邻域欠采样的AdaBoostv算法
2023-01-31张振莲鲁淑霞翟俊海
张振莲,鲁淑霞,2,翟俊海,2
1(河北大学 数学与信息科学学院,河北 保定 071002) 2(河北大学 河北省机器学习与计算智能重点实验室,河北 保定 071002)
1 引 言
类别非平衡是机器学习领域一个非常活跃的研究领域.处理类别非平衡的方法主要可分为两类:数据级方法和算法级方法.在算法层面上,通过创建新的学习算法或修改现有算法来解决这个问题.算法级解决方案的优点是直接将用户的偏好合并到模型中[1].然而,学习算法需要预先确定,一旦实现就不能改变.我们重点集中在数据级解决方案上.
数据层面上最常用的方法有欠采样[2]、过采样[3],欠采样方法可能会删除一些有用的数据,而过采样方法有可能会引起数据的过度拟合.现有文献表明,类重叠[4]对学习算法的性能有很高的负面影响.基于类重叠的方法主要解决非平衡数据分类中的类重叠问题.处理类重叠的方法主要有整个重叠区域的方法、边界附近重叠样例的方法.采用的技术主要有:聚类、近邻搜素、噪声去除、集成、区域分割等.
基于重叠的欠采样(OBU)[5]是处理整个重叠区域的方法,该方法旨在通过消除重叠区域中的所有多数类样例来最大化少数类实例的可见性,出现了过多的消除;DBMUTE[6]是另一种基于重叠的欠采样方法,即消除少数类子聚类附近的多数类样例,强调类重叠问题的变异能获得更好的分类结果;自适应合成采样(ADASYN)[7],通过在重叠区域选择性地过采样来增强少数类的存在,缺点是与多数类实例高度重叠的稀疏少数类样例被排除在过采样之外.
为了降低信息丢失的风险,一些方法只关注位于决策边界附近的重叠样例.文献[8]中提出了一种基于邻域的欠采样框架,旨在从重叠区域中准确地移除有问题的多数类样例,以防止过度消除,同时增强少数类的存在;编辑最近邻(ENN)[9]关注于决策边界附近的实例,通过考虑属于另一个类的k个最近邻来选择性地删除多数类样例;梁等人[10]提出了LR-SMOTE算法,使新生成的样本更接近样本中心,错误分类的正类样本的负最近邻被全部去除;SMOTE-IPF[11]是为了消除原始数据中的噪声样例以及SMOTE生成的噪声样例而提出的,通过在SMOTE之后应用噪声滤波器来实现;在文献[12]中,以最小化信息损失为目标,只删除了相似度高、对分类贡献小的多数类样例.研究处理非平衡数据集中的类重叠,可以有效地提高学习算法的性能.
为了解决非平衡数据分类问题,我们提出邻域欠采样AdaBoostv算法.主要贡献如下:
1)针对两类非平衡数据的类重叠问题,引入了两种基于邻域的欠采样方法,用于消除重叠区域中的负类样本;将基于邻域的欠采样方法应用到AdaBoostv算法中,提高分类器的分类能力.
2)为了解决非平衡数据分类问题,AdaBoostv算法的基分类器采用加权最优间隔分布机模型,并对模型中的间隔均值项和铰链损失项加权,权值是依据数据的非平衡比给出的,并利用带有方差减小的随机梯度下降方法(SVRG)[13]对加权最优间隔分布机模型进行求解,以提高算法的收敛速度.
2 相关工作
2.1 加权最优间隔分布机
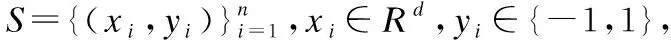
(1)
其中,负类样本的权重为Bi=(n+/n-)p,正类样本的权重为Bi=(n-/n+)p,p为(0,1]的常数.λ1,λ2为折中参数.
对于非线性可分问题,将数据通过非线性变换φ(x)映射到高维特征空间,再据表示定理[16],得到对应的非线性加权最优间隔分布机模型为:
(2)
其中,X=[φ(x1),φ(x2),…,φ(xn)],α=[α1,α2,…,αn]T,G=[G1,G2,…,Gn]=XTX.
利用带有方差减小的随机梯度下降方法对加权最优间隔分布机模型和非线性加权最优间隔分布机模型进行求解.
