WAGAN:基于小波变换和注意力机制的工控传感器数据异常检测方法
2023-01-31贾俊铖董国柱陆武民
马 标,贾俊铖,董国柱,章 红,陆武民
1(苏州大学 计算机科学与技术学院,江苏 苏州 215006) 2(浙江中控技术股份有限公司,杭州 310058) 3(苏州大学 电子信息学院,江苏 苏州 215006)
1 引 言
传统的工业生产环境中,工业控制系统(Industrial Control System,ICS)主要负责协调和控制各种设备按照生产要求执行各种任务.随着工业化和信息化的深度融合,工业控制系统在完成工业生产任务的基础上还需要具有数据分析、远程操控等功能,因此越来越多的工业控制系统打破自身的封闭性选择接入互联网,升级为工业互联网.由于传统的工业控制网络的主要功能是完成工业生产,在设计时缺乏安全考虑,在开放的网络环境中容易遭受攻击.从网络安全方面看,传统工控系统在物理隔离环境下,采用私有的通信协议和软硬件设施来保证网络安全,接入互联网后物理隔离被打破,系统的一些固有漏洞容易被攻击者利用,从而进行破坏性攻击.从物理安全方面看,攻击者通过网络在工业设备中植入恶意软件可以造成复杂的语义攻击,攻击可以直接修改传感器设备的返回值、执行器的执行顺序等影响整个物理空间的生产逻辑,造成重大生产事故.2001年澳大利亚污水处理厂入侵事件,2010年伊朗核燃料提炼工厂攻击事件等多起非法攻击事件都给工业生产和国家财产造成了巨大损失.
在工业控制系统中,可编程逻辑控制器(Programmable Logic Controller,PLC)和人机界面(Human Machine Interface,HMI)的通信多采用专有的通信协议(比如S7Comm、Modbus等),这导致很多互联网中通用的安全技术在工业控制网络中并不适用.并且由于传统的工业控制网络已经应用多年,使用范围广泛,将现有工业网络全部替换代价太大,所以在不改变现有工业网络的基础上制定新的入侵检测系统(Intrusion Detection System,IDS)是亟需解决的问题.
随着工业的发展,自动化生产需要多种联网的传感器来监督和控制生产流程,这些传感器会生成大量的多元时间序列数据,通过监控这些传感器数值可以实时了解ICS的生产情况,对ICS正常运行下的传感器数值进行建模能有效识别入侵行为.本文提出了一种基于WAGAN(Wavelet Attention Generative Adversarial Networks)的工控传感器数值异常检测方法,通过检测现场设备的传感器数值发现异常行为.
本文的主要贡献如下:
1)使用多级离散小波变换分解重构传感器数据,降低了数据噪声影响,同时将多级重构数据放入网络进行训练来学习更多数据特征.
2)使用注意力机制和多层LSTM(Long Short-Term Memory)网络学习多维时间序列数据的有效特征.
3)使用重构误差和判别器误差的权重和来判断测试样本是否异常.使用仿真平台捕捉的传感器数据进行试验.试验结果表明,WAGAN模型相比于现有的异常检测方法具有更高的异常检出率.
2 相关工作
工业传感器能实时监控工业生产过程,通过对ICS正常运行下的传感器数值进行建模能有效识别入侵行为.Inoue J等[1]使用两种无监督学习方法来检测传感器数值异常,分别是LSTM网络和一类支持向量机(One Class Support Vector Machine,OCSVM),LSTM网络的异常检出率更高但是训练和测试时间过长,OCSVM方法时间复杂度较低但是异常检出率低.Kravchik M等[2]提出一种基于检测预测值与观察值的统计偏差的异常检测方法,使用一维卷积神经网络来检测ICS异常,其性能比RNN(Recurrent Neural Network)要好,且网络结构更简单,训练速度更快.Ahmed C M等[3]利用传感器的硬件特性和过程的物理特性来为每个传感器创建唯一的指纹,传感器指纹是传感器和嵌入在传感器测量结果中的过程噪声的函数.在系统正常运行期间会创建基于噪声的指纹,通过对比噪声模式与指纹模式的偏差能够检测到攻击.Lin Q等[4]提出一种基于图形模型的方法,通过定时自动机来学习传感器数变化的行为规律,通过贝叶斯网络来挖掘传感器和执行器的依赖关系,此图形模型可以有效检测过程异常,并根据模型的可解释检测结果定位异常传感器或执行器.
多元时间序列数据中的时间尺度是影响模型性能的关键因素,因为当前状态通常会受到先前状态的影响.若模型在训练时仅处理数据数值而不考虑其中的时间属性,则无法捕获流量数据中的隐式依赖关系.与传统的RNN在反向传播阶段会遇到梯度消失的问题不同,LSTM[5]可以通过连接的存储单元和3个门(即输入门,忘记门和门)捕获序列中的长期依赖关系.为了进一步挖掘时间序列中的依赖信息,注意力机制[6]被应用进来.确定时间序列的时间尺度是很困难的任务,需要通过平移(移位)和扩张(缩放)将序列的低频模式与高频模式分离[7],小波变换恰好可以从时域和频域的多分辨率方面挖掘序列的依赖信息[8].Cheng M等[9]提出了一种的多尺度LSTM模型(Multi-Scale LSTM,MSLSTM)以完全表征不同尺度的时间依赖性.MSLSTM模型利用离散小波变换来获取多个尺度的时间信息,并开发了一个分层的两层LSTM体系结构,其中第1层学习不同时间尺度的注意力以生成一个集成的历史特征,第2层捕获特征中的长期和短期时间依赖性.
