融合深度BiGRU与全局图卷积的方面级情感分析模型
2023-01-31杨春霞陈启岗
杨春霞,徐 奔,陈启岗,桂 强
(南京信息工程大学 自动化学院,南京 210044) (江苏省大数据分析技术重点实验室,南京 210044) (江苏省大气环境与装备技术协同创新中心,南京 210044)
1 引 言
方面级情感分析作为情感分析中细粒度的研究任务,目的在于判断一个句子中特定方面的情感极性.伴随着互联网的高速发展,用户关于产品、服务的各种评论数据量激增,从这些数据中获取用户关于特定方面的情感极性无疑在舆情分析、国民情绪预测、商品质量跟踪等应用中都有着非常可观的价值,所以对方面级情感进行分析是有必要的.
方面级情感分析任务中常使用循环神经网络(Recurrent Neural Network,RNN)、长短期记忆(Long Short-Term Memory,LSTM)神经网络提取文本中的语义特征信息,并从浅往深提取语义特征,而大多研究基于深层LSTM提取语义信息[1].GRU作为LSTM的变体,在信息处理方面有着速度快效率高的优势,所以本文利用GRU挖掘深层信息.
随着研究的深入,不少人认为仅从语义层面提取信息忽略了文本中的句法结构.单根据语义特征进行方面级情感分类存在偏差,因此融合语义特征与句法结构是必要的[2].
图卷积与依存树的搭配可以很好的融合语义与句法信息.普通图卷积网络在提取特征时忽略了信息传播的方向问题,双向图卷积网络可以通过正反两个方向对语义特征和句法信息进行特征融合,完成信息的交互从而更好的完成任务.传统的句法依存树只包含与根节点有关的连接,且生成的邻接矩阵中包含许多零元素,存在数据稀疏的问题.现实生活中,一条语句中的词语都处于同一语境,任意两个词之间都存在联系,但传统依存树中不能描述出每个词语之间的关系,存在信息丢失问题,所以本文考虑如何解决数据稀疏与信息丢失问题.
基于以上分析,本文提出了一种基于深度双向门控循环单元(Deep Bi-DirectionalGated Recurrent Unit,DGB)与全局双向图卷积(Global Bi-Directional Graph Convolution Networks,GBGCN)的方面级情感分析模型(DBG-GBGCN),工作内容如下:
1)本文先使用深度双向门控循环单元(BiGRU)对词向量编码,提取方面词及其上下文单词的语义特征,得到带有上下文信息的隐层表示.
2)本文构建了带有全局信息的句法依存树,根据原始句法依存树中节点关系生成邻接矩阵,将节点与节点之间都加了一条边进行连接,形成了包含全局句法结构信息的全局图矩阵,将此矩阵与上下文的隐层表示一起输入至双向图卷积进行特征融合,可以获得全局句法结构信息.
3)本文使用了双向图卷积网络,从正反两个方向进行训练,使之融合了语义特征与句法结构信息.得到GBGCN的输出后,再经过对方面词的掩码筛选操作,得到了特定的方面词表示.在处理层中使用了注意力机制,将掩码过后的方面词表示与深度BiGRU得到的隐层表示进行注意力操作,再将隐层表示与特定方面词加权求和,用softmax函数得到用于情感分类的极性.
4)本文在公开的5个情感分析数据集上进行模型对比实验、有效性实验等,实验结果表明,本文提出的DBG-GBGCN模型是有效的.
2 相关工作
如今大多数情感研究都是围绕着深度学习开展的,先前许多研究者对于方面级情感分析的研究主要集中在语义信息提取中,如Bahdanau[3]等人在机器翻译的任务中使用了循环神经网络,使用RNN可以对文本进行语义特征的提取,在任务中与注意力机制结合取得了不错的效果.但是RNN不能很好的处理长距离文本信息,LSTM是针对这个问题提出的改进,所以Wang[4]等人将RNN替换为LSTM并与注意力结合,提升了模型的效能,证明LSTM可以更好提取语义特征.而Liu[5]等人采用的BiGRU提取金融领域的文本,证明了BiRGU比BiLSTM在信息处理方面更有效.BiGRU可以通过正反两个方向对句子特征进行削弱或加强,以互补的形式来减弱加强文本信息处理.现有研究中大多使用浅层特征信息,也有许多研究考虑到了深层次的信息,如李[1]等人做出了改变,使用深度BiLSTM验证了深度网络对特征和语义关系有着更好的提取能力,张[6]等人使用堆叠LSTM解决了收敛慢,识别精度低的问题,实现了深层次抽象特征的提取.李[7]等人提出了一种深层自注意力Bi-LSTM模型,用以增强对象相关的情感信息.陈[8]等人使用双向切片GRU以增强语义提取的深度,表明提取深层信息是有必要的.但是这些研究大多基于LSTM研究深层次信息获取,GRU相比于LSTM在信息获取方面有着更高的效率,利用GRU获取深层次信息是本文考虑的问题.
