基于Python的三种网络爬虫技术研究
2023-02-12杨健,陈伟
杨 健,陈 伟
(诸暨市公安局,浙江 绍兴 311800)
1 引言(Introduction)
随着信息技术的发展,网络数据成为一种重要资产,如何快速有效地提取和分析数据是目前该研究领域的热点[1]。夏火松等[2]、云洋[3]应用Requests技术分别开发了商品评论、百度贴吧图片爬虫,优化了爬虫算法,并为用户提供了有效的信息参考。刘灿等[4]、WU等[5]基于Scrapy框架开发了教育新闻、Steam商店信息爬虫,实现了个性化推荐、自动获取游戏信息。潘洪涛[6]利用Selenium技术具有的自动化测试特性,设计与实现了一种多源统一爬虫框架,可以面向多个网站数据源,以统一的接口形式实现数据抓取;许景贤等[7]安装配套的Chrome WebDriver驱动,调用Selenium接口模拟人工自动点击浏览器,绕过淘宝配置的反爬措施,成功爬取淘宝上的商品价格和名称。上述研究工作使用Python多种爬虫技术实现了相关业务需求,但均没有探讨技术区别和选用理由。
针对以上问题,本文介绍了基于Python的Requests、Scrapy和Selenium三种主流爬虫技术,设计实现网络爬虫的程序框架。通过设计爬取“站长之家”网站简历数据的实验案例,实现不同技术的环境配置、程序开发和并发性能等的比较。结果表明,不同的网络爬虫技术具有不同的优点和缺点,适用不同的业务场景,因此在开发方案选择上要合理选用,以提升数据爬取的稳定性、准确性和工作效率。
2 爬虫技术介绍(Introduction to crawler technology)
使用Requests、Scrapy和Selenium技术开发的网络爬虫,由于抓取的原始数据格式包含HTML、XML和JSON,因此对目标数据的获取要辅以其他技术解析并持久化保存。
2.1 Requests技术
Requests技术属于爬虫基础性工具包,它模拟人输入网址向服务器递交网络请求,实现自动爬取HTML网页页面信息的功能。根据HTTP协议对资源的六大操作方法,Requests配备对应的GET、POST、HEAD、PUT、PATCH、DELETE六个基础方法和一个REQUEST通用方法,具有HTTP连接池自动化、持久Cookie会话、SSL认证等基本功能。
2.2 Selenium技术
Selenium技术是一个基于Web应用程序且支持浏览器驱动的开源自动化测试框架,其运行过程就是一个可视化地模拟人输入网址、滚动鼠标、点击等动态的操作过程,能够对Chrome、Firefox、IE等浏览器中的对象元素进行定位、窗口跳转及结果比较等操作,具有执行网页JS加载、Ajax动态异步等技术,能做到可见即可爬,支持Python、Java、C#主流编程语言二次开发。
2.3 Scrapy技术
Scrapy技术是一个网站数据爬取和结构性数据提取的应用框架,包含引擎、调度器、下载器、解析爬虫、项目管道五个模块和下载器、解析爬虫两个中间件。该技术框架已设计了爬虫通用的数据和业务接口,方便根据业务需求聚焦爬取、解析、下载、存储等操作。
2.4 其他辅助技术
网络爬虫爬取初始数据后需要进行解析,常用的技术如下:(1)Xpath库,它能够对特定数据进行定位,以更好地获取特定元素,通常存储在XML文档中,在一定程度上起着导航作用。(2)RE正则表达式库,它通过规定一系列的字符及符号来进行数据筛选,实现图片、视频和关键字的搜索,进而实现信息的爬取。(3)BS4库,它运用HTML解析策略,把HTML源代码重新进行格式化,方便使用者对其中的节点、标签、属性等进行操作,完成网站数据的抓取、筛选操作。(4)JSON库,它是一种轻量级的数据交换格式,采用对象和数组的组合形式表示数据,用于将数据对象编码为JSON格式进行输出或存储,再将JSON格式对象解码为Python对象。