最近,生成对抗网络(Generative Adversarial Networks,GAN)被广泛应用于异常检测领域,与传统的分类方法不同,GAN通过半监督的方式进行学习,训练后的鉴别器能从真实数据中检测异常数据,使其成为一种有吸引力的半监督的异常检测方法[10].相比于原始GAN,EGAN[11]和Bi-GAN[12]添加了一个编码器,它将真实样本映射到潜在向量,从而避免测试过程中恢复潜在向量表示的计算开销.Jiang W等[13]使用编码器-解码器-编码器3层网络构建生成器从正常样本中提取有效特征,用于异常检测的异常分数由真实损失和潜在损失组成.Lu H等[14]提出一种改进的GAN方法MSGAN,该方法使用基于WGAN-GP的自适应更新策略来生成伪造的异常样本,提高了异常检测的准确性.徐志京等[15]使用多尺度融合生成对抗网络对图像进行去雨处理,给异常检测中去除数据噪声点带来启发.Li D等[16]提出半监督方法MAD-GAN(Multivariate Anomaly Detection with GAN),该方法使用LSTM作为基本模型(即生成器和鉴别器)在GAN框架中捕获时间序列分布的时间相关性,同时考虑整个变量集以捕获变量之间的潜在相互作用,能有效检测异常.
3 问题描述
在真实的工业生产中,ICS根据工业生产的实际流程设计HMI可视化界面,HMI通过SCADA系统实时与PLC通信并将通信流量中的数据信息显示在HMI界面上,生产者可以通过HMI实时了解工业生产的实际情况.但是随着攻击的不断升级,攻击者为了隐藏攻击活动,会通过恶意软件劫持HMI和PLC间通信的流量包,阻止从PLC端发出的真实数据包,并将更改后的数据包发送到HMI端.Stuxnet[17]和Irongate[18]是两种针对ICS的渗透攻击,它们在获取PLC的控制权后,会捕获PLC正常工作时的出站值并重播以掩盖对受控进程发起攻击时产生的异常,这使得生产者无法通过HMI来了解ICS真实的生产情况.Lin C Y等[19]提出了一种更加隐秘的攻击方案,攻击者通过Stuxnet和Irongate等入侵病毒控制PLC后,按照ICS生产周期来扫描PLC和HMI的通信流量,然后模拟PLC正常运作时的流量进行重放,其中重放的流量不仅包含传感器历史测量值,还遵循历史通信记录定时发送.重放流量中关于异常,有效负载的值,消息的大小和时间安排是完全合法的.
虽然通过对工控流量进行异常检测的方法可以有效防止针对HMI和PLC通道的入侵行为,但是对于已经获取了PLC控制权的攻击行为,该方法无法通过HMI和PLC通信的SCADA流量检测出异常.针对PLC已经被攻击者入侵控制而现有方法难以有效检测的情况,本文提出一种基于传感器数值的工业控制系统异常检测方法,即绕过PLC与HMI通信的方式采集传感器数值信息,通过对ICS正常运行下采集的传感器数据进行建模来检测异常行为.
在ICS入侵检测中使用的异常检测方法[20]可以大致分为有监督学习,无监督学习和半监督学习方法.有监督学习的方法包括支持向量机[21],随机森林[22]和人工神经网络[23,24]等,此类方法需要事先标记正常行为的样本和恶意行为的样本.在实践中很难获得准确且具有代表性的标记数据,并且该数据高度依赖于特定系统,使用该数据训练出的模型在异常检测方面普适性较差.无监督学习的方法是从未标记的真实数据中学习检测模型,Leandros等[25]提出一种基于OCSVM和K-means聚类的方法进行无监督的入侵检测,但是无监督学习方法没有充分利用数据的空间-时间相关性以及检测异常系统中多个传感器变量之间的其他依赖性,其针对语义攻击的检测能力较弱.半监督学习方法是使用一组部分标记的数据(例如无异常的干净数据)进行训练,在ICS入侵检测中这些数据代表不包含任何攻击的系统正常行为.与无监督学习方法相比,半监督学习方法能有效学习ICS系统正常运行时数据的特征,此方法具有更低的假阳性率.
目前,大多数现有方法是将传感器当前状态和模型预测的正常范围做简单比较来进行异常检测,但是由于现在工业生产工艺越来越复杂,生产过程会涉及非常多的传感器且传感器的变化也呈现多样性,传统的基于阈值的异常检测方法无法有效检测异常.为了充分挖掘传感器之间的依赖关系来提高检测准确率,MAD-GAN使用LSTM作为基础网络来构建GAN模型,将时间序列按多尺度进行划分来挖掘数据的潜在关联,模型训练完成以后通过利用GAN训练的生成器和鉴别器,以真实数据和生成数据的重建和误差损失来检测异常.针对现有方法难以有效提取传感器数据的有效特征,为了进一步提高模型准确率,本章提出一个基于小波变换和注意力机制的生成对抗网络模型,首先使用离散小波变换来生成多个层次的传感器数值,增强了数据特征.同时小波变换能有效降低数据的波动性,防止数值波动带来的结果误判.然后通过注意力机制和多层LSTM网络学习小波变换后的多层次传感器数值中的关联特征,最后通过训练后的生成对抗网络来识别异常行为.
