用于复杂环境下果蔬检测的改进YOLOv5算法研究*
2023-02-04汪颖王峰李玮王艳艳王应彪罗鑫
汪颖,王峰,李玮,王艳艳,王应彪,罗鑫
(西南林业大学机械与交通学院,昆明市,650224)
0 引言
我国作为世界农业生产大国之一,果蔬种植规模庞大,其采摘过程成为农业生产过程中重要环节。然而传统采摘主要以人工采摘为主,采摘难度大,工作时间长,同时却工作效率低下,致使投入生产的成本增加[1]。目前,随着技术的不断发展,农业机械自动化已成为主流趋势,自动采摘机械人的出现可以有效缓解劳动力紧缺的问题,具有重要的实际意义和广泛的应用前景[2]。
识别检测果蔬的精度成为准确进行自动采摘的关键前提。然而自然条件下的果蔬的复杂环境限制了果蔬的检测精度,例如树叶的遮挡,目标果蔬之间的重叠遮挡,光照环境等都会影响果蔬的检测识别。
目前国内外对果蔬检测识别的研究也已获得了一系列进展。车金庆等[3]将分割方法与注意力机制相结合实现黄色、绿色苹果图像的分割;Lu等[4]提出一种使用纹理和强度分布来检测树木图像中的绿色水果检测方法,但是识别准确率受光照影响较大;Wajid等[5]运用处理归纳决策的分析方法,用于检测柑橘的成熟度并进行果实分类,但识别检测精度不高。以上这些方法主要通过颜色纹理等特征来识别,多受环境影响,鲁棒性较差,无法更准确高效地检测识别目标。
相比于传统目标检测方法,深度学习在目标检测方向的应用展现了较大优势,卷积神经网络更广泛地应用于目标检测。现阶段与深度学习相关的目标检测方法主要包括两类,一类是两阶段目标检测算法,对待选区域依次进行提取划分,代表算法有R-CNN[6],Fast R-CNN[7],Faster R-CNN[8]等;另一类是单阶段检测算法,用单一卷积网络直接输出预测框和物体名称,代表算法主要有SSD[9]、YOLO[10]。何进荣等[11]提出了多卷积神经网络融合DXNet模型,提取出更加底层的纹理特征,显著提高苹果外部品质分级精度。彭红星等[12]改进结合SSD与深度残差模型,对4种水果进行检测,改进后的模型对遮挡面积小的水果检测精度较高。薛月菊等[13]采用YOLOv2算法识别芒果,对精度和检测速度有所提升,但无法满足大视场环境下的检测。
