基于混合图神经网络的方面级情感分类
2023-02-28唐恒亮尹棋正常亮亮
唐恒亮,尹棋正,常亮亮,薛 菲,曹 阳
北京物资学院 信息学院,北京 101149
方面级情感分类是当前自然语言处理领域中备受关注的一项基本任务[1]。不同于普通情感分类对一篇文章或一个句子所属的情感极性进行区分,方面级情感分类的任务是判断给定语句中所描述对象不同方面的情感极性,例如:
“A mix of students and area residents crowd into this narrow,barely there space for its quick,tasty treats at dirt-cheap prices.”
该语句摘自SemEval2014 Restaurant 数据集[2],语句中描述了某家餐厅的space、tasty 和prices,相应的方面级情感分类结果分别为消极、积极、积极。方面级情感分类提供了更精确具体的情感信息,因此在很多领域,特别是电子商务和社交网络舆情分析中得到广泛的应用,受到学术界与业界的广泛关注。
近年来,深度学习在自然语言处理领域不断取得令人瞩目的成就,越来越多的方面级情感分类模型使用神经网络。早期应用于方面级情感分类的神经网络[3]相较于传统的机器学习,在准确率、泛化能力以及鲁棒性上都有较大的提升。但是,方面级情感分类正确的前提是将方面词与相关上下文情感表达词正确匹配,此类模型缺乏解释句法依赖的机制,难以实现较高的分类准确率。Tang 等[4]通过研究证实了方面词与上下文情感表达词依赖关系对方面级情感分类的重要性。受此启发,结合注意力机制的长短期记忆网络(long short-term memory,LSTM)模型被广泛地应用[5]。此外,Xue和Li[6]认为某一方面的情感极性通常由一系列关键短语所决定,提出了一种注意力机制增强的卷积神经网络模型,取得了优异的效果。
随着对注意力机制的深入研究,发现通过引入注意力机制,能够从复杂的语句中捕获与方面词相关的细节情感特征。一些研究人员使用将注意力机制与卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)结合的方法进行序列分类任务。Tang 等[7]提出了一种基于注意力机制的MemNet模型,该模型基于输入语句的词向量构成的外部记忆进行注意力学习。Chen等[8]在MemNet的基础上提出了一个基于注意力机制的RAM(recurrent attention on memory)模型。
尽管基于注意力机制的模型能够在有限的程度上捕捉方面词与上下文词之间的情感关系特征,并取得较大的性能提升,但是由于注意力机制缺乏显式的句法依赖捕捉机制,在方面级情感分类的应用上仍存在较大的局限性。如对于上文SemEval2014 Restaurant数据集例子中tasty方面,注意力机制可能在某些情况下错误地注意到narrow 和barely,这将会对分类准确率产生较大的影响。
