标题与正文语义融合的新闻向量表示方法
2023-02-28连晓颖薛源海沈华伟
连晓颖,薛源海,刘 悦,沈华伟
1.中国科学院 计算技术研究所 数据智能系统研究中心,北京 100190
2.中国科学院大学,北京 101408
随着信息过载问题的日益加剧[1],Google News、MSN News、Yahoo!、今日头条等在线新闻资讯平台均通过推荐系统挖掘用户兴趣、扩大新闻媒体的影响力并为企业带来盈利。为应对海量数据和实时性的挑战,新闻推荐系统采用向量召回的方式快速筛选出新闻候选集,使得如何构建高质量的新闻、用户向量表示成为推荐系统的核心问题[2]。
新闻的标题和正文里都蕴含着丰富的文本语义信息,这也是新闻推荐系统有别于其他音乐、时装等推荐系统的主要特征。新闻标题往往简明扼要,而新闻正文则蕴含着更为丰富的语义信息,能够进一步补充标题的上下文语境。由于新闻正文在词数上远远大于标题,拥有文本长度长和语义信息复杂的特点,直接对正文全篇编码将耗时耗力。事实上,用户总是先根据新闻标题判断是否浏览正文,在看正文时也会希望看到和标题相关的补充信息。
本文将以新闻标题为查询,从新闻正文的头、尾、中间等各个部分获取新闻标题的补充信息,致力于在仅使用部分正文编码的情况下,生成语义信息更丰富、质量更优的新闻向量表示。
1 相关工作
传统的新闻推荐方法采用协同过滤和内容过滤的方式来生成新闻和用户的表示[3]。协同过滤方法以评分矩阵作为新闻和用户的特征,是一种基于ID 特征的表示方法,存在着严重的冷启动问题[4]。内容过滤方法则依赖于传统自然语言处理模型,如词频统计模型[2]、贝叶斯模型[5]、主题模型[6]等,容易忽视词序和上下文语义,对新闻文本语义的理解不够充分。
随着深度学习技术的发展,生成高质量的新闻、用户向量表示逐渐成为新闻推荐系统的热点研究方向。深度特征融合模型方法将人工构造的各类特征同时输入到模型中,采用浅层网络与深层网络混合的方式提取出这些特征的向量表示,主要代表模型有DFM(deep fusion model)[7]、Wide&Deep[8]、DeepFM[9]。由于依赖手工构造的特征,这类方法在应用时不仅需要大量的领域知识,还忽视了新闻的文本语义信息。
因为新闻的标题和正文里都蕴含着丰富的文本语义信息,所以充分理解这些文本语义变得格外重要。双塔模型方法向新闻塔中输入新闻标题得到新闻的向量表示,向用户塔中输入用户历史浏览的新闻标题得到用户的向量表示,最后把两者向量做内积计算出用户对新闻的评分。Yahoo! Japan[2]率先将双塔模型应用在了新闻推荐领域,而后Wu 等人提出的NRMS(neural news recommendation with multi-head self-attention)模型[1]用多头注意力机制[10]改进了新闻编码器,使得双塔模型结构逐渐成为新闻推荐领域的主流框架。