3 网络爬虫程序框架设计(Web crawler framework design)
网络爬虫一旦启动将采取定制、自动化模式爬取目标网页的数据,首先从初始页面的URL地址开始,通过向目标站点发送一个Web请求,等待服务器响应;然后获取响应的页面内容,可能包含HTML、JSON字符串、二进制等数据类型,根据响应网页数据类型,辅助以用正则表达式等网页解析库进行解析,获得目标数据;最后保存数据,将数据保存为文本格式或者保存至数据库。如果目标数据涉及URL地址嵌套关联,就要通过分析页面中的其他相关URL,抓取新的网页链接,反复循环,直至爬取、分析和获取所有页面内容。通用网络爬虫模型如图1所示。
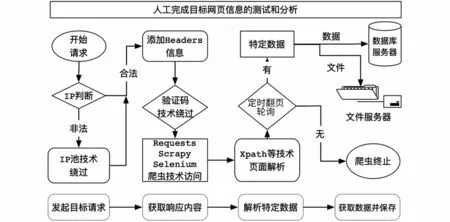
图1 通用网络爬虫模型Fig.1 General web crawler model
4 爬虫核心代码实现(Crawler core code)
本实验使用Python 3.6.4版本作为开发环境,采用集成工具PyCharm 2020.1版本开发。爬虫核心代码如下:


5 实验与分析(Experiment and analysis)
本实验以“站长之家”的简历栏目(https://sc.chinaz.com/jianli/)作为爬取数据目标,该网站简历栏目素材丰富,网页包含JS、CSS、文字、图片、文件等,网站robots协议允许所有网络爬虫访问。实验环境使用“联想”的小新AIR-14 2020笔记本电脑(操作系统:Windows 10专业版;处理器:Intel酷睿i5,CPU运行频率1.00 GHz;内存16 GB)和浙江大学华家池校区Wi-Fi网络SCEZJU-GUEST。
5.1 实验步骤
实验通过环境配置、代码实现、单线程和多线程等维度,比较三种爬虫技术的程序开发难易程度及耗时。为避免数据解析影响实验结果,在耗时计算中剔除了第三方库解析原始数据的时间,具体步骤如下。
Step1:安装配置。根据Requests、Scrapy和Selenium技术的安装要求及依赖包,配置环境和第三方插件。
Step2:准备工作。通过浏览器查看目标网页,确定URL地址及翻页参数。
Step3:获取数据。向目标网页发起请求,正常响应返回得到原始数据。
Step4:解析内容。通过Xpath库解析获取目标数据并在IDEA工具中打印。
Step5:变更URL翻页参数,通过步骤1至步骤4中,分别进行单线程、多线程等实验并记录时间。
5.2 实验与分析
5.2.1 环境安装、代码开发比较
表1显示了三种爬虫技术的环境配置与开发实现对比信息。其中,Requests、Scrapy和Selenium包通过Python的pip命令安装。在程序开发中,Requests、Scrapy网络爬虫在模拟访问时要携带Headers请求头,请求返回的响应不会执行获取网页中的JS动态代码,无法得到由JS异步请求的网页数据。开发Scrapy网络爬虫,程序代码要按照框架自带的引擎、调度器、下载器、解析爬虫、项目管道等模块要求开发,如果要调用爬虫抓取的不同数据进行业务定制,技术实现不够灵活。Selenium网络爬虫必须安装配套的Webdriver驱动以调用本机浏览器,Selenium爬虫通过本机浏览器模拟访问网页,因此代码中不需要携带Headers请求头。爬取网页的JS动态代码被浏览器执行,获取的响应已包含JS异步请求数据,这是Requests、Scrapy技术无法实现的。

