不确定性环境下在线实时定价的深度强化学习策略
2023-02-05王祖德陈彩华
王祖德,陈彩华,李 敏
(南京大学 工程管理学院,江苏 南京 210093)
0 引言
随着商业的发展,传统的固定定价模式已经难以适应需求动态变化的应用环境,给企业带来了诸如库存、销售以及客户满意度等问题,很难满足顾客差异化、多元化的消费需求。而动态定价伴随商业数字化的加快越来越得到企业的青睐,这也是企业避免粗暴定价模式,走向精细化运营方向的一种方式。特别是国内外基于互联网进行商品销售的企业对动态定价策略的运用更为明显,大型在线零售商亚马逊针对平台上数百万的商品引入动态定价策略进行价格调整来增加收益和打击竞争者;美团、淘宝、京东等电子商务平台也积极引入动态定价对其平台上的各种商品在不同供应时间点进行差异化的定价,诸如京东、淘宝平台上的限时秒杀、闪购以及优惠券活动,美团上的外卖折扣券、配送费用分时段计价的方式。
现今,电子商务让信息流全面转向了线上平台,使得数据资源集中在了电商平台中心。一些大型的电商网站采集了丰富的数据资源,而这些数据中包含了消费者行为模式的重要信息,这使得利用数据对客户需求估计来进行定价策略调整,增加产品周期内的累积收益成为了可能。然而,先前的研究主要存在以下两方面问题:一方面,部分资料对动态定价问题策略的研究主要基于一些固有的假设,缺乏对数据本身潜在信息的挖掘;另一方面,很多基于数据来研究动态定价问题的策略难以应对大数据的应用场景,主要问题是难以表达高维数据特征所包含的需求信息和定价之间的复杂关系。近年来,深度强化学习理论在游戏[1-2]、推荐系统[3-5]等领域都取得了广泛的应用,这促使了采用深度强化学习理论来研究动态定价问题。
本文采用深度强化学习理论研究依靠电子商务平台进行销售商品的动态定价问题。针对商品受到环境的复杂变化导致高水平不确定性需求的产生,依靠定价策略来学习需求的动态变化而进行价格调整。本文的贡献如下:
1)提出了解决有限销售时间段内在线销售给定库存量商品动态定价问题的动态定价学习框架DRL-DP 用于优化商品销售的长期累积收益;
2)综合考虑了影响需求变化的环境特征,提出了解决动态定价中高维状态特征问题的Q-network 神经网络;
3)设计了在线的定价代理交互环境用于训练和评估DRL-DP 的表现。
本文的结构如下:第1 节,对研究问题的相关文献进行了回顾;第2 节,对动态定价问题的要素进行了数学描述;第3 节,对动态定价问题的理论建模及算法设计进行了相关的叙述;第4 节是数值实验;第5 节,对本文的研究工作进行了总结和展望。
1 文献回顾
