GAN模型研究综述
2023-02-08刘鹤丹赵旭磊叶汉平
刘鹤丹,赵旭磊,叶汉平,王 健
(1.厦门大学嘉庚学院 信息科学与技术学院,福建 漳州 363105;2.中国船舶第七六〇研究所 海上试验测绘中心,辽宁 大连 116000)
0 引 言
近年来,研究人员一直在努力提升计算机的自主学习能力,计算机学习逐步进入了人工智能阶段。人工智能作为一门交叉性强的学科,致力于使计算机可以模拟人类的学习方法。在常见的机器学习模型中,大部分模型是需要监督学习的,而监督学习需要收集大量的数据集才能得到较好的训练结果,并且数据集的标注往往是需要通过人工的手段,这无疑会提高人工成本。在2014年,生成对抗网络模型GAN的出现为解决该类问题提出了很好的方案,GAN拥有无监督学习和优越的样本输出等优势,受到大批学者的喜爱,特别是在图像生成和目标检测等领域得到了广泛的应用与发展。
1 基本理论
1.1 理论基础
GAN采用博弈论中零和博弈的思想[1],其中包含两个模型:生成器和判别器。生成器会生成一系列的样本欺骗判别器,而判别器的目的是识别出这些样本的真实性,在两者的对抗过程中,会不断地提升模型的效率,直到生成器可生成能够欺骗判别器的样本为止,此时达到纳什均衡[2]。
1.2 GAN模型的两个基本要素
GAN模型[3]包含生成式模型G和判别式模型D(以下生成器与判别器均用G和D替代),G从统计学的角度直观地展示了数据分布情况,并对其进行建模P(X|Y),再通过贝叶斯公式进行预测,最后根据训练数据学习联合概率分布P(X,Y)。模型对比情况见表1所列。

表1 模型对比情况
2 GAN模型的发展历程
经典GAN网络架构如图1所示,两个神经网络G和D构成了一个动态博弈的过程。G和D使用联合损失函数,其中x表示真实数据,D(x)是每个图像x的单个标量值,表示此图像x是来自数据集的真实图像的可能性。此外,噪声z的发生器输出的G(z)、D(G(z))是鉴别器对假实例的真实概率的估计。EZ是G的所有输入的预期值。生成器G试图最小化函数,而D试图将函数最大化。优化目标公式如下:

图1 经典GAN架构
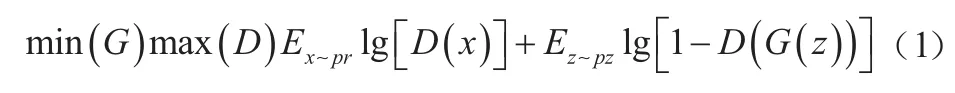
2.1 DCGAN:深度卷积GAN
DCGAN(Deep Convolutional Generative Adversarial Networks)[4]于2015年被提出,其架构如图2所示。对GAN架构进行了三方面改进:(1)代替空间池化函数为步幅卷积,允许网络对自身空间下采样学习,允许D对自身空间上采样学习;(2)最顶层的卷积后面消除全连接层;(3)批处理规范化。其中G使用了卷积神经网络,除了最终输出层使用了tanh,其余使用激活函数ReLu,模型目标是最小化判别网络的准确率。DCGAN的Generate网络结构如图3所示。D同样使用卷积神经网络,使用的激活函数是Leaky ReLu,以实现最大化判别网络的准确率。
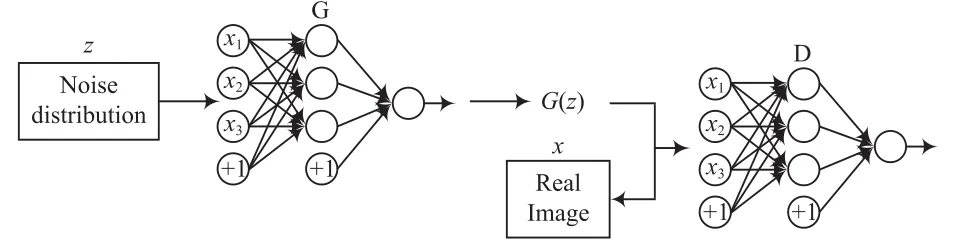
图2 DCGAN的网络结构
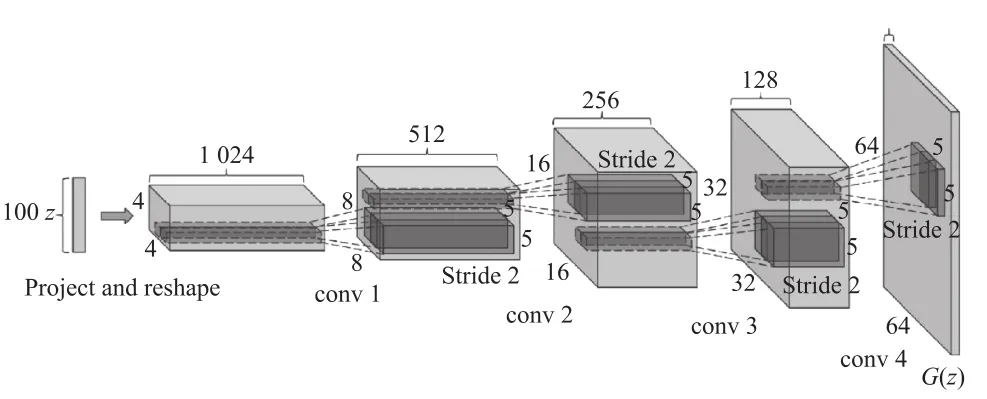
图3 DCGAN的Generate网络结构
2.2 CGAN:条件GAN
Mirza等人[5]提出了两个问题:如何扩大已有模型以适应预测的大量输出类别,如何实现GAN从一对多的映射;同时提出了CGAN(Conditional Generative Adversarial Networks)模型。该模型结构额外为生成器和判别器增加了条件y(表示希望生成的标签)。D会生成符合条件y的样本,而G会对生成的图像进行判断,判断是否符合条件y和是否具有真实性,并会对后续的优化目标公式进行相对应的优化改进。