针对以上问题本方法选用YOLOv5网络结构作为基准[14],YOLOv5相比于传统目标检测算法,识别精度高,检测速度快,具有很强的实时性。本文提出嵌入卷积注意力机制以提高网络特征的提取能力,并且引入完全交并比非极大抑制算法和加权双向特征金字塔网络,在不同光照下和大视场遮挡重叠的环境下进行识别试验,以验证网络的实际检测效果。
1 YOLOv5算法
YOLOv5(You Only Look Once)是一种单阶段目标检测算法。YOLOv5网络结构如图1所示,由四部分构成:输入端、主干网络、Neck和预测端。
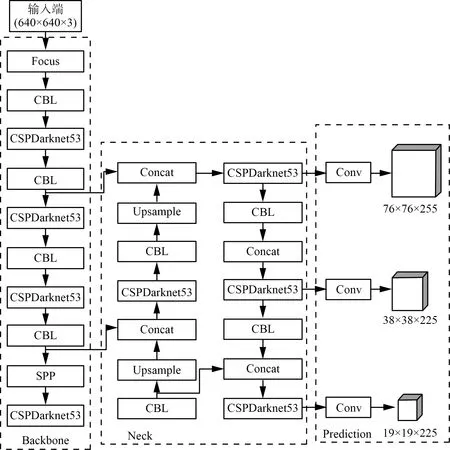
图1 YOLOv5网络结构
输入端主要包括Mosaic数据增强、图片自动缩放和锚框自动计算。Mosaic数据增强将变换后的图片进行重新排布拼接,丰富数据集内容,提升模型的训练速度和网络的精度;图片自动缩放对原始图片自动填入最少的黑色边框,降低计算量;锚框自动计算对原始输入框的长宽进行预测,自动将其与真实框进行对比,不断迭代更新,调整差距以此得到不同数据集所输出的最佳锚框值。
主干网络主要包括CSPDarknet53和Focus模块。CSPDarknet53提取特征图片,包括采用1×1,5×5,9×9,13×13的最大池化方式的SSP(空间金字塔池化)操作,输出长度相同的特征向量以此接收更多特征;Focus模块对图片进行切片互补操作,集合深度和高度信息扩充通道数,实现下采样以达到增加局部感受野的作用。
Neck中采用FPN+PAN的结构,将自上向下传递的FPN层与自下向上传递的PAN层结合,传递多尺度标准的概念与位置信息,进一步融合上采样的结果和特征图,实现不同特征的融合。
预测端采用GIOU-Loss损失函数,反馈目标的定位,根据不同尺度下生成的预测框采用非极大抑制[15](Non-maximum suppression,NMS)操作。
2 CCB-YOLOv5网络