为了解决基于注意力机制模型的局限性,更好地利用方面词与上下文情感表示词之间的句法依赖关系,Zhang等[9]提出了一种应用在句法依赖树上的图卷积网络模型,能够捕捉句法依赖树中所包含的句法依赖关系。图卷积网络(graph convolutional network,GCN)是一种用于处理非结构化数据的神经网络,因此对自然语言处理中的非结构化数据的处理具有优势[10]。得益于句法依存树的引入,受到Zhang等人的启发,Tang等[11]使用Bi-GCN 获取依赖树的句法信息与Transformer 获取的文本平面表示迭代交互方式,提出了一种双重Transformer 结构模型进行方面级情感分类。Huang 和Carley[12]提出了一种方面依赖图注意力网络,更明确地利用了方面词与相关上下文情感表示词之间的关系。在如图1所示例句“nice beef but terrible juice.”的原始句法依赖树实例中,方面词“beef”和“juice”均与其情感表达词“nice”和“terrible”相连接。
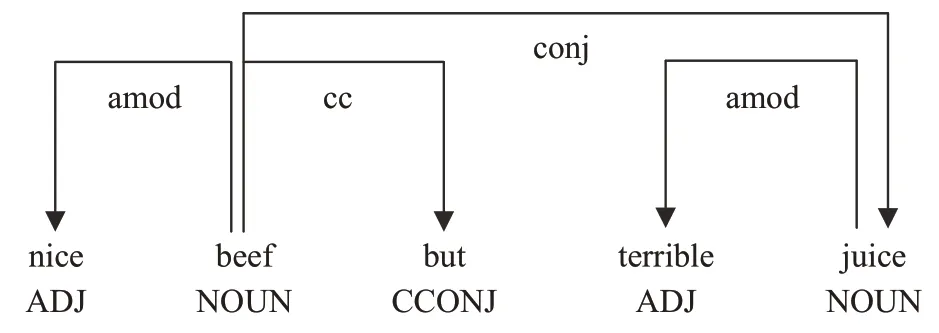
图1 句法依赖树实例Fig.1 Syntactic dependency tree example
建立在句法依赖树上的图神经网络模型被广泛地证明能对方面级情感分类产生显著的积极效果,其主要原因归功于图神经网络对句法依赖树这种图数据强大的特征提取能力。但是在该类方法中,句法依赖树的获取通常使用一些自然语言处理基础工具(如spaCy、CoreNLP等),由于目前依赖信息解析性能的不完善,不可避免地产生错误。此外,由于方面级情感分类应用的主要领域为电商评论或社交平台信息,此类语句存在着大量的不规范表达,在语法上具有随意性,因此该类模型性能并不能在这些数据上获得明显提升。
针对上文所提出的局限性,本文提出了一个具有创新性的混合图神经网络模型(mixture graph neural network model,MGNM)。本文主要贡献如下:
(1)设计了一种结合GCN 网络和残差图注意力网络(Res-graph attention network,Res-GAT)的混合模型。与现有模型的主要区别在于,该模型使用GCN 提取句法依赖树上的句法依赖关系,然后针对目前此类模型所面临的句法依赖树不稳定性问题,创造性地引入Res-GAT构建词级依赖关系作为GCN提取的句法依赖关系的补充,并且利用BiAffine模块在L-layer GCN与Res-GAT之间进行信息交互。
