基于VMD-LSTM的超短期风向多步预测
2023-01-31李秀昊刘怀西张智勇张敏吴迪苗得胜
李秀昊✉,刘怀西,张智勇,张敏,吴迪,苗得胜
(1.明阳智慧能源集团股份公司, 广东 中山 528437;2.中国南方电网广东中山供电局, 广东 中山 528437)
0 引言
在风力发电中,偏航系统依据风向进行对风操作,准确对风可以降低风力发电机组的载荷、提高风能利用率,进而提高发电量,直接影响机组的经济性和安全性[1]。而风向却是随机的、不稳定的,这使得偏航系统的对风存在一定的误差和滞后性,继而导致偏航系统偏航动作频繁。因此,风向的准确预测可以提高偏航系统的对风精度、减小偏航滞后性,有利于风电场结合风向变化趋势制定偏航控制策略,进而对偏航优化提供保障,对风电企业经济、安全生产具有较大的工程实践指导意义。
风向建模方法主要分为物理建模法、统计建模法和数据驱动建模法。物理建模法通常利用数值天气预报(Numerical Weather Prediction,NWP)数据进行建模[2],模型计算量大,主要用于长期预测。统计建模法一般使用时间序列建模,主要包括自回归移动平均模型(Autoregressive Moving Average model,ARMA)[3]、自回归差分移动平均模型(Autoregressive Integrated Moving Average model, ARIMA)[4]、自回归条件异方差模型(Autoregressive Conditional Heteroskedasticity model, ARCH)[5]等,相比于物理模型,统计建模法不用求解复杂的物理模型,计算效率高,常用于短期预测,但无法准确地描述非线性数据。由于风向数据具有非线性、非平稳性、随机性等特点,数据驱动模型可有效地处理复杂时序预测,BP神经网络[6]、支持向量机[7]等模型都取得不错的效果。张亚超[8]等提出一种基于VMD-SE和基模型的自适应多层级综合预测模型,可实现短期风电功率3步预测。但传统的浅层神经网络难以充分挖掘数据的深层特征,导致模型预测精度受限。深度学习以其强大的特征提取能力,在时序预测等任务上取得巨大的成功。唐振浩[9]等提出一种基于数据解析的混合建模算法(Data Analytics based Hybrid Algorithm,DAHA),可实现风向的单步预测。林涛[10]等提出1种变分模态分解(VMD)和蝙蝠算法(Bat Algorithm,BA)优化长短期记忆(LSTM)神经网络的短期风向预测模型,可提前预测未来 5 min、15 min 和 30 min 的风向。