GCN将传统的卷积神经网络变为图上的卷积神经网络,这样可以通过图结构对信息进行特征提取,从结构层面去完成任务.如Zhang[9]等人使用了图卷积神经网络提取了句子中的句法依存信息,将句子中的句法特征融入了情感分析的任务之中.杨[10]等人对图卷积神经网络进行了很好的实践,将图卷积网络运用在了中文对话中,证明了图卷积网络的适用性.王[11]等人将注意力与图卷积相结合并很好的运用在了关系抽取方面.Fu[12]等人将BiGCN运用在了关系抽取的任务上,证明BiGCN比普通GCN能更好的进行结构特征提取.于此本文考虑将使用BiGCN对上下文信息进行特征融合.
依存树是提取句法结构的有利工具.对依存树进行修剪会影响到句法提取的效果.如Zhang[13]等人从句法结构层面去考虑信息有助于模型完成正确的情感分类,证明用依存树从句法层面提取结构信息是合理的.Chen[14]等人将依存树生成的邻接矩阵修改为带有位置信息的邻接矩阵,使得句法结构中带有位置权重,传入GCN中获取有用的位置信息.王[11]等人使用了基于注意力的依存树软剪枝策略,证明了修剪依存树的策略可以很好的捕获句法间结构信息.Hou[15]等人提出了一种集成多个图的集成图模型,可以通过不同依存树的解析器,获取不一样的句法结构信息.齐[16]等人修改邻接矩阵,使用带有权重信息的权重矩阵,可以增强权重从而取得更佳分类效果,但是对于信息缺失与数据稀疏问题仍没有做出改变.这些方法虽然可以通过修剪依存树对结构信息进行改进,但是缺少考虑全局的句法信息.对此本文使用全局图矩阵解决信息丢失与数据稀疏问题.
3 模型概述
本文的DBG-GBGCN模型框架主要包含深度BiGRU、全局矩阵、L层BiGCN、连接层、掩码层、注意力层和分类层,具体结构如图1所示.
3.1 词嵌入
词嵌入是指将词语映射为词向量的过程.经过预训练的词向量可以从未标记的文本信息中提取出需要的语义句法信息.在本文中使用了预训练好的Glove[17]词典将每个词生成分布式表示,本文将一个句子映射成基于方面词的上下文表示.一句话由n个单词{ω1,ω2,…,ωφ+1,…,ωφ+m,…,ωn-1,ωn}组成,其中ωφ+1,…,ωφ+m代表方面词,其余代表基于方面词的上下文单词,通过Glove映射成一个新的词向量来代替这个单词的原始表示,之后会得到一个包含全部单词的分布式词嵌入矩阵,嵌入矩阵的表示形式为W∈U×dm,其中U表示词汇表大小,dm代表的是单词的嵌入维度,对于每个单词都会有对应的词向量ei,词向量对应的句子向量就可以表示为{e1,e2,…,eφ+1,…,eφ+m,…,en-1,en},即为基于方面词区分的上文与下文词表示.
