基于Transformer与自适应空间特征融合的群猪目标检测算法研究
2023-02-07耿艳利林彦伯付艳芳杨淑才
耿艳利 ,林彦伯,付艳芳,杨淑才
(1. 河北工业大学人工智能与数据科学学院,天津 300130;2.智能康复装置与检测技术教育部工程研究中心,天津 300130;3.河北省畜牧总站,石家庄 050035;4.天津魔界客智能科技有限公司,天津 300130)
我国精准畜牧业发展尚处于初级阶段,生猪养殖过程中对猪只状态和行为监测主要以人工为主,增加养殖管理成本,且存在人畜交叉感染风险[1-2]。2020年国务院办公厅《关于促进畜牧业高质量发展的意见》中明确提出,畜牧业需要提升智能化水平和动物疫病防控能力,加强大数据、人工智能、云计算、物联网等技术应用。深度学习目标检测技术可提供无接触式群猪监测方法,但算法存在精确度不高和模型占用内存大等问题,应用于实际工程存在困难。
在图像处理领域中,卷积神经网络(Convolutional Neural Network,CNN)表现出色[3-4],CNN 作为特征提取器已在R-CNN[5]、SPP-NET[6]、Faster R-CNN[7]、Mask R-CNN[8]、YOLOv3 等目标检 测 算法中应用广泛。学界将基于深度学习目标检测算法应用于猪只个体目标检测[9-12]。
刘岩等采用两阶段算法,利用生猪图像BING特征训练两级线性SVM 模型产生高质量候选区域,再训练CNN 网络模型进行分类,最后使用非极大值抑制方法保留得分较高窗口[13],其平均检测时间为0.71 s,检测速度远低于常用目标检测算法。Martin 等利用 2D 摄像机和 Faster R-CNN 检测网络检测生猪位置和姿态,平均检测精度达到80.2%[14]。Cowton 等利用 Faster R-CNN 模型检测生猪位置,精度达到90.1%,满足试验预期[15]。高云等在Mask R-CNN基础上建立PigNet网络,可对不同形态、粘连严重群猪图像准确分割出独立猪只个体目标[16]。胡志伟等在HTC模型中引入双重注意力单元使平均精确度达到93.3%[17]。但上述两模型均以Mask R-CNN为基础,存在占用内存较多和检测速度慢等劣势。房俊龙等以CenterNet 为基础结构,引入MobileNet 作为模型特征提取网络降低模型大小并提高检测速度[18],平均精确度未明显提升。苏恒强等针对图像光照强度、猪只种类颜色、障碍物遮挡等干扰,提出基于YOLOv3的生猪目标检测方法[19],在模型大小方面未改进。
CNN 缺乏对图像全局理解,识别精度难以提高。Transformer由自注意力机制组成不受局部相互作用限制,可挖掘长距离数据依赖关系。Swin Transformer[20]是将Transformer 块中标准多头自注意力模块替换为基于移动窗口的多头自注意力模块。自适应空间特征融合方法将多尺度特征调整为相同分辨率,通过训练找到最佳的权重进行融合。本文提出一种基于Transformer与自适应空间特征融合的群猪目标检测算法,有助于智能化猪场建设,为养殖场动物计数和行为识别等方面提供技术支持。
1 试验数据
本研究群猪图像采集于天津市蓟州区新河口村养殖场(2021年10月16日10:00~16:30,天气晴转多云,光照偏弱,室外环境,温度8~15 ℃),选取长白猪品种作为拍摄对象。养殖场中单个猪栏长×宽分别为4 m×2.7 m,每个猪舍生猪数量4~11 头。选取其中2栏约90日龄、质量平均为50 kg的育肥期猪只共计22头作为试验对象。如图1所示,将带有IMX219模块的Jetson Nano开发板悬挂固定在斜侧方位采集猪群视频,拍摄得到视频总时长为260 min。原始视频格式为MP4,分辨率(帧宽度×帧高度)为1 280像素×720像素,帧速率29.9帧·s-1。

