6G算力网络:体系架构与关键技术
2023-02-09郭凤仙孙耀华彭木根
郭凤仙,孙耀华,彭木根
(1.北京邮电大学 计算机学院(国家示范性软件学院),北京100876;2.北京邮电大学 信息与通信工程学院,北京100876)
0 引言
随着智能设备、物联网、人工智能、网络技术等 的发展,移动通信系统与技术取得了较大进步,逐步形成了较为成熟的无线感知、无线通信和泛在计算等多个功能体系,构建了终端采集信息、网络传递信息、云边处理信息的烟囱式信息服务框架。然而,随着无人化、浸入式、数字孪生等通信、感知和计算高度融合业务的演进发展,当前的烟囱式信息服务框架难以满足其各方面的技术需求[1-2]。6G通信、感知、计算(通感算)融合是指在共享频谱、时间、空间和能量等资源条件下,利用蜂窝网作为感知和通信基础设施,并通过信号、通道、信息、平台等层面上的统一设计,实现一个信号、一个通道、一个天线、一个平台对感知和通信信息的统一承载和处理,从而实现 6G通感算深度融合。通感技术的发展与深度融合将带来巨量的数据处理需求。据华为发布的《计算2030》预测,2030年人类将进入尧字节(YottaByte,YB)数据时代,全球数据每年新增1 YB[3]。海量数据处理与分析将消耗大量算力。据OpenAI分析显示,从2012—2021年,人工智能算法对算力的需求增长了390万倍。作为通感深度融合系统的基石,算力的作用不言而喻。
在上述背景下,云计算、移动边缘计算和雾计算等技术蓬勃发展,同时智能终端算力不断增强,算力沿网络由中心延伸至边缘,形成了网在算中、算在网中的局面。然而,算力在使用方式上大多采用独占模式,利用率不高。据分析,数据中心的平均利用率只有55%,许多数据中心地利用率甚至不到20%[4]。由此推断,未来网络必将面临算力供不应求的局面。
面对上述挑战,尽管边缘计算的广泛部署能够有效缓解上述问题,但是如何更加高效的利用这些分布式泛在算力更具有现实意义,亦面临着诸多技术挑战:① 现有算力节点从规模上大到智算中心、超算中心,小到智能终端、gNB加速卡,在能力上囊括了通用算力、并行算力、智能算力、定制化算力,将业务调度至不合适的算力节点将导致资源的浪费,难以满足多样化业务的服务级别协议(Service Level Agreement,SLA)需求。② 算力节点高度分散且单一算力节点能力有限,通常将服务分散至多算力节点。面对上述多服务器场景,当前网络依赖应用层技术,如域名系统(Domain Name System,DNS),应对负载均衡、重连、服务迁移等问题,等待时延长达数分钟,严重影响时延敏感型业务体验。③ 算力和网络分属于彼此独立的管控系统,动态性差,如传统的移动边缘计算仍依赖于中心控制节点,引入了一定的控制时延,如何实现边缘计算与网络共治进一步满足时延敏感型业务需求是边缘计算落地的关键。
因此,为高效利用云、边、端泛在多级算力,国内外学者和研究机构依据“算力+网络”深度融合的思想提出了算力网络(Computing Force Networks, CFN),旨在基于统一算力建模方法,利用网络发达的触角感知业务需求和算力状态,进行算网统一管控,从而突破传统网络应用层和网络层相互隔离所带来的调度固化问题,实现业务与算网资源的按需实时适配,满足用户的SLA需求。本文围绕算力网络的发展历程和发展现状,介绍了算力网络的愿景、架构以及关键技术,然后分析了算力网络面临的挑战和发展趋势。
1 发展历程与现状
1.1 发展历程
