组合深度残差网络手势识别
2023-02-08位政贤
位政贤
(桂林电子科技大学,广西 桂林 541000)
0 引 言
手势识别作为一种更自然、更直观的人机交互方式,融入了人们的生活。按照识别设备与身体接触与否分类,手势识别技术又可分为接触式手势识别和非接触式手势识别[1]。接触式手势识别需要一些设备(如数据手套),优点是准确率高,缺点是成本高、操作繁琐,用户使用前需要学习校准,交互不够自然,制约了推广和使用[2]。而非接触式手势识别优点明显,尤其是视觉手势识别[3]。基于视觉的手势识别设备简单,能够满足人机交互对自然性的要求,具有非常广阔的应用前景。因而本文采用了单目视觉手势识别技术。
传统的视觉手势识别过程分为:手势跟踪和手势分割、手势建模、特征提取和手势识别。手势识别的算法是研究的关键部分,识别算法可分为基于模板匹配的方法、基于数据分类的方法和基于深度学习的方法[4]。传统的手势识别方法中使用最普遍的模板匹配算法是动态时间扭曲(DTW)法;数据分类方法包括人工神经网络(ANN)、隐马尔可夫模型(HMM)、支持向量机(SVM)等方法[5]。传统的手势识别使用人工标定来提取特征,准确率受到标定人员熟练性和其他因素的影响,准确率较低[6]。因此引入深度学习方法,它是大数据与人工智能领域成功结合的成果[7]。深度学习通过卷积神经网络对大量图像进行多次训练,利用卷积模型自动提取和处理目标图像中的特征[8]。深度学习是无监督学习,可以智能提取需要的图像特征信息,也可以自动获取更高层次的特征,克服了人工提取特征的主观性和局限性的缺点[9]。基于深度学习的手势识别,根据处理时间维度的不同方式,可以进一步分为卷积神经网络、三维卷积神经网络(3DCNN)和序列模型等[10]。
深度学习弥补了传统机器学习中提取特征的不足,并且以VGGNet、GoogleNet、ResNet等为代表的卷积神经网络(CNN)模型在图像处理、音频处理等领域具有良好的性能[11]。卷积神经网络(CNN)是一种深度学习的网络结构,由卷积层、池化层和全连接层等组成[12]。吴晓凤等人[13]通过基于Faster R-CNN的卷积神经网络实现手势识别,修改了框架的关键参数以达到目的[14]。但存在的问题是它容易受到外界环境的干扰,并且光照条件和人类皮肤颜色对分类准确性的影响较大,导致识别率和系统鲁棒性较低。尽管近年来基于深度学习的手势识别取得了较好的成绩,但是在针对环境变化和自遮蔽问题的静态手势识别开发中仍然存在重大挑战。