(2)提出了一种应用于连通词关系图的Res-GAT,通过为GAT 设计独特的残差连接,改善了非单层GAT极易出现的过平滑问题。在Res-GAT部分,将所输入语句中的词作为节点,构建连通词关系图,然后Res-GAT中的多头注意力机制为节点之间关系分配权值,得到词与词之间不同的重要性关系,以此作为GCN 提取句法依赖关系的补充参与方面词情感极性的判断。
(3)在Twitter[3]、SemEval2014 Restaurant、Laptop、SemEval2015 Restaurant[13]和SemEval2016 Restaurant[14]五个数据集上进行大量的实验验证,并与当前主流的相关工作进行比较,实验效果证明本文模型优于相关工作。并设置了一系列的消融实验,证明了本文模型相关设置与改进的合理性。
1 模型描述
基于混合图神经网络的方面级情感分类模型MGNM如图2所示。
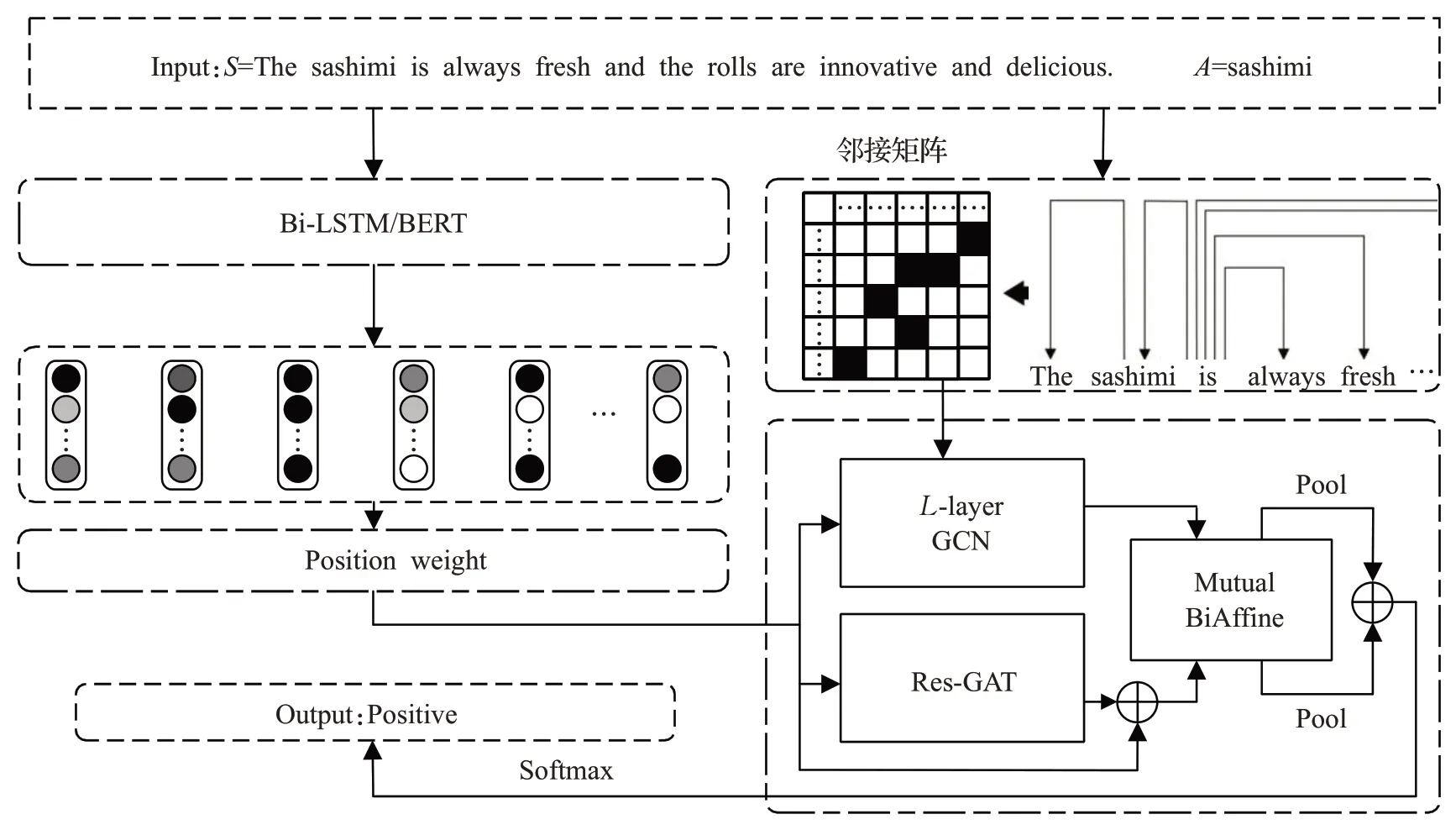
图2 MGNM模型示意图Fig.2 Schematic diagram of MGNM
在MGNM 中采用GloVe[15]和双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)或预训练BERT(bidirectional encoder representations from transformers)[16]两种方法获取词向量与上下文表示。模型设置了一个L-layer GCN 获取句法依赖信息,设置Res-GAT 构建包含单词之间重要性关系的词级依赖关系,然后采用Mutual BiAffine 模块使两种特征信息交互产生影响,最后将两种特征拼接后作为最终特征表示。以下介绍MGNM的各组成部分与原理。
1.1 模型输入
给定一个n个词的句子S,表示为S={w1,w2,…,wτ,…,wτ+m-1,…,wn},其中包含m个方面词,τ为方面词开始的标记。本文采用GloVe 和Bi-LSTM 或预训练BERT 两种方法获取词向量与上下文表示,下面分别对这两种方法进行介绍。
1.1.1 GloVe与Bi-LSTM
预训练嵌入矩阵GloVe 是由斯坦福大学发布的一个基于词频统计的词表征工具。MGNM 使用GloVe 将给定句子S中的单词映射到低维向量空间,获取单词的词嵌入向量,句子S的嵌入向量表示为,N表示词的个数,demb表示词嵌入向量的维度。
为获取语句的上下文信息,将句子的词嵌入向量输入到Bi-LSTM 网络,Bi-LSTM 是由前向LSTM 与后向LSTM 两个方向的LSTM 组成,将前向LSTM 与后向LSTM隐藏层输出拼接作为输出,因此能够从两个方向提取语句的上下文信息,从而构建出包含文本上下文信息的隐藏状态向量。对于组成Bi-LSTM的LSTM,计算公式如下:
式中,et为t时刻输入到Bi-LSTM中的词向量,it、ft、ot分别为输入门、遗忘门和输出门,ct和ct-1为t时刻与t-1 时刻记忆单元状态,ht和ht-1代表t时刻与t-1时刻LSTM 的隐藏层输出,Wi、Wf、Wo、Wt为可训练权重矩阵,bi、bf、bo、bt为偏差,σ代表sigmoid 函数,tanh为双曲正切激活函数。
由于Bi-LSTM是由前向LSTM和后向LSTM组成,并将两个不同方向的LSTM输出拼接,计算公式如下:
通过以上Bi-LSTM对所给语句S的词向量进行上下文编码后,输出隐藏状态向量矩阵:
其中,时间步t的隐藏状态向量表示为,dh为Bi-LSTM输出隐藏状态向量的维度。
1.1.2 BERT
本文使用BERT 模型生成所给语句单词的特征表示,BERT 是Google 发布的一种预训练语言表征模型。在该模型中将BERT 所提取的特征表示作为词向量输入到图神经网络中。为便于BERT的调整和训练,将语句与方面词结合成完整句子输入到BERT中,具体形式为[CLS]+S+A+[SEP],其中S为上下文语句,A为方面词。输出的上下文表示为:
1.2 MGNM
1.2.1 位置权重
受Zhang等人启发[9],考虑与方面词相近的上下文词的重要性,将输入层输出的HS传递到GCN或Res-GAT之前,为句中单词增加位置感知变换,其目的是减少依赖解析过程中产生的噪声与偏差。计算过程如下:
式中,F(·)代表位置感知变换函数,qi∈ℝ 代表第i个单词的位置权重。最终句子S的上下文表示矩阵HS经过位置感知变换后得到,向量维度不发生变化。
1.2.2 多层GCN
为获取句法依赖特征,本文设置了一个应用于句法依赖树的多层GCN。具体来说,首先为给定语句构建句法依赖树(本文使用Spacy模块获取),然后根据句法依赖树可轻易得出包含句法依赖树结构关系的邻接矩阵A∈ℝn×n,n表示所给语句包含单词数。此外,根据GCN 的特性,为节点加入自循环可以在GCN 聚合更新节点信息,更好地保留原节点信息,因此在邻接矩阵A中为每个节点增加自循环,将节点与自身连接,即Aii=1,i为句中第i个单词。
图卷积网络是一种用于处理非结构化数据的特征提取器,对自然语言处理领域的图结构数据处理具有很强的优势。文中设置的l-layer GCN 可以使每个节点受到l次邻居节点的影响。这种方法对句法依赖树进行卷积,将句法依赖信息添加在有关词序的文本特征上,实现句法依赖特征的汇集。
首先,将经过位置感知变换的上下文表示Hq输入到l-layer GCN,即将节点的特征输入到GCN 中,然后使用归一化因子进行图卷积运算,如下:
1.2.3 Res-GAT