动态定价问题历来受到关注。一些学者从贝叶斯理论的角度来解决动态定价问题,Mason 和Välimäki[6]在研究单个商品动态定价问题中,对顾客的到达率采用了贝叶斯学习的方式;Harrison 等[7]将需求不确定性限定在两种需求函数中,采用贝叶斯方式学习最优定价策略。需求模型假设在一组有限的函数簇内,将价格优化转换为多臂赌博机(multiarmed bandit,MAB)问题,Chhabra 和Das[8]研究了针对在线数字商品拍卖的MAB 问题学习;Xu 等[9]将具有时变回报的隐私数据动态定价问题转化为MAB 问题;Moradipari 等[10]采用MAB 框架来解决价格受未知因素影响和响应随机性的电力实时定价问题并通过Thompson Sampling 算法求解。不确定性环境下基于鲁棒优化理论提出了保守性的动态定价策略,Li 等[11]对需求率模型具有不确定性的情况采用鲁棒优化进行研究;Cohen 等[12]提出了直接从数据中学习鲁棒性的动态定价策略。部分学者也从博弈论角度考虑多个参与主体的动态定价问题,陈晓红等[13]研究了多零售商动态博弈定价;Srinivasan 等[14]利用博弈论对新加坡电力市场进行了动态定价建模;曾贺奇等[15]从博弈论角度考虑了两竞争商定价问题。
近年来,强化学习在研究动态定价问题上也有一些进展。Han[16]在解决一般性动态定价问题将Bayesian 方法和Q-Learning 结合,采用贝叶斯的方式将MDP 的转移函数和奖励函数作为分布,并利用采样方式进行动作的选择;Collins等[17]比较了SARSA、Q-learning 和Monte-Carlo learning 这三种方法对于航空公司动态定价博弈的效果,并且还分析了将强化学习应用于此类问题所获得的额外效益;Dogan 等[18]采用强化学习理论分析了在不同环境下各零售商在多零售商竞争环境中的定价决策;Rana 等[19]考虑了多个相互依赖产品的收益问题,当需求是随机的且需求函数的形式未知时,使用强化学习来模拟相互依赖产品的最优定价;Cai 等[20]通过强化学习研究了电子商务市场中广告实时竞价问题;Lu等[21]采用马尔科夫决策过程建模了分级电力市场中能源管理的动态定价问题并采用Q-Learning 算法求解。
综上所述,前期的相关文献对顾客到达率采用已知分布,需求和价格之间的关系假设为已知的带有未知参数的函数或者函数簇。然而,现实应用场景中的顾客到达率以及需求受到环境多种因素综合影响而变化。此外,在需求估计中采用了统计学习的方式,与价格优化分割成两阶段的决策模型。而采用强化学习理论研究动态定价问题作为一种免模型的方式,对需求估计和价格优化相结合,是单阶段决策模型。但是前期关于强化学习研究动态定价问题的文献多集中在表格式强化学习,模型的学习和表达能力有限,无法处理高维数据特征下的定价问题。而本文研究基于具有良好表征能力的深度强化学习理论来解决需求受到环境多种因素影响的实时动态定价问题。
2 问题描述
电商平台进行销售的部分商品需在固定的销售时间段内销售给定的库存量,特别是易腐性和时尚类商品,而平台由于数据获取、存储、利用的便利性以及环境交互的可实施性,特别适合于动态定价策略的运用。这类商品由于在销售单个周期时间内不允许进行再次补货,销售末期剩余的商品不存在残值。当面临复杂的市场变化环境时,往往需求快速地变化而难以确定,此时可以利用数据学习需求的动态变化,通过相关的数据特征变化来反映需求的动态变化情况,采用动态定价策略来控制库存水平的状态变化。因此,当面对复杂的不确定性需求环境时,商家一般会采用动态定价策略来提高累积收益。针对该问题做出如下假设:
