局部最近邻密度和颜色特征加权的超像素生成
2023-01-31徐新黎邢少恒王凯栋许营坤王万良
徐新黎,邢少恒,王凯栋,许营坤,管 秋,王万良
(浙江工业大学 计算机科学与技术学院,杭州 310023)
1 引 言
作为计算机视觉任务中的重要预处理步骤,Ren等人[1]提出的超像素算法可以把图像中具有相似亮度、颜色和其他特征的像素聚合成具有一致性、能够保持一定图像局部结构特征的子区域,从而减少后续处理的基本单元数目.超像素因其良好的边界附着性、语义一致性和高效性等特点,并可以有效降低处理对象规模和后续处理的计算复杂度,已被广泛应用于图像分割[2-4]、目标检测与跟踪[5-7]、显著性检测[8,9]、光流估计[10-12]及其他视觉任务中.
超像素的好坏由边界附着性、区域紧致性、形状规则性和复杂环境适应性等特性决定,近年来,为获取良好表现的超像素,不少超像素算法被提出,根据其原理的不同可以概括为基于聚类、基于图和基于深度学习3类超像素算法.基于聚类的超像素算法使用不同的聚类算法对图像中的像素点进行聚类,如简单线性迭代聚类SLIC(Simple Linear Iterative Clustering)[13]使用K-means聚类对像素空间和颜色信息的五维特征表示(XYlab特征)进行迭代聚类,因其简单有效而被广泛使用,但迭代过程中SLIC初始保留的一些边缘可能会丢失,这也是迭代聚类方法常见的缺点.线性谱聚类LSC(Linear Spectral Clustering)[14]算法将像素特征表示映射到十维特征空间再使用K-means聚类,可以有效捕获全局图像属性,但其分割性能仍有提升的空间.简单非线性迭代聚类SNIC(Simple Non-Iterative Clustering)[15]在SLIC基础上改进为不需迭代计算聚类中心点.Peng等人[16]使用高阶能量函数来表达和优化K-means聚类得到的超像素的表示,Liu等人[17]提出了流形简单线性迭代MSLIC,将像素的五维特征映射成二维流形特征,可以获得语义敏感的超像素,相较SLIC略微提升了分割质量.除了使用K-means聚类,其他聚类方法也被广泛应用于超像素的生成之中,Shen等人[18]使用DBSCAN聚类方法仅根据像素的颜色特征生成较为规则超像素,然而边缘贴合性能表现不佳.能量驱动采样SEEDS(Superpixels extracted via energy-driven sampling)[19]通过优化边缘项和颜色项组成的目标能量函数来动态地使初始区域的边缘不断逼近图像边缘,以生成超像素,其能量函数需经过多次的的优化迭代.Zhang等人提出了密度峰值聚类超像素聚类DPCS(Density Peaks Clustering Superpixel)[20],通过计算样本点的密度,距离和决策值来自动发现聚类中心,实现对像素的高效聚类,然而没有挖掘像素信息的深层联系和聚类时的颜色与空间信息的比重,且生成的超像素不能保证一致性与连通性.
基于图的算法将分割图像视为以像素为节点、以像素邻接关系为边的图结构,使用图算法为节点进行分类,如规一化切割算法NC(Normalized Cuts)[21]使用纹理和边缘信息构成能量函数,通过最小化全局能量函数生成形状规则的超像素,然而其时间复杂度为O(N3/2).懒惰随机游走算法LRW(Lazy Random Walks)[22]迭代地计算随机游走到已标记像素的最大可能性,自适应地调整种子点的位置,熵率算法ERS(Entropy Rate Superpixel)[23]基于随机游走的熵率来最大化目标函数,以连接子图生成边缘贴合良好的超像素.伪布尔优化算法PB(pseudo-boolean optimization)[24]通过去边算法实现图划分生成超像素,其时间复杂度为O(N),其速度可达到实时性要求,但生成的超像素边缘贴合度也相对较低.通常基于图的超像素算法的时间复杂度都比较高.