图1 猪只图像信息采集现场Fig.1 Pig images information collection site
1.1 关键帧提取
为防止数据重复冗余,对视频进行关键帧提取。首先将采集视频数据转换成图像序列;其次采用关键帧提取法提高数据集质量;最后将序列图像中每一帧区分为关键帧和正常帧。关键帧是猪只姿势发生变化的图像,通常包含较多运动信息,其余图像为正常帧。借鉴绝对直方图差分法[21],本文将图像直方图特征以余弦相似度来创建连续帧簇,检查新帧是否与最后形成簇相似,选择簇中最后添加帧作为关键帧。其中余弦相似度的阈值为0.9,保留3 465张作为初选数据集。
1.2 数据集构建
初选数据集中图片存在模糊现象,利用拉普拉斯算子进行图像预处理,删去目标不清晰图像[22]。将RGB 图像转换为灰度图,再经拉普拉斯算子卷积运算与图像灰度均值方差,该方差定义为图像清晰度。依据经验图像清晰度,阈值取60,超过这个阈值定义为清晰图像,保留2 400张图像作为数据集。采用Labelme图像标注工具并以矩形框标注猪只外轮廓,生成json 文件后转换成符合VOC数据集格式的xml 文件。COCO 数据集试验表明,数据增强将检测精度提高2.3%。为提升模型泛化能力进而提高检测精度,利用数据增强技术扩充样本。将上述数据集利用Albumentations 库作翻转、随机旋转、增加噪音等方法进行数据增强处理,增强图像如图2 所示。新数据样本共计9 600幅,按8∶1∶1划分为训练集、验证集和测试集。

图2 图像增强示例Fig.2 Sample images of image enhancement
2 群猪目标检测算法
2.1 Swin Transformer网络模型
Swin Transformer 网络(ST)模仿 CNN 分层结构。在初始化阶段,将图像分割成小块,将相邻小块合并到下一个Transformer 层中,如图3 所示,利用非重叠窗口计算自注意力降低,计算复杂度。这种划分会减少窗口之间的连接,因此模型采用平移窗口方法,增强窗口之间信息联系。