GAT 是图神经网络结合注意力机制的一种重要变体,在节点特征聚合操作时,能够使用注意力机制为节点之间分配重要性权值,提高网络的表达能力。在MGNM 中将所输入语句中的词作为节点,构建包含连通词关系图,GAT负责利用多头注意力机制对词与词之间分配权值,得到词与词之间依赖的重要性关系。下式为节点i在第l+1 层特征表达计算过程:
为进一步提升图注意力层的表达能力和模型的稳定性,在图注意力层加入K组相互独立的注意力机制,然后将输出结果拼接:
值得注意的是,在该部分首先为所输入语句构建一个强连通图,该图将句中单词作为节点,图中每个节点都与其他节点相连接,然后获取该连通图的邻接矩阵Aq∈ℝn×n,n表示所给语句包含单词数。与句法依赖树邻接矩阵A相似,在Aq中也增加节点自循环保留节点自身信息。此外,考虑到多层GAT 极易出现过平滑问题,本文为GAT设计了独特的残差连接方式:
1.3 特征结合
为了使GCN 与Res-GAT 所提取的两种特征HL∈与HL′∈充分融合并交换相关特征,模型采用BiAffine Module进行特征融合。
式中,W1与W2为可训练权重矩阵,θ1和θ2为从HL到HL′与HL′到HL的临时线性映射矩阵,HB为HL′到HL的映射,同样HB′为HL到HL′的映射。
然后将HB和HB′进行平均池化:
随后将它们进行拼接得到最终表示r:
1.4 情感分类
将最终特征表示r馈送到全连接层,随后是Softmax归一化层,最后产生概率分布的情感极性决策空间。
其中,dp与情感标签维度相同,学习权重表示为Wp∈,偏置表示为。
1.5 模型训练
本文所提出的DWGCN采用交叉熵损失和L2正则化的标准梯度下降算法训练。
2 实验设计及分析
2.1 实验平台与数据集
本实验采用的实验平台信息如表1所示,所有模型的训练与测试均在GPU上进行。
表1 实验平台Table 1 Experiment platform
为验证本文提出的方面级情感分类模型的有效性,本文的实验在Twitter数据集,以及分别从SemEval2014 task4、SemEval2015 task12 和SemEval2016 task5 中获取的四个数据集(Rest14、Lap14、Rest15、Rest16)上进行,这四个数据集分别是来源于电商平台对笔记本电脑和餐厅的评价。五个数据集中方面词情感极性包括积极、消极和中性三种。本文所采用的五个数据集情况统计如表2所示。
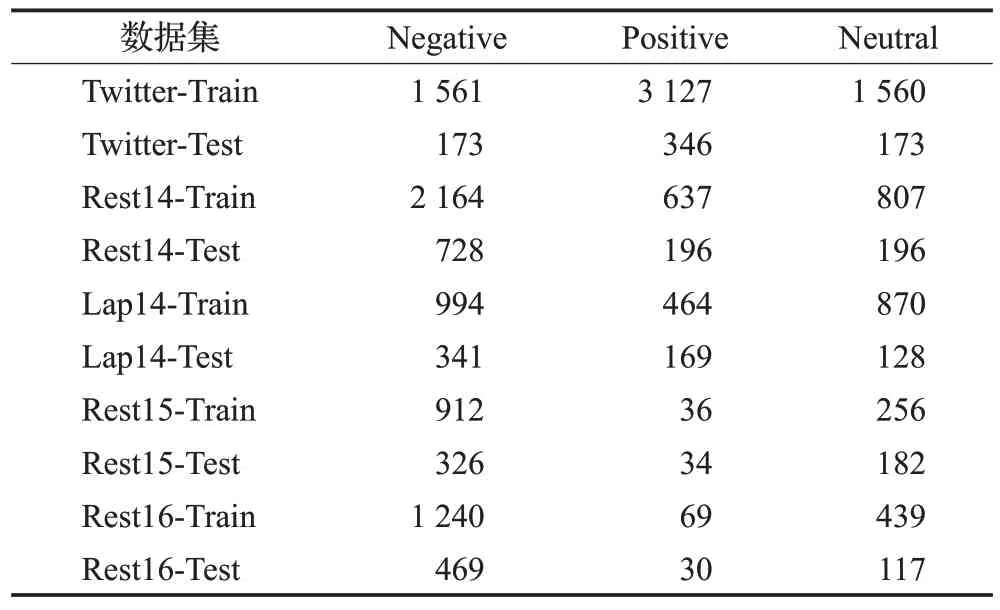
表2 数据集信息表Table 2 Statistics for datasets
2.2 实验设置
