基于EMD-LSTM-ARMA模型短期发电量组合预测
2023-02-07王仲平何黎黎丁更乾
王仲平,何黎黎,丁更乾
(1.兰州交通大学 数理学院,甘肃 兰州 730070;2.甘肃省康乐县第二中学,甘肃 临夏 731599)
0 引言
随着全社会用电量逐年上涨,短期发电量预测变得尤为重要,是实现节能、经济正常运行、满足人民生活的前提条件和重要保障。
对发电量进行预测的方法有很多,包括4类:统计模型、空间测量算法、物理方法、人工智能算法。统计模型主要结合历史数据的特点来预测发电量,并利用预测误差来改变模型参数,统计模型中建模前需要对数据分布进行假设,得到的结果对于非线性时间序列数据来说并不令人满意;空间测量建模需要来自不同空间相关站点的发电量数据,这给模型的实现和操作带来了困难;物理方法通常用于预测天气数据,如风速、风向、温度等,且物理模型训练时间长,无法用于短期预测;用于预测的典型人工智能模型有人工神经网络模型、模糊逻辑模型、支持向量机和深度学习等。为了减少原始数据的随机干扰,学者们提出了数据预处理技术和模型优化算法。广泛运用的数据预处理方法有小波包分解、经验模态分解、奇异谱分析等。常用的模型优化算法包括粒子群优化、遗传算法、杜鹃搜索等。通过将数据预处理技术与模型优化算法相结合的策略,可以使预测模型得到更精确的结果。
文献[1]采用了一种基于多维特征融合网络(MFFN)和长短期记忆(LSTM)的预测方法,对来自不同地区4个风电场的发电量进行了预测,通过对比分析组合预测模型可以得到更好的结果;文献[2]采用了ARIMA-MSFD组合模型对甘肃省水力月发电量进行了预测;文献[3]则提出了经验模态分解和堆栈式长短期记忆的组合算法,应用于家庭短期电力负荷预测,提高了预测精度;文献[4]采用了一种基于改进经验模态分解和Elman神经网络相结合的预测方法,对辐照时长及强度首先进行了聚类分析,然后经过改进的EMD算法对历史数据进行了处理,再输入Elman神经网络中进行预测分析,结果说明了该组合预测方法可以在一定程度上提高预测的准确性。