2.2 AdaBoostv算法
AdaBoostv算法[17]是提升算法AdaBoost的改进版本,它最大化样例的最小间隔达到给定的精度.该算法在计算基分类器的线性组合系数时,将可达到间隔的当前估计纳入其中.AdaBoostv算法所需要的迭代次数的上限与AdaBoost所需要的次数相同,AdaBoost必须有可达到间隔的显式估计作为参数.AdaBoostv算法据基分类器的误差率来更新样例权重,样例权重更新公式为:
(3)
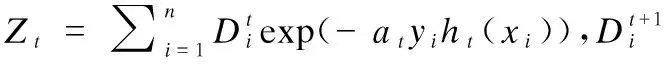
AdaBoostv算法通过最小化Zt获得基分类器的权重at,
(4)
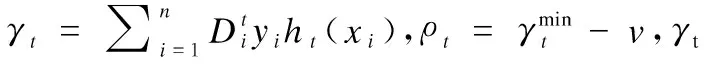
样例xi的间隔为:
(5)
由公式(5)可知,样例间隔的取值范围为连续区间[-1,1].
最优间隔为:
(6)
其中H为基分类器集合,H={h|h:x→[-1,1]}.
AdaBoostv算法的最终分类器为:
(7)
3 邻域欠采样的AdaBoostv算法
当多个类的样例共享数据空间中的一个公共区域时,就会发生类重叠.虽然这些样例属于不同的类别,但它们有相似的特征,这是分类任务的一个重大障碍.当数据中也存在类非平衡时,类重叠问题变得更加严重.在一个非平衡和重叠的数据集中,多数类是重叠区域中的主导类,决策边界会向少数类偏移,那么类边界附近的少数类样例就会被错误分类,这在现实世界的问题中是不希望的.
我们引入两种基于邻域的欠采样方法[8],通过欠采样类重叠区域的多数类样本可使原本模糊的决策边界更加清晰,有利于提高整体分类性能.
3.1 共同近邻搜索
共同近邻搜索删除正类样例的共同负近邻,任何两个正查询的共同负最近邻被识别为潜在的重叠样例并被删除.该方法的性能依赖于数据密度,当少数类的密度远低于多数类的密度时,只有很少的共同负近邻样例.共同近邻搜索算法使用k近邻来探索每个样本的局部环境,k按照下面的经验公式给出:
(8)
其中IR=n-/n+为非平衡比,n-和n+分别为负类和正类样例个数.
算法1.共同近邻搜索欠采样(COM)
输入:训练集S,k
输出:欠采样后的训练集S0
1.begin
2.S←训练集;
3.Spos←S中的正类样例;
1http://www.keel.es/
4.A←频率表;
5.foreachx∈Sposdo
6.NN←k近邻;
7.NNneg←NN中的负类样例;
8.foreachy∈NNnegdo
9.Ay.freq←Ay.freq+1;-
10.foreachx∈A.instancedo
11.ifAx.freq>1then
12.X←X∪{x};
13.S0←S-X;
14.return{S0}
3.2 递归搜索
递归搜索是共同近邻搜索的扩展,以确保足够和准确地消除重叠的负类样例.设X为共同近邻搜索中将要删除的重叠的负类样例集合,递归搜索则删除X中任意两个负类查询的共同负近邻样例,以及X中的所有元素.因此,递归搜索将会检测到更多的重叠负类样例.
算法2.递归搜索欠采样(REC)
输入:训练集S,k,X为算法1中的集合
输出:欠采样后的训练集S0
1.begin
2.S←训练集;
3.A←频率表;
4.foreachx1∈Xdo
5.NN2←k近邻;
6.NN2neg←NN2中的负类样例;
7.foreachy∈NN2negdo
9.foreachx2∈A′.instancedo
10.ifA′x2.freq>1then
11.X2←X2∪{x2};
12.S0←S-(X∪X2);
13.return{S0}
3.3 邻域欠采样的AdaBoostv算法
首先,基于共同近邻搜索欠采样(COM)和递归搜索欠采样(REC)对训练数据集S进行欠采样,用于消除类重叠区域中的负类样例;然后,针对欠采样后获得的数据集S0,应用AdaBoostv算法,AdaBoostv算法的基分类器采用加权最优间隔分布机模型,利用SVRG方法对加权最优间隔分布机模型进行求解.以更好地处理非平衡数据的分类问题.
算法3.邻域欠采样的AdaBoostv算法.