3.2 深度BiGRU
(1)
(2)
(3)
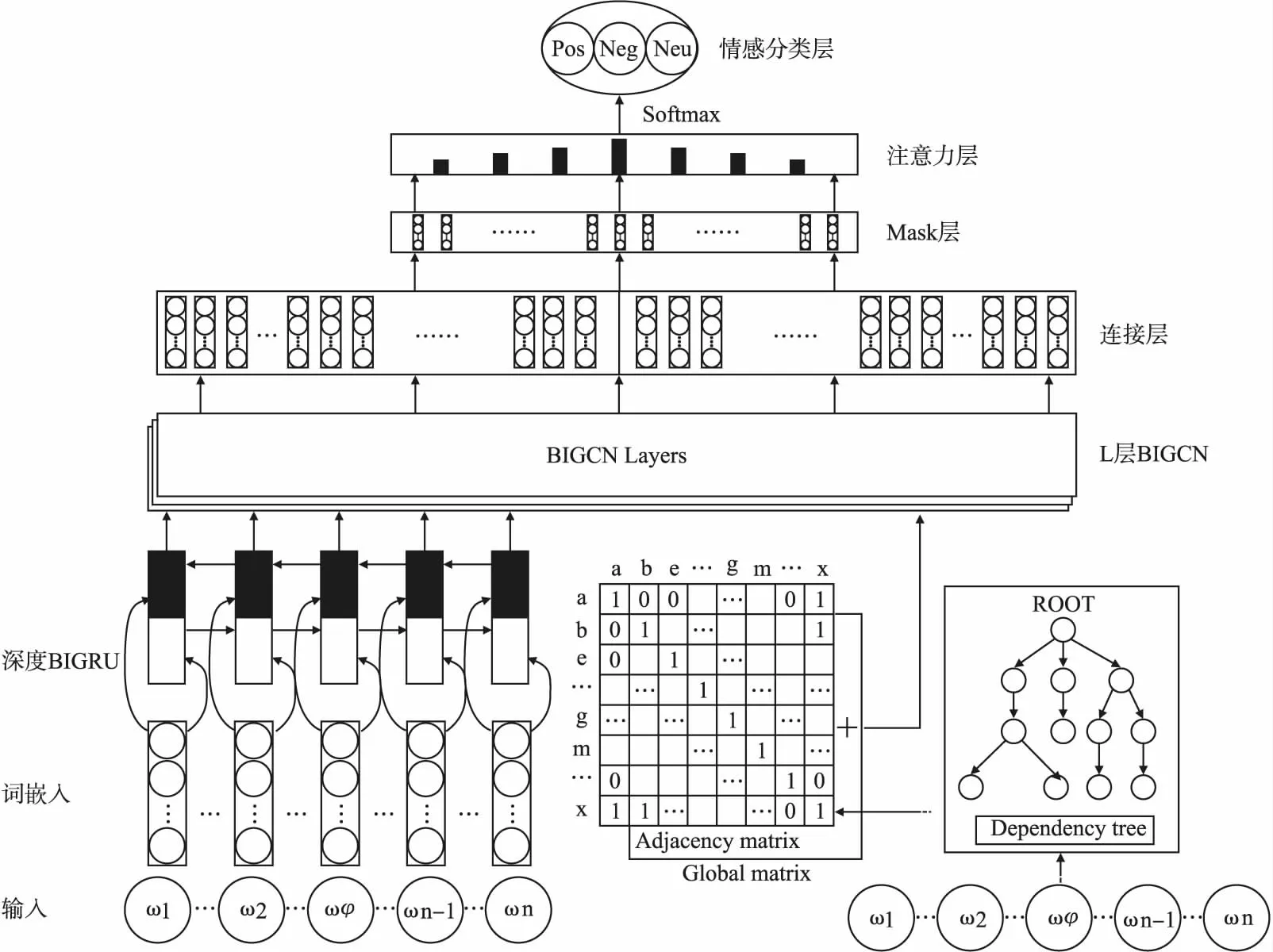
图1 模型框架Fig.1 Framework of the model
本文使用的BiGRU如图2所示,在输入层之上使用一层BiGRU,BiGRU包含着正向GRU和反向GRU传递的过程,通过双向GRU可以使基于方面词的上下文信息表征更加丰富,以互补的形式加强信息的交互,这样相对单向GRU来说能够捕获更多有用信息,通常情况下双向GRU也会表现的比单向GRU效果好.深度BiGRU就是将神经网络的深度不断拓展,在一层BiGRU基础上,再叠加多层BiGRU,叠加的方式就是将每个BiGRU层的输出作为下一层BiGRU相应节点的输入.本文在实验中堆叠了两层以达到深度的效果.
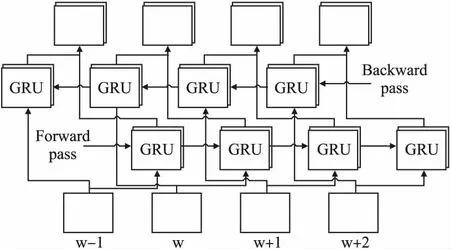
图2 BiGRU结构图Fig.2 Structure of BiGRU
深度BiGRU中每层都包含着正向传递和反向传递两个序列的子网络,如公式(4)和公式(5)所示正向传播代表着输入序列的依次传递,反向传播代表着输入序列的逆向传递.公式(6)表示正向与反向传播的拼接,为一层最终输出.