为了解决原始Yolov5网络对于不同光照下的遮挡目标和密集目标检测存在的不足之处,本文提出一种CCB-YOLOv5(CBAM and CIOU-NMS and BiFPN-YOLOv5)网络,在主干网络的CBL卷积模块中嵌入卷积注意力机制CBAM,提高目标特征的提取能力,原始Yolov5采用非极大抑制算法进行迭代—遍历—消除过程,删除重复的检测框,只保留当前最大置信度的检测框。非极大抑制直接删除相邻的同类别目标,对于密集目标检测效果较差。因此引入完全交并比非极大抑制算法(CIOU-NMS)[16],考虑了预测框和真实框的长宽比成一定比例,生成预测框并进行迭代遍历,让预测框不断趋近于真实框以提高预测框的输出精确度,加快了预测框的回归收敛速度,降低密集目标重叠导致的漏检率,使得预测框更接近真实框。为了缓解特征提取时的遗漏情况,将 Yolov5原始加强特征提取网络PANet[17]结构改进为加权双向特征金字塔网络BiFPN[18]结构,进行自上而下的深层特征和自下而上的浅层特征融合,并跳过某些中间层,连接融合不同尺度的特征层。其网络结构如图2所示。
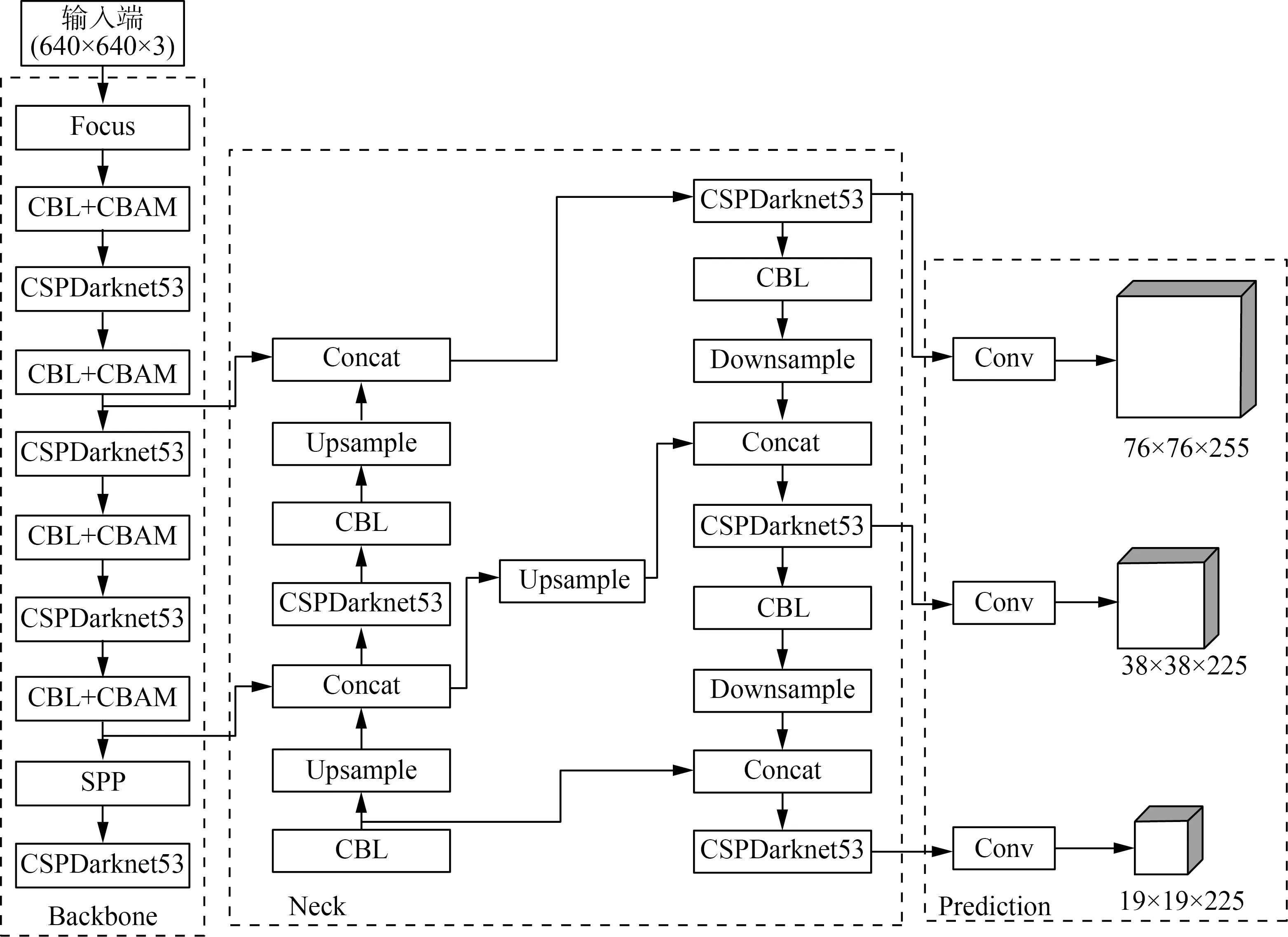
图2 CCB-YOLOv5网络结构
2.1 卷积注意力机制
CBAM是由独立的一维通道注意力和二维空间注意力两个模块组成,同时关注通道和空间两方面信息,聚焦于突出特征。图3为通道注意力模块的示意图,首先对输入的深度和高度方向分别取平均特征点和最大特征点,压缩冗余空间,生成两个不同空间上的1×1×C的特征图,然后送入一个两层共享的神经网络,先压缩再扩充,保持通道数C不变,接着对元素进行逐一生成权重值加和后送入sigmoid函数,生成特征图。具体计算如式(1)所示。
Mc(F)=σ(MLP(AvgPool(F))+
MLP(MaxPool(F)))
(1)
式中:Mc——通道注意力特征图;
σ——sigmoid函数;
MLP——共享神经网络;
AvgPool——平均特征点;
MaxPool——最大特征点;
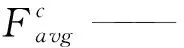
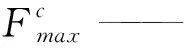
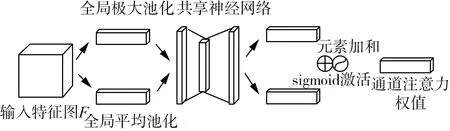