输入:训练集S,折中参数λ1、λ2,迭代次数T,所需精度v
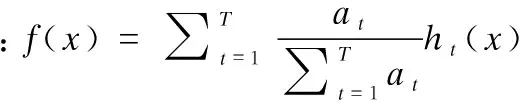
1.基于COM、REC对训练数据集S进行欠采样,采样后的训练集记为S0
3.fort=1,…,T
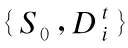
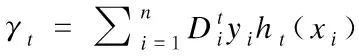
6. 若|γt|=1,则at=sign(γt),h1=ht,T=1;停止
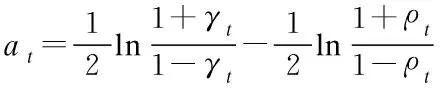
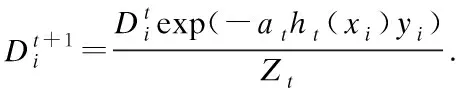
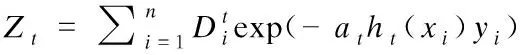
10.end for
4 实 验
给出所提算法和对比算法的实验结果,实验结果均采用五折交叉验证的平均值.编程语言采用Matlab,版本为MatlabR2017b,实验除Avila数据集[18]和bank数据集[19]外,其它数据集均来自KEEL1,数据集信息如表1所示.
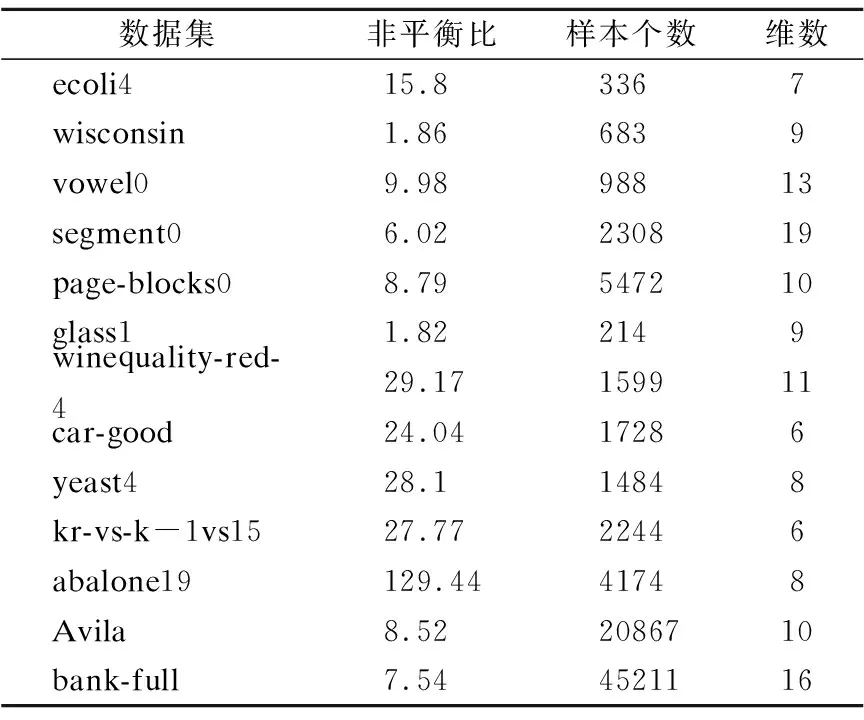
表1 非平衡数据集Table 1 Imbalanced datasets
4.1 处理类重叠的重要性实验
为了说明非平衡数据分类中删除类重叠区域中负类样本的重要性,在人工数据集上进行了以下实验.首先,生成服从高斯分布的二维人工数据集,该数据集中正类样本个数为100,负类样本个数为500.首先给出人工数据集中高斯分布的参数设置如表2所示.
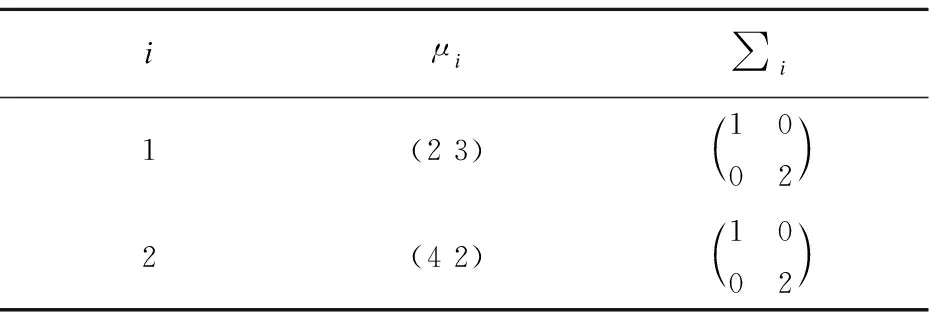
表2 两个高斯分布的人工数据集Table 2 Two artificial datasets with Gaussian distribution
其次,给出生成的原始数据分布图、COM欠采样后的数据分布图以及REC欠采样后的数据分布图,如图1、图2、图3所示(“+”号为正类样本,“*”号为负类样本).
