结合多尺度特征和注意力机制的公路裂缝检测
2023-02-07张瑞燕
张瑞燕
(中国海洋大学 工程学院,山东 青岛 266100)
0 引言
目前,我国公路建设在世界发展处于领先水平,交通运输部发布了2016—2020年交通运输业发展数据,期间公路总里程数已从469.52万千米增加到519.81万千米[1]。尽管我国公路建设方面发展迅速,但在公路服役期间暴露出众多安全问题,长期外界条件的影响及公路养护不及时导致病害持续得不到解决,其中裂缝仍然是最普遍存在的病害[2],并且也是公路损伤的开端,因此,裂缝检测对公路结构的维护、安全防护和降低损失具有重要的实际应用价值。由于几十年前设备不先进并且没有适用的分析算法,路面管理人员一直延续手动评估裂缝的方法,该方法可操作性差、检测效率低、人工成本高。
近年来,目标检测方法和语义分割方法在路面裂缝检测方面的应用受到研究者广泛关注,同时结合无人机非接触的方法可以获取存在裂缝的公路图像,该方法不仅成本低,而且更便捷、灵活和安全,实现了自动提取图像中的裂缝。目标检测方法能快速确定公路裂缝的位置,文献[3]将YOLOv2用于检测路面裂缝,达到了88.51%检测精度,但模型有待进一步改进。文献[4]运用YOLOv3进行路面裂缝检测,然而YOLOv3仅仅能对路面裂缝进行定位,并不能对裂缝提取。在进行路面检测时,路面管理人员更注重裂缝具体信息[5],比如裂缝形状信息、分布信息等,因此,相比于目标检测方法,语义分割在路面检测方面具有明显优势。文献[6]将FCN网络用于道路裂缝检测,实现了在不需要后处理情况下的裂缝检测,但是对细裂缝或者靠近图像边缘的裂缝检测效果较差。文献[7]采用U-Net检测裂缝,实验表明,U-Net比FCN具有更强的鲁棒性和更高的精度,受背景环境的影响较小,当训练集较小时也能达到较高精度,然而这些输出结果都依赖人为针对数据集调整模型参数,对于实际工程应用具有局限性。文献[8]将DeeplabV3+用于路面裂缝检测,尽管DeeplabV3+在一些公共数据集表现较好,但是在对裂缝进行分割时仍出现误检情况,比如将与裂缝具有类似特征的物体分割成裂缝,并且对细小的裂缝或者存在大量噪音背景的裂缝图片分割效果不佳,仍有待改进。因此,本文通过特征金字塔模块和注意力机制提高模型在细小裂缝上的检测精度。
