W-Net网络的输入为含密图像,经过四层下采样操作后,在最后一个下采样节点进行通道分离操作,分裂成两个分支分别执行两张秘密图像的重构工作。
对于W-Net的跳跃连接操作,假设节点为xi,j,其中i为下采样的层数,j为分支数,则xi,j节点的计算公式为:
其中,C(·)为卷积操作+LeakyReLU激活函数+BN操作,F(·)代表反卷积操作+LeakyReLU 激活函数+BN 操作,[·,·]代表通道拼接操作,U(·)代表上采样操作。通过跳跃连接操作,其上采样部分的节点可以得到两方面的特征信息,一是下采样部分与其同一分辨率的细节特征,二是上采样部分更高分辨率的特征图。将浅层次细节和深层次语义相融合,从全尺度搜索更多的图像信息,从而使恢复出来的两张秘密图像质量更好。
2.4 混合损失函数
为了让模型可以综合考虑到两张图像像素以及整体之间的差异,本文将MS-SSIM(multi-scale structural similarity index)[15]、MAE(mean absolute error)和MSE损失引入构建一个复合损失函数。其中,MSE 表示图像x和y的均方误差,计算公式为:
其中,p表示图像像素点,N表示图像总像素。
MAE损失是两张图像逐像素比较差异,计算公式为:
MSE 损失以及MAE 损失仅是逐像素比较差异,没有考虑到人类的视觉感知,即忽略了图像亮度、结构性等信息,因此引入MS-SSIM损失。MS-SSIM损失运用到了不同尺度的SSIM(structural similarity index),相当于考虑了不同的分辨率,很好地解决了SSIM 损失高斯滤波参数不好平衡的问题。MS-SSIM损失的计算公式为:
其中,μx、μy分别为x和y的平均值,也代表图像x和y的亮度;K1为一个小于等于1的常数;M为自定义尺度,在此取值为5;σx、σy分别为x和y的标准差,也代表图像x和y的对比度;σxy为x和y的协方差,也代表图像x和y的结构相似度;K2为一个小于等于1的常数。通常用1-MS-SSIM(x,y)来衡量两张图像的差异。
MS-SSIM 容易导致亮度和颜色的偏差,但可以较好地保留高频信息[16]。MAE损失可以保证亮度和颜色不变化,因此将两者结合起来构成混合损失函数。同时,为防止陷入局部最优,在运用该混合损失函数训练网络收敛后,继续用MSE损失进行训练,可以达到更好的训练效果。