4 数据预处理
ICS依据工业传感器实时掌控工业生产流程,但是传感器的数值变化并不是线性的,存在一定的波动性和噪声.在图1中绘制了400个传感器数值样本的图,其中前200个样本代表正常数值,后200个样本代表异常数值.在图1(a)中,根据绿色的分界线可以看到正常样本和异常样本中都存在到波动点.传统的机器学习分类方法仅根据当前时刻的状态做出决策,因此很有可能将正常样本中的波动点A判断为异常,异常样本中的波动点B判断为正常.但是如果检测异常时将波动点周围更多样本信息考虑进去,则可以发现波动点A周围的样本都是正常的,其实波动点A只是传感器的一个噪声点,属于正常样本.同理可知,波动点B是异常样本中的噪声,虽然从传感器数值上看是正常的,但依旧属于攻击行为.针对这种因传感器数值波动而使得模型检测准确率降低的情况,本文引入离散小波变换来去除数值波动噪声和提取数据高维特征.
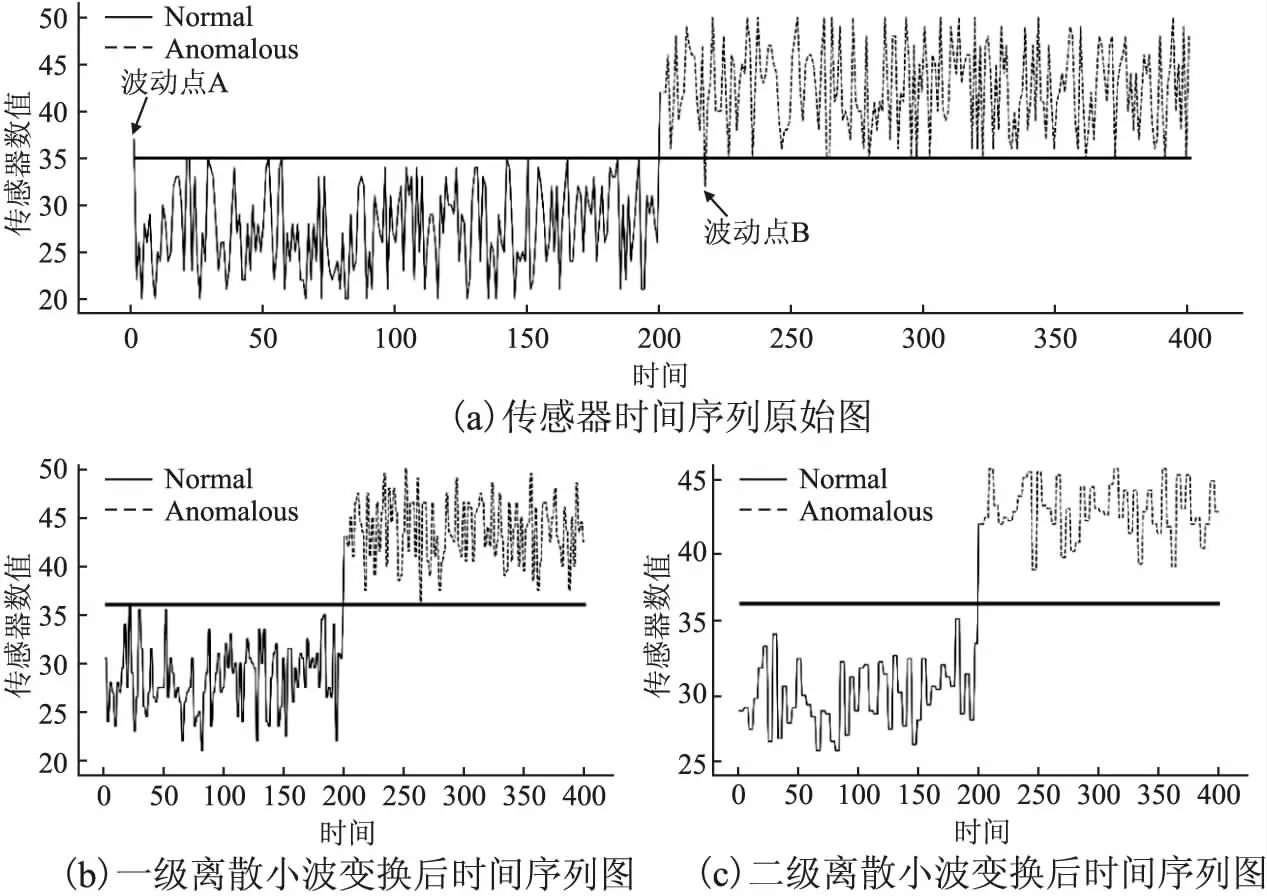
图1 多尺度时间序列图Fig.1 Multi-scale time series diagram
离散小波变换基本原理是选取一个基础的小波,通过对基波进行平移伸缩来拟合原始的离散数据.经过一级离散小波变换可以将原始序列Xn={x1,x2,…,xn}分解为近似部分A1和细节部分D1,其中近似部分即低频信息,表示原始数据的主要信息特征,细节部分即高频信息,表示原始数据的一些噪声信息或者特殊特征.小波分解技术在音频降噪和提取特殊声音等方面应用广泛[26-28],小波变换可以将原始的音频信息进行多次分解生成多尺度的高频信息和低频信息,通过将低频信息去除再使用逆离散小波变换重新合成新的音频来去除噪声,也可以提取人的声音而除去人的音色信息.