依据组织形式,算力可以划分为4个层次:芯片级算力、整机算力、集约化算力和网络化算力[5],算力的提升可以通过不同的层次实现。
在单芯片算力方面,20世纪60年代,半导体技术的发展使得计算机进入芯片时代。芯片成为算力的主要载体,目前主要包括CPU、GPU、NPU/TPU、FPGA等类型。CPU作为通用基础算力,软硬件解耦,具有最高的灵活度,在不考虑性能的前提下几乎能够完成所有的计算任务。从20世纪80年代开始,在经历了架构设计、多核并行、提高CPU频率等各种手段之后,CPU的整体性能提升达到了一个瓶颈。现今CPU性能每年提升不到3%。若要实现CPU性能翻倍,需要20年。面对上述困境,GPU应运而生,主要擅长处理类似图像处理这类高密度计算且数据相关性小的并行计算任务。不同于CPU,通过将大量晶体管用于计算单元,GPU算力得到大幅提升。GPU算力的提升主要通过增加核数,受限于成本,其性能即将到顶。另一种方式通过牺牲灵活性换取性能的提升,即软硬件耦合,代表芯片包括FPGA、TPU、NPU等。FPGA是一种高性能、低功耗的半定制化芯片,在性能上同时具有CPU和GPU的流水线和并行能力,能够针对神经网络这类算法的特性增加并行度、调整内存访问,以更好匹配其需求。而NPU、TPU是专门为机器学习算法定制的ASIC芯片,在处理速度上是CPU、GPU这类芯片的15~30倍,其算力的提升主要依赖于计算单元MAC的累加。
在整机算力方面,无论是智能终端、个人电脑(Personal Computer,PC)、服务器甚至是网络设备,大多采用多核CPU或者CPU+xPU(其中,xPU是指GPU、NPU、TPU、FPGA等芯片)的主流架构。一方面,可通过多核并行提升整机算力,但是由于半导体工艺进步放缓、芯片功耗急剧上升,多核架构算力性能提升变慢;另一方面,可通过异构计算架构,即集成通用算力CPU与硬件加速算力xPU,使得更多处理器能够并行计算。特别地,在异构计算架构中,xPU均作为CPU的硬件加速器的形态存在,接受CPU的控制。其中CPU负责底层基础计算,xPU负责上层特定计算任务。由于业务多样,算法迭代快,异构计算架构在扩展性上受限,无法长期落地。
集约化算力包括各类计算中心,如传统数据中心、云计算中心、新型的智算中心、超算中心以及边缘计算机房等基础计算设施。首先,不同的计算中心能力不同,例如传统数据中心主要提供存储能力,云计算中心主要为多样化业务提供基础算力,智算中心主要为人工智能应用提供智能算力,超算中心主要面向科学计算,而边缘计算主要提供低时延算力。其次,不同计算中心的规模差别巨大,如我国神威太湖之光超算中心峰值算力达125千兆浮点运算次数每秒(peta Floating-point Operations per Seconds, PFLOPS),边缘计算机房由于场地限制通常仅具有数台服务器。集约化算力的提升主要通过提升规模和广泛部署。
网络化算力是指通过网络连接、组织、调度的分散化算力,是一种分布式网络计算模型,其演进历史如图1所示。分布式计算模型可追溯至20世纪90年代,PC算力的增强促进了互联网技术的发展,同时PC的普及带来了分散化算力。为利用这些闲散的算力,研究者提出了网格计算,利用网络连接闲置的计算资源形成计算网格,从而完成需要大量算力的科学计算。然而,由于当时网络技术以及计算技术的限制,网格计算效率不高,并未得到大规模商用。21世纪初,随着虚拟化、微服务、云原生技术等计算技术的发展,云计算蓬勃发展,通过资源池化,为用户提供弹性可靠的算力供给。随着新型业务的发展,传统云计算由于集中部署无法满足用户的低时延需求,移动边缘计算应运而生。尽管边缘算力是分布式部署的,但是在资源供给上仍属于集中式方式。网络的作用仅限于连接算力,算力调度需要额外的编排调度系统,跨地域算力调度困难,泛在算力普遍利用率不高。
