案件要素异构图的舆情新闻抽取式摘要
2023-02-28余正涛黄于欣
李 刚,余正涛,黄于欣
1.昆明理工大学 信息工程与自动化学院,昆明 650500
2.昆明理工大学 云南省人工智能重点实验室,昆明 650500
随着互联网的快速发展,与案件相关的舆情信息越来越多,从案件相关的舆情新闻中生成简短的摘要对于快速了解案情,掌握和监控舆情的发展态势有着重要的作用。
案件舆情摘要可以看作一个面向特定领域的摘要,目前针对该任务主要有抽取式和生成式两种方法。抽取式摘要指直接从原文中抽取重要的句子作为摘要句,摘要句来自于原文,流畅性好,忠实度高,在实际场景下能达到很好的效果。传统的抽取式摘要方法包括基于主题模型的方法和基于图排序的方法。基于主题模型的方法指通过隐含狄利克雷分布(latent Dirichlet allocation,LDA)模型得到文本主题,采用不同的算法来计算句子和主题的相似度,从而得到摘要句。例如刘娜等[1]将LDA 建立的主题分成重要和非重要两类,并根据词频、位置等统计特征和LDA 特征一起计算句子权重。吴仁守等[2]提出在时间演化的基础上同时考虑主题的演化,最后将标题作为摘要输出。基于图排序的方法是指将句子作为顶点,句子之间的相似度作为边的权重,根据顶点的权重分数来确定关键句。例如Mihalcea等[3]通过TextRank 图排序算法抽取文本中重要性较高的句子形成摘要。另一类抽取式摘要方法主要是基于深度神经网络,把抽取式摘要任务看作句子分类任务,通过给每个句子打标签来确定其是否属于摘要句,其核心在于如何更好地生成句子的表征。Nallapati等[4]首次提出将抽取式摘要看作序列分类问题,构建SummaRuNNer 文本分类模型,用门控循环单元(gated recurrent unit,GRU)作为序列分类器的模块,结合词和句子两层编码特征来判断句子是否是摘要句。Zhang等[5]提出一种把抽取的句子标签作为隐藏变量的抽取式摘要模型,将句子和原始摘要进行对比来对句子进行分类,得到摘要。
以上的研究工作大多集中在开放领域,与通用摘要数据相比,案件相关的舆情新闻通常包含“被害人、犯罪嫌疑人、案发地点”等信息,这些信息是舆情新闻中的重要部分,同时对于摘要生成也具有重要意义。
如图1 所示,描述了“新晃操场埋尸案”(邓世平被杀案)的相关内容,在摘要和正文中都包含“邓世平、杜少平、黄炳松,新晃操场”等案件要素,因此本文认为包含案件要素的句子更易成为摘要句,在句子的建模过程中应该考虑案件要素信息。基于此假设,韩鹏宇等[6]提出一种基于案件要素增强的涉案舆情文本摘要方法,通过对案件要素进行独立编码,然后基于注意力机制融入到词和句子的编码层中,取得了很好的效果。但是该方法将案件要素看作一个序列,基于双向GRU 网络来生成带有上下文信息的案件要素编码。这种编码方式可能会带来不必要的噪声信息,从而影响模型的性能。另外,该方法通过引入基于句子的位置信息、显著性信息及新颖性信息的多特征分类层来建模句子之间的关联关系。而本文认为,建模不同句子之间的关联关系对于摘要抽取有着重要的作用,应该被更充分地利用。

