基于改进子任务门控网络的非侵入居民负荷分解
2023-02-19郭艳霞徐正一
郭艳霞,徐正一,琚 赟
(华北电力大学,北京 102200)
0 引言
非侵入式负荷监测技术(non-intrusive load monitoring,NILM)指通过在用户进户总线处设置传感器,获取家用电器的聚合信息,然后计算得到目标电器的负荷电量以及负荷模式,有利于用户合理规划资源,节约用电,同时帮助电力公司规划电源建设,优化能源结构[1—3]。
NILM最早的方法是基于组合优化的解聚技术,采用诸如进化算法、线性和非线性整数规划等方法进行非侵入负荷分解[4—6]。但是,组合优化方法在任一时刻均独立执行功率分解,不考虑负荷随时间的变化。这些算法对噪音非常敏感,只对安装少量电器的用户分解准确。因此,此类方法不适合应用于现实生活场景。
随着研究的深入,机器学习被证明是解决NILM问题的关键技术,例如K-近邻、支持向量机、决策树等分类器[7—8]。文献[9]为了减少模型计算学习的时间,提高分类性能,提出了一种改进的K-最近邻算法,提高了对于不同类别电器之间的辨别能力。但是,机器学习方法适用于浅层网络和小批量数据,随着电器设备数量和类别的增加,这些方法会遇到可扩展性问题,阻碍模型的性能。
2015 年开始,深度学习模型被应用到NILM 领域中。文献[10]首次基于序列到序列和神经网络来建模,利用滑动窗口解决功率序列数据训练问题,尝试使用递归神经网络[11]和去噪自动编码器[12]在输入序列和输出序列之间进行映射,取得了先进的成果。此后,很多学者基于序列到序列进行改进[13—14]。文献[15]提出了一种基于互感器双向编码器表示和改进目标函数的结构,性能优于其他序列到序列模型。然而,当输入和输出序列的长度变长时,应用序列到序列学习使训练过程难以收敛。针对此难题,文献[16]提出了序列到点模型,在输入序列和输出序列中点之间进行映射,解决了输出信号的每个元素被预测多次,从而平滑边缘的问题。在此基础上,众多研究进行了网络结构的优化[17—19]。文献[20]利用时域卷积网络训练负荷分解模型,并用激活函数Gelu 代替传统的激活函数Relu,有效提高了分解精度。但是,序列到点方法的每个正向过程只产生一个输出信号,因此在推断期间引入了太多的计算量。文献[21]权衡了序列到序列和序列到点两种方法的利弊,提出序列到子序列的方法。此外,目前非侵入负荷分解模型均只利用负荷数据的时间序列信息,将NILM问题定义为回归任务。文献[22]为了将时间序列功率信息和开∕关状态信息进行结合,基于多任务学习的思想,提出了子任务门控网络(subtask gated networks,SGN),同时进行回归任务和分类任务,有效提高分解效率。但是这项研究中的回归和分类网络均基于序列到序列方法,处理长时间序列数据时模型收敛困难。