本文创新点有:根据公路裂缝的特点提出一种基于改进DeeplabV3+的编码-解码路面裂缝检测算法DCPNet,用特征金字塔结构改进DeeplabV3+的解码结构,将包含丰富语义信息的高级特征与包含丰富空间信息的低级特征进行融合,充分利用裂缝样本中的信息;将空间注意力模块和通道注意力模块引入到网络中,增强对裂缝关键信息的关注并抑制无关信息,增强对小目标的识别能力。
1 原理方法
1.1 特征金字塔网络结构
深度卷积神经网络中的浅层卷积层提取了低级特征,其中会包含更多的细节信息,例如边缘信息、形状信息、位置信息,网络深层卷积层会提取包含更多语义信息的高级特征。模型在进行预测时,语义信息会直接精确地识别出物体,但是通常会忽略位置信息,因而要利用低级特征进行辅助识别,将高级特征与低级特征进行融合,特征金字塔网络结构的多尺度特征融合可以达到这个目的。
特征金字塔网络[9]能够提高对小目标的检测精度,是进行多尺度特征融合的方式之一。其网络结构包含三种路径:自下而上的路径、特征之间连接的横向路径、自上而下的路径。自下而上的路径本质是卷积神经网络的特征提取过程,在这个过程中,输入的特征图尺寸会随着卷积过程发生改变,然后将特征图尺寸不发生改变的阶段最后一层输出输入到横向路径中。自上而下的路径通过上采样进行,上采样通过最近邻插值增加像素点达到扩大特征图尺寸的目的。横向连接路径将纵向两条路径每个阶段的特征进行融合,来自自下而上路径的特征图会经过1×1卷积调整通道数,使得特征通道数与自上而下路径的特征通道相同,然后通过特征向量加法实现特征融合。由于上采样过程中会产生混叠效应,因此要将融合后的特征进行3×3卷积以减少混叠效应。通过不断迭代,每层会产生新的特征图,逐渐构成金字塔结构,实现多尺度特征提取与信息融合。
1.2 引入SCSE注意力模块