图1 案件舆情文本数据示例Fig.1 Example of case public opinion text data
基于图结构的方法能够更直接地表达不同节点之间的关联关系,近年来在文本分类、阅读理解、文本摘要等任务上取得了很好的效果。如Hu 等[7]针对短文本分类任务,提出一种主题-实体异构神经图,通过构造短文本和主题、实体等信息之间的关联关系来增强短文本的表示,取得了很好的效果。Tu 等[8]针对阅读理解任务,引入包含文档、实体及候选对象的异构图网络,完成跨文档的多跳阅读理解任务。在文本摘要任务方面,Tan等[9]提出一种基于句子注意力机制的摘要方法,在序列到序列的框架中,引入基于句子重要性的图注意力机制对句子进行编码,更好地建模句子之间的关系,提高了摘要的质量。Liu等[10]提出一种基于BERT(bidirectional encoder representations from transformers)[11]预训练语言模型的抽取式摘要方法,利用BERT 生成句子表示,在此基础上构造分类器,实现摘要的生成。Zhong 等[12]提出将抽取式摘要任务转化为语义文本匹配问题的模型,把文档和候选摘要采用BERT映射到同一个语义空间中,通过语义文本匹配方法生成摘要。本文提出基于句子、词和案件要素的异构图神经网络,在句子学习过程中引入案件要素作为额外的词级节点,通过建模词及案件要素等词级节点到句子节点的关联关系来更好地建模句子信息,从而生成更具客观性与概括性的案件舆情摘要。
1 案件要素异构图的摘要方法
本文提出基于案件要素异构图的案件舆情文本摘要方法。模型包括三个主要部分,分别是异构图构建模块(包括句子节点表示、案件要素节点表示和边权重表示)、融合案件要素图注意力模块和句子抽取模块,本节分别对以上部分进行详细介绍。具体模型结构如图2所示。
1.1 异构图构建模块
为了建模句子之间的关联关系,本文采用一个包含不同粒度信息的异构图表示一篇文档,如图2所示。在这个图中,有词、案件要素、句子三种类型的节点。词节点是最基本的节点,代表文档的词级信息。每个句子节点对应文档中一个句子,代表一个句子的全局信息。还定义了两种类型的边来表示图中的两类结构信息:一是如果词出现在这个句子中,就将词节点与句子节点连接;二是将句子节点与所有案件要素节点连接。这两种类型的边用TFIDF计算得到。
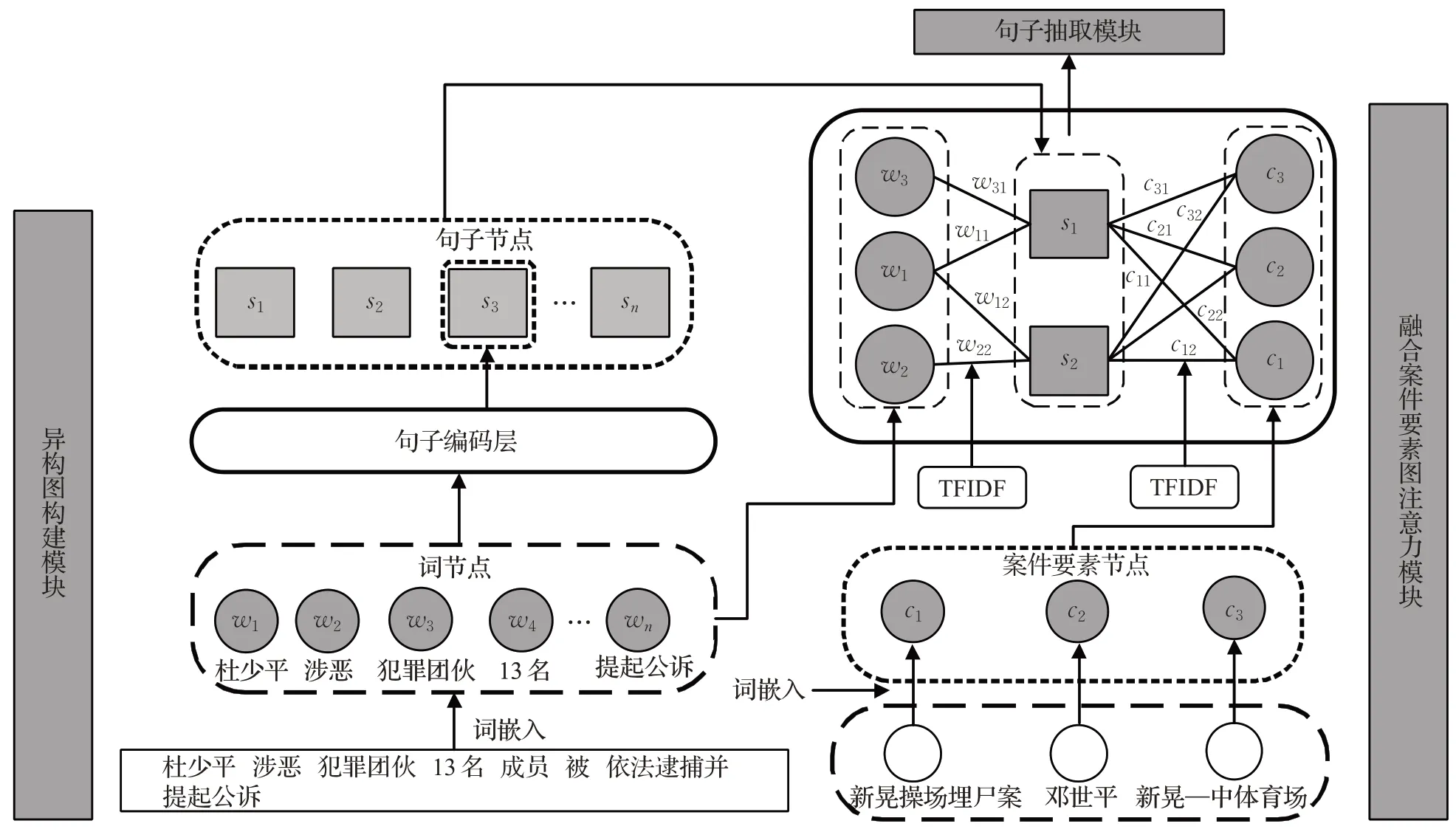
图2 案件要素异构图的案件舆情抽取式摘要模型Fig.2 Case public opinion extractive summary model based on heterogeneous graphs of case elements