基于深度学习的算法使用卷积神经网络来预测像素的分类以生成超像素,如超像素采样网络SSN(Superpixel Sampling Networks)[25]先使用卷积神经网络CNN提取像素特征,根据目标超像素数目生成初始超像素网格,再通过可微SLIC迭代预测每个像素属于周围超像素9邻域区域的概率作为关联图,可以端到端地训练整个网络,生成超像素.然而,为了达到更高的精度,SSN在训练网络的过程中,需要使用图像的边缘监督信息.像素嵌入网络SEN(Superpixel Embedding Network)[26]通过U型深度自编码器提取像素特征,并在特征空间进行Mean-Shift聚类来生成超像素,和SSN一样,SEN同样要使用有监督信息的图片进行模型训练.这类超像素算法需要长时间的训练迭代且对不同类别图片集不具有广泛适用性.
目前的超像素算法或存在边缘叠合度尚可但时间复杂度过高、或存在时间性能优异但边缘贴合度较低的问题.为了快速、高效地生成高质量的超像素,更好地提取图像的局部边缘特征,受密度峰值聚类DPC[27]和LSC[14]算法启发,本文提出一种基于局部最近邻密度和颜色特征加权的超像素生成算法NDPCS(Nearest-neighbor Density Peak and Color Feature Weighting to Generate Superpixel).NDPCS基于密度峰值聚类,无需迭代就可生成具有较高边缘召回率及可达分割精度的超像素.
2 基于最近邻密度和颜色加权的超像素算法
2.1 基于最近邻的像素点局部密度
密度峰值搜索聚类DPC[27]是近年提出的聚类方法,其主要思想是寻找被低密度区域分离的高密度区域.DPC基于以下两个假设:1)聚类中心点的密度大于周围邻居点的密度;2)聚类中心点的密度与其他聚类中心点的距离较大.故DPC需要计算样本点i的密度ρi和距离δi,密度为到其他样本点距离小于截断距离的点的个数:
(1)
其中:
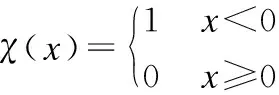
(2)
(3)
dij为样本点xi和xj的欧式距离,D为样本点的维数,dT为设定的截断距离.密度ρi反映了样本点在dT邻域内的邻居个数.距离δi为样本点到周围大密度点的最小距离:
(4)
DPC[27]以具有较大决策值的样本点为聚类中心,并将其余样本点分配到它的最近邻且密度比其大的样本点所在的簇,完成聚类.密度峰值聚类可以很好地适应复杂形状的样本数据,无需迭代地完成聚类,但聚类结果受截断距离的影响较大,且需要计算所有样本点两两之间的距离,计算开销较大,时间复杂度较高.
对于输入的彩色图像I,每一个像素点的特征可以表示为一个5维向量pi=[li,ai,bi,xi,yi]T,其中li,ai,bi为像素点的颜色特征,分别表示亮度、绿红通道和蓝黄通道,xi,yi像素点的横坐标和纵坐标.基于密度峰值搜索聚类的超像素分割算法DPCS[20]就是使用密度峰值聚类对像素的五维特征进行简单聚类.通常,像素点的局部密度反应图像中像素点周围相近像素的聚集程度.一般聚类数据集中,密集区域点的密度要大于稀疏区域点的密度,而密集区域中点到邻居点的距离和要小于稀疏区域中点到邻居点的距离和.但图像中像素点是规则均匀排列的,像素点除了位置信息,还有颜色等特征.DPCS[20]算法指出在以像素点为中心的圆形区域内,根据特征距离定义的像素点局部密度能反映圆形区域中所有像素在该像素周围的聚集程度,即周围聚集的相似像素越多则该像素点密度越大,反之则密度越小,然而DPCS[20]没有考虑不同类别的邻居数目对其局部密度的影响.
Wang等人[28]对密度峰值聚类的研究发现,使用邻域部分样本点计算密度可以改善聚类结果.为提取图像的局部边缘特征并减少计算复杂度,本文方法NDPCS采用基于局部最近邻的密度,即使用像素点邻域内的最近邻居而非邻域内的所有邻居来计算像素的局部密度,从而可以更好地感知图像边缘信息,并在像素聚类时提高边缘贴合度.因此,定义最近邻的像素点pi的局部密度ρi为:
(5)
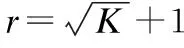
dij=dc(pi,pj)+ds(pi,pj)
(6)
(7)
(8)
式(6)中dc(pi,pj)为像素pi和pj之间颜色分量的相似度,ds(pi,pj)为像素pi和pj之间空间距离.显然,像素点之间的距离dij越小,两像素点的颜色和空间信息越接近,即相似度越大.基于最近邻的像素局部密度(见式(5))与像素点到周围最近邻居点的距离和成反比,距离和越小,则代表其周围同质像素越多,即其局部密度越大.
