作物害虫图像智能识别方法
2023-02-21李雨晴陈燕红李永可肖天赐李清源
李雨晴,陈燕红,李永可,肖天赐,李清源
(新疆农业大学计算机与信息工程学院,乌鲁木齐 830052)
0 引 言
【研究意义】农作物虫害是影响作物生产的主要因素之一[1]。由于害虫结构复杂,同种害虫在生命周期的不同阶段的特征差异很大,且不同种类的害虫之间可能具有高度相似的特征,因此对农作物害虫实现精准的识别与分类任务艰巨[2]。为防止大范围农作物虫害的发生,对农作物害虫进行早期的识别与分类十分必要。作物害虫种类的精准识别与分类对于虫害防控来说至关重要。需要采用一种有效的方法,实现农作物害虫种类的快速精准识别。【前人研究进展】传统的害虫识别方法主要为人工鉴定,不仅耗时耗力、时效性差且受人为因素干扰大[3]。利用机器学习方法对害虫识别与分类,需要利用人工设计特征,能否取得较高的准确率主要取决于特征的提取。张永玲等[4]通过提取颜色和HOG融合特征和稀疏表示,采用支持向量机实现水稻昆虫图像中测报害虫的自动识别;马鹏鹏[5]通过融合图像特征和特征选择,利用支持向量机实现水稻灯诱害虫图像的识别,准确率高达91.4%。仅利用人工选取特征缺乏对高级语义信息表示的能力,其可泛化性和准确率难以满足实际应用的要求。深度学习作为机器学习的一个分支,通过使用多层的卷积神经网络,以端到端的方式自动学习并提取特征,具有较强的表征能力[6]。Huang等[7]采用贝叶斯优化算法优化参数结合迁移学习方法,对8类番茄害虫识别准确率达97.12%;Reza等[8]对Inception-v3网络使用迁移学习和数据增强策略进行训练实现了害虫的识别;华月珊等[9]通过优化ResNet网络构建了面向小蠢科害虫的深度感知模型。【本研究切入点】尽管深度学习在害虫识别领域已取得较大的进展,但多数研究仅针对一种农作物的害虫进行识别,并常使用单一模型不断调参,增加了时间成本。需提高害虫识别的准确性和泛化性。【拟解决的关键问题】采用迁移学习与集成学习结合的农作物害虫识别算法。将在大规模数据集ImageNet上预训练的深层神经网络模型迁移到害虫识别任务中,选择性能较好的EfficientNet、Vision Transformer、Swin Transformer和ConvNeXt模型,采用基于投票机制的集成策略完成对害虫的识别。
1 材料与方法
1.1 材 料
1.1.1 数据集
以大规模、具有挑战性且种类最多的公开害虫图像数据集IP102[10]作为材料。该数据集具有层次分类系统,并且呈现一个自然的长尾分布,其包含的图像主要来源于互联网上的图像以及视频片段截取,故图像大小、像素、拍摄时间及要求并不统一,最终由农业专家们分别进行独立标注与协同标注。该数据集共包括75 222张害虫图像,分属102个害虫类别,涵盖大田作物与经济作物两大害虫体系,包括水稻、小麦、苜蓿、甜菜、玉米、柑橘、芒果、和葡萄共8种作物。训练集、验证集和测试集分别包含45 095张、7 508张和22 619张害虫图像。