手势通常可以分为动态手势和静态手势。本文着重针对静态手势存在的准确率低等问题,做出了如下贡献:(1)解决了复杂背景下多个用户同时执行手势的手势识别问题;(2)将传统手势识别中的YCrCb肤色模型和深度学习结合;(3)对现有数据集进行预处理,并以ResNet-101作为训练网络,在大型ImageNet数据集中训练出预训练模型文件,接着使用迁移学习的方法搭建手势识别残差网络模型,以更好、更快地提高手势识别的准确性。
1 相关工作
随着人工智能的迅速发展,目前卷积神经网络(CNN)应用最为广泛。对于神经网络的发展,研究人员首先考虑的是增加网络的层数。例如,ImageNet竞赛中表现出色的卷积神经网络,2012年推出8层的AlexNet网络,2014年推出了16层的VGGNet以及22层的GoogleNet[15]。下面对深度残差学习、迁移学习、肤色建模工作进行具体的介绍。
1.1 深度残差学习
对于部分神经网络而言,理论上,网络层数越多所能提供的信息也就越多,特征也越丰富。然而,实践研究表明,随着网络的深入,梯度变得无限小,性能逐渐趋于饱和,优化效果变差,测试数据和训练数据的准确性下降。这种现象称为“退化”。文献[16]通过引入深度残差学习来解决此问题。残差网络的搭建可以减少训练参数和数据量。残差网络的学习模型如图1所示。
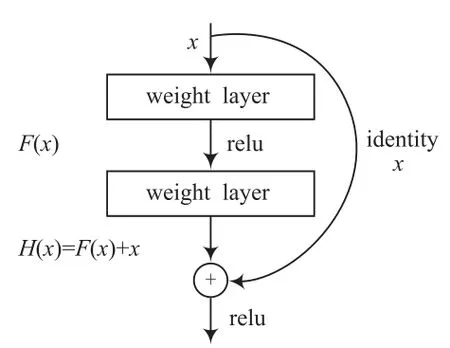
图1 残差网络学习模型
残差网络的思想是高速网络的跨层链接的改进:利用“shortcut connections(捷径连接)”的方法,把输入x直接传到输出作为初始结果输入到下方,输出结果为:

当F(x)=0时,H(x)=x。因此,ResNet学习目标通过H(x)和x的差值来实现改变,残差为:

另一种残差学习块是Bottleneck,如图2所示。3层的残差学习模块与2层不同的是第一个卷积层采用了1×1的卷积核来降维数据,经过1个3×3的卷积核,再经过1个1×1的卷积核恢复到原来的维度。这样做极大地减少了计算量,同时又能够较好地处理深层次网络。实验表明,这种残差块对于深层次网络训练有较好的效果。
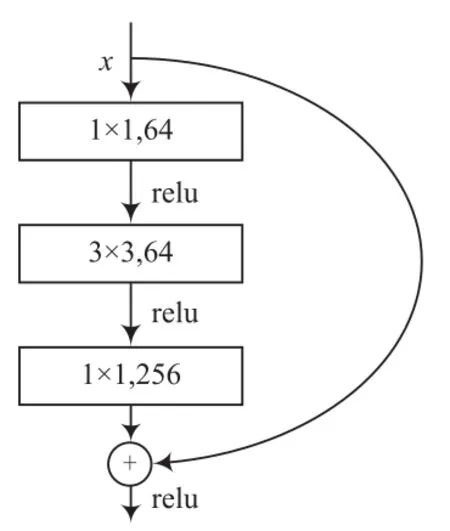
图2 ResNet-50/101/152构建模块
残差网络有多种不同的结构,如ResNet-50、ResNet-101和ResNet-152等。在本文中使用了三种不同的残差网络对手势图像数据集进行测试,以分析不同残差网络模型对手势识别结果的影响。
1.2 迁移学习
