基于层级BiGRU+Attention的面向查询的新闻多文档抽取式摘要方法
2023-01-31曾昭霖徐广义邓忠莹
曾昭霖,严 馨,徐广义,陈 玮,邓忠莹
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(昆明理工大学 云南省人工智能重点实验室,昆明 650500) 3(云南南天电子信息产业股份有限公司,昆明 650040)
1 引 言
随着互联网技术的飞速发展,信息的传播和交互速度的不断加快,互联网上的信息量呈指数级地增长,如何高效地从如此多的文本信息中自动提取出其主要内容,已成为当今学术界自然语言处理领域中研究的一个热点[1].自动文本摘要技术是一种结合计算机技术与人类语言学知识的综合性技术方法,它能有效地帮助人们高效地从大量文本中提取出关键内容信息,提高信息的利用率、传播率;还可以帮助用户快速浏览和判断出自己所感兴趣的内容信息,更加高效地从互联网上获得更多有效信息,有效降低用户的信息负载[2].
自动文本摘要技术主要可以分为:抽取式摘要(Extractive Summarization)和生成式摘要(Abstractive Summarization)两大类;抽取式摘要是直接从原文中抽取语句来生成摘要,摘要句全部来自原文当中;生成式摘要是在理解了全文内容的基础上,通过对文中句子缩写、词语同义替换、转述等来生成概括性摘要.虽然生成式摘要更接近人写摘要的过程,但抽取式文本摘要的实现技术相较简单一些、易于在工业中落地,并且由于抽取式摘要是从源文档中直接抽取句子生成摘要,还有一个很大的优势是能够保证生成的摘要句在语法和事实上的准确性,具有较大的研究价值[3].与一般的多文档抽取式摘要不同,面向查询的多文档抽取式摘要旨在从根据用户查询语句返回的相关文档集中,依据查询信息以及文档主旨,抽取出一份内容凝练、与查询相关、冗余性低的摘要;要求摘要结果不仅归纳了文档主旨信息,还要能反映用户的查询信息需求,因此更加具有针对性,更适合当前互联网环境下用户对信息获取的个性化需求[4].
2 相关工作
面向查询的多文档抽取式摘要所使用的方法大都与一般的抽取式自动摘要方法类似,只是在研究方法中加入了查询相关特征的适用性改进[5].在自动摘要技术研究的早期,大多是采用基于规则的方法,即简单采用一些启发式定义的函数或者特征的线性组合来评价文档中句子的重要性[6];在此之后,Xiong等[7]利用层次Dirichlet 过程(HDP)主题模型来学习句子中的词-主题概率分布,并通过超图来获取词-主题概率分布与句子间成对相似度的聚类关系,最后通过顶点增强的超图时变随机游走算法对句子进行排序;唐晓波等[8]运用LDA主题模型进行句子聚类与主题发现,在主题下通过计算句子相似度来构建图模型,并利用TextRank算法来获得图模型中句节点的重要性,再结合句子基于统计特征的重要性来获得摘要.近些年来,随着深度学习神经网络的兴起,越来越多的人开始转向将深度学习神经网络应用于自动摘要领域中.Zhang等人[9]提出了一种潜在变量的抽取式摘要模型,把文档中句子对应的标签视为一个二元潜在变量,通过基于Encoder-Decoder结构的句子压缩模型,得到文中句子作为摘要句的条件概率,并结合强化学习算法进行摘要模型的训练;Cao等人[10]提出名为AttSum的面向查询的多文档摘要模型,该模型通过注意力机制采用联合学习的方法,同时建模处理了句子的文档显著性以及查询相关性;Nallapati等人[11]提出了基于循环神经网络的SummaRuNNer模型,该模型从句子的重要性和新颖性等角度出发,在计算候选摘要句的概率时考虑了之前所有时刻句子的摘要概率信息,能直观地解释文本摘要的生成过程;Zhong等人[12]不再遵循常用的单独抽取句子和句子间关系建模的框架,而是将抽取文本摘要任务定义为一个在语义空间中的文本匹配问题,并试图量化句子级与摘要级方法之间的内在固有差距.
