遗忘曲线和BTM词频双层加权微博用户画像
2023-02-27马文莉杨利君
吴 迪,马文莉,杨利君
(河北工程大学 信息与电气工程学院,河北 邯郸 056038)
0 引 言
目前,用户画像[1-5]主要分为3类:基于用户行为[6]、用户偏好[7]和主题的用户画像[8]。其中,基于主题的用户画像因能够充分利用微博用户各种文本信息,以建立全面精准的用户画像而被广泛应用。Ding等[9]提出了基于动态文本建模的LDA-RCC模型,用于分析用户兴趣并建立用户画像。李琴等[10]提出了变分自编码的有监督主题情感联合分析模型,刻画用户群体游客画像。上述研究只利用主题模型提取用户主题词,未考虑用户兴趣的变化。
近年来,研究者们开始考虑时间因素对微博用户兴趣的影响。吴树芳等[11]提出了利用层次分析法和生命周期理论微博用户画像构建方法。冯勇等[12]提出了利用遗忘曲线拟合衰减因子的TIF-LDA主题模型。安璐等[13]利用生命周期理论,从用户和文本两个角度,提取微博用户特征。王胜等[14]充分考虑主题模型建模过程词频权重对主题词的影响,提出了基于词频特征的SL-LDA主题模型,提高中频词的影响力。
针对微博短文本具有时效性和建模中频词缺失的问题,从时间和词频两个角度出发,提出了遗忘曲线和BTM词频双层加权微博用户画像TW-BTM方法。利用遗忘曲线拟合时间函数,以计算词条的时间权重;采用词频特征改进BTM建模过程,以提高中频词的词频权重。
1 BTM主题模型
针对传统主题模型LDA对短文本建模的不足,短文本建模BTM主题模型应运而生。利用整个语料库的单词共现模式提高主题学习能力,解决了短文本特征稀疏的问题。具体来说,是将整个语料库看成所有主题的混合,其中每个词对都是独立于一个主题的。一个词对属于某一主题的概率称为词概率分布,是由词对中每个词属于该主题的概率相乘得到。BTM图模型如图1所示,超参数α和β是狄利克雷先验参数,具体描述如下:①对语料库采样一个主题分布Θ~Dir(α); ②对每个主题Z∈[1,k], 确定主题Z下的词分布Φ~Dir(β); ③对每个双词b=(wi,wj)∈B, 采样一个主题Z~Mult(Θ), 根据主题Z, 每个词对都从独立主题中采样,即wi,wj~Mult(Φ)。
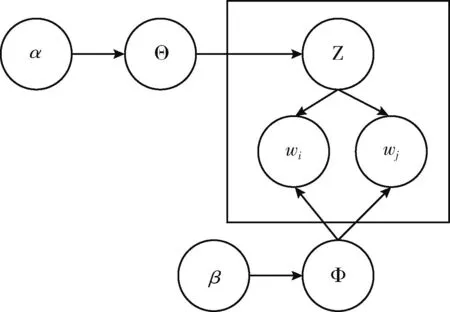
图1 BTM图模型
2 遗忘曲线和BTM词频双层加权微博用户画像方法
针对用户博文时效性及短文本建模中频词缺失的问题,提出了遗忘曲线和BTM词频双层加权微博用户画像TW-BTM方法(forgetting curve time function and btm word frequency double-weighted microblog user portrait,TW-BTM)。将微博数据集按时间片切分;利用拟合时间函数,计算微博词条的时间权重,动态调整用户兴趣词集;采用词频加权BTM对不同时间片上处理后的用户兴趣词集建模,获取经双层加权处理的用户兴趣主题词;通过微博用户行为影响力获取不同时间片下各主题对应的主题词,构建用户画像。TW-BTM方法框架如图2所示。