N:表示给定商品的库存量,在单个销售周期内不允许再次补货,剩余商品的残值为零;
t:表示调整定价的时间步,t=1,2,…,T,最多可以进行T次价格的调整。实际应用中难以做到连续地调整价格,因此采用这种固定的时间间隔来调整价格是最为合理的方式之一;
pt:表示在时间步t的定价,pt属于一个定价集合P,即pt∈P;
nt:表示在时间步t时给定价格pt后的[t,t+1)时间段内销售出的商品数量。
基于以上假设,此问题可以建模为:
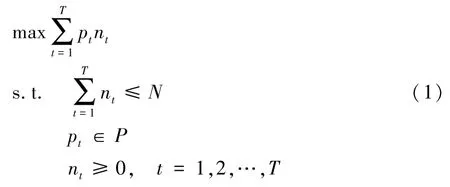
这里的销量nt表示需求环境对定价pt的响应,由环境特征的动态变化以及需求敏感性所决定;pt是通过学习算法感知环境特征变化来权衡当前定价收益与未来收益给出的定价。接下来,将根据问题描述分析基于深度强化学习理论的定价模型以及仿真环境的构建。
3 动态定价模型
3.1 动态定价的MDP
本文将此类动态定价问题建模为离散有限的MDP。MDP 由〈S,A,P,R,γ〉五元组构成,S表示状态空间,A表示动作空间,P:S×A×S→[0,1]表示状态转移概率函数,R:S×A→ℝ 表示回报函数,γ∈[0,1]表示折扣因子。上述动态定价问题MDP 的具体分析如下:
状态空间S:状态信息通过特征描述,即S=(S_observation,S_stock,S_seq)。其中,特征分为观测状态S_observation,库存状态S_stock以及序列反馈信息S_seq三组。观测状态表示对定价市场环境的感知,可以是当前时间步同类竞争商品的价格、不同时段顾客的流量等影响顾客到达率以及需求敏感性的特征;库存状态由当前定价时间步到销售期结束的剩余时间量和剩余库存量构成;序列反馈信息表示从定价开始到当前时间步的库存状态变化、销量状态变化以及定价状态变化的序列反馈,用于学习不同时间步状态信息下采取不同定价动作的需求敏感性变化特性,如下图2 的Qnetwork 所示,在时间步t的序列反馈信息表示为S_seqt={(ki,ei,di),i=1,2,…,t-1},其中ki,ei,di分别表示在时间步i的剩余库存量占总库存量N的比例,i到i+1时间段的销量ni占总到达人数arrivei的比例,i到i+1 时间段的定价折扣率。
动作空间A:在动态定价中采用了折扣率的调整方式,动作空间A表示定价折扣率集合。假设顾客接受的最大保留价格为Pmax,如果采用J个不同的折扣率,则A={dr1,…,drJ}。时间步t的动作at∈A,那么实际的定价为Pmax·at。这种价格调整方式是电子商务平台上最为常见的一种方式。例如,采用限时折扣券。
状态转移概率函数P:p(st+1|st,at)表达了在状态st,采取动作at,状态由st转移到st+1的概率。状态转移不确定性的来源主要在于当前库存状态下观测状态影响因素的动态变化导致顾客到达率的变化以及市场环境对定价动作at的需求响应强度。
