基于改进SSD 的航拍飞机目标检测方法
2023-02-22喻佳成张灵灵
李 静,喻佳成,张灵灵
(1.西安工业大学 电子信息工程学院,陕西 西安 710021;2.西安工业大学 兵器科学与技术学院,陕西 西安 710021)
1 引言
近年来,随着无人机技术与目标检测技术的快速发展,通过结合两者来获取空间数据已经成为当下的主流趋势。尤其是在军用领域,因无人机具有机动性强、隐蔽性好、成本低的优点,使用无人机来获取军事场所的目标信息已经成为重点研究对象[1-3]。随着计算机算力的提高和卷积神经网络强大的特征提取能力被发掘,很多研究人员将其应用于目标检测[4-6]、目标跟踪[7-8]等领域,以深度学习为基础的目标检测技术已逐步应用在航拍图像的目标检测任务当中[9-11]。
目前,通过深度学习来提取特征并完成检测任务的方法主要有两类:两阶段和单阶段目标检测算法。两阶段目标检测算法采用先确定待检区然后确定目标位置信息与类别的思想,典型代表有R-CNN[12]、Faster R-CNN[13]等。以YOLO[14-16]、SSD[17]算法为代表的单阶段目标检测算法则不去单独地确定待检区,而是直接确定待检目标的位置信息与类别信息。YOLO 算法将待检测图像划分为多个网格,使用每个网格来检测一个目标,这样虽然能够快速地完成检测,但是对于航拍图像中的小目标检测效果不佳。SSD 算法将金字塔特征层级的思想应用在目标检测问题中,使用不同尺寸的特征图检测不同大小的目标,对于小目标的检测效果有所提高,因此许多学者以SSD 算法为基础对其改进来完成航拍图像中的目标检测任务。Jisoo Jeng[18]等人提出的R-SSD 算法使用特征金字塔(Feature Pyramid Networks,FPN)[19]的方法将深层网络提取的特征图与浅层网络提取的特征图进行融合构成了语义、细节信息丰富的特征图用于检测,提高了小目标的检测精度,但是大量的融合操作导致模型参数变大,检测速率下降。Fu 等人[20]提出的DSSD 算法通过反卷积以及跳跃连接的方式来融合深层网络与浅层网络,丰富了浅层网络的语义信息,对航拍图像中的目标检测效果较好,但是模型参数过大,检测速度较慢。Chen 等人[21]提出的改进多尺度特征融合SSD 算法跳跃式地将两层深层网络特征图与浅层网络特征图融合,很好地解决了航拍图像中小目标检测效果不好的问题,但是融合机制过于复杂,导致网络结构大,检测速度大幅下降。