如图2所示,TW-BTM方法的总体框架包括:微博文本预处理、微博用户主题满意度、时间和词频双层加权、微博用户行为影响力计算。
2.1 微博文本预处理
采用jieba分词对微博短文本进行处理,主要包括微博短文本过滤、分词及词性标注、去停用词和特征选择4个步骤。对处理好的文本集按时间片大小划分数据。微博短文本集预处理流程如图3所示。
由于数据集的特殊性,本文根据数据集的特点,构建一个词典userdict和添加了一些网络口语、表情包的停用词表stoplist,帮助分词工具更好的对数据集中特定词的准确分词,提高分词的准确率。
2.2 时间和词频双层加权
2.2.1 遗忘曲线时间加权
针对用户博文时效性的问题,不同时间的博文表现了用户对话题不同的关注兴趣点,故考虑时间因素的影响,从时间权重的角度,动态调整用户兴趣词集。
采用jieba分词后的数据,初步构建用户兴趣词集。利用艾宾浩斯遗忘曲线拟合时间函数,获取不同时间片微博文本词条的时间权重之和,动态调整用户兴趣词集,挖掘不同时期的用户关注点。
艾宾浩斯遗忘曲线[12]是由德国心理学家艾宾浩斯针对人脑对于新事物的遗忘规律得出的研究成果。艾宾浩斯遗忘曲线,描述了人对事物的记忆随时间变化逐渐降低的过程。可以将用户对一个事物的兴趣关注度类比为记忆,根据艾宾浩斯曲线呈现的图像得出用户对一个事物的兴趣关注程度随着时间不断降低的结论。利用遗忘函数拟合的时间因子,符合遗忘曲线变化趋势,进而拟合时间函数。
假设ST表示艾宾浩斯遗忘曲线拟合时间因子,则公式如下所示
ST=85.09×[Tmax-(Tu0-tε)]-0.2298+16.22
(1)
假设TW表示用户词条出现的时间与当前时间的时间差所反映的用户兴趣变化的权重,则公式如下所示
(2)
假设SumTW表示时间片内各词条的时间权重之和,则公式如下所示
(3)
其中,Tu0表示词条在时间片内第一次出现的时间,Tmax表示时间窗口的最大时间,Tcur表示当前时间,Trec表示词条在时间片内最后一次出现的时间,t=1,2,…,n表示时间片的个数,ε表示时间窗的大小。式(2)中的数字含义参考文献[16]。
根据遗忘曲线时间权重之和SunTW, 设置时间权重阈值,通过实验获取最佳阈值,筛选掉低频词汇,提高中频词占比,帮助模型能够更好提取用户兴趣主题词。
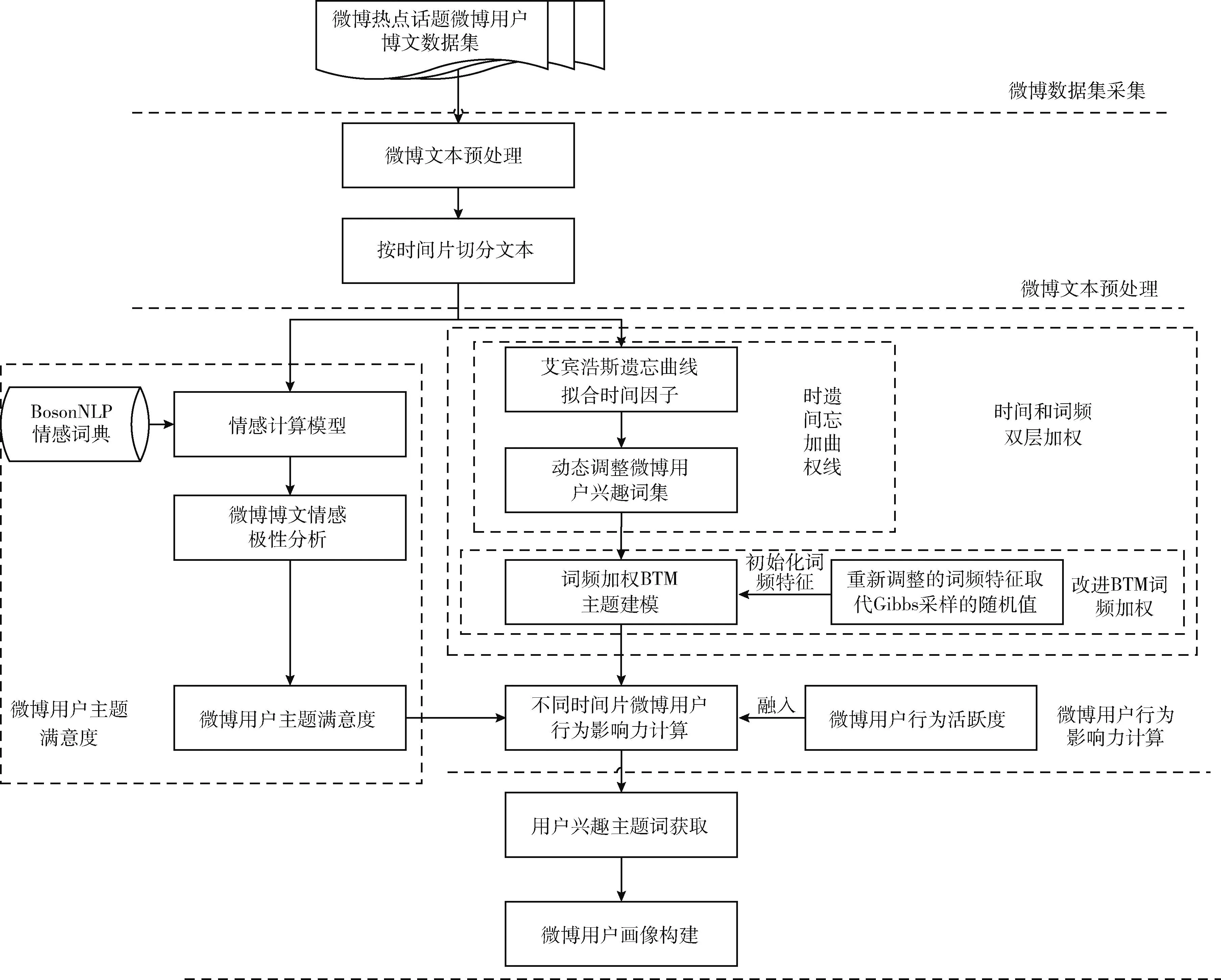
图2 TW-BTM方法框架

图3 微博短文本集预处理流程
2.2.2 改进BTM词频加权
