结合用户特征的政务服务协同过滤推荐方法
2023-02-04仇阿根张用川郑莹莹
仇阿根 张用川 罗 宁 郑莹莹 陆 文
1(中国测绘科学研究院 北京 100830)
2(重庆交通大学 重庆 400074)
3(中国科学院软件所 北京 100190)
1 引 言
随着人类获取地理空间位置能力和精度的提升,地理信息被广泛应用于各个领域。由于技术进步带来的数据增长,在数据应用过程中,出现了数据过载问题,研究者们期望利用推荐系统解决该问题并取得了一定的进展。近年来,党中央、国务院高度重视“互联网+政务服务”工作,全国各地相继开展了智慧政府的建立及相应模式的创新,不断提升自身的行政能力和服务能力[1]。在实际生产场景中,目前存在的问题有:(1)政务服务事项繁杂、分类众多、覆盖面广,给服务提供带来了困难;(2)政务服务面向社会大众,无论是企业还是个人,因其自身差异,都需要个性化的信息服务;(3)随着大数据时代的发展,用户难以在眼花缭乱的数据中找到自己所需要的信息[2-3]。虽然政府系统、网站采用搜索引擎技术解决上述问题,并取得了一定成效,但传统的搜索引擎无法有效地整合政务服务中的个人特征,政务服务信息同质化程度较高,用户需要反复地人工过滤搜索的信息,才能找到真正“合适”的信息[4]。随着我国政务服务水平的不断提升,为公众提供个性化的政府资源推荐服务尤为重要。众多专家学者将目光投向用户画像领域——通过对用户信息的描述与提取,将其作用于政务信息资源的个性化推荐。在大数据环境下,用户画像技术能够全面细致地把握用户的兴趣和需求,为用户提供个性、优质的政务服务信息资源[5-6]。
在政府信息研究方面,李娇等[7]通过 Apriori算法抽取用户访问页面之间的关联规则,为个性化政务信息服务提供了有力的数据支持。胡海波[8]构建了基于“LBS+SNS”的移动政务个性化信息服务模型,分析了移动政务的信息服务模式,并指出政务服务观念应从“人找服务”转变为“服务找人”。用户画像技术可以将用户诉求与设计方向相结合,转化联结用户属性数据,以勾画目标用户[9]。RM Quintana 以用户的检索行为、兴趣偏好等个人信息为基础,构建了 MOOC 用户画像模型[10]。盛姝等[11]利用医享网的患者数据,基于用户角色属性、行为属性及文本特征,构建了典型用户识别指标,将用户群体分为 4 类,构建画像概念模型;再利用用户行为识别算法与主题聚类算法,进一步挖掘用户处于不同角色关注的主题内容,实现用户信息需求的精准分析[11]。随着电子政务的深入发展和“互联网+政务服务”工作的推进,政务信息资源总量不断增长,用户需求越来越多样化、个人化。政府个性化信息服务应主动考虑用户需求、重新定位,以用户行为信息为服务导向,以用户需求为核心,主动收集用户属性及感兴趣的信息,预测用户的未来发展趋势,针对用户的信息需求,提供最贴切的信息服务。在不了解用户偏好的情况下,协同过滤推荐算法仅利用用户对项目的历史行为数据,就可预测用户对未知项目的评分,从而为用户进行推荐。杨峰提出的电子政务信息推荐服务框架则采用了信息协同过滤技术,向公众主动提供适合用户的信息组合,并能够较好地把握用户需求[12-14]。
目前,国内政务信息资源个性化服务在推荐技术方面进行了一定研究,但以用户为中心进行导向型服务的相关研究较少。大部分研究针对信息资源处理方式进行改进和完善,且传统的个性化推荐方式以内容过滤或协同过滤为主,在推荐精准度上仍存在偏差。由于政务服务的独特性,上述研究方法存在以下弊端[15-16]:(1)在使用协同过滤算法时,未考虑用户体量大、存在热门信息等因素,其中,冷门信息将导致得分矩阵分布极端稀疏;(2)未综合考量用户属性与用户行为信息。为解决上述问题,本文提出了一种将用户画像与协同过滤算法进行融合的方法。具体步骤为:首先建立用户画像标签,然后信息量化用户画像,最后将量化信息填充到协同过滤算法的得分矩阵中,并参与推荐计算。本方法可以在考虑用户属性信息、兼顾用户行为信息的同时,解决得分矩阵分布极端稀疏的问题,提高推荐精度。
2 相关技术与理论
2.1 基于用户的协同过滤算法