2.3 SGAN:半监督GAN
Denton 等人[6]在2016年提出SGAN(Semi-supervised learning GAN),训练时可通过少量带标签的数据配合无标签数据。该模型结构解决了一个半监督分类任务的同时还学习一个生成模型;在数据集上学习G的同时训练一个图像分类器C;共享了D和C之间的部分权重,一些权重专属于D,一些权重专属于C;让GAN生成带类别标签的样本,要求D/C指派标签。
2.4 InfoGAN:无监督GAN
针对传统GAN使用高度混杂的模型和随机噪声z,但不能显式地表示真实数据空间下的属性或特征的问题,Chen等人[7]提出InfoGAN以无监督方式学习隐空间下非混杂方式的真实特征表示。将随机噪声分成不可压缩部分z和可解释的隐编码c。Generate(G)表示为G(z,c),通过最大化c与生成数据x之间的信息来防止GAN在训练过程中忽略c的特征表示能力,并增加c和G(z,c)之间的互信息I(c;G(z,c))为约束。
2.5 WGAN
Arjovsky等人[8]针对训练梯度不稳定、生成样本单一、模式崩溃、梯度消失等问题提出了四点改进措施:去除D最后一层的sigmoid,G和D的损失不再取对数,在更新D的参数后截断其绝对值到固定常数c下,使用RMSProp、SGD等算法替代基于动量的优化算法。
2.6 SAGAN:自我注意生成对抗网络
Zhang等人[9]指出先前的模型过分使用卷积来模拟不同图像区域之间的依赖,导致传统卷积GAN存在一些问题,因此提出SAGAN。将self-attention机制加入传统的卷积GAN,该机制在模拟远程依赖、计算和统计时有更加出彩的表现,能够更好地处理长范围、多层次的依赖,生成图像时做好每一个位置的细节和远端的协调。此外,D能够更精准地对全局图像使用几何约束。
2.7 BigGAN:大型生成对抗网络
针对GAN难以实现从复杂数据集中生成高分辨率、多样化样本的缺点,Brock等人[10]提出了BigGAN,该模型增大了BatchSize和channel number,采用“截断技巧”等,用原有GAN的8倍batch size大小,将隐藏层变量数量扩充到原有模型的4倍进行训练,获得了很好的效果。
2.8 StyleGAN:基于风格的生成对抗网络
2017年NVIDIA提出了ProGAN[11],该模型采用渐进式训练,解决了高分辨率图像生成困难的问题,但控制生成图像的特定特征能力有限。Karras等人[12]提出了StytleGAN,每一层视觉特征都可以通过修改该层的输入来控制,且该过程并不受其他层级的影响。StytleGAN的模型结构除了采用传统的输入,将一个可学习的常数作为生成器的初始输入,还采用8个由全连接层所组成的映射网络来实现输出的w与输入的z大小相同;引入样式模块(AdalN),将w通过卷积层的AdaIN输入到生成网络中;添加尺度化噪声到合成网络的分辨率级上,然后通过输入层输入到G中;对G使用混合正则化,对训练样本使用样式混合的方式生成图像,在训练过程中使用两个随机隐码z,而不是一个,在生成图像时会在合成网络上随机地选择一个点,实现一个隐码到另一个隐码的切换,并且加入感知路径长度和线性可分性两种新的量化解耦方法。
2.9 EigenGAN
He等人[13]提出了通过明确的维度来控制特定层中语义属性表示的EigenGAN模型,可无监督地从不同生成器层挖掘可解释和可控的维度。EigenGAN将一个具有正交基础的线性空间嵌入到每个生成器层;在对抗训练中,这些子空间会在每一层中发现一组“特征维度”,对应一组语义属性或可解释的变化。
2.10 ICGAN