针对传统BTM主题模型在处理微博短文本时存在语义特征稀疏和中频词缺失的问题,本文对BTM进行改进,提出了一种词频加权的BTM主题模型。具体是根据统计文档中的当前词的词频、中频词的词频及词频统计结果中的最大最小值,并计算每个词出现的次数及在文本中的权重之和,重新调整特征词的权重。将调整好的词频特征引入Gibbs采样的过程中,采样过程中初始化的不再是随机值,而是重新计算的词频权重。这可以降低高频词的影响力,提高中频特征词的影响力。经过计算时间权重和提高中频词词频权重,使得模型不过分偏重于高频特征词词语,更准确提取各主题间的主题词。
为保障加权后总特征词的个数不变,需要对每个特征词的权重做调整,Ci为调整好的词的权重。用计算得到的Ci替换Gibbs采样过程中初始化的随机值。假设Gi表示第i个词的权重,取值范围[1,2]。则模型的词频加权公式如下[15]
(4)
(5)
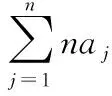
2.3 微博用户行为影响力计算
2.3.1 微博用户主题满意度
微博汇聚了大量包含人们思想、感受和经历的文本[16]。热点话题下,用户发布的博文具有不同的情感信息,表达了用户的不同感受。通过对微博文本的情感极性分析,更准确提取用户需求。根据用户发布的博文,利用借助情感词典的情感计算模型,计算整条博文的情感得分。
由于微博博文发布格式随意,内容常包含大量网络用语和日常口语。常用的情感词典无法覆盖这些网络交互用语,不能准确挖掘文本原本的情感信息。因此采用BosonNLP情感词典对用户博文进行情感分析,该词典是从微博、新闻、论坛等数据来源的上百万篇情感标注数据当中自动构建的情感极性词典。因为标注包括微博数据,并有很多网络用语及非正式简称,对非规范文本也有较高的覆盖率,更符合本文分析博文情感极性的情况。
情感计算模型步骤具体如下:
步骤1 获取BosonNLP情感词典内容,BosonNLP情感词典中包含情感词和对应的情感权重;读取情感词典的每一行,转换成字典格式;
步骤2 将分词结果转换为字典,找出分词文本中的情感词、否定词和程度副词;
步骤3 情感词权重初始化为1,单条用户博文情感分数为0,情感词下标初始化为-1,情感词的位置下标集合;
步骤4 遍历分词文本
(1)判断是否是情感词,如果是情感词,则权重*情感词;
(2)情感词下标加1,获取下一个情感词的位置;①判断当前的情感词与下一个情感词之间是否有否定词或程度副词;②更新单条博文的权重,如果有否定词,权重取反;
(3)定位下一个情感词;
步骤5 计算博文整体的情感得分,情感值为正数,表示积极;为负数表示消极。
通过情感计算模型,对用户文本进行情感分析,获取每一条用户博文的情感极性,动态挖掘微博用户主题满意度,获取用户关注兴趣点。
假设wk,t为t时间片下主题k的满意度,则微博用户主题满意度[15]公式如下
(6)
式中:ht为t时间片下k主题的积极博文数量,Sk,t为t时间片下主题k下的博文总数。