回报函数R:在时间步t的状态st下采取动作at后,定价环境会对相应的定价动作给予一定的立即回报rt+1。本文并没有沿用前期大多数强化学习处理动态定价问题文献中采用[t,t+1)时间段的立即收益rt+1=Pmaxat·nt作为回报,而在立即回报中引入了销量转化率,将立即回报定义为rt+1=。回报函数相比于立即收益,能够表达不同定价对顾客到达量产生的收益转化。此外,在不确定性的定价环境中采用立即收益作为回报的数值波动较大,导致对状态-动作值估计的方差较大,不利于算法的收敛,当在立即回报中引入比例可以抑制数值波动的剧烈变化,提高对状态-动作值估计的准确性。
折扣因子γ:γ度量了未来收益对于当前时刻所选择动作的贴现率,用于衡量当前立即回报和后序延时奖励的相对重要程度,由人为经验确定。
图1 展示了动态定价问题的代理与定价环境之间的MDP 交互过程。随着定价时间步t递进,代理获取定价环境中的状态信息st,利用算法学习定价策略π给出定价动作at,促使定价环境状态转换到st+1并给予相应的立即回报rt+1,形成状态转换对(st,at,rt+1,st+1)。代理与定价环境持续交互,利用环境反馈,通过算法不断进行试错学习,积累定价经验,达到优化定价策略的目的。
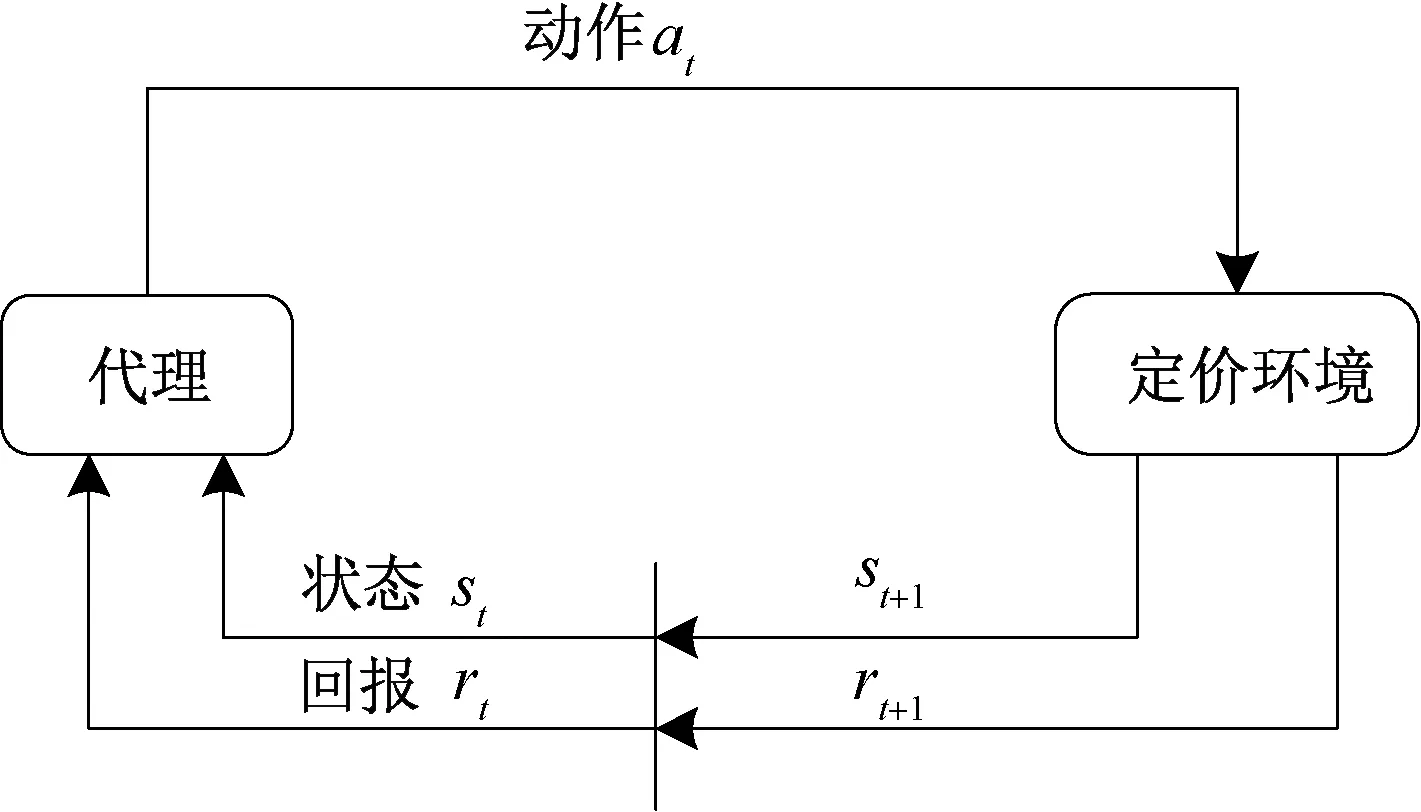
图1 动态定价的马尔科夫决策过程Figure 1 The MDP of dynamic pricing
动态定价策略的学习采用随机性策略π:S×A→[0,1],将状态可选择的动作映射到一定的概率上面,并满足下列的条件:s∈S,π(a|s)≥0,∑a∈Aπ(a|s)=1。代理的目标是通过持续交互寻找一个最佳策略π∗来最大化定价轨迹τ={s1,a1,r2,s2,a2,r3,…,sT,aT,rT+1,sT+1}的长期回报期望:

公式(2)中的r(τ)=,Eτ~π(τ)[r(τ)]实际表达的是周期内累积收益的近似期望,代理通过与环境的交互学习来求解公式(1)中精确规划模型的近似解。
3.2 定价算法
强化学习是一种在线自适应学习框架,被广泛用于处理序列决策问题。基于强化学习理论解决动态定价问题具有的优势在于强化学习从与环境的交互经验中学习最佳的定价策略,能够随环境变化而自适应地调整定价,并将需求估计与价格优化两阶段结合在一起。此外,对定价环境并不需要模型假设。深度强化学习框架DQN(Deep Q-network)[1]以及变体Double Q-learning[22]、Dueling DQN[23]等得到了广泛的应用,本文基于DQN 原理提出了解决高维数据特征下的动态定价学习框架DRL-DP。
Q-learning[24]是解决MDP 问题的一种表格式强化学习算法,在Q-learning 算法中为了评估当前状态s下根据策略π采取定价动作a产生的长期回报期望,定义状态- 动作值函数Qπ(s,a):

