Human-Computer Interaction Using Deep Fusion Model-Based Facial Expression Recognition System
2023-02-26SaiyedUmerRanjeetKumarRoutShailendraTiwariAhmadAliAlZubiJazemMutaredAlanaziandKulakovYurii
Saiyed Umer,Ranjeet Kumar Rout,Shailendra Tiwari,Ahmad Ali AlZubi,Jazem Mutared Alanazi and Kulakov Yurii
1Department of Computer Science&Engineering,Aliah University,Kolkata,700156,India
2Department of Computer Science and Engineering,National Institute of Technology,Srinagar,Jammu and Kashmir,190006,India
3Department of Computer Science&Engineering,Thapar University,Patiala,147004,India
4Computer Science Department,King Saud University,Riyadh,11451,Saudi Arabia
5Department of Computer Engineering,National Technical University of Ukraine,Igor Sikorsky Kyiv Polytechnic Institute,Kyiv,03056,Ukraine
ABSTRACT A deep fusion model is proposed for facial expression-based human-computer Interaction system.Initially,image preprocessing,i.e.,the extraction of the facial region from the input image is utilized.Thereafter,the extraction of more discriminative and distinctive deep learning features is achieved using extracted facial regions.To prevent overfitting,in-depth features of facial images are extracted and assigned to the proposed convolutional neural network(CNN)models.Various CNN models are then trained.Finally,the performance of each CNN model is fused to obtain the final decision for the seven basic classes of facial expressions,i.e.,fear,disgust,anger,surprise,sadness,happiness,neutral.For experimental purposes,three benchmark datasets,i.e.,SFEW,CK+,and KDEF are utilized.The performance of the proposed system is compared with some state-of-the-art methods concerning each dataset.Extensive performance analysis reveals that the proposed system outperforms the competitive methods in terms of various performance metrics.Finally,the proposed deep fusion model is being utilized to control a music player using the recognized emotions of the users.
KEYWORDS Deep learning;facial expression;emotions;recognition;CNN
1 Introduction
Facial expressions are an important way of communication for understanding emotions in human beings.These human emotions are identified by various traits such as text,Electroencephalography,speech,and face.These emotions performed by these traits are more noticeable and observable[1].There is a wide range of applications of these emotions in Computer Vision applications,such as sentiment analysis for pain analysis in the human body,security,criminal interrogation,patient communication,psychological treatment,etc.Facial emotions play an essential role in the various emotional traits that contribute to more exciting expressions.According to Ekman et al.[2],there are seven basic expressions on the human face such as fear,neutral,sadness,disgust,anger,happiness,and surprise.In facial expression recognition,these expressions are recognized.The capturing of these expressions is less invasive and tangible than other emotional traits.Moreover,the intensity variations over the facial region differ due to these expressions.Some examples of these seven basic facial expressions are shown in Fig.1.

Figure 1:Some basic human facial expression images
The facial features play an essential role in identifying the emotions on the human face.The seven basic emotions (expressions) where each expression has its significance based on its intensity on the face.Moreover,it has also been observed that there are some mixed emotions[3]which are the combinations of these basic seven emotions.Capturing expressions under unconstrained environments is less invasive and tangible and requires non-interruption while the person is far or moving from some distance.So,over the past few years,emotion recognition using facial expressions has brought much more attention to affective computing and cognitive science research areas.There are various aspects of FER (facial expression recognition) models in human-computer interaction,augmented reality,driving assistant models,etc.During the implementation of the FER model,the categorical subject model derives the emotions in terms of discrete primary emotion[4].
The facial expressions are obtained from the eye,mouth,and cheeks portion of the face region.In contrast,the other parts of the facial region support enhancing the expression level in the face region.The research areas of facial expression are in the study of affective computing [5] which is an application of computer vision problems.In affective computing research areas,the recognition of facial expressions is a categorical-based model.The analysis of the coding of facial action units is a continuous-based model.We have considered the categorical model for the facial expression recognition (FER) model in this work.The FER model includes both images,and video-based recognition[6].The spatial information is extracted as feature representation in the image-based FER model,whereas both spatial and temporal features are considered in the video-based FER model.The spatial features have high distinctiveness and discriminating power than temporal features[6].Using a small number of training instances in genetic programming for face image classification has been proposed by Bi et al.[7].Similarly,the multi-objective genetic programming for feature learning for face recognition system has been proposed by Bi et al.[8].
Initially,Ekman et al.[9]defined six facial expressions such as fear,anger,disgust,happiness,sadness,and surprise and performed emotion recognition for the FER model.Further,Ekman et al.proposed the concept of the Facial action coding model[10]to measure the facial movement using facial action points.The recognition of facial expressions mainly depends on the types of feature extraction,which are classified as(i)Appearance-based,(ii)Geometric-based feature representation[11].Many works have been done based on these appearances and geometrical features from the facial images.For example,Castrillon et al.[12]designed a gender classification model by considering several models of analyzing the texture patterns within the facial region in.By incorporating the RGB colour channel features along with depth,informative features about the facial region proposed for the FER model in[13].In their FER model,Yan et al.[14]employed the image filtering based feature representation for the low-resolution based image samples.Sadeghi et al.[15]built the histogram distance learning-based feature representation for the proposed model.Makhmudkhujaev et al.[16] presented the various directional descriptors with prominent local patterns as features from the facial images.These Models and employed techniques follow local to global feature representation schemes,and most of these features are structural and statistical-based features.
In the computer vision research areas,the above-discussed features have succeeded in solving object recognition,biometric identification,face recognition,instance-based recognition,and texture classification problems.But due to current state-of-the-art problems,these models have limited performance.Learning robust and discriminative low-rank representations for face recognition with occlusion has been proposed in [17].In the current cutting-edge problems,the deep learning-based approaches have gained great success in solving problems either in computer vision or in business world research areas.The deep learning-based approach is described as a neural network with many layers and parameters.This approach defines some fundamental network architectures such as unsupervised pre-trained networks [18],convolutional [19],recurrent [20],and recursive neural networks[21].Among these networks,the convolutional neural networks[19] are used for the FER model.Ye et al.[22]proposed a region-based convolutional fusion network for the facial expression recognition model.By identifying relationships among different regions of a facial image,the FERS is built by Sun et al.[23].Lai et al.[24]developed CNN models to recognize facial expressions.A FER model based on local fine-grained temporal and global spatial appearance features using a global-local CNN network has been built in [25].Hence,with the several benefits of deep learning-based CNN architectures,a facial expression recognition model has been proposed in this work that can predict the challenging expressions in the facial region in both controlled and uncontrolled environments.There are several existing works in the FER model using image/video-based,but still,there are several challenging issues[26].During image acquisition of the facial region,the images suffer from motion blur,noise artifacts,occlusion by the hair,illumination variations,and occlusion by accessories such as glass,makeup,scarf,and mark.Accepting these challenges,we have developed a categorical modelbased facial expression recognition model using images in this work.The contributions of this paper are summarized as follows:
• Deep fusion-based facial expression recognition model is proposed for human-computer interaction.
