基于时序时空双流卷积的异常行为识别
2023-02-07张仁路高丙朋
张仁路,高丙朋
(新疆大学 电气工程学院,新疆 乌鲁木齐 830049)
0 引言
近年来,公共安全问题日益突出,对地铁站内异常行为识别可以保障人身安全,维持良好秩序。基于计算机视觉的异常行为识别得到研究学者的广泛关注,学者们提出了一些研究方法,主要分为传统方法和深度学习方法。传统的异常行为识别方法根据异常行为特点,手工表征特征来判断是否发生异常行为。文献[1]利用小波变换提取异常行为的纹理和颜色等特征,在此基础上利用支持向量机检测识别视频中的异常行为特征。文献[2]在时序图像特征点基础上获得目标对象的空间外观特征描述,提出基于多流谱聚类的异常行为检测方法,但该方法无法识别交互性的异常行为。文献[3]提出了一种多特征融合方法,利用当前帧中所有候选对象的相似特征与前一帧中异常特征进行匹配,实现早期异常行为的分类,该方法在昏暗环境下识别精度低,仍有一些局限性。文献[4]提出了一种人体行为分类框架,利用一种基于几何特征的特征提取技术通过形态学图像处理技术,从人体斑点中提取几何特征,实现异常行为识别,但该方法的表征能力受限于所提取的特征。基于深度学习的异常行为识别方法,可以通过大量的样本不断地训练优化网络,有更好的特征表征能力,在图像分类任务中,卷积神经网络(CNN)[5-8]表现出比较好的性能,一些学者将卷积神经网络应用于行为识别领域。文献[9]提出了一种深度卷积框架的异常行为检测统一框架,从标准RGB图像中自动检测人类异常行为,提高了静态姿势识别结果的准确性。ResNet[10]网络可以有效缓解深层次卷积神经网络梯度消失和梯度爆炸的问题,因此在深度学习领域常被用作基础特征提取网络。文献[11]提出了双流架构,将双流网络用于异常行为识别领域,利用多任务的方法进行异常行为识别研究。文献[12]提出了一种新的基于CNN的动作分类和检测框架,该方法将骨架运动和骨架原始坐标特征信息输入卷积神经网络,形成双流CNN网络进行标签预测,但是该方法由于网络不断加深仍然存在过拟合问题。文献[13]提出了非常深入的双流网络,通过网络预培训提高了网络的学习效率。