为了提高超像素分割性能,以便更好地发现图像的边缘细节,避免将图像中细长形状的物体边缘合并到颜色不相似的区域,受LSC[14]算法启发,可以将像素的5维特征表示映射到10维:
pi=[l1i,l2i,a1i,a2i,b1i,b2i,x1i,x2i,y1i,y2i]T
(9)
其映射函数为:
(11)
其中Cs/Cc=0.075为控制超像素紧致度的默认参数.
10维特征表示的像素pi到周围最近邻点pj的颜色距离dc和空间距离ds为:
dc(pi,pj)=
(12)
(13)
和5维特征空间相比,图像中距离较远的相似像素在10维特征空间中距离更近.3.3节对使用不同维度特征进行超像素分割的结果进行了分析对比.
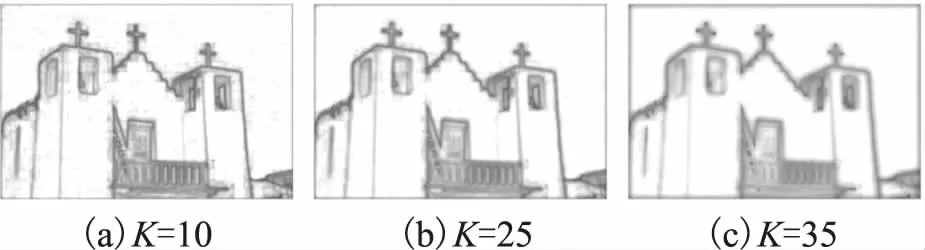
图1 不同最近邻个数时的密度热力图Fig.1 Density heat map with different number of nearest neighbors
使用K近邻的密度峰值算法可以更好地适应聚类中的复杂形状.但对于图像中纹理简单、颜色一致的区域,可能会出现多个等值的局部密度最大值点.最近邻数量K的取值大小会影响局部密度最大值点的数量以及密度对图像边缘的检测能力.图1为在尺寸为321×481图片上取不同K值的密度热力图,随着K值的增大,密度对于目标边界的边缘检测能力逐渐减弱.
2.2 像素点距离计算
计算像素点pi的距离δi,即为pi寻找最近的大密度像素点,根据其密度是否为局部极值而采用不同的距离计算策略.对于非局部密度最大值点pi,其距离为到邻域内最近的大密度像素点的距离:
(14)
Nr为计算距离时的邻域像素点集合.
若pi为局部密度最大值点,则其大密度点也是局部密度最大值点,因此其距离为:
(15)
NL为所有局部密度最大值的像素点集合.
由于图像中像素在平面空间中是紧密排列的,且图像中尤其是纹理较简单的自然图像中往往存在大范围颜色相近区域(如天空之类的背景部分),这可能导致很多图像上相邻或距离相近的像素点同为局部密度最大值点.如果一个像素点为局部密度最大值点,则按照密度峰值聚类的距离计算方法,应当距离其他局部密度最大值点的距离更远.因此,局部密度最大值点的距离δi为到最近的拥有相等或较大密度的其他局部密度最大值点的距离.
对图像的所有像素点的决策值分布进行分析可得,拥有局部最大密度的点往往拥有较大决策值λi=ρiδi,少数几个非局部密度最大值点也拥有稍大的决策值,但其个数过少,对分割结果的影响可以忽略不计,因此只计算这些局部密度最大值点的距离是合理的,在不损失分割精度的情况下,NDPCS选择仅计算局部密度最大值点的距离,并以此计算决策值,从中挑选出聚类中心.
2.3 基于决策值和颜色特征加权的初始超像素生成
根据局部密度最大值点的密度ρi和距离δi,以决策值λi=ρiδi为参考可以生成初始的超像素.根据2.2节的分析,NDPCS仅从局部密度最大值点中选择聚类中心,具体为将图中局部密度最大值点的决策值进行排序,选取其中的前k个作为聚类中心Clu={c1,c2,...,ck},并将其对应的标签记为label={1,2,…,k}.