由MS-SSIM、MAE、MSE 构成的混合损失函数如式(11)~(14)所示。
其中,c代表载体图像;c′代表含密图像;s1代表第一张秘密图像;代表重构的第一张秘密图像;s2代表第二张秘密图像;代表重构的第二张秘密图像;α、β、γ是超参数,α用于权衡MS-SSIM损失与MAE损失分量的重要程度,β、γ用于权衡含密图像生成真实性以及秘密图像提取准确率。
3 实验及分析
3.1 实验基础
为了验证本文提出方案的有效性,实验使用PASCAL VOC2012 和Tiny ImageNet 两个数据集。从PASCAL VOC2012 数据集中随机选择15 000 张图像作为训练集,1 500 张作为测试集;从Tiny ImageNet 数据集中随机选择1 500 张作为测试集,所有图像的尺寸统一调整为256×256。算法的实验环境是谷歌云端TPU服务器,程序使用python3.7版本的tensorflow深度学习框架实现。
上述方案在训练时,采用Xavier初始化方法来初始化模型参数;初始学习率设置为10-3。网络首先采用MS-SSIM+MAE 混合损失函数训练编码-解码网络,网络收敛后采用MSE损失函数继续训练编码-解码网络,训练50 轮后采用keras 的回调函数,根据当前损失动态调整学习率,学习率的衰减因子为0.2。受限于算力,批尺寸设置为8;采用Adam 随机梯度下降算法来进行参数的迭代优化。根据经验进行多轮尝试后,将损失函数中的超参数α、β、γ分别设置为0.6、1、1。因为本文想要恢复出较高质量的秘密图像,所以将权衡含密图像生成质量和秘密图像提取质量的参数β和γ均设置为1。
3.2 含密图像及重构秘密图像质量测试
为了验证本文提出方案设计的有效性,对本文方案以及文献[10]方法生成含密图像以及重构秘密图像的质量进行对比。常用的衡量图像质量的指标是SSIM和PSNR(peak signal to noise ratio),其在两个数据集上的实验结果如表2所示。可以看到,本文方案生成含密图像及重构秘密图像的质量远优于文献[10]的方法,在Tiny ImageNet数据集上,本文方案生成含密图像的PSNR值比文献[10]方法提高了12 dB,SSIM 值比文献[10]方法提高了5%;两张重构秘密图像的PSNR 平均值比文献[10]方法提高了10 dB,SSIM 平均值比文献[10]方法提高了10%。