从图1、图2、图3中可以看出,通过欠采样类重叠区域的多数类样本可使原本模糊的决策边界更加清晰,最大化正类样本的可见性,更有利于整体分类性能的提高.
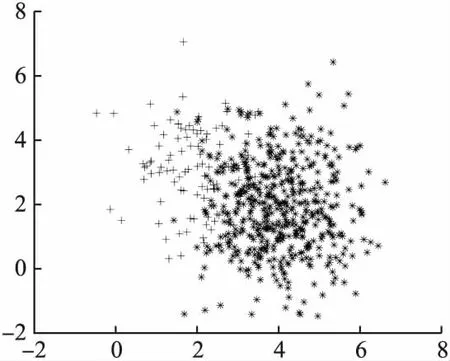
图1 原始数据分布Fig.1 Original data distribution
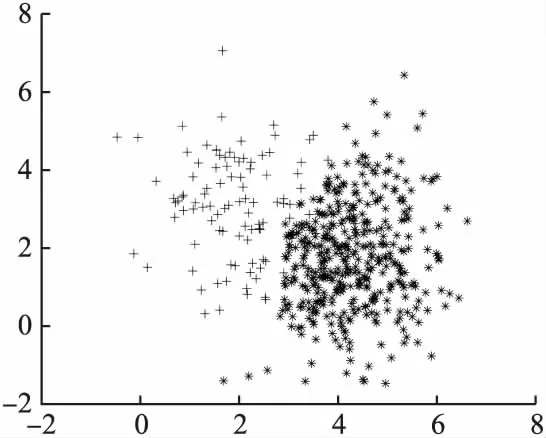
图2 COM欠采样数据分布Fig.2 COM undersampling data distribution
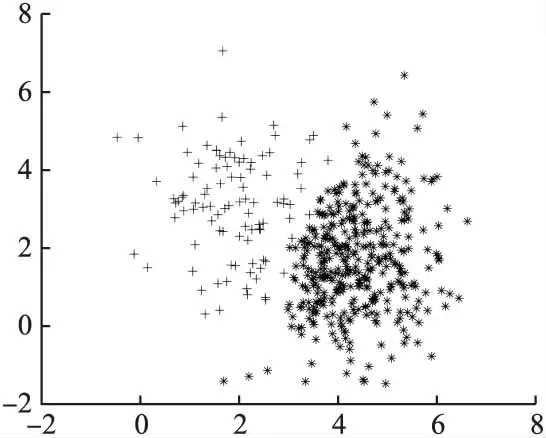
图3 REC欠采样数据分布Fig.3 REC undersampling data distribution
最后,给出原始的AdaBoostv算法与提出的基于欠采样的AdaBoostv算法在人工数据集上的几何均值和召回率对比实验,结果如表3所示.
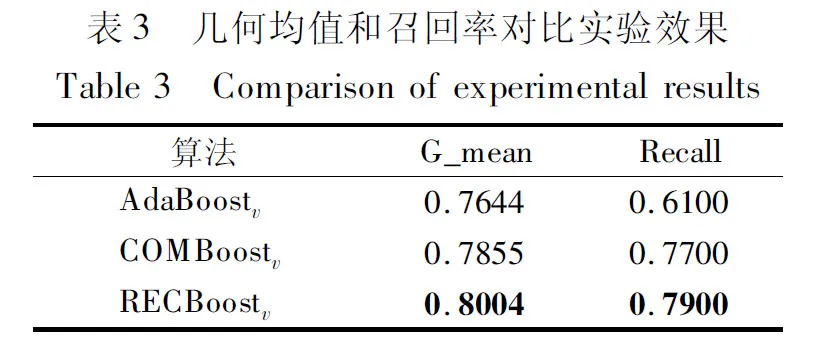
从表3中可以看出,提出的两种算法在几何均值和召回率上优于原始的AdaBoostv算法,并且RECBoostv算法在人工数据集上的分类能力优于COMBoostv算法.
4.2 参数设置
观察表4、表5可知,改进SVM优化模型中的权重参数p在大多数数据集上的值都为0.5,v值在所有数据集上都取为0.02,由此可知,v值不宜取得过大.观察λ1和λ2,虽然二者取值有差异,但差异不宜过大.在非线性算法中,高斯核参数σ的取值会根据不同的数据集取不同的参数值,但亦不宜过大,否则会影响到分类精度,我们需要对参数值进行适当地调整.