不同于密度峰值聚类的按簇搜索归类,考虑到图像边缘和像素空间分布,为了更好地使不同类别标签的像素贴近物体的真实边缘,NDPCS为每个非聚类中心像素i寻找距离最近的聚类中心点ci,具体为计算每个聚类中心和其周围邻域内每个像素的距离,将像素点的类别标签指派为最近聚类中心的类别标签,生成初始超像素:
(16)
其中d(i,ci)为像素点i到聚类中心点ci的距离:
d(i,ci)=α×dc(i,ci)+(1-α)ds(i,ci)
(17)
其中α∈(0,1)为颜色分量权重.使用颜色特征加权的距离来计算像素点同聚类中心点的距离,可以更好地捕获图像的语义边缘.相比不带加权的距离计算,给予颜色特征更高的权重,可以生成边缘贴合度更好的超像素,更能适应复杂的形状,保留图像中孤立的细节.
1https://github.com/davidstutz/superpixel-benchmark/
2.4 非连通区域的启发式合并
对非聚类中心的像素点进行类别指派后,因为像素聚类的特性,会出现超像素不连通的情况,即具有同一标签的像素空间上不在同一个连通域中;此外,因为图像中噪声点和噪声区域的存在,可能生成区域过小的超像素,而通常希望一个超像素不应过小,超像素内部是颜色相似度高且像素是连通的.
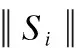
d(Si,Sj)=α×dc(u,v)+(1-α)×ds(u,v)
(18)
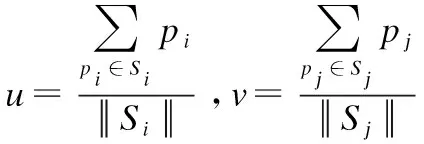
图2展示了合并前后的超像素.由图2可知,以基于颜色特征加权的合并方式,将过小的超像素子域归并到与其最相似的邻域超像素中,从而可以将在聚类过程中因为距离限制造成的同一语义部分割裂开的区域进行合并,保证了超像素之间的像素连通性,并且尽可能保留了物体的边缘.
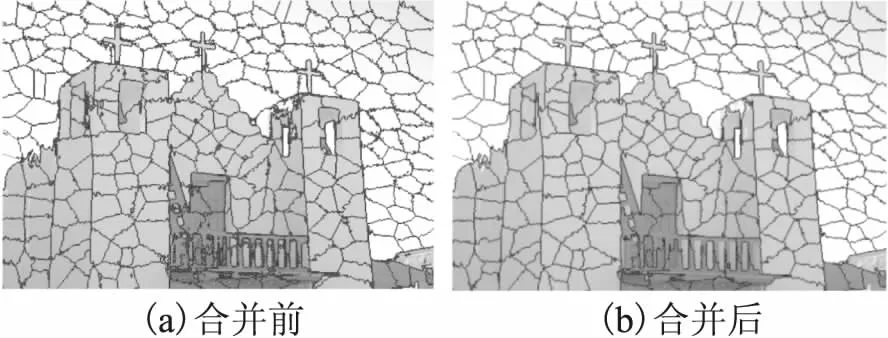
图2 超像素的合并Fig.2 Superpixel merging
2.5 算法复杂度分析
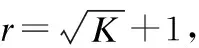
综上,NDPCS算法总的时间复杂度为O(((2r-1)2+k)N+m2),其中m2和N约为一个数量级,而r和k远小于N,因此,NDPCS算法的时间复杂度可以简化为O(N).NDPCS算法在计算过程中只需存储大小为N的局部密度、m个局部密度最大值点的距离和决策值以及k个超像素的最大距离和N个像素的标签,因此其空间复杂度为O(N).
3 实验与结果分析
3.1 数据集及实验环境
实验以Berkeley数据集BSDS500[29]为验证数据集,BSDS500包含500张尺寸为321×481或481×321的自然图片,每张图片由至少5个不同的标注人员进行自然物体边缘的标注.
所有算法均运行在CPU为Intel Corei7-8700(3.2GHz)、RAM为16G的计算机上,其中DPCS[20]由于没有公开的源代码,采用的是C++复现的版本,SLIC[13]、LSC[14]、ERS[23]和PB[24]使用David等[30]关于超像素的研究综述中提供的代码1,David 等以C++实现了部分超像素的算法并提供了调用接口,SEEDS[19]算法使用OpenCV的实现版本,该版本在不改变分割精度的情况下,运行时间更短,所有算法参数均使用原文中最优表现的参数,且没有特别设计的GPU加速计算与并行计算.