(4)
(5)
(6)
将第1层BiGRU的输出作为第2层BiGRU的输入,并以此类推.用深度BiGRU对上下文进行编码后,得到的上下文隐层表示如公式(7)~公式(10)所示.
(7)
(8)
(9)
Os={O1,O2,…,Oφ+1,…,Oφ+m,…,On-1,On}
(10)

3.3 依存树上的全局图矩阵
将句法依存树运用在方面级情感分析中,可以提取词语各部分的句法结构,表示单词之间的句法依存信息,句子中的词向量都可以看作图结构中的节点表示,将节点以邻接矩阵的形式进行图卷积.从数据结构角度来看,一句话中词与词间存在句法联系,单以谓语动词作为根节点构建邻接矩阵,关系较远的词语之间会被赋予零,从而生成的邻接矩阵中会包含许多零元素,可能会存在着信息缺失问题,例如图3所示.在对矩阵进行增减、卷积等操作时可能会导致数据愈变稀疏,大维度的矩阵中仅含有少量的单位元素.从语句角度来说,一句较长语句的情感主要由与根节点相连的几个关键词确定,存在忽略了其余单词作用的问题,从而造成关键信息的缺失.为了解决依存树生成的邻接矩阵中包含大量零元素,可能存在信息缺失与数据稀疏的问题,本文构建了全局图矩阵,在原始的邻接矩阵附加上一层单位阵即为全局图矩阵.本文对于全局矩阵的构造方式如式(11)~式(14)所示.
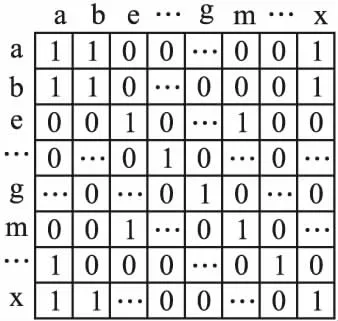
图3 数据稀疏的矩阵Fig.3 Sparse data matrix
Xii=1
(11)
Xij=1或Xij=0
(12)
Yij=1
(13)
Gij=Xij+Yij
(14)
Xii=1表示邻接矩阵的对角线上所有元素设置为1,代表图中每个节点进行了自循环操作.式中Xij=1表示第i个节点存在有向连接至第j个节点.Xij=0表示第i个节点与第j个节点之间不存在连接,在生成的邻接矩阵时,又附加了单位阵Yij,表示将图结构中每个节点之间都加了一条边进行连接,这样可以使图包含全局的依赖信息.Gij代表着图中所有节点连接,即为全局图矩阵.如此操作让每个单词都起到相应的作用,避免了数据稀疏与信息残缺,实验证明全局图矩阵的存在可以提升分类效果.
3.4 双向图卷积
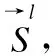
(15)
(16)
(17)
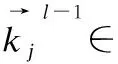
(18)

(19)
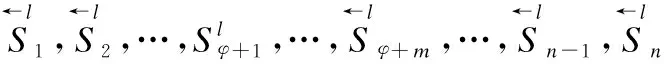
(20)
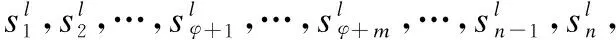
3.5 方面词处理层
3.5.1 掩码层与注意力层
将连接层中BiGCN的拼接结果作为掩码层的输入,掩码层中会根据是否为方面词这个条件,进行选择性屏蔽,其中将表示为方面词的词向量会保持不变,非方面词的词向量则会被设置为0,方式如公式(21)所示.
(21)
经过掩码层的输出表示如式(22)所示.
(22)
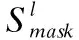
(23)
(24)
其中Qi表示上下文中第i个词对方面词的相关性,at表示方面词对上下文的注意力权重,μ表示表征向量,最终权重分配公式如(25)所示.
(25)
3.5.2 情感分类层
经过注意力权重分配后,输出信息会获得带有方面词以及上下文信息融合的特征向量,将特征向量作为最后进行方面级情感分类的输入,在经过全连接层与线性层将其映射到一个含有三分类情感极性向量空间后,使用softmax函数进行情感极性概率预测,取最大值就是所表示的情感极性.