不同于2D卷积,一些学者将3D卷积应用于异常行为识别领域。文献[14]提出了一种新的三维动作提取器,利用3D卷积提取视频中的动作特征信息。文献[15]在三维体素(3DV)时间分割过程中进行整体编码,提出了一种多流的动作识别方法。文献[16]提出了伪3D残差网,通过深入结构多样性,提升了网络识别效果,并将原3D卷积进行拆分,降低网络模型的参数量。总体来说三维方法参数量大、网络训练较慢,限制了网络的使用性和有效性。
综上所述,异常行为识别方法有很多种,在特殊场合行为识别研究较少,识别精度不高。异常行为是一个连续的过程,帧间连续关联时间序列信息是动作特征的重要信息,本文从帧间运动时间依赖关系思路出发,提出了一种深层次双流长短期残差网络结构,能够有效利用空间外观和运动光流的连续关联时间信息,并且通过多种加权融合策略加强模型识别效果,在地铁站昏暗环境下仍具有较好的识别效果。
1 基本原理
1.1 基于改进的LTwo-stream_ResNet34网络的异常行为识别模型
双流网络模型本质是相互独立的两个模型,通过对原有网络进行改进,可提高网络模型的性能,提升识别效果,在异常行为识别过程中,建立一种能够提取运动中时序特征的模型,是异常行为识别的关键。长短期记忆(LSTM)网络具有强大的记忆能力,其能够学习视频帧序列间的长依赖关系。在地铁站异常行为识别过程中,本文以双流网络模型为基础,用双流网络分别提取视频中的空间特征与局部的运动特征,将LSTM网络与ResNet34网络结合,改进的网络结构如图1所示。
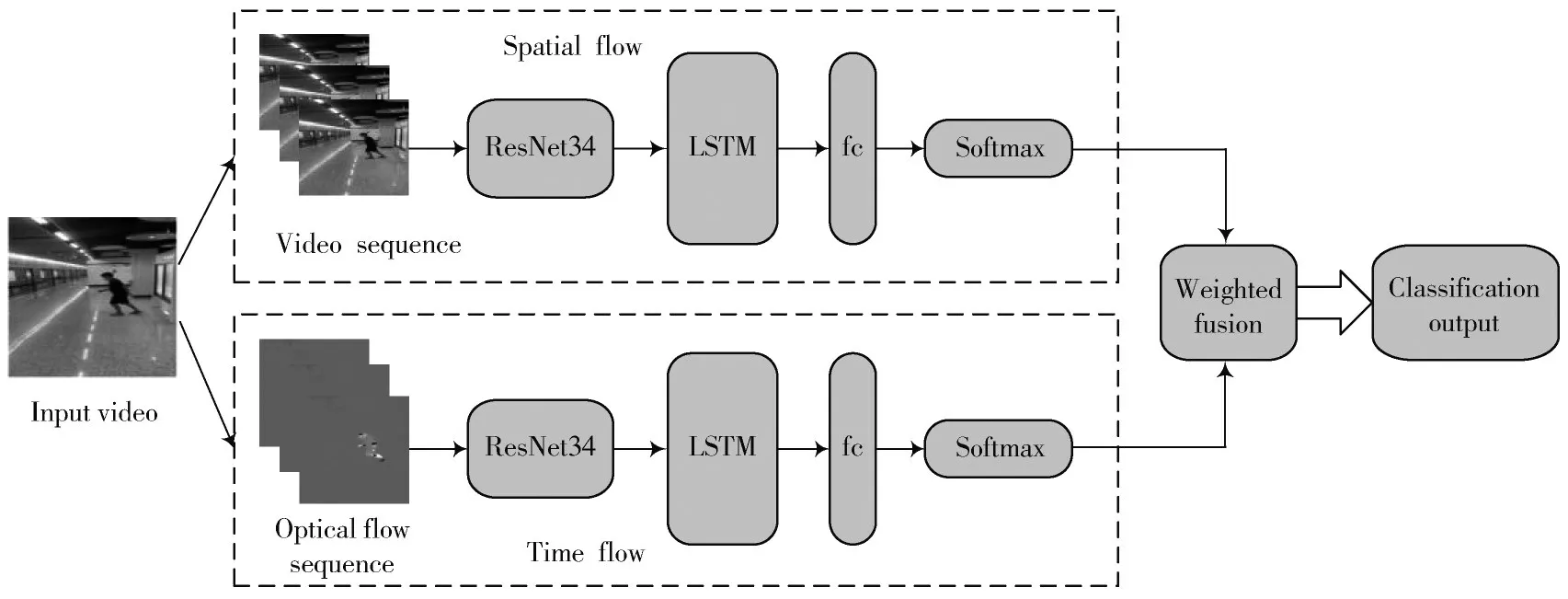
图1 双流LTwo-stream_ResNet34网络结构
