一种面向粒球粗糙集的快速约简求解方法
2023-01-31陈中华徐泰华王平心杨习贝
陈中华,巴 婧,徐泰华 ,王平心,杨习贝
1(江苏科技大学 计算机学院,江苏 镇江 212100) 2(江苏科技大学 理学院,江苏 镇江 212100)
1 引 言
在粗糙集[1-3]研究领域内,属性约简[4-8]一直是一个热点话题.作为一种数据预处理技术,属性约简的核心思想是利用不确定性度量函数对属性进行评估,筛选并删除条件属性集中的冗余属性,从而达到降低数据维度并提升学习器泛化性能的目的.
正由于属性约简所具有的诸多优势,因此如何提升约简求解的效率,已然受到众多学者的广泛关注[9-12].近年来,已有诸多学者对经典粗糙集[13]进行了拓展和丰富[14-17],提出了新的粗糙集模型,并对相关的约简求解问题进行了研究.例如,Hu等人[14]设计了基于邻域粗糙集的前向贪心约简求解算法,受到了领域内诸多学者的关注与认可.
传统的邻域粗糙集模型通过引入邻域关系的概念,可以灵活地使用邻域半径判别论域中的两个样本相似与否.然而,传统的邻域粗糙集模型往往需要通过采用网格化搜索或尝试策略,找寻出符合问题求解的邻域半径,这必然会导致与邻域粗糙集相关的问题求解方法在时间效率上存在缺陷.
为了克服这一缺陷,已有学者借鉴自适应理念,提出了一些能够无参数地决定邻域半径大小的策略.例如,Zhou等人[18]针对在线流特征选择问题,提出了Gap邻域的概念,该邻域的大小由数据中样本间距离的差值自动地确定;Xia等人[19]为提升基于粒计算的分类器的性能,提出了粒球[19-21]的概念,其生成过程是迭代地使用2-means聚类,依据数据自身的分布自动地生成大小不一的粒球,直至粒球的纯度达到给定的阈值,粒球的纯度实际上就是粒球中那些样本标签与粒球标签一致的样本的比重.
基于粒球的概念,Xia等人[21]还提出了粒球粗糙集模型,并基于该模型探索了属性约简的相关问题.相较Hu[14]等人提出的邻域粗糙集下的约简求解算法,面向粒球粗糙集的约简求解算法显著地提升了时间效率.然而,在这一过程中,笔者发现粒球的生成过程占据了大部分的时间消耗,因此如若能提高粒球的生成效率,则可带来约简求解时间效率的总体提升.鉴于此,笔者将伪标签策略引入到粒球的生成过程中,以期粒球的内部更加聚集,减少真实标签所带来的不一致情形,从而达到提高粒球的产生效率及快速获得约简的目的.
2 基础知识
2.1 粒球粗糙集
形式化地,决策系统可以表示为一个二元组DS=
Xia等人[21]提出的粒球的概念,在信息粒化的进程中能够依据球内数据的分布,自适应地生成信息粒.相较以往的邻域粗糙集而言,粒球方法具有更高的灵活性,并且无需半径寻优这一耗时的过程.一般来说,粒球的主要结构包括球心和半径,其详细定义如定义1所示.
定义1.给定一个决策系统DS,∀A⊆AT,在论域U上依据条件属性集A,可以诱导生成一个以C为球心,r为半径的粒球GBs(GBs⊆U),即:
(1)
(2)
其中,球心C为GBs中所有样本点的重心,半径r为GBs中所有样本点到C的距离的均值,|GBs|表示GBs中样本的个数.
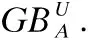
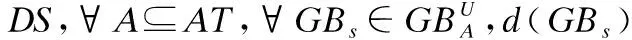
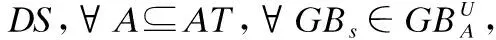
(3)
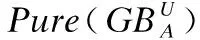
在Xia等人[21]所提出的粒球的生成过程中,初始时将论域U视作一个粒球,然后对每个粒球迭代地使用2-means聚类,用以对每个粒球进行分解,直至每个新生成的粒球的纯度均达到给定阈值.其主要步骤如下所示:
1)假设n表示现有粒球的数量,将论域U视为一个初始粒球,此时n的值为1;
2)利用2-means算法分别对现有的每个粒球进行聚类,使得原来的每个粒球分别分裂成两个更小的粒球,则现有的粒球数量为n·2;
3)求得现有每个粒球的纯度;
4)遍历所有现有的粒球,若每个粒球的纯度均不低于给定的阈值,则算法结束;否则返回步骤2).