∂=softmax(V·μ+θ)
(26)
式(26)中,V代表着权重矩阵,θ代表偏差项.
损失函数选用的是基于L2正则化的交叉熵损失函数,损失函数如公式(27)所示.
(27)
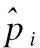
4 实 验
4.1 实验平台
本文的实验平台及实验环境如表1所示.
4.2 数据集介绍
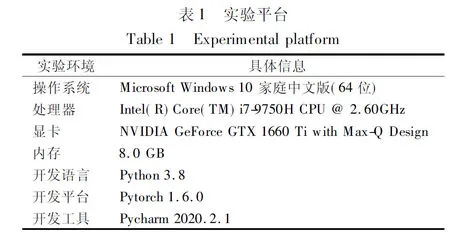
本文选取了5个公开的数据集,分别是TWITTER评论数据集、SemEval 2014 任务4中的LAP14与REST14数据集、SemEval 2015 任务12中的REST15数据集和SemEval 2016 任务5中的REST16数据集.以上数据集中包含消极、中性和积极3种不同情感极性,具体分布情况如表2所示.
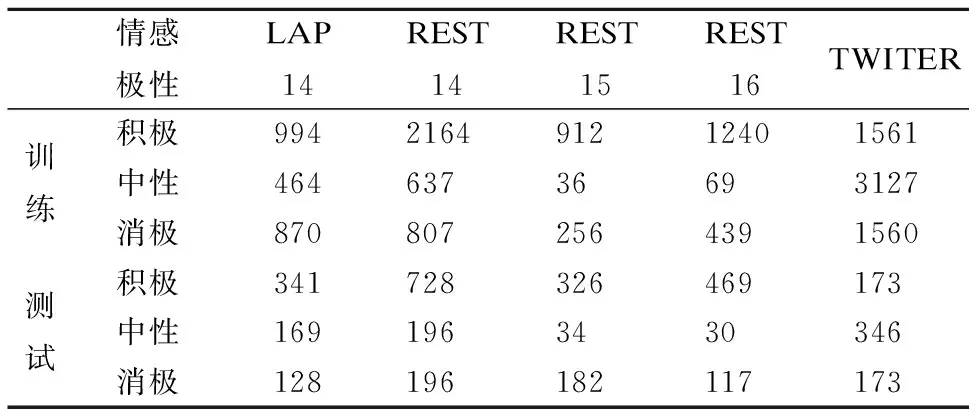
表2 数据集Table 2 Dataset
4.3 实验参数设置与评价指标
4.3.1 实验参数
本文初始化的词向量为300维,BiGRU采用2层,BiGCN在对比实验中采用2层,使用了Dropout防止过拟合,并使用Adam优化器进行优化,在BiGCN中采用Early stop操作防止精度衰减.具体参数设置如表3所示.
4.3.2 评价指标
本文采取了准确率(Accuracy,Acc)和MacroF1值作为验证模型的指标,公式(28)如下.
(28)
式中P、R表示精确率与召回率,n表示类别数,TP表示为正的样本预测,实际为正样本.FP表示为正的样本预测,实际为负样本.FN表示为负的样本预测,实际为正样本.TN表示为负的样本预测,实际也为负样本.MacroF1(简称F1)表示各个类别F1的平均值.T为正样本,N为总样本.
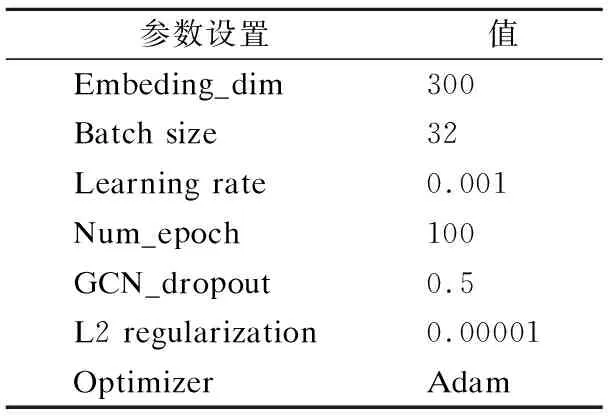
表3 参数设置Table 3 Parameter settings
4.4 对比实验
本文使用以下模型作为对比模型:
1)SVM[18]:使用了常规的SVM分类器,对一些特征进行了提取,在该任务中系统会自动确定方面术语、方面类别以及情感.