图的拓扑结构用邻接矩阵A表示,因为包含两种边结构信息,故分为两种类型的图:词-句子图,案件要素-句子图。因此本文定义两种邻接矩阵:Aw-s由词、句子节点与之间的权重构成;Ac-s由案件要素、句子节点以及权重构成。
1.1.1 句子节点表示
为了更好地获得句子表征,使用卷积神经网络(convolutional neural networks,CNN)[13]得到句子局部词级信息特征,再通过双向长短期记忆网络(bi-directional long short-term memory,BiLSTM)[14]获得句子级全局特征,最后拼接局部和全局特征,得到句子的特征表示。
输入序列D={s1,s2,…,sn}是含有n个句子的一篇文档,si={w1,w2,…,wm}表示第i个句子中含有m个词,m个词的局部特征用ls表示,句子全局特征采用gs表示,最后将ls与gs拼接得到句子特征表示:
式(1)中n表示正文中句子的数目,ds是每个句子输入时的特征维数。
1.1.2 案件要素节点表示
在案件要素编码中,案件要素通过预训练词向量得到每一个要素的特征表示。
式(2)中p表示案件要素的数目,dc是输入案件要素c的特征矩阵维数。
同理,将文档中的句子通过分词后使用预训练词向量得到词的特征表示。
式(3)中m表示句子经过分词后词的数目,dw表示词w输入的特征维数。
1.1.3 边权重表示
本文定义了两种类型的边:一是词、句子边权重值,用ww,s表示,得到词、句子节点权重构成的邻接矩阵Aw,s;二是案件要素、句子边权重值,用cc,s表示,得到案件要素、句子节点权重构成的邻接矩阵Ac,s。这两种边的权重值通过TFIDF计算得到。
经过以上步骤,得到词节点矩阵Xw,案件要素矩阵Xc,句子节点矩阵Xs,边权重cc,s、ww,s。得到异构图G={V,E},V=W∪C∪S,E=ww,s∪cc,s。
1.2 融合案件要素的图注意力模块
为了更新图的邻接矩阵A和节点信息X,本文通过引入图注意力网络(graph attention networks,GAT)[15]聚合要素节点信息来学习每个节点的特征表示,具体如图3所示。

图3 融入案件要素的图注意力模型Fig.3 Graph attention model incorporating case elements
式(4)中Wa、Wq、Wk是可训练参数,zic表示节点i与要素节点c之间的注意力系数。
式(5)是对通过式(4)得到的zic进行归一化操作,Ni是指在邻接矩阵Ac,s中节点i的邻居节点集合,c∈Ni是指要素节点c包含在节点i的所有邻居节点集合Ni中,αic是节点i与c的注意力权重。
图3 中左边是通过单层图注意力计算句子与要素节点权重,右边是通过多头注意力机制(图中K=3)计算句子与要素节点权重,具体过程如下所示:
式(6)得到了句子节点i学习到的特征,是第k组注意力机制计算出的权重系数,指句子节点i融合案件要素节点信息并经过GAT后学到的特征。
在每个图注意力层后,引入一个前馈网络(feed forward networks,FFN)层,对要素与句子双向更新,得到从要素节点更新句子节点的特征表示。
同理在邻接矩阵Aw,s中,得到经过词节点更新后的句子节点表示,然后两者拼接得到最终的句子节点表示,具体表示如下:
1.3 句子抽取模块
式(8)中pi表示句子节点i经过图注意力后被标注为候选摘要的概率,W是训练参数。
对于输入文档样本D={s1,s2,…,sn},对应的句子真实标签y={y1,y2…,yn}(yi∈{0,1}),yi=1 表示第i个句子应该包含在摘要中。最终的句子被分为两种,即摘要句和非摘要句,采用交叉熵作为损失函数:
式(9)中I是训练集中所有句子的集合,yi表示句子i的标签,pi表示对应句子yi=1 时的概率。
2 实验设置
2.1 案件舆情摘要数据集
使用爬虫程序基于百度百科搜集相关案件舆情新闻。首先构造一个案件库,案件库中包含着大量的案件名称,根据案件名称在百度百科中去搜索相关的案件舆情新闻,搜索结果以网页的形式展现。数据集中定义的案件要素是百度百科网站自带的对案件不同侧面的描述,案件要素在正文及摘要中都会出现,这些信息是舆情新闻中的重要部分,同时对于摘要生成也具有重要意义,因此定义的案件要素是具有科学性与准确性的。
进行人工校准、清洗,删除非案件的数据,去除例如“ ”等噪声数据,最后构建出案件舆情摘要数据集,有效数据14 214对。数据集的统计结果如表1所示。
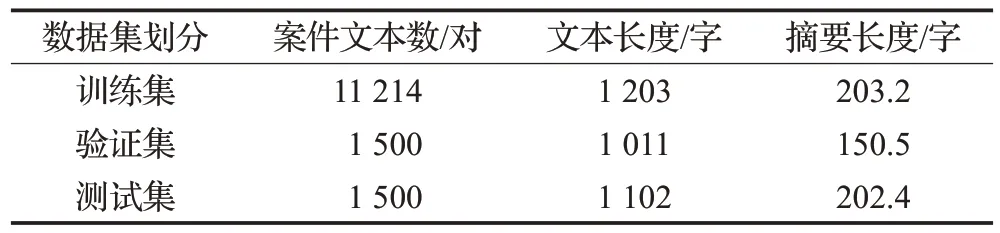
表1 数据集统计Table 1 Data set statistics
2.2 模型训练设置
采用Word2vec 工具,联合搜狗新闻数据集[16]和本文案件舆情数据集预先训练词向量,来表示案件舆情文本中的一个字(词)。每个GAT层头注意力数目为8,隐藏层维度大小dh=64,采用ds=128 和de=50 进行初始化。采用ROUGE(recall-oriented understudy for gisting evaluation)[17]中的RG-1、RG-2 和RG-L 的F 值作为评价指标,训练参数设置如表2所示。

表2 模型训练参数设置Table 2 Model training parameter settings
2.3 基线模型设置
本节选择了5个模型作为基准模型,分别在案件舆情摘要数据集上进行实验,基准模型为LEAD-3、TetxRank、MMR、SummaRuNNer、BERT(BertSum+Classifier,BertSum+Transformer)。
(1)LEAD-3 是一种依靠句子在文章中的位置来抽取摘要的方法,文档的重要信息易出现在文章开头部分,抽取文档前三句作为摘要。