2.2 用户画像技术
用户画像概念最早由交互设计之父 Alan Cooper 提出,指通过建立真实用户信息的标签模型,以实现用户信息的抽象化表达。该模型基于一系列的正式数据,同时使用虚拟的方式代表用户数据[19]。一般地,用户画像的构建仅需遵循两个基本原则:首先是从具体的服务情景出发,针对性地解决实际问题;其次是按照用户的独有特点和特征进行设计。政务信息服务用户画像指收集用户使用政务信息服务过程中的数据,数据收集应尽可能全面且具体,包含用户的基本信息及其真实的动态数据情况等,可分别从静态和动态的角度出发,更好地掌握和收集用户的数据[20]。在收集的数据基础上,挖掘出表示用户特征的关键性标签,并在这种共性指导下,给予个性的特征以独特的呈现方式,利用信息的行为规律,实现政务信息资源的深层次个性化推荐服务[21-22]。用户画像的构架流程,可从以下 3 个方面进行阐述:
(1)数据收集:用户数据量大且来源多样,可根据用户画像的不同特征属性,将用户数据分成多个维度。目前,用户画像数据收集手段主要包括社会调查、网络数据收集和平台数据库收集3 种方式。具体指:通过社会调查法中的访谈、调查等方式收集数据;利用网络爬虫等技术手段合法获取用户公共数据;直接从平台数据库收集用户数据。例如,通过各类管理系统、数字资源服务系统以及微博、微信等相关移动平台的用户数据库,直接收集各类用户数据。
(2)特征提取:为确保用户画像数据的完整性,避免脏数据影响模型构建,需要对用户数据进行整理和分类,并通过一定的数据挖掘方法提取用户特征及用户标签,并构建用户画像。目前,用户肖像研究主要采用人工提取和技术提取两种方法进行特征提取。
人工提取:在相关理论、研究者的知识和经验的支持下,通过文献综述、研究、访谈和专家建议,对抽象用户属性进行描述,从而提取用户特征,构建用户画像。
技术提取:利用机器学习算法(如决策树、逻辑回归和支持向量机等)提取用户特征,通常这些算法适用于大数据背景下海量用户数据的研究场景,如利用 LDA 模型文本挖掘用户感兴趣的微博主题,获得用户偏好主题。
(3)形成用户画像:完成数据收集和特征提取后,利用机器学习算法构建模型,将处理后的结果转化为用户标签,用各种直观、清晰的视觉图形呈现用户画像。目前,常用的表现形式包括标签云、人物图像、统计图、直方图、雷达图等,可根据实际需求创建。
本文从某市平台数据库中收集企业用户的基本信息与行为信息,利用人工提取的方式,对企业法人用户的用户画像进行构建,具体画像信息如表 1 和图 1 所示。