图3 通道注意力模块
图4为空间注意力模块的示意图,空间注意力更加关注输入图像的具体位置信息,与通道注意力关注的特征信息互补,进一步强化通道和位置特征融合得到输出特征图。空间注意力模块将前一步的输出结果作为其输入,首先对通道进行取平均值点和最大值点操作,实现信息的聚合,生成两个跨通道的二维映射,然后扩展这两个特征图的深度,经过一个7×7的标准卷积层,降维为一个通道,再通过激活函数进行标准化生成特征图。最后整合两模块的输出矩阵得到最终的特征图。具体计算如式(2)所示。
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))
(2)
式中:Ms——空间注意力特征图;
f7×7——7×7的卷积计算;
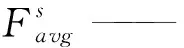
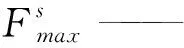
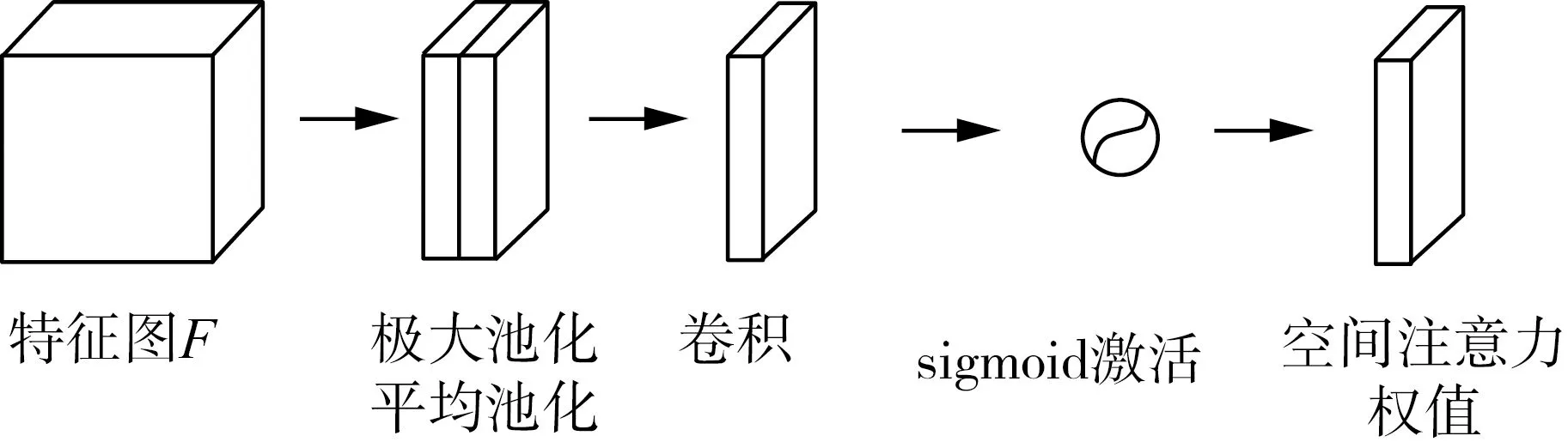
图4 空间注意力模块
2.2 非极大抑制
完全交并比非极大抑制算法(CIOU-NMS)中CIOU[18]不仅考虑了重叠面积、中心点距离,而且考虑了长宽比,加入权重系数α和长宽比特定参数ν,计算公式如式(3)~式(5)所示。
(3)
(4)
(5)
式中:b——预测框对角线交点;
bgt——真实框对角线交点;
ρ——两交点之间的直线距离;
c——内含预测框和真实框的最小矩形的对角线长度;
α——权重函数,用来调节比例大小;
ν——一致性比例,用来保持长宽比相似;
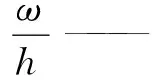
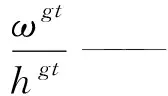
通过CIOU解决了预测框完全包含真实框但真实框所处位置不同时损失值一样的缺点。
2.3 多尺度特征融合网络
为了避免网络加深导致特征选择性丢失。Backbone主干网络提取的3种不同尺度BiFPN结构,进行多尺度特征融合。具体原理图如图5所示。