2)LSTM[19]:根据句子中的上下文对目标的语义相关性进行建模,并将目标信息合并到LSTM来提高情感分类的准确率.
3)AOA[20]:以一种联合方式为方面和句子同时建模,并通过AOA模块自动关注句子重要的部分.
4)IAN[21]:利用注意力实现了目标词与上下文的交互性,并运用在方面词的情感分类任务中.
5)ASCNN[22]:将卷积神经网络用于句子分类任务与情感分析问题,文中训练了一个从无监督神经语言模型得到的词向量的基础上进行卷积的卷积神经网络.
6)RepWalk[23]:使用了一个名为RepWalk的模型,在语法上执行了复制的随机游走图,实验证明在图上的随机游走策略确实可以提升效果,其中RepWalk+BiGRU表示使用了BiGRU处理语义信息,RepWalk+DL表示使用了依存树作为工具.
7)HSCN[24]:提出了获取上下文信息与目标词之间交互的模型,选择目标词以及上下文表示,使用一个目标语义蒸馏模块来产生目标特定上下文表征来进行水平感知预测.
8)ASGCN[2]:在依存树上建立一个图卷积网络,利用句法信息与单词依存关系进行情感分类,证明了语法信息和长距离单词依赖都被图卷积结构很好的捕获,其中ASGCN-DT代表使用的是有向图,ASGCN-DG代表使用的是无向图.
4.5 对比试验分析
通过表4的实验结果可以分析出,本文提出的DBG-GBGCN在5个不同的公开数据集上的准确率和F1值都有着一定的提升.SVM模型作为传统机器学习的算法,只使用了SVM基本分类器手工提取特征,没有结合深度学习的神经网络模型.LSTM模型对上下文进行建模,考虑到了语义特征提取,但是语义信息提取只停留在了浅层,而且单从语义结构去考虑的建模,全局信息以及句法结构信息并没有考虑.AOA与IAN类似,都通过目标词实现了与上下文之间的信息交互从而获取语义,缺少从图的结构去理解句法结构信息,同时缺少全局信息,效果会低于带有图结构的神经网络模型.ASCNN将卷积神经网络加入到了词向量的处理之中,考虑到了结构信息,但是没有联系上下文信息与结构信息进行信息交互.RepWalk模型中不仅考虑到了语义的特征提取,还考虑到图的随机游走,实现了语义与结构的综合考虑,效果相比而言有所提升.HSCN将目标词与上下文进行水平感知预测,在语义性能方面得到了很大程度上提升,同样的在句法结构方面没有做出改进.ASGCN将图卷积神经网络应用到了词向量中,无向图的结果要好于有向图,两种方法都实现了从图的层面进行卷积操作,考虑到了句法信息的同时又融入了浅层语义信息,所以实验效果验证了会优于其他几个模型,但是对于深层次的语义信息与全局句法结构信息并没有考虑到.
本文提出的DBG-GBGCN模型在5个数据集上与工作近似的ASGCN模型中较好的ASGCN-DG模型相对比,准确率分别提升了1.25%、1.55%、0.55%、0.62%、1.83%,F1值分别提升了1.63%、2.21%、2.97%、3.27%、2.27%.相比于ASGCN模型有所提升,原因在于DBG-GBGCN改进了语义提取层,使用了深度BiGRU更好的提取深层次上下文信息,以互补的形式来减弱和加强文本信息交互,并且构建了带有全局句法结构信息的图矩阵,通过BiGCN的融合将上下文信息完成了深层语义与句法结构的二次交互,将深层BiGRU中忽略掉的信息进行再次利用,达到了深层语义与全局句法的综合考虑,所以效果会有一定提升,验证了深层语义与全局信息融合的可行性,该模型可以在深层信息提取与数据稀疏信息丢失的问题上得到一定改善.
从数据集角度分析来看,LAP14、TWITTER数据集数据分别相对均衡,而REST14,15,16数据集中积极、中性、消极样本分布更加波动,可以说明DBG-GBGCN具有一定的稳定性,数据集样本分布不能直接影响本模型的效果.此外,无论是数据量稀疏的REST15,还是数据量丰富的TWITTER,DBG-GBGCN都有着不错的表现,这归功于它从深层语义与句法两个方面结合考虑,实现了二者信息的交互.对于包含着一些不规范的语法结构,尤其含有噪声的时候,DBG-GBGCN依然表现出了不错的性能.综上所述,DBG-GBGCN是稳健有效的.