根据上述公式(3),最优的Q∗(s,a)=,那么最优的策略即是在每个状态s下选择最优的状态-动作值Q∗(s,a)下的定价动作a。根据贝尔曼等式[25],有:
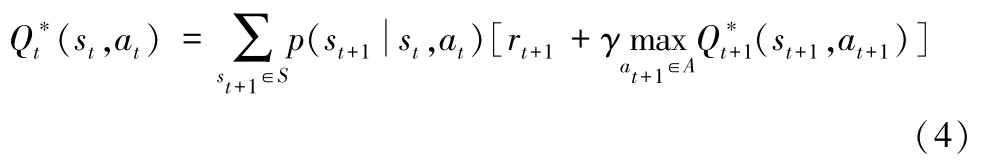
因此,根据状态-动作值函数Qπ(s,a)可以评估策略π的优劣,Q-learning 算法通过公式(5)迭代方式不断优化状态-动作值函数去改进策略。α∈[0,1]表示学习率:
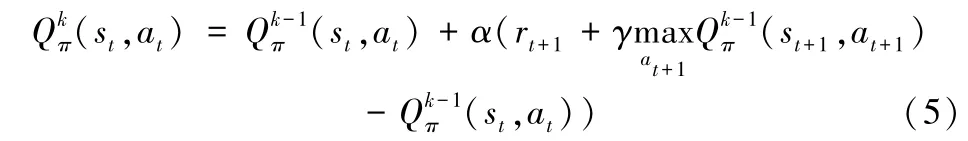
对于本文的动态定价问题,每个定价时间步的状态属于高维特征空间采样,采用Q-learning 算法的方式去估计每个状态-动作对(s,a)的Q(s,a)值是不可行的。解决此问题,可以采用参数为θ的函数近似器来估计Q(s,a)≈Q(s,a|θ)。对于高维状态特征空间下的动态定价问题,状态-动作值函数Q(s,a)是非线性的,文献[1]提出了良好的非线性近似器——神经网络Q(s,a|θ)去估计Q(s,a)。针对本文所解决的动态定价问题的Q-network 神经网络设计在3.3 节进行了详细的介绍。为了训练Q-network,采用均方误差L(θ)作为损失函数:

公式(6)中的D={(st,at,rt,st+1)}表示代理与环境交互形成的状态转换对集合,对于损失函数L(θ)一般采用批量梯度下降算法及其变体来训练。
接下来,本文根据DQN 原理在表1 中详细介绍了动态定价学习框架DRL-DP。在DRL-DP 中,本文对ε-greedy 策略的探索率ε采用了逐步衰减的方式,表明在代理与定价环境的交互初期鼓励积极的探索,随着交互进行逐步减小探索而增加对现有最佳策略的利用。对目标网络的更新采用了软更新机制,使得交互过程更加地平稳,不会使得定价策略突然发生较大改变,影响顾客体验。

表1 动态定价算法框架DRL-DPTable 1 The DRL-DP for dynamic pricing
3.3 Q-network 架构
Q-network 架构的设计关系到正确地近似表达不同状态下采取不同动作的累积折扣回报价值,在图2 中展示了本文设计的Q-network 架构。本文对Q-network 架构的设计综合考虑到了状态信息、观测信息以及序列反馈信息来评估当前状态下选取不同动作的累积折扣回报价值。因此,针对底层特征提取分别设计了观测状态、库存状态和序列反馈信息模块。
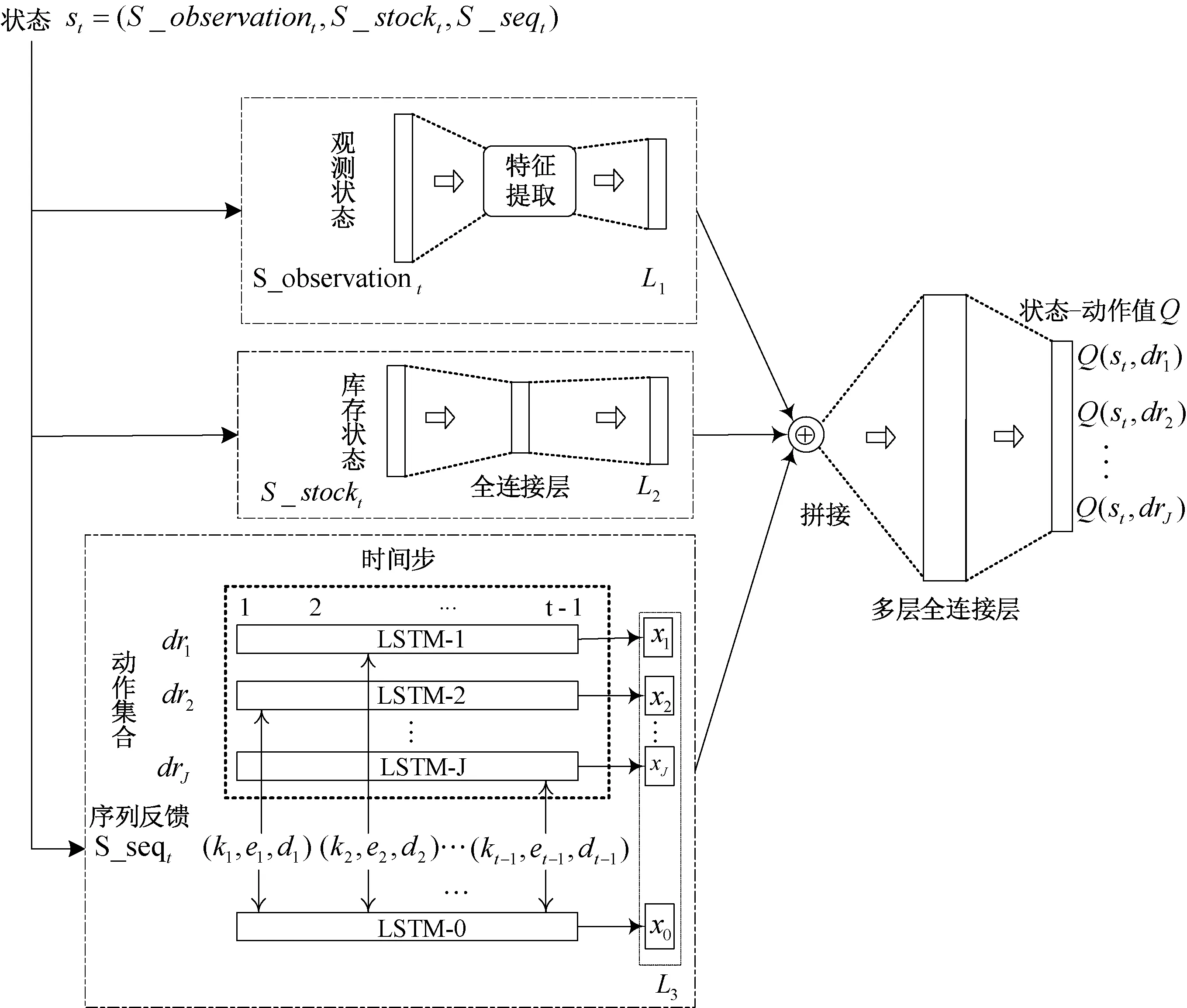
图2 Q-network 的架构Figure 2 The architecture of Q-network
观测状态信息提取:根据具体应用场景中的观测特征特点设计相应的特征提取,获取对顾客到达率以及需求信息表达所需的高阶特征层L1以便进一步优化。
库存状态信息提取:库存状态信息固定,输入的库存状态包含了不同时间段的库存信息,通过全连接层得到待查询的库存信息层高阶表示L2。