网络分为空间流网络和时间流网络两个分支,空间流网络的输入为视频帧的RGB图片,时间流网络的输入为堆叠的由稠密度光流法生成的光流图,其中光流图反映了相邻帧像素点的位移变化。每个分支ResNet34网络先进行特征提取,LSTM网络将ResNet34网络的输出作为输入,学习高层语义特征的时间序列信息,随后将提取的特征信息送入全连接层,在Softmax层采用加权融合的方式对输出值进行计算,最终实现异常行为识别。ResNet34与LSTM的连接如图2所示,输入的是光流和视频帧序列。
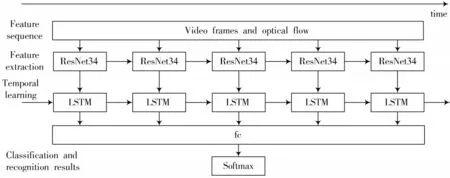
图2 ResNet34-LSTM网络结构
1.2 ResNet网络特征提取
为了提取更深的语义特征信息,双流网络每个分支都采用ResNet34网络结构作为特征提取网络,ResNet34能够缓解网络加深而造成的梯度消失和梯度爆炸的问题,网络结构如图3所示。
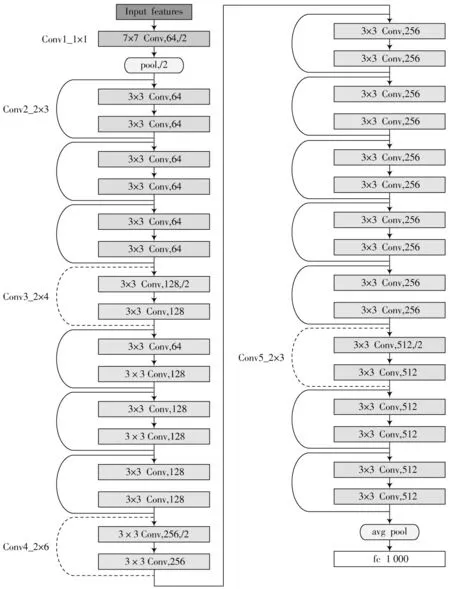
图3 ResNet34网络模型结构
网络由5个卷积模块组合成,每个卷积模块有多个残差块,首先将光流图和视频帧图片统一缩放为224×224的尺寸,在空间流网络中输入的是3通道的单帧RGB视频帧,在时间流网络中输入的是双通道连续堆叠的10帧光流图像,随后将特征信息依次输入网络的5个卷积模块(Conv1_x、Conv2_x、Conv3_x、Conv4_x、Conv5_x)。
其中:Conv1_x卷积模块由64个卷积核构成,尺寸大小为7×7,步长为2,经过第一个卷积模块卷积之后,连接一个最大池化层,步长为2。Conv2_x卷积模块由3个残差模块组成,每个残差模块包涵2个卷积层,每一个卷积层由64个卷积核构成,其尺寸大小为3×3。Conv3_x卷积模块由4个残差模块组成,每个残差模块包涵2个卷积层,每个卷积层有128个卷积核,每个卷积核的尺寸大小为3×3。Conv4_x卷积模块由6个残差模块组成,每个残差模块由2个卷积层构成,每个卷积层有256个卷积,尺寸大小为3×3。Conv5卷积模块由3个残差模块组成,每个残差模块有2个卷积层,每个卷积层包涵512个卷积核,尺寸大小为3×3。将提取后的特征进行池化,经过全连接层后,LSTM网络将提取的特征作为输入,有效利用高层语义特征的帧间时间依赖关系。