后续的个性化注意力模型如DAN(deep attention neural network)[11]、NPA(neural news recommendation with personalized attention)[12]等也是在这一主流框架的基础上增添了交叉特征,加强双塔间的依赖性,但这些模型都仅注重挖掘新闻标题中蕴含的语义信息。同样是在双塔模型框架的基础上,NAML模型[13]采用截取正文开头的方式编码新闻正文,生成了更高质量的新闻向量表示,验证了新闻正文语义信息的重要性。但这类方法的主要不足在于忽视了正文的后文语义,容易对前文过拟合,未能充分利用新闻正文中蕴含的语义信息。
针对新闻正文语义利用不充分的问题,本文以新闻标题为查询,从新闻正文的多个区域中聚合标题的补充信息,生成语义信息更丰富的新闻向量表示。
2 标题与正文语义融合的新闻向量表示方法
本文提出了标题与正文语义融合的新闻向量表示方法(news recommendation with title attention,NRTA),先将新闻正文分词后,划分为P个互不重叠、长度为L个词的区域,然后计算新闻正文各区域与新闻标题的相关性,以此加权聚合新闻正文各区域的语义,使新闻正文的头、尾、中间等各个部分均有机会成为新闻标题的补充信息。
本文接下来将分别从NRTA 模型结构、新闻编码器、用户编码器以及模型训练方法四方面进行详细阐述。
2.1 NRTA模型结构
NRTA 的模型结构如图1 所示,沿用了NAML 模型的双塔结构,由新闻塔和用户塔组成,主要改动在于新闻塔的正文编码器和文本编码器。
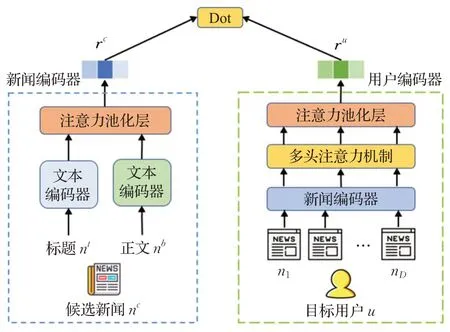
图1 NRTA模型结构示意图Fig.1 Structure of NRTA model
正文编码器以新闻标题为查询,计算正文各区域应分配的注意力权重,加权聚合正文各区域的向量表示从而获得新闻正文的向量表示。文本编码器则是正文编码器的基础模块,不仅用于新闻标题编码,还用于新闻正文各区域的编码。本文为建模跨区域的词相关性,在Transformer文本编码器的基础上设计了记忆单元,以更加准确地理解正文各区域的语义信息。
用注意力池化层加权聚合新闻标题和正文的向量表示,即可得到候选新闻的最终向量表示rc;通过历史浏览新闻的向量表示获得目标用户的向量表示ru;在NRTA 模型的输出端依旧是将目标用户的向量表示ru和候选新闻的向量表示rc做内积,得到目标用户对候选新闻的评分,如式(1)所示。
2.2 新闻编码器
2.2.1 正文编码器
本文采用基于标题的注意力池化层聚合出新闻正文的向量表示rb,在进行正文编码前,需要先用文本编码器获取新闻标题的向量表示rt。在聚合每个区域的向量表示时,各区域的注意力权重依赖于该区域向量表示与新闻标题向量表示的相关性。正文编码器的模型结构如图2所示。
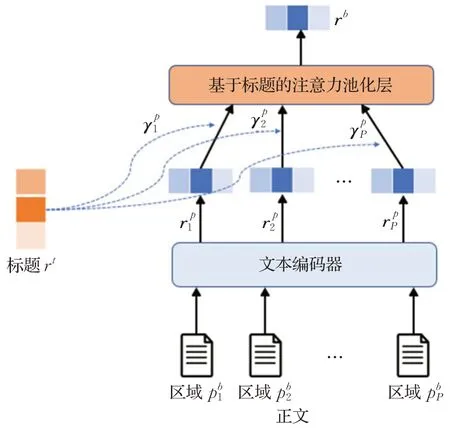