向玲[11]等提出一种变分模态分解(VMD)-模糊信息粒化(Fuzzy Information Granulation, FIG)和参数优化门控循环单元(Gate Recurrent Unit,GRU)的风速多步区间预测方法,可实现风速3步区间预测。由于风向具有强波动性和随机性等特点,但现有文献进行超短期风向预测时多为单步预测,且风向多步预测中预测步长较短,难以满足风电场的实际生产需求。
为此,针对超短期风向多步准确预测,本文提出一种基于VMD-LSTM的风向多步预测算法,准确预测未来4 h的风向。首先,通过自相关函数计算风向不同时期之间的相关性,以选取模型最佳的风向序列输入长度;然后,针对风向数据波动性、随机性的特点,采用变分模态分解法将风向序列分解为相对稳定的模态信号,通过最小样本熵确定分解的子模态数,并对分解后的模态信号分别建立超短期风向预测模型进行预测;最后,重构风向序列,叠加各分量预测结果,实现超短期风向24步预测。
1 风向特征分析
明阳智能某风电场3个风电机组(1#、2#、3#)1年风向数据的风玫瑰图如图1所示。其中,扇形区域的颜色表示不同的风速大小,长度表示风向的频率。
由图1所示及统计可知,1#、2#号风机的主导风向为东,3#号风机的主导风向为东南偏东;1#、2#、3#号风机的盛行风向区间为(67.5°,112.5°),盛行风频率分别为40.31%、39.96%、40.61%。虽然1#、2#、3#号风机同处一风场,但受风机排布位置及尾流的影响[12],同一风场不同风机的风向也有所差别。由此可见,风向存在较大的随机性与不稳定性,进一步增大了风向预测的难度。
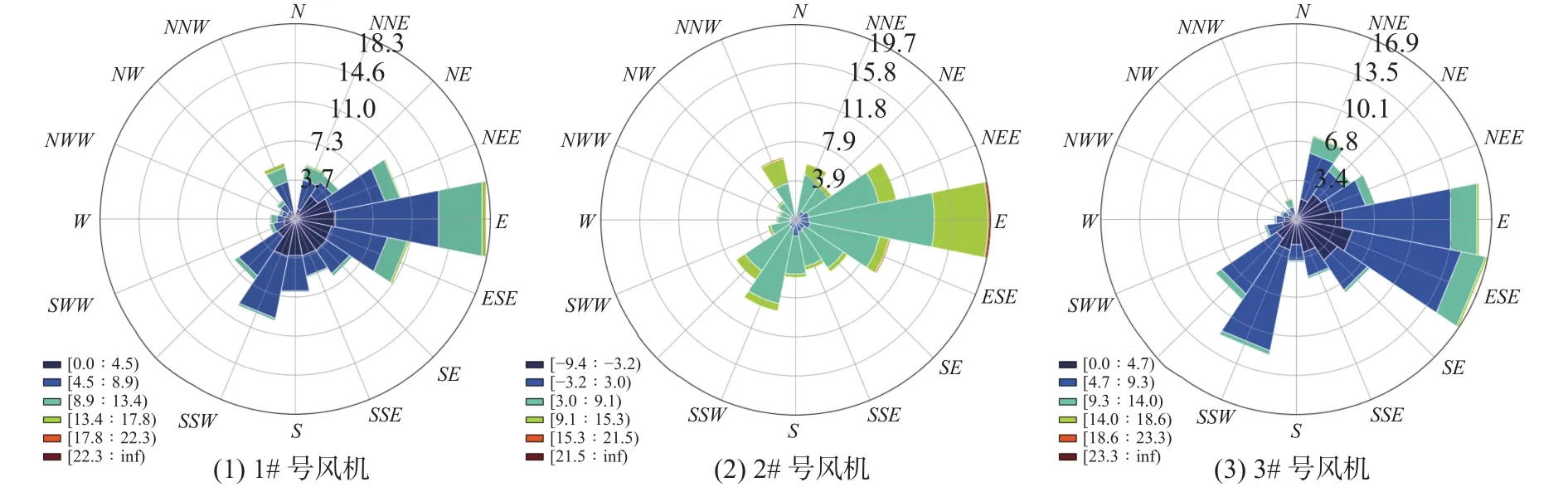
图1 全年风向玫瑰图Fig.1 Year-round wind rose map
2 风向建模
2.1 基于 ACF 的模型特征输入长度选择
不同的序列输入长度对模型的预测结果有一定的影响。模型输入的序列长度过短,难以表征序列特征,降低模型预测的准确率;输入序列过长导致信息冗余,降低模型的建模效率。本文采用自相关函数计算前k个时刻(k> 0 )的风向xt−k与当前时刻的风向xt之间的相关性,以选取最佳的风向序列输入长度。
自相关函数(Autocorrelation Function, ACF)用于度量同一事件在不同时期之间的相关性程度。对于时间序列 {Xt} ,ACF度量时间序列中每隔k个时间单位(xt和xt−k)的观测值之间的相关性,计算公式如下:

式中:
如图2所示,横坐标表示时间滞后长度,纵坐标表示滞后为k个时刻的风向序列与当前序列的相关性。本文计算了72个样本点的相关性,随着k的增大,历史风向与当前风向的相关性逐渐减弱,当k>35↖时其自相关系数小于0.6。为了兼顾模型的预测精度与效率,选择自相关系数大于0.6的序列。此外,输入序列长度应不少于预测序列长度,本文中预测未来4 h的风向,即输入序列长度应不少于24个样本点。因此,本文选取自相关系数大于0.6的前24个采样点的风向作为模型的输入序列。

图2 风向自相关性Fig.2 The autocorrelation coefficient of wind direction
2.2 基于 SE-VMD 的特征转换
变分模态分解(Variational Mode Decomposition,VMD)是一种完全内在、自适应、非递归的信号分解技术[13],通过求解约束变分问题,将信号转换到频域内分解为K个有限带宽的本征模函数(Intrinsic Mode Function, IMF),这种方法可以有效避免经验模态分解(Empirical Mode Decomposition, EMD)和局部均值分解(Local Mean Decomposition, LMD),在分解中由于递归分解模式所造成的包络线估计误差,具备强大的非线性和非平稳性信号处理能力,相比于EMD和集合经验模态分解(Ensemble Empirical Mode Decomposition, EEMD)等信号分解方法,它在解决信号噪声和避免模态混叠的问题上有显著优势。但VMD分解的IMF子模态数K对分解结果有很大的影响:当K太小时,分解后的序列会丢失过多信息从而导致模态混叠;当K太大时,会出现过度分解的问题。
为了评估序列数据的复杂性,Richman和Moornan等[14]提出样本熵(Sample Entropy, SE),通过度量信号中产生新模式的概率大小来衡量时间序列的复杂性,时间序列越复杂,样本熵的值越大。
针对风向数据波动性、随机性的特点,本文采用VMD对风向序列进行分解,得到多个稳定的子信号,通过最小SE值对VMD进行优化[15],以获取合适的K值。
2.3 基于 LSTM 的风向预测建模
长短期记忆(Long Short-Term Memory, LSTM)是一种特殊的循环神经网络(Recurrent Neural Network,RNN),主要为了解决长序列训练过程中的梯度消失和梯度爆炸问题[16]。相比于RNN,LSTM能够在更长的序列中有更好的表现。LSTM由多个单元组成,每个LSTM单元包括3个门控系统和1个记忆单元,具体为:
遗忘门:
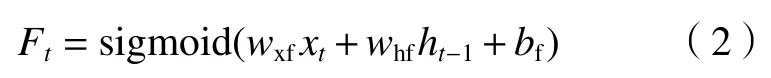
输入门:
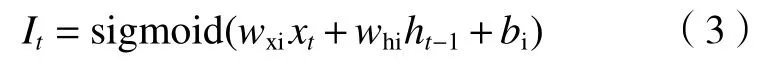
输出门:
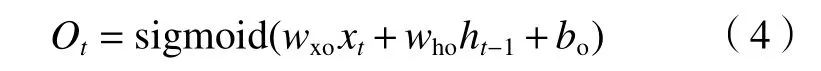
记忆单元状态值:

LSTM记忆单元在t时刻的输出:

式(2)~式(6)中,w(Ft,It,Ot,Ct)和b(Ft,It,Ot,Ct)为三个门控单元和记忆单元的权重和偏置值。
本文采用两层的LSTM网络挖掘风向时序序列的深层特征,每层的神经元个数为100,学习率为0.001,优化器为Adam,迭代次数为10,激活函数为ReLU,如图3所示。

图3 LSTM结构Fig.3 The structure of LSTM
3 试验结果与分析
3.1 数据预处理
本文采用明阳智能某风电场数据采集与监视控制系统(SCADA)提供的2021年风向数据。风向数据来源于3个风力发电机(1#、2#、3#),时间粒度为10 min,按季度分为4组。为保证时间样本的顺序性,使用样本总量前70%的序列作为训练集,后30%的时间序列作为测试集,具体如表1所示。

表1 数据集信息Tab.1 Dataset information
根据 GB/T 37523-2019[17]对风向数据进行合理范围筛选,剔除异常数据值,使用滑动平均法对缺失数据进行插补;采用最大-最小归一化方法对风向数据进行处理,将风向数据映射到[0,1]内,归一化计算如下:
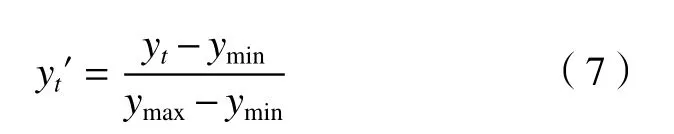
式中:
yt′−t时 刻归一化后的风向数据;
yt−t时 刻的原始风向数据;
ymax−风向序列的最大值;
ymin−风向序列的最小值。
3.2 评价指标
本文采用绝对平均误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error, RMSE)、平 均 绝 对 百 分 比 误 差 (Mean Absolute PercentageError, MAPE)作为评价指标,衡量预测值与真实值的偏离程度、评价数据的变化程度、定量评价预测模型,其表达式分别为:

式中:
ytrue−真实值;
ypre−预测值;
n−样本个数。
3.3 预测流程
本文算法流程图如图4所示。

图4 算法流程图Fig.4 Algorithm flowchart
具体步骤如下:
1) 采集风向序列并对其进行预处理。
2) 绘制风向玫瑰图,分析风向特征。
3) 基于ACF计算风向不同时期之间的相关性,选取自相关系数大于0.6的前24个采样点的风向作为模型的输入序列。
4) 采用VMD将风向序列分解为相对稳定的模态信号,通过最小样本熵确定分解的子模态数K。
5) 对分解后的K个模态信号分别建立预测模型,进行超短期风向多步预测。
6) 重构风向序列,叠加各分量预测结果。
3.4 结果与分析
3.4.1 基于 SE 的 VMD 分解模态数确定
VMD分解的子模态数K直接决定了风向信号分解的好坏,对预测结果有一定的影响。本文利用VMD对风向数据进行分解得到K个IMF,计算每个IMF的SE值,以获得具有最小SE的序列作为趋势项,通过对比不同K值的最小SE值以确定子模态数。本文令K取值为2~10,如图5显示了在取不同K值时最小SE值和预测绝对平均误差的变化趋势。
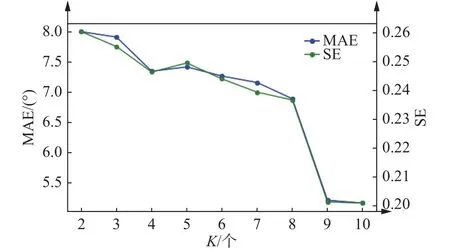
图5 最小样本熵和绝对平均误差的变化趋势Fig.5 Variation trend of minimum sample entropy and absolute mean error
由图5可知,随着VMD分解的子模态数K的增加,最小样本熵的值减小,风向预测模型的绝对平均误差MAE减小,并且两者衰减的变化趋势基本保持一致,表明最小样本熵的值能够有效地表征信号分解能力。当子模态数K较小时,原始风向信号分解不足,序列趋势项中混入了其他干扰项,使得SE值较大。随着K值的增大,SE值逐渐变小,当取得适当的K值时,SE值骤减,此时再增大分解次数K,SE值变化较小,并且逐渐趋于稳定。因此,将SE骤减趋于稳定的转折点作为VMD分解的次数,以避免过度分解。在本文中,取K=9,即利用VMD将原始风向信号分解为9个子序列,如图6所示。
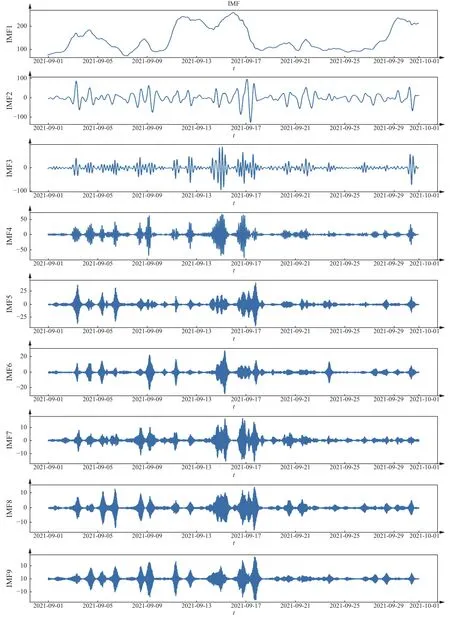
图6 原始风向信号VMD分解Fig.6 Original wind direction decomposition by VMD
3.4.2 基于 VMD-LSTM 的风向多步预测
为验证VMD分解对预测结果的影响,进行VMD分解前后对比算法建模预测结果的比较。由表2、图7和图8可知,VMD-LSTM在4个季度的24步风向预测的平均 MAE、RMSE、MAPE为 8.430°、16.870°、9.155,比未分解的LSTM模型平均减少77.91%、69.30%、69.42%,因此,VMD将原始风向序列分解为相对稳定的模态信号,可以有效地降低风向的非线性、非平稳性和随机性,提高风向序列预测的准确性。
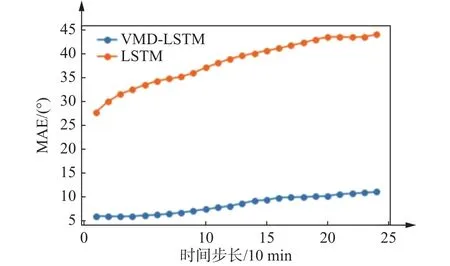
图7 LSTM与VMD-LSTM预测结果对比Fig.7 Comparison of LSTM and VMD-LSTM forecast results

图8 基于VMD-LSTM的风向多步预测结果Fig.8 Wind direction multistep forecast results based on VMD-LSTM