1.3 LSTM时序特征提取
LSTM能够很好地处理特征的时序问题,是一种改进之后的循环神经网络,具有很强大的记忆能力。将ResNet提取的动作特征矢量输入到长短期记忆网络,LSTM分别学习空间特征和光流特征的时间序列信息。LSTM采用3个门控单元控制记忆状态,包括遗忘门、输入门与输出门,结构如图4所示。
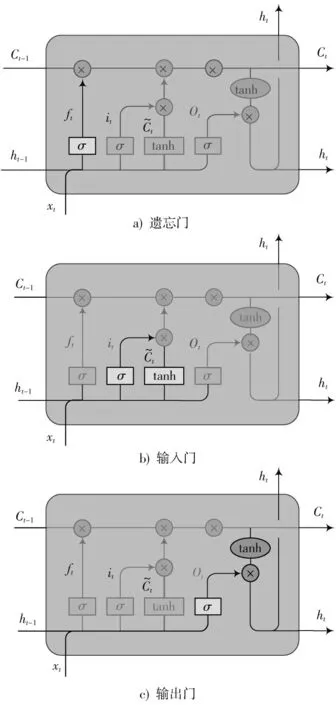
图4 LSTM网络结构
遗忘门决定了历史状态信息的遗忘速度,即决定了上一时刻Ct-1中有多少信息被保存到当前时刻Ct中,它是由sigmoid的输出值ft进行控制,ft的取值范围为0~1,当数值越接近0时,意味着数据被遗忘的程度就越大,越接近1时,意味着数据更应该被保留。输入门决定当前时刻Ct可以加入多少新信息C͂t。先将当前隐藏状态的信息和当前输入的信息输入到sigmoid函数,在0和1之间调整输出值来决定更新哪些信息,0表示重要,1表示不重要。也可以将隐藏状态和当前输入信息传给tanh函数,并在-1~1之间压缩数值来调节网络。输出门决定了当前状态更新到记忆单元的程度,用来将遗忘门与输入门的信息进行整合,经过tanh函数将数值取值为-1~1之间,再由sigmoid函数输出的Ot值控制输出。
ResNet网络将提取后的特征经过LSTM网络进行全局时间序列特征的学习时,在t时刻,每一个长短期记忆网络的输入都有一个卷积神经网络的输出xt与之相对应。在每一时刻,长短时记忆网络都有一个输出,当前时刻的输出值都受到上一时刻的影响。然后再将多个时刻的相应输出进行平均运算,将其送入Softmax进行行为识别分类。
长短时记忆网络状态更新表达式为:
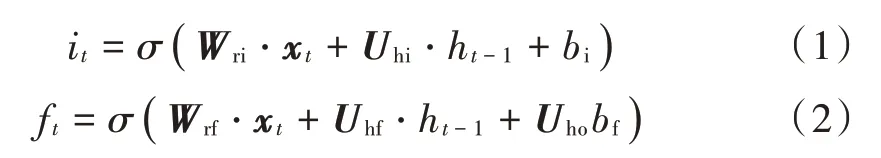
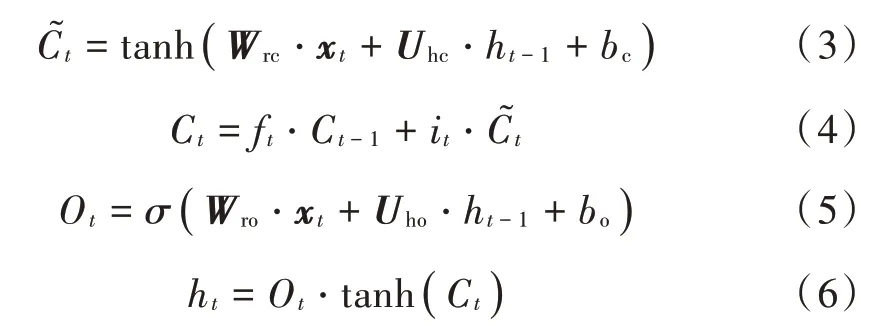