离散小波变换能不同尺度上对原始数据信号进行分解,分解的尺度可以根据不同的目标来确定.通过将原始信号与低通滤波器Hn卷积获得近似系数,而细节系数由高通滤波器Gn获得,这些系数都要通过降采样滤波器Q进行降采样.在离散小波变换的具体分解过程中,一级变换就是将Xn分解为A1和D1,二级变换则是将A1再次分解为A2和D2,依次类推最多可以分解log2n层,其中n为序列Xn的长度.
不同级别离散小波变换生成的低频信息和高频信息从多维度提供原始信号的特征信息,其中较高级别的低频信息能反映原始信号全局变化趋势.对于不同尺度级别的离散小波变换进行重构即进行逆离散小波变换,可以提取原始信号的多尺度特征.如图2所示,原始信号经过离散小波变换后会生成低频信息和高频信息,将高频信息经过阈值量化处理,再使用重构滤波器将处理后的高频信息和低频信息进行卷积,从而得到重构信号,重构信号可以让数据特征更加明显.图1(b)是经过一级离散小波变换再重构后的传感器时间序列图,从图中可以明显看到噪声点被去除,正常样本和异常样本被水平分界线清晰区分开.图1(c)是经过二级离散小波变换再重构后的传感器时间序列图,从图中可以看待原本在分界线处有较多重合的正负样本被进一步区分,多级小波变换可以进一步挖掘正常样本和异常样本各自的数据特征,可以反映序列的整体趋势.
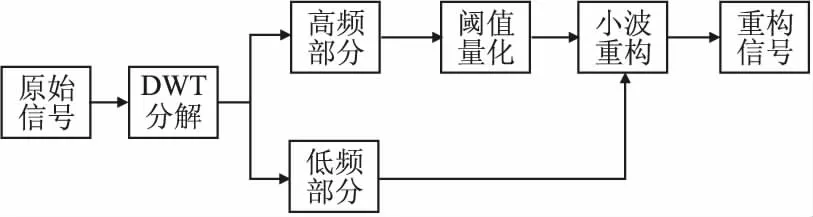
图2 逆离散小波变换重构过程图
多数现有的异常检测方法仅根据当前数据来构建传统的异常检测模型,而忽略了时间序列间的前后关联.在真实的工业生产中各个生产环节前后关联,各传感器数值是反映工业生产的实际情况,因此当前传感器数值变化在时间维度上是有关联的.本文所提的WAGAN模型不是单独处理每个数据流,而是同时考虑整个变量集,以便让模型捕获变量之间的潜在关联.对于数据进行多尺度处理的过程为:给定输入数据集Xn={x1,x2,…,xi,…,xn},Xn∈d×n,其中d为xi的维度,n为序列总个数,将Xn经过K级离散小波变换分解和重构后可获得多尺度时间序列R:
R={R1,R2,…,Rk,…},k∈(1,K)
(1)
(2)
其中Rk表示Xn经过第k级离散小波变换分解和重构后的值.再将获得的多尺度序列使用长度为w的滑动窗口进行切分处理且步长为1,可以得到新的输入Xtrain,Xtrain∈N×K×w×d,其中N为Xtrain的总样本数且值为n-w+1,K为离散小波变换分解和重构等级,w为滑动窗口长度,d为序列维度.
5 WAGAN网络模型
通过对ICS运行机制的深入了解和对传感器数值规律的分析,本文在GAN模型中引入离散小波变换和注意力机制来进一步挖掘数据特征,提出了基于小波变换和注意力机制的GAN模型(WaveletAttentionGAN,WAGAN).如图3所示,WAGAN模型分为两个部分:WAGAN训练模型和WAGAN检测模型.经过第4章节的数据预处理,原始的时间序列数据已经处理为多尺度时间序列数据Xtrain,以下为WAGAN训练模型和WAGAN检测模型具体执行流程.
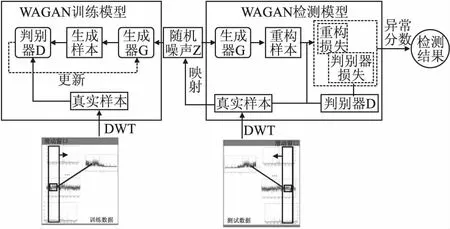
图3 WAGAN网络模型结构图
在训练模型中,首先生成随机的噪声Z输入到生成器(Generator,G)中,G根据Z输出生成样本;然后从训练数据中选取真实样本(训练数据全为正常样本),将真实样本和生成样本一起输入给判别器(Discriminator,D),D根据样本输出结果;最后根据D的输出更新D和G的参数,让G能生成以假乱真的样本,让D能准确辨别真假样本.D通过生成逼真的样本来捕获训练数据的异常特征,可以将其视为ICS正常运行下的运行规律.