由上述粒球的概念,不难得到粒球粗糙集的定义,如定义4所示.
定义4.给定一个决策系统DS,∀A⊆AT,∀Xp∈U/IND(d),根据条件属性集A,Xp的粒球上、下近似集分别定义为:
(4)
(5)
2.2 属性约简
作为基于粗糙集理论的特征选择方法,属性约简在诸多研究领域已然受到了相关学者的广泛关注.一般来说,属性约简的目的是获取满足给定约束条件的极小属性子集,并以此来降低数据维度、提高学习模型的泛化能力.形式化地,属性约简的一般定义如定义5所示.
定义5.给定一个决策系统DS,Cρ是与给定的一个度量ρ相关的约束条件,∀red⊆AT,red为AT的一个约简当且仅当:
1)red满足Cρ.
2)∀red′⊂red,red′不满足Cρ.
其中度量ρ可被描述为一个函数,形如: 2U×2AT→R,R是所有实数的合集.
在定义5中,不难发现red实际是一个满足给定约束条件的极小属性子集,其中:1)能够保证相较于原始属性集,约简中的属性能够满足指定的约束条件;2)保证了约简的极小性.
在粗糙集领域现有的诸多研究成果中,度量ρ可以使用不同的方式进行计算.例如,在经典粗糙集方法中,度量ρ可以使用近似质量来计算,约束条件Cρ就表示等价类的近似质量;而在Xia等人[21]提出的粒球粗糙集方法中,此时可以采用粒球的纯度作为度量ρ的计算方式,Cρ则表示原始数据上的粒球的纯度.
3 属性约简加速方法
3.1 伪标签粒球粗糙集
由2.1节可知,当粒球中存在较多与粒球标签相异的样本时,该粒球便不断分裂以生成新的粒球,直至每个粒球的纯度都达到给定的阈值,随着迭代次数的增多,这个过程耗时巨大,因此势必也会为约简的求解带来显式的时间增长.为解决这一问题,本节将从提高粒球生成的效率这一层面出发,考虑粒球的新型生成方式,进而进行属性约简方面的探究.
在Xia等人[21]提出的粒球粗糙集中,粒球的生成过程是一个无监督的进程,虽然样本的标签并未参与到生成粒球这一过程中,但样本的标签信息却被用来计算粒球的纯度,并依据计算结果来判定是否继续分裂粒球.由此不难看出,当数据中存在较多不一致情形时,获得高纯度的粒球可能较为困难,这便直接影响到后续进行约简求解的时间效率.
样本的伪标签也可以采用无监督的模式进行获取[15].伪标签可以使得数据中样本分布的刻画更为聚集.考虑到这一优势,笔者在本节中将伪标签策略引入粒球的生成过程中,旨在减少不一致情形,提高粒球的生成效率.
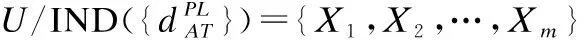
在数据中引入样本的伪标签后,需进一步对Xia等人[21]提出的粒球粗糙集中相关概念重新进行定义,详细描述如定义6所示.
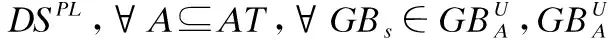
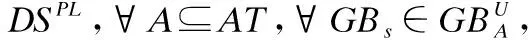
(6)
在伪标签粒球的生成过程中,首先根据条件属性集AT获取样本的伪标签,伪标签的数目与原始数据中原标签的数目相等,并使用获取的伪标签对数据原标签进行更新;其次,将论域U视作一个伪标签粒球,然后对每个伪标签粒球迭代地使用2-means聚类,用以对每个伪标签粒球进行分解,直至每个新生成的伪标签粒球的纯度均达到给定的阈值.详细的算法流程如算法1所示.
算法1.伪标签粒球生成算法
输入:DS=
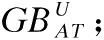
步骤1.根据条件属性集AT获取样本的伪标签,并使用获取的伪标签更新数据的原标签;

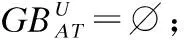
步骤4.Repeat
1)使用2-means分解伪标签粒球;
2)求得每个伪标签粒球的纯度;
Until每个伪标签粒球的纯度均不低于给定的阈值;
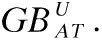
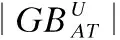
根据上述伪标签粒球的概念,不难得到伪标签粒球粗糙集的定义,如定义8所示.