式中:xt为当前时刻特征提取网络输出的特征矩阵;σ为sigmoid函数;Wrf,Wri,Wrc,Wro分别是输入层到遗忘门、输入门、存储单元和输出门的权重矩阵;Uhf,Uhi,Uhc,Uho分别为隐含层到遗忘门、输出门、存储单元和输出门的权重矩阵;bf,bi,bc,bo分别为遗忘门、输入门、存储单元和输出门的偏置。
1.4 多种融合策略
原双流网络在特征经过Softmax层后将输出值取平均对动作进行分类预测,然而双流网络所提取的特征不同,两个流单独识别的效果有差异,因此,本文在时间流卷积神经网络和空间流卷积神经网络融合时采用多种融合策略,对时间流和空间流提取到的高层语义特征信息进行加权融合。加权融合公式为:
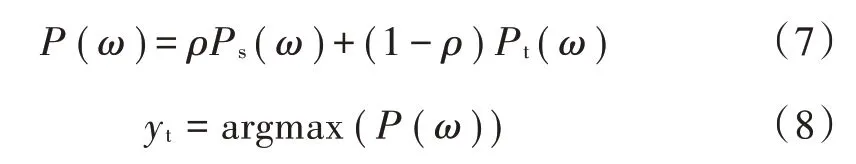
式中:ρ为空间流卷积网络的权重;Pt(ω)为时间流概率输出值;Ps(ω)为空间流网络的概率输出值;P(ω)为改进后的双流网络最终的概率输出值;yt为最终的输出结果。
2 实验结果分析
2.1 实验环境及参数设置
本文实验的程序语言为Python,编译器为PyCharm 2021.3,框架为Pytorch 1.8.1。实验环境:显卡设备为Nvidia GeForce RTX 3060(12 GB显存),操作系统为Ubantu 20.04,运行内存为32 GB。具体的参数训练设置如下:
1)空间流网络输入的是单帧RGB图像,时间流网络输入的是堆叠的10帧光流图像,在输入网络时,将图像大小设定为224×224。
2)空间流和时间流网络的batch_size大小设置为10,初始学习率为0.001,学习率的衰减方式lr_step每10轮衰减一次,gamma=0.1。
3)空间流和时间流卷积神经网络都采用带动量的随机梯度下降法(SGD)的方式进行网络优化。
4)在每个网络的全连接层后都增加一个Dropout层,对神经元进行随机失活。其中在空间流网络中Dropout的失活率设置为0.5,时间流网络的失活率设置为0.5。