在检测模型中,检测所使用的生成器G和判别器G是训练模型训练所得.首先从测试数据中选出要测试的真实样本,并将测试样本映射到随机噪声Z所在的潜在向量空间来寻找最接近测试样本的随机噪声Z;然后将最接近测试样本的噪声Z输入到G中生成重构的测试样本,将重构样本和实际测试样本进行对比得到重构损失(Reconstruction loss);其次将测试样本输入到D中得到判别器损失(Discrimination loss);最后根据重构损失和判别器损失可以得到异常分数(Discrimination and Reconstruction Anomaly Score,DRS),根据DRS可以判断测试样本是否异常.
5.1 模型网络结构
5.1.1 注意力机制模块
注意力机制(Attention),是指在神经网络过程中将训练的注意力从全局转移到目标关注的局部重点的一种机制,其原理就类似于人观察眼前画面的过程,人眼在观察某个画面时,人的注意力往往集中在感兴趣的区域并自动过滤掉画面中一些无关背景,从而迅速获取整个画面的有用信息.注意力机制最早由Bahdanau D等[29]提出,并应用在机器翻译领域,使用注意力机制帮助解码器获取所有输入状态的加权组合来进行输出.此后,注意力机制被广泛应用在计算机视觉[30-32]和自然语言处理[33,34]等领域.
为了进一步挖掘传感器数值的潜在特征,本文对原始的时间序列经过K级离散小波变换重构并对重构后的数据使用滑动窗口进行重新分组,让数据尺度扩大了K-1级,数据的复杂化使得模型变得难以训练.因此本文引入注意力机制来学习多尺度重构数据每一级的特征权重,权重越大表示该特征向量对模型结果的影响力更大.根据权重确定多尺度信息的主导特征所在,充分利用主导特征的信息,抑制权重小的特征表示,从而过滤掉无用的信息、筛选出有价值的信息,使得模型有选择地学习这些输入样本.从解释性的层次来说,向量权值的获取对训练过程的可解释性有一定的提高,通过使用注意力机制能帮助模型选择出那一级或哪几级离散小波变换在WAGAN模型构建中起到决策作用.

图4 注意力机制结构图
如图4所示,注意力机制输入为D′和h,D′指上下文内容,h指时间序列中每一个时刻的隐藏单元,a是表示经过softmax函数后的h和d的关联权重,c指用来做为下文LSTM网络输入的权值和.具体计算过程如下:
ut=tanh(W1D′+W2ht)
(3)
at=softmax(ut)
(4)
c=∑tatht
(5)
5.1.2 生成器网络
在WAGAN模型中,生成器的作用是模仿真实样本生成能欺骗判别器的假样本,因为在训练过程中使用的训练数据全是正常样本,使用经过训练后,生成器生成的假样本能准确包含真实样本的主要特征.生成器网络的具体结构如图5所示,包含两个LSTM层和一个Attention模块.生成器的输入为随机噪声Z,Z∈K×w×d,本文中随机样本Z和真实样本X维度一致且生成器是通过Z生成样本,因此按照真实样本含义来解释Z,其中K表示离散小波变换分解重构级数,w为时间步长即滑动窗口的大小,d为噪声序列维度,表示时间为t时第k级离散小波变换后的序列.先将随机噪声Z输入到第1个LSTM层得到隐藏单元表示时间部分为t时第k级离散小波变换序列的特征;然后将隐藏单元输入到全连接层得到特征其中Wu为权重,bu为偏置;再通过和uw来计算每一层特征的注意力权重其中uw是训练过程中的一个随机向量.最后由注意力权重和输入的噪声序列得到注意力的权重和Ct其具体计算形式如下:
(6)
(7)
(8)
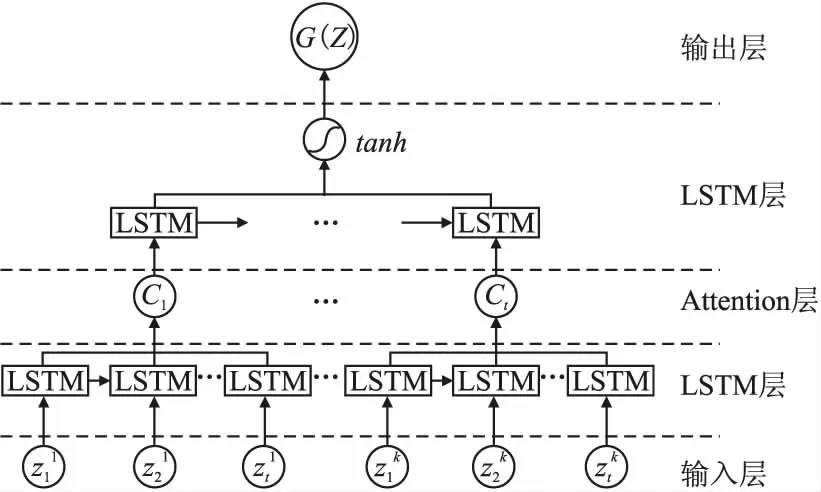
图5 生成器网络结构图
Ct是经过注意力机制得到的参数,包含了所有时刻为t时数据的高维特征.将代表数据特征的Ct输入到下一层LSTM网络中,然后将输出送入tanh激活函数.因为生成器生成的结果需要和真实样本一致,所以在输出结果前需要将结果重构为G(z),G(z)∈K×w×d.通过不断训练生成器模型,从随机噪声Z的数据空间中学习到符合真实样本特征的生成样本.生成器的损失函数为交叉熵函数,具体公式如下,其中y为判别器判别结果:
L(G)=-[ylnG(z)+(1-y)ln(1-G(z))]
(9)
5.1.3 判别器网络
判别器D的作用是判断输入的样本是真实样本还是生成的假样本,输出的结果为0-1序列,“1”代表真实样本,“0”代表生成的假样本,然后根据输出的结果更新生成器和判别器.判别器的网络结构和生成器的结构类似,包括两层LSTM网络和一个Attention模块.判别器的输入为假样本G(z)或真样本x,x∈Xtrain,G(z)和x结构一致,G(z),x∈K×w×d.判别器结果在输出前需要经过sigmoid激活函数将数值压缩到0和1之间,越接近1则越可能为真实样本,越接近0则越可能为生成样本.判别器D的损失函数和生成器一样都是交叉熵函数.