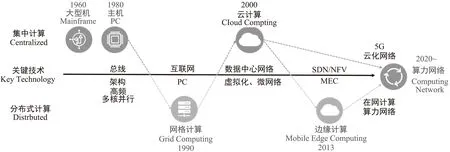
图1 网络计算模式演进历程
在网络化算力演进趋势下,算网融合需求明显。在部署形式上,移动边缘计算广泛部署,网络云化发展迅速,形成了网在算中、算在网中的状态,具备一体化供给的先提条件[6]。在技术上,软件定义网络(Software-Defined Networking,SDN)和网络功能虚拟化(Network Function Virtualization,NFV)赋予了网络灵活编排能力,虚拟化、微服务、云原生、无服务器计算等使云具备了弹性可靠的算力供给能力,二者提供了网络和算力灵活编排调度的可能。在需求上,新型业务不断涌现,一方面要求未来网络提供多样的网络和算力供给,另一方面对时延、服务质量的变化更加敏感,要求网络能够保障SLA需求。
1.2 研究现状
面对上述算网融合需求,为高效利用泛在分布式算力,工业界和学术界在算力网络方面开展了大量工作。本节将从产业、网络架构和关键技术等方面进行介绍。
在产业方面,2019年,中国联通和中国移动分别发布了《中国联通算力网络白皮书》《算力感知网络技术白皮书》[7-8],正式拉开了算力网络时代的帷幕。算力网络的体系架构在逻辑功能上被划分为算网融合资源层、算力路由层和算力服务层,以实现在统一度量和建模下的算力感知、路由和协同调度。算力网络的核心在于通过引入业务感知网络和计算优先网络,将业务信息与资源信息嵌入数据包,通过改进路由层协议,如边界网关协议(Border Gateway Protocol,BGP)和内部网关协议(Interior Gateway Protocol,IGP),在控制面进行业务信息和算力资源信息的扩散,从而实现基于算力和网络信息的联合寻路,实现算网协同的资源调度。此后,三大运营商联合华为、中国信息通信研究院等组织,先后发布了数版算力网络白皮书,详述了算力网络体系架构、发展阶段以及核心技术体系。特别地,在中国移动2021年发布的《算力网络白皮书》阐述了算力网络的三个发展阶段,即泛在协同、融合统一和一体内生[9]。
在算力度量和建模方面,文献[10]提出了面向业务体验的算力建模方法,首先将算力划分为逻辑运算能力、并行计算能力以及神经网络加速能力,通过度量函数将其映射到统一的量纲,然后以分级的形式将其划分为小、中、大、超大型算力。针对数据中心算力,中国信息通信研究院云计算与大数据研究所提出了综合衡量算力的五力模型,利用多属性群决策方法将与计算能力相关的通用算力、智能算力、算效、存储能力、网络能力等不同量纲进行融合对比,进而对不同数据中心就其能力进行定级[11]。然而上述度量和建模方法由于缺乏对业务的分析建模,仍不能作为业务与算力的适配的桥梁。
算力感知主要通过扩展现有路由协议,将算力节点信息嵌入数据包,使得网络能够实时感知算力节点的算力信息,其实现方式与算力路由方法相关,可划分为集中式和分布式。在统一度量的基础上,算力网络首先进行算力信息的采集,进行算力信息通告,即将算力信息通告至控制节点,在控制面完成算力感知;然后控制面根据算力路由协议生成路由表,转发面按照其进行转发,完成算力节点和路径的联合选择。文献[12]提出了一种基于域名解析机制的算力网络实现方案,由算力资源管理模块以集中式方式收集算力资源信息并进行统一的分配调度。该方案利用应用层技术实现负载均衡,仅作为算力网络的初步实现方案。中兴通讯股份有限公司基于SRv6提出了一种分级分层的控制面架构,将不同颗粒的算力资源和服务状态在不同的网络域进行通告,并创建对应的分级路由表,转发面执行无状态转发[13]。