• Proposed deep learning models extract more distinctive and discriminant features from the facial images.
• To improve the recognition performance of the proposed model,some influential factors such as data augmentation,fine-tuning the hyper-parameters,and multi-resolution with progressive image sizing are employed to improve the recognition model’s performance.
• Different deep learning-based approaches are fused at the post-classification stage to obtain the final decision for the recognition model.
• The proposed model is tested on three benchmark datasets:SFEW,CK+,and KDEF,and the performance and comparison with the existing state-of-the-art models due to these datasets have been demonstrated with the proposed system.
This paper is organized as Section 2 describes each step of the proposed Modelology; The experimental dataset description,results in discussion,and comparisons have been demonstrated in Section 3;Finally,the findings of this research have been concluded in Section 4.
2 Proposed Scheme
This section discusses implementing the proposed deep fusion-based facial expression recognition(FER) model.Depending upon the input face,the proposed model predicts the type of expressions among the seven facial expressions (anger,sadness,surprise,disgust,happiness,neutral,and fear)classes.The proposed model is decomposed into four steps: (i) the first step is image preprocessing,where the face region(F)is detected from the input imageIm×n,(ii)in the second step,deep learningbased approaches have been employed for feature learning,and classification purposes,(iii)in the third step several parameters regarding the performance improvement of the proposed model have been discussed,(iv)for the usability of different training models the scores due to these training models are fused to obtain the final decision for the facial expression class in the fourth component.The working principle of the proposed model is represented in Fig.2.
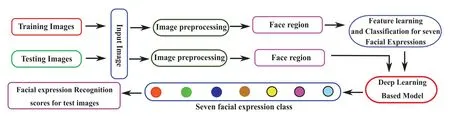
Figure 2:Block diagram of the proposed system
2.1 Image Preprocessing
During an unconstrained imaging environment,noise,illuminations,variations in poses,and cluttered backgrounds are mainly the problems,and these may arise some irrelevant features.So,to extract more relevant and valuable features,the face region has been detected as a region of interest from the input image.The extracted face region has been normalized to similar dimensions that the same dimensional feature vector can be extracted.In this work for face detection,a tree-structured part model[27]has been employed,which works for all variants of face poses.This model computes sixtyeight landmark points for the frontal face,while thirty-nine landmark points have been extracted for the profile face.Then these landmark points are employed to calculate the face region from the input image.The Bilinear image interpolation technique has been applied to the detected face region for the normalization purpose.The face detection process for the proposed model is depicted in Fig.3.
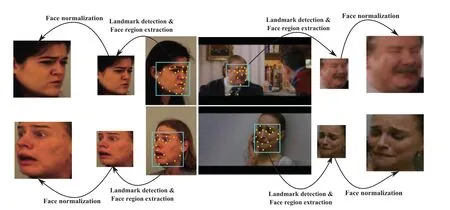
Figure 3:Face preprocessing for the proposed model
2.2 Feature Learning Followed by Classification
The proposed facial expression recognition model belongs to a pattern recognition problem.The objective of this problem is to extract more distinctive and discriminative features as a feature vector from the facial region images.Then,the classifiers learn these feature vectors to derive a model that will predict the class for facial expressions in the facial region.There exist several structural and statistical-based approaches [28] to solving the FER problem.But nowadays,deep learningbased approaches have gained tremendous success in solving the various issues and problems in the computer vision research area.The deep learning-based approaches work in an encapsulated way by the combined effect of both feature learning and classification task.There are several deep learningbased approaches,and among them,the convolutional neural network(CNN)[29]based models have been employed in this work.The CNN based approaches are based on the core building blocks of convolutional layers,pooling layers,fully connected layers,and dense layers[29].The convolutional layer is the layer where the input is an image that has been convoluted with several distinct filters(kernels).Then,the convoluted images are computed as feature maps concerning the kernels.The computation of these feature maps increases the complexity of the CNN network by increasing the image size and the number of kernels employed for that convolutional layer in the network.
During feature learning,the weights in the kernel are adjusted as parameter settings.The benefits of the convolutional layer are (i) it performs local connectivity by obtaining correlations between neighbours pixels,(ii)weight-sharing in the same feature map reduces the complexity of the network,and(iii)it maintains the shift-invariant properties about the location of the objects.So,the input and output in the convolution layer iswhereFn×n×3is a 3-color channel image,wk×l×lbe theknumber of kernels with each kernel hasl×lsize,be the derived feature maps while each feature map hasn×nsize.To extract more discriminanting features from the feature maps,the max-pooling layers [30] have been employed.The technique of max-pooling layer downsamples the matrices of the features to its half size if 2 × 2 filter size has been employed.In this layer,the filter of size 2×2 strides over the feature map and compute in its region the maximum value first horizontally and then vertically for the computation of discriminant features in the matrix maps to the next layer.The benefits of using max-pooling layers are(i)it decreases the parameters,(ii)reduces the computational overheads,(iii)makes the process of parameter settings faster within the network,and(iv)avoids overfitting problems.
The addition of the fully connected layer is performed at the end of the network to perform a classification task for the learned features from the previous layer.It ensures all neurons from the previous layers are fully connected to the next layer in the form of a 1-dimensional feature map.Another layer is the dense layer[31]which is also a type of fully-connection layer.The main differences between fully-connected and dense layers are(i)linear operations are being performed in a dense layer,and (ii) the dense layer computes the matching scores for each input sample as outcomes using the softmax activation function[32]at the end of the network.In addition to these layers,some other layers,such as batch normalization[33]and dropout layers[34]have also been adopted in this work.The batch normalization layer also reduces the computational overheads while maintaining the homogeneity in the batch of data for learning the parameters in the network.The dropout layer is being used to ignore some randomly selected neurons in the network from learning,i.e.,the weights to that neurons will not be updated during training.The use of dropout layers in the network prevents overfitting problems and combines the predictions of various neural nets.
Here using convolutional layers,max-pooling layers,fully connected,batch normalization,and dropout layers,we have built some convolutional neural networks (CNNs) architectures.The proposed CNN architectures contain the combination of these layers.The diagram for the first CNN architecture is shown in Fig.4.This figure shows five blocks where each block has a sequence of layers,i.e.,Convolutional+Activation+Maxpooling+Batch-Normalization.After the five blocks,there are two fully connected layers (Dense+Dropout).For better understanding and clarity,the number of convolutional layers with kernel size,number of kernels,the number of max-pooling layers,batch normalization,dropouts,feature map’s output shape,and the number of parameters concerning each layer is reported in Table 1.Similarly,the second CNN architecture is shown in Fig.5,and the explanation of the layers and parameters for this network is reported in Table 2.From Tables 1 and 2,it may be concluded that some activation functions such as ReLu(Rectified Linear Unit),Softmax,and Adam as optimizer have been adopted for learning the parameters in the network.Both CNN architectures have been learned for seven class FER problems in this work.