表1 环境配置与开发实现对比表Tab.1 Comparison table of environment configuration and development implementation
5.2.2 单线程运行下爬虫性能分析
采用单线程爬取网页实验中,运行三种爬虫程序,分别爬取目标网站网页数量为10 页、100 页、500 页和1,000 页且运行3 次,记录时间和计算平均值。表2显示了三种爬虫爬取页面的耗时对比。经分析发现:(1)对同样页面数进行轮爬,三种爬虫第1、2、3 次的爬取耗时差异不大,但三种爬虫之间的爬取耗时对比差异较大。(2)Requests爬虫的四轮实验的平均每页爬取时间为0.24 s、0.27 s、0.28 s和0.26 s,爬取速度比较稳定;Selenium爬虫的四轮实验的平均每页爬取时间为1.08 s、1.47 s、1.64 s和1.42 s,当爬取的页面数量较多时,平均爬取每页的耗时多于爬取少量页面的耗时,但总体速度比较稳定;Scrapy爬虫的四轮实验的平均每页爬取时间为0.08 s、0.02 s、0.02 s和0.02 s,爬取每页的平均耗时均不到0.1 s,速度极快且稳定。在单线程爬取实验中,Scrapy爬虫耗时最少、Selenium爬虫耗时最多。(3)三种爬虫爬取网页数量为10 页、100 页、500 页和1,000 页的平均耗时接近线性递增。从增量来看,Scrapy爬虫耗时最少,Selenium爬虫耗时最多,随着爬取页面数量的增加,三种爬虫的爬取耗时差距逐渐增大,如图2所示。
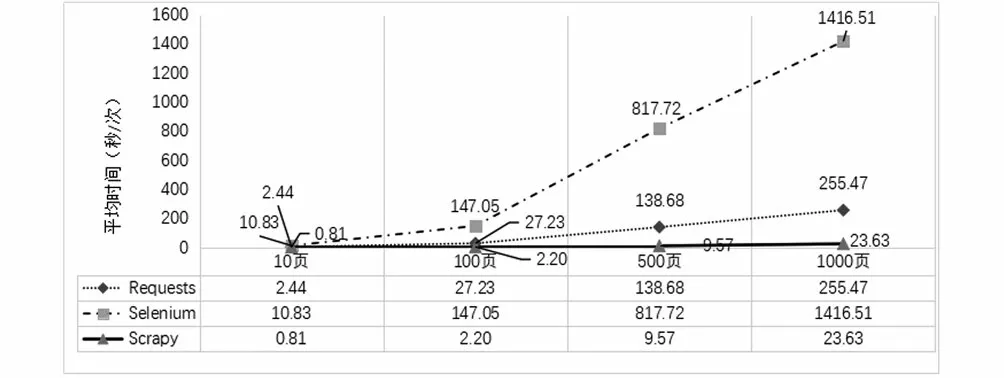
图2 单线程爬取平均耗时对比Fig.2 Comparison of average time consumption of single thread crawling
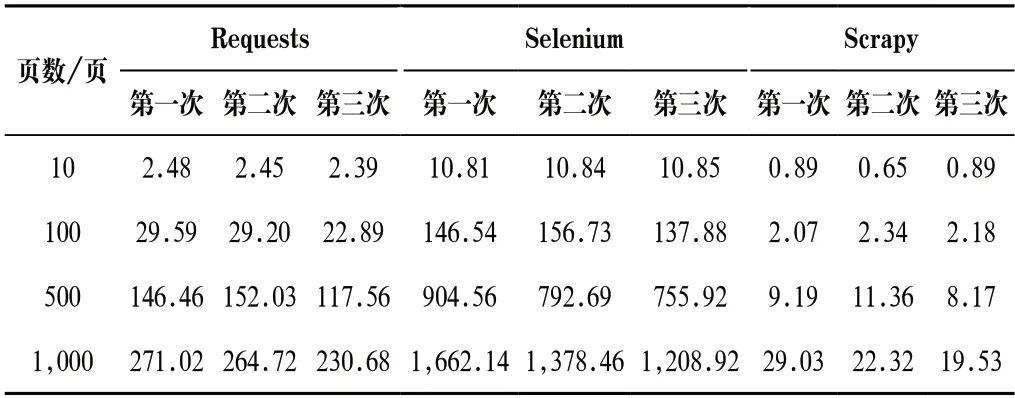
表2 单线程爬取耗时对比Tab.2 Single thread crawling time comparison(单位:秒/次)
5.2.3 多线程运行下爬虫性能分析
采用多线程爬取网页实验中,统一开发并发线程数为16个,分别运行三种爬虫程序爬取目标网站网页数量1,000 页且运行3 次,计算耗时平均值。表3显示为单线程和多线程爬取的比较情况。分析发现以下情况:(1)Requests、Selenium和Scrapy爬虫在多线程爬取时,平均耗时分别为25.39 s、172.12 s和23.52 s,平均每页耗时分别为0.03 s、0.17 s和0.02 s,Scrapy和Requests爬虫耗时最少并且耗时差距接近,而Selenium爬虫耗时依然最多。(2)Requests和Selenium爬虫采用多线程爬取页面时,耗时明显少于单线程,而Scrapy爬虫耗时几乎不变,如图3所示。
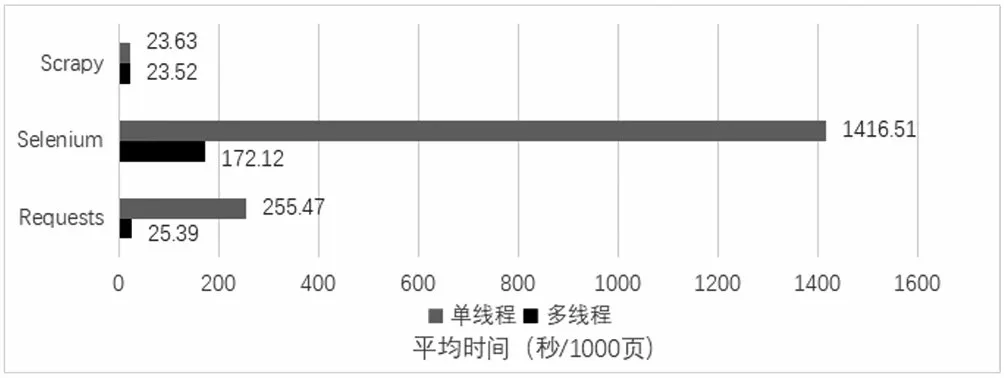
图3 单线程和多线程爬取平均耗时对比图Fig.3 Comparison chart of average time consumption of single thread and multi-thread crawling