针对现有算法对航拍图像中的小目标检测效果不佳、实时性不足等问题,基于SSD 算法进行改进,引入一种特征融合机制通过逐层地将深层特征图与浅层特征图进行融合,构成具有丰富语义、细节信息的特征图用于检测,并在网络特征图输出处引入混合注意力机制,在不会过多增加计算量的基础上使网络优先将注意力放在有用信息上并抑制复杂背景等无用信息,最后优化默认框参数,进一步提升小目标检测精度。
2 SSD 算法基本原理
SSD 模型是典型的单阶段检测算法,将预测问题转换成列回归问题,在保证检测精度的同时提高了检测速度。采用金字塔特征层级的思想,即在不同尺度的特征层上预测不同大小的物体,使用具有较高分辨率的浅层特征图来预测小物体,分辨率较低的深层特征图来预测较大的物体,相对提高了对小目标的检测精度。SSD 模型由骨干网络和额外卷积层两部分组成,具体模型框架如图1 所示。
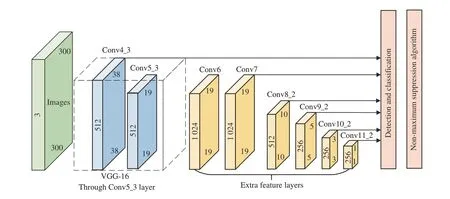
图1 SSD 模型结构Fig.1 Structure of SSD model
SSD 模型以VGG16 作为主干网络,贯穿至VGG16 的Conv5_3 层并将max_pooling5 的步距由2 调整至1。额外卷积层由Conv6~Conv11 组成,并逐层将特征图的尺寸缩小构成金字塔层级,提取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv10_2 作为预测特征图来检测不同大小的目标。SSD 模型在提取到的预测特征图上会生成数量不同的预测框,对于每个预测特征图都会有n×n个中心点并且每个中心点都会生成m个预测框。Conv4_3~Conv11_2 层n和m的取值分别为38,19,10,5,3,1 和4,6,6,6,4,4。最后,通过非极大值抑制算法和设置的置信度阈值消去位置、类别不符合的预测框,输出检测结果。
3 改进的SSD 算法
3.1 改进SSD 算法框架
SSD 模型使用金字塔特征层级的思想,用不同尺度的特征层来检测不同大小的目标。其中浅层特征图负责检测小目标,而在航拍图像中小目标检测效果不好的原因主要有两点,分别是浅层特征图没有具备足够的纹理、位置等细节信息和语义信息匮乏。针对这两点原因,本文设计了一种特征融合机制,首先就浅层特征图的细节信息不够丰富和缺乏语义信息的问题,引入细节信息补充特征层(Details complement feature layer,DCFL)和自深向浅逐层融合的语义信息补充特征层(Semantic complements feature layer,SCFL)来增加Conv4_3 层的细节和纹理信息。