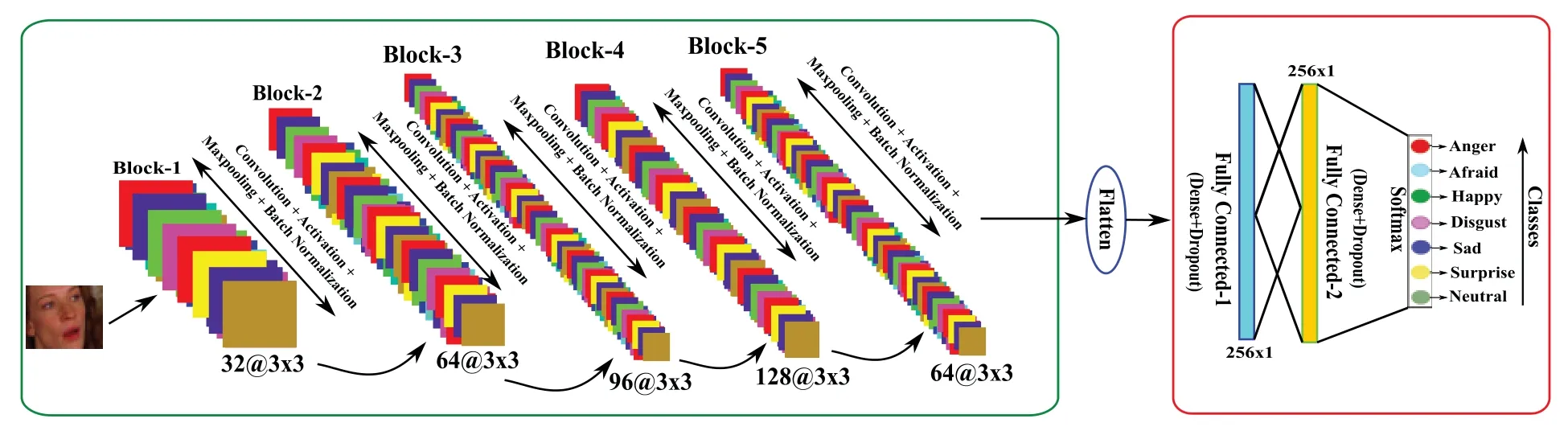
Figure 4:Proposed CNN1 architecture for the FER model
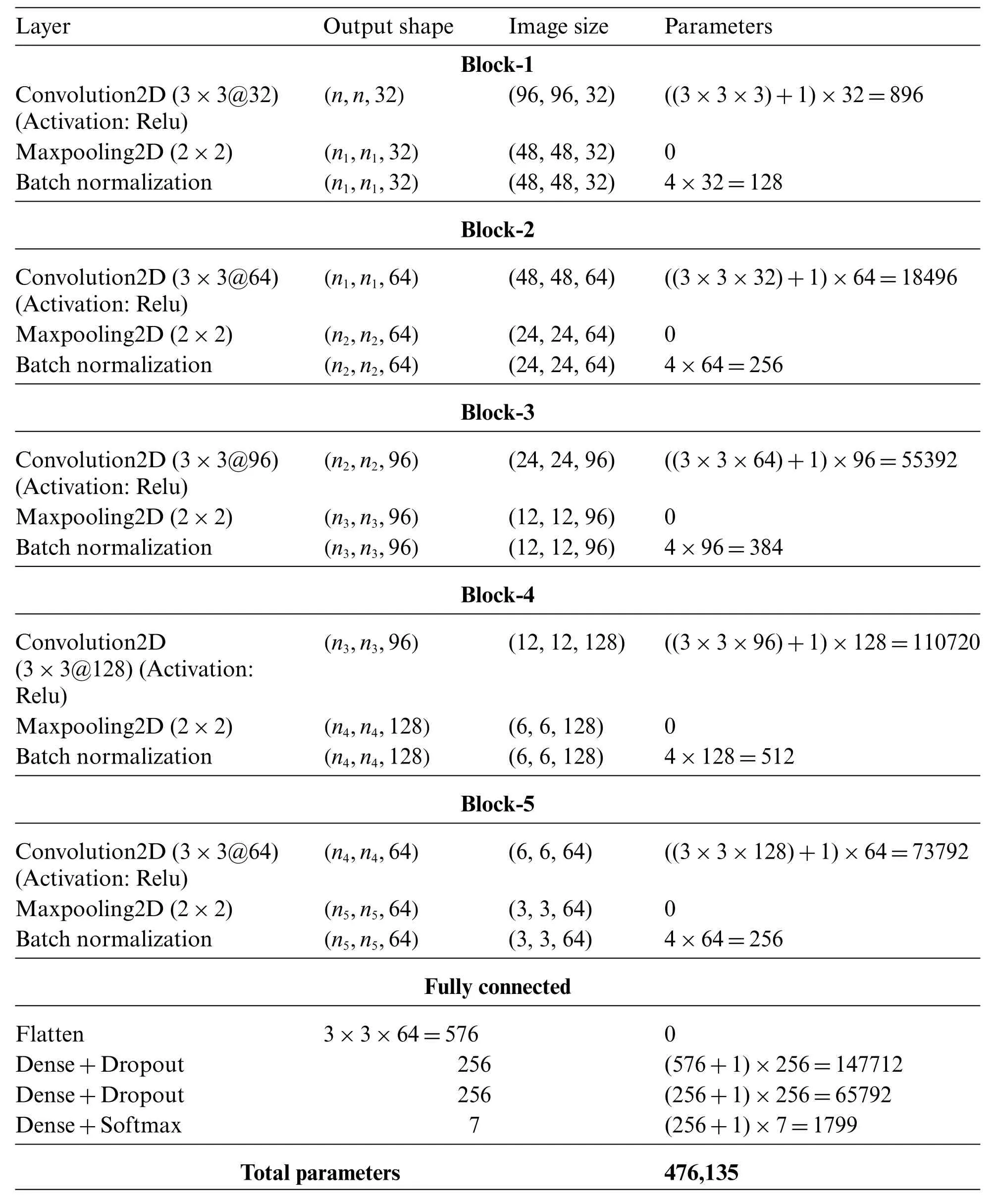
Table 1: Description of parameters,layers,and output shapes for CNN1 architecture
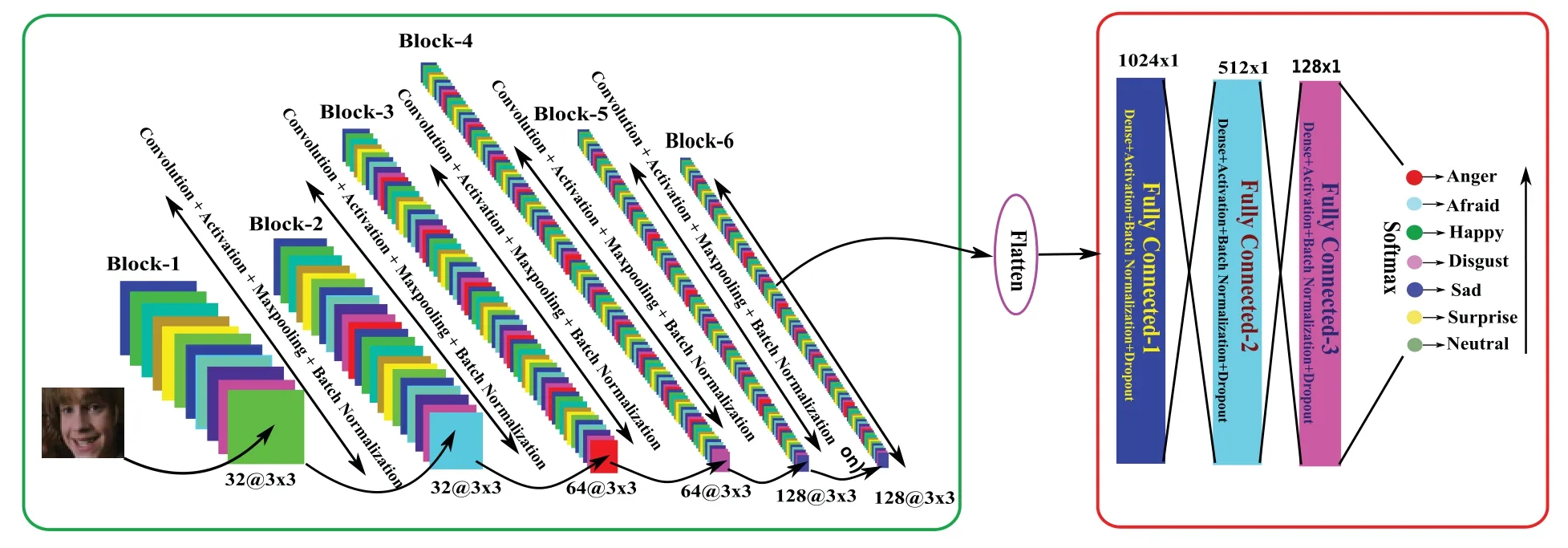
Figure 5:Proposed CNN2 architecture for the FER model
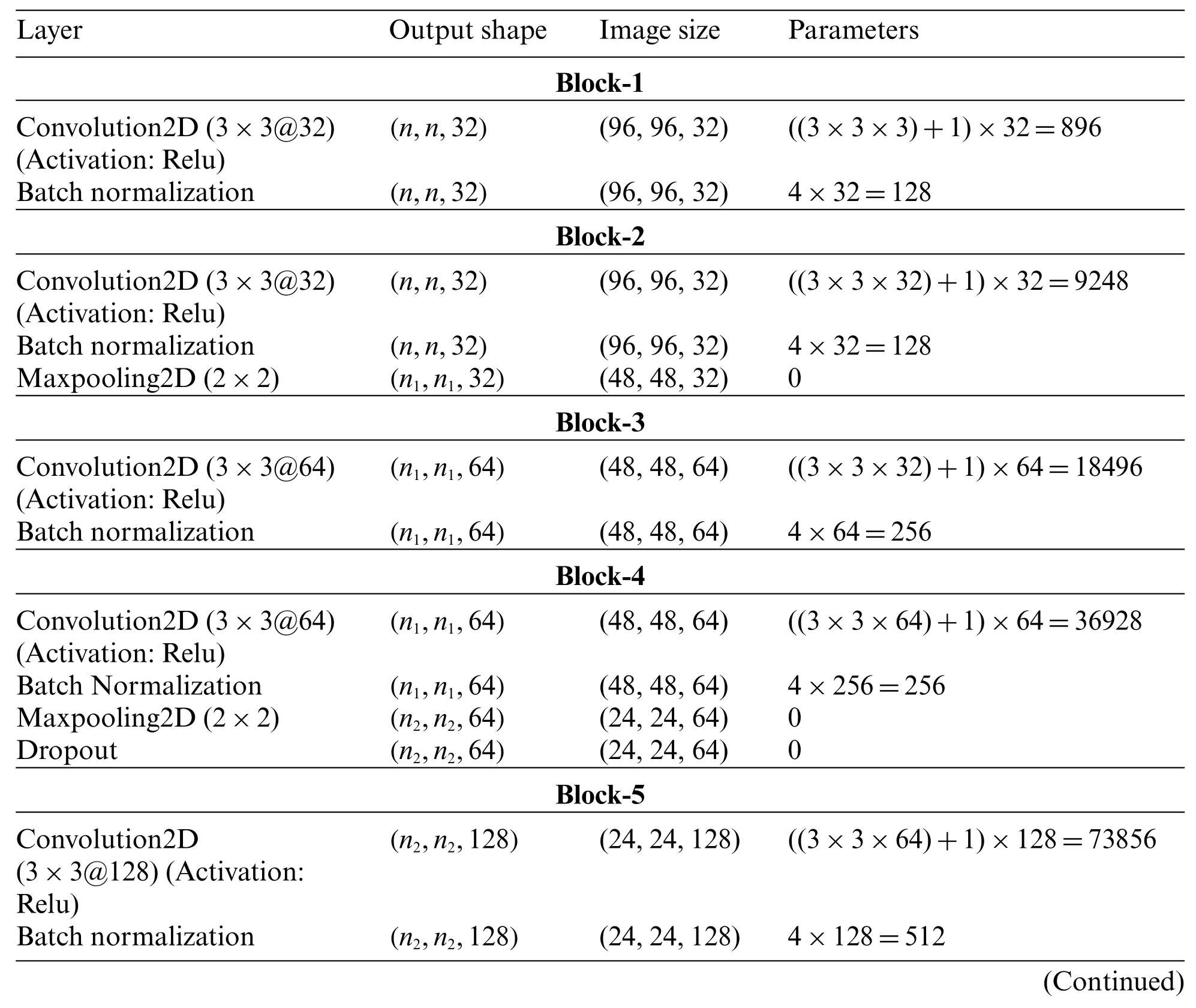
Table 2: Description of parameters,layers,and output shapes for CNN2 architecture
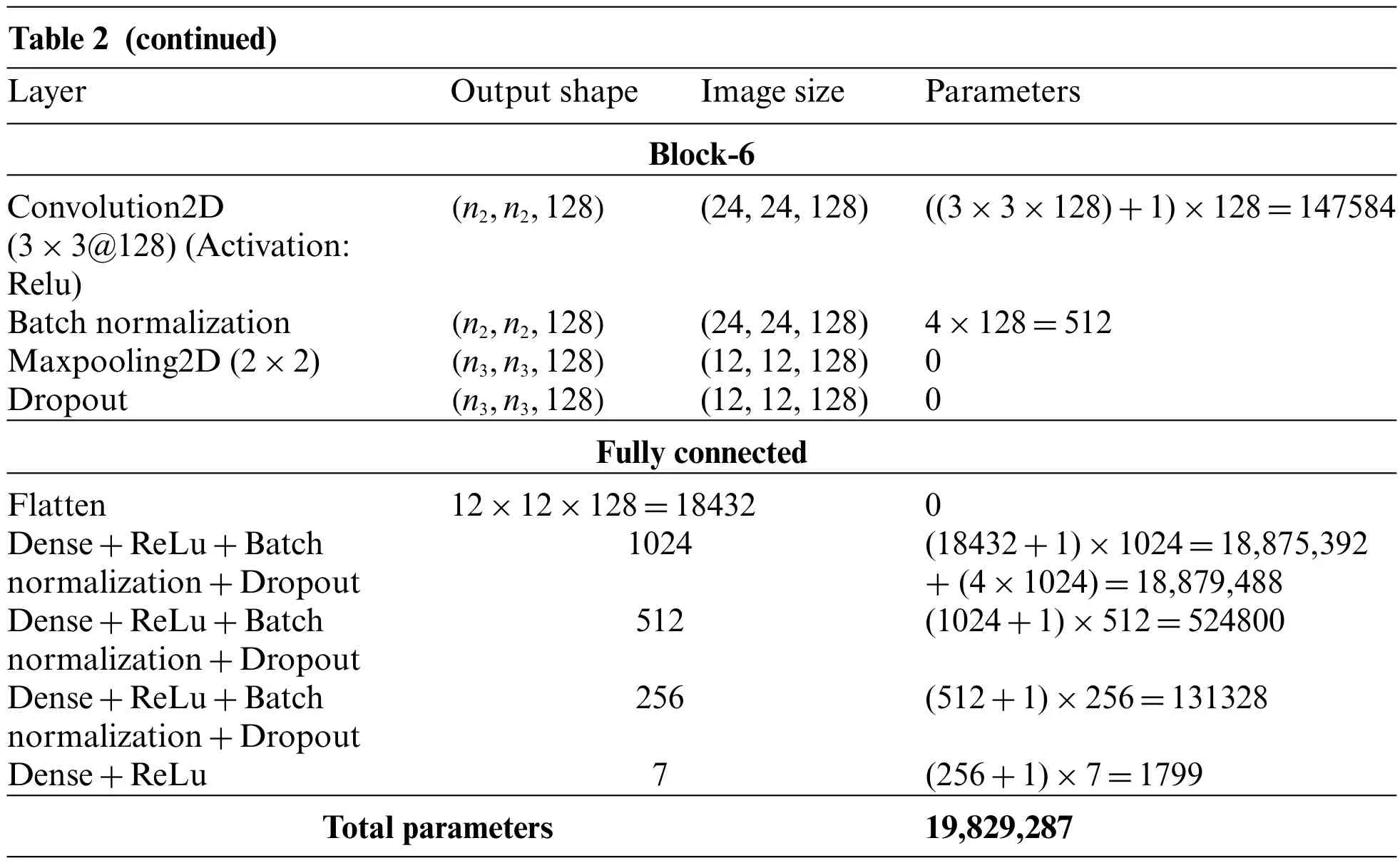
Table 2 (continued)LayerOutput shapeImage sizeParameters Block-6 Convolution2D(3×3@128)(Activation:Relu)(n2,n2,128)(24,24,128)((3×3×128)+1)×128=147584 Batch normalization(n2,n2,128)(24,24,128)4×128=512 Maxpooling2D(2×2)(n3,n3,128)(12,12,128)0 Dropout(n3,n3,128)(12,12,128)0 Fully connected Flatten12×12×128=184320 Dense+ReLu+Batch normalization+Dropout 1024(18432+1)×1024=18,875,392+(4×1024)=18,879,488 Dense+ReLu+Batch normalization+Dropout 512(1024+1)×512=524800 Dense+ReLu+Batch normalization+Dropout 256(512+1)×256=131328 Dense+ReLu7(256+1)×7=1799 Total parameters19,829,287
2.3 Factors Affecting the Recognition System’s Performance
2.3.1 Image Augmentation
In machine learning,the image augmentation technique has been employed for increasing the number of samples that corresponds to each input image,and it is done by applying several filtering and affine transformation techniques[35].The benefits of using the