本文针对我国某地区2019年4—9月某一光伏电站的发电量数据,提出了一种基于EMD-LSTM-ARMA的短期发电量组合预测模型。首先将原始发电量数据通过经验模态分解后得到5个本征模态分量和1个残差分量,将归一化后的IMF1和IMF2输入设计好的LSTM网络中进行建模预测;然后通过ARMA模型对IMF3进行建模预测;再对IMF4、IMF5和残差分量进行重构得出了某个低频分量,将这个低频分量在设置好的LSTM网络中进行建模预测;最后对各个分量得到的预测信息进行求和得出了最终的预测值。
1 研究方法
1.1 经验模态分解
经验模态分解主要利用信号极值点的特征将任意的一个信号分解为一些本征模态函数以及一个单调的残差分量,其中,各个IMF分量分别表示原始数据在不同频率阶段的变化状态,残差分量则反映了原始数据的变化趋势。在其定义域内满足本征模函数(IMF)的两个条件为:
1)极值点个数与零点个数相等,或者差值不超过1个;
2)任意时刻的上下包络函数的均值均为0。
EMD算法过程如下:
1)找出给定的时间序列函数{x()t}极大值点和极小值点;
2)将各个极大值点用曲线相连得到上包络线xmax(t),各个极小值点连接得到下包络线xmin(t);
3)计算出对应的上、下包络线的均值,将其记为m1:
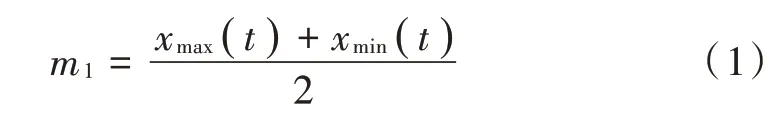
4)减去平均值,得到新函数:
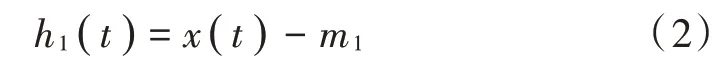
5)用新函数h1(t)替代原来的x(t),重复上述步骤得到的hk(t),k=2,3,…,满足IMF条件时就停止,定义:
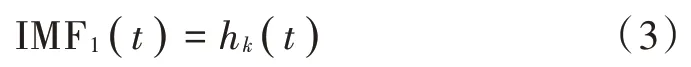
6)将IMF1从x(t)中分离出来,得到r1:

重复n次,得到x(t)的n个IMF分量以及残差分量rn为:

当rn是一个单调函数,EMD分解停止,得到式(6)的结果:
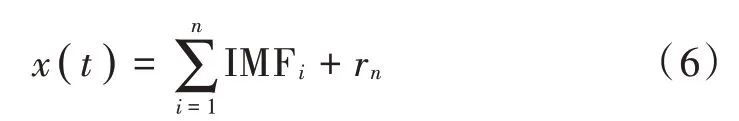
1.2 长短期记忆网络
一个具有记忆长短期信息功能的模型叫作长短期记忆网络,目的是解决数据存在的长期依赖问题。LSTM引进了“门”的机制,有两种传输状态,一个Ct(记忆状态)和一个ht(隐含层状态),LSTM的“门”机制是指该算法引入了3个“门”来作为其运行的三个阶段,这3个“门”分别为:遗忘门(忘记阶段)、输入门(选择记忆阶段)和输出门(输出阶段)。其内部结构如图1所示。
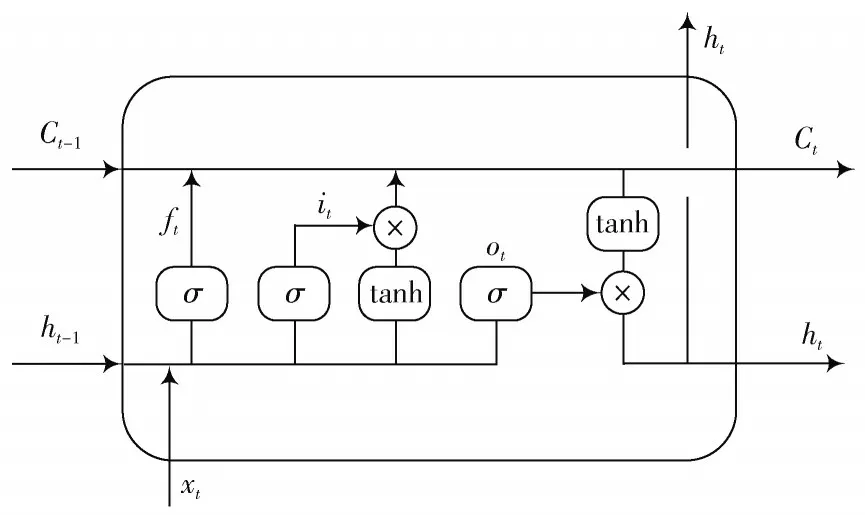
图1 LSTM内部结构图
1)“忘记阶段”顾名思义是进行一种“忘记”的过程,该过程主要是对上个节点的输入进行有选择性的忘记,然后把现在的输入xt和上个状态遗留下来的ht-1进行组合,从而有4个状态,然后该组合经过sigmoid激活函数,其数值被转换到[0,1]之间,并以此作为遗忘门的状态,输出ft的值域为[0,1],LSTM记忆神经元是通过ft来控制上一神经元状态Ct-1哪些需要遗忘。其中ft表示如下:
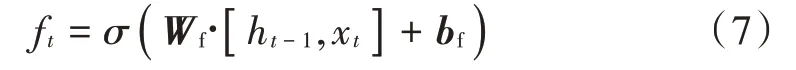
式中:Wf为遗忘门系数矩阵;bf为偏差矩阵;σ为sigmoid激活函数。
2)“选择记忆阶段”是将当前的输入xt选择“记忆”,过程是将输入门和tanh函数进行组合来决定需要被“记忆”的信息有哪些。把经过tanh函数而产生的向量记为临时状态向量,再结合输入门输入的信息向量Ct-1来更新当前记忆单元的状态Ct,it为控制向量。其中,,it,Ct表达式分别如下:
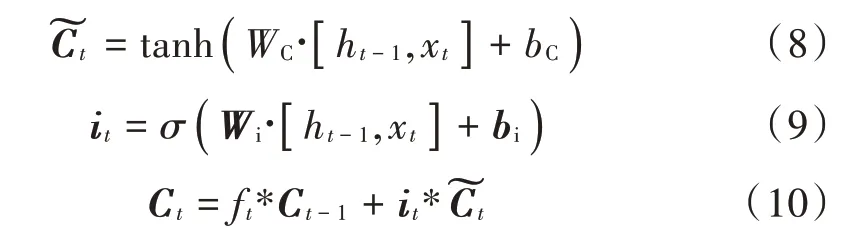
式中:Wi为输入门系数矩阵;bi为偏差矩阵;“*”表示按元素乘。
3)“输出阶段”则是利用输出门决定重要信息的筛选,即是哪些“记忆”将会被当成当前状态的输出。首先将Ct中的某部分记忆通过sigmoid函数,以此来控制被输出的记忆是哪些,其次把Ct通过tanh函数进行映射,最后把tanh层得到的函数值和sigmoid层得到的函数值再进行运算得到最后的输出结果。其中ot,ht表达式如下:
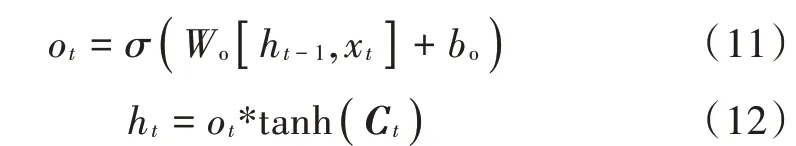
式中:Wo为输出门线性关系的系数;bo为偏差。
1.3 自回归移动平均模型
自回归部分AR(p)和移动平均部分MA(q)的组合就得到了自回归移动平均模型,即ARMA(p,q),表示为:
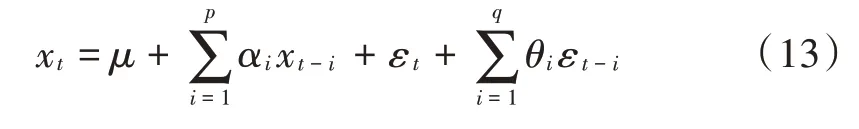
式中:p是自回归阶数;q为移动平均阶数。
1.4 模型评价指标
本文主要使用均方根误差对模型预测结果进行评价,其中RMSE计算公式如下:
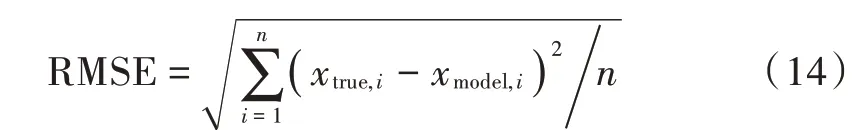
1.5 EMD-LSTM-ARMA组合预测模型结构
首先将原始发电量数据通过经验模态分解后得到5个本征模态分量和1个残差分量;然后将IMF4、IMF5和残差分量R进行重构得到IMF_RE,利用LSTM网络分别对第一分量数据和第二分量数据、重构得到的低频分量数据进行建模预测;再将IMF3分量输入至ARMA模型中进行预测;最后将各个分量预测结果进行重构,得出短期发电量预测结果。EMD-LSTM-ARMA组合预测流程图如图2所示。