然后引入混合注意力机制(Botteleneck-Attention-Module,BAM)来增强特征层对关键信息的提取能力。最后针对遥感图像数据集尺度偏小,对默认框的尺度和数量进行优化。网络结构如图2 所示,FFM(Feature Fusion Module)为特征融合机制中的特征融合模块。
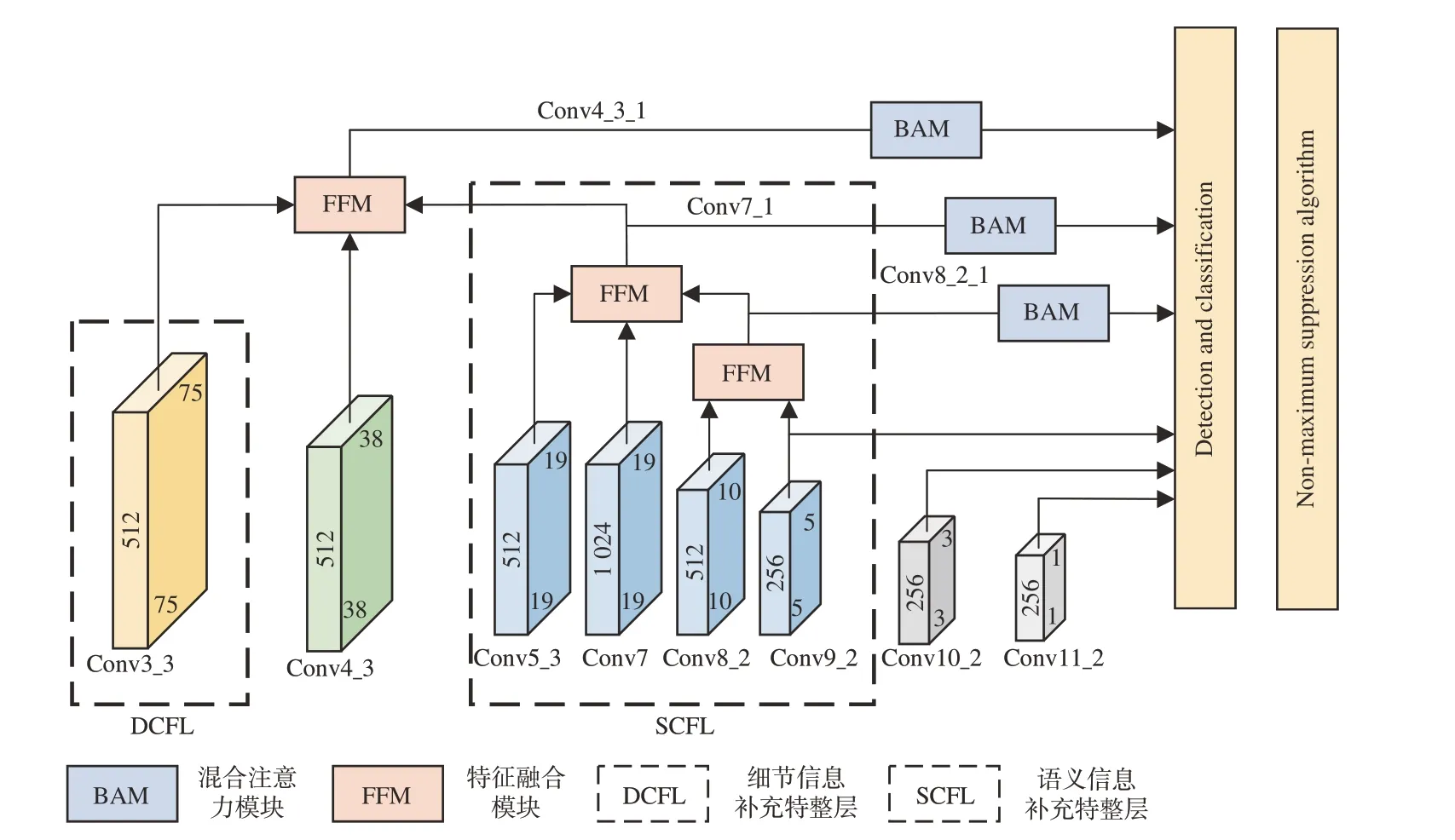
图2 改进SSD 模型结构Fig.2 Structure of improved SSD model
3.2 特征融合机制
在SSD 框架中,对小目标的检测主要由浅层网络中Conv4_3 层输出的特征图完成。但因为细节信息不够丰富以及语义信息匮乏两点原因,导致对航拍图像中的小目标检测效果不佳。因此引入细节信息补充层和语义信息补充层与Conv4_3 层经过特征融合模块(FFM)输出新的Conv4_3_1 层的特征图,用来对小目标进行检测。
对于细节信息补充特征层(DCFL),应当选取尺寸大、感受野小、细节信息丰富的Conv3_3层。而语义信息补充层(SCFL)是由深层特征图通过递归反向路径逐层融合而来。在以往的特征融合过程中,直接将深层的特征图与浅层特征图进行融合来增加浅层特征图中的语义信息,这样忽略了层与层之间的连接关系,导致丢失过多的关键信息。具体的融合过程如式(1)~(3)所示:

式中:cfi(i=1,2,3)为融合后的特征层,ci(i=3,4,5,7,8,9)为融合层,ϕf为特征融合模块。首先选取Conv8_2 和Conv9_2 层作为递归反向路径的起始层。不选取Conv10_2 和Conv11_2 的原因是这两个特征层尺寸过小,所包含信息太少,融合之后对目标定位与分类精度并没有提升,反而使模型的训练与检测速度变慢。将Conv8_2 和Conv9_2经过特征融合模块后的输出结果Conv8_2_1 再与两个相邻的特征层Conv7 和Conv5_3 送入特征融合模块得到最终的语义信息补充特征层。特征融合模块将本文特征融合机制中选取的特征层进行融合,首先对Conv3_3、Conv4_2 和Conv7_1这3 个特征层进行融合,如图3 所示,其具体步骤如下:
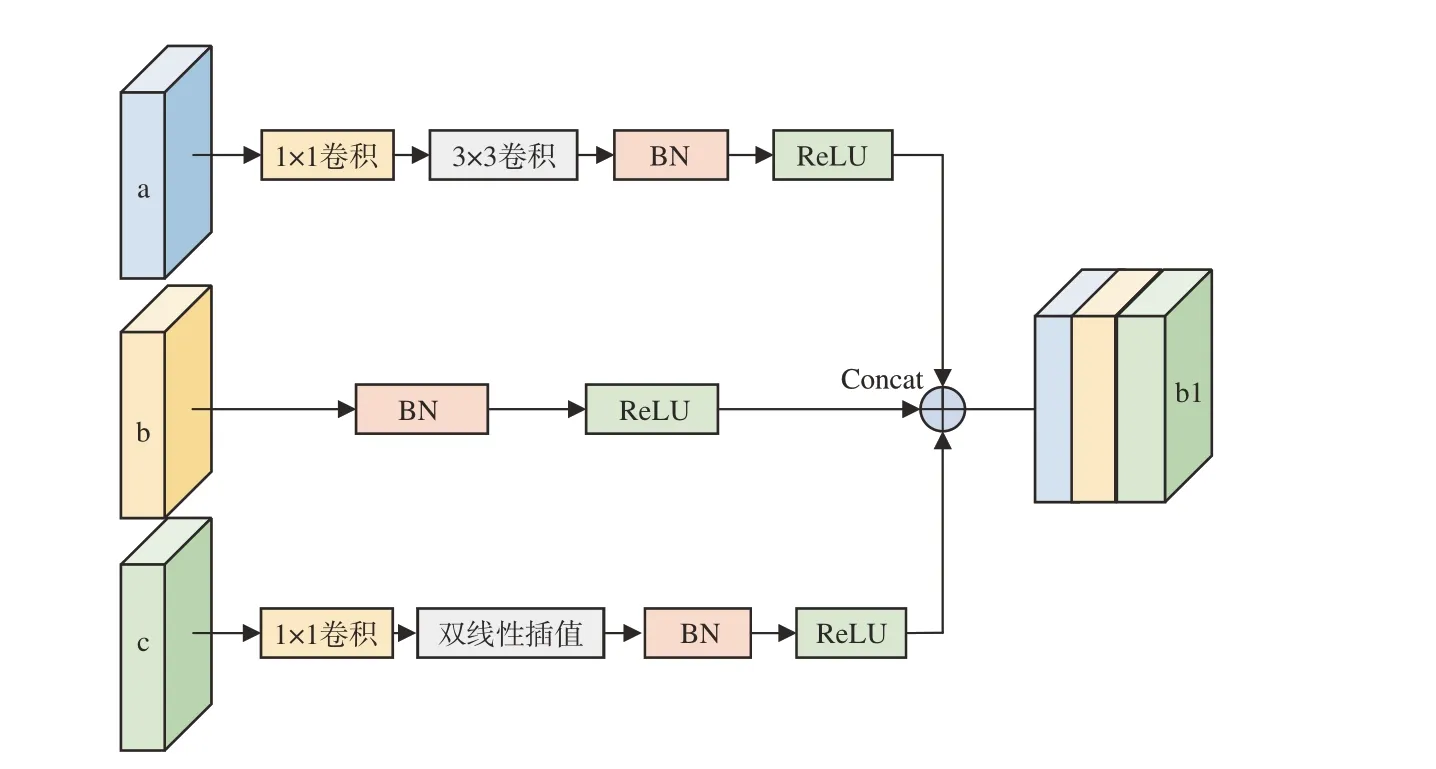
图3 特征融合过程示意图Fig.3 Schematic diagram of the FFM process