image augmentation techniques are(i)handling the overtraining situation of the convolution neural networks,(ii)reducing the overfitting problems,and (iii) helping the process of fine-tuning for learning the hyper-parameters to get better CNN performance.The image augmentation techniques generate several samples without changing the image fidelity and their visual qualities[36].The generated samples enhance the CNN learning parameters,and learning these better models can be predicted to recognise the required problems.There are several data augmentation techniques and among them,we have employed image filtering techniques such as Bilateral Filtering [37],Unsharp Filter [38],Sharpening Filter[39],Affine transformation[40]: reflection,rotation,scaling [41],shearing [42],zooming[43],filling[44],and horizontally flipping [45] techniques applied on images.Hence,by applying these data augmentation techniques,there are eighteen (original+seventeen augmented) images are generated to correspond to each training image.The image augmentation algorithm for the proposed model has been demonstrated in Fig.6.Algorithm 1 shows the step-by-step computation of the image augmentation technique.

Figure 6:Demonstration of image augmentation applied on each image F in the proposed model

Algorithm 1:Image Augmentation Input:Face Region F Output:Faug 1.Apply Bilateral Filtering[37]on F to get F1 2.Apply Unsharp Filtering[38]on F to get F2 3.Apply Sharpening Filters[39]with different filter mask such as{ω1,ω2,ω3,...,ω9}on F to get F3,...,F11 4.Apply image rotation[40]on F to get F12 5.Apply image scaling[41]on F to get F13 6.Apply image shearing[42]on F to get F14 7.Apply image zooming[43]on F to get F15 8.Apply image filling[44]on F to get F16 9.Apply image horizontal flipping[45]on F to get F17 10.Final augmented set for each F is Faug={F1,...,F17}
2.3.2 Fine Tuning
In deep learning approaches,the performance of CNN may be improved by fine-tuning the hyperparameters of the trained model[46].The fine-tuning considers a trained network model and initializes it by its trained weight,and uses the data from the same domain for further training of that model to a new model.The fine-tuning technique speeds up the training process while also overcoming the small dataset size problem.In fine-tuning,either the whole layers of the trained network are retrained,or some of the layers of the trained model are frozen,and the remaining layers are trained.The performance of the proposed CNN models can also be improved by tuning the hyper-parameters such as learning rate,L2-regularization,batch size,and increasing the model depth [47].Moreover,increasing the image resolution,i.e.,progressive resizing of the face region,can also improve the performance of the proposed CNN model.