2 算力网络愿景、架构与工作机制
2.1 愿景与体系架构
算力网络的核心是基于统一的算力度量和建模方法,感知业务、网络、算力,利用网络实现对跨地域算力的灵活按需调度编排,满足多样化业务对算网的需求,保障其SLA需求,是云网融合、边缘计算向算网融合演进的新阶段。不同于云网融合,其调度粒度更细,是算力的标准化技术。不同于边缘计算,网络的作用不再仅限于连接,包括了感知、组织、调度等功能,能够实现分布式算力的深度互联和灵活调度。
算力网络愿景如图2所示,主要由算网基础设施和运营云、管理云组成。
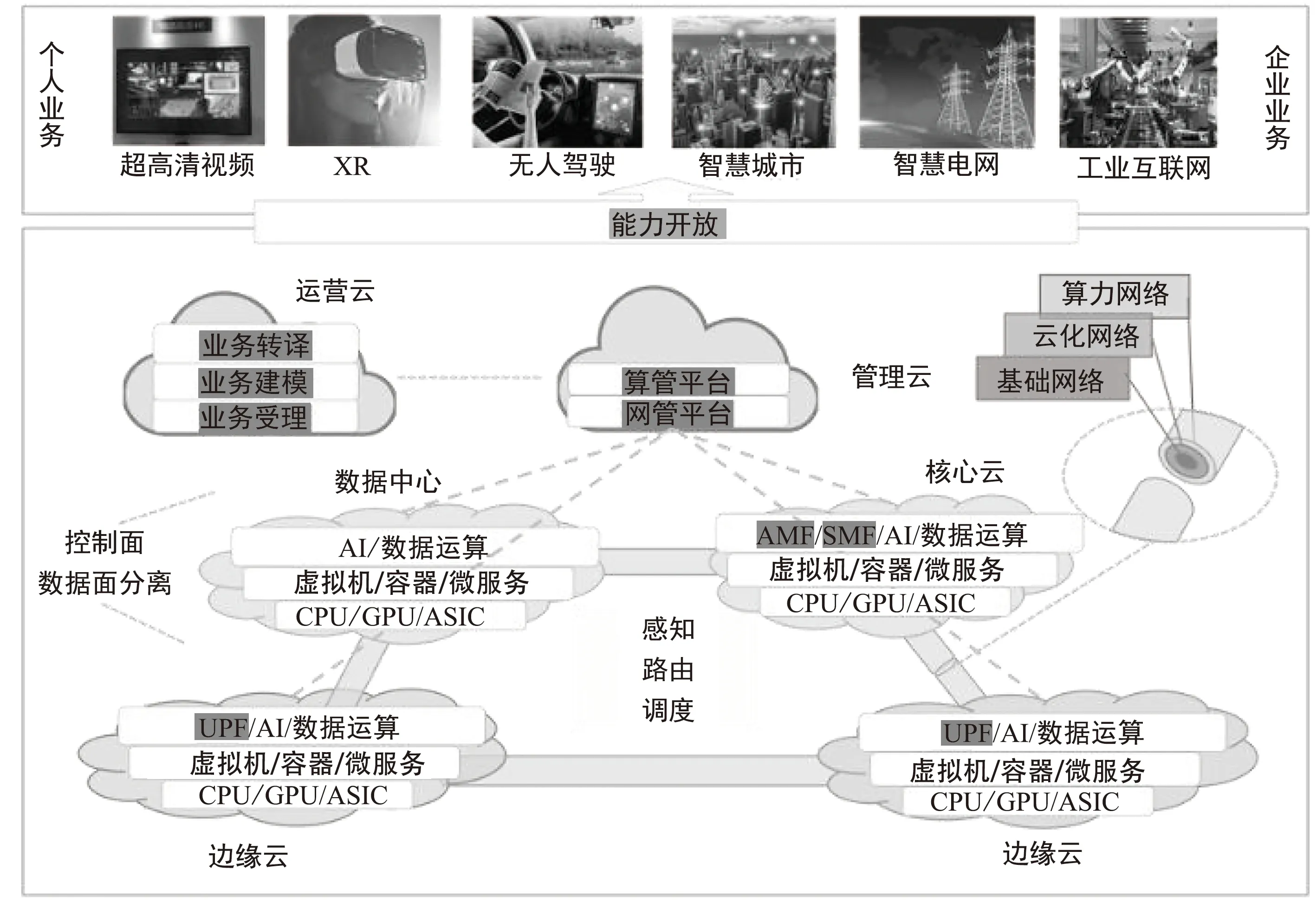
图2 算力网络愿景
在算网基础设施中,算力包括承载在接入云、边缘云、核心云、数据中心上不同粒度的算力,即CPU、GPU、ASIC这类硬件算力资源,虚拟机、容器、微服务这类封装化算力资源,以及人工智能(Artificial Intelligence,AI)算法、数据等这类顶层算力资源。网络包括基础网络(如移动网络中的承载网络)、云化网络设施(如云化接入网、核心网等)、算力网络(如算力路由等)。算力网络以基础网络和云化网络为基础、以算力网络为核心,为上层业务提供算网融合服务,如电信业务、超高清视频、扩展现实(Extended Reality,XR)、无人驾驶等业务以及智慧城市、智慧电网、工业互联网等业务。
具体而言,运营云是指运营系统,主要有业务受理、业务建模、业务转译三大功能:① 业务受理主要负责受理第三方业务,如XR、无人驾驶、智慧电网、工业互联网等第三方业务,获取其业务需求,如业务类型、特征、性能需求等信息;② 业务建模主要负责描述业务的网络和算力需求,包括空口资源、算力资源、网络资源等;③ 业务转译负责将业务需求映射为业务的网络和算力需求,从而实现业务需求的感知。算力基础设施负责承载算力业务,如AI训练和推理、针对XR的渲染任务和编解码任务。在基础网络和云化网络基础之上,算力节点间以算力网络为中心进行组网,负责算网感知和随路算网资源监测以及相应的控制功能。依据上述信息,管理云进行智能编排和管理,如业务部署/迁移、路由编排决策等,并下发至算网管理平台,完成算网管理编排。
算力网络架构如图3所示,该架构结合了中国移动所提三层算力网络体系架构[9]和“四层五面”6G网络架构[14]的逻辑架构设计思想,重点突出了与算力面相关的层与面以及相应的功能。具体而言,该架构在横向逻辑上仍划分为算网基础设施层、融合算网功能层、应用与服务层。其中,算网基础设施层由算网等基础设施组成,为功能层提供传输、计算、存储等底层资源,功能层形成特定的网络功能和计算功能,提供基本的网络和计算服务,应用与服务层为业务提供相应的支持。在纵向逻辑上,除了传统的管理面、控制面、数据面外,新增加了算力面。计算面在底层统一算力度量的基础上,在功能层提供计算执行功能,在顶层提供算力服务调用功能,负责向第三方提供算力支持。
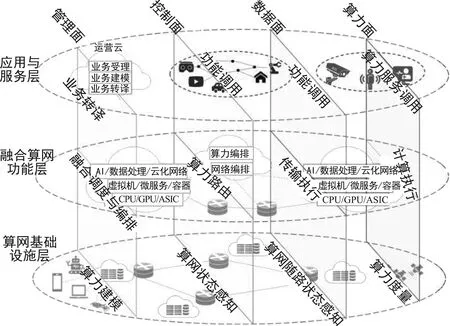
图3 算力网络三层四面逻辑架构体系