图2 NRTA模型正文编码器结构示意图Fig.2 Structure of body encoder in NRTA model
2.2.2 文本编码器
文本编码器不仅参与了新闻标题的编码过程,还参与了新闻正文每一个区域文本的编码过程,是整个NRTA 模型的基础模块。为了探究不同神经网络层对NRTA模型表现的影响,本文分别采用Transformer多头注意力机制[10]和CNN卷积层[14]设计了两种文本编码器,模型结构如图3所示。
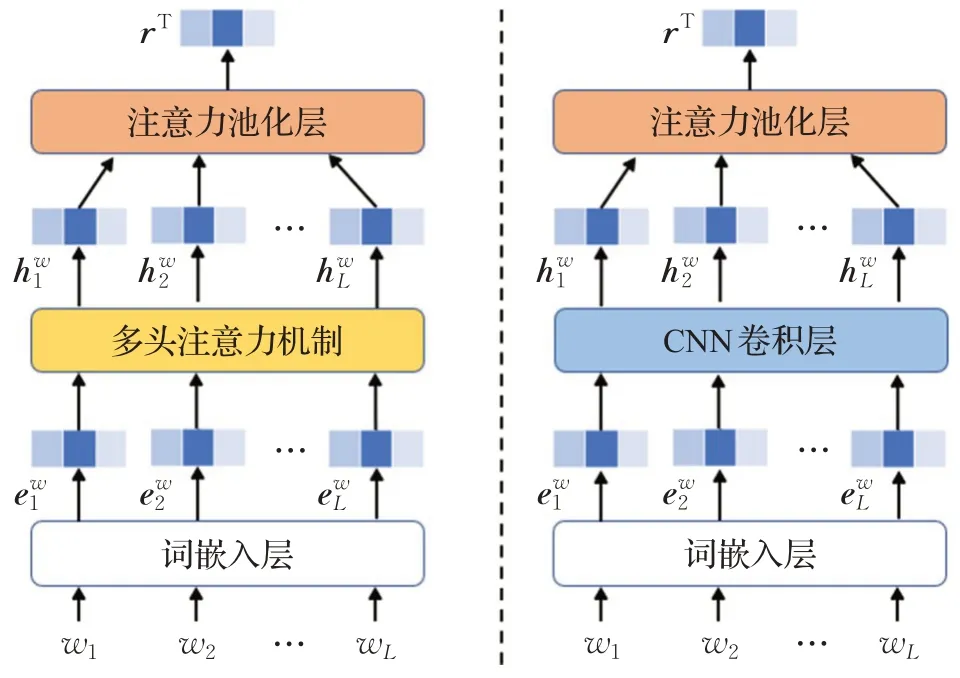
图3 文本编码器Fig.3 Structure of text encoder
图3中,左侧是采用了Transformer多头注意力机制的文本编码器,简称为Transformer文本编码器;右侧是采用了CNN卷积层的文本编码器,简称为CNN文本编码器。这两种文本编码器的编码过程完全一致,首先输入文本词序列[w1,w2,…,wL];通过词嵌入层获得词向量序列;再由Transformer 的多头注意力机制或者CNN卷积层将词向量重新映射成隐层表示序列;最后用注意力池化层加权求和每个词的隐层向量表示,获得文本最终的向量表示rT。注意力池化层的公式如式(3)所示。
(1)Transformer文本编码器
为了能更充分地理解新闻正文里每一个区域蕴含的语义信息,在Transformer文本编码器的设计上,本文参考TransformerXL 模型[15]的思想,设计了拥有记忆单元的文本编码器建模跨区域的词相关性,使得文本编码器不仅适用于新闻标题编码,还能适用于新闻正文各区域编码。与原先NRMS模型中使用的Transformer多头注意力机制相比,主要区别如图4所示。
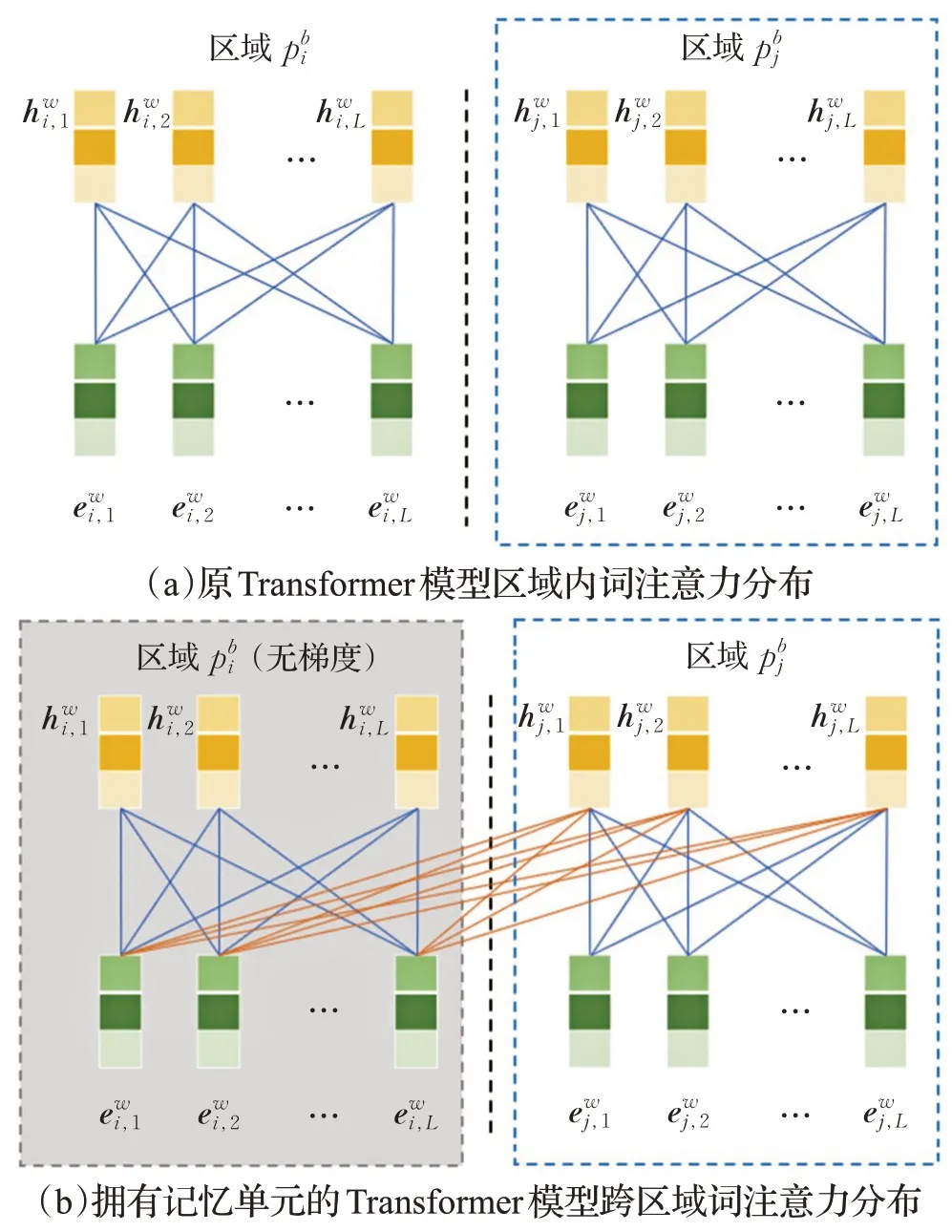
图4 Transformer文本编码器跨区域词相关性示意图Fig.4 Diagram of cross-region word correlation of Transformer text encoder
图4(a)展示的是原先的Transformer模型在多区域文本编码时的词注意力分布情况。图中共有两个待编码的文本区域,在对这两个区域编码时,多头注意力机制仅专注于建模各区域内部的词相关性,没有考虑到跨区域的词相关性。事实上,在对正文多区域编码的情况下,每段文本区域的语义与其前文关系密不可分,若能考虑到区域间的词相关性则能更全面地理解该区域文本蕴含的语义信息。
图4(b)展示的是拥有记忆单元的Transformer模型在多区域文本编码时的词注意力分布情况。在对区域内的文本编码时,会将上一个区域的词向量序列同时输入到Transformer多头注意力机制中,从而使得区域不仅能关注到区域内的词相关性,还能建模与上一区域内的词的相关性,具体计算公式如式(4)所示。