使用1×1卷积核对Conv3_1和Conv7_1两个特征层进行通道降维处理,变为原来通道数的1/4,Conv4_3 变为原来通道数的1/2。然后使用双线性插值对Conv7_1 进行上采样处理,使其尺度扩大一倍,与Conv4_3 的尺度保持一致。使用3×3 卷积核对Conv3_3 进行下采样处理,使其尺度缩小一倍,与Conv4_3 保持一致。然后将进行过上、下采样处理后的Conv7_1 和Conv3_1 以及Conv4_3经过批归一化(BN)层和ReLU 激活函数,最后采用concat融合方式让网络去学习融合特征,避免造成信息的损失。融合输出为Conv4_3_1。对于Conv7_1 的融合过程与Conv4_3_1 的融合过程类似。对于Conv8_2 和Conv9_2 两个特征层进行融合,没有了需要下采样的特征层,将Conv8_2和Conv9_2 使用1×1 卷积核,将Conv8_2 通道数降维处理变为原来的1/2,Conv9_2 通道数不变,然后将Conv9_2 进行双线性插值使其尺度变为原尺度的1 倍,与Conv8_2 一致。经过批归一化(BN)层和ReLU 激活函数,最后采用Concat 融合得到融合特征层Conv8_2_1。
为了验证经过特征融合后的Conv4_3_1 层具有更丰富的细节信息与语义信息,将其特征图输出并与原网络的Conv4_3 层的特征图进行对比,如图4 所示。通过原网络的Conv4_3 层输出与融合后的Conv4_3_1 输出对比可以看出,在飞机目标处原网络仅提取到很少的特征,而融合后飞机目标部分的轮廓、细节信息显示更为明显,显然具备更多特征。理论上,融合后的特征层可以预测到更多的目标,精度也会有所提升。

图4 融合前后的特征图对比Fig.4 Feature map comparison before and after fusion
3.3 混合注意力机制
在特征融合机制中,为了获得更多的细节、语义信息,将多个特征层的特征通道进行了叠加,但是并没有反映不同通道之间的重要性和相关性以及没有考虑特征图的空间层面上的重要性,因此引入了一种混合空间与通道的注意力机制(Botteleneck-Attention-Module,BAM)[22]。BAM 在通道注意力机制SE-Net(Squeeze-and-Excitation Networks,SE-Net)[23]的基础上添加了空间压缩生成的空间注意力向量与SE-Net 生成的通道注意力向量进行叠加,得到既有空间注意力又有通道注意力的向量,其具体网络模型的结构图如图5 所示。