P3、P4、P5、P6、P7经过卷积和平均池化后生成特征图P-in3、P-in4、P-in5、P-in6、P-in7,P-in7进行上采样后与P-in6叠加得到P-td6,P-in6进行上采样后与P-in5叠加得到P-td5,以此类推,P-in5、P-in4进行上采样后叠加得到特征图P-out3,再依次进行下采样,获得特征图P-out4、P-out5、P-out6、P-out7。具体运算如式(6)、式(7)所示,以P-td4、P-out4为例,输出的P-out3、P-out4、P-out5、P-out6、P-out7包含五个深浅语义信息的全局特征。在识别小目标时可以轻松进行多尺度特征融合,更好地表达信息,以此提高识别精度和准确率。
(6)
P-out4=conv{[ω1·P-in4+ω2·P-td4+ω2·Resize(P-out3)]/(ω1+ω2+ω3+ε)}
(7)
式中:P-in——输入特征;
P-out——输出特征;
P-td——融合过程的中间层;
ωi——可学习的权重,介于0~1之间;
ε——远小于1的数。
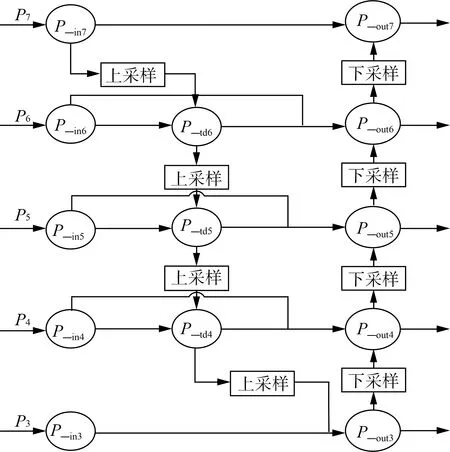
图5 BiFPN原理
3 试验与分析
3.1 数据预处理
本试验以苹果为例,研究使用的数据集来自网络爬取到的苹果图片,经过人工挑选,删除模糊及重复图像后,获取共计1 023幅苹果图像。以苹果个数作为分类条件,其中单个苹果图像361幅,2~10个苹果图像603幅,10个以上苹果图像59幅。以不同光照作为分类条件,其中顺光图像409幅,逆光图像387幅,侧光图像227幅。
采用LabelImg软件对最终图片进行标注,包括类别名称和外包矩形边框,其信息存储于xml类型的标注文件内。为了提高模型对样本的适应能力对1 023幅苹果图像进行数据增强,扩充为原来的5倍,共计5 115 幅苹果图像,其中训练集和验证集的数量分别为4 575和540。批训练数设为16,初始学习率设为0.001,权重衰减设为0.000 5,epoch设为100,采用随机梯度下降法进行训练。
3.2 试验环境