图3 分层特征图和平移窗口方法Fig.3 Hierarchical feature map and shifted window approach
ST 网络架构中包含Patch Partition 层、Patch Expanding 层、Patch Merging 层 和 Swin Transformer层,其中Patch Expanding和2个Swin Transformer层组成第1 阶段,Patch Merging 层和多个Swin Transformer 层组成第2、3、4 阶段。首先将尺寸为H×W×3(高度×宽度×通道数)的图像数据经过Patch Partition层的切片操作输出,然后经过第1~4阶段的特征提取模块,将第2~4阶段输出的特征图作为最终结果,其特征图尺寸分别为。ST网络架构如图4 所示,其中C 是通道数。Patch Partition层进行切片操作,分辨率降低到原来的四分之一,将损失的像素信息补充到通道。Patch Expanding 层不改变特征图高度和宽度,只将通道数映射成C。Patch Merging 层用于将分辨率降低二分之一且通道数增加1倍。
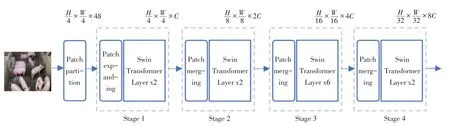
图4 ST网络架构Fig.4 ST network structure
Swin Transformer 层负责特征学习且不改变特征图尺寸。每个阶段中Swin Transformer 层个数必须是偶数,每层包括层归一化模块(Layer normalization,LN)、多头自注意模块、残差结构和多层感知器(Muti-layer perception,MLP)组成,如图5所示。多头自注意力模块是基于平移窗口构造,在连续两层中分别应用基于窗口的多头自注意模块(Window based Multi-head Self Attention,WMSA)和平移窗口的多头自注意模块(Shifted Window based Multi-head Self Attention,SWMSA)。每个阶段中具体步骤如公式(1)~(4)所示:
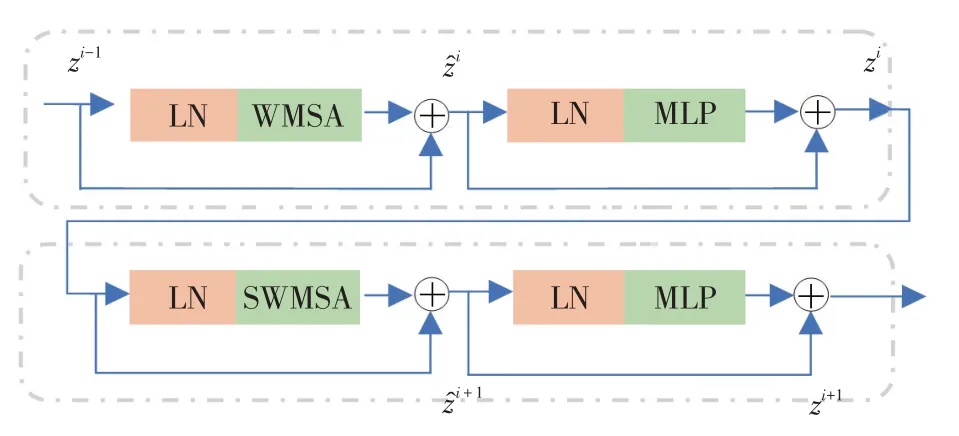
图5 连续的Swin Transformer层Fig.5 Successive Swin Transformer layers
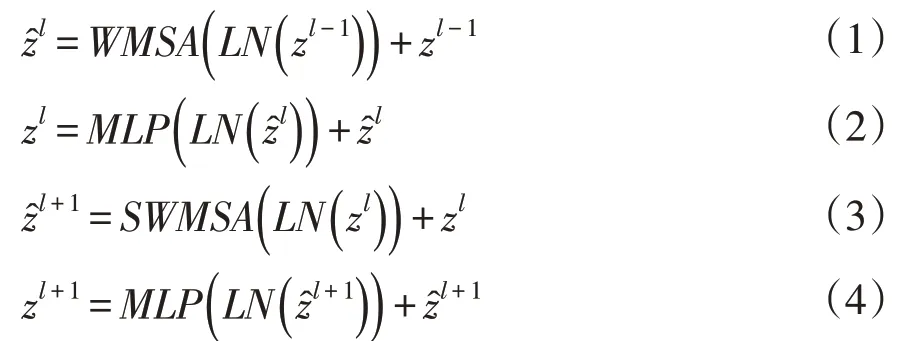
式中,zl-1表示第l-1层MLP输出特征,表示第l层 WMSA 输出特征,zl表示第l层 MLP 输出特征,表示第l+1 层 SWMSA 输出特征,zl+1表示第l+1层MLP输出特征。
2.2 特征提取网络
单阶段目标检测模型均由主干网络、特征融合网络、预测网络组成。主干网络输出由浅到深三种尺寸特征,浅层特征图分辨率较高,目标位置信息相对丰富,但语义信息不明显;深层特征图分辨率低,语义信息丰富,但丢失较多目标位置信息。因此,将浅层特征图与深层特征图进行信息融合更有利于目标区分。特征金字塔网络(Feature pyramid networks,FPN)从深层向浅层传递语义特征,解决浅层特征语义信息较差问题,保持浅层特征利于检测小目标优势,提高检测精度。
自适应空间特征融合(Adaptively Spatial Feature Fusion,ASFF)方法过滤各尺寸空间信息抑制不一致特征,提高检测精度且具有计算量小的优点。ASFF 关键是自适应学习各尺度特征空间权重,首先恒等缩放将不同尺寸特征图调整一致,然后计算各尺度权重,最后将权重值与调整后各尺寸特征图相乘得到融合特征。
2.3 改进预测框的损失函数
预测框回归指标常采用由预测框和真实框距离成本、重叠区域成本和纵横比成本组成的CIoU计算[23]。预测框在训练过程中靠近真实框方向不确定,收敛速度变慢且效率降低。SIoU 考虑回归方向成本,使预测框移动到最近坐标轴,随后延该轴方向靠近真实框,本文借鉴上述两种方法提出一种改进交并比计算方法RIoU,用于计算预测框回归损失值。
RIoU中的回归方向和距离成本计算公式:
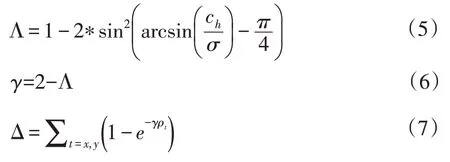
纵横比和重叠区域成本计算公式:

改进预测框损失计算公式:

公式(5)中Ch和σ分别是预测框与真实框中心点高度差和距离。公式(7)中ρx和ρy表示中心距离与外接矩阵对角线距离比值的平方。公式(9)中真实框的宽高用wgt和hgt表示,预测框宽高用w和h表示。公式(10)中B和BGT分别表示预测框和真实框。公式(12)中Lbox是改进后的损失函数计算方法。
2.4 本文算法
将单阶段目标检测模型作为基础架构,提出基于Transformer 与自适应空间特征融合的群猪目标检测算法TA-Net,该算法主干网络采用ST 模型,输出三层特征图;特征融合网络采用FPN+ASFF;预测网络采用核为1×1 的2D 卷积直接输出结果,模型结构如图6 所示。主干网络中窗口为13×13,通道数C 为32,ST 网络四个阶段中多头注意力头个数分别为4、8、16、32。模型训练中预测框损失采用RIoU计算。

图6 基于Transformer与自适应空间特征融合的群猪目标检测算法Fig.6 Pigs target detection algorithm based on Transformer and adaptively spatial feature fusion
3 试验平台参数及评价指标
3.1 试验平台
试验训练环境为Ubuntu16.04,硬件配置CPU为E5-2680 4 核,主频2.60 GHz,内存为32 GB,GPU 为 11G NVIDIA GeForce GTX 1080Ti。试验测试环境为64 位Windows10 操作系统,硬件配置CPU 为Intel(R)-Core(TM)i5-10200H,主频2.40 GHz,显卡为 4G NVIDIA GeForce GTX 1650Ti,内存为16GB。试验采用Python 编程语言,并在Torch 1.7.0 进行网络搭建、训练和测试,并采用正态分布对网络参数进行初始化。
3.2 评价指标
本文试验主要采用以下5个评价指标:精确率(Precision,P),召回率(Recall,R),平均精确率(Average Precision,AP),F1 分数(F1-Score),检测速度(Frames Per Second,FPS),模型大小(Model Size)。P、R、AP、F1的计算公式分别为:


式中,TP指图像中猪只目标被正确检测个数,FP指图像中非猪只目标被检测为猪只个数,FN指图像中猪只目标未被检测为猪只个数,AP指模型对猪只目标检测精度平均值,式(16)中dr表示积分变量用于求解[0, 1]区间P与R乘积积分值。
3.3 模型训练
图像在输入给模型前,尺寸调整为416×416×3,训练中采用余弦退火学习率策略和马赛克增强技术。每8 个样本作为一个批次,前100 个Epoch初始学习率设置为0.001,后100 个Epoch 初始学习率设置为0.0001。利用K 均值聚类算法(KMeans Clustering Algorithm)对猪只数据集的锚框作聚类分析,计算适合猪只目标大小的锚框,取聚类个数为9,得到锚框尺寸分别为:(52,57),(120,29),(76,60),(138,41),(110,60),(77,98),(63,164),(165,65),(117,134)。
4 结果与分析
4.1 主干网络参数与融合增强模型性能分析
构建 3 种不同层级的 ST 网络 ST4、ST6 和 ST8,研究Swin Transformer 层数对模型性能提升程度的影响,区别在于ST网络的第三阶段Swin Transformer层数分别为4、6和8。FPN作为特征融合网络第一层,PAN 和ASFF 均可作为融合增强模型。不同层级ST与PAN和ASFF组合成不同网络后在群猪数据集上测试结果见表1。验证不同层级ST网络有效性和PAN和ASFF对检测精度的影响,采用CIoU计算模型训练中预测框损失。