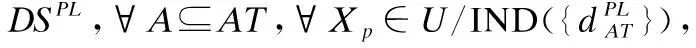
(7)
(8)
3.2 快速约简求解算法
在3.1节中,笔者给出了伪标签粒球粗糙集的相关定义,本节中笔者将利用伪标签粒球粗糙集,设计前向贪心搜索算法,用于求解基于伪标签粒球粗糙集的约简,具体的算法描述如算法2所示.
算法2.快速约简求解算法
输入:DS=
输出:约简red;
步骤2.令red=∅;
步骤3.Whilered不满足约束条件Cρdo
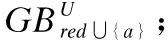
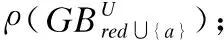
3)挑选出合适的属性,形如b=arg
4)red=red∪{b};
End
步骤4.Repeat
2)Ifred满足约束条件Cρ
red=red-{a};
End
Untilred不再发生变化或|red|=1;
步骤5.输出red.

4 实验分析
为了验证所提算法的有效性,在本节中,笔者选取了12组基准数据集进行相关的实验对比分析,数据的具体描述见表1.
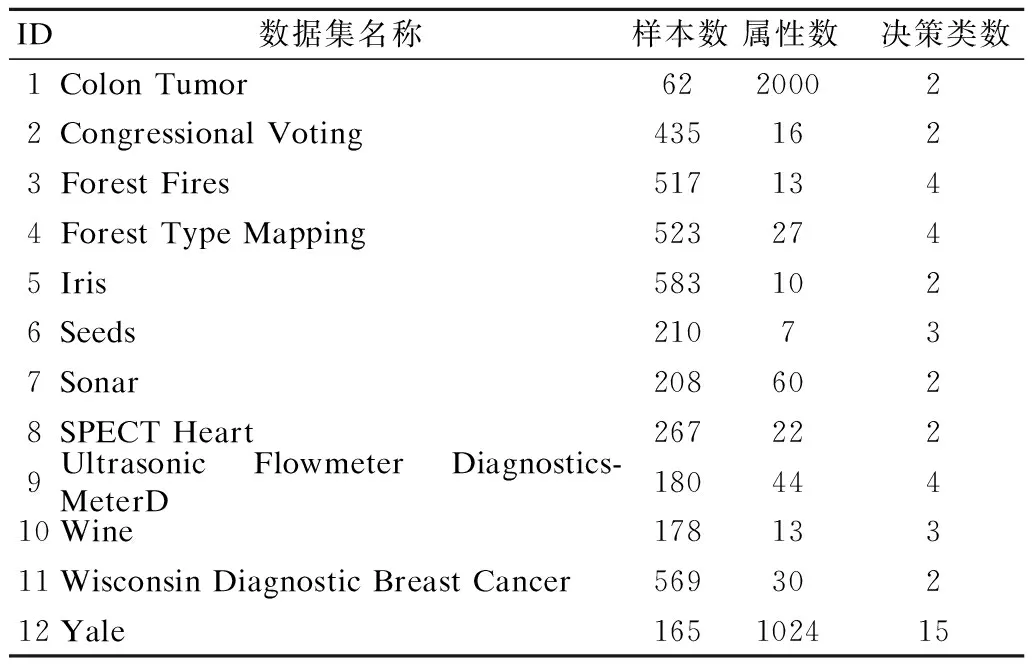
表1 数据集描述Table 1 Data sets description
4.1 粒球生成的时间消耗对比
在本节实验中,将针对Xia等人[21]提出的粒球生成算法及笔者提出的伪标签粒球生成算法,进行时间消耗的对比分析,最终采集的时间消耗为两种方法分别求解1000次粒球所需时间的均值,具体结果如表2所示.