句子的查询相关性排序及内容显著性排序是面向查询的多文档自动摘要的两个主要任务,但目前大多数面向查询的多文档自动摘要研究往往将这两个任务分开执行,最后把所有得分做一个线性相加,或通过设定的实验权重系数来将这两个得分连接起来.但这样会使得这两个排序过程中的信息不能交互同时考虑,可能会导致最终的摘要结果不能很好地反映用户查询的需求.Cao在文献[10]中提出的AttSum面向查询的抽取式摘要模型,虽然在建模文档特征表示时很好地将句子的内容显著性和查询相关性通过注意力机制同时考虑了,解决了分开孤立计算的问题,但该模型是通过对词向量表示进行卷积、池化操作来获得句子的向量表示,没有充分考虑到文档中句子之间的语义关系、句子的上下文信息及句子中词之间的潜在关联,可能会导致之后的文档向量表示的特征学习不充分;且在摘要句的选择时,仅依赖于句子向量表示与文档向量表示的相似度值进行摘要句抽取选择,但该方法为纯数据驱动的隐式建模,缺乏对句子表面特征的显式建模,然而在前人的研究[3]中已经证实句子表面特征的显式建模在抽取式摘要任务中也是具有重要价值意义的.
因此,本文提出了一种基于层级BiGRU+Attention的面向查询的新闻多文档抽取式摘要方法,相较于AttSum模型本文方法在编码句子、文档级向量表示时使用层级BiGRU+Attention神经网络模型进行建模;并使用相较于BERT预训练模型[13]更加专注于中文特殊构词语法,在更丰富的训练语料中加入了包含短语、命名实体级语义单元遮蔽的基于知识增强的语义表示模型(ERNIE预训练语言模型)[14]将文本向量化;其中加入了相应的注意力机制使得编码得到的向量表示捕获到文档中潜在的语义关系、上下文信息;再利用句向量表示与文档向量表示进行相似度计算来获得相应的句子重要性得分;并在计算句子综合特征权重得分时除了包含通过神经网络打分模型隐式建模得到的句子重要性得分外,还充分考虑了句子中包含的关键词特征、句子的长度特征以及句子的时序权重系数等显式建模的句子表面特征权重;最后再利用MMR算法来抽取摘要,从而更为准确地抽取出与文档主旨及查询需求匹配度高同时也与已选摘要冗余信息较少的摘要句,提高最终摘要的质量.本文中面向查询的多文档抽取式摘要方法的框架如图1所示.
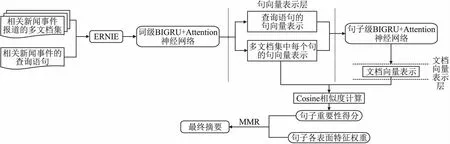
图1 基于层级BiGRU+Attention的面向查询的多文档抽取式摘要方法框架图Fig.1 Framework diagram of query-oriented multi-document extractive summarization method based on hierarchical BiGRU+Attention
3 层级BiGRU+Attention神经网络句子重要性打分模型
该层级BiGRU+Attention神经网络句子重要性打分模型主要分为以下3部分:1)先将多个相关文档视为一个整体文档,对该文档集合中的每个句子进行词级编码表示,通过ERNIE预训练模型对文本进行向量化,再送入到词级编码的BiGRU神经网络中,加以词级注意力机制,得到多文档集中的每个句子以及相应查询语句的句向量表示;2)是将获得的句向量表示通过句子级编码的BiGRU神经网络使其包含文档的上下文语义信息,并将其与查询语句做双线性变换注意力计算[17]得到每个句子相应的查询相关性权重,再将获得的句向量表示通过加权和计算得到该文档向量表示;3)为句子重要性打分过程,是将文档集中每个句子的向量表示与该文档向量表示进行相似度计算,得到每个句子的重要性得分,该得分同时包含了句子的文档内容显著性以及查询相关性信息;该神经网络模型同时建模处理了句子的文档中心性和查询相关性,并充分考虑了文档语法结构.该部分的模型结构图如图2所示.