图1 用户画像Fig. 1 User portrait

表1 用户画像信息Table 1 User portrait information
3 方法改进
目前,传统协同过滤方法在政务服务个性化推荐的研究中,仅利用用户行为信息即用户得分矩阵计算用户间相似度,没有考虑用户地理位置等属性信息,推荐精度可能较差。此外,政务服务用户体量大,存在热门事项信息和冷门事项信息等特征,可能导致得分矩阵分布极端稀疏[19]。
台湾专科护理师甄审考试笔试从2006年12月开始,而口试则从2007年4月开始,口试一直使用OSCE。目前该考试只设定一站,时间为20分钟,包括15分钟考试和5分钟计分与换场(含看题2分钟)。主要测试应试者评估病人、鉴别诊断、临床推理决策、拟定照护计划与沟通等专科护理师应具备的核心能力。
为解决上述问题,本文从两方面着手:一方面,根据推荐业务的特点结合地理位置信息,建立政务服务用户画像与自然人政务服务用户画像,获取用户标签,为后续推荐计算中结合用户地理位置等属性信息奠定基础;另一方面,从用户相似度计算的方面着手,改进传统协同过滤算法,将建立好的用户标签在得分矩阵中进行标记,量化用户地理位置等属性信息,同时对用户评分进行修正,提出利用用户行为信息、地理位置等属性信息,构建用户特征矩阵,用于计算用户间相似度,该矩阵的填充值即用户特征,是用户属性信息与用户得分融合计算的结果。改进原理如图 2 所示。
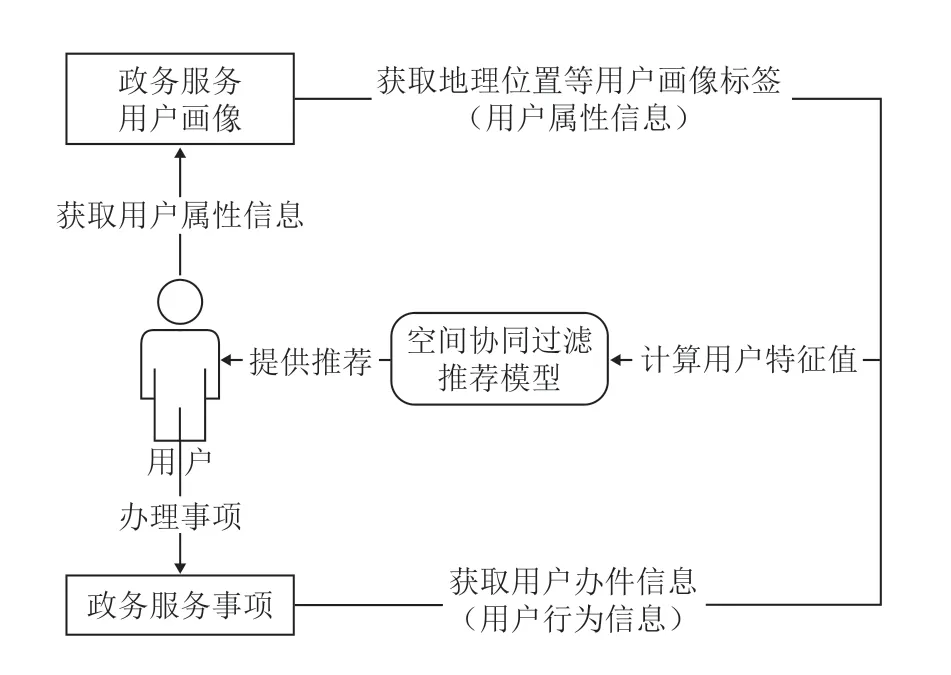
图2 政务服务推荐算法流程Fig. 2 Government service recommendation algorithm flow
3.1 度量奇异值权重下的政务服务用户行为特征偏好
Bobadilla 等[19]曾提出一种基于奇异性的相似度量模型,以区分用户评分的相关性。其基本思想为:将评分较高的项目定义为正向项目,评分较低的为负向项目,若存在两用户对某项目的评分都为正向,而其他大部分用户对其评分为负向,那么此项目对于两个用户的相似度计算具有较高的参考价值,将该项目的影响因素与传统协同过滤方法相结合,用于计算用户之间的相似度,在预测项目得分的同时,进行项目推荐。
在该方法中,针对不同用户对各项目的评分情况,分别为其标记“正向”标签与“负向”标签,以期实现用户行为的分类及数据表达。将用户属性与得分情况综合考量后,对办理事项进行标记,从而量化用户属性信息,以解决传统协同过滤方法中未考虑用户属性信息的问题,提升政府服务事项推荐的准确率。
假设企业法人用户-办理事项评分矩阵如表 2所示。通过构建用户画像,得到 5 个企业法人用户的产业类型信息,将此信息与企业法人用户-办理事项评分矩阵相结合,把用户所属的产业类型标签标记在其评分矩阵的对应位置上,得到如表 3 所示的企业法人用户-产业类型矩阵。