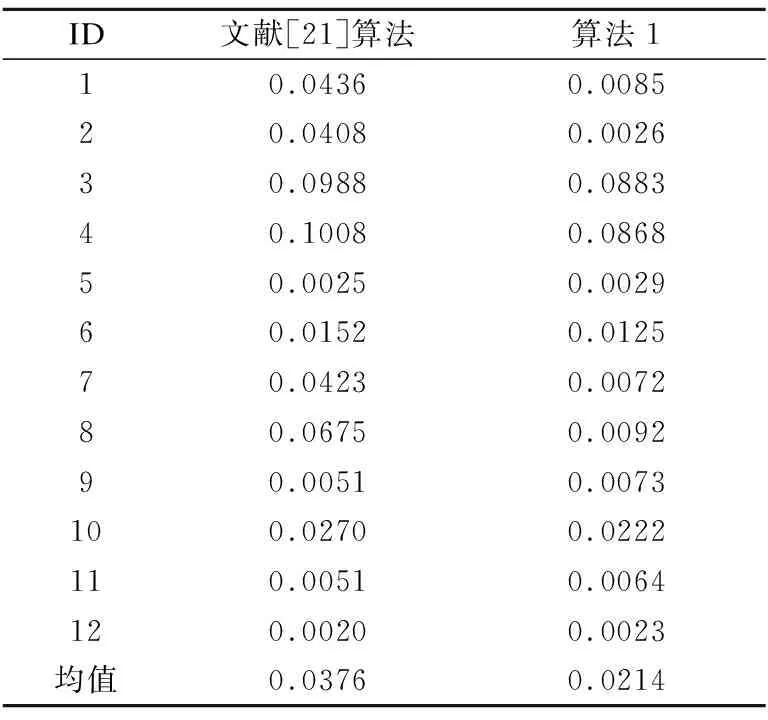
表2 两种算法生成粒球的时间消耗(秒)
观察表2,不难得出如下结论:在多数数据上,使用伪标签粒球生成算法所需的时间消耗要低于Xia等人[21]提出的粒球生成算法所需的时间消耗.这说明,在数据中引入伪标签策略,可以有效地提升粒球生成的效率.
4.2 约简求解的时间消耗对比
在文献[21]中,Xia等人[21]不仅提出了粒球粗糙集模型,还针对属性约简的求解问题进行了研究,并设计了基于后向贪心的约简求解算法.但文献[22]指出,针对高维数据,采用该方法进行约简求解时,在剔除属性的过程中,将会产生巨大的时间消耗.鉴于此,文献[22]提出了基于粒球粗糙集的前向贪心约简求解方法.
此外,值得注意的是,粒球粗糙集是一种自适应生成邻域信息粒的技术,因此笔者还将粒球粗糙集的约简求解与Gap邻域粗糙集[18]的约简求解进行了对比,这主要是因为Gap邻域也是一种具有清晰语义解释的自适应生成信息粒的方法.
除此之外,笔者还挑选了传统的基于半径设置的邻域信息粒生成方法,进行约简求解.其中,对于邻域粗糙集的半径选择问题,文中选取了0.02,0.04,…,0.40等20个不同半径,步长为0.02.
在本节实验中,对文献[18]算法、文献[22]算法、笔者在文中所提算法2以及邻域粗糙集约简求解的时间消耗进行统计,如表3所示.
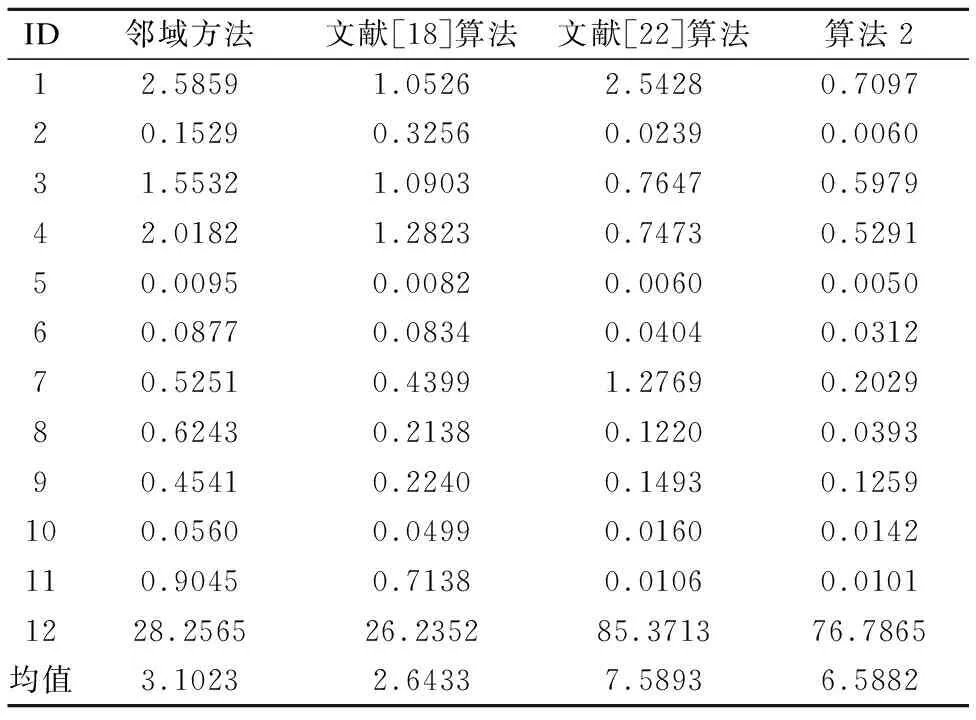
表3 不同算法求解约简的时间消耗对比(秒)Table 3 Time consumptions of different algorithms for deriving reducts(Seconds)
观察表3,不难得出如下结论.