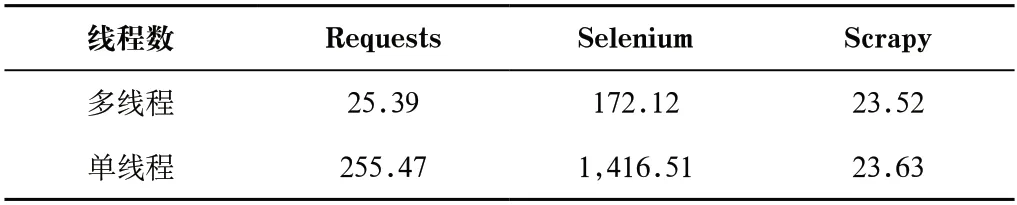
表3 平均耗时对比Tab.3 Average time consumption comparison(单位:秒/1,000 页)
5.2.4 反爬虫规则下爬虫登录对比分析
目前,很多网站具有一定的反爬虫机制,但对网络爬虫的相关研究,除robots这一“君子协定”外,并无相关的法律法规限制[8]。研究发现“中国裁判文书网”设置的反爬虫机制严谨,故以此作为实验对象对比不同爬虫技术的绕过效果。
在手动测试中,打开网页输入用户名、密码并多次登录网站后,会跳出登录验证网页,必须正确输入验证码才允许操作人员登录。在Selenium技术开发的网络爬虫测试中,采用“程序睡眠+键盘输入+自动填写”进行绕过登录。首先启动爬虫程序调用本地浏览器直接访问验证网页,使用time.sleep()方法让爬虫进程睡眠20 s,以提供键盘输入信息的操作时间;其次直接手动在浏览器输入验证码证实非机器人行为,等睡眠结束后程序再调用click()方法自动执行确认按钮,实现验证并跳转到登录页面;再次使用find_element()和send_keys()方法定位文本框并自动填入用户名和密码;最后调用click()方法点击登录按钮,完成爬虫模拟登录。爬虫登录网站获取到用户的Cookies后,可以应用Cookies信息在其他爬虫技术,实现网页数据定制化爬取。
在模拟登录过程中,Selenium会打开一个浏览器,操作页面全程实时可视化,显现爬虫对网页的操作及元素变化,包括文本填写、页面跳转、新建网页等。由于网页中存在随机验证码进行非机器人操作验证,如果使用Requests、Scrapy技术开发的网络爬虫,则无法通过自动填报验证码信息突破网站的反爬虫机制。
6 结论(Conclusion)
本文研究了基于Python的Requests、Scrapy和Selenium爬虫技术,开发实现了单线程、多线程等6 个网络爬虫程序,验证了不同爬虫技术之间的性能和技术实现差异。从实验数据来看,在排除其他因素干扰的情况下,只考虑爬取速度,则Requests技术、Scrapy技术单线程爬取网页数据速度相当,并且远快于Selenium技术。若使用多线程爬取,Scrapy技术的爬取速度远快于Requests技术,Selenium技术的爬取速度依旧最慢且性能表现很不理想。在考虑爬取速度的基础上,结合3 个爬虫技术的特征,可得出Requests技术爬取速度中规中矩,在Python内置模块的基础上高度封装了HTTP库,入门简单,对面向深度定制或小批量数据的爬虫开发更为合适;Scrapy使用了异步网络框架代码,既简化了代码逻辑,又提高了开发效率,线程并发性能显而易见,但代码的自定义开发要契合Scrapy框架,遇到目标数据涉及多个关联URL,则开发不够灵活,入门稍难,偏向适用于开发网站级别的网络爬虫,不适合深度定制;Selenium技术开发的网络爬虫,本质上是驱动浏览器对目标站点发送请求,浏览器在访问目标站点后,需要把HTML、CSS、JS等静态资源加载完毕,因而整体效率在3 个技术中最低,但其会解析执行目标网页的CSS、JS代码,可以避开一系列复杂的通信流程,具有绕过复杂的反爬虫机制能力,这方面的能力优于Requests和Scrapy已被证实。网络爬虫的实际开发遇到的网站场景较为复杂、多样,要根据不同业务需求选择不同的爬虫技术,一项系统的业务往往要多种爬虫技术配合使用才能达到获取数据的目的。