(2)TextRank 是一种基于图的摘要提取算法,将句子视为节点,通过计算图中每个节点的得分,来选择得分最高的几个句子作为摘要。
(3)MMR(maximal marginal relevance)[18]最大边界相关算法,是用于计算查询文本与被搜索文档之间的相似度,再对文档进行排序,最后选取句子的算法。
(4)SummaRuNNer[4]是基于序列分类器的循环神经网络对句子分类训练模型,采用两层双向GRU 和循环神经网络(recurrent neural network,RNN)来对句子进行编码,得到每一个句子是否为摘要句的分类结果,最后得到由分类结果组成的摘要。
(5)基于BERT[11]预训练词向量模型中,“BertSum+Classifier”采用BertSum[10]对句子进行表征,在BERT 输出句子向量后,增加一个线性分类层,使用sigmoid函数提取摘要;“BertSum+Transformer”采用BertSum 对句子进行特征表示,并运用多层Transformer[19]从BertSum 输出的句子向量中提取特征,最后通过sigmoid 分类器输出摘要。
(6)MatchSum[12]是把抽取式摘要任务转化为一个语义文本匹配问题的模型,主要是将文档和候选摘要采用BERT映射到同一个语义空间中,通过语义文本匹配方法生成摘要。
3 实验结果分析
3.1 基线模型分析
第一组实验是本文模型和5 个基线模型在案件舆情摘要数据集上的对比实验,结果如表3所示。
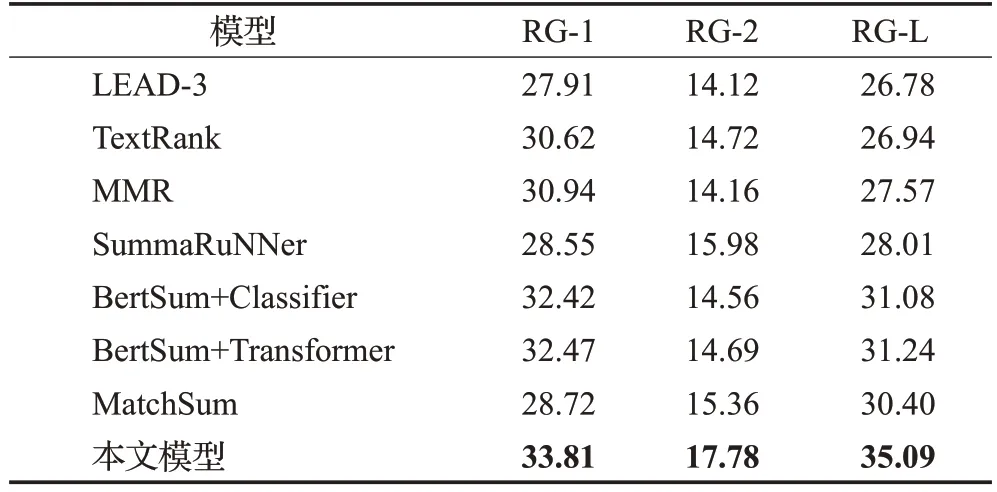
表3 基线模型对比实验Table 3 Baseline models comparison experiment 单位:%
从表3实验结果可以看出:(1)本文模型与LEAD-3模型相比,LEAD-3模型效果较差,这是由于在案件舆情文本中,前几个句子中不全是对案件的描述,而是对文本的发布来源、时间等与案件信息无关的描述,这样的句子不能表达文本主题,因此文档中的前三句话不能作为摘要。(2)本文模型与TextRank 模型相比,RG-1 和RG-2 的值分别提升3.19 个百分点和3.06 个百分点,是因为本文模型融入案件要素抽取的句子与主题语义相关,而TextRank 的方法没有考虑与文本之间的语义关系,生成的摘要不能包含文章的主题信息。(3)本文模型与MMR 模型相比,RG-1 和RG-2 值有2.87 个百分点和3.62个百分点的提升,原因是本文模型引入基于案件要素异构图更直观地表征句子之间的关联关系,本文模型比仅考虑句子相似度的MMR 方法更能全面地捕捉到文档中的句子信息,有利于生成结构清晰、语义完整的摘要。