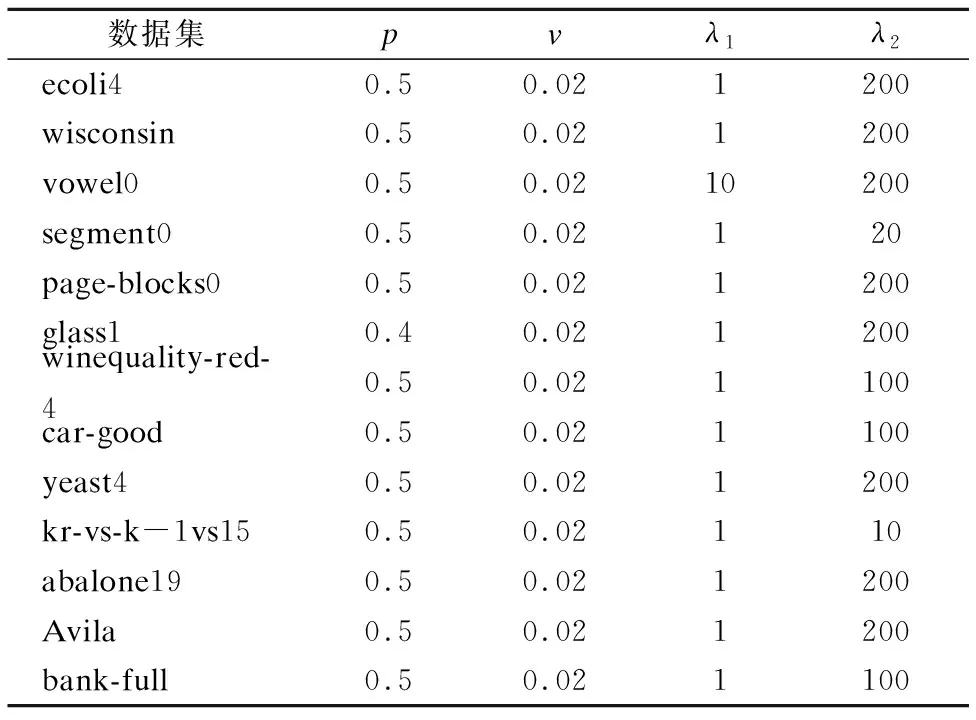
表4 线性算法在不同数据集上的参数Table 4 Parameters of the linear algorithm on different data sets
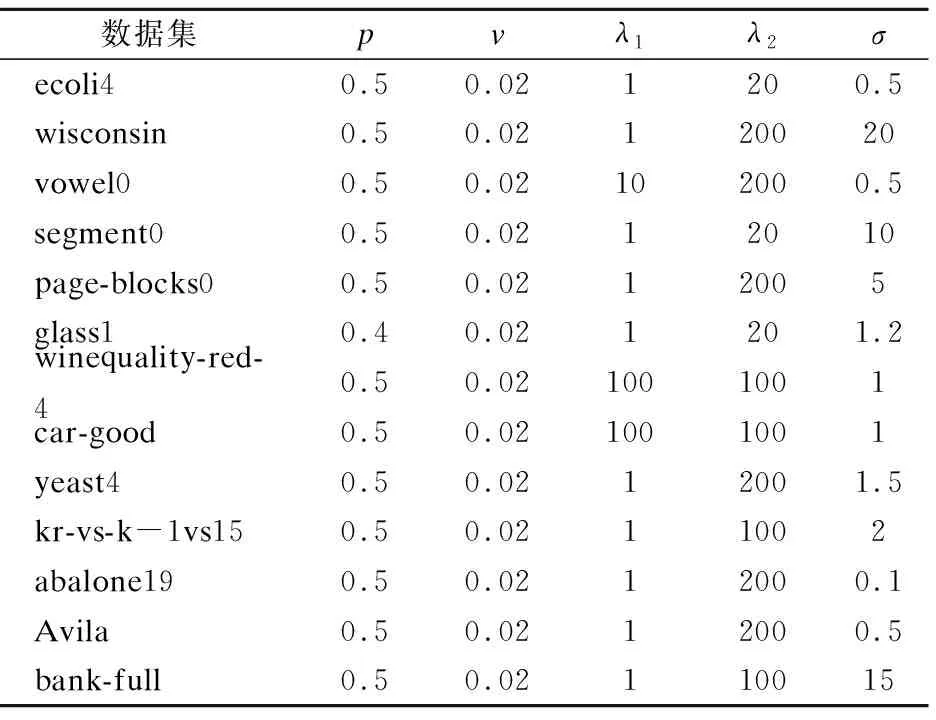
表5 非线性算法在不同数据集上的参数Table 5 Parameters of the nonlinear algorithm
4.3 几何均值和召回率对比实验
首先给出对比算法的描述,对比算法分别为AdaBoost算法和随机欠采样AdaBoost算法(RUSBoost)[20].AdaBoost算法采用改进的SVM模型,RUSBoost采用标准SVM模型.两种算法都采用SVRG方法.