图5 BAM 示意图Fig.5 Schematic diagram of the bottleneck attention module
对于构建空间注意力向量,首先将输入的特征图使用1×1 卷积核进行通道压缩,其次使用两个3×3 卷积核来增大感受野,然后再次使用一个1×1 卷积核将通道数变为1,最后经过归一化操作调整空间分支的输出尺度构成空间注意力向量。对于构建通道注意力向量,首先将输入的特征图使用全局平均池化将输入图像的宽、高压缩为1×1,然后利用多层感知机制学习每个通道的估计,最后经过归一化操作得到通道注意力向量。将得到的空间注意力向量与通道注意力向量叠加并且经过Sigmoid 函数得到最终的混合注意力向量,整体过程如式(4)~(6)所示:

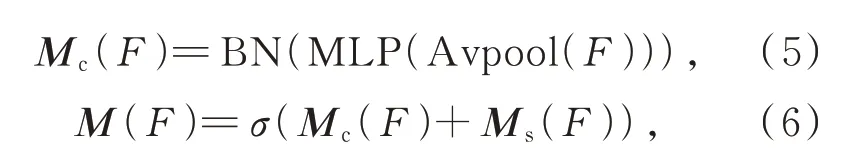
式中F为输入的特征图为不同大小的卷积核,Ms(F)为归一化操作,Ms(F)为空间注意力向量,Avgpool 为全局平均池化,MLP 为多层感知机制,Mc(F)为通道注意力向量,M(F)为混合注意力向量,σ为Sigmoid 函数,BN 为批归一化层。
使用Grad-CAM[24]技术来直观地展示模型中引入混合注意力模块的有效性。热力图颜色区域越深说明该区域对类别识别的影响越大。如图6 所示,在添加通道注意力机制后,模型开始关注右侧的目标。在加入混合注意力机制后,模型对右侧目标的关注度是优于通道注意力机制的。

图6 热力图可视化Fig.6 Visualization of heat maps
3.4 先验框参数优化
SSD 模型用不同尺度的特征图来检测不同大小的目标,因此不同的特征层会产生不同大小的先验框并且先验框的大小符合线性递增的原则:随着特征层尺度的减小,先验框的尺寸增大,具体如式(7)~(9)所示:

式中Sn为6 个特征层的先验框对于原图的比例;Smin和Smax为比例的最大值与最小值,在原SSD框架中取0.2 和0.9;default 为先验框的尺寸。
通过统计数据集中标注框与原图的比例,如图7 所示,可以看出飞机目标的最小尺寸约为22×22,在原SSD 模型中当Smin设置为0.2 时,最浅层特征层先验框的尺寸为30×30,不能覆盖数据集中最小尺寸的飞机目标。因此根据数据集中最小目标的尺寸对先验框进行调整,将Smin的值调整为0.14,根据式(8)可以计算出此时最小的先验框尺寸为21×21,基本上可以覆盖输入图像中的各种形状和大小的目标。尺寸调整前后的先验框尺寸如表1 所示。