表1 不同层级ST与PAN和ASFF组合成不同网络后性能对比Tabel 1 Performance comparison of models with different levels of ST combined with PAN or ASFF
试验结果表明,引入ASFF 或PAN 的模型4-9与模型1-3 相比在精确率、召回率、F1 值、平均精确率方面均有提升。引入ASFF 的模型4-6 比使用PAN 的模型7-9 所达到最高平均精确率提高1.3%,最快检测速度提升1.3 Hz,平均模型大小减少1.5 MB。
在模型4-6中模型5性能最优,其精确率、召回率、F1 值、平均精确率、模型大小、检测速度分别为90.5%、96.6%、0.934、94.8%、22.1 MB、33.4 Hz。在模型7-9 中,模型8 精确率、召回率、F1 值、平均精确率、模型大小、检测速度分别为92.9%、97.2%、0.950、96.1%、20.6 MB、34.9 Hz。与模型9 相比模型大小减少2 MB,检测速度提高1.7 Hz,其余指标依次提升0.1%、0.6%、0.4%、0.3%。与模型7 相比,精确率、召回率、F1 值、平均精确率分别提升1.3%、0.6%、1.0%、2.9%,上述分析说明,ST8对本文数据集检测任务有较大冗余,引入过多注意力信息反而弱化注意力区域激活值,降低其层数不影响模型性能,且可降低运算量减少模型占用空间,ST6相比ST4对网络性能有明显提升,因此本文采用ST6 作为主干网络,特征融合网络采用FPN+ASFF。
4.2 改进后预测框回归损失计算方法对TA-Net影响
将预测框的三种回归损失计算方法进行比较,验证对本文网络影响。表2 为CIoU、SIoU 和RIoU 三种回归损失计算方法测试结果。试验表明,RIoU使本文网络的平均精确率相比CIoU提高0.4%,说明添加方向惩罚成本后可有效提升检测精度。RIoU比SIoU提高0.3%,二者在纵横比成本计算方面不同,SIoU 允许高度和宽度梯度值同增同减,RIoU 与CIoU 采用相同纵横比成本计算方法,文献[24]证明该方法限制两梯度值必须相反,数据集中猪只样本通常具有大纵横比,测试结果表明RIoU 更适合用于群猪目标识别。本文采用RIoU作为预测框的回归损失计算方法。

表2 预测框三种回归损失计算方法对比Tabel 2 Comparison of three regression loss calculation methods in prediction box
4.3 与不同目标检测模型性能对比
在群猪数据集上测试TA-Net 与常见目标检测模型见表3所示。SSD检测速度最快达到40.1 Hz,但模型架构中缺少特征融合网络,导致检测效果较差。Faster RCNN-resnet 50是两阶段检测模型,其精确率为93.7%,高于其他模型,召回率和平均精确率较低,原因是主干网络只提取单层特征图且分辨率较小,其他模型均提取多层特征提升检测效果。RetinaNet-resnet101 召回率较高,达到95.8%,原因是输出每层特征中均包含9 个先验框有利于提升召回率,其预测网络将分类与回归分两路输出,同样有利于提高预测框回归精度。EfficientDet-D7 平均精确率为94.0%,主干网络输出5层特征图降低信息损失,融合网络中采用加权双向特征网络能够提升检测效果但降低检测速度。YOLOv4 平均精确率为94.1%,检测速度比Efficient-Det-D7 快11.6 Hz,优势在于主干网络选用CSPDarknet53,更适用于目标检测。上述模型主干网络均为堆叠CNN结构,TA-Net主干网络以Transformer为基础结构,TA-Net在召回率、F1分数、平均精确率方面比YOLOv4高出1.5%、1.7%、1.6%、2.4%,模型占用内存量缩小12.5倍且检测速度提高13 Hz。TA-Net中主干网络输出三层特征图的通道数分别为64、128、256,YOLOv4 中主干网络输出三层特征图的通道数分别为256、512、1024,TA-Net 主干网络输出特征图通道数减少75%,这是TA-Net 在模型大小和检测速度上占优势关键原因。TA-Net引入的Swin Transformer 主干网络既提取图像全局信息又大幅度减少模型参数,提高检测速度,并且ASFF方法有效融合多尺度特征,使模型平均精确率达到96.5%,与SSD、Faster RCNN-resnet50、RetinaNet-resnet101、EfficientDet-D7和YOLOv4相比提高14.3%、5.0%、3.4%、2.5%、2.4%。综上,TA-Net 提高检测精度和检测速度并大幅度减少模型占用空间,可应用于群猪目标检测。