序列反馈信息提取:在动态定价问题中,每个时间步的定价动作决策需要考虑当前定价动作带来的立即回报与未来收益之间的平衡,历史的定价序列可以用于学习不同时间步在不同状态下的定价需求敏感性变化经验。序列反馈信息提取的输入为当前定价时间步t之前不同时间步的序列元组信息(ki,ei,di),其中i=1,2,…,t-1。本文采用长短记忆神经网络LSTM-0(Long Short-Term Memory,LSTM)不区分定价动作去捕获序列元组所带来的价值x0。此外,为了提取不同时间步在不同状态下采取不同动作的价值信息,根据采取的动作不同分别采用LSTM-1,…,LSTM-J 提取相应动作下的序列元组信息,得到综合的信息表达x1,…,xJ。如果只采用LSTM-0 部分,那么就可能会掩盖在信息变化中不同动作所带来的价值区别以及因为对某个动作探索不足导致信息过少而其价值被忽略掉。
多层全连接层:将L1,L2,L3信息层拼接后,采用多层全连接层提取综合信息表达。
状态-动作值输出层Q:表示在状态st下,定价集合A中每个定价动作的状态-动作值Q(st,drj)作为对动作价值的估计。
4 数值实验
接下来,本文将DRL-DP 与基于表格式强化学习动态定价算法Q-learning[26]、Q(λ)[27]的定价策略学习能力在模拟的不确定性动态定价环境中进行了对比分析。Q-learning、Q(λ)与DRL-DP 在MDP 定义的不同之处在于状态空间为商品剩余的库存量,回报函数采用立即收益Pmaxat·nt。实验内容如下:1)对比三种强化学习动态定价算法的收益表现以及定价策略的收敛情况分析;2)分析探索率对三种强化学习动态定价算法收益的影响;3)分析DRL-DP 回报函数设计的合理性。
4.1 实验环境设置
实验环境中假设代理不知道顾客的到达率以及需求模型,只通过与环境交互基于历史观测数据学习而作出定价决策,相关的实验数据通过如下假设生成。
顾客到达率模型:假设顾客的到达率是具有时间相关性的泊松分布,这个假设是随机性的。顾客的初始平均到达率为μ(1),由在区间[x0,x1]的均匀分布生成,平均到达率随时间t递减μ(t)=μ(1)-ξt,t=2,…,T。这符合对一部分易腐性和时尚类商品的需求热度随销售时间的推移而逐渐降低的现实应用背景。
需求模型:假设顾客支付意愿随距离售卖截止时间的接近而呈现指数性的增加,实际需求通过需求函数dt=u(t)-生成。
上述的顾客达到率模型和需求模型参照了文献[27]的生成方式。
DRL-DP 观测空间的特征生成:观测空间表达了代理对市场环境的感知,市场环境信息是由特征构成的(例如,人流量动态变化、竞争对手产品价格变化等),直接影响顾客到达率。刻画观测空间特征对顾客到达率的影响,即表达顾客到达率μ(t)与观测空间特征之间的关系,那么可以利用μ(t)生成观测空间的特征,表达特征决定不同时段的顾客到达率,建立观测空间特征与μ(t)之间的联系。本文采用了三层前馈神经网络模拟,网络的输入为顾客到达率μ(t),输出为观测空间的m个特征,即观测空间在时间步t的观测状态S_observationt=。