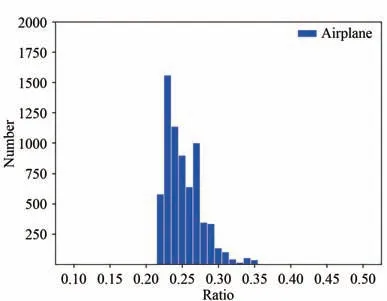
图7 待检测目标真实框与原图比值Fig.7 Size ratio of the real frame in the original image
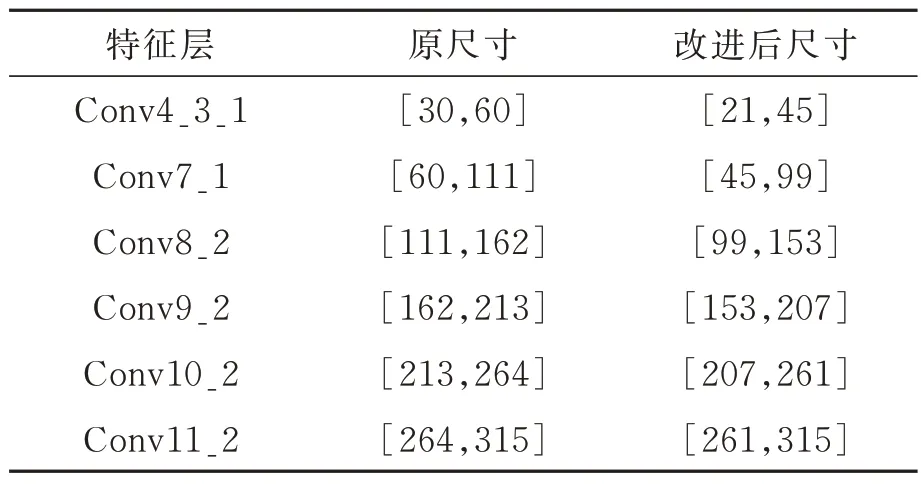
表1 每层特征图上的先验框尺寸Tab.1 Priori boxes and numbers on layer of feature maps
4 实验与结果分析
4.1 数据集与参数设置
本实验在自制的航拍飞机数据集上进行。其中航拍的飞机图片共3 581 张,按照7∶1∶2 的比例划分为训练集、验证集和测试集,其中训练集包含2 506 张图片,验证集包含358 张图片,测试集包含717 张图片。航拍数据集按照Pascal VOC2012 的格式建立,场景中大多数目标均为小目标。实验在Windows 操作系统下进行,其中CPU 为AMD Ryzen5 5600x6-Core Processor,内存为16G,GPU为NVIDIA GeForce RTX 2080Ti,采 用Pytorch作为深度学习框架。初始学习率为0.000 1,动量因子参数为0.9,批处理大小为16,优化算法采用随机梯度下降,衰减系数为0.1,最大迭代次数为120 000 次。
为了提高测量的精度,可在同一放大倍率下对不同的圆直径进行测量并分别计算出每一个像素所代表的长度,然后求平均值作为在该放大倍率下的比例尺。
4.2 实验评价指标
本文采用平均精度(Average Precision,AP)和每秒检测图像的帧数(Frame Per Second,FPS)作为评价指标。其中AP 是在0~1 范围之间由准确率(Precision)和召回率(Recall)绘制的曲线与坐标轴之间的面积。准确率、召回率和精度(AP)的定义如式(10)~(12)所示:

其中:TP 为正样本中的比例,FP 为负样本正例,FN 为负样本中的负例。
4.3 实验结果分析
为了对改进SSD 模型的性能进行评估,在自制的航拍图像数据集进行训练和测试,实验结果如表2 所示。