3.2 超像素结果对比
图3展示了NDPCS算法和其他6种算法(SLIC[13]、LSC[14]、SEEDS[19]、ERS[23]、PB[24]和DPCS[20])超像素数目分别为300和800时在部分数据集上的可视化分割结果,其中每张图左侧为原图分割结果,右侧为局部区域的细节放大图,“NDPCS_5d”指NDPCS在5维特征空间中的超像素结果,“NDPCS_10d”指NDPCS在10维特征空间中的超像素结果.
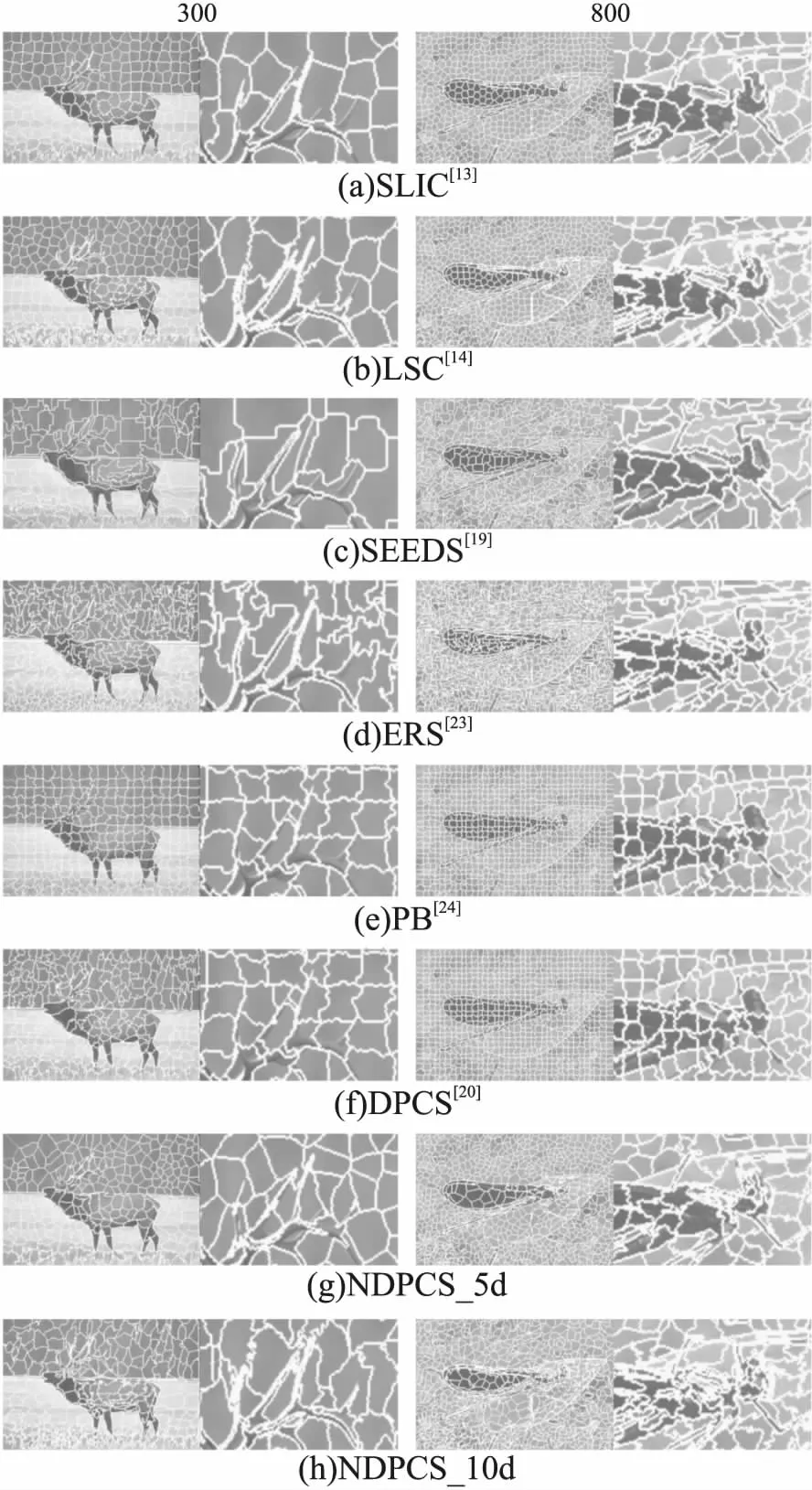
图3 不同超像素算法在部分图片上的分割结果Fig.3 Segmentation results of different superpixel algorithms
从图3中可以看出,SLIC[13]、LSC[14]以及PB[24]生成的超像素大小比较均匀,这是因为SLIC和LSC都以均匀步长初始化超像素种子.其余算法均为在全局像素中或挑选聚类中心,或调整初始边缘,无法保证超像素的在图像坐标空间上的均匀性.通过比较细节发现,同样使用5维CIELab信息进行聚类,相较于使用K-means聚类的SLIC,使用密度峰值聚类的DPCS[20]和NDPCS_5d生成的超像素明显可以更好地好贴合物体边缘.而同样使用10维特征信息聚类,相较于LSC[14],NDPCS_10d生成的超像素对物体边缘尤其是细长形状的边缘更加敏感,更贴合自然认知.