本文建立了地铁站异常行为数据集,异常行为分别为打架(fight)、晕倒(run)、翻越(overstep)、奔跑(run)、砸东西(smash)。每类动作有三个视角,分别为左视角、右视角、前视角,每个视角有50个视频片段,每个视频片段时长为6 s,每类动作一共150个视频段。数据集共包含750个视频。视频的行帧速率为30 f/s,分辨率大小为1080×1920。数据集部分样例如图5所示。

图5 数据集部分样例
2.2 不同方法的对比实验
将本文改进的空间流网络(LResNet34_rgb)、改进的时间流网络(LResNet34_optical)、改进的双流网络(LTwo-stream_ResNet34)与空间流网络(ResNet34_rgb)、时 间 流 网 络(ResNet34_optical)、双 流 网 络(Twostream_ResNet34)进行对比实验。本文空间流和时间流的网络测试损失值逐渐降低,经过80轮以后损失值趋于稳定,模型收敛,空间流和时间流网络损失值变化曲线分别如图6和图7所示。
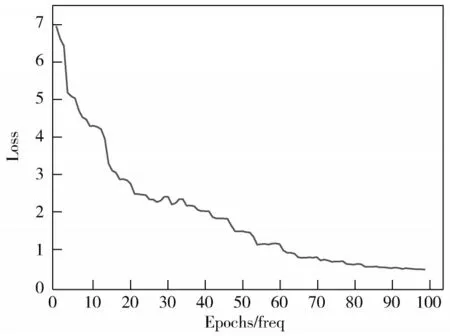
图6 空间流损失变化
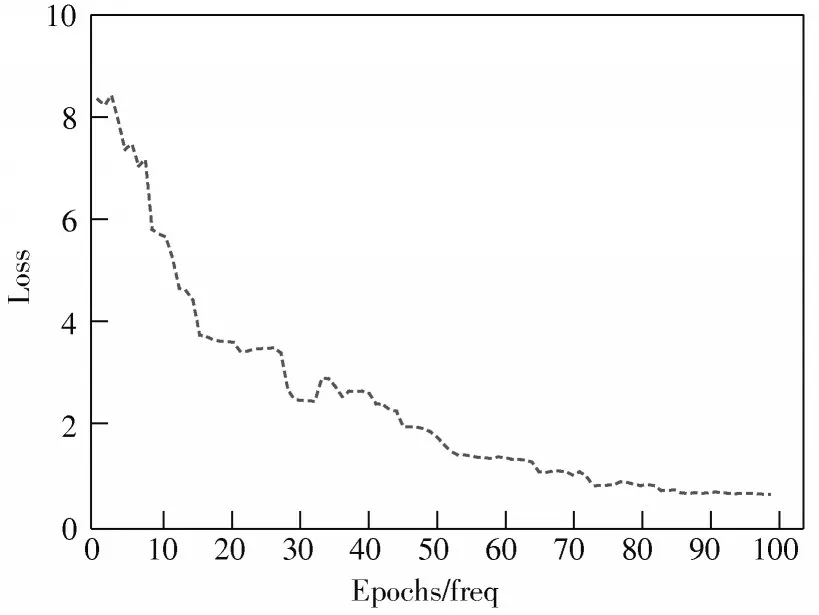
图7 时间流损失变化
本文算法与其他算法的平均识别准确率对比结果如表1所示。考虑行为动作的帧间运动时间序列信息,本文算法通过长短期记忆网络学习高层语义的特征信息。表1数据表明,改进后的空间流网络比原网络识别平均准确率提升了1.6%,改进后的时间流网络比原网络识别平均准确率提升了1.9%。实验验证了改进后的时间流和空间流网络能够有效利用空间外观和运动光流的时间序列信息,提升了识别准确率。同时,将改进后的空间流和时间流网络进行平均融合,平均识别准确率比Two-stream_ResNet34网络提高了6%,其与Twostream_ResNet34网络测试平均识别准确率变化曲线如图8所示,验证了改进后的双流网络可以更好地提取空间运动特征和光流运动特征,能够有效融合时间流和空间流网络分别提取的具有时序关系的高层语义特征信息,具有异常行为识别优越性。
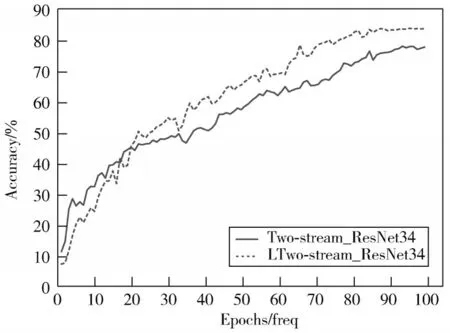