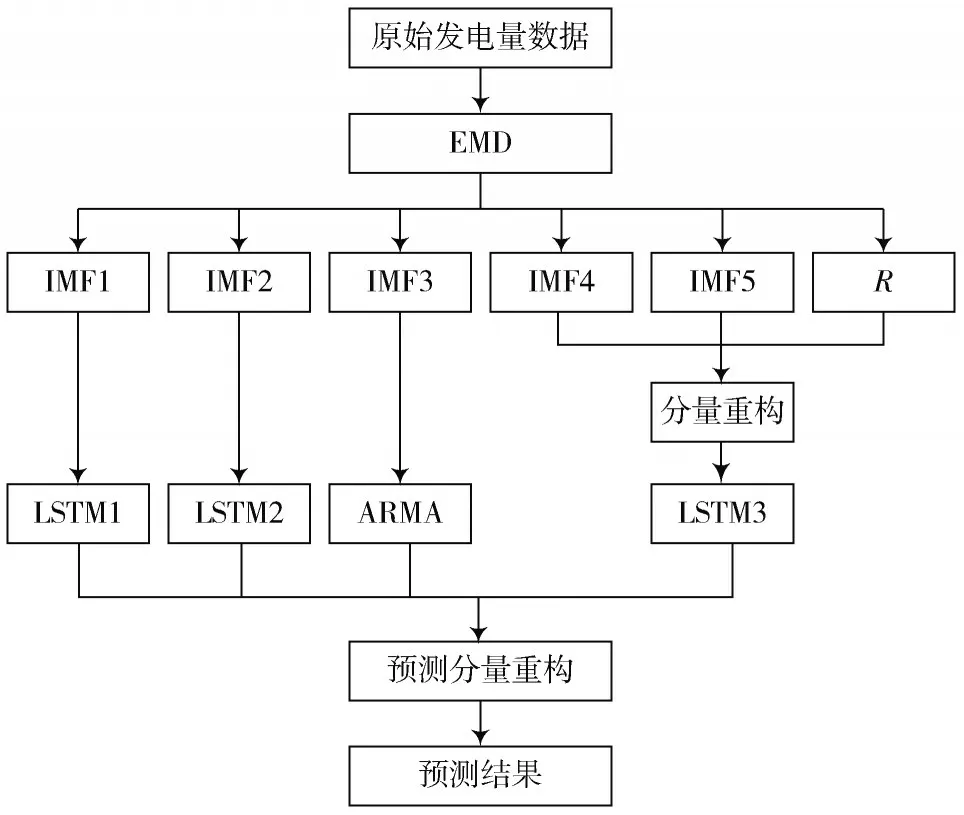
图2 EMD-LSTM-ARMA组合预测流程图
2 实证分析
2.1 数据描述
本文数据来自某地区2019年4月1日—9月20日的发电量数据,共173个数据。将138个数据定为训练集,35个数据定为测试集。该地区原始发电量数据如图3所示。
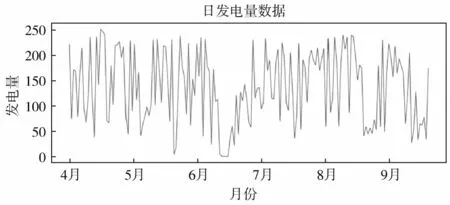
图3 某地区发电量变化曲线
发电量数据的描述性统计见表1。

表1 发电量数据的描述性统计
2.2 EMD分解
将EMD算法应用于原始发电量数据,得到的原始数据序列与其分解后的各个分量如图4所示。
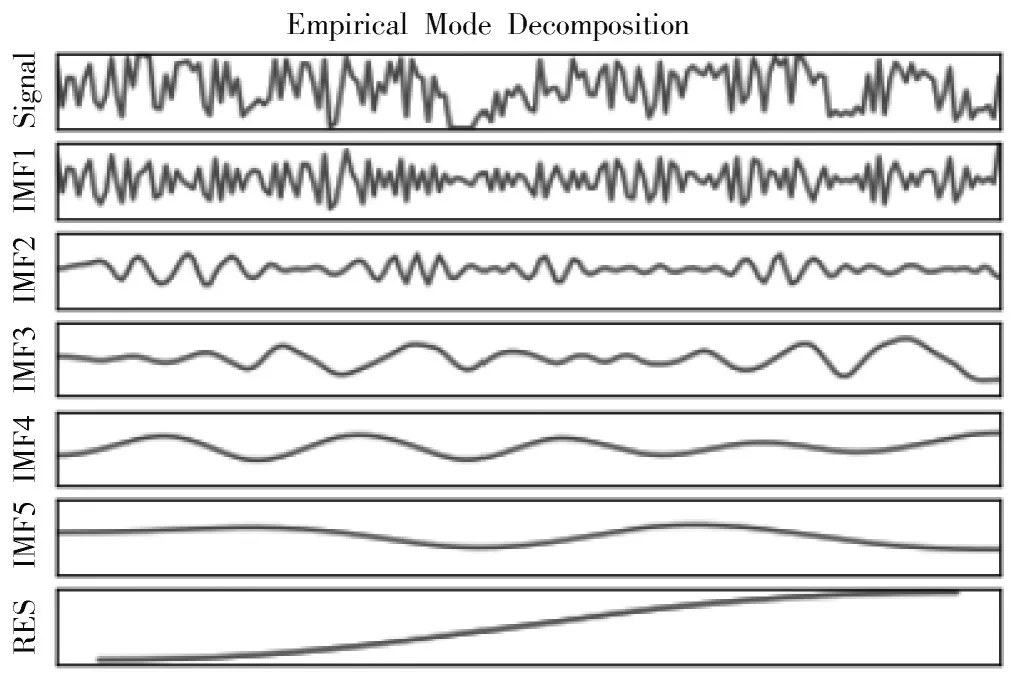
图4 原始序列与各子序列图
由于一些分量数据波动幅度较大,梯度下降速度较慢,为了提高梯度下降的速度,对各个分量建模前先对数据进行归一化处理,将其压缩到[0,1]之间:
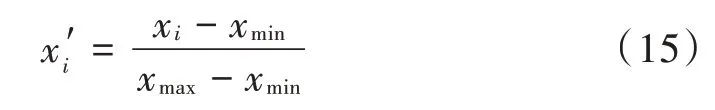
式中:xi为原始数据;xmax为最大值;xmin为最小值;x′i为归一化值,且x′i∈[0,1]。
2.3 模型预测
2.3.1 LSTM模型预测
将归一化后的IMF1和IMF2输入设计好的LSTM网络中进行建模预测,得到的预测结果再通过反归一化得到,将分量IMF4、IMF5和残差分量R重构得到IMF_RE,与IMF1、IMF2分量的预测过程一致,输入到不同的LSTM网络中得到预测结果。其中各个分量的输入特征的时间步长为7,即根据前7天的发电量预测下一天的发电量。
LSTM模型中各参数:LSTM隐含层层数、隐含层神经元、初始学习率和最大迭代次数等。对不同隐含层层数下的LSTM模型进行了多次实验(以IMF1为例),表2为不同隐含层层数下的预测结果。