线性算法与非线性算法的几何均值测试结果如表6、表7所示.
观察表6、表7,可以发现提出的两种欠采样集成算法的几何均值明显优于其它算法,而对于不同的数据集,两种欠采样集成方法的几何均值各有优劣,这是由于不同数据集的两类样本的数据密度高低不同造成的.
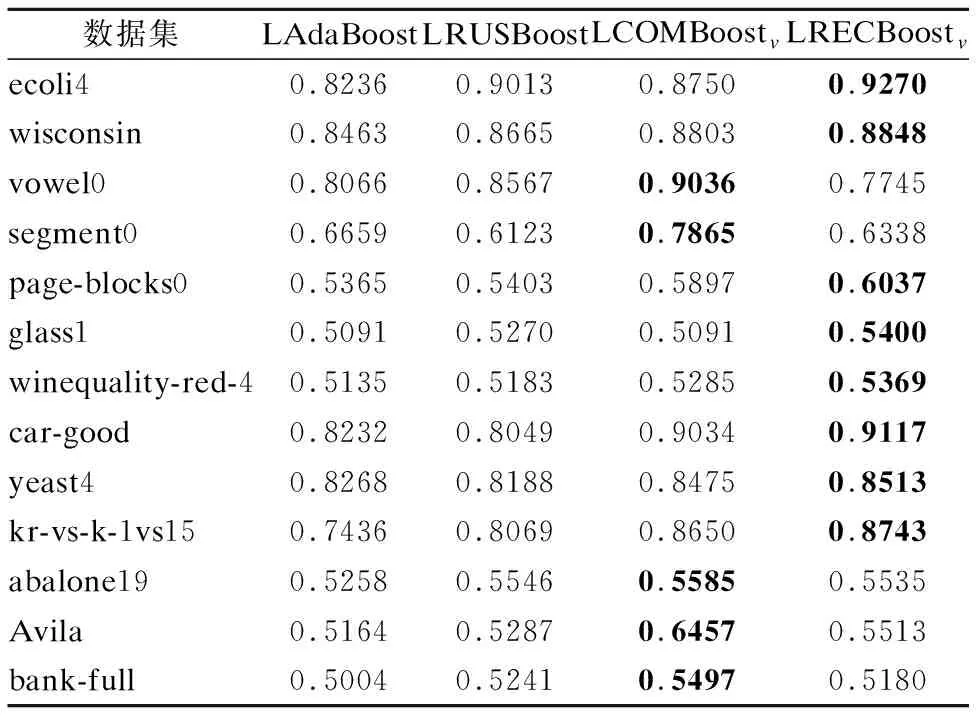
表6 线性算法的几何均值Table 6 G_mean of linear algorithm
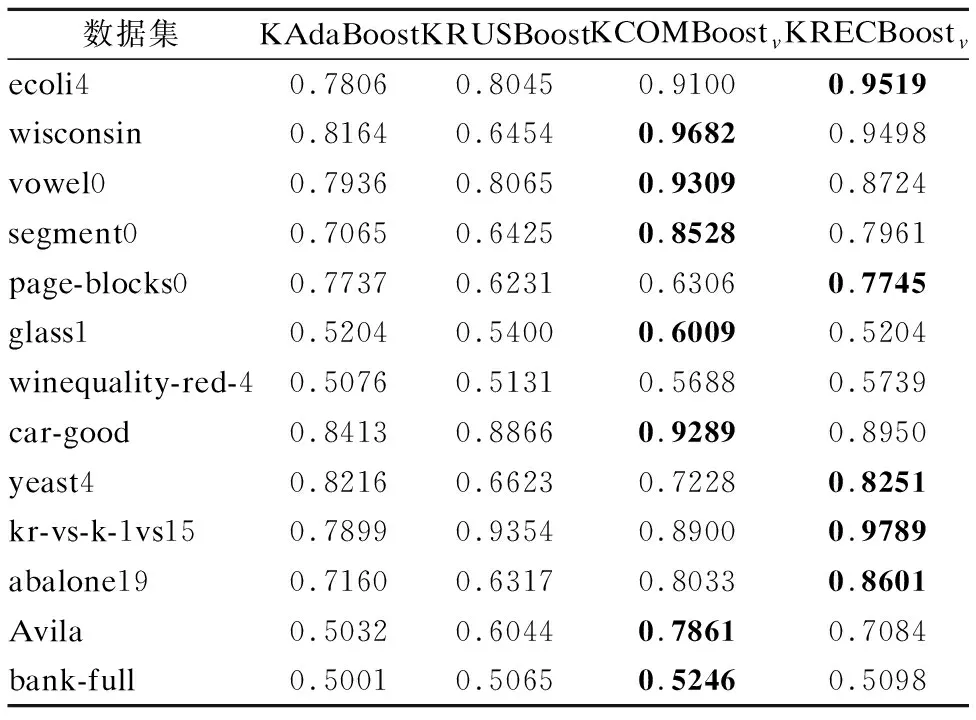