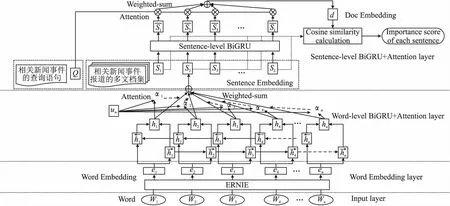
图2 层级BiGRU+Attention神经网络句子重要性打分模型结构图Fig.2 Hierarchical BiGRU+Attention neural network sentence importance scoring model structure diagram
3.1 层级BiGRU+Attention神经网络
将描述同一新闻事件主题的多个报道文档视为一个包含所有L个句子的整体文档D,D=(S1,S2,S3,…,Si,…,SL),Si为多文档集合D中的第i个句子,其中每个句子由n个词组成,D中任意一个句子可以表示为Si=(wi1,wi2,…,wit,…,win),wit表示第i个句子中的第t个词.将句子中的每个词通过ERNIE预训练语言模型获得相应的向量化表示,并送入词级编码的BiGRU神经网络中,加以词级注意力机制,加权和得到文档集中每个句子以及查询语句的句向量表示;再将得到的句向量表示通过句子级编码的BiGRU神经网络,并将其与查询语句做双线性变换注意力机制计算,最后对其进行加权和操作得到该文档向量表示.
3.1.1 词级BiGRU+Attention
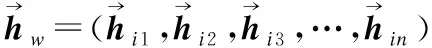
(1)
(2)
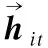
(3)
式中:“;”表示拼接,该新的词向量表示包含了以该词为中心的该句的上下文信息.
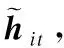
(4)
(5)
(6)
式中,uw为在训练过程中随机初始化并随其他参数共同学习更新的参数,bw为偏置项,Ww为权重矩阵,均为可训练参数;查询语句的句向量表示Q也通过以上方法获得.
3.1.2 句子级BiGRU+Attention
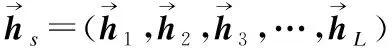
(7)
(8)
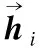
(9)
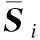
(10)
(11)
(12)
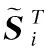
3.2 句子重要性打分
将文档集中每个句子的句向量表示Si与该文档向量表示d进行相似度计算,获得关于每个句子的重要性得分,该得分通过之前的建模同时包含了文档中句子的文档内容显著性以及查询相关性.该相似度计算采用cosine余弦相似度计算:
(13)
依据文献[18]中的说明,余弦相似度是目前比较好的、常用来衡量两个向量表示之间相似度的方法,与欧式距离相比它可以对不同范围的数值进行自动缩放.文档向量表示d通过双线性变换注意力机制,使其在本身具有反映文档深层主旨信息这一特性的基础上,并融入了句子的查询相关性信息;使得该相似度值Scoresq(Si),即句子的重要性得分,同时建模包含了句子的文档内容显著性以及查询相关性特征得分.
3.3 层级BiGRU+Attention句子重要性打分模型的训练
本文中的层级BiGRU+Attention神经网络句子重要性打分模型采用与Cao等人[10]提出的抽取式摘要模型AttSum相似的模型训练方式;在模型的训练过程中,采用结对排序(pairwiserankingstrategy)策略[19]来调整神经网络模型的参数.具体来说,先计算出训练集中的所有句子基于ROUGE-2指标的得分,其中获得较高ROUGE-2分数的句子被视为是正样本,其余的被视为负样本.然后,随机选择一对正、负样本句子,并分别将它们表示为Spos和Sneg.通过上面的层级BiGRU+Attention神经网络编码,可以获得正样本句子的句向量表示S+、负样本句子的句向量表示S-,以及文档向量表示d.从而可以依据句子重要性打分公式(13)计算出Spos和Sneg的重要性排序分数;根据结对排序策略的标准,层级BiGRU+Attention神经网络重要性打分模型应该给与正样本句子Spos相对于负样本句子Sneg更高的重要性得分.基于结对排序策略的损失函数的定义如式(14)所示:
Loss(d,S+,S-)=max(0,Ω-cos(d,S+)+cos(d,S-))
(14)
式中:Ω为一个边缘阈值,用来控制正样本句子和负样本句子之间的分数差距.利用该损失函数,可以使用梯度下降算法来训练更新神经网络模型中的参数.