表2 企业法人用户-办理事项评分矩阵Table 2 Enterprise legal person user-transaction score matrix

表3 企业法人用户-产业类型矩阵Table 3 Corporate user-industry type matrix
R代表房地产业,F代表金融业,若某办理事项中R标签较多,则表明该办理事项对于房地产业类型企业办理意愿更大,反之则是金融业类型企业办理意愿更大。其中,L为用户画像得到的所有用户属性的统称。




3.2 结合用户特征的政务服务协同过滤推荐方法
本文推荐算法融合了用户行为信息、地理位置等属性信息,提高了推荐准确率,改进了传统协同过滤算法关于用户相似度的计算方式,在用户-得分矩阵的基础上,利用用户-特征矩阵,提出了空间协同过滤算法,其具体算法步骤如图 3所示。
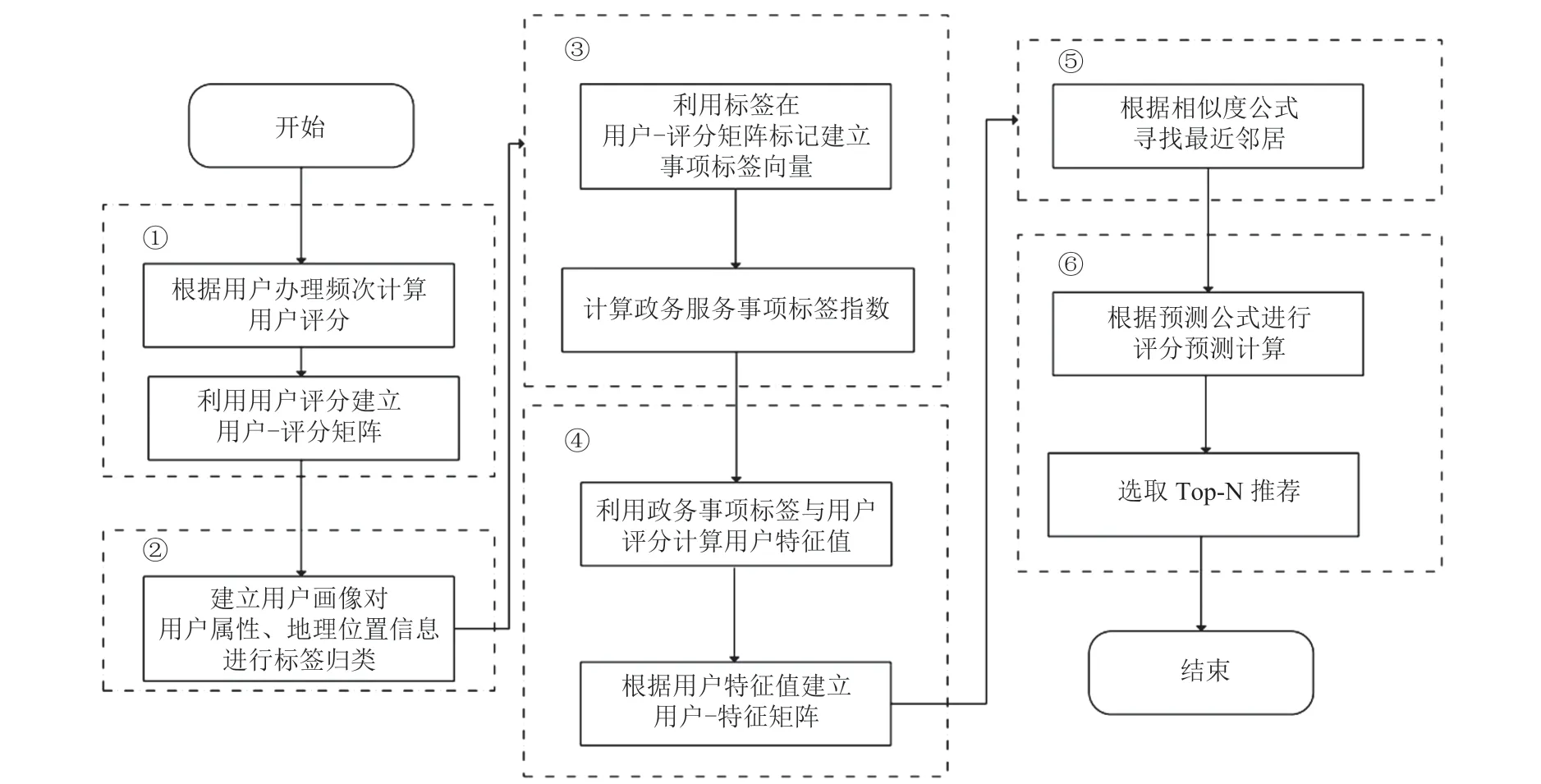
图3 空间协同过滤算法流程Fig. 3 Spatial collaborative filtering algorithm flow
本文提出的结合用户特征的政务服务协同过滤推荐算法在构建用户评分矩阵时,使用了与传统协同过滤算法相同的方式。在用户相似度计算方面,本文算法将用户评分属性信息相结合,利用第 2.2 节提出的用户特征,构建如表 4 所示的政务服务用户-特征矩阵。
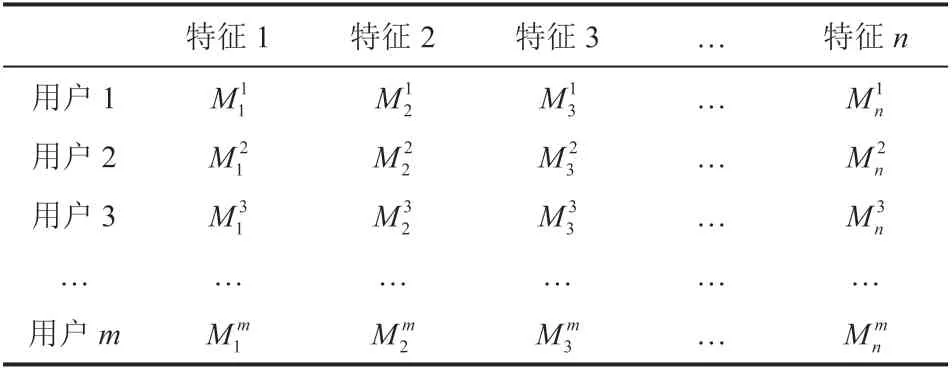
表4 企业法人用户-用户特征矩阵Table 4 Corporate user-user feature matrix