不同于以往网络架构设计,控制面和数据面不再仅隶属于功能面,而是作为纵向逻辑功能,贯穿三层;在底层对算网资源进行感知和随路监测,在功能层提供算力路由控制功能和传输执行功能,在顶层提供相应的功能调用接口,实现功能开放。此外,不同于传统意义上的控制面和数据面是功能层为支持传输业务提供的控制机制和业务数据的传输机制,为支持算力面,控制面和用户面需要增强其功能,用于算网融合控制和数据传输。一方面,分布式算力调度导致算力节点间数据流增多,数据面承载的数据流量模式发生了明显变化;另一方面,控制面是算网融合一种有效的方案。在控制面和数据面获取算网状态的前提下,管理面依据上述信息和业务转译获取到的业务需求信息,结合底层的资源/服务模型,对算网资源进行联合编排和调度,调用控制面功能,实现算网功能的联合编排和调度,数据面和算力面联合完成业务适配的算网服务的一体化供给。
2.2 工作机制
基于上述网络架构,本节简要介绍算力网络的基本工作流程,主要包括两大步骤:算力服务部署和算力服务处理。
针对算力服务部署,其工作流程如下:
① 管理面受理用户部署需求,并通过业务转译为业务模型,如网络带宽、算力类型、算力大小等需求,完成业务感知;
② 算力路由控制面收集算力节点状态信息,如算力负载、算力类型、算力服务能力等,并通过相关应用编程接口(Application Programming Interface,API)向管理面通告其信息,完成算力感知;
③ 管理面依据业务需求和算力资源信息,为其选择合适的节点进行算力服务部署,算力路由和管理面更新相应的信息。
通常,一个算力服务可部署在多个算力节点中。面对多算力服务场景,潜在解决方案包括以下两种:基于DNS的负载均衡技术和基于任播技术。基于DNS的负载均衡技术与内容分发网络(Content Delivery Network,CDN)中的DNS技术类似,本节不再赘述。下面简要介绍基于任播技术的算力服务处理的基本工作流程。
如图4所示,算力服务以服务标识(Service Identification,SID)进行标识,其中SID是一个任播地址。在算力网络中,一个SID标识唯一的算力服务。用户通过SID访问算力服务。用户请求可能由任意部署有所请求算力服务的算力节点响应。算力路由保留有该自治域或者算力节点下所有算力服务SID所对应的单播IP地址,由算力路由进行域内外的IP地址转换。
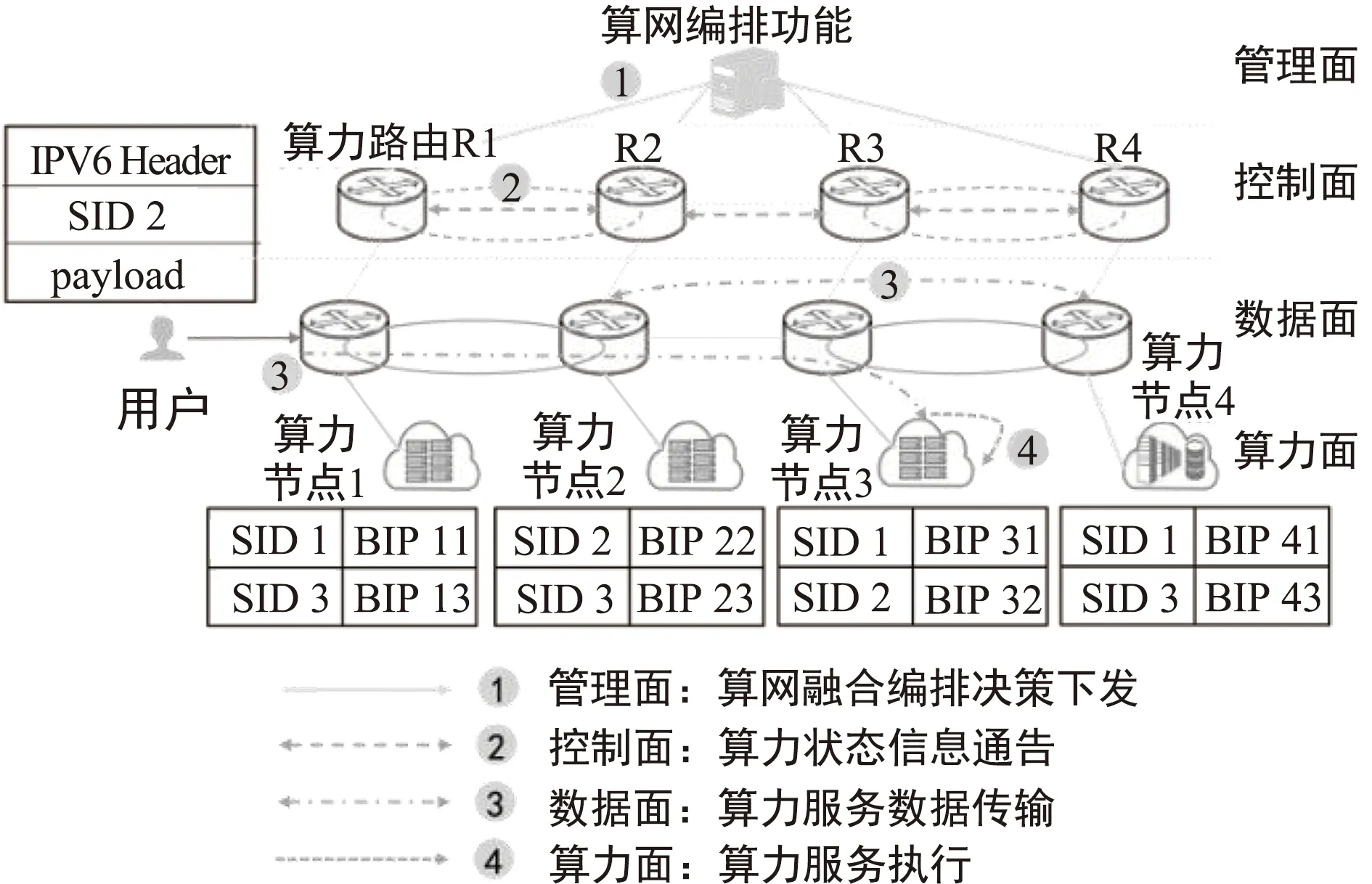
图4 算力服务处理过程
基于上述设置,算力服务处理流程如下:
① 算力面向算力路由同步其算力服务状态,包括可用性、负载等信息;
② 控制面收集上述信息,并向相邻路由通告该信息,并依据网络距离和算力节点信息多要素更新相应路由表项;当算力服务或者算力节点信息发生改变,管理面进行算网联合编排,更新路由表和算力服务部署;
③ 用户发出算力服务请求,目的地址为SID,源地址为用户IP地址;入口算力路由收到用户的算力服务请求,源IP地址分别修改为该算力路由IP地址,目的IP地址修改为出口算力路由,并通过查找路由表转发至下一跳;
④ 出口算力路由通过查找本地SID与BIP绑定信息,确认最终算力服务节点,并执行相应的计算任务。对于需要流粘性保持的数据流,入口算力路由可借助SRv6技术将后续数据包发送至绑定的出口算力路由。
3 关键技术
基于上述网络架构,算力网络需要突破算力度量与建模、算力感知、算力路由和算力调度等关键技术瓶颈。
3.1 算力度量与建模
面对异构计算场景,算力网络亟需突破算力度量和建模方法,其目的包括:① 针对算力使用量,形成统一的可度量、可计费的算力度量单位,为算力交易提供标准;② 评估算力节点的服务能力,为业务算力适配提供参考信息。