5.2 检测流程
在训练过程中使用的训练数据集Xtrain均为不包含攻击行为正常样本,而测试所用的时间序列数据包含了攻击行为.将测试数据经过第4章节中的数据预处理可以得到测试数据集Xtest∈RM×K×w×d,其中M为预处理后的测试数据集的样本数.WAGAN模型的检测流程如图3右侧部分所示,通过左侧的训练模型获得训练完成的生成器G和判别器D.基于GAN的异常检测大多是使用训练好的判别器来识别异常数据和正常数据,但是本文采用生成器和判别器结合的方式来检测异常.生成器根据输入的测试样本生成重构样本,并计算重构样本和测试样本间的误差可以得到重构误差;判别器根据输入的测试样本可以得到判别器误差;根据两个误差相加之和是否大于阈值可以判断测试样本是否为异常,下面介绍具体检测流程.
5.2.1 生成器重构误差
生成器经过训练以后能够将随机噪声Z转换成真实样本:G(z):z→x.生成器在训练时所使用的训练数据全是正常样本,可以认为生成器G可以学习到正常状态下工控系统传感器数值的分布,而Z则是这些数值变化的向量空间.因此对于测试数据Xtest可以找到和它最接近的正常样本Z′,通过比较Xtest和Z′得到重构误差.如果测试样本Xtest是异常样本,由于训练过程中没有出现,所以重构误差会很大.为得到最优最接近测试样本的Z′,本文先生成一个随机噪声Z,通过计算G(Z)和测试样本Xtest的相似性,然后利用梯度下降来更新噪声Z,计算公式如下:
(10)
寻找最优最优最接近测试样本Z′的过程就是最小化Xtest和G(Z)的差值即求生成的样本中最接近Xtest的随机噪声.找到Z′后,可以通过比较G(Z′)和Xtest的差异来求重构误差,计算公式如下:
(11)
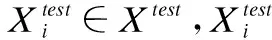
5.2.2 判别器误差
训练模型中所用的训练数据全是ICS正常运行下捕获的正常数据,因此通过训练模型获得的判别器D能学习到正常样本的特征来准确地识别出正常的真实样本.测试样本都是真实样本,对于判别器D而言标签都为“1”,当测试样本为异常样本时,由于异常样本不符合正常样本的特征,判别器D误差会将异常样本识别为假样本,判别结果经过sigmoid激活函数输出接近0,这使得判别器误差会很大,通过这种方式可以识别异常样本.具体计算公式如下:
(12)
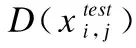
(13)
5.2.3 误差分数
检测异常时,根据重构误差和判别器误差来共同计算异常损失,通过参数λ来调节两部分误差权重.计算公式如下:
(14)
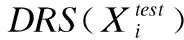
(15)
(16)
6 实验结果与分析
6.1 实验数据集
为了对WAGAN模型的检测准确率进行评估,并将其与同类异常检测方法进行比较,本文采用新加坡科技设计大学搭建的仿真平台——安全水处理平台[35](SecureWaterTreatment,SWaT)所捕获的传感器数据集.SWaT是一个按照真实的水处理厂缩小的仿真平台,每分钟可产生5加仑的干净水资源.该仿真平台水处理过程主要分为6个步骤:1)吸收需要处理的污水并将其存储在水箱中;2)将污水进行预处理并评估水质,如果水质不在可接受的范围内,则执行化学处理;3)使用滤膜去除水中的杂质;4)使用紫外线灯在脱氯过程中去除化学反应产生的氯化胆碱;5)将上面处理后的水使用水泵输送到反渗透系统中以减少无机杂质;6)最后将处理后的水存储起来,以便在水分配系统中进行分配.
SWaT仿真平台是由HMI、PLC、SCADA系统、现场设备以及实时数据库组成.现场设备中包含51个传感器可以实时检测和控制设备运行情况,污水处理的6个过程分别由6个PLC设备控制,SCADA系统将传感器的状态通过PLC和HMI通信实时反馈在HMI界面上.传感器可以通过无线网络每隔一秒将传感器的数值上传到实时数据库中,传感器数值包括水位高度等浮点数值和代表阀门开关状态等整数.