(4)本文模型与SummaRuNNer相比,RG-1和RG-2分别提升了6.26 个百分点和1.8 个百分点,结果表明本文提出将案件要素作为外部知识融入的异构图摘要模型,可以有效地提高模型的摘要性能,抽取出的摘要更能贴近案件舆情文本主题,相关性更高。(5)本文模型与采用Classifier 和Transformer 作为解码器的模型相比,在RG-1和RG-2上分别提升了1.39个百分点、3.22个百分点和1.34个百分点、3.09个百分点,基于BERT的编码方式忽略文本的上下文信息,从而无法找到与主题相关的句子,生成摘要。而本文模型相比于BertSum模型的实验结果,说明融入案件要素构建异构图的方法是有效的,能够全面地表征文档跨句子之间的关联关系,对于抽取出更贴近文档主题的句子有着重要的指导作用。(6)本文模型与MatchSum模型相比,在RG-1和RG-2上分别提升了5.09 个百分点、2.42 个百分点,说明运用图结构表征文档跨句子之间的关联关系,融入案件要素作为辅助信息的方法是有效的,对于抽取出更贴近文档主题的句子有着重要的指导作用。
3.2 不同案件要素抽取方法对比实验分析
第二组实验主要验证采用不同方法获取案件要素对摘要生成的影响,用TFIDF、TextRank 和命名实体识别(named entity recognition,NER)抽取关键词或实体充当案件要素,融入到本文模型中生成摘要,“句子+词+GAT”表示未融入案件要素的异构图方法,基于图注意力实现摘要生成,结果如表4所示。
从表4 可以看出:(1)本文模型与“句子+词+GAT”未融入案件要素模型相比,RG-1和RG-2值提升1.35个百分点、1.68 个百分点,验证了融入案件要素能提高摘要生成的效果。(2)“句子+词+GAT”、NER 和抽取关键词方法相比,使用NER 方法的效果比抽取关键词和未使用要素的方法差,因为NER 识别文本中具有特定意义的人名、地名、机构名三种实体,得到大量的冗余信息,不利于图注意力的学习,导致摘要效果下降。(3)TFIDF、TextRank 抽取关键词与NER 的方法相比,抽取关键词的实验效果在RG-1上分别提高了1.48个百分点和1.39个百分点,证明使用关键词比实体效果更好,使用关键词的方法能减少NER 造成摘要性能下降的不利影响。在文中关键词能更加全面地表达文章主题信息,从而提高摘要性能。(4)本文模型与TFIDF、TextRank抽取关键词方法相比,在RG-1和RG-2上分别提升了0.57个百分点和0.66 个百分点,可以看出差距很小。在实际应用中,当只有正文而没有案件要素时,可以借助关键词辅助摘要的生成。(5)证明本文数据集的案件要素具有科学性,更能全面地体现文档的主题信息,包含的案件信息更完整,能生成更加接近案件主题的摘要。
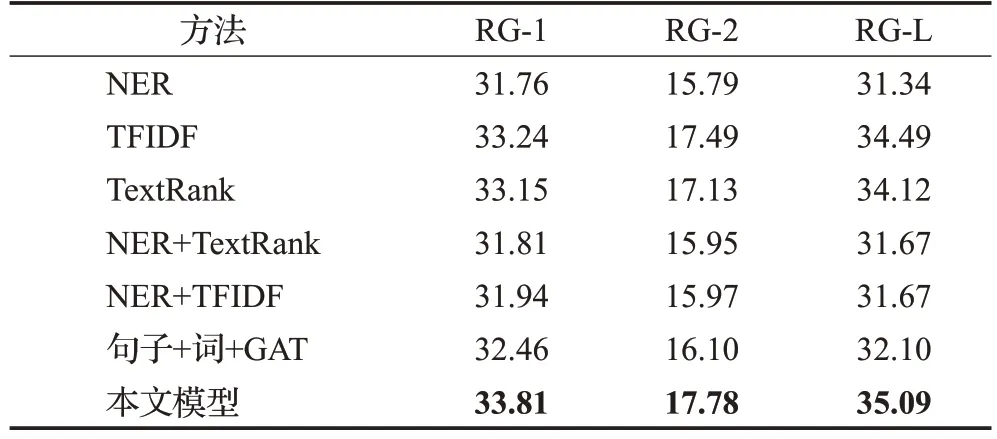