3.3 性能比对分析
本文采用边缘召回率BR(Boundary Recall)[30]、欠分割误差UE(Under-segmentation Error)[13]和可达分割精度ASA(Achievable Segmentation Accuracy)[19]这3个反映边缘贴合能力的指标,以及反映超像素内部像素同一性的内部聚类差异ICV(Intra-Cluster Variation)[30]来对超像素分割结果进行评价.
边缘召回率BR是超像素分割最常用的指标之一,描述了超像素边缘S落在真实边缘G的能力,BR越大,则分割出的超像素边界与实际的真值标注边界越接近:
(19)
其中TP(S,G)为与超像素边缘S距离不大于ε的真实边缘G的像素个数,FN(S,G)为与超像素边缘S距离大于ε的真实边缘G的像素个数.
欠分割误差UE是测量超像素与自然物体超出重叠的标准.一个好的超像素算法分割出的超像素,应当尽可能少地“跨越”真值标签中不同的区域,并鼓励超像素更多地与自然物体重叠并减少非重叠部分.假设超像素分割的结果为S={s1,s2,…,sk},图片的真值标签为G={g1,g2,...,gl},则欠分割误差UE可以表示为:
(20)
可达分割精度ASA量化了超像素分割作为计算机视觉的预处理步骤,可以在后续任务(例如图像分割)中能够达到的最大精度,是超像素中可用于分割的部分与总像素的比值,其公式见式(21).在以超像素为基础的下游任务中,希望超像素分割对下游任务的影响尽可能小,即希望可达分割精度较高.
(21)
内部聚类差异ICV反映了超像素内部像素点和超像素整体的差异.该指标不依赖于真值标签,可以由超像素分割结果和原图片计算得到.
(22)
其中I(xn)为超像素Sj内单个像素的颜色,μ(Sj)为Sj的平均颜色.ICV越低,表示超像素内部像素颜色越趋近于统一,即超像素分割质量越高.
由于聚类生成超像素存在一定程度的不连通性,SLIC、LSC和NDPCS均需要通过超像素合并来保证每个超像素的像素彼此连通,故这几种方法不能确定最终超像素的数目,合并后实际的超像素数目相比预期设定的数目有轻微波动,例如设定超像素数目300,实际生成300±30个超像素,实验表明,合并造成的超像素数目误差值不影响算法之间的性能和精度对比.
图4展示了NDPCS和6种流行算法的性能对比.NDPCS算法设置参数K=10、α=0.7.如图4所示,NDPCS优于在3个评价指标上SLIC[13]、LSC[14]、ERS[23]、DPCS[20]、PB[24]等算法,这得益于最近邻密度对边缘检测的贡献、聚类时利用决策值对密度的选取.随着超像素数目的增加,NDPCS在边缘召回率上的指标仍保持领先,说明在使用相同数据的情况下使用局部最近邻密度和颜色加权聚类的NDPCS可以提升像素聚类结果的性能,尤其是可以提高图像中物体边缘的检测和感知能力.在反映超像素内部颜色差异性的指标ICV上,10维特征表示的NDPCS算法在超像素数目大于200时低于所对比算法,这是由于合并时超像素之间的颜色特征加权的相似度对合并的指导作用,给予颜色更大的权重有利于将相似颜色的像素聚为一类.