表2 基于VMD-LSTM的风向多步预测结果Tab.2 Wind direction multistep forecast results based on VMD-LSTM
预测误差随着预测时间的增加而累加,进而导致误差逐步增大,LSTM模型平均每步误差增长约为1.26°,VMD-LSTM模型误差稳步增长,增长幅度较小,平均每步误差增长约为0.29°,说明VMD-LSEM模型可以有效地降低误差的增长速度,稳定误差增长幅度。
3.4.3 风向预测方法比较
不同的预测方法对超短期风向多步预测有一定的影响。本文基于不同季度的风向分别构建ARMA、RF、VMD-RF、LSTM、VMD-LSTM模型。
由表3和图9可知,VMD-LSTM在每个季度的各个误差评价指标均优于其他算法。VMD-LSTM模型较表现次好的VMD-RF模型,其平均MAE、RMSE、MAPE分别减少37.19%、23.80%、26.85%。通过不同建模算法的试验,结果表明,VMD-LSTM在不同季度下的风向具有更高的准确性和较好的预测能力。此外,VMD-LSTM和VMD-RF比未分解的模型LSTM和RF的MSE分别降低了77.91%和57.86%,说明经过分解后的建模精度有较大幅度的提高,VMD在提取风向趋势信息方面具有较好的能力。
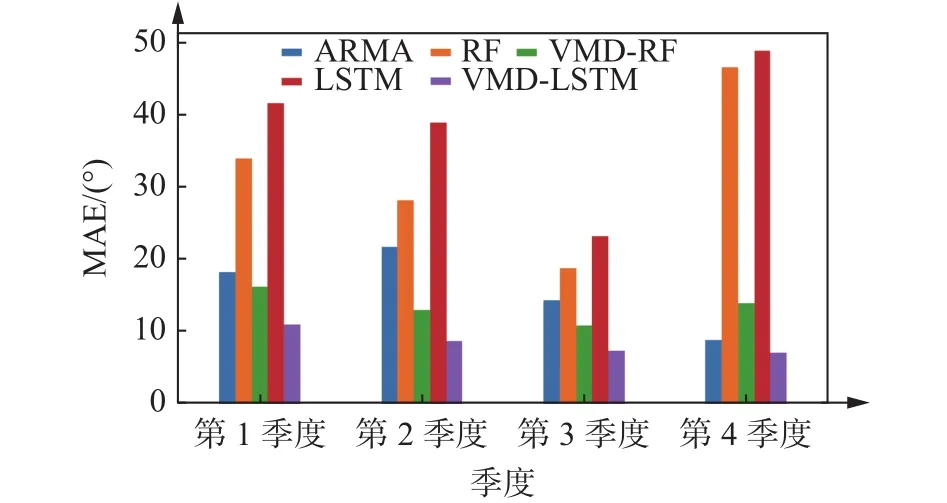
图9 不同方法的风向预测结果Fig.9 Wind direction forecast results of different methods

表3 不同方法的风向预测结果Tab.3 Wind direction forecast results of different methods
3.4.4 不同风机预测结果
为检验该方法对不同风机的风向预测效果,本文对比分析了同一风场1#、2#、3#号风机,绝对平均误差MAE见表4。

表4 不同风机的风向预测结果MAETab.4 MAE of wind direction forecast for different wind turbines (°)
虽然1#、2#、3#号风机同处一风场,但受风机排布位置及尾流的影响,导致不同风机在每个季度的预测结果也有所差异,但不同风机的预测总体误差差距较小,说明VMD-LSTM可适用于同一风场不同风机的预测,具有良好的泛化能力。
4 结论
由于风向具有强波动性和随机性等特点,目前的超短期风向预测步长较短,难以满足风电场的实际生产需求。为此,本文提出1种基于VMD-LSTM的风向多步预测算法,通过算例分析,得到以下主要结论:
1)VMD将原始风向序列分解为相对稳定的模态信号,可以有效地降低风向的非线性、非平稳性和随机性,提高风向序列预测的准确性。利用最小样本熵的值确定VMD分解的子模态数,可优化VMD的风向信号分解性能,提高VMD的风向趋势信息提取能力。
2)针对不同的预测方法对超短期风向多步预测的影响,分别构建 ARMA、RF、VMD-RF、LSTM、VMD-LSTM预测模型。比较发现,VMD-LSTM在4个季度的24步风向预测的平均MAE、RMSE、MAPE为 8.430°、16.870°、9.155,在每个季度不同时间尺度的各个误差评价指标均优于其他算法,所提算法可满足风电场的实际生产中优化控制偏航角的要求。
3)由于风向数据具有较大的随机性和不稳定性等特点,且受风机排布位置及尾流的影响,进一步增大了风向预测的难度。通过对比不同风机的预测结果,证明了模型的鲁棒性,具有良好的泛化能力。