4.6 模型分析实验
4.6.1 深度BiGRU的有效性与层数实验
首先验证了深度BiGRU对于模型的影响,如表5中所示,将深度BiGRU与BiRNN、BiLSTM做对比,3种模型上都使用了全局图矩阵与BiGCN.由表可知,深度BiGRU相比于BiLSTM在准确率指标上提升了0.79%、1.34%、2.03%、1.47%、0.72%,结果表明深度BiGRU能更有效的获取上下文间深层次的语义信息,证明了BiRGU相比于BiLSTM在信息处理方面更有效.这是因为GRU是LSTM的变体,而BiGRU可以更好的通过正反两个方向对句子特征进行加强,以互补的形式来加强文本信息处理,实验证明深度BiGRU可以加强词义联系,获取到文本的深层特征,在深层次信息获取方面有着一定的改善.

表5 BiGRU的对比试验Table 5 Comparative test of BiGRU
其次为了研究深度BiGRU的层数问题,建立了在不同子数据集上最优层数实验,并在Lap14、Restaurant16、Twitter 3个数据集上进行实验对比.考虑到层数过大会出现过拟合的情况,于是层数范围设为{1,2,3,4,5}.层数实验如图4所示,其中主坐标轴代表准确率的指标,次坐标轴代表F1的指标.由图4可知堆叠2层BiGRU模型性能优于单层模型,因为多层结构会有着更强的提取特征信息的能力,当层数为3时模型性能出现小幅下滑,当层数为4和5时模型性能有稍许回升,但是需要考虑过拟合导致梯度消失的问题.所以将深度BiGRU的层数设置为两层用以提取深层语义特征最佳.
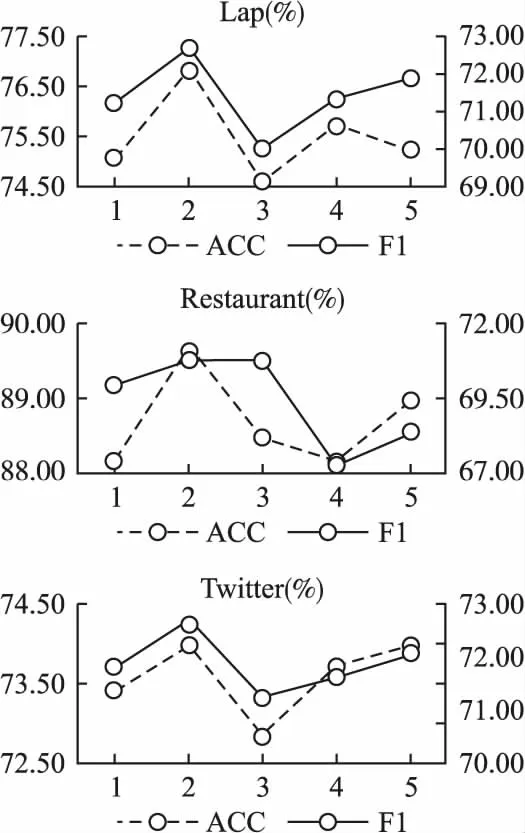
图4 BiGRU层数对比Fig.4 Comparison of layers of BiGRU
4.6.2 全局图的有效性验证
为了验证全局图矩阵的有效性,本文将建立BiGCN与GBiGCN模型,分别代表着无全局图矩阵与有全局图矩阵.通过对全局图矩阵的消融,由表6可知在5个不同数据集上的准确率分别提升了1.1%、0.54%、0.74%、0.82%、0.86%,F1值分别提升了0.83%、1.13%、2.56%、2.02%、1.22%.使用了全局图矩阵后从数据结构角度来看,邻接矩阵中包含了1与2,在对矩阵进行增减、注意力、卷积等操作时不会出现零元素, 每个位置都会赋予值,使得模型考虑每个位置的作用,即为包含了全局的特征信息.从语句角度来说,全局矩阵使得其余单词也可以发挥作用,而非选择忽略.实验结果证明了有全局图矩阵的模型效果优于没有全局图矩阵的模型,全局图可以获取更全面的特征,在信息丢失与数据稀疏方面得到一定改善.