IP102数据集的每类害虫包含了真实环境中害虫生命周期的不同生长状态。在某一生命周期不同害虫的特征非常相似,同一害虫在不同生命周期的特征又差异极大,两类害虫的生命周期都由卵、幼虫、蛹与成虫构成,在不同的生命周期特征存在很大的差异,但在同一生命周期中虽为不同种类,却具有极其相似的特征。不同类别的同科害虫也具有极其相似的特征。图1

图1 IP102数据集个别类别示例Fig.1 Examples of IP102 datasets individual categories
1.1.2 迁移学习微调
采用在计算机视觉领域被广泛应用的迁移学习(Transfer Learning)方法进行训练。迁移学习通过从源数据集上学习到的浅层网络参数迁移到目标数据集的网络中。虽然源数据集的图像与目标数据集的图像无关,但是目标数据集上的网络也能够抽取到较通用的底层图像特征,例如边缘、角点、纹理和物体组成等,使得网络能够快速学习新数据集的高维特征[11]。微调(Fine-Tuning)是实现迁移学习的常用技术,对于目标数据集与源数据集的相似度较高时,可在目标任务上复用预训练模型的部分组件,并对其参数进行微调。
以IP102数据集为基础,借助迁移学习思想和微调方法,利用在ImageNet大规模数据集上预训练过的模型。通过复制预训练模型上除了输出层外的所有模型设计以及参数,并微调模型的输出层参数,以使网络能在短时间训练和学习中获得更好的性能,从而在加快模型收敛的同时提升识别准确率。
首先将IP102数据集中的图像进行预处理,分别输入EfficientNet-B3、ShuffleNet、MobileNet、ConvNeXt、Vision Transformer和Swin Transformer等6个预训练模型,将各模型的除分类层外的所有参数复制,并对模型分类层参数进行微调,以适应IP102数据集的害虫图像数据。将EfficientNet-B3记为EN,ShuffleNet记为SN,MobileNet记为MN,ConvNeXt 记为CN,Vision Transformer记为VT,Swin Transformer记为ST。
1.1.3 CNN和Transformer