针对以上问题,文中提出了基于序列到子序列和SGN的非侵入负荷分解模型,并尝试在SGN的两个分支网络中添加空间注意力和通道注意力模块。本文主要研究内容如下:
(1)采用序列到子序列方法构建网络模型,实现电源主序列到目标电器子序列中间较短部分的映射,减小模型收敛的困难度和推理周期的计算量。
(2)基于多任务学习的思想,构建回归子网络和分类子网络,利用目标电器开∕关状态分类任务降低功率分解回归任务的误差,提高功率分解精度。
(3)在回归子网络和分类子网络中添加通道注意力机制和空间注意力机制,混合注意力机制考虑到卷积层输出对各通道的依赖性,选择性地增强信息量最大的特征,减少特征学习过程中其他电器的噪声干扰。
1 非侵入负荷分解模型
1.1 非侵入负荷分解概念
非侵入负荷分解指在家庭电力入口处安装传感装置采集总负荷数据,然后进行分析,得到各用电设备的用电量以及用电模式。
文中的分解信号为采集到的功率数据。假设Y(t)为t时刻某一家庭的主电源读数,Xi(t)为t时刻设备i的电源读数,则可表示如下

式中:T为采集功率数据的时间段;m为家庭中被观测电器的总个数;ε为当平均值为0、方差为σ2时的高斯噪声因子,即为家庭中未被观测到的电器设备的干扰读数。非侵入负荷分解的任务则是根据Y(t)得到Xi(t)。
1.2 序列到子序列方法
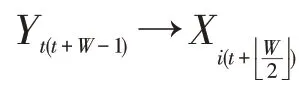
1.3 通道注意力与空间注意力
将文献[23]提出的卷积块注意模块应用到NILM任务中,可提高模型的特征表达能力。若给定的输入特征图为F,卷积块注意模块首先通过式(3)得到维度为1的通道注意图Mc,然后通过式(4)得到二维空间注意图Ms,两者表示如下

式中:⊗为两个特征映射逐元素相乘;F′为通道注意特征图与输入特征图相乘得到的特征映射;F″为经过空间注意模块调整得到的最终特征映射。
1.3.1 通道注意力
普通的卷积层没有考虑每个通道之间的依赖程度,每一个卷积层的卷积核可以视为一个特征通道。通道注意力模块首先同时进行最大池化和均值池化,得到平均池特征和最大池特征,然后分别由多层感知器(multi-layer perceptron,MLP)和一个隐藏层组成的共享网络计算两个特征,输出结果直接求和,最终使用sigmoid函数获得通道注意特征图Mc∈RC×1×1。结构图如图1所示,其过程表达如下
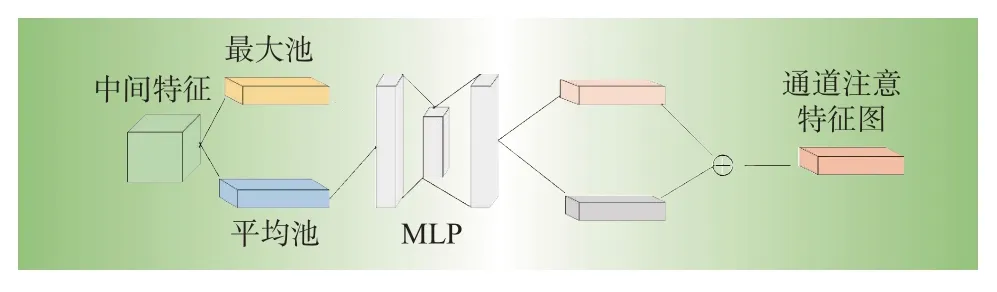
图1 通道注意力模块Fig.1 Channel attention module
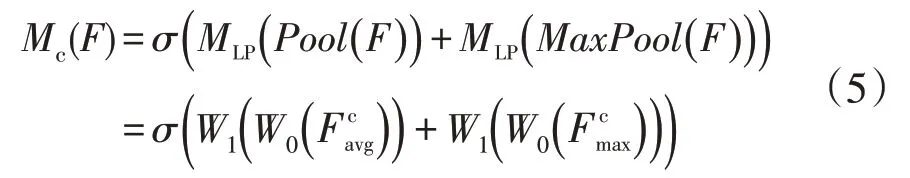
式中:σ为sigmoid 函数;W0、W1为权重参数,W0∈RC r×C,W1∈RC×C r;WLP为多层感知器模型函数;MaxPool为最大池化函数。
1.3.2 空间注意力