上述是根据图中描绘的情况介绍的拥有一个记忆单元的Transformer 模型,因为只输入了待编码区域的前一个区域的词向量序列。可以很容易地把上述方法推广到拥有C个记忆单元的Transformer 模型的情况,只需要把前C个区域的词向量序列和待编码区域词向量序列在序列长度的维度上拼接起来,作为Transformer多头注意力机制的Key和Value即可。这样就能在内存允许的条件下,尽可能多地建模当前区域内的词与前文区域内的词的相关性,以此增强模型对当前区域文本的理解能力,生成语义信息更为准确的文本向量表示。
Transformer 文本编码器在编码新闻标题时可以看作记忆单元C=0 的情况;编码新闻正文的每个区域时则依据参数C和前文区域数量自适应调整。
(2)CNN文本编码器
CNN文本编码器和NAML模型的标题编码器结构相同,CNN卷积层的计算公式如式(5)所示。其中Fw和bw是CNN 卷积层的参数,则是由位置i-O到i+O的词向量序列拼接而成,O是CNN 卷积核的大小。CNN卷积层采用Same-Padding的方式保证输入序列长度和输出序列长度一致。
2.2.3 注意力池化层
由文本编码器和正文编码器得到新闻标题的向量表示rt以及新闻正文的向量表示rb后,通过新闻编码器的最后一层注意力池化层加权聚合标题和正文的向量表示,得到新闻的最终向量表示rc,具体计算公式如式(6)所示。
2.3 用户编码器
用户编码器和NRMS模型保持一致。首先,输入目标用户的历史浏览新闻序列[n1,n2,…,nD],通过新闻编码器获得每条历史浏览新闻的向量表示序列,由多头注意力机制层将历史浏览新闻的隐层表示重新映射为序列,计算公式如式(7)所示。最后由注意力池化层加权求和历史浏览新闻的向量表示,获得最终的用户向量表示ru,计算公式如式(8)所示。
2.4 模型训练
NRTA模型在训练时会同时输入一个目标用户、一条该用户点击过的新闻y+以及一条该用户未点击过的新闻y-。在输出时将用户向量表示和两条候选新闻向量表示做内积,得到用户对每条候选新闻的评分pi。最后采用softmax函数归一化用户对两条候选新闻的评分,计算公式如式(9)所示。
通过上述转换,用户点击率预测问题转变成了二分类问题,因此NRTA模型在训练时可以采用分类问题中常用的负对数似然损失函数,具体计算公式如式(10)所示。
3 实验结果与分析
3.1 数据集
本文在MIND-Small[16]和Adressa-10 weeks[17]两个来源于线上应用的开源新闻推荐数据集上进行实验。其中MIND-Small是2020年微软发布的新闻数据集,数据主要来源于MSN News,提供了划分好的训练集和测试集,NRMS、NAML 等论文均基于MSN News 数据集开展实验。Adressa-10 weeks是挪威科技大学(NTNU)和Adressavisen 合作发布的新闻推荐数据集,包含三个月的日志数据,需要自行构建训练集和测试集。两数据集的统计信息见表1。