卷积神经网络(Convolutional Neural Network, CNN)是含有卷积层的神经网络,通过在卷积层中重复使用卷积核来有效的表征局部空间信息,利用池化层通过降低数据体空间尺寸从而减少模型参数,全连接层作为分类器能够把输入从特征空间映射到类标签[12]。近年来,Transformer在大规模图像分类任务中展现出同等或更加优越的性能,是一种基于自注意力机制的神经网络结构[13]。Transformer具备强大的长程建模能力,其主要模块Multi-Head Self-Attention能同时感知到输入序列的全局信息。
分别对基于CNN和Transformer体系结构的EfficientNet、ShuffleNet、MobileNet、ConvNeXt、Vision Transformer和Swin Transformer等6种深层神经网络模型进行单独训练,对IP102害虫数据集进行识别,并在测试阶段,将表现较好的模型预测结果进行集成。
1.1.4 EfficientNet
EfficientNet是一种轻量化网络,通过利用复合系数统一缩放模型的网络深度、网络宽度和输入图像分辨率三个维度,获取对特定需求的最优网络参数,实现兼顾效率和准确率的优化[14]。其内部通过多个移动翻转瓶颈卷积核(Mobile Inverted Bottleneck Convlution, MBConv)堆叠实现,在每个MBConv中使用类似残差连接的结构,并在短路连接部分利用SE(Squeeze-and-Excitation)模块进行优化。
1.1.5 Vision Transformer
ViT(Vision Transformer, ViT)是将Transformer应用在图像识别的模型,是第一个不包含卷积的纯Transformer视觉骨干网络[15]。ViT将输入图像分为多个正方形词元(token),默认词元大小为16像素。通过Embedding层将每个词元转化为固定长度的向量,在输入序列中添加class token以及位置编码作为Transformer Encoder的输入,再将Transformer Encoder模块重复堆叠L次,最后添加用于分类的MLP Head层结构。采用分单元处理像素并对每个单元应用自注意力机制的方式,使得ViT具备快速处理大量训练数据集的能力。
1.1.6 Swin Transformer
有研究提出了一种通用Transformer骨干网络,称为Swin Transformer(SwinT),是采用移动窗格的分层视觉Transformer[16]。SwinT采用类似CNN的层次化构建方法,在线性计算复杂度的基础上构造了分层的特征映射。并引入局部性思想,通过基于窗口的自注意力方法(Windows Multi-Head Self-Attention, W-MSA),将自注意力计算限制在非重叠的窗口区域以减少计算量。通过基于移动窗口的自注意力方法(Shifted Windows Multi-Head Self-Attention, SW-MSA),在计算等价的前提下,引入滑动窗口操作和Mask机制实现了相邻窗口间的信息传递。每个stage都交替采用W-MSA和SW-MSA模块,有效增强模型的表达能力。