本文试验基于pytorch深度学习框架,试验环境为python3.8,并行计算架构CUDA11.2,GPU加速原语库cuDNN8.2,具体配置为Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz、内存16 GB和显存8 GB的NVIDIA Quadro P4000。
3.3 评价指标
为了评估训练的模型在自然环境下对苹果的检测效果,本文采用精确度P(Precision)、召回率R(Recall)、平均精度AP(Average Precision)和mAP(mean Average Precision)四个指标评价模型的检测效果。首先介绍以下几个概念:TP(True Positives)说明是苹果正确判定为苹果,即为真正类;TN(True Negatives) 说明是苹果错误判定为不是苹果,即为真负类;FP(False Positives) 说明不是苹果,错误判定为是苹果,即为假正类;FN(False Negatives) 说明不是苹果正确判定为不是苹果,即为假负类。
其中精准率P表示正确判定为苹果占全部判定为苹果(包括错误判定为苹果)的比例。
(8)
召回率R表示苹果正确检测为苹果占全部苹果比例。
(9)
平均精度AP表示精准率P和召回率R所构成的曲线围成的面积,即AP值。
(10)
均值平均精度mAP表示对所有分类AP取均值。
(11)
3.4 试验结果与分析
使用改进后的CCB-YOLOv5模型进行试验。试验得到损失函数Loss,精准率P,召回率R,均值平均精度mAP分别与迭代次数的曲线图,如图6所示。
从图6可以看出,CCB-YOLOv5算法的损失在迭代到55轮逐渐降低到0.02,最终稳定在0.019左右,相比于原始模型收敛速度更快,损失值更小。经过100次迭代,最终模型的精准率P为94.7%,召回率R为87%,均值平均精度mAP为92.5%。改进后的CCB-YOLOv5模型在P相差不大的前提下R提高了将近7%,mAP提高了将近3.5%。
卷积注意力机制更加重视被检测目标所需关注的通道和空间,获取更为重要的信息,提高网络的特征提取能力;大视场下的苹果图比较密集,苹果大小不一并且伴随着遮挡情况,完全交并比非极大抑制算法加速了预测框的回归收敛,可以有效降低由于遮挡率较高导致的漏检,提高召回率;但是随着卷积层的不断加深,会造成特征的丢失,BiFPN通过不同级的深层特征和浅层特征的融合提升了网络性能,在识别小目标苹果时可以更好地表达信息,以此提高识别精度和准确率。