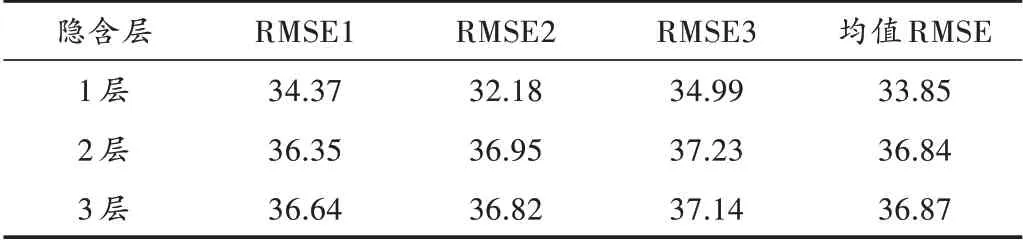
表2 IMF1不同隐含层层数下LSTM网络模型的预测结果
结果表明,增加隐含层层数预测误差变大,说明模型发生了过拟合。虽然增加隐含层层数可以提高模型对特征的学习能力,但是学习能力过强会减弱模型的泛化性能,从而使得模型在测试集上表现较差,因此最终确定IMF1的LSTM隐含层数为一层。再通过使用交叉验证和网格搜索的方法,确定隐含层神经元个数为20,最大迭代次数为900,初始学习率为0.001。同理,可得到IMF2、IMF_RE的LSTM网络结构见表3。
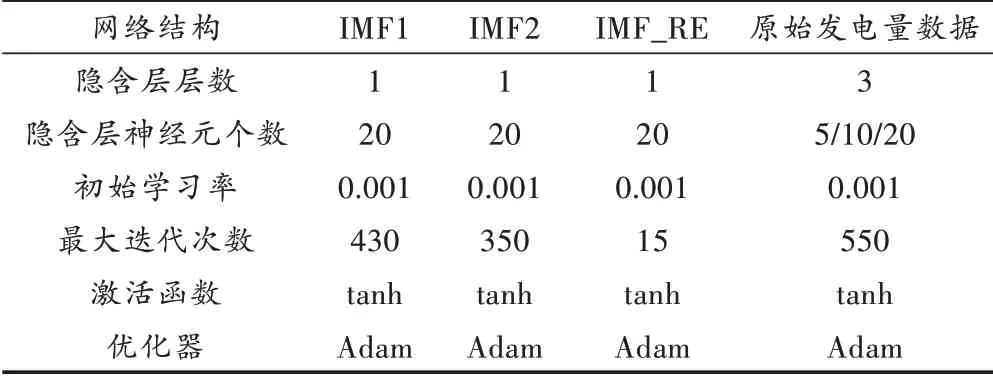
表3 LSTM网络结构
将各分量的预测结果进行线性叠加得到最终预测值,预测值的拟合效果如图5所示。
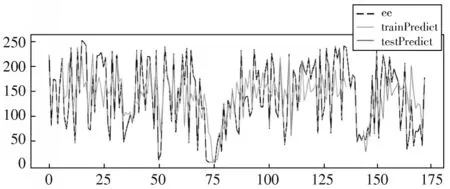
图5 原始发电量预测值及最终实际值对比图
2.3.2 ARMA模型预测
由分析对比可知,将分量IMF3进行ARMA模型预测是个更为合适的选择,经过单位根检验后的IMF3序列是平稳的。由表4可得,检验统计量的值为-4.380 5,均小于1%,5%,10%置信度的临界统计值,且p=0.000 3,认为IMF3序列通过了平稳性检验,可对其进行ARMA模型建模预测。
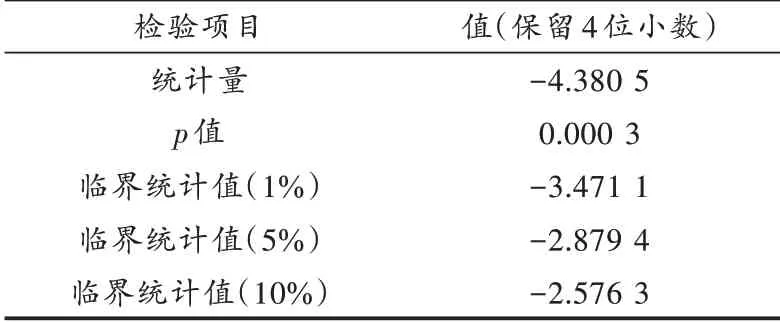
表4 单位根检验结果
由自相关和偏自相关系数图(见图6)可以看出,自相关系数呈现出拖尾的状态,偏自相关系数在3阶后截尾,因此p的值可能为2,3,4,5,q的值为0。
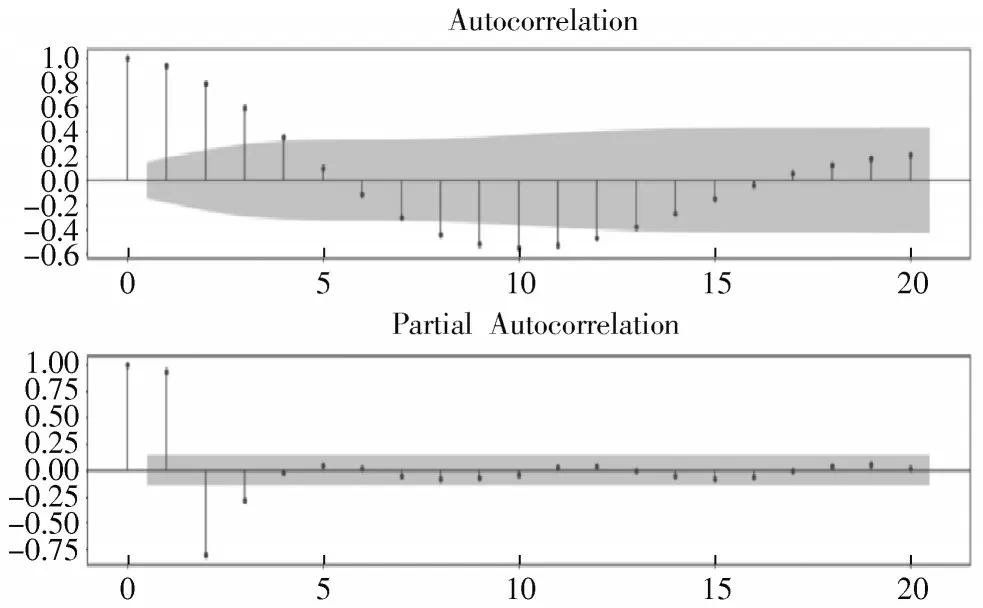
图6 自相关与偏自相关系数图