4 句子的权重计算及抽取
4.1 句子的综合特征权重计算
虽然层级BiGRU+Attention神经网络句子重要性打分模型能有效地同时对句子的内容显著性及查询相关性进行处理,但其为基于数据驱动的隐式建模,并不能完全替代一些在抽取式摘要任务中具有一定重要作用的句子表面特征,例如句子中包含的关键词特征、句子的长度特征等显式建模的表面特征.因此,在本文中将其与通过神经网络隐式建模的句子重要性相结合考虑,来获得句子综合特征权重得分,进行摘要句的抽取选择.
4.1.1 句子中包含的关键词特征权重
高亮的关键词通常是能高度概括文章主旨的关键性词语,也是文章中主旨内容相关描述的重要组成成分;因此一个句子中包含的文档关键词越多,该句在文档当中就相对来说更加重要,尤其对新闻文本来说.文档中关键词的识别及权重计算通过常用的TF-IDF(词频-逆文档频率)算法来计算得出:
(15)
式中,Wi,j表示文中词语wi的TF-IDF得分,tfi,j表示词语wi在当前文本dj中出现的频率,N表示文档集中的总文档数,ηj为包含词语wj的文档数,+1是为防止出现分母为0的情况.
1http://icrc.hitsz.edu.cn/Article/show/139.html
2https://github.com/wonderfulsuccess/chinese_abstractive_corpus
3http://tcci.ccf.org.cn/conference/2017/taskdata.phphttp://tcci.ccf.org.cn/conference/2015/pages/page05_evadata.html
越是能反映文档主题信息的关键性词语,其TF-IDF得分越高;通过将句子中包含的所有词语的TF-IDF得分相加,来获得句子包含关键词的特征权重时,为了避免长句子中所包含的词过多,从而导致句子间基于关键词特征权重得分的差距过大的情况;本文在计算得到句子Si所包含的关键词的总得分基础上,再除以该句子的长度,即该句词语数;计算方法如式(16)所示:
(16)
其中,Wif-idf(Si)为句子Si所包含关键词的特征得分;LSi为句子Si的长度,也即该句中所包含的词语总数.
4.1.2 句子的长度特征权重
句子的长度特征在许多自动文本摘要的研究中也是一个经常考虑的因素,摘要句的选择大多是长度适中的句子,过短的句子由于其包含的文本信息较少,通常没有太大的实际意义;过长的句子虽然包含了许多文本信息,但内容过于繁杂,被选为摘要句的可能性较低.句子Si关于句子本身长度LSi与文档集中平均句子长度Lmid(Si)比较的长度特征权重得分,计算方法见式(17):
(17)
综合这两个显式建模的句子表面特征权重得分,以及前面通过神经网络隐式建模获得的句子重要性得分,通过设置相应的权重系数进行组合,得到句子Si的综合特征权重得分:
Wgroup(Si)=α×Scoresq(Si)+β×Wtf-idf(Si)+
γ×Wlen(Si)
(18)
其中,α,β,γ为句子Si的各项特征权重在句子综合特征权重得分Wgroup(Si)中的占比大小,且占比之和必须为1;本文中各项特征权重占比的设定经过综合考虑和分析各特征因素,将其分别设置为α=0.5,β=0.25,γ=0.25.
4.1.3 句子的时序权重系数
对于新闻报道来说,一个很重要的特性就是报道文章的时效性,新闻媒体是紧跟着新闻事件的发展进程进行跟踪报道,较新的报道内容通常会在之前报道内容的基础上又引入新的事件进展和社会舆论聚焦点;且对于查询用户来说,新闻事件的新进展也是他们较为关心的一点,更符合用户的信息需求.因此,在对新闻文档进行摘要句抽取时,除了综合考虑以上的各句子特征外,还需要进一步考虑句子的时间权重.