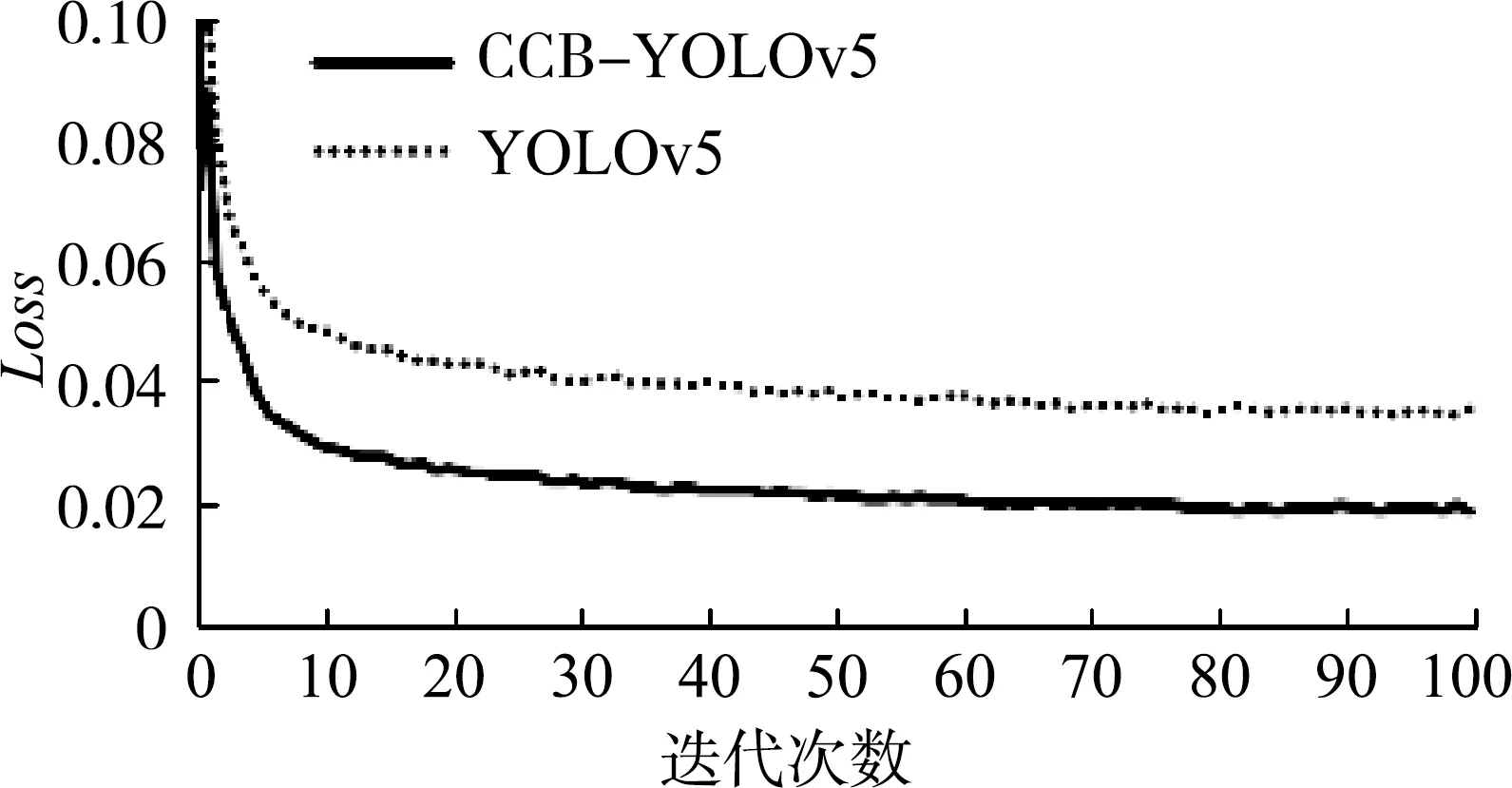
(a) 损失loss曲线
图7展示了原始未检测图片,原始YOLOv5和改进后的CCB-YOLOv5模型对真实苹果的识别结果图,图7(a)列为原始未检测图片,图7(b)列为原始YOLOv5的识别结果图,图7(c)列为改进后的CCB-YOLOv5的识别结果图,由第一行对比图可以看出原始YOLOv5在遮挡面积较大的情况下存在漏检的情况,改进后的CCB-YOLOv5能够更好地检测出遮挡面积较大的苹果,而且能够更好地过滤由于相互遮挡造成的不必要的信息,使预测框和检测目标的轮廓外形更好地贴合,其中椭圆形框为原始YOLOv5漏检苹果;从第二到第四行对比图可以看出改进后的模型对逆光,侧光和顺光等复杂光照条件下的苹果检测能力明显提升,置信度提升高达0.04;由第五行对比图可以看出虽然苹果和树叶颜色相近且存在大面积遮挡,但是改进后的CCB-YOLOv5在原始YOLOv5的基础上,整体精度有所提升。改进后的CCB-YOLOv5推理检测速度为11 ms,检测速度较快,并且识别到的目标置信度大都在0.5以上,处于较高范围。

(a) 原始图像 (b) YOLOv5 (c) CCB-YOLOv5
3.5 消融试验
对原始YOLOv5网络进行改进提出来本试验的方法CCB-YOLOv5,为了验证各项改进对苹果的检测是否有效,设置消融试验,通过控制变量进行对比研究。四种模型的结果对比如表1所示,其中符号“√”表示在原始YOLOv5网络中添加相应模块,模型1表示在YOLOv5中添加CBAM卷积注意力机制,模型2表示在YOLOv5中添加完全交并比非极大抑制CIOU-NMS,模型3表示在YOLOv5中添加加权双向特征金字塔BiFPN,模型4表示在YOLOv5中依次添加CBAM,CIOU-NMS和BiFPN三个模块。