表1 MIND和Adressa数据集统计信息Table 1 Statistics of MIND and Adressa datasets
本文根据Adressa-10 weeks 数据集里的用户日志构建了训练集、验证集和测试集。首先将Adressa-10 weeks 数据集里的event 按session 起止标记串联起来获得session,取前50 天的点击日志作为训练集用户的浏览历史;前60 天的点击日志作为验证集和测试集用户的浏览历史;50~60天的点击日志作为训练集;60~70天的点击日志按照2∶8 的比例随机划分为验证集和测试集。由于Adressa-10 week数据集提供的是用户点击日志,只有正样本,本文从每个用户用不到的那部分浏览历史中采样了等量的负样本。
3.2 评价指标
本文采用了搜索推荐场景下常用的排序、分类评价指标,分别是AUC、MRR、nDCG和F1[2]。在MIND数据集上采用AUC、MRR、nDCG@5、nDCG@10 四项指标;在Adressa数据集上采用AUC、F1两项指标。
3.3 基线方法
本文采用基于标题语义信息的NRMS 模型和基于正文语义信息的NAML模型两种方法作为基准。
NRMS[1]采用多头注意力机制生成新闻和用户的向量表示,注重于挖掘新闻中词与词之间的相关性以及用户历史浏览新闻间的相关性。仅使用新闻标题信息,是新闻推荐领域的重要基线模型。
NAML[3]基于CNN 生成新闻标题和新闻正文的向量表示,在NRMS 模型的基础上加入新闻正文信息,采用注意力机制聚合新闻标题和新闻正文的向量表示。在对新闻正文编码时仅截取正文的开头一段,也是新闻推荐领域中重要的基线模型。
3.4 实验设置
本文基于Pytorch 实现上述所有模型,在Tesla k80 GPU(显存11 GB)上进行模型的训练和测试。为保证实验环境的一致性,表2给出了在MIND和Adressa数据集上各模型实验时的通用参数设置。
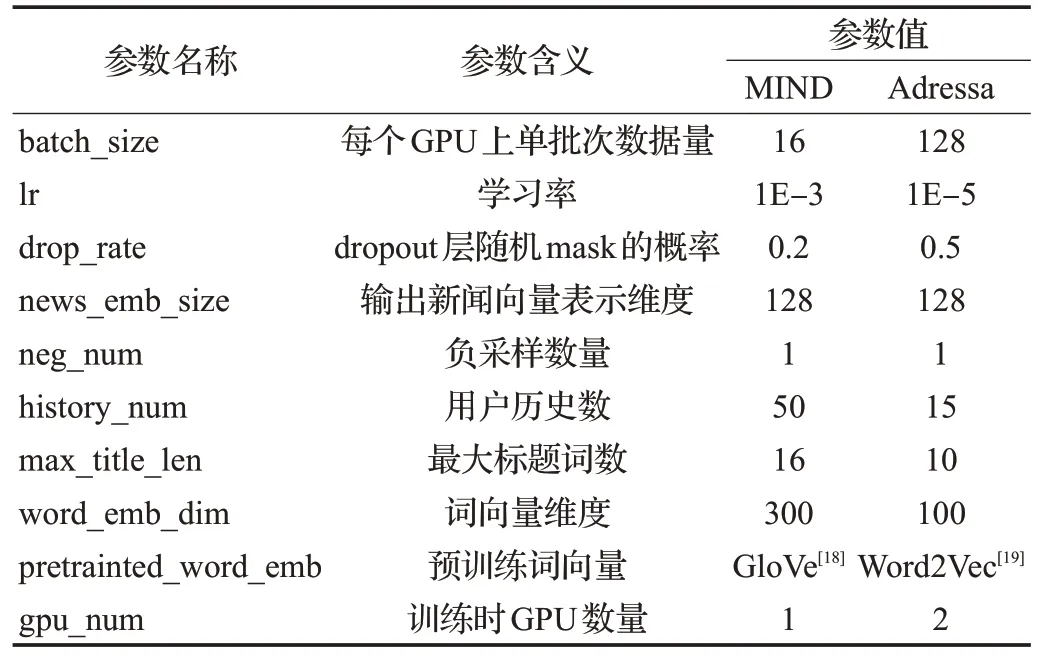
表2 通用参数设置Table 2 General parameter settings
3.5 实验结果与分析
3.5.1 基线对比实验
本文分别在MIND 和Adressa 两个数据集上,进行了NRMS、NAML、NRTA 三个模型的多组实验。由于NAML 原文用CNN 作为文本编码器,而NRMS 原文用Transformer 作为文本编码器,因此本文分别采用Transformer 和CNN 两种文本编码器对比NRTA 模型以及基线方法NAML 模型,选出各模型在不同指标下的几组最优结果进行对比。设NAML模型正文开头截取长度为W个词,NRTA 模型选取区域个数为P=η+μ+τ,每个区域长度为L个词,其中从正文开头连续选取η个区域,从正文中部连续选取μ个区域,从正文末尾连续选取τ个区域,记忆单元的数量为C。表中各模型在各指标上的最高分已用粗体标出,具体结果如表3和表4所示。