表3 不同目标检测模型性能对比Tabel 3 Performance comparison of different models for detection
4.4 与现有猪只目标检测方法对比
本文所提TA-Net 在本文测试集中群猪目标检测结果以及现有生猪目标检测方法报告检测结果见表4。其中,文献[18]将MobileNet 作为模型特征提取网络,FPN作为特征融合网络,以无锚式CenterNet 为检测层,在模型大小方面与TA-Net 相当,但其平均精度低于TA-Net模型2.2%。TA-Net与文献[18]方法具有相似模型大小,但TA-Net 使用较大的数据集训练模型,因此检测精度较高。文献[19]将原始YOLOv3 算法应用到生猪图像目标检测方面,在平均精度和模型大小方面TA-Net 明显优于该方法。文献[25]将一种改进的轻量化YOLOv4 算法用于生猪目标检测,在不损失精度情况下压缩模型,在平均精度方面均优于文献[18]、[19]的算法。TA-Net模型相比于其他方法在检测平均精度上达到最高且模型占用内存量较低,说明利用较少模型参数可实现较高检测精度。

表4 TA-Net与现有检测方法结果对比Tabel 4 Comparison between TA-Net and existing detection methods
4.5 本文算法的检测结果分析
利用Eigen-CAM对模型内部可视化分析,热力图中颜色越偏向红色,说明模型注意力越集中在该区域;原图中蓝色虚线框是遮挡区域,黄色虚线框是粘连区域。如图7所示,从热力图中可看出TANet重点提取猪只头部和背部区域特征。在遮挡和粘连区域中,猪只腿部和尾部均无法作为主要识别标准,网络自动将注意力更多集中到猪只背部和头部。试验表明,TA-Net在猪只遮挡和粘连时准确识别其位置并得到较精确预测框。

图7 热力图和TA-Net检测结果Fig.7 Heat map and output results of TA-Net
5 结 论
以育肥期长白猪作为研究对象,采用单阶段目标检测架构,以Swin Transformer 为主干网络,在FPN 后引入ASFF 作为特征融合网络,构建群猪图像目标检测网络。TA-Net 在模型大小和检测速度上占优势,关键在于主干网络输出三层特征图通道数与YOLOv4相比减少75%。提出一种改进交并比计算方法RIoU作为预测框回归损失值,在CIoU基础上增加回归方向成本,使预测框先移动到最近坐标轴,随后延该轴方向靠近真实框。与CIoU 和SIoU 相比,RIoU 更适用于预测框回归损失值计算。在群猪数据集上测试TA-Net 的各项指标优于SSD、Faster RCNN-resnet50、RetinaNet-resnet101、EfficientDet-D7 和YOLOv4。在检测精度和模型内存占用量方面,TA-Net 优于现有文献方法。说明本文算法利用较少模型参数可实现较高检测精度。TA-Net 提高检测精度和检测速度,大幅度减少模型占用空间,可应用于群猪目标检测。