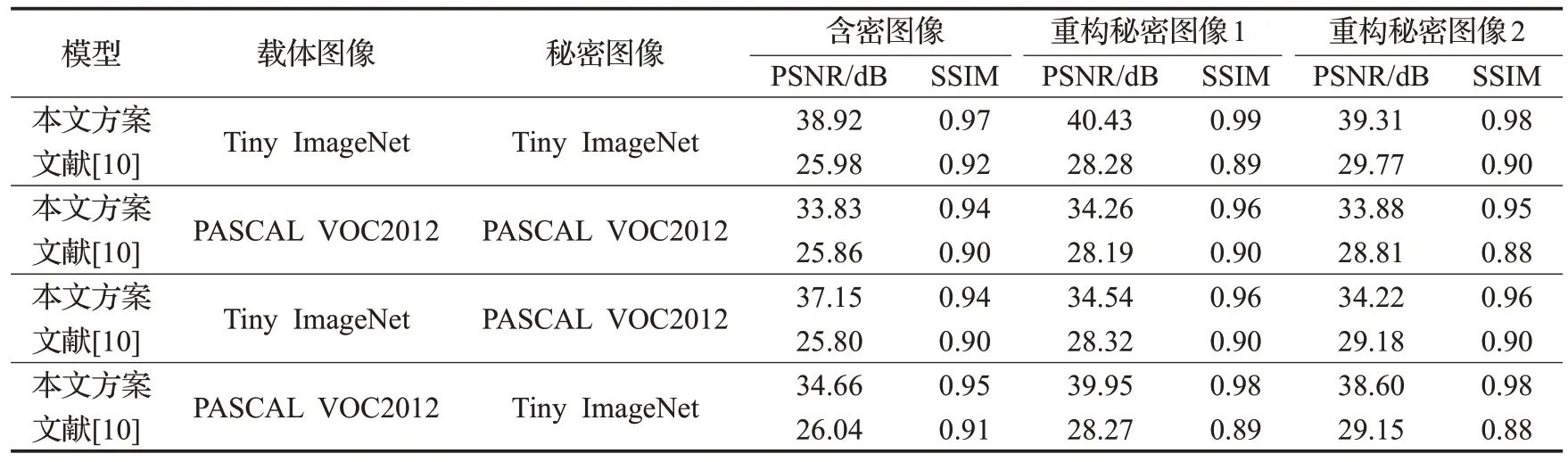
表2 两种方案的图像视觉质量对比Table 2 Visual comparison of image quality for two solutions
图8和图9给出了本文方案与文献[10]在两个数据集上可视化结果的比较。可以看到,即使将两张秘密图像隐藏到一张相同尺寸的载体图像中,本文方案生成的含密图像以及重构的秘密图像仍具有较高的视觉质量,不存在明显的颜色失真问题。为了展示原始图像和生成图像之间的差异,将其残差图像放大了10 倍。与文献[10]对比,本文方案的残差图像更暗,说明本文方案生成的含密图像以及重构的两张秘密图像均有着更小的误差,与原始图像更加接近。实验表明,本文方案生成的含密图像以及重构的秘密图像具有较高的图像质量,在定性和定量方面的指标都优于文献[10]。与文献[10]相比,本文方案针对编码网络设计了双分支输入以及Res2Net-Inception模块,通过两个分支分别提取载体图像与秘密图像特征,可以防止两类图像特征混杂,而加入的Res2Net_Inception 模块从不同感受野提取图像特征,并通过注意力机制抑制与隐写任务关系不大的特征,从而使含密图像拥有良好的视觉效果。针对解码网络设计了W-Net 结构,从全尺度捕捉图像特征,从而提高重构秘密图像质量。针对损失函数设计的混合损失综合考虑两幅图像像素级别差异以及整体差异,进一步促进图像质量的提高。因此,可以得出结论,在网络中将不同层的输入映射融合作为深卷积层的输出,最大限度地利用全尺度的特征映射,以及设计适用于隐写任务的损失函数是提高隐写图像视觉质量的有效方法。
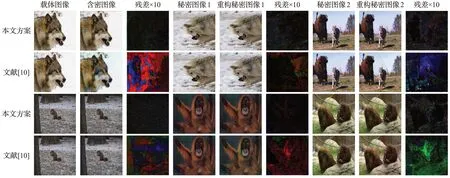
图8 两个在Tiny ImageNet数据集上的可视化结果Fig.8 Two visualization examples on Tiny ImageNet dataset
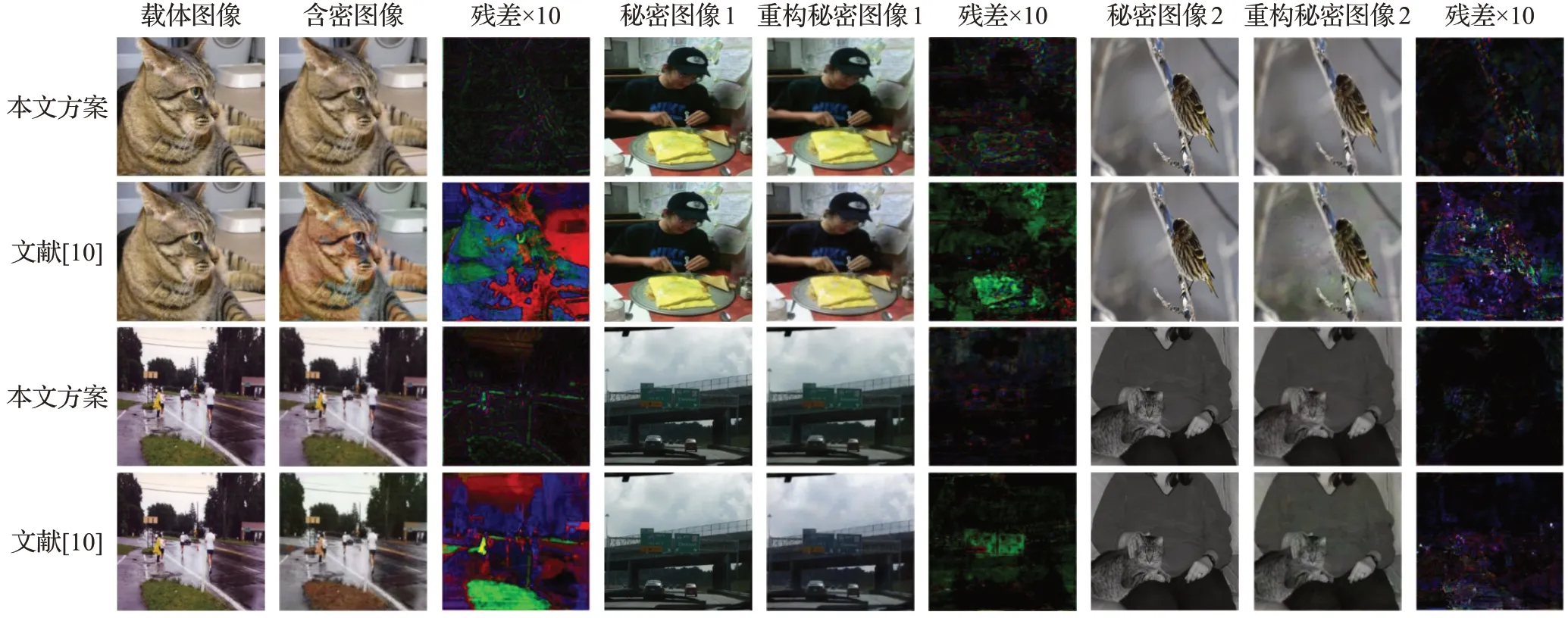
图9 两个在PASCAL VOC2012数据集上的可视化结果Fig.9 Two visualization examples on PASCAL VOC2012 dataset