4 实验设计与分析
4.1 数据预处理
本文使用的数据均来源于某市政务服务平台与市场监督管理局,由企业法人办件数据、企业法人用户信息数据、政务服务办理事项数据(政务服务事项实施清单)3 部分构成。根据实际情况对数据进行清洗处理。剔除重要字段缺失、错误或其他可能影响实验结果的不良数据后,选取办件数量排名前 10 000 的企业法人用户及其 55 000余条办件数据,构建企业法人用户-办理事项评分矩阵,评分值区间为[0,1],部分评分数据如表 5所示。

表5 企业法人用户-办理事项评分数据(部分)Table 5 Score data of enterprise legal person user-matters handled (part)
利用企业法人信息数据构建用户画像,主要分为风险评级、产业类型、公司性质、注册资金、行政区划、注册时间 6 个大类,部分标签内容如表 6 所示。根据用户画像标签,可建立如表 7 所示的用户信息表。

表6 企业法人用户标签数据(部分)Table 6 Corporate user label data (part)

表7 企业法人用户信息表(部分)Table 7 Corporate user information table (part)
为满足实验训练与检验算法的需要,将数据分为训练集与测试集两部分,其中 80% 为训练集,20% 为测试集。利用企业法人用户-办理事项评分数据,将训练集数据结合第 3.1 节提及的度量奇异值权重下的政务服务用户行为特征偏好方法,构建企业法人用户-用户特征矩阵,至此数据处理工作结束。
4.2 推荐算法评价指标
一方面,本文采取平均绝对误差(Mean Absolute Error,MAE)作为实验结果的评价指标,其主要根据实验所获取的预测评分与实际用户评分的差值大小来判定算法的优劣性。差值越小,算法性能越优;反之则算法性能越差。计算公式如公式(11)所示[23]。


另一方面,由于推荐类算法可看作是一种二元分类问题(推荐与不推荐),所以也常采用准确率、召回率、F1值作为评价模型优劣的指标[17-18]。其中,准确率(Precision)是指在所有被推荐项目中,用户偏爱项目所占的比率;召回率(Recall)是指在所有被推荐项目中,用户偏爱项目的总数与总项目集合中用户感兴趣项目总数的比率;F1值是模型准确率和召回率的调和平均,其作为一种综合性的评价指标,可以更加全面直观地评价算法的整体性能。


为进一步比较基于用户空间协同过滤的政务服务推荐方法的优劣,基于相同的政务数据和服务推荐流程,研究采用传统协同过滤对面向企业法人的政务数据进行服务推荐。传统协同过滤算法通过计算相似度,依据获取的预测评分实现个性化推荐。
4.3 实验结果
4.3.1 推荐结果分析
利用上述方法为企业法人进行政务服务推荐。推荐用户是某投资担保公司,设立日期为2013 年,主营业务是信贷担保、票据承兑保证、外贸融资保证、工程投资保证,其所属产业大类为金融业,企业注册地为西城区。在参数设置中将邻近值K设置为 10,并选取预测得分 TOP-10进行推荐,结果如表 8 所示。
由表 8 可知,前 8 条事项与该公司的业务范围有较大关联,后 2 条事项属于各企业法人的相关通用办理事项。因此,该推荐结果具有一定的参考意义。
表8 用户推荐事项(部分)Table 8 Users recommend matters (part)
4.3.2 评价指标结果分析
将本文方法与传统协同过滤算法和基于内容的推荐算法进行对比,根据 MAE 分析最优邻居值的大小,并比较两种算法的优劣性。其中,最大邻近值以 10 为间隔进行选取,范围为[10,80]。
由图 4 可知,随着最大邻近值的不断增加,三者的 MAE 值初始时均呈下降趋势,当最邻近数为 60 时,MAE 值逐渐趋于平稳,达到最优状态。在本实验选取的邻近值范围内,与传统协同过滤算法和基于内容的推荐算法相比,本文方法的 MAE 值较小,降低了约 5.3%,稳定程度更高,说明在一定程度上,本文提出的算法可提升协同过滤算法的预测评分质量。

图4 MAE 比较Fig. 4 MAE comparison
由于准确率、召回率、F1值为二元评分体系,因此,需要对实验结果进行评分转换,以便分析本文实验数据。其中,1~3 分为不相关项目,4~5 分为相关项目。由图 4 可知,设置最大邻近值K=60,在性能最优的状态下,对不同算法的 3 个值进行分析,用以比较两种算法的推荐能力。
由图 5、图 6 和图 7 可知,与传统的协同过滤算法相比,本文提出的顾及位置与用户特征的政务服务协同过滤推荐方法的推荐效果较优。由图 5 可知,随着推荐个数的增加,两种算法的准确率均不断降低,究其原因,当用户推荐个数不断增加时,参与计算的用户得分矩阵与用户特征矩阵的规模会随之扩大,导致了数据稀疏性的增加。虽然本文提出的算法在一定程度上可削弱稀疏性的影响,但并不能完全消除。两种算法的召回率与准确率呈相反趋势,随着推荐个数的增加,召回率不断上升,究其原因,随着实验推荐结果中政务服务事项的增加,其中含有用户感兴趣的事项也在增加,所以召回率呈现增加的趋势。随着推荐个数的增加,两种算法的F1值均呈现先上升后下降的趋势,究其原因,是其变化趋势与准确率和召回率的变化速率有关。在传统的协同过滤中,少有空间信息参与计算。与无地理位置信息参与的推荐计算相比,有地理位置信息参与的推荐计算效果较优,这是由于政务服务事项推荐的业务与数据性质导致的。对于所有政务服务事项而言,由于地区不同、所属的行政级别不同,在政务服务业务中,完全相同的一项办理业务会被认为是不同的事项,拥有不同的统一事项实施编码,分条存储于政务服务事项库中。因此,在推荐计算中,若不考虑地理位置信息,就会为用户推荐多条相同但分属不同地区与行政级别的事项。因此通过增加用户以及事项的地理位置信息,可一定程度上减少该情况的发生,增加推荐精度。