SWaT数据集在11天内共采集了946722个样本,包含51个传感器数值,其中前7天是SWaT仿真平台正常运行状态下采集的传感器数值信息,后4天是对SWaT平台进行多种类型攻击后采集的传感器信息.针对SWaT平台的攻击共有36种,包含传统的常规攻击,如侦查攻击;也包含语义攻击,通过劫持PLC的方式来修改传感器数值,或者打开传感器阀门等直接影响系统运行.攻击的持续时间为几分钟到一个小时不等.为了保证数据采集的准确性,系统在正常运行的前7天内稳定运行;在进行攻击时,需要在发起另一次攻击之前或连续发起攻击之前将系统运行至正常状态.SWaT数据集中,系统正常运行下收集的样本数为496800个,攻击开始后收集的样本数为449919.由于正常运行时的系统是从启动状态开始运行,考虑到系统运行到正常状态需要一定时间,本文在训练时将前6个小时的数据即21600条样本去除.本文中正常样本标记为负样本“0”,异常样本标记为正样本“1”.
6.2 实验评估指标
本文使用标准的评估指标,精确率(Precision),召回率(Recall)和F1分数来评估WAGAN的异常检测性能,各指标计算公式如下:
(17)
(18)
(19)
精确率用于衡量检测模型正确识别了多少正样本,但是当数据集严重不平衡时,精确率很难有效反映模型性能,比如当数据集中负样本数量占比很大时,模型性能很难通过精确率反映.召回率是衡量有多少正样本被检测出来的指标,但是只通过召回率也很难反映模型实际检测性能.F1值能同时兼顾精确率和准确率,因此需要将精确率、召回率和F1这3个指标结合起来评估WAGAN模型的异常检测性能.
6.3 实验设置
将SWaT数据集进行划分,前7天的正常数据作为训练样本,训练样本中需要去除21600条系统未稳定运行的样本,样本总数为475200;后4天加入攻击的数据作为测试样本,样本总数为449919.样本是由51个传感器数值组成,其维度d为51.为了获取更多数据特征,使用K级离散小波变换依次对51列数值进行分解重构,实验中K取值为3,离散小波变换的基波函数为“Haar”小波.为了获取时间序列前后关联,使用滑动窗口长度w为30的滑动窗口进行切分处理且步长为1,可以得到训练数据Xtrain,Xtrain∈N×K×w×d,其中N为Xtrain的总样本数为473171,同理可得测试数据Xtest.
在实验过程中,实验平台以及设备对实验数据的结果会产生影响,为了确保实验结果真实有效,所有实验都在同一环境下进行.实验环境以及相关软硬件配置如表1所示.

表1 实验环境
WAGAN模型中,生成器由两个LSTM层和一个Attention模块组成,生成器的输入为随机噪声Z,Z∈K×w×d,Z的大小为3×30×51,第1个LSTM层的隐藏单元数为153,第2个LSTM层的隐藏单元数为51,激活函数为tanh,使用交叉熵为损失函数并使用梯度下降为优化器,优化器的学习率为0.1.判别器的输入为真实样本x,x的大小为3×30×51,其网络结构与生成器一致,激活函数为sigmoid,使用交叉熵为损失函数并使用Adam为优化器,优化器的学习率为0.001.生成器和判别器的训练交替运行,batchsize为500,epoch大小为100.检测异常时,根据重构误差和判别器误差来共同计算异常损失,通过参数λ来调节两部分误差权重并根据异常阈值τ来判断是否异常,其中λ的值为0.2,τ的值为0.6.
6.4 实验结果
为了验证WAGAN模型的异常检测性能,将WAGAN模型和其他半监督异常检测方法进行,比较方法包括OCSVM[1]、Bi-GAN[12]、EGAN[11]和MAD-GAN[16].上述半监督方法训练时使用的数据集均是SWaT中正常运行时的数据,测试数据为添加了多种攻击的数据.
实验结果如表2所示,表中黑体部分为各衡量指标中最好的结果,OCSVM方法是依据正常样本的特征映射来训练模型,通过异常样本在模型中特征映射和正常样本有所区别来检测异常,但是很多正常样本与异常样本的特征区分并不明显,一些特殊情况下异常样本的传感器数值也符合正常样本的数组范围.Bi-GAN是一个双向学习的过程,对于已经配对的“原始样本和隐变量”,其中原始样本是已知的,隐变量是学习随机噪声分布;对于已经配对的“生成样本和随机噪声”,随机噪声是已知的,生成样本是学习原始样本.此方法使用编码器和解码器来学习正常样本的隐藏特征,然后根据训练好的判别器识别异常样本,此方法较OCSVM方法在精确率方面有所提升,但是召回率和F1分数方面表现很差.EGAN与Bi-GAN的原理类似,只是在模型效率方面做了些提升,检测结果也不理想.MAD-GAN模型考虑了时间序列数据之间关联性,按照不同时间尺度将多个样本划分为一组进行训练,同时将生成器和判别器结合来识别异常样本,模型异常检测效果得到明显提升.本文提出的WAGAN方法使用了离散小波变换在多个维度上挖掘数据特征,然后在不同时间尺度上将数据进行分组并使用注意力机制和两层LSTM模型提取时间序列数据前后关联特征,该方法较其他方法提升明显.综上所述,OCSVM、EGAN和Bi-GAN因为方法本身限制且没有考虑时间序列前后关联性,所以在检测结果上较差;MAD-GAN方法在精确率上最好,达到92.68%,但是召回率和F1分数表现一般;本文提出的WAGAN方法因为使用了多层离散小波变换来增强原始数据,所以检测样本的异常会被扩大,这使得模型更容易识别出异常样本同时也较容易将正常样本误判.虽然WAGAN方法精确率较MAD-GAN方法略低,为89.60%,但是召回率达到99.65%,F1分数达到94.36%,较MAD-GAN方法提升明显.在ICS异常检测中,以略低的精确率来换取更高的召回率来保证工控入侵检测系统的低漏报率和稳定性是十分值得的.