图8 改进后双流网络与Two-stream_ResNet34网络准确率对比
2.3 不同融合策略实验
由表1可知,空间流网络的平均识别准确率略高于时间流网络,不同于以往平均融合策略,进一步研究模型融合识别效果。本文采用多种权重融合策略将网络进行融合,给空间流网络权值分别为0.55,0.60,0.65,0.70,0.75,平均识别准确率如表2所示。准确率测试变化曲线如图9所示。在权值为0.55~0.70范围时,随着空间流网络权重在一定范围内不断增加,改进后双流网络模型的识别准确率不断提升,权重为0.70时,平均识别准确率高达90.5%,比Two-stream_ResNet34网络准确率提升了12.9%。网络模型损失值变化如图10所示,网络模型在70轮测试后,模型收敛,系统趋于稳定,并且权值为0.70时,网络模型的收敛速度最快,实验验证了本文方法加权融合方式在行为识别领域的优越性。
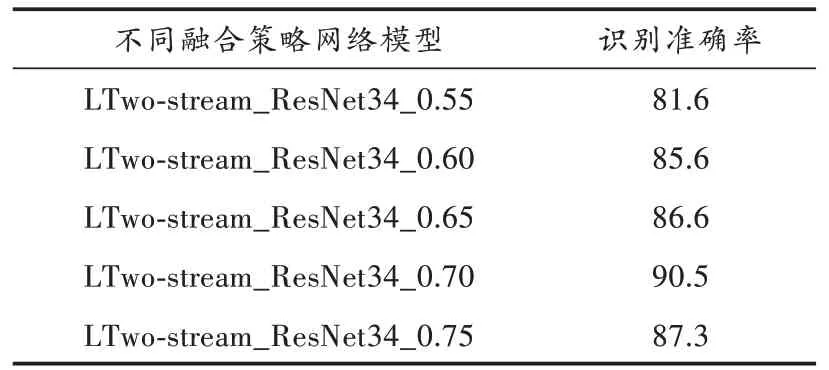
表2 不同融合策略平均识别准确率 %
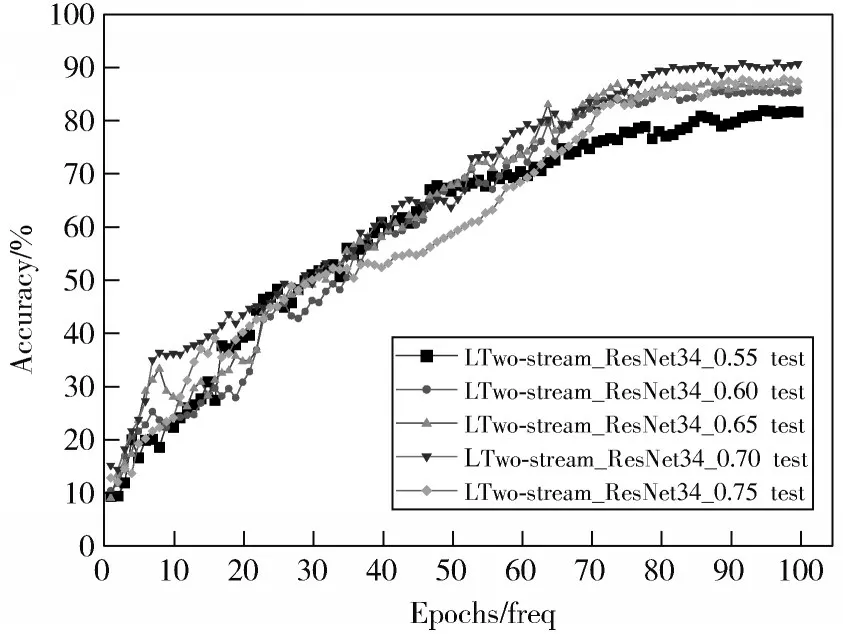
图9 不同融合模型测试识别准确率
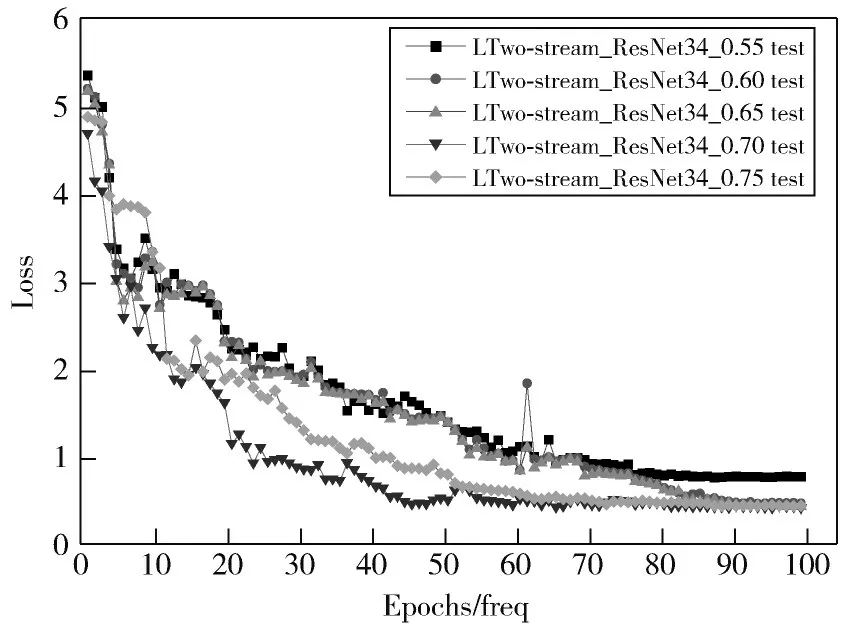
图10 不同融合模型测试损失值
本文改进的方法识别效果如图11所示,图11c)和图11d)为夜间环境下发生的动作,表明昏暗环境下本文算法仍然具有较好的识别效果。

图11 异常行为识别效果
3 结语
异常行为识别在公共安全问题日益突出的今天逐渐成为研究的热点,本文提出了一种时序双流网络结构来提取时序特征信息,能够有效利用运动特征的时间依赖关系,采用时间流网络学习帧间光流时间序列信息,空间流网络学习空间外观特征的时间序列信息,解决基本双流网络方法忽略帧间运动的问题,能够有效识别地铁站的人体异常行为,提高了异常行为识别准确率。此外,不同于以往单一的平均融合方式,本文采用了多种加权融合策略,能够更科学地利用双流网络每个分支提取的特征,融合后的网络具有较好的识别效果。