本文的新闻多文档摘要数据集中每个新闻事件主题下的多篇新闻报道,是按照新闻媒体报道文章的发表时间的先后顺序倒序排序放置并进行编号的,越是近期发表的新闻报道,文档编号越小;基于此,加入句子时序权重系数的句子综合特征权重得分计算方法如式(19)所示:
(19)
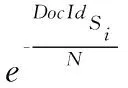
4.2 摘要句的抽取
多文档摘要任务是需要概括在同一主题下的多篇相关文档的主旨内容来生成摘要,其摘要句来源于多个文档,因此本文在进行摘要句抽取选择时,除了考虑候选摘要句包含句子时序权重的综合特征权重得分以外,还需考虑候选摘要句与已选摘要句之间的信息冗余度问题.
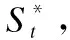
(20)
(21)
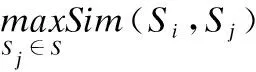
(22)
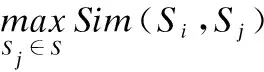
2)关于本文中的摘要句抽取选择过程算法的流程描述,如表1所示.
5 实 验
5.1 实验数据
当前,还没有适合本课题研究方向的公开的中文新闻多文档抽取式摘要语料,国内常见的中文文本摘要公开数据集有哈工大提供的LCSTS1、教育行业新闻自动摘要数据集2以及由NLPCC会议提供的NLPCC-2015、2017数据集3等,但都是基于单文档的一般新闻摘要数据集,并不适用于面向查询的多文档抽取式摘要方法的训练和测试.因此需要利用爬虫技术,以新闻事件查询语句为查询线索从各大新闻网站(如新浪新闻、澎湃新闻、新华网、中国新闻网等)上抓取相关新闻事件的报道数据,再对抓取下来的数据进行预处理,并对每个新闻事件主题下的多篇新闻报道按照新闻媒体报道文章的发表时间的先后顺序倒序排序放置并进行文档编号,越是近期的报道其编号越小;以构建出本文所需要的面向查询的中文新闻多文档抽取式摘要语料.

表1 基于MMR算法的摘要句抽取算法Table 1 Summary sentence extraction algorithm based on MMR algorithm
该语料包含780个国内发生的各类新闻事件(Title),涉及娱乐、财经、教育、科技、社会等各方面,其中每个新闻事件文档集合中包含16篇左右来自各大新闻媒体的中文新闻报道文档(Content),且都含有相应的人工撰写的查询语句(Query)以及标准参考摘要(Reference Summary),参考摘要为2名相关研究人员先各自进行独立人工摘要抽取,再交叉综合2人的摘要结果共同讨论,在每个事件主题下抽取出300字左右的原文本作为标准参考摘要,避免因个人主观臆断可能带来的结果偏差;在层级BiGRU+Attention神经网络模型的训练中按照9∶1的比例将数据集划分为训练集和测试集,在实验中采用10折交叉验证法.
5.2 实验设置及评价指标
5.2.1 实验参数设置
本文中通过ERNIE预训练语言模型获得的向量化表示的维度为768维,并在模型训练过程中对ERNIE进行微调;词级、句子级GRU隐藏单元数设置为256,层数为2,词级上下文向量uw维度设置为512维;为了防止网络过拟合,dropout概率设置为0.5;批次大小设置为16,训练迭代轮次为20;使用Adam作为模型优化器;结对排序中的边缘阈值在本文中设置为0.5,初始学习率设置为1e-5;句子MMR算法得分计算中的调节因子λ参数值,根据实验结果表明,本文中设置为0.7时效果较好.
5.2.2 评价指标
本文使用的是Chin-Yew Lin提出的一种内部评价方法ROUGE指标[16],是目前自动文本摘要任务中常用的一种评价指标,其评价原理是通过计算生成的摘要与人工参考摘要重叠的基本单元(n元语法、词序列和词对)的召回率来衡量生成摘要质量,值越大表明抽取出来的摘要质量越高.本文采用ROUGE-1、ROUGE-2、ROUGE-L作为评测指标,其中ROUGE-L是基于匹配到的最长公共子序列的重叠率,ROUGE-N计算公式为:
(23)
其中,N表示N-gram(n元语法)的长度,分子中的Countmatch(n-gram)表示抽取出来的摘要与参考摘要匹配到的共现N-gram个数,分母中的Count(n-gram)表示标准参考摘要中的N-gram个数.