由表2可知,本文所提的改进SSD 模型与两阶段的目标检测模型Faster R-CNN 相比,精度提高了3.35%,检测速度提高了24.1,说明本文的模型在检测准确率和速度上均优于两阶段的检测算法。与经典的改进SSD 模型DSSD 相比精度分别提高了4.26%,检测速度较DSSD 提高了19.4。与YOLOv3 相比,精度提高了4.03%,检测速度降低了3.1。与YOLOv4 相比精度提高了1.4%,检测速度降低了6.6。与主打检测速度的轻量级网络YOLOv4-tiny 相比精度提高了6.4%,检测速度降低了30.4。实验表明,改进的SSD 模型能够提升对小目标检测的效果,并且也能够满足实时检测的要求。图8 为不同方法在不同场景下航拍飞机图像上的检测结果,其中从上到下依次为小目标密集区域、复杂背景区、多尺度目标区。

表2 各算法在航拍飞机数据集上的检测精度Tab.2 Detection accuracy of each algorithm in aerial aircraft data set
由图8 可以看出,在小目标密集区域,对于图最左侧的几个极小的飞机目标,改进的SSD 模型可以全部检测到,YOLOv4 模型漏检了一个,其他的模型都有较多的目标没有检测到。在复杂背景区域,最右侧的目标较小且机身颜色与地面颜色十分相似,改进的SSD 模型可以全部检测出,并且在图的左侧没有出现误检的情况;YO‐LOv4 模型对于右侧的小目标漏检了一个并且左侧出现了一个误检的情况;YOLOv4-tiny 模型对于右侧与背景颜色相近的目标均没有检测出并且在左侧存在多个误检的情况;YOLOv3 模型相比于YOLOv4-tiny 模型能够检测到更多的目标,但是也有多个目标未能检测到且存在误检的情况;其他模型也存在漏检、误检的情况。在多尺度目标区域可以看出,所有模型对于较大尺度的模型都检测到,但对于图中最上方和右侧以及左侧靠下位置的小目标,只有改进的SSD 模型可以全部检测出,YOLOv4 模型没有检测到左侧的小目标,YOLOv4-tiny 有较多小目标,没有检测到,YOLOv3 模型除没有检测到的小目标还出现了一个误检的目标。通过在不同场景下与不同方法的对比可以得出,改进的SSD 模型相比于其他模型能够更好地检测出小目标,并且对于一些复杂场景下的目标也可以做到正确识别。

图8 不同方法在不同场景下的检测结果Fig.8 Detection results of different algorithms in different scenarios