从资源的使用方式来看,算力网络是一种算力的标准化技术。算力网络强调业务逻辑在用户,即用户仅开发程序,算力网络负责进行算力资源的管理编排,算力的使用按照使用量进行计费。在现今的云计算和边缘计算的模式下,用户首先选择算力节点,分配相应的计算资源和存储资源,然后加载应用、执行运算,并将计算的结果存储起来,在此期间还需要管理资源的释放和再利用。算力的使用按照占用量进行计费,即使算力资源空闲时仍需要支付相应的费用。这样粗放的使用方式使得算力资源存在极大的浪费。无服务器计算[15]是一种可动态扩展的云计算模型,能够按需提供计算资源。函数即服务是无服务器计算的典型计算类型,即将应用程序拆解为细粒度的函数,按照业务需求提供计算资源和执行计算。计费方式依据函数的执行时间和次数进行计算。然而,以函数进行计费的方式面临着计费方式难以统一、度量粒度较粗、难以衡量等问题。以太坊智能合约在执行时被编译为以太坊虚拟机的指令,不同的指令以不同的标准进行收费[16],如表1所示。

表1 计算量度量方法对比
尽管上述方式由于应用场景不同并不能直接应用于算力网络,但是为算力网络的标准化提供了很有益的参考,即从业务的需求出发,将其需求拆解为计算单元的细粒度操作,即指令/操作。受上述计算方式启发,算力使用量可利用算法计算量来表示。以两个大小为n×n的矩阵相乘为例,其计算量为N3个乘法操作。以深度学习经典模型AlexNet为例,该模型由5个卷积层和3个全连接层组成,每层计算量可由其设置获得,总计算量为1.45 G浮点运算数次数(Giga Floating-point Operations, GFLOPs),其中包括乘法操作和加法操作。
为实现业务与算力适配,需要评估算力节点服务能力。基于上述计算量计算方法,算力的衡量单位包括浮点运算数次数每秒(Floating-point Operations per Seconds, FLOPS)和操作数每秒(Operations per Second),分别表现为对浮点数和整数的操作能力,在数值上与双精度浮点数操作数相差8倍。因此,可忽略计算精度,将所有芯片的算力换算为双精度浮点数操作数,即FLOPS,由此获得单算力节点的总算力。现有计算平台大多采用异构计算模式,即通用算力+硬件加速算力,其中CPU为通用算力,并行算力(GPU)、智能算力(TPU/NPU)和定制化算力(FPGA)为硬件加速算力。不同算力擅长不同的业务,因此仅依靠算力大小无法完全彰显算力节点对外服务能力。因此,可采用算力分级+能力隶属度的方式评估算力节点服务能力。首先,根据文献[8]中的分级方式,将该算力节点进行分级,对外展现其处理能力等级。然后将上述4种算力作为输入信息,采用文献[9]中的多属性群决策算法或者人工智能算法获得处理能力隶属度。最后,算力节点由{算力分级、算力类型}表示,其中算力大小和算力类型可由数组或者向量表示。相应的,业务算力需求可由{算力大小、算力类型}表示。
3.2 算力感知与路由
算力路由是在控制面实现最优算力节点与最优路径的联合决策。依据信息收集和决策方式,算力路由可分为集中式方案和分布式方案。