具体的环境参数设置如下所示:
初始库存N=300;
单周期最多定价次数T=10;
保留价格Pmax=20;
动作集合A={1.0,0.7,0.5,0.3,0.1};
顾客到达率μ(1)∈[60,80],μ(t)=μ(1)-5t;
需求函数dt=u(t)-5t·;
观测空间的特征数量m=10。
4.2 结果分析
文中4.1 节动态定价问题的最优定价策略由已知顾客到达率和需求全部信息的动态规划计算得到。表2 总结了三种算法在与环境交互学习一定迭代幕数之后的平均收益占最优定价策略取得收益的百分比。Q-learning 和Q(λ)的定价策略收敛速度较慢,平均收益取10000 幕迭代所得,DRL-DP 的定价策略收敛速度快,平均收益取1000 幕迭代所得。从总的平均收益水平分析可知,DRL-DP 从观测空间的状态特征学习到了顾客的到达率信息,收敛速率快,前1000幕与环境的交互已经比表格式强化学习动态定价算法10000幕的交互提升了百分之十几的平均收益水平。

表2 比较不同算法的平均收益Table 2 Comparison of the average revenue from different algorithms
下面比较三种动态定价算法策略的收敛情况。从图3和表3 中可知,随着与环境交互的增多,DRL-DP 在与环境的交互中逐渐学习改进定价策略,随着迭代幕数的增多,收益不断提高,最后策略收敛,收益趋于稳定。此外,可以比较出DRL-DP 的定价策略学习能力明显优于Q-learning 和Q(λ),收敛速度快,前100 幕所取得的平均收益已经高于了Qlearning 和Q(λ),在[500,1000]幕的平均收益已经趋于平稳,并且显著高于前两者算法的定价策略收敛到平稳状态后的平均收益。由于在不确定性的定价环境中,需求与顾客的到达率存在相关性,Q-learning 和Q(λ)定价模型的学习表达能力有限,造成对状态-动作值的估计需要采样更多的数据而导致算法的收敛速度较慢。此外,受到顾客到达率随机性的影响,Q-learning 和Q(λ)缺乏对观测空间特征信息的掌握,导致Q-learning 和Q(λ)估计的状态-动作值不够准确并且产生波动,而DRL-DP 利用神经网络去近似值函数能够在不确定性的定价环境中对其估计更加准确。实验结果验证了DRL-DP 在不确定性动态定价环境中具有比表格式强化学习动态定价算法更优的定价策略学习能力。

表3 在不同迭代幕数下的平均收益Table 3 The average revenue with different number of episodes
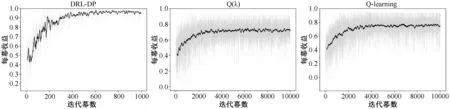
图3 不同算法随迭代幕数的收益变化Figure 3 The revenue with different number of episodes