2.3.3 Scores Fusion
The techniques under this category are sum-rule,and product-rule based fusion models[48].These fusion techniques are based on scores which are obtained in this work from the proposed CNN trained models with respect to each test sample.Let assume that for any test sampleti,s1∈R1×Mands2∈R1×M,Mbe the class number,are two score vectors obtained from the proposedCNN1andCNN2facial expression trained models.Then the final score vector for the test sampletiusing(i)sum-rule based fusion technique is given bys=s1+s2,and (ii) product-rule based fusion technique is given bys=s1×s2.Now the final score vectorsis used to find the predicted class label for the test sampleti.
3 Experimental Results
This section explains the experiments performed for the proposed facial expression recognition model(FERS).Here we have employed the three benchmark datasets for experimental purposes.The first employed dataset is Cohn-Kanade Extended(CK+)[49]which is composed of 593 short videos from 123 subjects with different lighting and aging variations.For experimental purposes,981 image samples were selected from 123 subjects,where the image samples are of six (Surprise,Happiness,Fear,Disgust,Sadness,and Anger)facial expression classes.Fig.7a demonstrates some image samples from this dataset.Karolinska directed emotional faces(KDEF)[50]is our second dataset which is a seven facial expression class dataset.This dataset comprises 4900 emotional images of human faces with a collection of 35 females and 35 males.In this work,we have downloaded 2447 images,and 1222 images are used for training,while the remaining 1225 are used for testing purposes.Fig.7b demonstrates some images of this dataset.The third dataset is Static Facial Expressions in the Wild(SFEW) [51] which is also a seven facial expression class dataset.This dataset selects frames from the AFEW (Acted Facial Expressions in the Wild) dataset,a dynamic temporal facial expression dataset.This dataset covers several challenges of FER problems.The images of this dataset face several challenges such as varied focus,different resolution of face,various head poses,significant variation in age,considerable variation in occlusions,etc.In this dataset total of 700 frames are extracted from the AFEW dataset,where each frame has been labelled as sadness,surprise,happiness,fear,disgust,anger,and neutral expression class.During experimentation,346 images were selected as training images,and 354 images were selected as testing images.Some images of this dataset have been shown in Fig.7c.Table 3 summarizes the detailed description of the employed datasets for the proposed model.

Figure 7: (Continued)

Figure 7:Some image samples from(a)CK+,(b)KDEF,and(c)SFEW datasets

Table 3: Summarizing the employed dataset for the proposed model
Here,CK+and KDEF datasets have been randomly partitioned,with 50%of the samples from each class being used to form the training set while the remaining 50%of samples from each class form testing set.In the SFEW dataset,the number of training-testing samples is already mentioned in[51].
3.1 Results and Discussion
The implementation of the proposed model has been performed in Python on Ubuntu 16.04 LTS O/S version with Intel Core i7 processor 3.20 GHz and 32′GB RAM.For deep learning approaches,several packages have been employed from Keras [52],and for building the CNN architecture,the Theano Python library has been employed.The performance of the proposed model is shown in the correct recognition rate,i.e.,accuracy in%
During face preprocessing,the face regionFusing the TSPM model is detected from the given input imageI.Then the extracted face regionFis normalized toN×Nfixed size such that a fixed dimensional feature vector can be extracted from eachFN×N.Then the extracted facial regions from the training samples undergo the proposed convolutional neural network architectures,i.e.,CNN1andCNN2.During experimentation,the size of the face regionN×Nis 48×48 while the batch size and the number of epochs vary.To improve the performance of the proposed model,the data augmentation techniques(discussed in Section 2.3.1)have been applied on eachF48×48using Algorithm 1 and hence for eachF,{F1,...,F18}augmented images are obtained.
• Different loss functions impact:At first,the experiment was performed by training theCNN1architecture withF48×48input images by varying the different loss functions to minimize the errors in the network.Here,the mean squared error (MSE) [53],binary cross-entropy [54],and Hinge loss [55] loss functions have been considered for the measuring their impact on the performance of facial expression recognition (FER) system using the proposedCNN1model.These performances have been shown in Fig.8 that shows for the binary cross-entropy loss function,and the performance is better.Hence,the binary cross-entropy loss function is considered for further experiment.
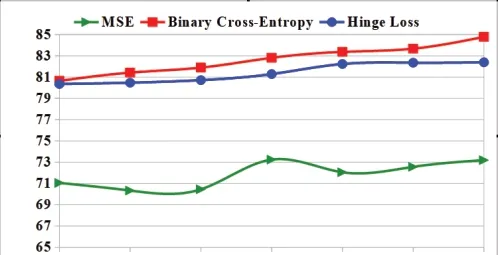
Figure 8:Effectiveness of different loss functions on the performance of CNN1 models for CK+dataset
• Batch vs.epoch impact:In this work,it is seen that the recognition of the proposed model also improves due to the variation of {8,16,32} batch sizes with corresponding {50,100,200,500}epochs.Fig.9 demonstrates the effectiveness of batch sizes and the number of epochs over the performance of the proposed model due toCNN1models for CK+,KDEF,and SFEW datasets.From this figure,it has been observed that the performance improves with the increase of epochs employed for learning the trained model,while the batch size is more or less effective over the performance of the proposed model.For this work,it has been observed that for batch size 8,the performance of the FER model is much better for CK+,KDEF,and SFEW datasets.Hence for further experiments,we have employed eight batch sizes of training samples with 500 epochs for learning the parameters ofCNN1andCNN2architectures.

Figure 9:Effectiveness of trade-off between batch sizes and number of epochs on the performance of CNN1 models:(a)CK+,(b)KDEF,and(c)SFEW dataset
• Data augmentation impact:The effectiveness of data augmentation on the performance of the proposed model is depicted in Fig.10.It is found that the data augmentation techniques have increased the performance of the proposed model.Hence,for further implementation of the proposed model,data augmentation is implemented on each training sample to increase the training sample’s size for better learning of the CNN models.