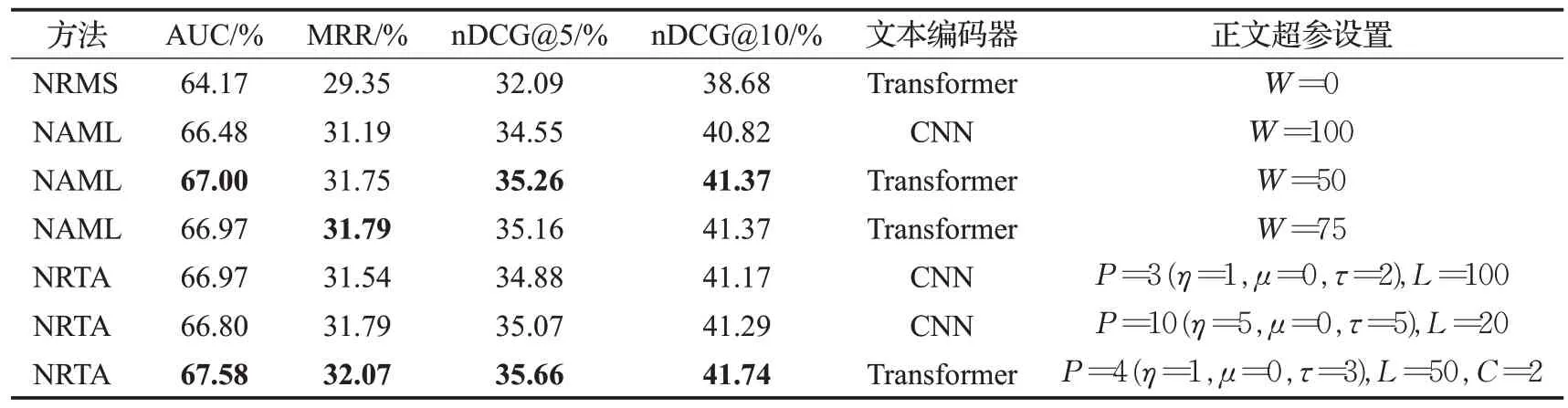
表3 MIND数据集上与基线模型对比的实验结果Table 3 Experimental results compared with baseline model on MIND dataset

表4 Adressa数据集上与基线模型对比的实验结果Table 4 Experimental results compared with baseline model on Adressa dataset
在MIND数据集上,与用Transformer文本编码器的NAML模型各项指标的最优值相比,NRTA模型的AUC指标高出0.86%,MRR 指标高出0.87%,nDCG@5 指标高出1.11%,nDCG@10 指标高出0.89%。若与用CNN文本编码器的NAML 模型相比,NRTA 模型的AUC 指标高出1.65%,MRR 指标高出2.82%,nDCG@5 指标高出3.20%,nDCG@10 指标高出2.25%。NRTA 模型与NAML 模型在MIND 数据集上的各指标最优值对比如图5所示。
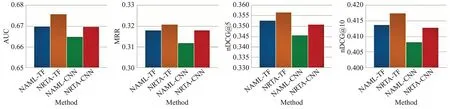
图5 NRTA与NAML在MIND数据集上的各指标最优值对比Fig.5 Comparison of optimal values of various indicators between NRTA and NAML on MIND dataset
在Adressa 数据集上,与用Transformer 文本编码器的NAML 模型各项指标的最优值对比,NRTA 模型的AUC指标高出3.95%,F1指标高出3.75%。若与用CNN文本编码器的NAML模型相比,NRTA模型的AUC指标高出2.18%,F1指标高出2.12%。NRTA模型与NAML模型在Adressa数据集上的各指标最优值对比如图6所示。
从图5 和图6 可以看出,本文提出的NRTA 模型在MIND和Adressa两个数据集的各个指标上都取得了最优效果。无论NRTA 模型采用CNN 文本编码器还是Transformer 文本编码器,其中总有一个能达到最优效果,而另一个文本编码器在表现上则与NAML 模型的最优效果近似持平甚至略高于NAML模型的最优效果。

图6 NRTA与NAML在Adressa数据集上的各指标最优值对比Fig.6 Comparison of optimal values of various indicators between NRTA and NAML on Adressa dataset
3.5.2 区域数量选取实验