1)利用传统邻域粗糙集方法,进行约简求解所需的时间消耗显著高于其他3种算法所需的时间消耗.以数据Forest Fires为例,在运用邻域粗糙集方法进行约简求解时,所需的时间为1.5532秒,而利用文献[18]算法、文献[22]算法和笔者所提出的算法2进行约简求解,所需的时间消耗分别为1.0903秒、0.7647秒和0.5979秒.由此可见,相较于设置半径的方法来说,自适应确定邻域信息粒的方法的确能够在约简求解时带来较大的时间优势.
2)在进行约简求解时,文献[22]算法所需的时间消耗要比文献[18]算法的低,虽然它们都是数据自适应的方法,但是Gap方法需要逐个求出样本间距离,并对样本间的距离从近到远进行排序,而粒球迭代过程使用聚类算法,每次处理一簇样本,所以文献[22]算法具有更快的速度.但是在2个高维数据上,所提方法相较于Gap方法还存在一定的差距.
综上所述,相较于Xia等人[21]所提出的粒球粗糙集约简,文中所提方法在约简效率上已经有了很大程度的提升,但是在对高维数据进行约简求解时,相较于Gap方法,仍具有可以进一步探索的空间.
表4展示了约简求解所耗时间的加速比.
根据表4所示结果,可以清晰地看出,相较于邻域粗糙集、文献[18]算法、文献[22]算法,笔者所提出的算法2提供了较为显著的加速比.
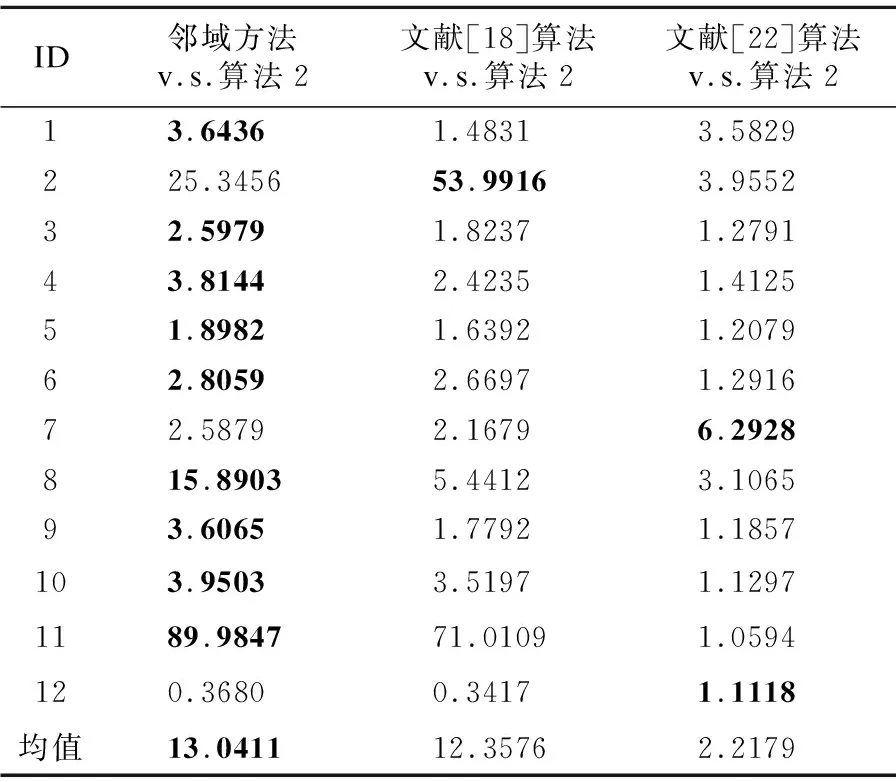
表4 求解约简所需时间的加速比Table 4 Speed-up ratios related to the elapsed time of deriving reducts
此外,为了进一步地展示文中所提算法2的优越性,在文中的表5展示了约简求解时得到的约简率.