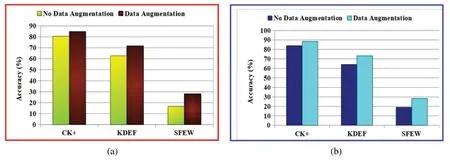
Figure 10:Effectiveness of data augmentation over the performance of the proposed model due to:(a)CNN1 and(b)CNN2 models
• Multiscaling and Multiresolution impact:Hence,the recognition performance of the proposed model is reported in Table 4 where the usefulness and effectiveness of multiscaling and multiresolution of images (progressive image resizing) with variable sizes such asF48×48,F64×64,andF96×96has been shown.In this experiment,we used the Mini-Batch Gradient Descent optimization technique [56] with batch sizes such as 8 and the number of epochs is 500 for reporting the performance.From the Table 4,it has been observed that for CK+,KDEF,and SFEW datasets,the performance of the proposed model increases with increasing the image size in both the CNN architectures and also the performance is slightly better due toCNN2thanCNN1model.So,the proposed model attains the highest performance,95.89%for CK+,78.27% for KDEF,and 35.31% for the SFEW dataset due to theCNN2model and using theCNN1model,the proposed model attains 93.41%for CK+,77.76%for KDEF,and 33.05%for SFEW dataset.
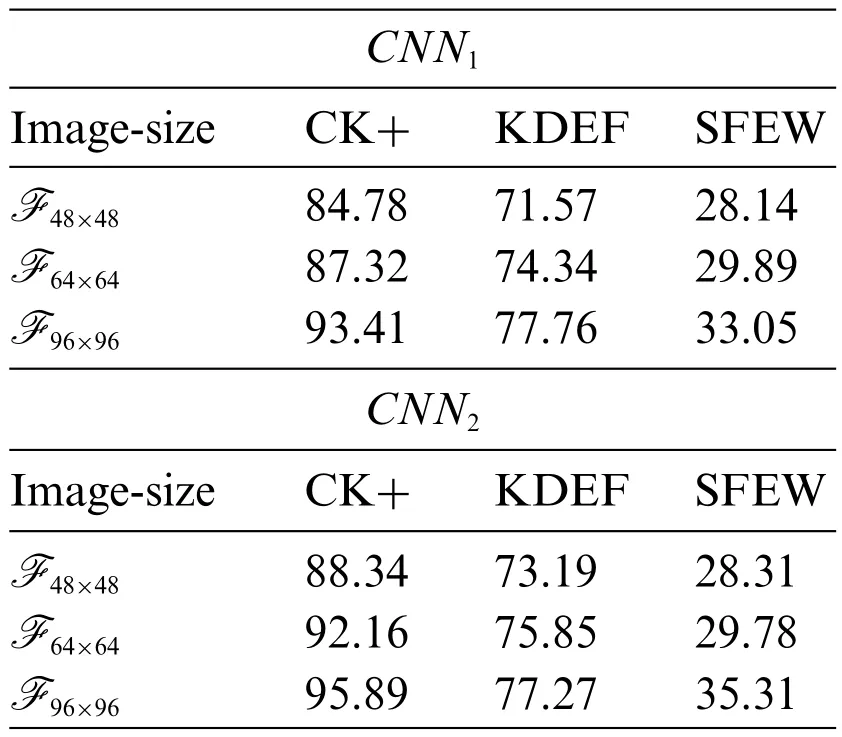
Table 4: Performance due to CNN1 and CNN2 models in terms of accuracy (%) with varying image sizes
• Fine tuning impact:Here,the performance of the proposedCNN1andCNN2architectures are improved by applying the method of fine-tuning to tune the hyper-parameters of the trained model.This fine-tuning method considers the trainedCNN1andCNN2network model,initializes its trained weight,and re-trained the whole network by freezing some of the layers to reduce the computational overhead of training hyper-parameters of the trained model.Hence the impact of fine-tuning for the proposed FERS has been shown in Fig.11.

Figure 11:Impact of fine tuning the hyper-parameters of the trained CNN1 and CNN2 models on the performance of the proposed FERS
• Scores fusion impact:To adapt the effectiveness of both CNN models,the performance of the proposed model has been fused such that the scores due toCNN1andCNN2models have been fused to derive a final decision for the proposed model.Here score level fusion techniques such as sum-rule and product-rule-based methods have been used.Here the sum-rule based score level fusion is defined ass=si+sj,whereas the product-rule based score level fusion is defined ass=si×sj,siandsjbe the scores for a test sample due toCNN1andCNN2models,respectively.The fused performance of the proposed system due toCNN1andCNN2models have been shown in Table 5 concerning each employed facial expression dataset.This table shows that each dataset has attained better performance after fusion,and the product-rule has achieved better performance than the sum-rule-based score level fusion technique.Hence,for CK+,KDEF,and SFEW datasets,the proposed model has obtained 96.89%,82.35%,and 41.73%accuracy,respectively.For these performances,the confusion matrix performance for CK+,KDEF,and SFEW datasets has been shown in Fig.12 for a better understanding of the classification of each test sample in its corresponding class.
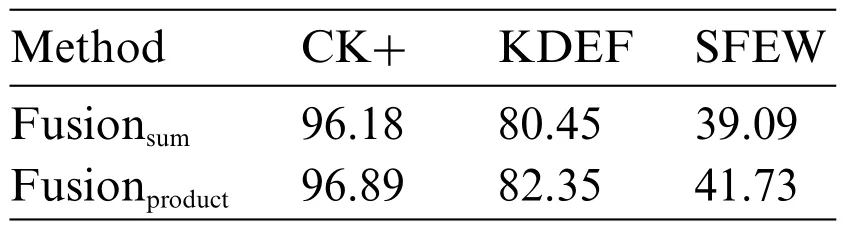
Table 5:Effectiveness of score fusion on the performance of CNN1 and CNN2 in terms of accuracy(%)
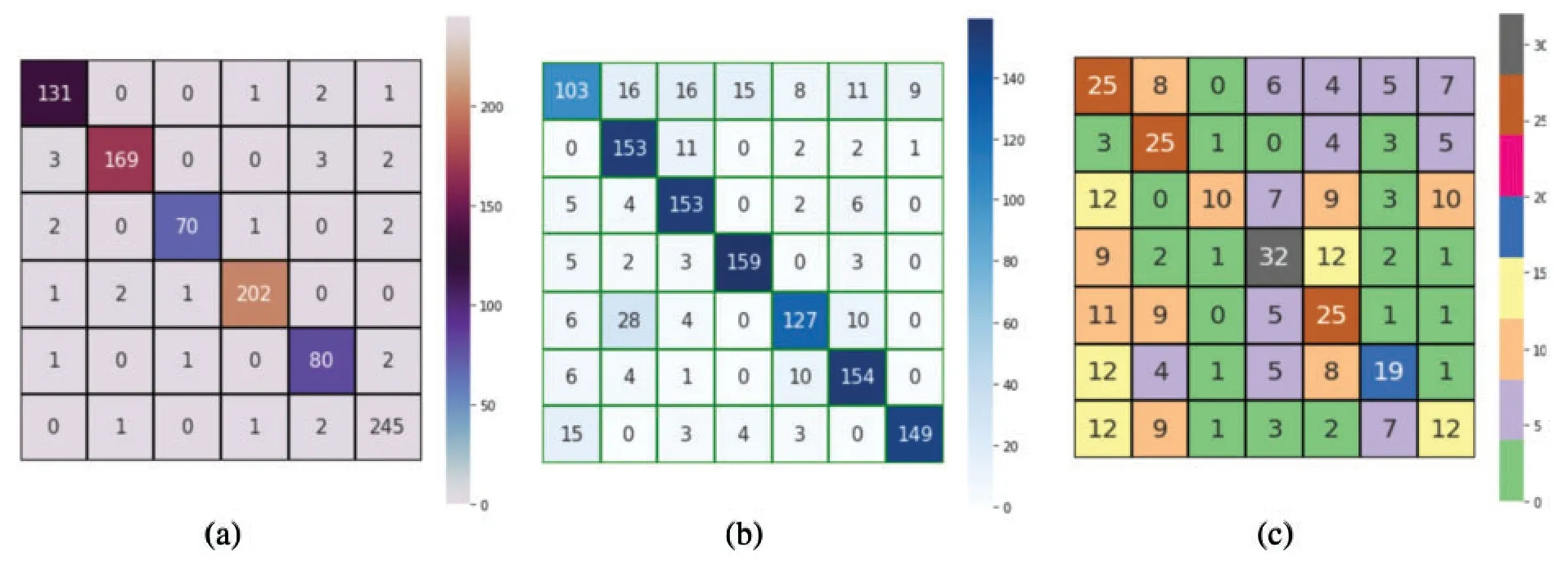
Figure 12:Confusion matrix performance for(a)CK+,(b)KDEF,and(c)SFEW dataset due to the fused performance of CNN1 and CNN2 models
3.2 Comparisons