表6 全局图消融Table 6 Global graph ablation
4.6.3 BiGCN的有效性与层数实验
为了进一步研究BiGCN的有效性,首先将普通GCN与BiGCN在准确率指标上进行了对比,实验如图5所示,BiGCN相比普通GCN在准确率指标上分别提升了1.73%、0.63%、1.11%、1.3%、0.86%,实验结果表明了BiGCN,从正反两个方向进行图卷积操作,实现上下文信息的交互,可以更好的进行特征融合,是比普通GCN有效的.
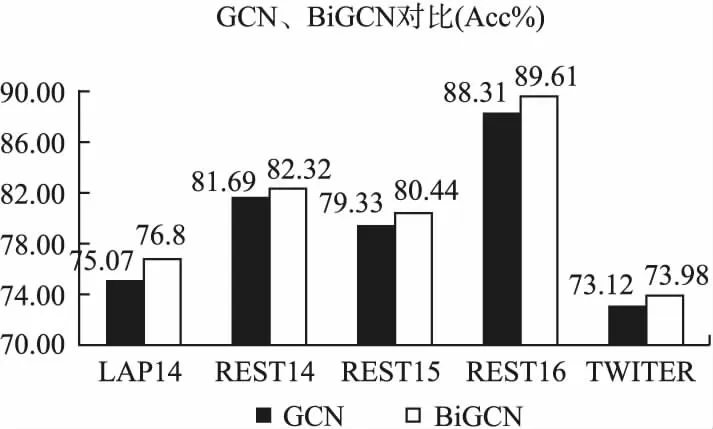
图5 BiGCN的有效性Fig.5 Effectiveness of BiGCN
其次以LAP14数据集为例,对BiGCN层数进行了对比实验,在实验中取BiGCN层数范围为{1,2,3,4,5},图6中横坐标代表着BiGCN的层数,主纵坐标包含着准确率与F1值.从图中可以看出,当BiGCN层数设置为2的时候,准确率与F1值都达到了最高值,当层数为3或4的时候,其性能明显呈现出了下降的趋势,主要是因为当层数变多后,BiGCN需要训练的参数也会越来越多,负载过大使模型变得难以训练.当层数设置为5的时候,其性能会有些许回升,但是与2层相比还是存在着一定的差距,而且同样需要考虑过拟合的问题.所以BiGCN的层数设置为2层最佳.
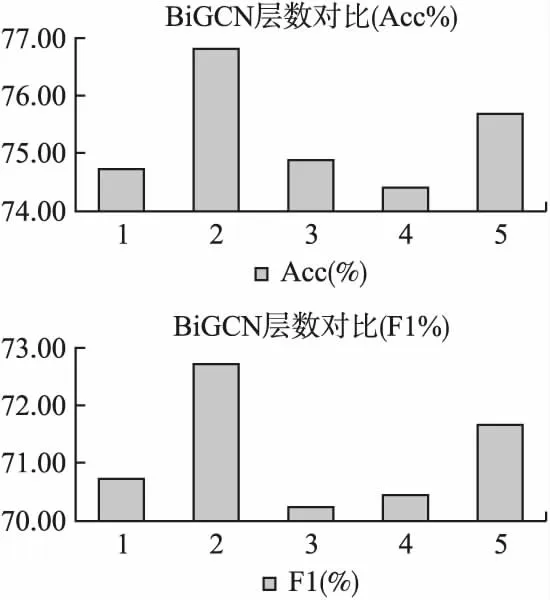
图6 BiGCN层数对比Fig.6 Comparison of BiGCN layers
5 结束语
为了解决深层语义提取与句法信息丢失的问题,本文提出了DBG-GBGCN模型来进行情感分类任务:通过深度BiGRU来更好的获取方面词上下文深层次信息表示;利用带有全局信息的图矩阵获取更全面的句法信息,并使用BiGCN从正反两个方向将语义与句法特征融合,最后经过掩码与注意力机制,用softmax完成情感分类.在五个公开数据集上进行了实验对比,取得了更优秀的分类效果,同时也验证了深层语义与全局句法的合理性.
虽然本文提出的模型在多个数据集上取得了不错的效果,但是带有全局信息的图矩阵,可能会过多的包含了冗余信息,如何修剪依存树,或利用注意力机制使每个向量带有自己的权重,这将会是进一步提升效果与性能的一个方向.