空间注意力关注“哪里”是重要信息,与通道注意力互补。如公式(6)所示,通道注意模块和初始特征图计算得到的F′在通道轴上进行平均池和最大池操作,分别得到∈R1×H×W和∈R1×H×W,然后将其连接成一个二维特征图,输入到卷积核为7×7 的隐藏层进行卷积得到与输入特征图维度一致的二维特征映射,最终使用sigmoid函数获得空间注意特征图Ms∈R1×H×W。空间注意力模块结构图如图2所示,其过程表达如下
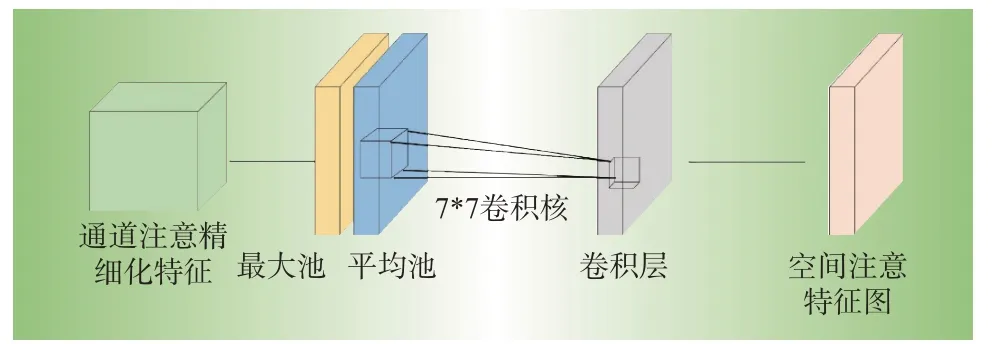
图2 空间注意力模块Fig.2 Spatial attention module
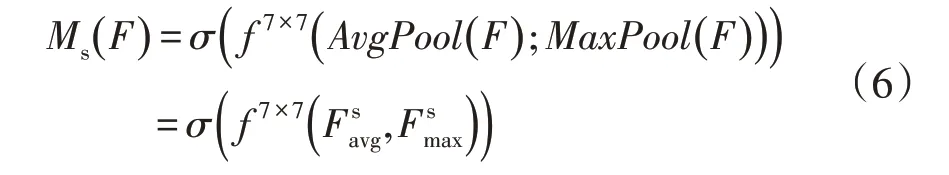
式中:AvgPool为平均池化函数。
2 基于改进SGN的非侵入负荷分解模型
2.1 模型整体架构
文中将电器开∕关状态作为门控机制,为其添加门控损失,使得模型可以直接从门控分类子网进行学习,并且与主回归任务结合共同形成模型的最终输出,分解模型如图3所示。
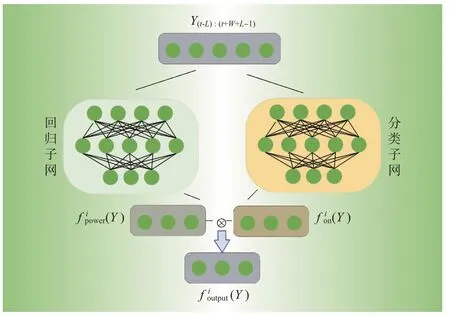
图3 基于序列到子序列和SGN的整体结构图Fig.3 Schematic based on sequnce-to-subsequnce and SGN

式中:⊗为两个输出结果逐元素相乘,不同于文献[22]的计算方式,文中不再是将回归网络输出的功率值直接乘以电器开∕关的概率值,而是乘以0或者1,函数H直接将小于0.5的概率值转换为0,反之,转换为1。
在整个模型架构中,我们分别利用以下损失函数进行优化
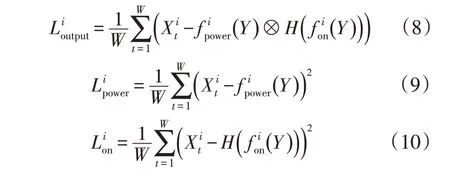
2.2 子网络架构
结合通道注意力机制和空间注意力机制的子网络架构如图4 所示。首先通过5 层基本卷积学习特征;然后经过通道注意力和空间注意力模块细化特征;最后全连接层实现线性映射,得到输出结果。
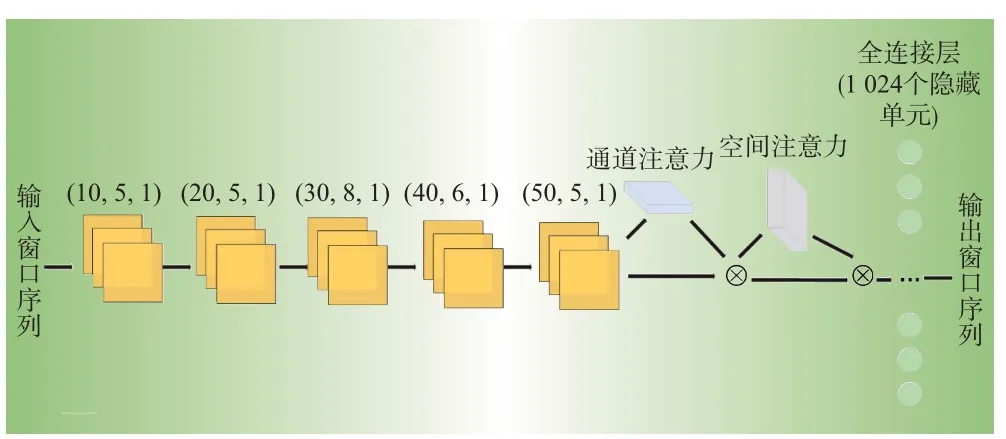
图4 分支网络模型Fig.4 Branch network model
3 实验分析与结果
3.1 性能指标
两个性能指标用于评估提出的模型,分别为平均绝对误差(mean absolute error,MAE)和均方根误差(root-mean-square error,RMSE)。根据1.1 节的定义,Xt为t时刻设备的真实读数,为t时刻本文模型的预测输出读数,MAE显示每个时刻真实值和预测值的平均差,表示为,RMSE 显 示每个时刻预测值与真实值偏差的平方与总观测时间T比值的平方根,表示为。
3.2 数据分析与处理
3.2.1 数据集及电器分析
本文使用文献[24]公布的UK-dale 数据集进行实验。数据采样时间周期为2012年11月到2015年1 月,每个家庭的数据包括一个主电源功率读数和其对应的每个电器的单独功率读数。