5.3 对比实验结果与分析
本文使用上述评价指标作为摘要实验结果的评测指标,从以下几方面分析设计了下面3个对比实验:
实验1.调节因子参数取值的选择.调节因子λ,用于控制候选摘要句的句子综合特征权重重要度以及与已选摘要句之间信息冗余度,在句子最终MMR得分中的占比权衡;λ∈[0,1],当λ为0或1时,句子最终MMR得分为仅考虑候选摘要句的句子综合特征权重或句间冗余程度,没有全面统一地进行考虑.因此对本文MMR算法中的调节因子值,设置以0.1的步长在数值0.1~0.9之间设计对比实验、分析,实验结果如表2所示.
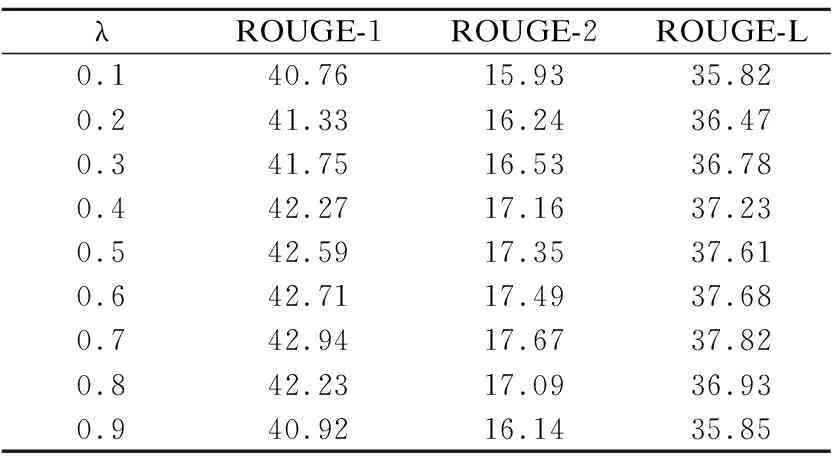
表2 调节因子不同取值的实验结果对比(%)Table 2 Comparison of experimental results with different values of the regulatory factor λ(%)
从实验结果可以看出,随着取值的逐渐增加,ROUGE-1、ROUGE-2、ROUGE-L值随之先增加后减小,当=0.7时达到最高值,因此选择0.7作为本文MMR算法中调节因子参数的选取值.在取值较小时,句子的MMR算法得分偏向于控制句子的冗余度,会使得一些包含重要内容信息但不能满足冗余约束的句子被排除;在λ值较大时,句子的MMR算法得分侧重于选择综合特征权重得分较高的句子.当取值超过0.7时,各项ROUGE评估值出现整体下降,一个很可能的原因就是对冗余度控制过小,过度关注于候选摘要句自身的重要性,而忽视与已选摘要句之间信息的冗余,导致摘要句之间的重要内容信息重复描述、句子差异性较低,使得摘要质量下降.
实验2.不同句子表面特征组合的消融实验.为了验证在句子最终重要性得分中加入句子中包含的关键词特征、句子的长度特征以及句子的时序权重系数等显式建模的句子表面特征,对抽取出来的摘要质量的影响程度;本文设计了几种不同的句子表面特征组合方式在相同调节因子λ参数值下进行实验对比,其中包括:
HBGRU+Att:仅通过层级BiGRU+Attention神经网络句子重要性打分模型,不加任何句子表面特征,获得的句子重要性得分直接应用于MMR算法中,来抽取摘要句;
4https://github.com/google-research/bert
5https://github.com/PaddlePaddle/ERNIE
HBGRU+Att+TF-IDF:使用层级BiGRU+Attention神经网络句子重要性打分模型获得的句子重要性再加上句子中包含的关键词特征权重的得分,作为MMR算法中句子综合特征权重得分;
HBGRU+Att+TF-IDF+LS:使用层级BiGRU+Attention神经网络句子重要性打分模型获得的句子重要性,加上句子中包含的关键词特征权重的得分、句子的长度特征的得分;
HBGRU+Att+AllFea:本文所提出的多文档抽取式摘要方法;
实验结果如表3所示.