为了探究NRTA 模型在正文区域选取上的相关问题,本文做了区域数量选取的相关实验。在做实验时采用的是各数据集上NRTA模型最优表现的参数配置,固定区域长度L=50。
图7 和图8 分别展示了MIND 数据集和Adressa 数据集上NRTA 模型各指标随着区域数量变化的情况。图中横轴是不同的区域数量,纵轴是各指标上模型得分。红色虚线标出的是用CNN文本编码器的NAML模型最优值,绿色虚线标出的是用Transformer 文本编码器的NAML模型最优值。橙色折线NRTA-H代表P个区域全部从正文开头连续选取,即η=P,μ=0,τ=0 时NRTA 模型的表现;蓝色折线NRTA-HT 代表从正文开头选取η个区域,余下P-η个区域全部从正文末尾选取时NRTA 模型的表现;紫色折线NRTA-HM 代表从正文开头选取η个区域,余下P-η个区域全部从正文中部选取时NRTA模型的表现。其中,从正文开头选取的区域数量0<η≤2 约有50到100个词,这是参照NAML模型最佳表现时开头选取词数设定的,在此基础上将余下的P-η个区域从正文的中部或结尾选取,更能体现正文后文语义的价值。
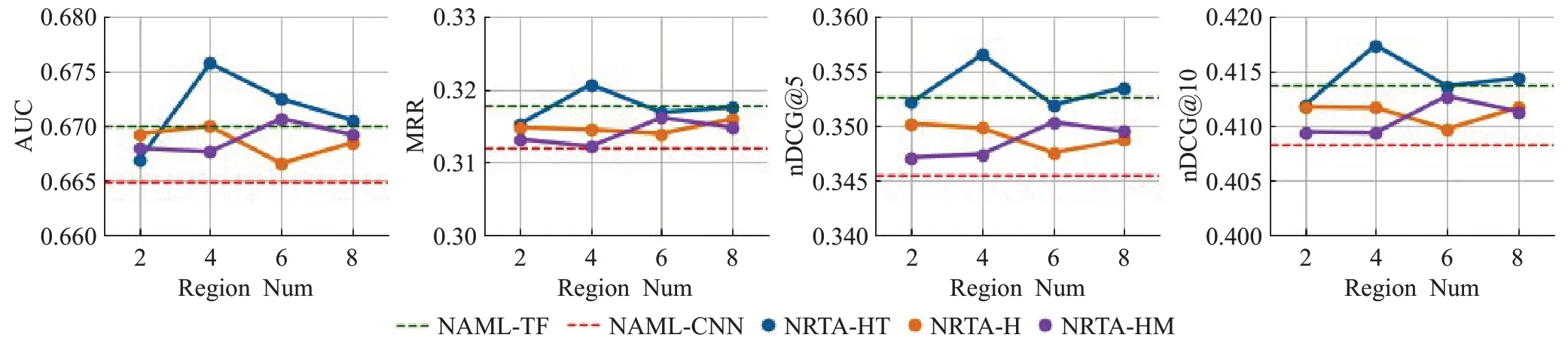
图7 MIND数据集上NRTA各指标随区域数量变化的情况Fig.7 Change of various indicators of NRTA with different numbers of regions on MIND dataset

图8 Adressa数据集上NRTA各指标随区域数量变化的情况Fig.8 Change of various indicators of NRTA with different numbers of regions on Adressa dataset
从折线图可以看出,在MIND 数据集上,NRTA-HT总能在各项指标上取得最优效果;NRTA-H和NRTA-HM的效果则有明显下降。在Adressa 数据集上,NRTA-H和NRTA-HM 总能在各项指标上取得最优效果,NRTAHT也能明显优于基线方法。
本文对上述现象分析如下:首先,在两个数据集上,从正文的开头和结尾部分选取区域都能优于基线模型方法,这进一步印证了后文语义信息的重要性。其次,在MIND 数据集上选取正文的开头和结尾要优于选取正文的中间部分,而在Adressa 数据集上选取正文的开头和中间要优于选取正文的结尾部分,这一现象很可能是由数据集本身造成的。其中,MIND数据集里的正负样本来源于真实的会话场景,正负样本新闻的相似度较高,需要更具总结性的语义特征才能增强正负样本的区分性。直观上理解,一篇新闻正文的开头和结尾多是对新闻内容进行概括总结的表述,而正文的中间部分则多是叙述事情的经过,因此在MIND数据集上选取更具总结性的正文开头和结尾部分效果要更好。相比之下,Adressa 数据集里的负样本来源于随机采样,正负样本新闻的相似度较低,从而连贯的语义表述也能具有很强的区分性,因此在Adressa 数据集上选取正文的开头和中间部分效果也很好。最后,随着正文区域数量变化,在两个数据集的各指标上NRTA 模型总能取得最优效果,说明NRTA 模型对区域数量这一超参的变化足够稳定。