1.1.7 ConvNeXt
ConvNeXt是由Facebook AI Research和UC Berkeley共同提出的一个纯卷积神经网络[17]。ConvNeXt首先使用训练ViT的策略训练原始ResNet50模型,再借鉴SwinT模型的设计,使用现有的结构和方法,依次从5个角度进行递进优化:(1)各阶段的计算量和图像下采样方法。(2)参照ResNeXt分组卷积思想,采用更激进的深度可分离卷积。(3)使用MobileNetV2中类似Transformer Block的逆瓶颈层结构。(4)增大卷积核尺寸。(5)激活函数、Normalization等微观设计。
1.1.8 集成学习
集成学习通过训练多个基本分类器,以串联或并联的方式组合在一起,再采用某种结合策略完成学习任务,以达到减小方差、偏差和改进预测的效果[18]。集成学习的主要问题是结合策略的选择,比较常用的结合策略有平均法、投票法和学习法。平均法适用于数值类的回归预测问题,投票法和学习法常用于分类任务,采用投票法作为结合策略。
首先在害虫数据集上对模型进行迁移学习训练并微调,选择分类性能较好的4个模型集成。分别对测试集进行预测,将各模型的输出结果并联,再采用基于投票机制的结合策略完成预测。图2
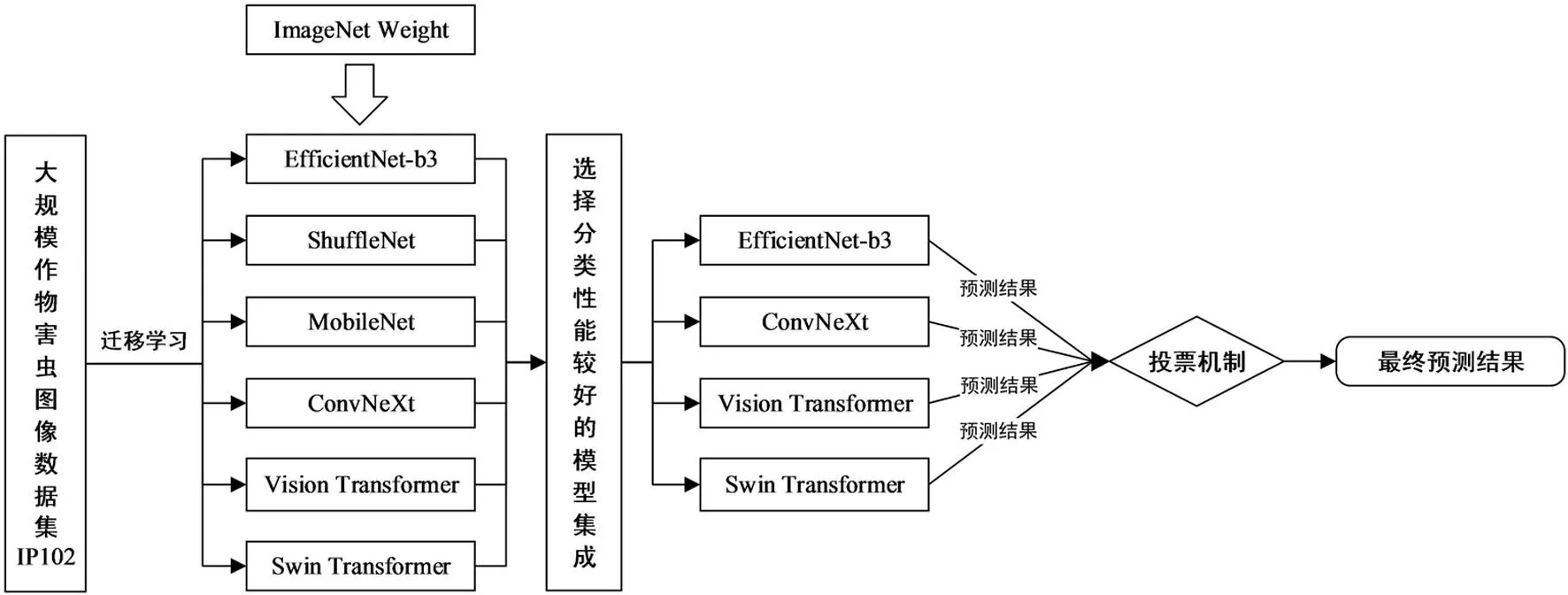
图2 集成学习结合策略Fig.2 Combining strategies for ensemble learning
1.1.9 投票机制
投票法(Voting)是集成学习识别任务中常用的结合策略,也是一种遵循少数服从多数原则的方法。包括绝对多数投票法、相对多数投票法和加权投票法。给定一个学习任务,构建基于投票机制的集成模型F(xi),假定集成包含M个基分类器{f1,f2, …,fM},将M个基分类器对害虫图像样本xi的预测结果{f1(xi),f2(xi),…,fM(xi)}进行线性组合。
(1)相对多数投票法
相对多数投票法通过选择预测结果中票数最高的分类类别(也称为硬投票)。若同时有多个类别获得最高票,按基分类器升序的次序进行选择。
(2)加权投票法
由于基分类器的性能各不相同,加权投票法可以通过人为主观设置或者根据模型评估指标来设置基分类器的权重,对基分类器加权之后再采用相对多数投票法的机制进行投票。
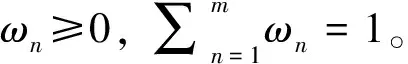
1.2 方 法
1.2.1 数据预处理