表7 非线性算法的几何均值Table 7 G_mean of nonlinear algorithm
给出召回率对比实验,实验结果如表8、表9所示.
观察表8和表9,提出算法的召回率普遍优于对比算法,并且在一些数据集上的召回率达到1,说明提出的两种算法使得分类器更加关注少数类样本,从而更能提高少数类样本的分类精度.
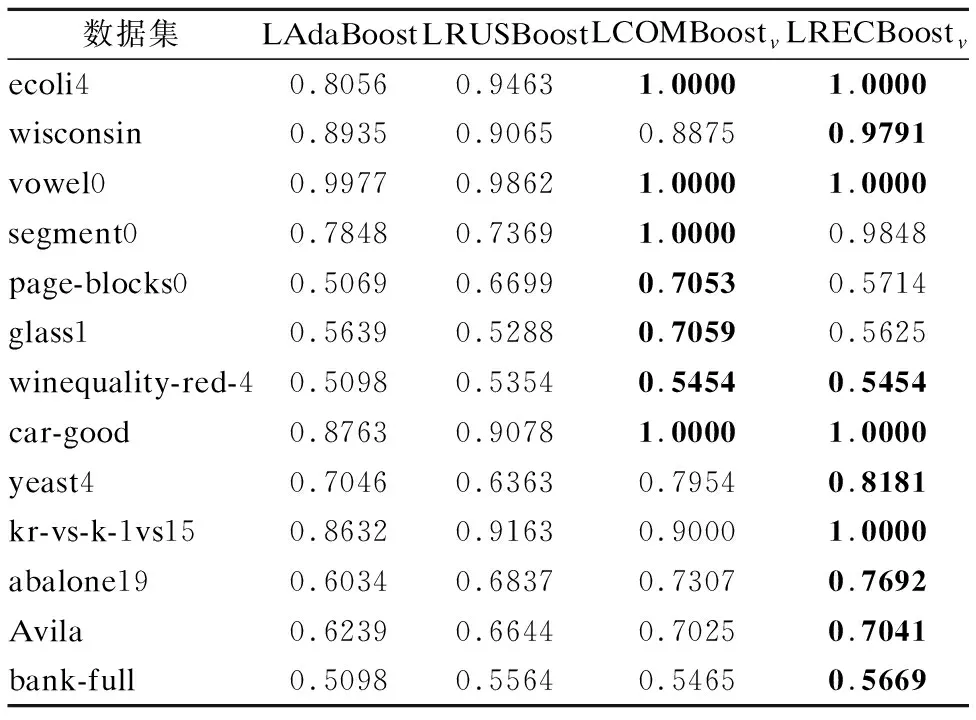
表8 线性算法的召回率Table 8 Recall of linear algorithm
4.4 最优间隔对比实验
给出提出算法与对比算法在非平衡数据集上的最优间隔折线图,如图4、图5所示.