总体来说,选取新闻正文的开头和结尾部分在两个数据集上都能使NRTA 模型取得不错的效果,且MIND数据集里的正负样本也要更加贴近真实的新闻推荐场景,因此在应用NRTA模型时推荐选取区域覆盖在正文开头的前50~100词,以及正文结尾的100~200词。
3.5.3 区域长度实验
在确定了如何选取区域数量与区域位置之后,区域长度又会对NRTA 模型的表现带来怎样的影响呢?对此,本文对比了不同区域长度下NRTA 模型的表现,在对比时依旧采用NRTA 模型的最优参数配置和最优区域选取方法。
图9和图10分别展示了MIND数据集和Adressa数据集上NRTA 模型各指标随着区域长度变化的情况。图中横轴是不同的区域长度,纵轴是各指标上模型得分。红色虚线标出的是用CNN文本编码器的NAML模型最优值,绿色虚线标出的是用Transformer 文本编码器的NAML模型最优值。
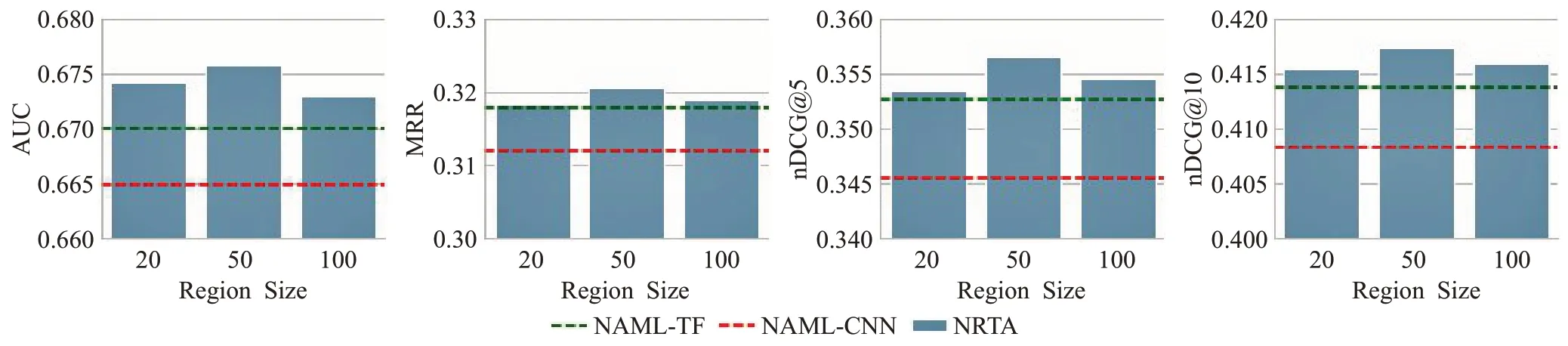
图9 MIND数据集上NRTA各指标随区域长度变化的情况Fig.9 Change of various indicators of NRTA with different region sizes on MIND dataset

图10 Adressa数据集上NRTA各指标随区域长度变化的情况Fig.10 Change of various indicators of NRTA with different region sizes on Adressa dataset
从柱状图可以看出,当NRTA模型采用最优的区域选取方法时,在两个数据集的各个指标上区域长度无论是20 词、50 词还是100 词均能明显优于基线方法。其中,区域长度为50 词时在两个数据集上的效果都是最优的,因此在应用NRTA模型时推荐正文区域长度在50词左右。
4 总结与展望
本文针对新闻正文文本长度大、语义信息复杂的问题提出了NRTA模型,从新闻正文的多个区域里挖掘新闻标题的补充信息,关注正文前文语义的同时也关注后文语义,进一步丰富了新闻向量表示。在MIND和Adressa两个新闻推荐领域的开源数据集上开展实验,通过基线对比实验验证了本文方法的有效性;通过区域数量选取实验和区域长度实验给出了NRTA模型的应用建议,充分检验了本文方法的实用性。
随着研究工作的深入,仍有一些问题有待解决。新闻正文的多个区域之间在语义上是互相关联的,要充分理解一个区域的语义信息只看前文是远远不够的,如何更好地建模正文多区域之间的相关性,更准确地理解每个区域的语义信息,对充分理解新闻语义非常重要,将针对这一问题做进一步研究。