文献[25]根据工作模式将电器分为4类,分别为开∕关两状态电器、多状态电器、连续变化型电器和持续工作型电器。开∕关两状态电器工作模式单一,运行期间功率恒定;多状态电器的多种工作模式是相对固定的,每个工作模式每次运行时功率值较稳定,而且一种模式切换到另一种模式时,功率的变化过程也较稳定。文中主要以这两种电器类型为研究对象,通过对5个家庭的电器种类进行统计,发现家庭1、2、5均包含5种电器,文中采用家庭1、2进行实验。
3.2.2 数据处理
在数据采集过程中,由于设备原因,很多采样点缺失数据,本文利用NILMTK[26—27]工具包中的预处理方式进行了数据分割,当任意两个连续数据样本间的时间间隔大于3 min,则将其删除。另外,我们对数据进行了归一化和标准化处理。
3.3 结果分析与可视化
文中选取家庭1 中2013 年5—12 月的数据和2014年1—8月的数据作为训练集,其中20%划分为验证集,家庭1 中2014 年8—12 月的数据作为测试集,故测试集与训练集相互独立,无重叠部分。在实验过程中,聚合功率窗口长度为200,对应1 200 s的连续样本;目标电器窗口长度为32,对应192 s的连续样本;聚合功率窗口两侧增加的额外时间序列长度为32,对应192 s的连续样本。
为了验证文中序列到子序列模式相较于序列到序列和序列到点收敛速度快、模型推理计算量小的优势,我们首先将SGN 网络分别构建为以上3 种模式,以洗碗机的训练结果为例,迭代次数对比如图5所示,模型训练结果如表1所示。
由表1可知,在序列到子序列模式下,参数量和训练时间两个指标优于序列到序列,计算量优于序列到点。由图5可知,序列到点和序列到子序列的第1次和第2次训练大幅度降低了loss值,在第13次训练时达到了基本稳定;但是序列到序列模式在第8次训练才达到前两种方法第2次的训练效果,并且最终达到模型性能稳定时,训练次数为21,由此看出序列到子序列模式改进了序列到序列方式模型收敛速度慢的问题,并且大幅减小了序列到点的计算量。

表1 洗碗机3种构建模式性能对比Table 1 Comparison of metrics of three construction modes of dishwasher

图5 不同训练次数的损失值Fig.5 Loss values of different epochs
为了验证文中添加的通道注意力和空间注意力的有效性,以冰箱为例,图6 显示了训练过程中,模型有∕无注意力模块的迭代过程中损失值的变化。结果显示,两个注意力模块对于回归子网和分类子网的性能提升均有帮助,尤其是很大程度上降低了分类网络的损失值,更大程度上发挥了分类门控子网对于非侵入负荷分解任务的修正作用。
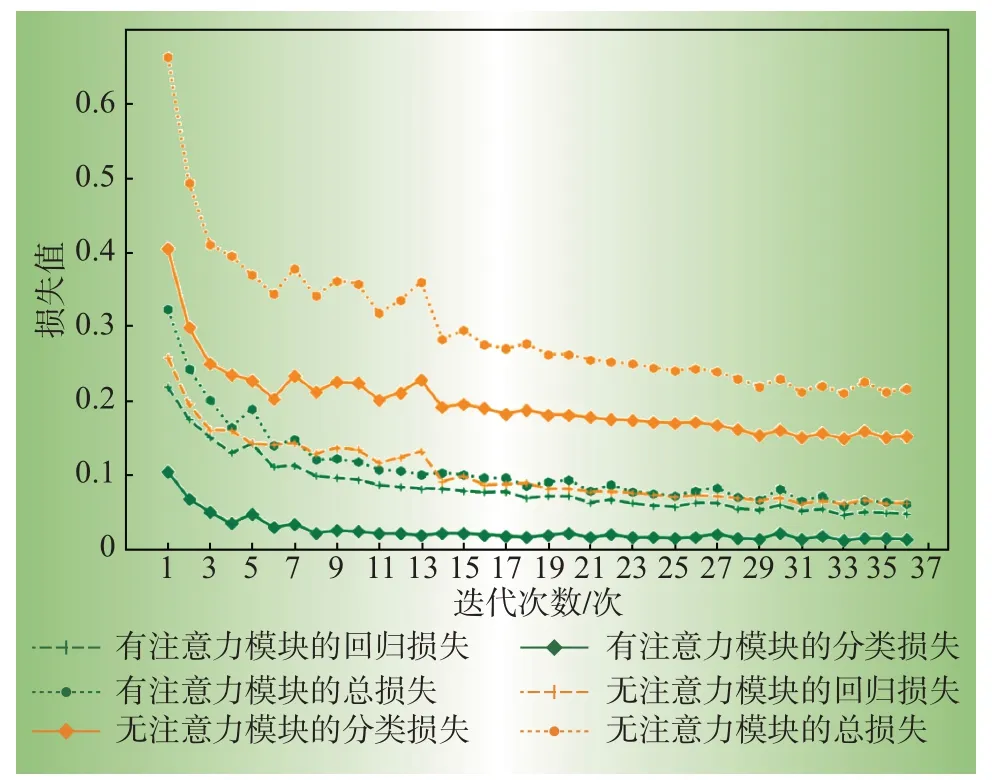
图6 有无注意力模块的损失值的对比Fig.6 Comparison of loss value with and without attention module