表4 不同案件要素抽取方法对比实验Table 4 Comparative experiment on extraction methods of different case elements 单位:%
3.3 不同数据集对比实验分析
第三组实验为了进一步验证本文模型的泛化能力,分别在韩鹏宇等[6]提出的涉案舆情新闻文本(涉案新闻数据集)、NLPCC2017 数据集上进行实验,其中NLPCC2017 是新闻文本数据集,选取15 000 条数据进行实验。相比本文的数据集,NLPCC2017 中缺失案件要素,根据3.2节中验证,采用TFIDF抽取关键词充当要素,实验结果如表5所示。
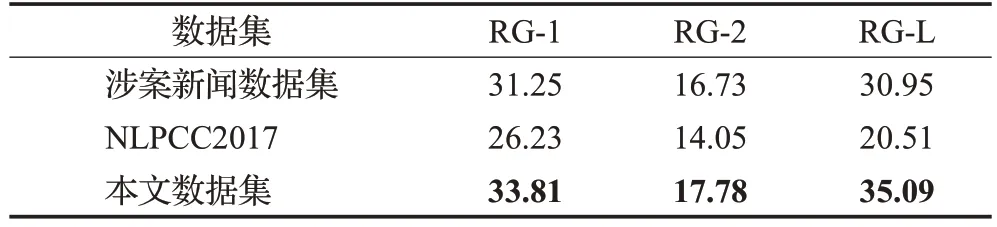
表5 不同数据集对比分析Table 5 Comparative analysis of different data sets 单位:%
从表5 可以看出:(1)本文数据集与涉案新闻数据集的实验结果相比,RG-1 和RG-2 值提升2.56 个百分点、1.05 个百分点,本文模型采用异构图构建句子之间的关联关系,通过聚合邻居节点信息来更新句子表示,得到与主题相关的句子,生成更具客观性与概括性的案件舆情摘要,验证了本文模型采用异构图构建文本句子关系的准确性与有效性;在NLPCC2017 数据集上结果较差,NLPCC2017数据集是一般性的新闻文本,句子间的关联性不强,无法捕捉句子之间的关联关系,生成的摘要效果较差。(2)本实验通过在不同的数据集上进行实验,验证了本文模型的泛化能力,可以看出本文模型可以很好地迁移到其他的数据集上,使用范围广,对于在没有案件要素的情况下,可以采用TFIDF等方法抽取关键词作为案件要素,最后得到摘要。
3.4 不同案件要素融入方法对比分析
第四组实验与文献[6]提出的基于案件要素指导的涉案舆情新闻文本模型进行对比,模型中分别在词、句子编码层融入案件要素注意力机制。GRU表示不引入任何案件要素和关键词信息的注意力机制,GRUcase_Attnall表示使用案件要素和关键词共同作为注意力机制。结果如图4所示。
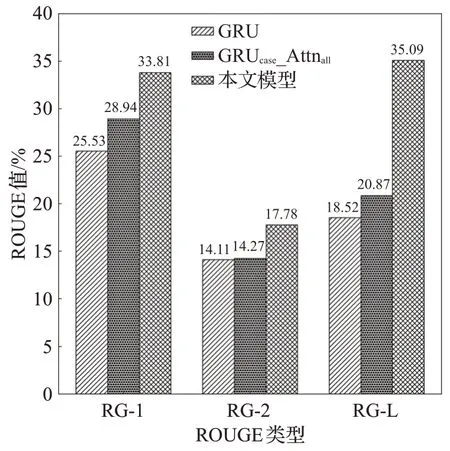
图4 不同案件要素融入方法分析Fig.4 Analysis of integration methods of elements of different cases
从图4可以看出,本文模型与GRU和GRUcase_Attnall模型相比,RG-L 值分别有16.57 个百分点和14.22 个百分点的提升,本文模型优于通过注意力机制将案件要素信息融入词、句子双层编码的方法。(1)文献[6]定义“案件名、案发地、涉案人员、案件描述”四个案件要素,主要是从文本中抽取得到,使用双向GRU编码对句子编码,获得句子和文本的特征,然后通过注意力机制将案件要素信息融入文本的词、句子双层编码中。