3.3 消融实验
消融实验主要讨论了不同损失函数及其组合对图像质量的影响,测试数据集为Tiny ImageNet,其结果如表3所示。在单独使用MS-SSIM损失训练时,含密图像的PSNR值偏低,这是由于MS-SSIM损失可以较好地保留高频区域的对比度,而秘密图像大多隐藏在载体图像纹理复杂的区域,从而导致生成的含密图像质量较差。采用了MS-SSIM+MAE混合损失后,各项测试指标均得到了较大的提升。而采用了本文所述的MS-SSIM+MAE混合损失与MSE 损失交替训练的方法后,图像质量进一步得到了提升,验证了本文所提MS-SSIM+MAE+MSE混合损失函数的优越性。
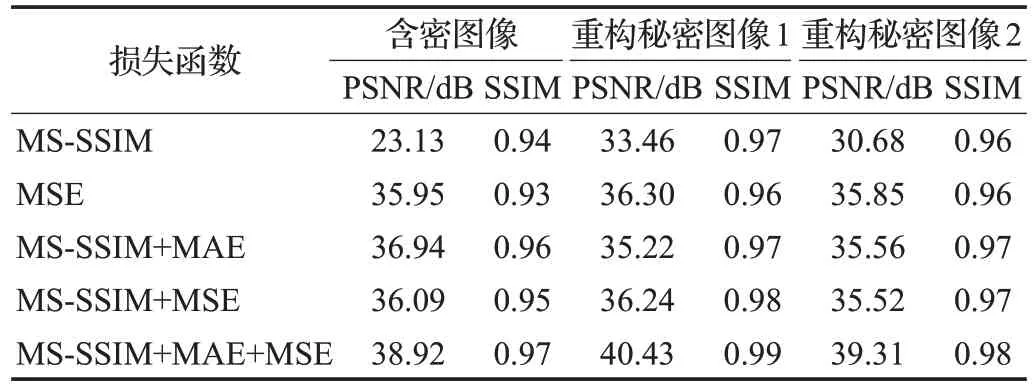
表3 不同损失函数的消融实验Table 3 Ablation experiments for different loss functions
3.4 极端情况下的图像质量测试
为了进一步探索本文方案的隐写能力,对一些极端情况下的图像隐藏进行测试。测试图像包括单色图像、噪声图像和自然图像。从图10和表4结果中可以看到,在单色图像和自然图像相互隐藏的情况下,生成的图像均具有较好的图像质量。但噪声图像作为载体或作为秘密图像时,噪声图像本身不能被很好地重构出来。

表4 极端情况下的图像质量Table 4 Visual quality results for extreme cases

图10 极端情况下的图像视觉效果Fig.10 Visual results for extreme cases
4 结束语
本文提出了一个基于富特征分支网络的高图像质量的一图藏两图方法,可以将两张秘密图像隐藏到一张相同尺寸的载体图像中,且保证生成的含密图像及重构的两张秘密图像具有较高的图像质量。编码网络中的Res2Net-Inception 模块在同一分辨率对不同尺度的特征进行提取,并自动抑制与隐写任务关系不大的非重要特征,从而实现特征的高效提取。解码网络的W-Net结构运用长短连接结合的方式抓取不同层次的特征,并运用两个分支同时提取两张秘密图像的特征,从而提高了秘密图像的重构质量。实验结果表明,本文方案生成的含密图像以及重构的秘密图像均具有较高的视觉质量。接下来将进一步优化以图藏图网络,在保证隐藏容量、图像质量的同时提高含密图像的抗隐写分析能力。