2.3.2 微博用户行为活跃度
考虑到热点话题下不同时间片文本重要性的不同,如何提取由双层加权获得的不同时间片用户兴趣词的占比构建用户画像是需要解决的问题。
热点话题下用户参与的方式存在多样性,点赞、评论和转发等用户行为,同样反映了用户兴趣关注点。考虑不同时间片用户博文转发量F、 评论量P和点赞量D等行为数据,提出了微博用户行为活跃度。
假设Tk,t表示第t个时间片的微博用户行为活跃度,则Tk,t计算公式如下
Tk,t=[(Ftmax/Fsum)+(Ptmax/Psum)+(Dtmax/Dsum)]/3
(7)
式中:Ftmax表示第t个时间片微博用户博文最高转发量,Fsum表示微博用户博文总转发量;Ptmax表示第t个时间片微博用户博文最高评论量,Psum表示微博用户博文总评论量;Dtmax表示第t个时间片微博用户博文最高点赞量,Dsum表示微博用户博文总点赞量。
结合微博用户主题满意度和微博用户行为活跃度等因素,提出微博用户行为影响力计算方法,提取不同时间片的用户兴趣主题词,更全面刻画热点话题下的用户画像。假设vtm为t时间片下的微博用户行为影响力,则vtm计算公式如下
(8)
式中:wk,t为t时间片下主题k的微博用户主题满意度,Tk,t表示第t个时间片下主题k的微博用户行为活跃度,nk,t表示t时间片下各主题k下的特征词个数。
综上,TW-BTM方法描述如下:
步骤1 处理好的文本集按时间片大小划分数据;
步骤2 对不同时间片内的微博词条根据式(1)~式(3)计算时间权重,并根据权重设置阈值,动态调整用户兴趣词集;
步骤3 将根据式(4)和式(5)计算得到的词频特征替换Gibbs抽样过程中初始化的随机值,利用词频加权BTM主题模型建模,提高中频特征词词频,获取经双层加权的用户兴趣主题词;
步骤4 采用BosonNLP情感词典和情感计算模型,分析用户博文情感极性,利用情感极性信息根据式(6)计算微博用户主题满意度;
步骤5 利用用户的兴趣行为(点赞、评论、转发)信息,根据式(7)计算微博用户行为活跃度;
步骤6 根据式(8),利用微博用户主题满意度和微博用户行为活跃度等因素计算微博用户行为影响力,根据影响力值,提取不同主题下的主题词;
步骤7 利用不同时间片下各主题词的汇总,构建各热点话题下的用户画像。
3 实验结果与分析
3.1 实验环境及数据
本文在64位Windows8版本系统的计算机上进行模型搭建与实验。采用PyCharm Professional Version 2021.2.1和Anaconda3开发环境下进行,编译语言为Python3。
本文采用的是新浪微博平台发布的2014年5月4日到5月11日的公开热点话题数据集,其中包含了84 168条数据,通过删除数据中的噪声重复数据,保留了37 739条博文。数据集的组成部分见表1,数据展示示例见表2。

表1 数据集的组成部分