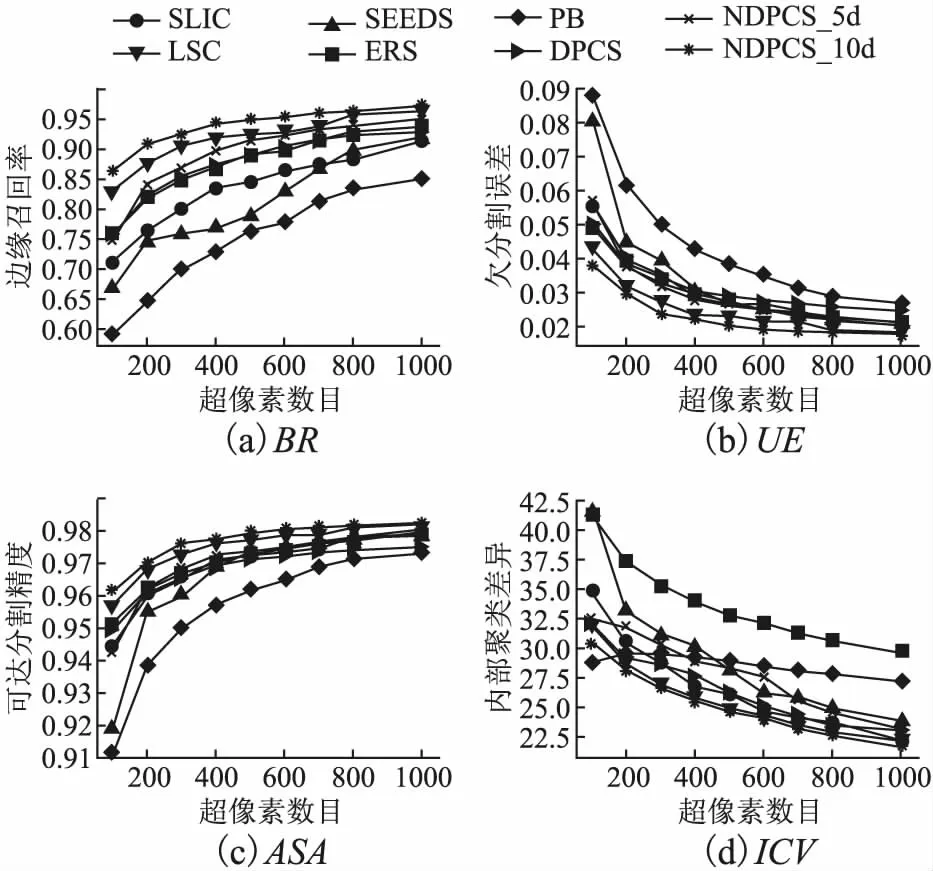
图4 不同超像素算法在BSDS500上的性能表现Fig.4 Performance of different superpixel algorithms on BSDS500
3.4 参数选择分析
对于NDPCS算法,分别以CIELAB颜色空间的5维向量和映射到谱空间中的10维向量来表示像素特征,并选择最近邻居个数K和颜色分量权重α的不同取值来分析对超像素生成结果的影响.
图5为超像素数目为300时,不同参数对边缘召回率的影响.从图5可以得出,NDPCS在最近邻居个数K=10时,边缘召回率取得最大值,随着K的增加,边缘召回率变化较小,这是因为K过小不足以反应像素点的聚集程度,而K过大则会弱化密度对边缘的检测能力,实验中取K=10.另外随着颜色分量权重α的变大,NDPCS在5维和10维空间分割的准确度都有显著提升,这是由于α越大,聚类时越无视空间信息,生成的超像素边缘越贴合真实图像的边缘,但会导致超像素的形状不规整,在未合并时孤立的超像素数目变多,增加算法时间消耗,为平衡时间与精度,实验中取α=0.7.