IP102数据集主要来源于互联网,各类害虫数据的样本单一且分布不均。首先将训练样本图像随机裁剪为不同大小和宽高比,以50%的概率进行随机水平翻转,验证集与测试集不做处理。之后,对所有图像数据进行缩放操作,分别按224×224和299×299像素缩放。
1.2.2 设置及评价指标
将Python作为编程语言,采用Pytorch深度学习框架构建害虫识别模型。并基于Kaggle平台,采用NVIDIA型号为Tesla P100-PCIE-16GB的GPU进行训练,内存为13G。
对6种深层神经网络模型采取不同的迁移学习微调策略进行改进和再训练。通过试错的方法确定各模型的冻结层数、权重衰减系数和学习率等超参数的不同组合。损失函数选择交叉熵损失函数,并采用AdamW优化器对损失函数优化。初始学习率设置在0.01~0.000 2,各模型的批处理大小均设为64。迭代次数设为20次,若模型在第20次还未完全收敛,就将迭代次数设为30次。
选择图像识别模型中最常用的准确率(Accuracy)来评价模型的表现。准确率为所有类别整体性能的平均。
式中,Ic是正确预测害虫类别的样本量,Iall表示害虫测试集的样本总量。
选择F1值作为综合评价指标。F1值是精确率(Precision)和召回率(Recall)的调和平均,F1值越大模型质量越高。
式中,TP、FP和FN分别表示分类正确的正样本、分类正确的负样本和分类错误的负样本。
2 结果与分析
2.1 各模型在IP102数据集上的迁移学习对比
研究表明,各模型在验证集上的平均准确率为69.99%。通过比较各模型在验证集上的性能,EN、CN、VT和ST模型在验证集上的准确率高于平均值。其中,CN模型的验证准确率高达74.91%。在集成学习时,可优先考虑使用CN模型与其它模型进行组合。4个模型的训练与验证准确率曲线显示,训练和验证的准确率能较快的稳定上升,各模型迁移学习的有效性。表1,图3
投票法要求各模型之间的效果不能有太大差别,筛选出验证集准确率高于平均准确率的EN、CN、VT和ST模型进行集成。表2,表3
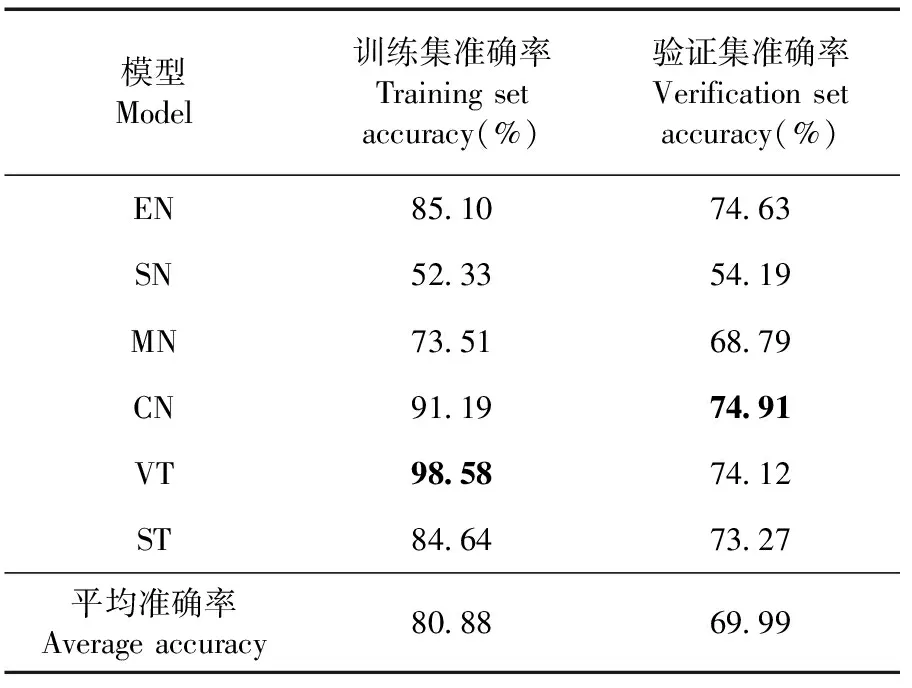
表1 各模型在IP102数据集上的迁移学习对比

表2 单模型在测试集上变化
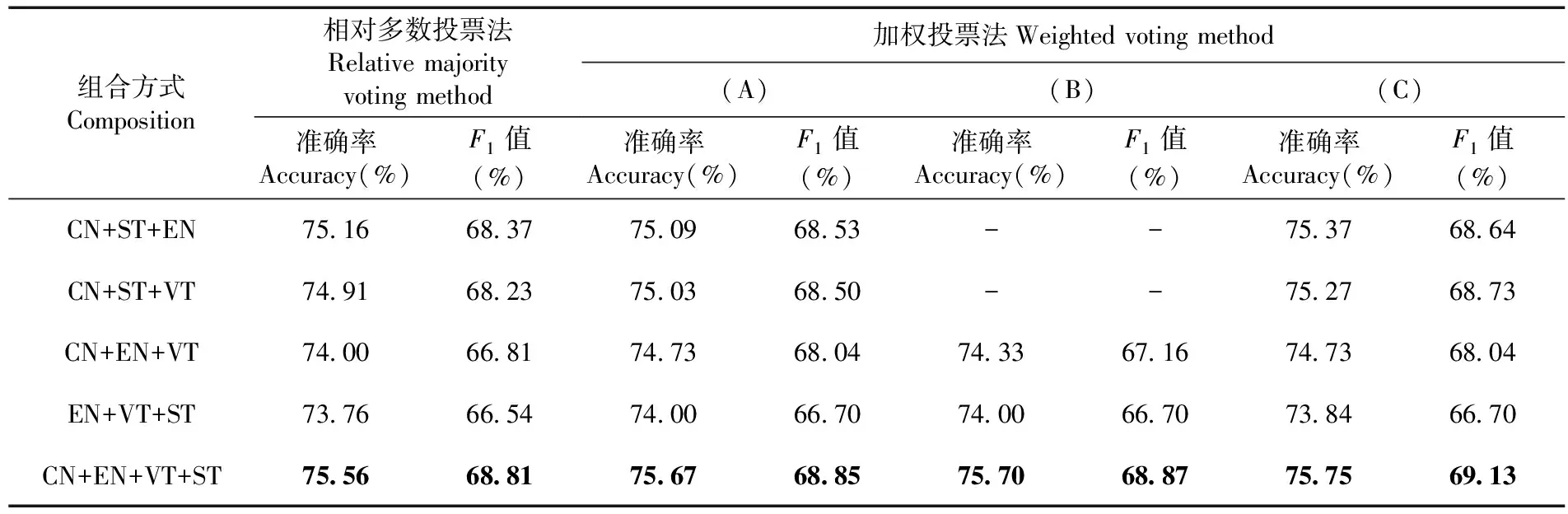
表3 多模型集成在测试集上的变化
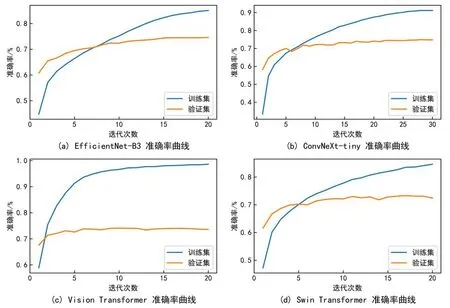
图3 4个模型的准确率Fig.3 Accuracy curves of the 4 models
2.2 各网络模型结果对比