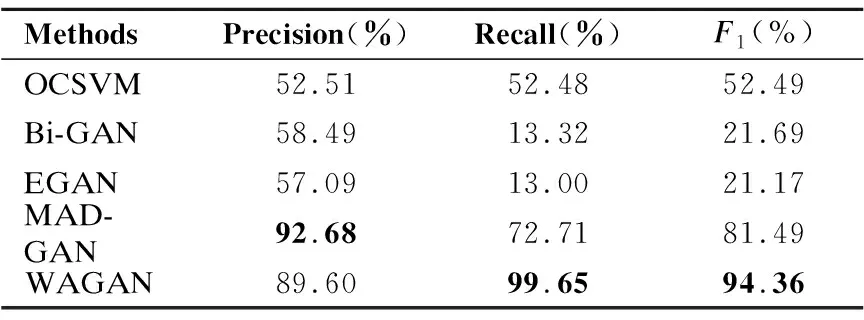
表2 不同方法异常检测结果Table 2 Anomaly detection results of different methods

图6 WAGAN模型检测过程迭代图
WAGAN模型在异常检测时会依次读取训练过程中每一次迭代的生成器和判别器模型,并根据待检测的样本来拟合最接近检测样本的随机噪声进行异常检测.图6是WAGAN模型100次迭代过程的检测结果,从图中可以看出WAGAN模型具有很高的稳定性.如图6(a)为WAGAN模型100次迭代的精确率图,精确率一直在88%以上振荡,当迭代到第42次时达到最大值89.60%;图6(b)为WAGAN模型100次迭代的召回率图,本方法通过多层离散小波变换分解重组将数据特征增强能有效识别出异常,召回率基本稳定在99%以上;图6(c)为WAGAN模型100次迭代的F1分数图,由于本方法召回率基本维持在99%以上,因此F1的波动受精确率的影响,振荡也与其相似,当迭代到第42次时达到最大值94.36%.
WAGAN模型在检测异常样本时,生成器根据输入样本得到重构误差,判别器根据输入样本得到判别器误差,重构误差和判别器误差的权重和即为检测样本异常分数,通过比较异常分数和阈值τ来判断检测样本是否为异常.如图7所示,本文选取了0.2-0.7共6个阈值,并根据评估指标F1分数来判断WAGAN模型的异常检测性能.当τ的值为0.6时,WAGAN模型的F1分数在100次迭代中整体最高且基本稳定在90%以上.
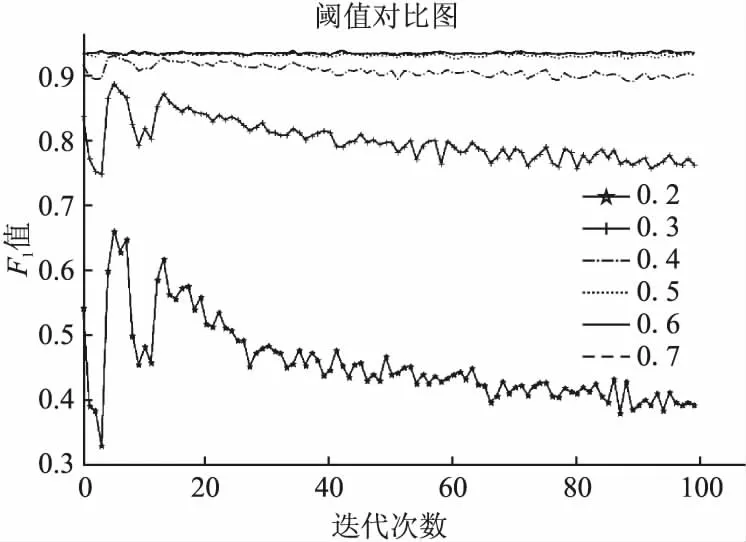
图7 不同阈值τ下WAGAN模型F1分数图
7 总 结
本文提出WAGAN模型来检测工控系统异常,根据生成器数值可能出现波动采用多级离散小波变换分解重组的方式去除噪声并增强数据特征,并使用注意力机制来提取有效特征.根据时间序列前后关联性将原始数据进行分组并使用LSTM网络学习数据的潜在关联性.在检测阶段,生成器根据测试样本寻找与其最接近的随机噪声并得到重构误差,判别器根据测试样本得到判别器误差,WAGAN模型将两者的权重和与阈值比较判断测试样本是否异常.为了验证模型性能,将WAGAN模型应用在真实的SWaT数据集上,并与其他同类方法进行对比.根据实验结果可知,本文方法异常检测性能更好且稳定.