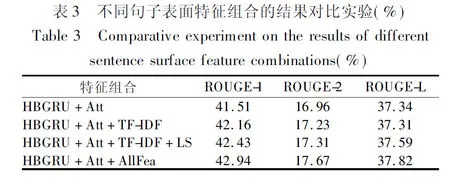
从表3的对比实验结果可以看出,在层级BiGRU+Attention神经网络重要性打分模型隐式建模的基础上,再加上这些显式建模的句子表面特征,能使得抽取出来的摘要质量获得一定的提升,这些手工表面特征在新闻摘要任务中被研究者们广泛使用、且认为是十分有效的[23].从实验结果中还可以看出,在考虑了句子中包含的关键词特征后,再加入句子的长度特征,对摘要效果的提升相对并不明显,因为两者都是针对句子某个方面的显式表面特征进行考虑的,只是侧重点不一样而已,其作用效果可能会有一定的重叠;但再加入句子的时序特征后能带来相对较好的提升,因为这是针对新闻报道所特有的时效性而设计考虑的特征.
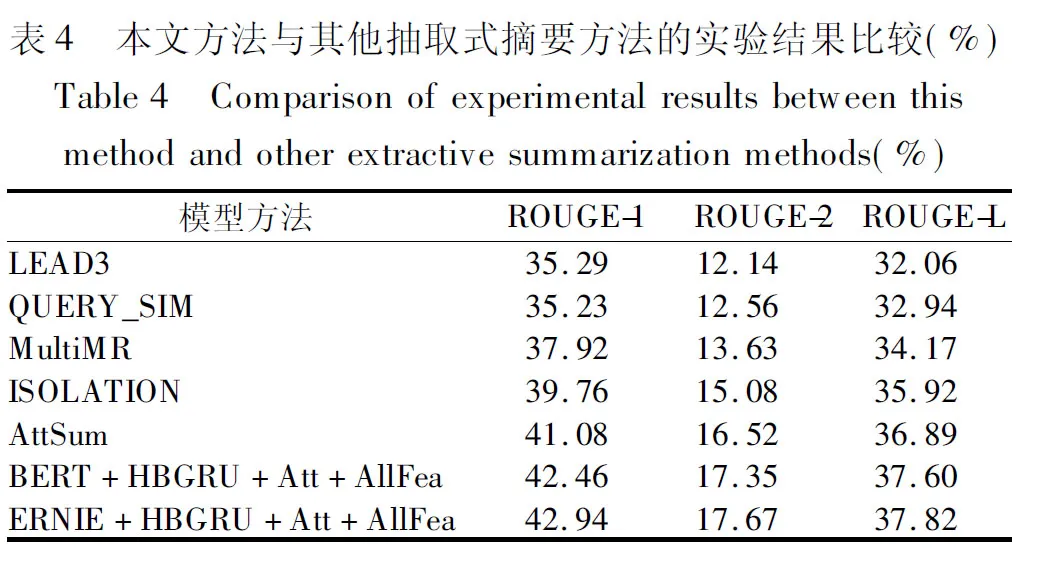
实验3.为了验证本文方法的有效性,将本文的方法与几种无监督的多文档抽取式摘要方法进行实验对比,对比方法有:
LEAD3[21]是一种直接抽取文章的前3句作为摘要结果的方法,常被用作为抽取式摘要的对比实验方法.通常大多数新闻文章都遵循总分总或是总分的逻辑框架结构,文章主旨信息的概述经常出现在文章的开头部分.
QUERY_SIM[10]是直接根据句子与查询语句基于TF-IDF特征的余弦相似度值来对句子进行排序选择的方法.
MultiMR[22]是一种基于图的多模态流形排序方法,该方法统一使用文档内部和跨文档句子之间的关系,以及句子与查询之间的关系来获得关于句子的综合排序得分.