图5 准确率比较Fig. 5 Comparison of accuracy

图6 召回率比较Fig. 6 Comparison of recall rates

图7 F1 值比较Fig. 7 Comparison of F1 values
综上所述,与传统协同过滤方法相比,本文方法在政务服务事项领域的性能更优,推荐效果更好。
4.3.3 地理位置信息因素影响
为验证地理位置信息对推荐效果的影响,本实验将处理完毕的数据进一步划分:一部分数据包含用户的地理位置信息数据,另一部分不包含此类信息。同样利用准确率、召回率、F1值 3 种二元评分指标,针对实验数据进行评分转换。其中,1~3 分为不相关项目,4~5 分为相关项目,设置最大邻近值K=60 开展实验,并使用本文提出的一种结合地理位置与用户特征的政务服务协同过滤推荐方法,以分析地理位置信息对推荐效果的影响。
由准确率、召回率、F1值 3 个评价指标的实验结果(如图 8、图 9 和图 10)可知,与无地理位置信息参与推荐计算相比,有地理位置信息参与的推荐计算效果较优,这是政务服务事项推荐的业务与数据性质导致的。
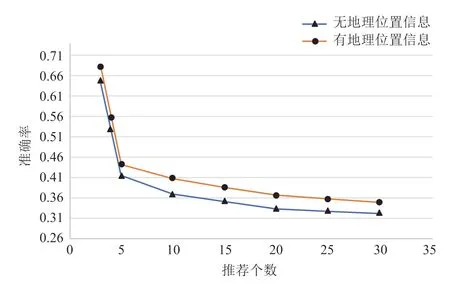
图8 地理位置对准确率的影响Fig. 8 The effect of location on accuracy

图9 地理位置对召回率的影响Fig. 9 Effect of location on recall ratio

图10 地理位置对 F1 值的影响Fig. 10 Effect of location on F1 value
5 结 语
政务信息资源的服务逐渐从大众化服务走向了个性化服务,良好的政务推荐服务不仅让政府能够更好地服务公众,而且公众能够更加及时地了解、清晰认识政府的方针政策,二者良好交流关系的建立可促进社会的稳定发展。针对政务服务事项推荐,本文提出一种结合用户特征的政务服务协同过滤推荐方法。该方法将用户画像技术与协同过滤技术相结合,引入政务服务领域,综合用户属性信息、用户位置信息、用户办件信息,为用户推荐可能需要办理的政务服务事项。本文还构建了有地理位置信息的政务服务用户画像,综合考虑用户属性与用户行为信息的同时,解决了由于热门、冷门事项导致的数据稀疏性问题。实验结果显示,与传统协同过滤方法相比,基于用户空间协同过滤的政务服务推荐算法获得了较小的 MAE 值和较低的准确率、召回率、F1值,说明引入地理位置信息可以提升推荐精度。在后续工作中,应进一步借鉴其他相关领域学科的经验,提升画像构建的合理性;其次,本实验仅使用企业法人政务服务数据进行分析,不足以构建较为完整的政务服务链条,在对服务进行推荐时,损失了一定的精度,后续可利用多组不同来源以及类型数据提供更优质的服务,构建完整的政务服务链条,以期发现更具通用性与普适性的算法。