为了验证模型的分解性能,我们在相同的实验环境下,将提出的模型与其他模型进行对比,结果如表2 所示。结果显示,文献[22]提出的SGN 模型相较于DAE和序列到点模型,在运行时间长的电器上表现出优势,但是在水壶和微波炉这种运行时间短的电器上性能反而降低,这是因为这两种电器运行时功率变化快,SGN 模型难以学习到特征。相较于SGN模型,文中的模型在大部分电器上的性能表现优异,水壶和微波炉的效果最为明显,水壶的平均绝对误差降低了87%,均方根误差降低了67%,微波炉的平均绝对误差降低了62%,均方根误差基本持平,说明文中添加的混合注意力机制改进了短时间运行电器信息难以提取的问题并且增强了长时间运行电器的特征提取能力,减少了噪声的影响。相较于文献[28]提出的模型,本文模型在开∕关状态电器上分解效果具有优势,在多状态长时间运行的电器上分解精度略差,说明本文模型在提取多状态变化特征时具有困难,但是文献[28]提出的多头概率稀疏自注意机制扩展了模型集中于不同位置的能力,能够更好地拟合多种特征。

表2 模型分解结果对比Table 2 Comparison of model disaggregation results
图7 给出了5 种电器局部分解效果对比实验结果,由图7可知文中的模型有效提高了5种电器的分解精度。对于小功率电器冰箱而言,文中模型几乎拟合了真实分解值,但是对比模型存在较大波动;对于水壶和微波炉这两种运行时间短、功率变化为瞬时状态的电器,文中模型可以精准地捕获到特征变化,但是SGN模型很难学习到突变的特征,分解值几乎为一条平滑的直线,文献[28]提出的模型分解精度基本与本文持平,但是在功率突变时,分解值与真实值差距较大;对于运行时间长的大功率电器,文中提出的模型在电器开启时功率分解精度略胜于SGN模型,分解值更加接近于真实值,功率变化情况捕获更加准确,但是与文献[28]相比,本文模型在多状态功率峰值分解精度不佳,与真实值有一定差距。

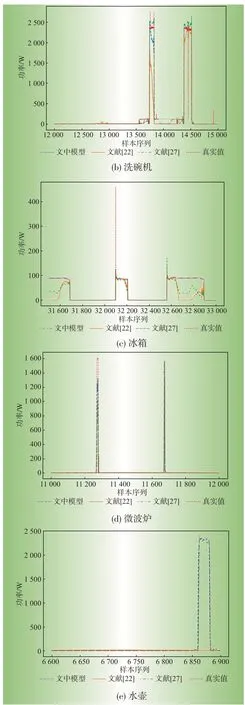
图7 电器分解效果对比Fig.7 Comparison of decomposition effects of electrical appliances
4 结束语
本文提出了基于序列到子序列和SGN 的非侵入负荷分解模型,以序列到子序列的模式构建网络,解决了序列到序列中模型收敛困难以及序列到点计算量大的问题,在两者之间进行了平衡;且将负荷分解任务同时定义为回归任务和分类任务,构建了多任务框架,在每个子任务网络中添加了通道注意力机制和空间注意力机制,有效提高了模型提取特征的能力。实验结果表明,本文提出的模型不仅减小了模型收敛的困难度和推理周期的计算量,而且减小了平均绝对误差和均方根误差,提高了分解精度,未来可以进一步调整网络结构,增强网络的泛化性,并将网络部署到实际场景中,提高其实用性。D