下面分析探索率对平均收益的影响,表明探索率采用逐步衰减是一种更为合理的方式。本文分析了三种算法在逐步衰减探索率(从1 逐步衰减到0.01,即1→0.01)和不同固定探索率下的平均收益。在表4 中,Q-learning 和Q(λ)取10000 幕迭代的平均收益,DRL-DP 取1000 幕迭代的平均收益。从表4 分析可知,一个适中的探索率能够产生更高的平均收益,而探索过多不利于定价策略的收敛而且持续性过高的探索率还会影响顾客体验;探索过少容易使定价策略收敛到较差的次优解,在这两种情况下都会导致降低平均收益水平,一个更好的策略是采用逐步衰减的探索率来平衡探索与利用之间的关系。此外,实验结果也表明在不同的探索率下,DRL-DP 相比另外两种算法在大多数情况下都能取得更好的平均收益。
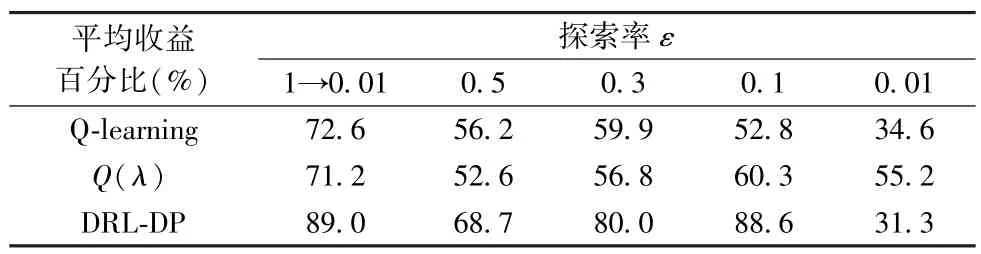
表4 不同探索率对平均收益的影响Table 4 The effect of different exploration rates on average revenue
下面分析DRL-DP 采用两种不同回报函数Pmaxat·nt和对收益的影响,表明本文定义回报函数为的合理性。图4 展示了DRL-DP 在两种不同回报函数下收益曲线的变化以及取得的平均收益,可知对于DRL-DP,当回报函数定义为取得的平均收益(89.0%)显著高于回报函数为Pmaxat·nt取得的平均收益(78.4%)。这是因为回报函数能够表达价格与收益转化率的关系。在实验环境中顾客流量是变化的,并且会使得需求产生自相关。顾客流量的变化会导致同一价格产生不同的收益,每个时段的收益转化率都是不同的,能够表达价格主导的这种收益转化率关系,所以取得的实际收益水平更好。此外,从收益曲线可以看出采用Pmaxat·nt作为回报函数,由于对状态-动作值估计的方差较大而导致了更大的收益波动情况,而在立即回报中引入比例提高了对状态-动作值估计的准确性,不仅提高了平均收益,而且提高了策略在不确定性动态定价环境中的稳定性。

图4 DRL-DP 采用两种不同回报函数下的收益表现Figure 4 The performance of the DRL-DP with two different reward functions
5 结语
本文基于深度强化学习理论提出了解决不确定性环境下有限库存动态定价问题的学习框架DRL-DP,并模拟了需求跨时段相互依赖的不确定性动态定价环境。通过仿真实验表明在不确定性动态定价环境中,需求与定价环境的特征存在相关性时,DRL-DP 相比于传统的表格式强化学习动态定价算法能够学习到更优的动态定价策略。
DRL-DP 与环境交互学习动态定价策略,自动从定价环境中的各种影响因素学习需求与价格的关系来最大化长期累积收益,通过交互经验改善动态定价策略。DRL-DP 不需要模型配置,同时适用于高维状态特征的学习,这对于大数据环境下现实应用问题的动态定价策略探索具有积极的意义。现实应用场景的环境更加复杂多变,希望未来对此方面感兴趣的学者能够基于真实的应用场景数据来解决动态性数据的获取问题,以实现更进一步的研究。