表2 数据集展示示例
3.2 模型参数的确定
本文引入PMI-score作为模型的评价指标,PMI-score表示同主题下特征词语之间的相关性,PMI-score分值越高,表明模型提取主题词效果越佳,建模效果越好。PMI-score的计算公式如下
(9)
其中,p(wi,wj) 表示滑动窗口内同时出现词对 (wi,wj) 的联合分布概率,p(wi) 是词语wi在边缘概率分布范围内出现在滑动窗口的边缘概率,N表示每个主题下特征词的个数,在这里,N=10。
TW-BTM的初始超参数取经验值,α=50/k,β=0.01, 迭代次数由实验所得,取20次实验结果的平均值作为迭代次数的PMI-score值,实验结果如图4所示。
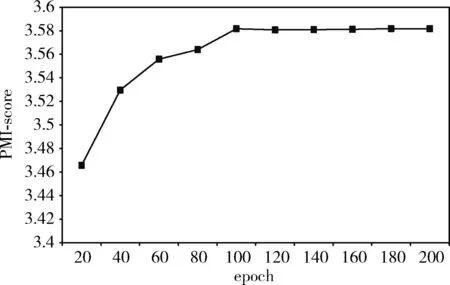
图4 TW-BTM在不同迭代次数下的PMI-score
由图4可知,迭代次数为100时,PMI-score值最优,表明提取的主题词效果最佳,因此,本实验中n-iter=100。
3.2.1 最优主题数选取
本文利用PMI-score确定最优主题数k值。本实验中,α=50/k,β=0.01, 迭代次数为100,Day=3,主题数k取值为3,4,5,6,7,8,9,10,11。实验重复进行20次,取20次实验结果的平均值作为不同k值的PMI-score值,实验结果如图5所示。
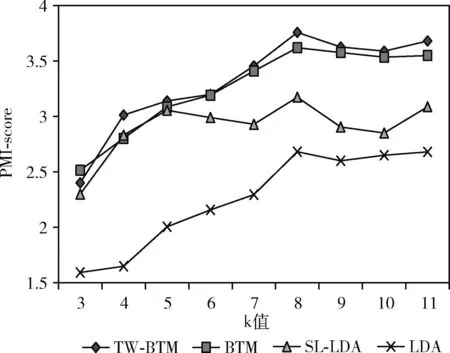
图5 4种方法在不同主题数下的PMI-score值
由图5可知,随着主题数的增加,4种模型的PMI-score都呈现先上升后下降的大趋势且都在主题数目为8时,4种方法的PMI-score值最大,表明此时模型的建模效果最佳,因此选取的最优主题数k=8。
3.2.2 时间函数阈值选取
针对微博数据具有时效性的特点,利用遗忘曲线拟合时间函数,获取每个时间片文本的时间权重,通过不同时间权重阈值的筛选,确定最佳的阈值。本实验中,迭代次数为100,最优主题数k为8,取20次实验结果的平均值作为不同阈值的PMI-score值,实验结果如图6所示。

图6 遗忘曲线拟合时间函数在不同阈值下的PMI-score值
如图6所示,本实验在未经时间函数处理的原始文本数据及遗忘曲线时间函数阈值范围设置为<100,<90和<80时进行。当文本的时间权重阈值为<100时,PMI-score值最大,这是由于时间函数筛选掉了数据集中的低频词,提高中频词的占比,使得TW-BTM能够取得更好的建模效果。当阈值为<90和<80时,PMI-score逐渐降低,这是因为阈值设置低,不仅会减少文本分词后的低频词汇,还减少了一部分中频词汇,导致在建模过程中,造成主题词提取分类不明确。当数据集为原始数据时,PMI-score值比较低的原因是噪声词过多,导致主题建模出现大量重复词汇且各主题间主题词的区分度不高,出现主题词混淆的情况。