GAN所生成图像与训练的数据集密切相关,这导致生成的图像存在局限性。而Casanova等人[14]提出ICGAN(Instance-Conditioned GAN)模型,可生成逼真且与训练集图像不同的图像组合。对于每个训练的数据点,采用参数化的混合形式对其周围密度进行建模处理;模型引入了一种非参数化方法对复杂数据集的分布进行建模,使用条件实例和噪声向量作为神经网络的输入,并且隐式地对其局部密度进行建模。ICGAN中,G与D可以联合训练,都参与了一个两者最小-最大博弈,在博弈中找到纳什均衡。
2.11 TransGAN
近年来,Transformers[15]在NLP领域大放异彩,TransGAN的研究者将Transformers结构作为GAN的主结构,并完全抛弃了CNN结构[16]。实验表明,采用Transformers作为GAN模型的主体结构在其性能上几乎能够匹敌目前最好的GAN模型。
2.12 OUR-GAN
针对传统的生成模型很难生成视觉上连贯的图像问题,Yoon等人[17]提出了OUR-GAN模型,用低分辨率生成视觉上连贯的图像,应用无缝衔接的子区域超分辨率来提高分辨率,解决了边界不连续问题,通过向特征图添加垂直位置嵌入来提高视觉连续性和多样性。
2.13 P2GAN
文献[18]提出了P2GAN(Posterior Promoted GAN),该模型采用D生成的后验分布的真实信息来提升G,并且通过将图像隐射到多元高斯分布来提取出真实的信息;G则使用AdaIN后的真实信息和潜码提升自身。
2.14 Inclusive GAN
文献[19]提出了Inclusive GAN模型,通过有效融合对抗模型与重建模型提升对少数样本群体的覆盖能力,提升了模型的包容能力。引入IMLE重建方法调和GAN,使其成为IMLE-GAN,综合了两个模型的优劣,保证了数据的覆盖性,有效提升模型整体的覆盖能力且更适应了对少数群体的包容能力。
2.15 MSG-GAN:多尺度梯度生成对抗网络
许多GAN及其变体模型很难适应不同的数据集,当真实分布和生成分布的支撑集不够重叠时,判别器反馈给生成器的梯度无法提供有益信息。文献[20]提出了MSG-GAN,可多尺度地提供梯度给D和G。
3 GAN的优劣
3.1 GAN的优势
GAN作为生成式模型,结构简单,不需要类似GSNs的马尔科夫链,只是用到了反向传播,其创造的数据样本远远优于其他的生成模型。这表明GAN可以训练任何形式下具有非特定目的生成网络;GAN的学习方式为无监督式学习,该方式被广泛应用于无监督和半监督学习领域,其训练方式不需要推断隐变量;对比VAEs,GANs尚未引入决定性偏置,也没有变分下界,因此GANs的生成实例相比于VAEs更为清晰。如果D训练妥善,那么G将会得到完美的训练样本分布。GANs的生成过程是渐进一致的过程,而VAE有偏差。
3.2 GAN的劣势
GAN普遍存在评价指标和梯度消失、模式崩溃、训练不稳定等问题。对于如何实现GAN在训练中达到纳什均衡,目前还没有较好的方法。虽然可以通过梯度下降法实现,但会导致其缺乏稳定性;GAN不适合处理文本类的离散型数据,因为通常需要将一个词映射为一个高维向量,当G向D输出结果不同时,D均会返回同样的结果,导致梯度信息不能很好地传递到D中。此外,GAN损失函数为JS散度,并不适用于衡量不相交分布之间的距离。
4 结 语
生成对抗神经网络是当下人工智能领域的前沿。越来越多的研究人员开始在这一领域进行挖掘,并产生越来越多的高效率模型。本文从介绍GAN模型的生成器和判别器出发,阐述了GAN模型的基本原理,并通过典型的GAN变体模型展示了GAN的发展历程。GAN目前仍面临着许多挑战,但值得期待。