图5为集中式算力路由方案,涉及到SDN、基于IPv6的分段路由(Segment Routing IPv6,SRv6)等技术。其中,SDN控制器负责收集算力信息、网络信息和业务需求信息,依据上述信息进行路径和算力节点的联合决策,三个算力节点均能为用户提供算力服务。首先,基于上述信息,采用算力路由算法(如负载均衡算法、联合最短路径算法等)获得最优路径和算力节点。然后将上述信息下发至入口路由节点,采用SRv6协议将路径信息和目的节点信息写入IPv6包头。后续节点按照分段路由信息进行报文转发。该方案能够实现业务粒度的路径编排和节点决策,能够更好地满足业务需求,改善网络性能。如图6所示,相较于传统仅考虑网络距离的传统路由算法,如开放式最短路径优先(Open Shortest Path First,OSPF),基于SRv6的算力路由能够实现更低的平均时延。
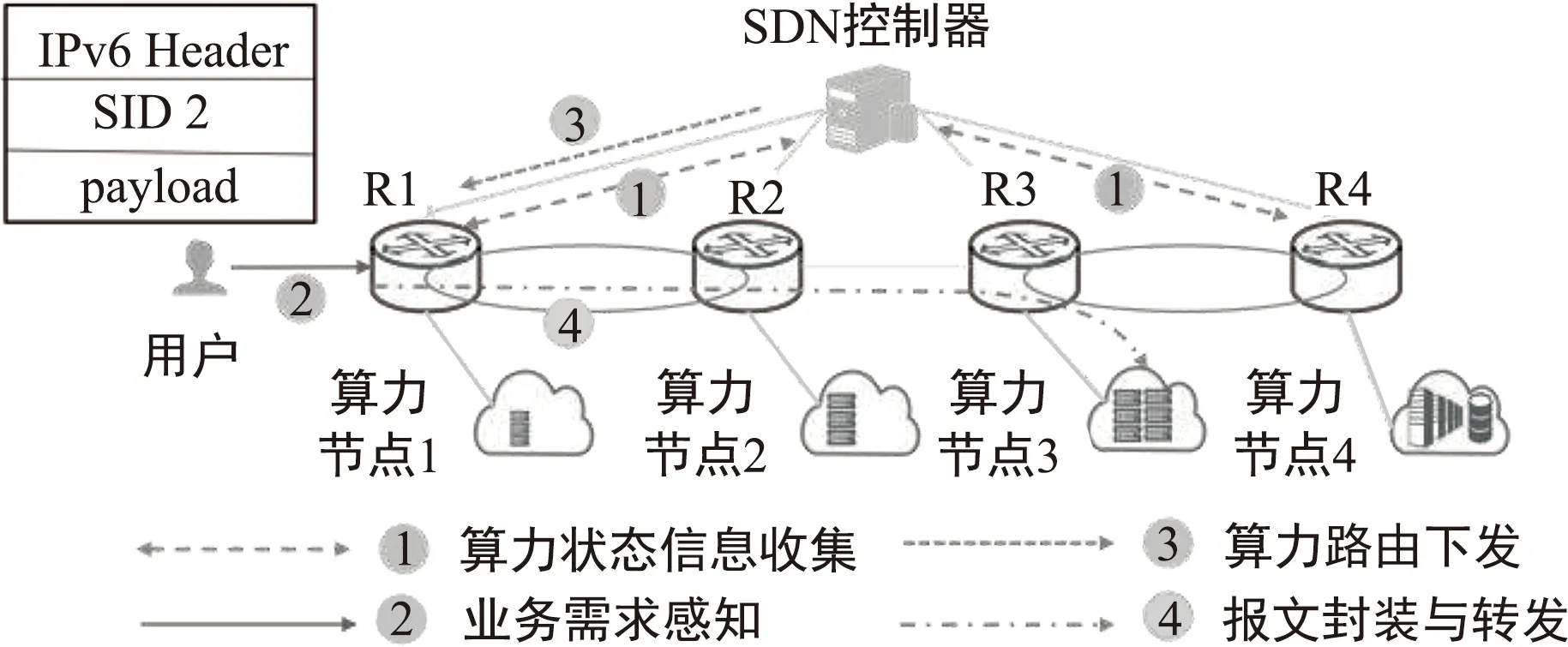
图5 集中式算力路由方案

图6 传统路由与算力路由性能对比
分布式算力路由方案如图7所示。在算网资源感知方面,可以通过telemetry实现网络状况感知,如带宽、时延、抖动等。算力状况以探针或者主动上报的形式上传至算力路由,算力路由汇聚本域所有算力节点的算力状况,如节点服务能力,并进行SID与BIP绑定,将相关信息存储至算力路由。为实现全网算力感知,算力路由可将上述算力状态信息通告至邻近算力路由节点或者广播至全网算力路由节点。为降低算网感知所带来的通信开销,亦可将算力状态信息打包至数据包内,进行随路算网状况监测。在计算服务执行过程中,根据获取到的算网资源信息,算力路由更新其路由表,其中联合距离依据网络状态和算力状态联合计算,下一跳地址依据最短联合距离进行修改。当用户请求某项服务时,按照算力路由表进行转发即可。为降低任播路由对路由表的影响,入口算力路由可将源IP地址修改为入口算力路由IP地址,目的IP地址修改为出口算力路由地址,此处依据最短联合距离决定出口算力路由节点。出口算力路由接收到数据包后,将目的IP地址修改为SID所对应的单播IP地址,然后将数据包转发至相应的算力节点。
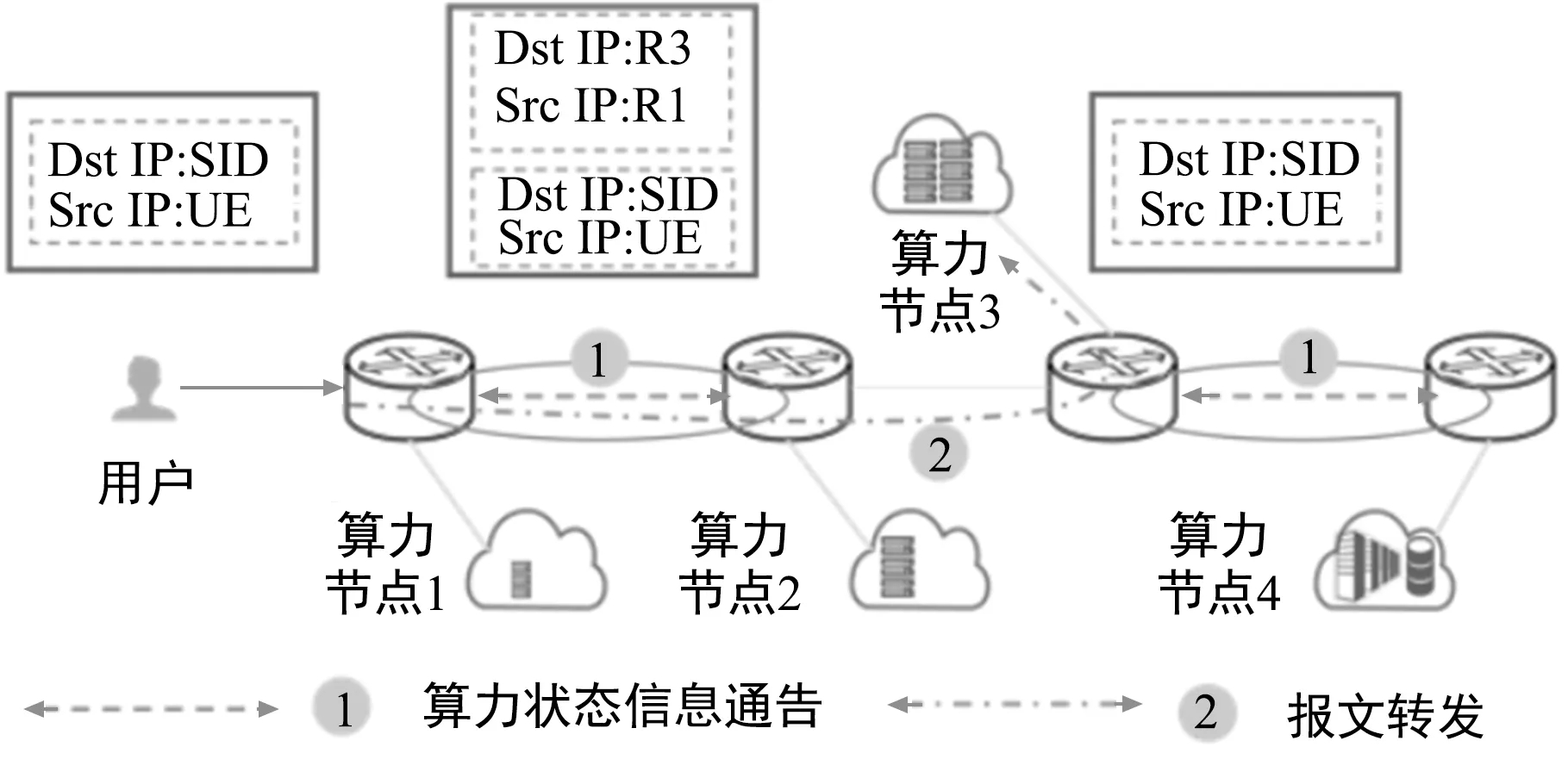
图7 分布式算力路由方案
3.3 业务感知的算力调度
在算力网络中,计算节点具有体量小、能力异构、高分散、高动态等特征。业务多样,对网络和算力需求不同。同时,业务表现出潮汐、突发、故障等多种模式,导致算力节点在时间和空间尺度上负载不均衡。因此,对业务进行感知,以及算力服务的部署/迁移和相应的编排,并将计算任务调度到合适的算力节点,是改善业务服务质量和提高算力利用效率的关键。
业务感知的算力调度流程如图8所示。区域内的业务呈现出明显的潮汐效应,比如商业区和住宅区由于用户的行为模式,造成业务负载随着时间周期性地动态变化。在业务感知机制上,管理编排平台基于人工智能的业务预测算法,将历史信息作为输入,对业务模型进行训练,从而预测业务行为,比如流量、用户移动性等业务信息,用于相关的服务部署和迁移。在业务预测算法上,可将数据上传至管理编排平台以集中式方式进行训练构建出业务预测模型。考虑到区域间业务流量的差别,统一的业务预测模型在应用时准确度会有所下降。针对该问题,可由局部算力节点进行再训练,对模型进行修正。针对算力感知机制,可由上文中的算力感知方法实现。
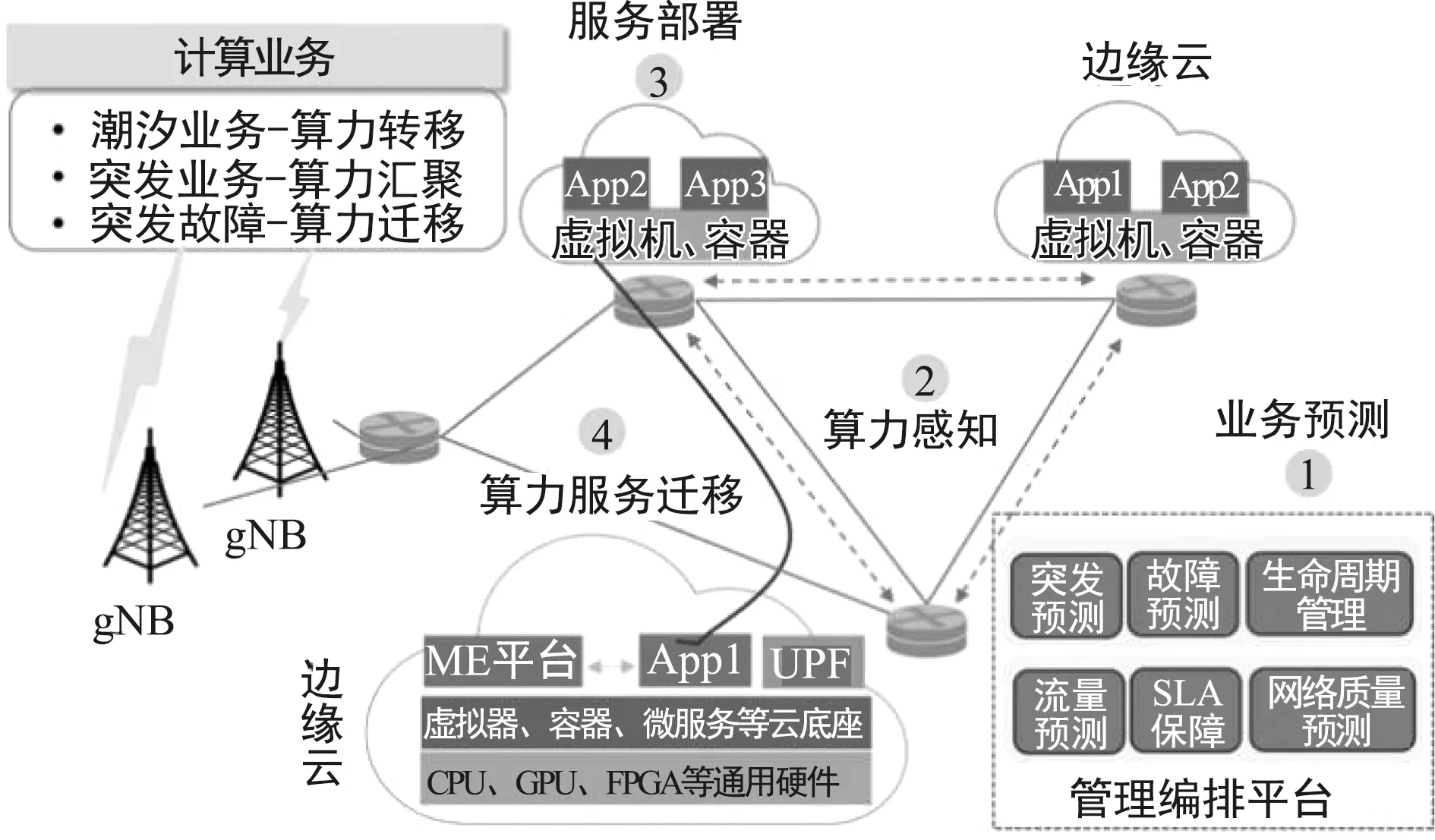
图8 算力调度流程图
以算力服务迁移为例,管理面在获取到所预测业务信息和算力信息后,进行集中决策,选择出满足要求的新算力节点并部署算力服务,然后进行相应的网络编排,修改相应接口和路由,以将后续相关业务路由至新算力节点,至此完成算力服务迁移。图9简要描述了管理面进行算力服务迁移的工作流程,描述了在移动边缘计算网络中算力服务由算力节点1向算力节点2迁移的过程。定义了业务预测功能和算力服务迁移决策功能部署方案,并增加了进行算力服务迁移决策的方案/标准。