SCSE注意力模块[10]包括基于通道注意机制的空间挤压和通道激励(cSE)注意力模块以及基于空间注意机制的通道挤压和空间激励(sSE)注意力模块。cSE注意力模块的计算过程是输入特性映射F=[f1,f2,…,fC]经过全局平均池化生成向量Z,然后经过全连接层和ReLU层,再通过全连接层,最后通过Sigmoid层得到激活值,它可以代表重要的渠道而忽略不重要的渠道。整个过程可表示为:
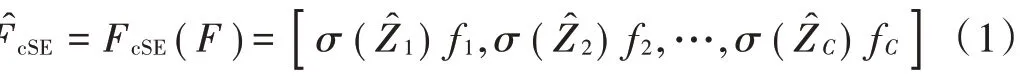
sSE注意力模块的计算过程是输入特征映射F=[f1,1,f1,2,…,fi,j,…,fH,W],通过1×1卷积生成q向量,然后通过Sigmoid层得到激活值。整个过程可表示为:
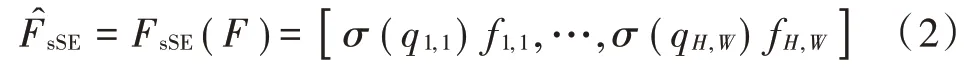
1.3 网络模型结构
尽管DeeplabV3+中的空洞空间金字塔模块具备多尺度模块的能力,但利用的仍旧是主干网络中深层次的多尺度信息和一条路径的低级特征信息,对于裂缝这种小目标特征提取是不够的,因此本文引入特征金字塔结构来提高模型联系上下文的能力。其次为了提高模型对有限裂缝样本的特征学习能力并提高对裂缝关键特征的关注度,将注意力模块嵌入到网络中,且不提高模型的复杂度。
DCP-Net的网络结构见图1,框架仍旧采用DeeplabV3+的编码-解码结构,其中编码器仍旧由主干网络和空洞金字塔模块构成,解码器由横向连接路径和自上而下路径组成。通过权衡运行速度和检测效率,采用更容易优化的ResNet-50作为提取特征的主干网络,并作为DCP-Net网络自下而上的路径,将ResNet-50中的4个尺寸不发生改变的特征图阶段输入到横向连接的路径中,阶段4经过空洞空间金字塔模块进行4倍上采样,阶段1、阶段2、阶段3在进行特征融合之前要将通道数降为48,融合后的特征经过3×3卷积通道数变为256,在3×3卷积之后嵌入SCSE注意力模块,提高模型对裂缝与背景的区分能力,细化裂缝特征,提高网络的表达能力,抑制不必要信息,强调重要信息。在自上而下的路径中逐渐融合低级特征,减少不同区域的上下文损失,获取裂缝的全局上下文信息。
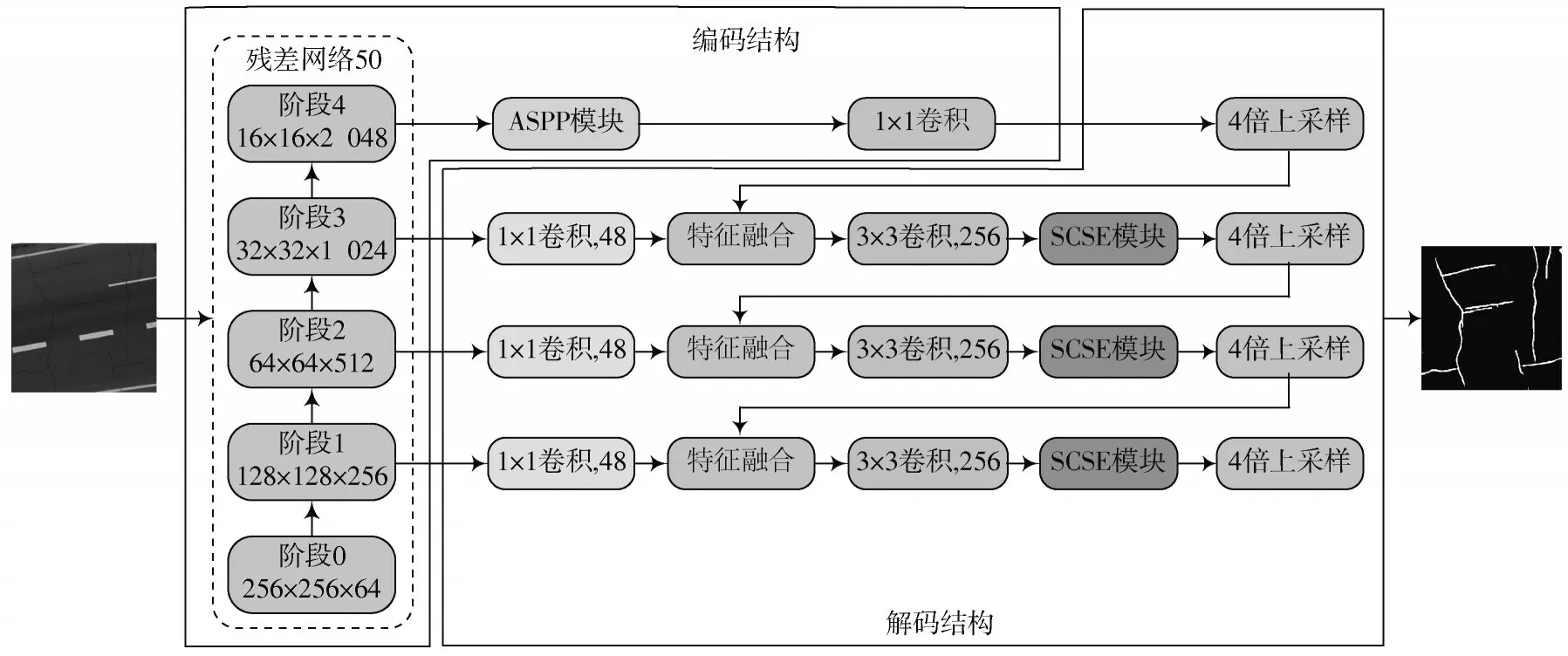
图1 DCP-Net网络结构图
因此,综上所述,DCP-Net网络与原始DeeplabV3+的区别是:
1)采用参数更少的ResNet-50作为主干网络;
2)修改了解码器部分,参照特征金字塔网络,增加两个支路,提取多尺度特征,融合低级特征和高级特征,保证充分利用有限样本中的裂缝信息;
3)引入SCSE注意力模块提高模型对有限裂缝样本的通道和空间信息的学习能力。
通过以上三点提高模型在小样本的检测精度。
2 实验
2.1 实验数据
因受限于采集设备和采集场景,本文使用开源航拍路面裂缝数据作为研究数据。目标域数据集来自名为AerialCrackDetection[11]的开源数据集,见图2。为了更好地适应语义分割的检测任务,将这些航拍图像剪裁为512×512尺寸,并选取1 010张图像进行标注,其中训练集数量为606张,验证集数量为202张,测试集数量为202张。

图2 裂缝示例图
2.2 实验参数及评价指标
本文中所有实验均在Ubuntu 16.04系统上运行,程序开发语言为Python,版本为3.6.10。并用Pytorch 1.5.0深度学习框架搭建网络模型,硬件配置中的CPU为Intel Core i5-9400F@2.90 GHz*6,GPU为NVIDIA GTX1660。训练模型时的初始学习率为0.007,迭代50次,权重衰减为0.000 5,动量为0.9。
为了准确地评估该方法的分割性能,需要考虑检测效率和精度。检测效率被认为是语义分割的重要指标之一,通过有效评估设备与模型之间的匹配关系,为模型在各种场景下的应用提供有效信息,本文用帧率(FPS)量化模型的检测效率,用像素准确率(PA)、平均像素准确度(MPA)、平均交并比(MIoU)评估模型精度。
3 实验结果及分析
3.1 网络结构的消融实验
用特征金字塔结构(FPN)、SCSE注意模块(SCSE)、空洞空间金字塔池化模块(ASPP)做消融实验来验证这些模块在提升网络性能方面的有效性,其中实验参数均相同,实验结果如表1所示。
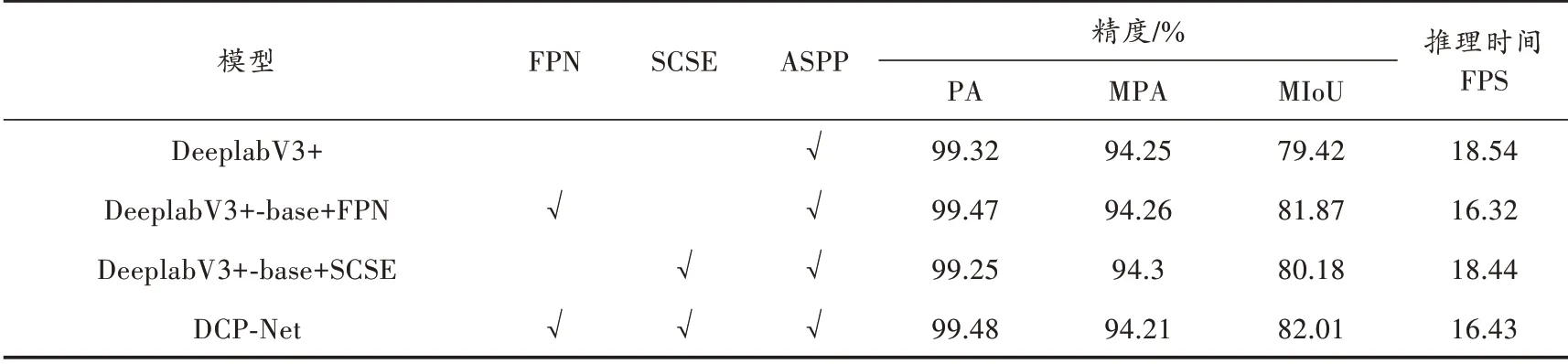
表1 不同网络结构性能对比