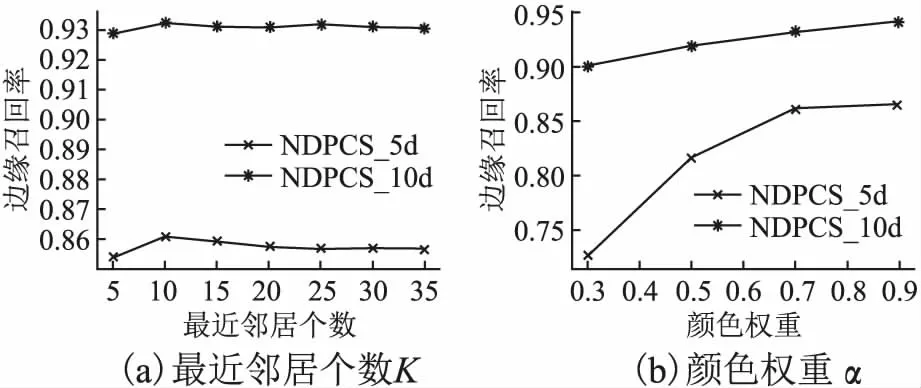
图5 不同参数下的边缘召回率Fig.5 Boundary recall under different parameters
3.5 时间性能分析
表1对7种不同的超像素算法的时间复杂度进行了比较,其中n为算法迭代次数,N为分割图像中的总像素数.其中基于聚类的算法SLIC[13]、LSC[14]、PB[24]、DPCS[20]和NDPCS的时间复杂度都为O(N),而基于图的算法ERS[23]时间复杂度要高出许多,这是因为ERS[23]将每个像素视为一个节点,且要计算任意两两像素间的距离,而SEEDS[19]算法由于颜色直方图的划分可以调整,尚无理论的时间复杂度.

表1 各算法时间复杂度Table 1 Time complexity of each algorithm
图6展示了各算法在不同尺度图像下的运行时间,其中ERS随着图像大小增加时间急速上升,这是因为ERS[23]是基于图论的算法,考虑每两个节点之间的距离,故其运行时间受图像尺寸影响较大;SLIC[13]算法因为简单的合并策略,比同样使用K-means算法的LSC[14]要快;DPCS[20]算法较NDPCS算法快,这是因为其计算距离时就已计算好像素点的归类.NDPCS与LSC[14]时长相当,因为在找到聚类中心后其归类与合并的复杂度相同,这里的LSC[14]是使用同NDPCS相同的合并策略,故较原论文时间稍有增加,但同时也增加了边缘召回率等精度.PB[24]采用去边算法实现图划分,在图像尺寸较小时近乎可以实时分割.从图6和图4可以看出,对比以上几种流行的非深度学习方法,NDPCS在牺牲较少时间性能的情况下,取得了最优的超像素分割结果.
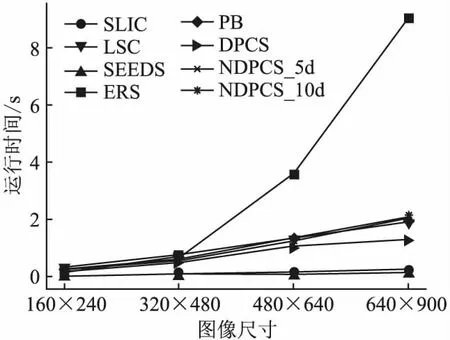
图6 各算法运行时间Fig.6 Running time of each algorithm
4 结 论
本文提出的基于局部最近邻密度和颜色特征加权的超像素生成算法NDPCS可以更好地提取图像的局部边缘特征.NDPCS首先在像素点的邻域范围内用最近邻居像素计算其局部密度,其次根据局部密度计算局部密度最大值点的决策值大小选择期望数目的像素作为超像素的种子,并且为每个像素以颜色特征加权的距离最小为依据寻找聚类中心,最后通过超像素大小和颜色特征加权相似度相结合的启发式策略合并孤立和过小超像素以保证超像素的连通性,实现超像素分割.NDPCS与6种经典或最新的超像素分割算法进行了对比实验,实验结果表明NDPCS在边缘召回率、欠分割误差和可达分割精度上优于其它大多算法,运算速度较快,在存储复杂性方面也有一定优势.但NDPCS同其他聚类方法一样,不能精确生成超像素的数目,因此如何在不损失精度的情况下选择新的合并策略以确保超像素的数目,以及如何使用并行计算来进一步提高算法的运行时间,是后续有待进一步研究的问题.