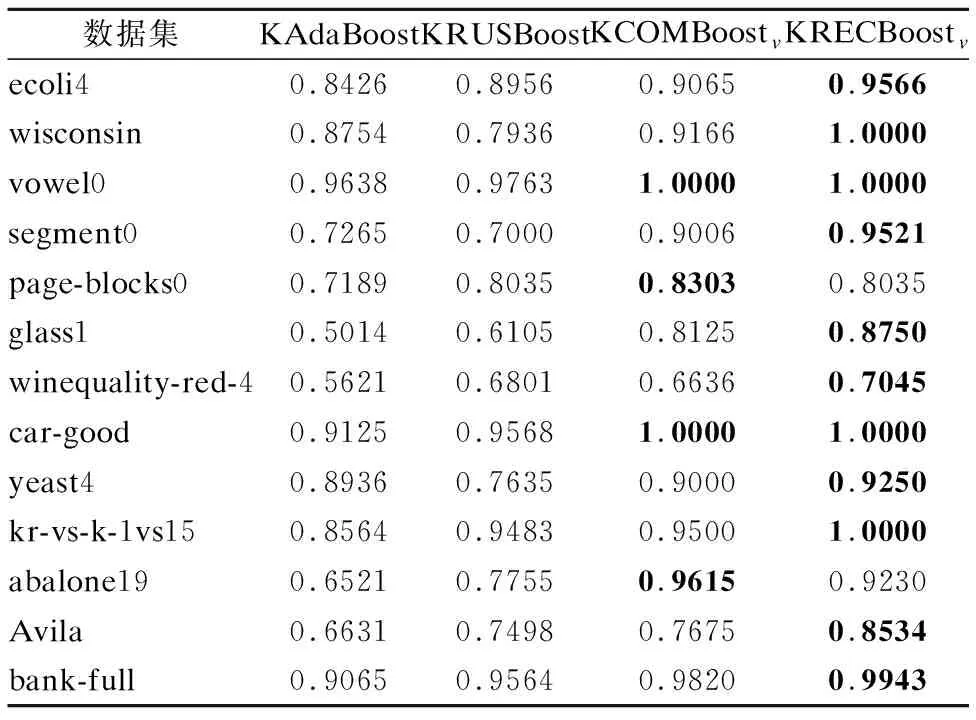
表9 非线性算法的召回率Table 9 Recall of nonlinear algorithm
观察图4、图5可以看出,无论线性算法还是非线性算法,提出的两种算法在训练集上的最优间隔折线走势极为相似且紧密靠拢,说明两种算法的最优间隔差异不大,均优于对比算法的最优间隔.
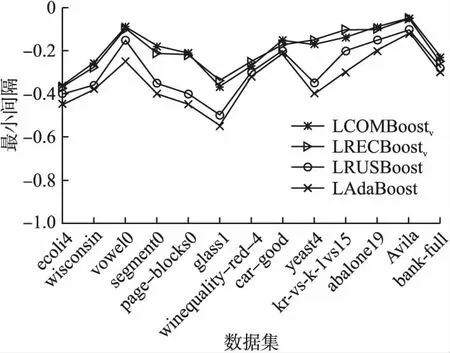
图4 线性算法的最优间隔Fig.4 Optimal margin for linear algorithm
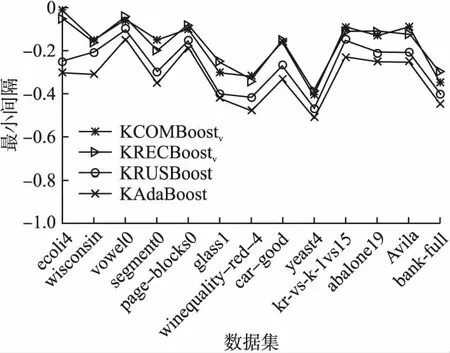
图5 非线性算法的最优间隔Fig.5 Optimal margin of nonlinear algorithm
5 总 结
提出了邻域欠采样的AdaBoostv算法,首先,针对类别非平衡情况下的类重叠问题,引入了两种邻域欠采样方法,用于消除类重叠区域中的多数类样本.其次,将两种欠采样方法应用在AdaBoostv算法上,AdaBoostv算法的基分类器采用加权最优间隔分布机模型,权值是依据数据的非平衡比给出的,以提高分类器处理非平衡数据的能力.并利用带有方差减小的随机梯度下降方法对优化模型进行求解,以提高算法的收敛速度.在人工数据集上实验表明通过欠采样类重叠区域的多数类样本可使原本模糊的决策边界更加清晰,有利于提高整体分类性能.在基准数据集上的几何均值、召回率和最优间隔对比实验表明,两种邻域欠采样的AdaBoostv算法在处理非平衡数据分类问题上具有明显的优越性.将两种欠采样的方法应用到多类数据的非平衡分类问题中是下一步研究工作的重点.