3.3 热点话题下微博文本主题分析及用户画像构建
3.3.1 微博文本主题分析
选取时间片3和时间片4下各主题的Top10主题词,相关热点话题的核心大致可以分为恒大、同桌的你、火箭、韩剧等8个主题。经过时间权重和词频权重的计算,TW-BTM提取的不同时间片各主题下用户兴趣主题词,见表3。
从表3可知,时间片3和时间片4主题词有一些重复的词,这是由于不同时间片的数据集属于同一个热点话题,主题相同,因此不同时间片的主题词有一定的重复度。同时前后时间片主题词又存在不同,这是由于时间的推移,用户对相关热点话题的关注度更加深入,出现用户兴趣偏移的情况,因此不同主题下主题词获取结果不同。表明了TW-BTM能够准确的捕获用户兴趣词,提高不同时间片各主题主题词的区分度。
3.3.2 微博用户主题满意度分析
通过借助BosonNLP词典,利用情感词典模型对热点话题下的用户博文进行情感分析,实现热点话题下用户博文的情感二分类结果。其中,积极29 420条,消极8319条,由于微博用户主题满意度需要不同时间片各主题下的积极博文数量,故积极博文分布见表4。

表3 Day3和Day4的Top10主题词

表4 热点话题的积极博文分布情况
由表4所示的不同时间片主题下积极博文分布,依据式(6)计算各主题的微博用户主题满意度。实验结果如图7所示。

图7 不同时间片下各主题的微博用户主题满意度
由图7可知,微博用户主题满意度都在0以上,表明热点话题下用户博文大多是积极的,但各主题的满意度是存在差异的。在各热点话题中,恒大话题的用户满意度是各主题最高的,且整体趋势趋于平稳状态。在时间片7略有下降,表明用户对那一天的比赛结果略有失望,用户消极情感有所上升,但还是以积极为主。魅族话题用户讨论也是积极为主,但是消极评论增加的比例也是稳定的,表明部分用户认为魅族手机存在一些不足之处,这也能帮助企业去更好改进产品,满足用户的基本诉求。用户对其余主题的积极情感虽有升有降,也是积极为主,消极为辅。
3.3.3 微博用户行为影响力分析
通过对不同时间片微博内容的点赞量、转发量、评论量的计算,获得微博用户行为活跃度,同时利用微博用户主题满意度与主题下的特征词个数,共同计算不同时间片各主题的微博用户行为影响力,见表5。

表5 不同时间片各主题的微博用户行为影响力
通过用户微博行为影响力的计算,获取每个时间片各主题下用户最感兴趣的主题词,构建热点话题下的用户画像。由表5可知,不同时间片各主题的微博用户行为影响力分布数值,相对平均,可以相应获取不同时间片的兴趣主题词,准确捕捉各主题下的用户兴趣关注点。同时也可以看出,在时间片7时的微博用户行为影响力低于其它时间片,这是由于时间片7的用户行为活跃度偏低和所包含的博文消极情感有所增加,用户满意度有所下降,导致该时间片下的微博用户行为影响力普遍偏低。