为探究模型的性能,在该实验中采用了两种输入方式。在MGNM-GloVe 中使用300 维预训练GloVe 模型初始化上下文得到词向量,Bi-LSTM 的隐藏状态向量维度也为300。在MGNM-BERT 中使用预训练BERT模型获取词向量,嵌入维度为768。模型中使用Adam(adaptive moment estimation)优化器,除BERT 以外所有权重均采用均匀分布初始化方法。对MGNM的GloVe静态嵌入与BERT 嵌入两种方式设置了不同的学习率。此外根据最优实验结果确定GCN与Res-GAT层数均为2,Res-GAT 的注意力头数为3。具体实验设置如表3所示。
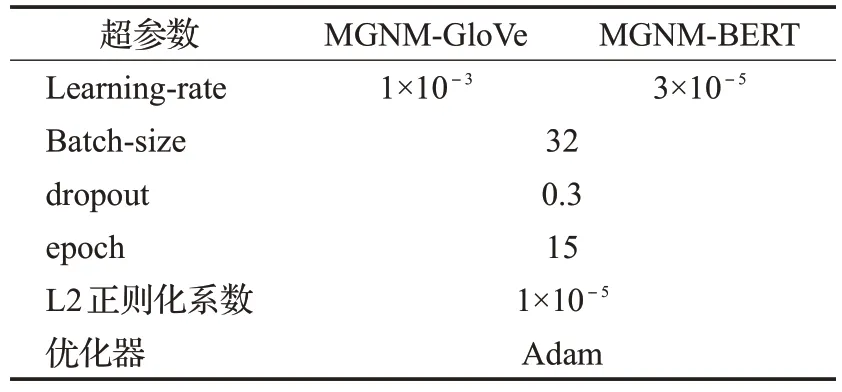
表3 参数设置Table 3 Parameter settings
2.3 评估指标
为了综合评价MGNM,采用准确度(accuracy,Acc)与宏观平均F1值(macro average F1,MF1)作为评估指标。引入混淆矩阵,如表4所示。设各个类别都如表中所示,预测正确的样本数为T,总样本数为N,其中TP+FN+TN+TN=N。
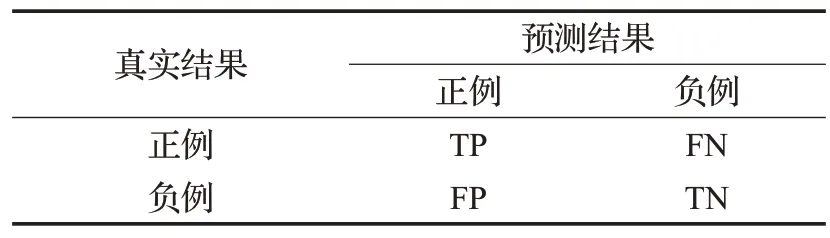
表4 混淆矩阵Table 4 Confusion matrix
根据表4混淆矩阵,准确率计算方法为:
MF1计算方式为:
式中,Precision与Recall为精准率与召回率,m表示类别数。
2.4 对比模型
为了综合评估本文所提出的基于混合图神经网络的方面级情感分类模型MGNM,引入了目前主流的方面级情感分类方法。其中SVM与LSTM是两种传统的方法,MemNet、IAN、AOA 和AEN 是基于注意力机制的方法,应用句法依赖关系的方法有LSTM+SynATT、TD-GAT、ASGCN。此外为验证本文所提出的Res-GAT的改进优于原始GAT 的程度,在该部分实验中创建MGNM-GAT,将Res-GAT 替换为原始GAT。本文采用的对比模型详情如下:
SVM[17]:基于复杂特征工程的传统支持向量机方法。
LSTM[4]:该方法使用LSTM 获取上下文隐藏状态向量用以方面级情感分类。
MemNet[7]:该方法提出使用外部存储器来模拟上下文表示,并使用多跳注意力架构。
IAN[18]:该方法设计了面向方面和上下文的交互建模模型,利用Bi-RNN 和注意机制实现面向方面词和上下文表示的交互学习。
AOA[19]:该方法提出了一个注意力集中注意网络模型(attention-over-attention neural network,AOA),以联合的方式建模方面和句子,明确捕获方面和上下文句子之间的相互作用。
AEN[20]:该方法设计了一种注意力编码网络,用来建模上下文和特定方面之间的关系,嵌入层采用预训练GloVe静态嵌入。
LSTM+SynATT[21]:该方法提出了一种可以更好地捕获方面语义的方法,并提出了一种将句法信息集成到注意机制中的注意模型。
ASGCN[9]:该方法第一次提出通过GCN 和依赖树学习特定方面的特征表示,解决长距离多词依赖问题。