根据表5所示结果,可以明显地看出,相较于文献[18]算法,笔者所提算法2得到的约简率仍有一定差距,但是相较于邻域方法、文献[22]算法,算法2具有更高的约简率.
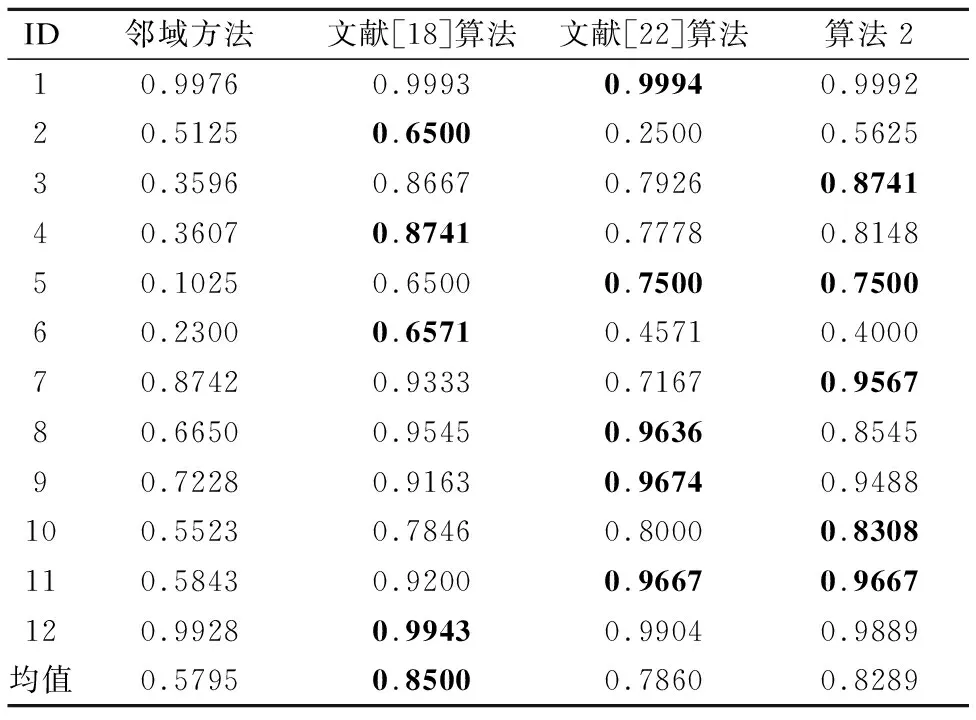
表5 求解约简时得到的约简率Table 5 Reduct ratios related to deriving reducts
4.3 分类准确率对比
在本节中,分别采取KNN(K取值为3)和SVM(libSVM[23]默认参数)两种分类器,利用约简所求得的属性,在测试集上进行分类.具体的分类准确率如表6所示.