为了更直观表示热点话题下用户讨论的主题词与权重,本文采用词项概率分布进一步生成热点话题下用户兴趣主题词词云,如图8所示。

图8 热点话题下用户兴趣主题词词云展示
从图8中的图(a)~图(d)可知,通过微博用户行为影响力计算获取的恒大、火箭、同桌的你和韩剧热点话题下的用户兴趣主题词,可以高度概括这4个主题下用户的关注点。因此从不同时间片获取的用户兴趣主题词,可以更形象地刻画各主题下的用户画像。
3.4 对比结果实验分析
为了验证TW-BTM方法的有效性,本实验使用公开数据集,分别与BTM、SL-LDA与LDA进行比较,利用这4种方法对数据集建模并分析实验结果。选用“同桌的你”热点话题的词分布进行分析,4种方法获取的Top10主题词见表6。

表6 4种方法在“同桌的你”热点话题下 Day1和Day7主题词
由表6可知,在关于“同桌的你”的主题词中,BTM、SL-LDA和LDA输出的结果中都存在噪声数据,TW-BTM方法输出的主题词几乎不含噪声词,说明TW-BTM建模得到的主题词能更好地概括和描述主题。这是由于TW-BTM在考虑时间因素的同时,也改进了吉布斯采样过程中词频特征的计算方法,提高了中频词的影响力,删除了无用的低频词和造成主题区分度不高的词。因此,TW-BTM相较于其它3种模型,能更准确挖掘热点话题下用户的兴趣词。
为了更形象展示4种方法在用户博文主题词挖掘方面的能力,本文计算了不同时间片内4种方法的PMI-score值,如图9所示。
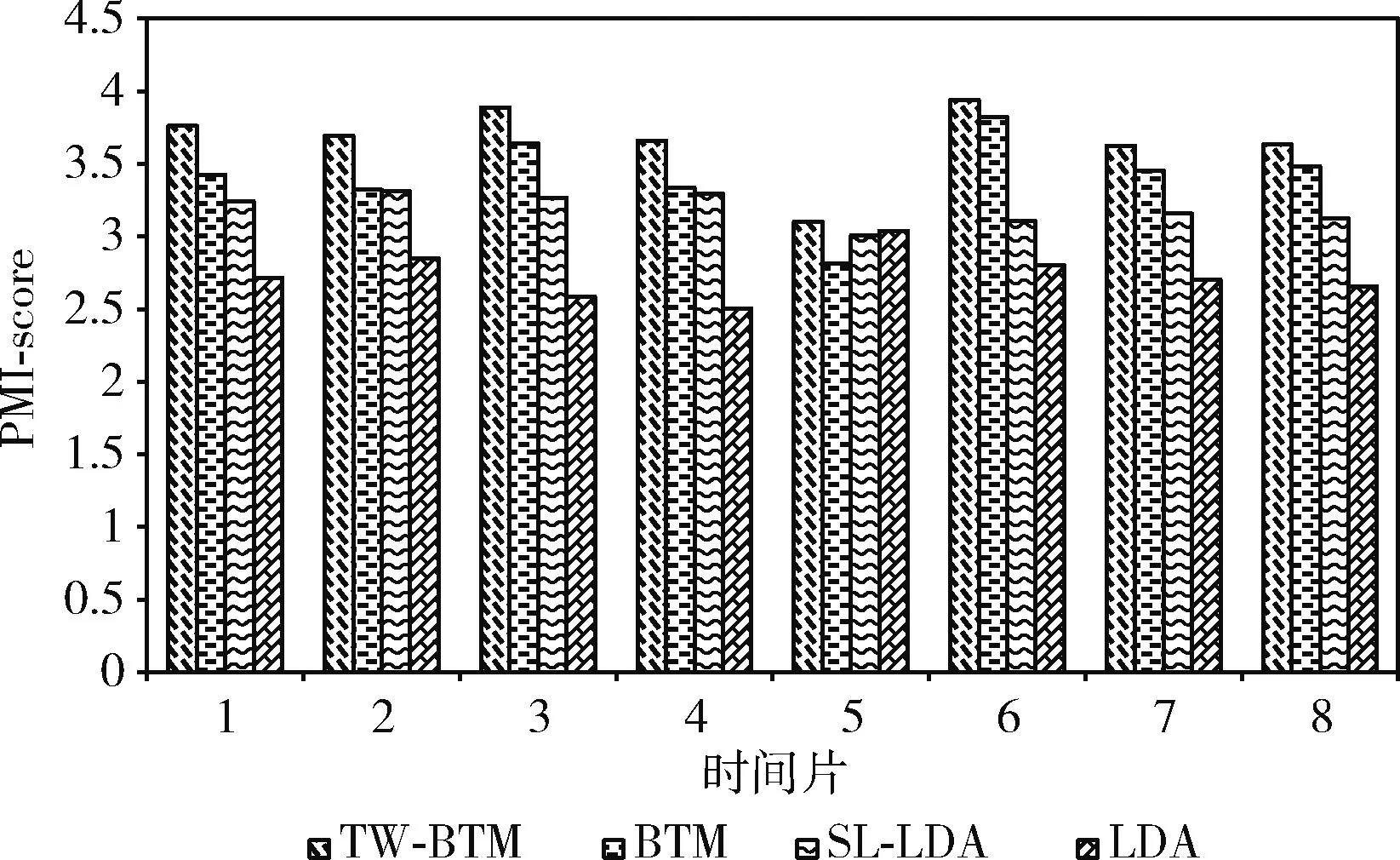
图9 4种方法在不同时间片内对应的PMI-score
由图9可知,TW-BTM在不同时间片的PMI-score值均大于其它3种模型。这是因为BTM擅长处理短文本,但是未考虑时间因素和中频词对主题建模及提取主题词的影响,导致获取的主题词区分度不高。LDA和SL-LDA由于更擅长对长文本建模,而微博短文本具有语义稀疏和时效性的特点,影响了两个模型的建模效果,导致出现不同时间片各主题间主题词混乱的情况。LDA由于其未考虑中频词的影响,导致模型建模效果在4种模型中最差。TW-BTM构建的用户画像能更准确地表达热点话题下用户的兴趣。
4 结束语
本文提出了遗忘曲线和BTM词频双层加权微博用户画像TW-BTM。利用遗忘曲线构建时间函数,计算微博文本时间权重,删除噪声词汇,提高中频词占比。改进BTM模型,将调整好的词频特征引入Gibbs采样过程中,提高了中频词的影响力和模型主题词提取的能力。结合微博用户主题满意度和微博用户行为活跃度等因素,提出微博用户行为影响力计算方法,准确获取经双层加权处理的不同时间片各主题的主题词,更全面构建热点话题下的用户画像。实验结果表明,与BTM、SL-LDA及LDA模型相比,TW-BTM在各个时间片内都有更高的PMI-score值,提高了主题间的区分度,降低了主题词的重复度,能更好地提取用户的兴趣词。