TD-GAT[12]:该方法提出了一种新的基于目标依赖图注意网络(TD-GAT)的方面级情感分类方法,明确地利用了词与词之间的依赖关系。
2.5 实验结果对比与分析
将MGNM 与SVM、LSTM、MemNet、IAN、AOA、AEN-GloVe、LSTM+SynATT、TD-GAT 和ASGCN 模型在Twitter、Lap14、Rest14、Rest15 和Rest16 这五个公开数据集上进行对比实验,表5为详细实验结果表。表中对比模型实验结果均来源于公开发表论文,N/A代表该项实验结果未公开。最好的前两项结果加粗表示。
从表5所示的对比实验结果中可以得出以下结论:本文所提出的MGNM-GloVe在五个数据集上的准确率(Acc)和F1值优于对比模型,其中在Lap14和Rest16数据集上的表现略优于其他比较模型,在Twitter与Rest14数据集上展现出较大的提升,但是在Rest15数据集上没有表现出值得关注的提升。使用预训练BERT 模型获取词向量作为输入的MGNM-BERT在五个数据集上均表现出明显的改进,证明预训练BERT模型能够大幅提升模型的性能。

表5 对比实验结果Table 5 Experimental results of different models 单位:%
与传统机器学习方法进行比较,基于神经网络的方法不依赖繁琐的人工提取特征,更适用于方面级别情感分类。在Twitter、Lap14和Rest14三个数据集上,MGNMGloVe 相较于SVM 准确率分别有11.53 个百分点、5.43个百分点、1.98个百分点的提升。LSTM能够利用上下文时序信息,但是缺乏方面词与语境匹配机制,难以取得较好的性能。
与基于注意力机制的四个模型相比,MNGM 中应用于句法依赖树上的GCN能够明确地捕捉方面词与上下文情感评价词的依赖关系,构建更合理的特征表示。以AEN 为例,AEN 采用基于多头注意力机制的编码器对上下文与方面词分别建模,然后通过以上获得的编码信息之间的交互影响得到最终特征表示。该类模型的效果取决于注意力机制是否准确地建立了方面词与上下文情感评价词之间的关系,但是由于句子复杂性以及注意力机制捕捉远距离依赖关系的固有缺陷,基于注意力机制的模型难以完全捕捉句法依赖关系。对比实验结果中也可以明显地看出,MGNM-GloVe 较四种基于注意力机制的模型的性能有着显著提升。