分别计算模型对应的AIC值,如表5所示。可以看出ARMA(4,0)模型的AIC值最小,因此选择ARMA(4,0)模型对分量IMF3进行预测。
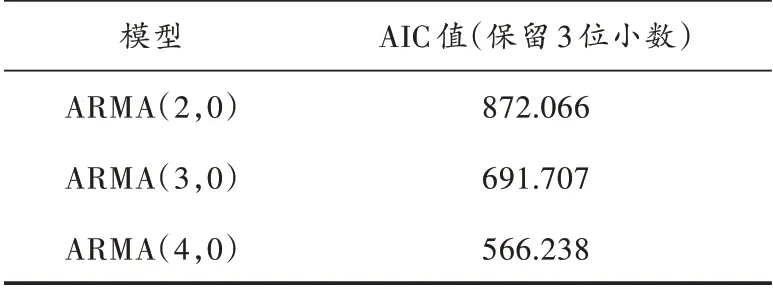
表5 ARMA模型的AIC值
2.4 预测分量重构
将各个预测的IMF数据(Pi)进行线性叠加,得到最终的预测值P。

2.5 实验结果对比
实验过程还将原始发电量数据通过单一ARMA模型和单一LSTM模型进行了预测,对比了EMD-LSTM-ARMA模型的预测效果,得到各个模型的RMSE值如表6所示。

表6 各模型预测误差对比
由表6可知,EMD-LSTM-ARMA模型的RMSE值最小,且相较于ARMA模型、LSTM模型分别降低了45.38%,44.36%,表明EMD-LSTM-ARMA模型具有更高的预测精度。
图7为3种 模 型 对2019年8月23日—9月29日 的发电量预测结果。
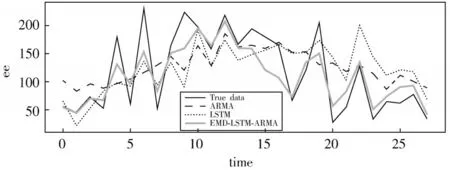
图7 不同模型发电量预测曲线
由图7可知,3种模型的预测效果均不是特别的好,可能是因为数据量太少,但是对发电量的变化趋势都可以较好的解释,相对于另外两种模型,EMD-LSTM-ARMA模型的预测误差较小,表明组合模型优于单一模型。
3 结论
根据上述实验对比结果,可得出如下结论:
1)经验模态分解确实可以将复杂的信号分解为有限个较为平稳的信号,据此数据的平稳性将更有利于进行建模分析。
2)LSTM模型对时间序列数据的拟合会优于传统时间序列模型,如ARIMA等,与其自身所具备的时间记忆的能力有着莫大的关系,从而能够提升模型的预测准确度。
3)EMD-LSTM-ARMA模型降低了原始发电量数据的非平稳性,且具有很好的非线性拟合和时间记忆能力,因此其预测效果优于文中所提到的其他两种模型。