三种改进网络的检测精度都有不同程度提升,检测效率都有所降低。由于原始DeeplabV3+检测精度的像素准确率和平均像素准确率指标都比较高,因此改进后的网络提升范围较小,而MIoU是分割精度的主要评价指标。使用特征金字塔模块和SCSE注意力模块对模型的MIoU提升较大,当单独使用特征金字塔结构时,MIoU提高了2.45%;使用SCSE注意力模块对模型的检测精度也有一定的提高。本文提出的DCP-Net的MIoU值比DeeplabV3+提高了2.59%,说明进行多尺度特征融合可以提高模型的性能,同时,提高模型对通道信息的关注度也可以提高模型的性能,尽管降低了模型的检测效率,但是降低程度较小,在实际路面裂缝检测工程应用中影响较小。
3.2 不同方法的消融实验
将本文提出的模型与典型语义分割模型进行对比,四种模型均用ResNet50作为主干网络提取裂缝特征,实验的精度和推理时间指标见表2。本文提出的模型精度指标均高于其他三种网络,DCP-Net的MIoU比CCNet高4.52%,比U-Net高2%。计算效率略低于其他模型,U-Net在检测效率上占据优势。
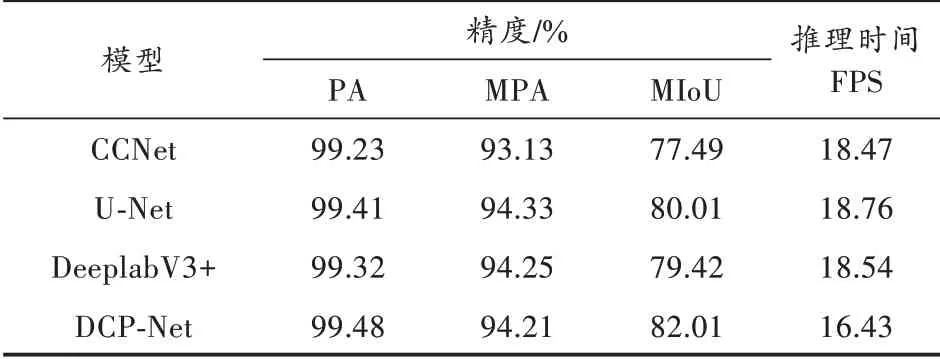
表2 不同模型的性能对比
四种方法的裂缝分割效果见图3,U-Net在二分类时较CCNet和DeeplabV3+具有明显优势,裂缝的分割效果较好,但对于复杂裂缝图像识别效果较差,特别是当多个裂缝交叉时,交叉部位明显出现不连贯或者出现误检的情况。相比于前面三种网络,DCP-Net的裂缝分割效果更好。
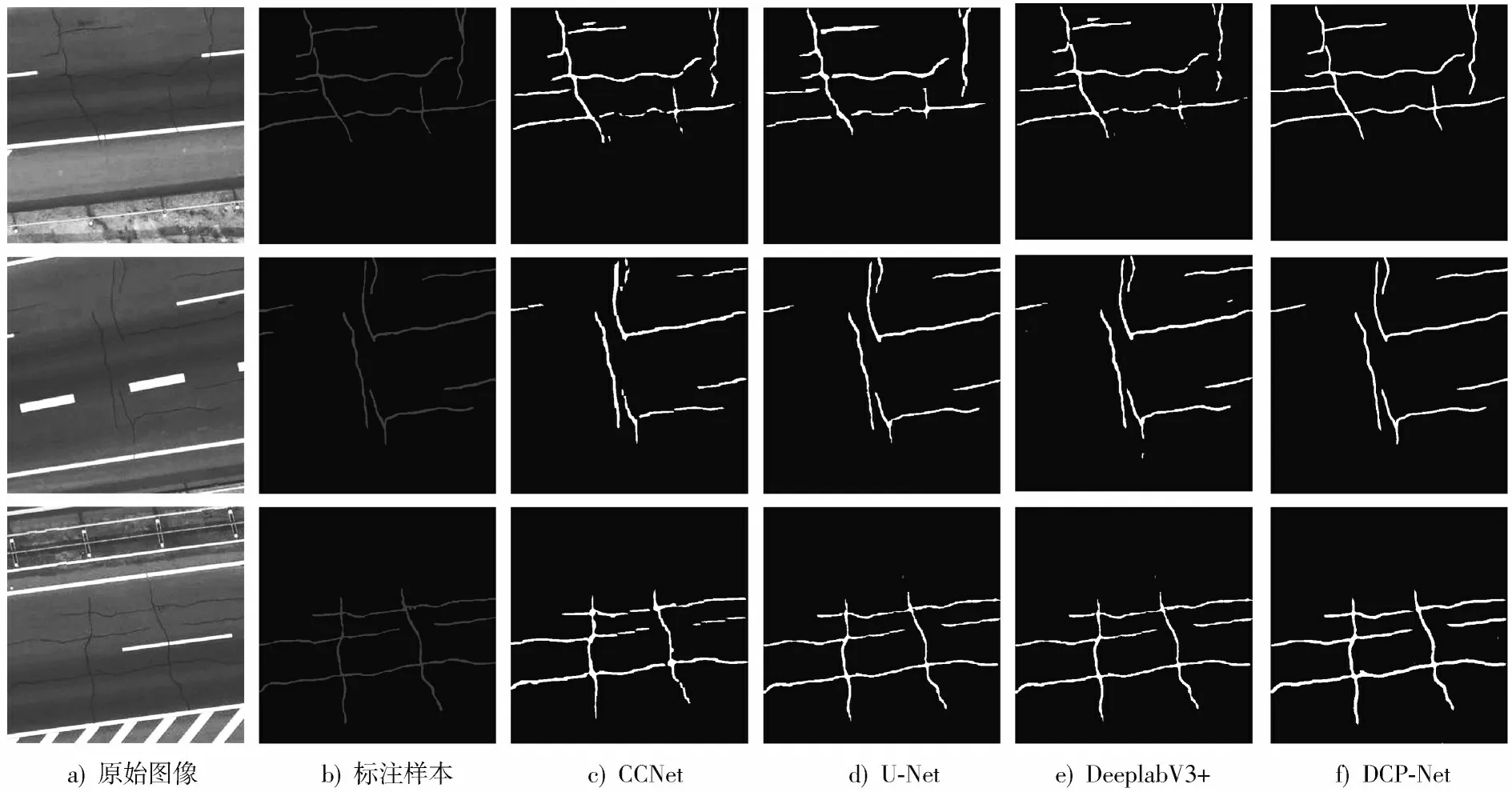
图3 不同方法裂缝分割结果
4 结语
本文提出一种结合多尺度特征融合和注意力机制的语义分割模型,利用特征金字塔结构将空间位置等细节信息和语义信息进行融合,得到了裂缝的全局上下文信息,帮助网络更好地提取裂缝特征。注意力模块提高了模型的通道学习能力,抑制对裂缝图片中无关信息的响应。
从最后的裂缝分割图像中可以看出,改进模型对裂缝分割效果有明显提升,减少了分割图像时出现的噪点数量及裂缝不连续的情况。在后续的研究中会研究测量算法,在用本文方法分割裂缝时,测量出裂缝的宽度供路面管理人员应用。