应用句法依赖关系的模型中,LSTM+SynATT方法与不考虑句法依赖关系的LSTM对比,在Lap14、Rest14和Rest15数据集上的性能表现出了显著的提升,证明句法依赖关系对于方面级情感分类的重要性。由于句法依赖关系表现为树状结构,因此图神经网络被引入。以ASGCN为例,在ASGCN模型中应用了一个句法依赖树上的多层GCN,由于句法依赖树的噪声与不稳定性,相较于其他对比模型性能提升有限。与基于图神经网络的ASGCN 和TD-GAT 相比,MGNM-GloVe 在Twitter、Lap14、Rest14和Rest16数据集上均有明显的提升,尤其是在Twitter 数据集上准确率提升达到2.78 个百分点。其原因是Twitter数据集来源于社交网络,语句的规范性不足,语法不敏感,MGNM中的Res-GAT所提取的词级依赖关系作为句法依赖关系的补充,发挥了重大的作用。
此外,应用预训练BERT模型的MGNM-BERT与所列出的所有对比模型相比,取得了压倒性的实验结果,证明了BERT提升模型性能的优势。
2.6 模型分析
为验证MGNM 中将GCN 与Res-GCN 结合的有效性,在该部分实验中去掉Res-GCN,仅保留GCN 建立MGNM-GCN;去掉GCN,建立MGNM-RGAT;将Res-GAT替换为原始GAT,建立MGNM-GAT模型。以上三种模型使用GloVe输入方式,在Twitter、Lap14和Rest14三个有代表性的数据集上进行实验,实验结果如表6所示。
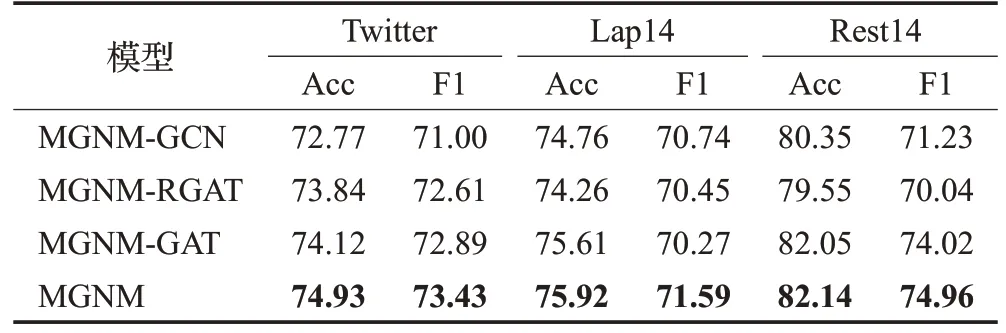
表6 消融实验结果Table 6 Results of ablation experiments 单位:%
从表6 中可以看出,MGNM 在准确率与F1 值两个指标上均高于MGNM-GCN 与MGNM-RGAT,表明MGNM性能与稳定性均优于以上两个消融模型。从实验结果来看MGNM-GCN 在Lap14 与Rest14 数据集上实验结果优于MGNM-RGAT,但是在语法不敏感的Twitter数据集上,MGNM-RGAT不依赖句法,使用注意力机制获取单词之间的关联程度,因此表现优于MGNMGCN。同时表6 所示,MGNM-GAT 的准确率(Acc)和F1 值相较于MGNM 有所下降,证明了Res-GAT 改善GAT过平滑问题的有效性。
3 结束语
为了降低句法依赖树的噪声以及文本语法不规范表达给方面级情感分类带来的不利影响,本文提出了一种基于混合图神经网络的情感分类模型。该模型首先采用了GloVe+Bi-LSTM 与BERT 两种方式获取文本的上下文表示编码,随后加入位置编码突出与方面词距离较近上下文单词的重要性;然后通过一个l-layer GCN获取方面词与上下文单词的依存关系,并通过Res-GAT获取单词之间重要性关联;最后使用特征融合模块将GCN 与Res-GAT 的输出相互施加影响并进行拼接,将拼接后的最终特征表示用于方面级情感分类。在五个数据集上的实验证明了MGNM的有效性。本文所提出的模型缓解了句法依赖树的噪声以及语法不规范性对情感分类任务的影响,下一步将深入研究修剪句法依赖树降低噪声,并利用不同句法依赖关系进行情感分类。