迁移学习是先在一个基础的数据集上训练任务,生成一个基础网络权重文件,然后把学习到的特征重新进行调整或迁移到另一个相似的目标网络上,使用目标网络的数据集进行训练。学习到的特征保存为一个网络文件,即一个预训练模型。迁移学习的方法是一种优化方法,既节省了时间,又能够有更好的性能表现。有效的学习迁移学习方法是删除输出层并将整个剩余网络视为特征提取器,即对预训练模型进行部分的训练,将模型的部分层锁定,保持其不变,对未锁定的层重新训练来获得新权重。迁移学习方法有三种:第一种方法是官方提供的预训练网络模型ResNet-101权重,保持原网络不变,再添加一个全连接层,训练这个全连接层;第二种方法是冻结网络模型提取图像通用特征的层,重新训练学习特定的最后几层的参数;第三种训练策略是载入别人预训练好的模型之后,使用数据集训练提到的所有网络参数。
1.3 肤色建模
肤色建模是基于人的肤色和其他背景颜色之间的差异为输入的图像建立模型的过程。建立描述肤色的色度模型需要选择一个合适的色彩空间,在该色彩空间中肤色可以聚类在一起,并且与非肤色区域尽可能少地重叠。在本文中,使用YCrCb色彩空间,该色彩空间被CCIR601广泛用于数字视频中。由于该模型将肤色点和非肤色点彼此分离,并克服了图像RGB空间中通常存在的离散肤色点和肤色区域噪声的问题以及环境光线的干扰问题,因此被广泛用于人体的定位以及脸部和手部等身体部位识别。YCrCb颜色空间和RGB颜色空间的对应关系如下:

进行这种映射的主要原因是人类视觉系统对色度中的高频分量不那么敏感。但是这种肤色建模存在一些缺点,因此需要使用YCrCb色彩空间进行转换,以消除色度对亮度的依赖性。色度Cr和Cb受亮度和二维独立分布的干扰较小,并且肤色聚类投影在Cr-Cb上的近似椭圆区域中。该算法可以检测到人体所有裸露部分的皮肤,例如手臂和脸部区域,并使皮肤的色点集中形成一个连通区域,从而为进一步的手势识别奠定了良好的基础。但是,由于一些多余的肤色信息将具有相同的检测性能,因此在肤色建模之前需要遮盖诸如面部之类的近肤色信息。
2 实验部分
结合上述算法研究,本文的技术路线如下:首先,将残差网络用于迭代训练以生成权重文件,并使用来自NUS Hand Posture的静态手势数据集,该数据集涵盖了6种手势(从0到5),训练集中有5 707个手势图像,测试集中有480个手势图像。在手势识别系统中使用训练生成的权重文件。本文的技术路线如图3所示。
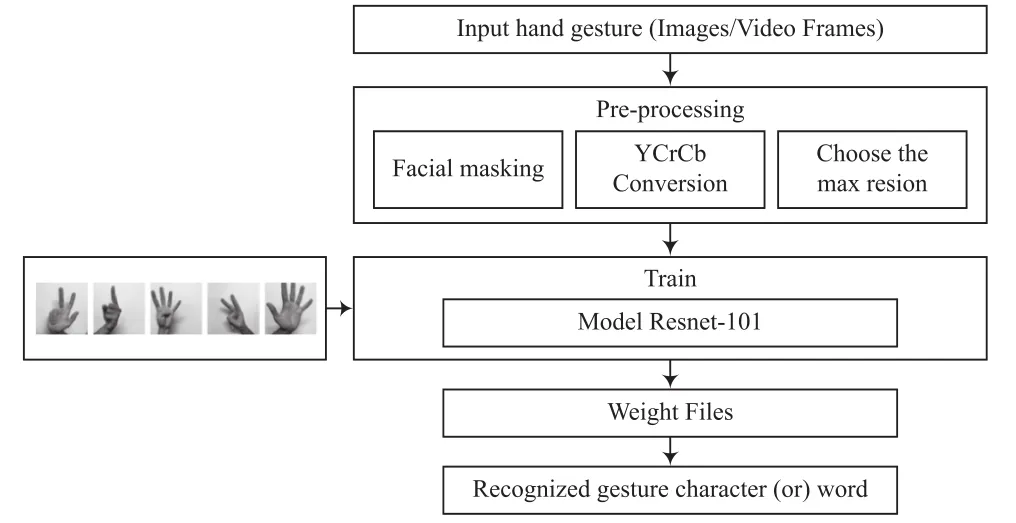
图3 技术路线
手势识别系统通过摄像头获取手势图像,使用OpenCV附带的功能遮盖脸部等近皮肤颜色部分,将处理后的图像转换为YCrCb皮肤颜色空间,并分离手部皮肤,在对皮肤进行颜色建模后从背景中提取颜色区域;然后按大小对所有分离的手部图像进行归一化处理,并依次使用先前训练过的手势数据权重文件进行预测,以进行正确的手势分类。
本文中的数据集较少,只有5 000张照片,数据集背景单一、数据之间具有高度相似性。在这种情况下,使用迁移学习方法不会要求重新训练模型。