这种方法把每个句子看作相互独立的关系,侧重关注句子、词和句子、案件要素之间的关系,对于案件长文本数据还应该考虑句子之间的关联关系。(2)在本文模型中,基于案件要素异构图的方法能有效地表示句子间的关联关系,融入案件要素的图注意力机制,能捕捉与案件要素相关的句子,生成内容更加凝练、简洁的摘要。(3)本文模型引入异构图能包含更多丰富的节点信息和语义信息,将多种类型的节点与边信息整合,突出与每个句子节点相关联的异构属性、异构内容,包含的节点类型更广,语义更丰富。
3.5 实例分析
为进一步验证本文模型的有效性,列举了不同方法获取案件要素实现抽取式摘要的结果。首先,选取“新晃操场埋尸案”案件的相关文本,针对该案件,采用两种抽取关键词方法得到案件要素,对输出摘要进行实例分析,具体如图5所示。

图5 不同方法抽取关键词生成摘要对比示例Fig.5 Comparative example of different methods of extracting keywords to generate abstracts
根据图5可以看出,“新晃操场埋尸案”中案件舆情文本主要描述嫌疑人杜少平及其同伙罗光忠对被害人邓世平实施犯罪,以及对该案件的起因、经过和案发后所牵连人员的处置等多个不同层次信息的描述:(1)基于TFIDF 的方法专注于描述嫌疑人杜少平审判结果的细节,基于TextRank的方法专注杜少平及其同伙罗光忠被依法逮捕并进行审判这一细节信息,都没有关注到被害人邓世平相关的具体内容,偏离原文主旨。(2)本文构建案件舆情摘要数据集中的案件要素包含案件名、案件时间、地点等信息,这些关键信息在摘要和正文文本中都包含,能对案件进行详尽描述,这也验证了本文构建数据集时,定义案件要素的科学性与准确性。在构图的过程中,把案件要素融入到异构图注意力过程中,尽可能地关注到与案件要素相关的句子。(3)TFIDF和TextRank两种方法获得的摘要都没有体现原文的主题信息。相反,本文定义的案件要素能较全面地概括案件的细节信息,融入到图注意力机制中并筛选出与主题关联性强的句子,能关注不同层次的不同细节信息,多维度把握文章的主题,扩大摘要信息的覆盖面,生成质量更高的文本摘要,从而验证了案件要素对案件舆情文本摘要生成具有重要的指导作用。
4 结束语
本文针对案件舆情摘要任务,提出一种基于异构图注意力机制融入案件要素的抽取式摘要模型。将句子、词及案件要素构建为异构图,并基于异构图注意力网络进行编码。实验结果表明,针对案件舆情这一特定领域的摘要任务,案件要素的融入能够提高句子的表示效果,生成更高质量的摘要。另外也验证了利用异构图来建模词、案件要素及句子之间的关系,相比直接使用注意力机制来融入案件要素效果更好。
在下一步的研究中,拟继续探索在同一案件下的多文档舆情新闻摘要任务中,如何利用案件要素来建模跨句子、跨文档的关联关系以及如何更好地表征这些关联关系,从而提升案件舆情多文档摘要任务的性能。