Here,during comparison with other existing CNN models,the input to these CNN models is the same facial region as used by the proposed system.Also,the same data augmentation techniques have been employed for all the compering methods employed here.Hence,the performance comparisons reported herewith have been made under the same training-testing protocol used by the proposed methodology.Table 6 shows the performance of analysis of Res-Net50 [57],Inception-v3[58],Sun et al.[59],and the proposed model on CK+ dataset.It is found that the proposed model achieves better performance with 96.89% performance.Table 7 shows KDEF dataset analysis,and it is found that the proposed model shows an average 82.35%improvement over the existing models.Table 8 shows the comparative analysis on SFEW dataset.It is found that the proposed model achieves better performance than the existing models by showing an average enhancement of 41.73%over the competitive models.

Table 6: Comparison of performance for CK+dataset(CV is cross validation)

Table 7: Comparison of performance for KDEF dataset(CV is cross validation)
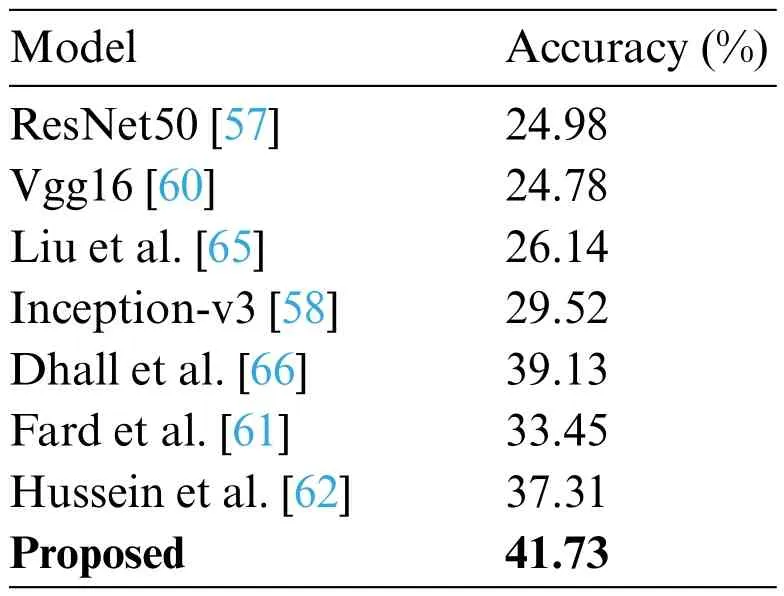
Table 8:Comparison of performance for SFEW dataset(here competing models used same trainingtesting protocols)
Apart from these,the proposed deep fusion model is used to control the music player.Depending upon the human emotions,the music player is controlled.Based upon the userâs emotion,a song is selected from the given class.The proposed model can be better used for disabled persons to change their moods.During the real-time testing,it was found that on a computer with 2.4 GHz,the proposed model can predict 28 frames per second.Therefore,the proposed model can be used for other humancomputer interface-based applications.
4 Conclusion
A facial expression recognition model was proposed under controlled and uncontrolled imaging environments.The images considered here are captured in the unconstrained environment,such as motion blurred,hazy,rotated,pose invariant,moving at a distance,and off-angle.The implementation of the proposed model was divided into three components: (i) image preprocessing,(ii) feature learning with classification,and(iii)performance fusion.The face region was extracted during image preprocessing as this is the region of interest for the proposed model.The extracted face region undergoes feature learning with classification tasks.Here for feature learning with classification task,two convolutional neural networks(CNNs)have been proposed where each CNN was learned with the facial regions of the training samples.In contrast,the learned CNN model was employed to obtain the classification performance using the facial region of testing samples.Finally,the performances obtained from both the CNN models were fused to build the final recognition model.Several factors affecting the CNN performance,such as data augmentation,fine-tuning the hyper-parameters,and multi-resolution with progressive image sizing,were also performed during experimentation.The proposed model was verified on three well-known datasets,i.e.,CK+,KDEF,and SFEW.Comparative analysis revealed that the proposed model outperforms the state-of-the-art models in various performance metrics.Finally,the proposed deep fusion model was utilized to control the music player using the recognized emotions of the user.
Funding Statement: This work was supported by the Researchers Supporting Project (No.RSP-2021/395),King Saud University,Riyadh,Saudi Arabia.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computer Modeling In Engineering&Sciences的其它文章
- Explicit Topology Optimization Design of Stiffened Plate Structures Based on the Moving Morphable Component(MMC)Method
- Towards a Unified Single Analysis Framework Embedded with Multiple Spatial and Time Discretized Methods for Linear Structural Dynamics
- Developments and Applications of Neutrosophic Theory in Civil Engineering Fields:A Review
- Surface Characteristics Measurement Using Computer Vision:A Review
- Recent Progress of Fabrication,Characterization,and Applications of Anodic Aluminum Oxide(AAO)Membrane:A Review
- Challenges and Limitations in Speech Recognition Technology:A Critical Review of Speech Signal Processing Algorithms,Tools and Systems