图9 算力服务迁移流程
上述算力调度决策机制由管理面通过控制面应用于算力面,是一种集中式调度机制。上述算力调度亦可采用分布式机制,即控制面基于业务预测信息和算力信息进行服务部署决策,并将该决策交由管理面进行仲裁和相应的编排。
4 技术挑战与未来发展方向
4.1 网络架构
当前算力网络架构主要面对承载网,在功能设计上聚焦于对TCP/IP网络的改进。在算网编排上,算网大脑分别指挥算力资源管理平台和网络资源管理平台,并未实现真正的算网融合。此外,移动通信网络在网络云化、云网融合的趋势下,电信云亦可作为算力的提供者。然而,移动通信网络中的算力并未被纳入算力网络体系中,如核心网、接入网云化后的算力。移动通信网络作为通信网络的重要组成部分,在算力网络驱动下,如何应对算网融合趋势,是6G移动通信网络架构面临的一大挑战。
4.2 实时算力感知
算力感知是进行高效算力调度的基础,是算力网络的基础。一方面,算力信息高度时变,大规模的算力采集和通告将带来大量的信令和通信开销;另一方面,大规模算力通告将带来实时性问题,无法保障算力信息的准确性和实效性。另一种算力信息感知方式是通过人工智能算法对算力节点的负载进行时空刻画。然而,网络中存在频繁的算力调度,流量错综复杂,将对算力节点负载带来不可预测的影响,基于人工智能的算力感知机制的准确性亦无法保障。因此,如何进行实时高效的算力感知仍有待深入研究。
4.3 算力路由
集中式算力方案借助SRv6可编程能力能够实现数据包级别的网络和算力的联合优化,由于不需要修改现有路由协议,是算力路由近期落地的首选方案。然而,算力感知和算力路由决策均依赖于SDN控制器,控制器压力较大,尤其随着网络规模增大,该问题更加凸显。分布式算力路由方案需要改进现有路由协议,距离实际应用还有相当长的一段距离。此外,联合距离的计算问题以及任播技术的缺陷仍有待解决。
4.4 面向人工智能的算力调度
在算力服务部署完成后,仍需要相应的计算任务调度机制,保障用户的服务质量,如时延、计算效率等。该机制需要应对以下两种情况:① 当多个节点均部署有所需算力服务并且可独立完成用户的计算任务时,需要选择最合适的算力节点;② 针对复杂业务,如大规模人工智能训练任务,单个算力节点不足以支撑其算力需求,需要多个算力节点协作完成。针对情况①:可由算力路由方案以及相应的负载均衡算法解决。针对情况②:用户提供算力服务其服务流不再具有“端到端”的传输模式,一种可能是通过管理面进行编排,一定范围内的算力节点或者网元节点按照预设的规则和流程进行交互和协作训练,从而完成人工智能训练任务。在该过程中,由于人工智能数据的传输模式、数据类型、对网络链路的要求以及参与节点的计算性能对人工智能训练的性能影响与传统业务不同,如何保障人工智能训练的性能需求有待深入探索。
5 结论
6G通感算融合已成为6G网络长期发展的方向,且与6G网络“内生智能、数融、开放、安全”等愿景一致。随着XR、自动驾驶、元宇宙等通感算融合应用的发展,算力网络可以为智慧城市、智慧电网、工业互联网提供强有力的性能保障,大力推动产业化升级和数字化转型。算力网络建设是一个长期、不断演进的过程,尽管当前算力网络已有一部分研究,在网络架构、关键技术等方面仍面临着诸多挑战,需要运营商、设备提供商、应用开发商、科研机构和高校的共同努力,突破网络架构和关键技术等方面的瓶颈问题。