ISOLATION[10]是一种分开单独计算句子内容显著性及查询相关性的摘要方法;该方法分别通过计算句子与文档向量表示的余弦相似度,以及句子与查询之间的TF-IDF余弦相似度值,以作为句子排序的内容显著性和查询相关性得分.
AttSum[10]是Cao等人提出的一种利用注意力机制来联合学习句子的内容显著性与查询相关性的多文档抽取式摘要方法,该方法通过神经网络模型建模了句子、文档的向量化表示,并采用一种简单的贪婪算法来选择摘要句.
BERT+HBGRU+Att+AllFea:使用Google提供的BERT-Base-Chinese中文预训练语言模型4,替换本文中的ERNIE1.0 Base中文预训练语言模型5,将文本向量化,并在训练过程中进行微调.
ERNIE+HBGRU+Att+AllFea:本文所提出的多文档抽取式摘要方法.
实验结果如表4所示.
进一步,为了更加直观地体现对比实验结果的效果提升,关于不同摘要方法对比实验结果的折线图如图3所示.
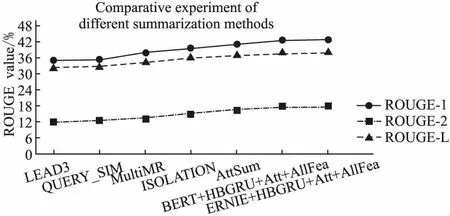
图3 本文方法与其他方法的对比实验结果折线图Fig.3 Line chart of the experimental results of the comparison between the method in this paper and other methods
由表4及图3的实验结果可以看出,本文的方法相较于LEAD3、QUERY_SIM、MultiMR以及ISOLATION这些常见的抽取式摘要方法,在摘要结果的各项ROUGE评价指标上都有较明显的提升,原因是本文的方法通过层级BiGRU+Attention神经网络模型建模了具有丰富上下文信息的句子、文档向量表示;并同时考虑处理了句子内容显著性与查询相关性,模仿人带着问题去阅读的行为习惯,解决了将其孤立考虑可能会导致的最终摘要结果质量不佳的问题.且将本文方法与AttSum方法相比较也有一定的效果提升,除了上述原因外,另一个重要的因素就是在计算句子的最终MMR得分中加入了文中的几种显式建模的句子表面特征,这在新闻摘要领域中被认为是十分有效的;此外还可以看出,本文中使用相较于BERT预训练模型在更丰富的预训练语料中加入了包含短语、命名实体级遮蔽的ERNIE预训练模型将文本向量化,包含了对实体概念知识的学习,具有更好的摘要效果.综上所述,可以看出本文提出的方法在面向查询的多文档抽取式摘要任务中具有一定的有效性、优越性.
6 结 语
本文针对面向查询的多文档抽取式摘要任务,提出了一种基于层级BiGRU+Attention的面向查询的新闻多文档抽取式摘要方法.该方法通过层级BiGRU+Attention神经网络句子重要性打分模型考虑了文档语法结构,建模了包含丰富上下文语义信息的句子、文档向量表示;并在建模文档向量表示时利用双线性变换注意力机制,同时处理了多文档中句子的文档内容显著性以及查询相关性,再利用句向量与文档向量表示进行相似度计算来获得相应的句子重要性得分;其次,在最后的句子综合特征权重得分中综合考虑了,通过神经网络隐式建模获得的句子重要性得分,以及显式建模的句子中包含的关键词特征、句子的长度特征以及句子的时序权重系数等句子表面特征权重,从而提高最终摘要结果的质量,更好地满足用户的信息需求.实验结果表明,本文所提出的方法能在一定程度上提高面向查询的多文档抽取式摘要效果.
本文方法的不足之处在于,在摘要句的选择算法中是将候选摘要句的句子信息重要度与冗余度放在两个孤立的过程中去分开考虑的,不能交互以利用对方的有效信息;因此,在下一步的研究中,考虑使用神经网络模型进一步将候选摘要句的信息重要性和冗余性这两部分结合起来同时考虑、互相协同,以进一步提高摘要的性能.