研究表明,CN模型在测试集上单独使用时提供了比其它网络更好的性能,准确率达到了74.41%,F1值为67.84%。相比其它组合方式,采用CN+EN+VT+ST的组合拥有更高的准确率和F1值。该组合方式在采用相对多数投票法进行结合时,比性能最好的单模型在准确率上提高了1.15%。当权重设置为(C)时,较相对多数投票法在准确率上提高了0.19%。表3
加权投票法结合策略在提升模型识别准确率的基础上,能使模型具备更好的稳定性。图4

图4 加权投票最优组合与各模型预测结果输出比较Fig.4 The optimal combination of weighted voting and the output of prediction results of each model
采用加权投票法将准确率提升了2.29%。采用CN+EN+VT+ST的组合,并设权重为(C)为最优组合方式,使得准确率达到75.75%,能够为害虫识别模型带来一定的增益,且具有较好的稳定性和泛化能力。表4
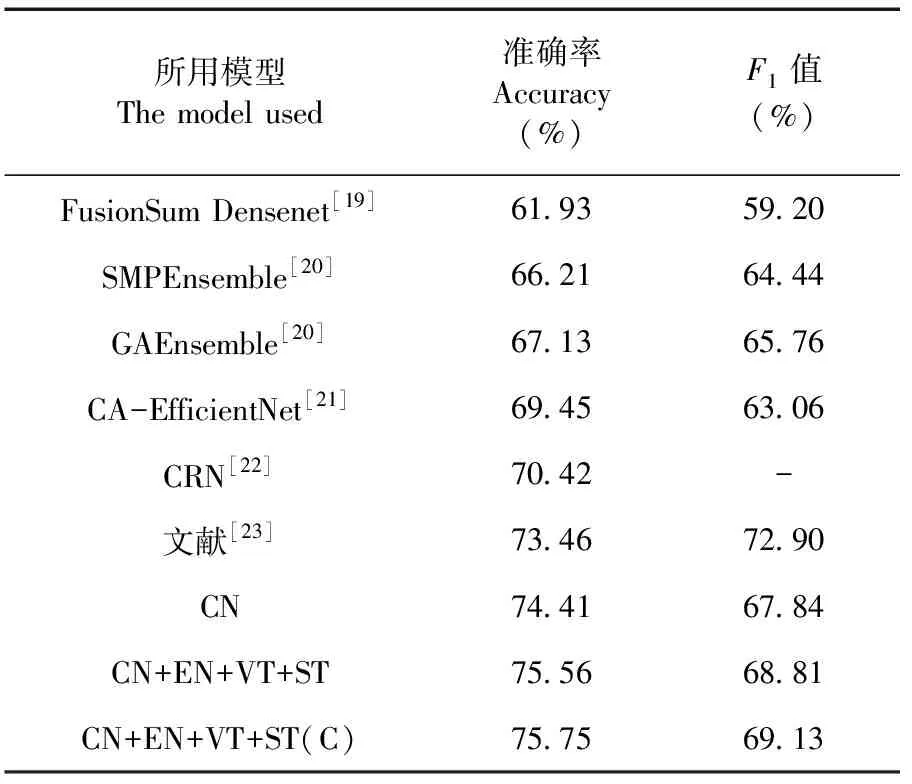
表4 各网络模型的实验结果对比
3 讨 论
3.1研究优先选用的CN模型取得了最高的识别准确率。相比同样采用多模型集成的方法,且准确率最高的文献[23]中所用模型,共进行26组实验,最终通过使用单模型迁移学习训练与集成学习方法达到有效提高模型识别准确率的效果,确定组合4个深层神经网络模型与加权投票结合策略来完成害虫识别任务,其识别准确率均优于单一网络模型。对比Ayan等基于遗传算法的害虫分类方法研究方法的有效性,研究算法的最优集成策略在IP102数据集上识别准确率为75.75%,高于利用遗传算法优化加权集成权重的害虫识别准确率67.13%。方法具有较高识别准确率,且使用数据增强与集成方法使得模型具备较强的泛化能力及稳定性,基本满足对多种作物害虫的精准识别。
3.2但该方法仍存在一些不足,一是由于IP102数据集存在图像类别分布不均衡的长尾分布特征,以及类内差异大、类间差异小的生物多样性特性。虽使用数据增强对样本进行扩充,但仍对害虫图像的识别准确率造成影响;二是集成学习方法虽然提高了模型的分类准确率,但会导致资源消耗过多,计算量增加等问题。基于满足复杂背景下作物害虫的精准识别的要求,下一步研究需要改进模型损失函数或改善数据集的长尾分布,解决模型参数量大且不易于部署的问题,以进一步广泛应用部署到移动端。
4 结 论
组合EfficientNet-B3、ConvNeXt、Vision Transformer和Swin Transformer模型采用加权投票策略集成,其识别准确率高达75.75%。在有限的数据集内对害虫图像的识别准确率进一步的提升,迁移学习结合多模型集成有助于提高模型的害虫识别和分类性能,确定的加权投票策略使模型具有更好的稳定性,数据增强、迁移学习微调技术与多个分类器集成也有效提升了模型泛化能力。