由表1可见,原始YOLOv5网络加入卷积注意力机制后能更好地提取目标特征,召回率提高了1.13%,精准率提高了2.25%,平均精度提高了2.39%;引入完全交并比非极大抑制算法后召回率提高了5.35%,平均精度提高了1.45%,精准率却降低了2.28%,由于P和R之间有一定相关性,所以在召回率提高时精准率降低的情况是难以避免的;改进原始PANet结构为多尺度特征融合BiFPN后召回率提高了1.18%,精准率提高了1.46%,平均精度提高了1.63%;同时加入三项改进,在帧速度下降0.023FPS,区别较小的情况下,召回率提高了5.4%,精准率提高了1.3%,平均精度提高了3.5%,对于小目标和密集目标的检测有较大提升。本文算法CCB-YOLOv5 改进的有效性得到了证实。
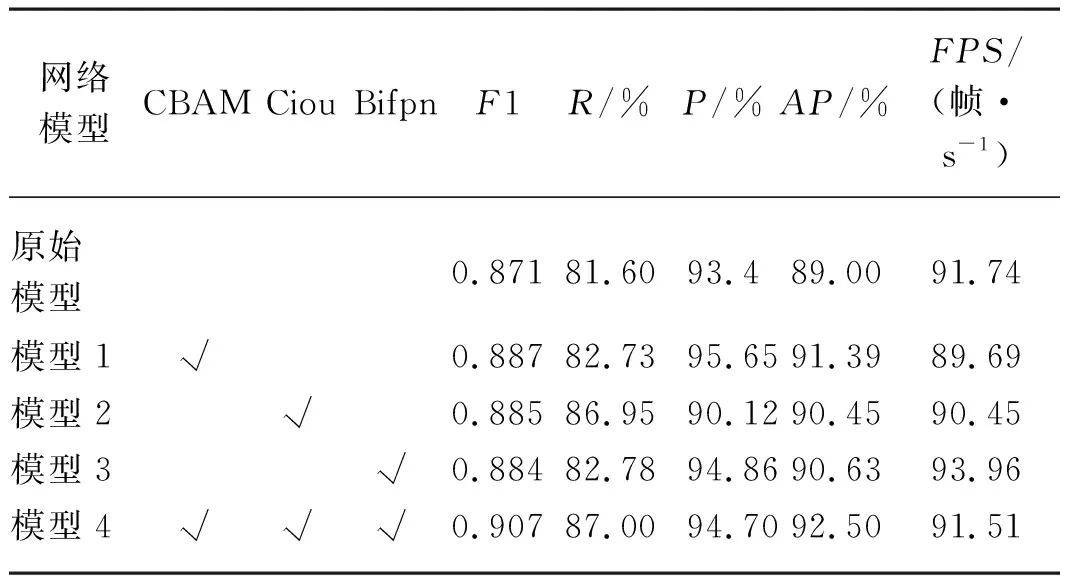
表1 消融试验Tab. 1 Ablation experiments
4 结论
1) 本文针对不同光照,遮挡重叠以及大视场等复杂条件下果蔬难以识别,精度不高的问题,提出了一种用于复杂环境下果蔬检测的改进YOLOv5算法——CCB-YOLOv5,该算法引入卷积注意力机制和完全交并比非极大抑制算法,改进原始特征提取网络为多尺度特征融合BiFPN,提高目标特征的提取能力以及识别精度和准确率,并以苹果为例进行试验。
2) 通过使用评价指标对本文提出的CCB-YOLOv5模型进行分析,召回率R为87%,精准率P为94.7%,平均精度mAP为92.5%,相较于原始YOLOv5模型R提高了将近7%,mAP提高了将近3.5%,识别精度较高。其次CCB-YOLOv5算法的损失在迭代到55轮左右逐渐趋于稳定,相比于原始模型收敛速度更快,损失值更小。在真实环境下平均每幅图在GPU下的检测推理速度为11 ms,速度较快。本文方法对遮挡目标和小目标的检测精度更高,对不同光照的鲁棒性更好,对果蔬的识别检测能够达到更好的效果。
3) 通过设置消融试验进行验证,加入卷积注意力机制后平均精度提高了2.39%,引入完全交并比非极大抑制算法后平均精度提高了1.45%,改进多尺度特征融合BiFPN后平均精度提高了1.63%,各项改进能更好地提取目标特征进行识别,进一步验证了各项改进的有效性。