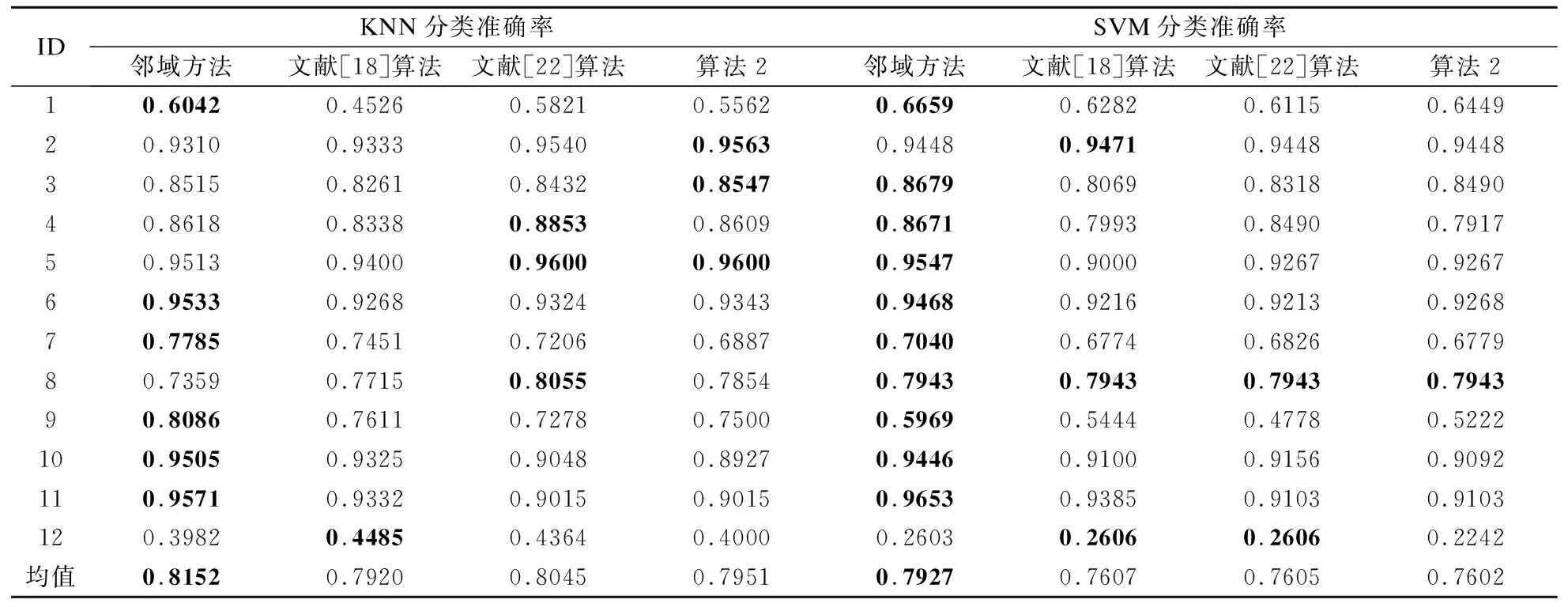
表6 KNN和 SVM 分类器的分类准确率Table 6 Classification accuracies based on KNN and SVM classifiers
通过表6展示的结果并进行对比分析,可以得出如下结论:从分类准确率的均值来看,无论是采用KNN还是SVM分类器,4种算法求得的约简均能提供相当的分类能力.从分类准确率在单个数据上的表现来看,相较其他3种算法,利用笔者所提算法2产生的约简,在某些数据上能够提供较好的分类能力.这说明在粒球粗糙集中引入伪标签策略并进行约简求解并不会降低后续学习器的分类性能.
最后,综合考虑时间消耗,相较于文中对比的其他3种算法,可以得知,利用伪标签粒球粗糙集进行约简求解,不仅在约简效率上占据较大优势,还能得到较高的约简率并维持较好的分类表现能力.
5 结束语
在利用粒球粗糙集进行约简求解时,粒球的生成过程在很大程度上影响着约简求解的时间效率.若数据中存在大量不一致样本,则根据样本自身提供的标签信息生成高纯度的粒球将会更加困难,进而导致计算粒球的时间消耗急剧增加.
因此,笔者将伪标签策略引入到粒球的计算过程中,使用伪标签对数据中样本的原始标签进行更新,旨在减少不一致情形,从而使得粒球中的样本分布更加聚集,降低计算粒球的时间消耗并以此来提升约简求解的效率.实验结果表明,所提出的伪标签粒球方法可以显著降低约简求解的时间消耗,并且所获取的约简也具备相当的分类能力.在本文的基础上,可以就以下工作进行进一步探索.
1)在生成粒球的过程中,由于k-means算法固有的随机性和不稳定性,因而可以考虑其他无监督策略以提升粒球及其粗糙集的稳定性.
2)在对高维数据进行约简求解时,基于粒球粗糙集的约简求解耗时巨大,可以考虑在其中引入属性簇[9]方法,进一步提升问题求解的效率.