图9 为在存在外界干扰的特殊环境时的改进SSD 模型的检测结果,其中图9(a)为飞机与周围环境颜色相近,图9(b)为航拍时受到云的遮挡,图9(c)为飞机隐蔽在树林中。可以看出改进的SSD 模型在3 种特殊的环境中均可以识别到目标,验证了改进的SSD 模型在受到一定环境因素干扰时仍然有着较好的检测结果。

图9 特殊环境下的检测结果Fig.9 Detection results in special environments
4.4 消融实验
为了验证改进的SSD 模型中各个模块的有效性,在航拍的飞机数据集上使用具有不同模块的模型进行消融实验,迭代次数设置为120 000 次。包含的模块有是否使用特征融合机制、是否使用混合注意力机制、是否对先验框进行优化几项区别。所有实验结果记录在表3 中,其中使用模块时在表格中用对勾号表示,不使用时则表格的这一栏为空。
由表3可知,在SSD 原模型的基础上添加了特征融合机制后,召回率和精度分别提高了13.1%和3.5%,代表检测到的小目标增多,整体的检测性能得到了提升,证明了将深层语义信息和浅层细节信息融合的有效性。准确率和帧率分别下降了0.4%和6.9 FPS,是因为检测到的小目标增多,但是存在很小一部分的误检情况以及网络增大,导致检测速度下降。在添加混合注意力模块(BAM)后,召回率和精度分别提升了8.5%和2.6%,证明了使用混合注意力机制可以使网络关注有目标的区域来提升检测效果。在优化先验框参数后,召回率和精度分别提升了4.6%和1.6%,证明在对先验框参数进行优化后可以改变感受野的大小,使其与目标大小更匹配,提高对小目标的检测效果。在表3 最后一行可以看出,在将3 个模块均添加到SSD 原模型上后,召回率提高了39.8%,精度提高了7.5%,证明了该算法的有效性,对小目标的检测有着较大的提升。
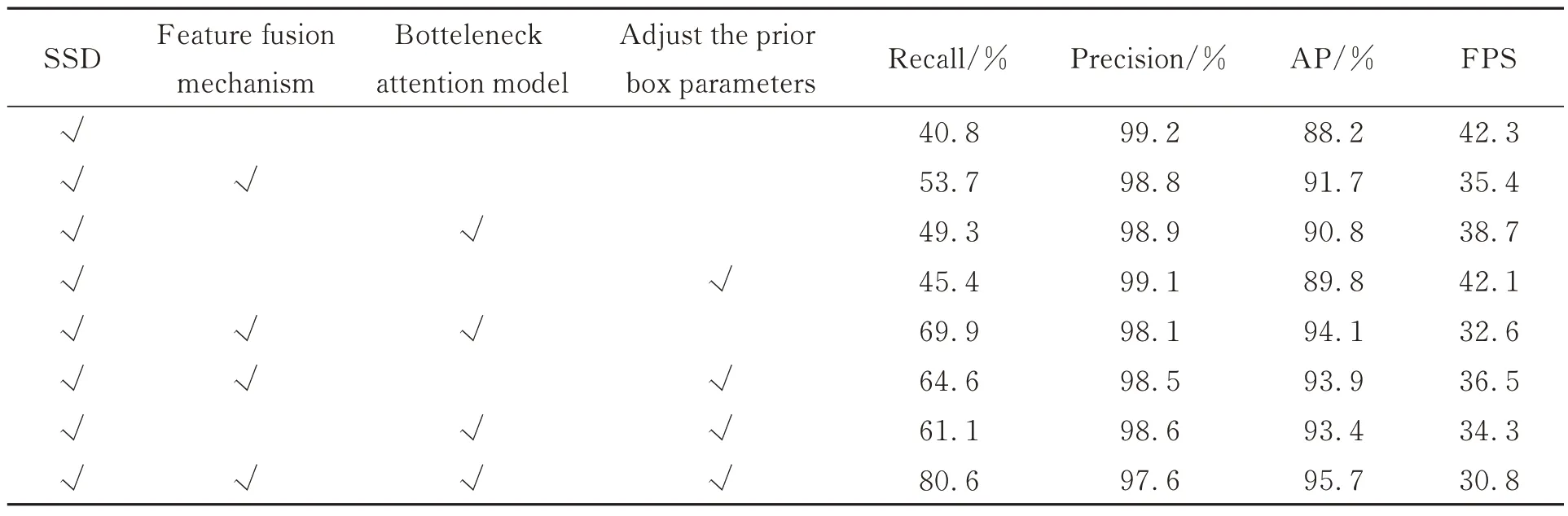
表3 各独立模块对航拍目标的检测效果影响Tab.3 Influence of each independent module on aerial target detection
5 结论
为解决在航拍图像中对于小目标检测效果不佳的问题,通过引入特征融合机制、添加注意力机制和优化先验框等措施,在SSD 算法的基础上提出了一种改进的航拍图像SSD 检测算法。实验结果表明,改进SSD 模型的检测结果优于原SSD 模型,精度由原来的88.2%提升到95.7%且对不同场景下的航拍飞机小目标均有比较好的检测结果,充分证明了方法的有效性。对比其他几种经典的目标检测算法,改进后模型在航拍目标检测任务中具有更高的综合性能。