第一组实验是对不同的迁移学习策略进行比较。本文通过对三种训练策略的比较,最终选择了第一种训练策略,所使用的预训练模型是ResNet-101官方提供的Slim框架预训练模型。实验发现,第一种迁移学习方法能够较快较好地达到实验的最好效果。因此,将输出层更改为与分类情况相匹配的结构,本文使用在ImageNet上训练的模型对6个手势进行了分类(从0到5),从而更改了密集层的输出以及最终的softmax从原始类别数到目标类别数。第二组实验是对 AlexNet、VGGNet、GoogleNet、ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152共8个网络模型的效果进行对比。由于这些网络模型很难同时获得最佳条件,因此本文对相同实验环境中的多个实验进行了比较分析,保持实验条件一致,并以网络分类测试的准确性为标准。第三组实验比较了5种常用的优化算法,例如Adam、SGD、Ftrl、Adagrad、Adadelta。在第二组实验中,每个特定实验组的测试准确性见表1所列。其中ResNet-101的精度略优于其他网络。
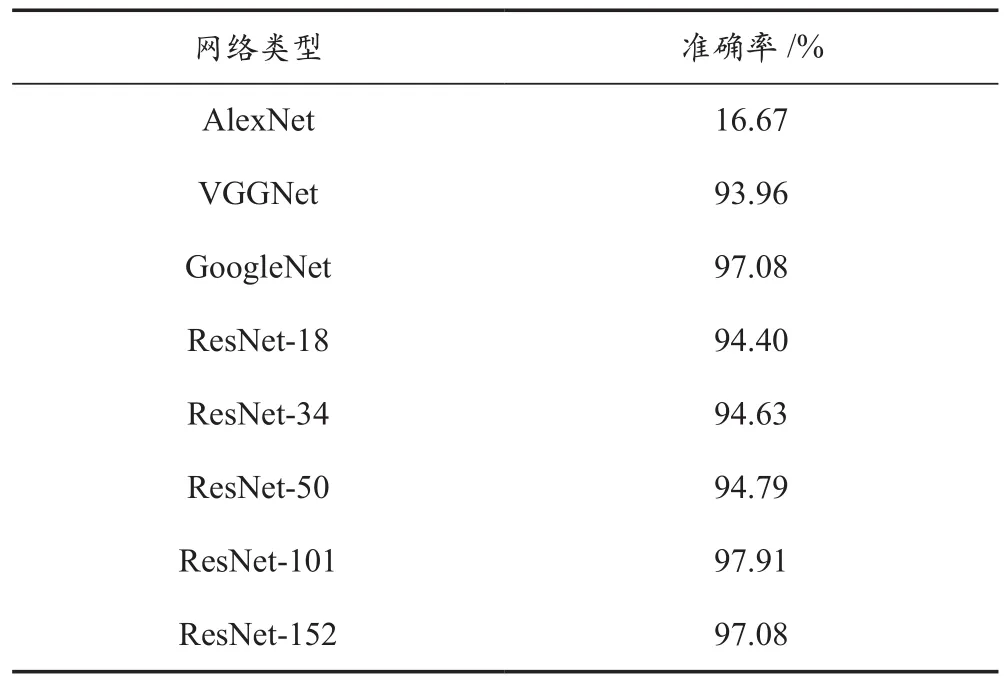
表1 测试准确性
第三组实验的结果如图4所示,可以看出,Adam的优化效果明显,并且可以在短时间内达到稳定的精度。
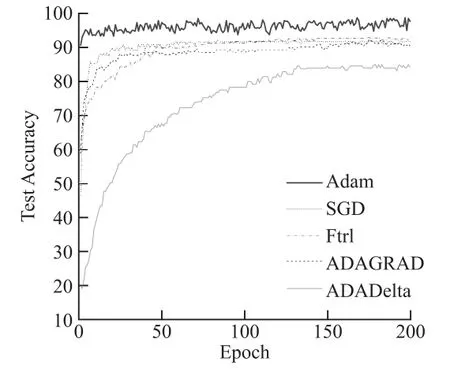
图4 优化方式对比
3 结 语
卷积神经网络利用多层神经元的拼接来提取不同级别的特征,并不断迭代以将它们组合成进一步的层次特征。与传统的人工提取特征方式相比,它具有更强大的特征表示和泛化能力。然而,神经网络层次的渗透带来了两个问题:一个是训练过程中由于神经网络导致的梯度消失和梯度爆炸问题;另一个是网络模型结构变得复杂,需要大量的计算和内存,实时性无法满足要求。针对深度卷积神经网络随着卷积层数的增加而难以训练和降低网络模型性能的问题,提出了一种基于深度残差网络模型的手势检测方法。模型权重文件是通过训练和验证从0到5的5 707个手势图像的实验数据集而生成的。本文在采集的手势图像中遮盖皮肤颜色类似部分(例如脸部等区域),在遮盖的遮罩上呈现YCrCb皮肤颜色处理后的图像,将处理后的图像中的手部区域修剪和缩放为指定大小,并使用生成的模型权重文件执行分类过程。实验的准确性较之前的系统有了很大的提高。尽管如此,本文提出的手势识别算法依然存在一些缺陷。例如,由于条件的限制,简化了实验中使用的手势数据集的背景,并且该算法的数量和类型需要拓宽手势。还应提高手势识别分类的准确性,以更好地应用于实际生产生活中的人机交互。
