大规模降雨监测数据异常识别方法
2023-01-31田济扬刘含影刘荣华丁留谦
田济扬,刘含影,刘荣华,丁留谦,刘 宇
(1.中国水利水电科学研究院,北京 100038;2.水利部防洪抗旱减灾工程技术研究中心,北京 100038)
1 研究背景
降雨监测是水文监测的重要组成部分,是暴雨洪水灾害防御工作的耳目和参谋[1-2]。21世纪以来,水利部门加大了对自动监测站建设的支持力度,特别是经过山洪灾害防治项目建设,全国山洪灾害自动监测站点达13.2万个,自动雨量站网平均密度为38 km2/站,是2006年(6000站)的22倍,最小报汛时段缩短到10 min,数据信息量增加100余倍,极大地缩小了降雨监测盲区,有力支撑了水旱灾害防御工作[3-5]。但由于部分测站建设标准偏低,位于山丘区的测站运维困难,数据质量难以得到保障,常常出现冒大数、缺测、漏测等情况,且测站出现问题具有很强的随机性,完全抛弃某一测站不切实际。
为使所有测站的监测数据得到有效利用,需从众多雨量监测站中找出不同时段内监测数据准确的站点,剔除数据质量存在问题的站点。目前常用的异常站点识别方法有Hampel法、肖维勒准则、格拉布斯准则、K-medoids聚类法、离群点监测等。Person等[6]提出了Hampel过滤方法,用中位数和中位绝对偏差代替对异常点敏感的平均数和标准差,使异常数据处理更有效。肖维勒准则的置信概率偏低,且概率分布不均匀,对异常数据的剔除存在误判的可能性[7]。格拉布斯准则适用于样本数量在[3,100]区间的异常数据判别[8]。在逐时雨量异常数据判别时,聚类分析契合了逐时降雨数据量大且变异性强的特点,但数据离散程度较大且区段划分具有极强的主观性[9]。离群点检测的优点是无需知道数据集的分布模型和分布参数,适用于存在某种距离度量手段的任何维度特征空间,其缺点是需要进行大量的距离计算与比较,对计算资源要求高[10]。
业务应用对异常站点识别方法的高效性、稳定性和可靠性均提出很高的要求。本文以福建全省雨量监测站为例,基于Hampel法、格拉布斯准则及周边测站法等方法建立起递进式异常站点筛查体系,并引入K-d tree(K-dimension tree)高级数据结构和并行计算提高计算效率,以期为异常站点的快速识别、控制雨量监测数据质量提供参考。
2 研究区与数据
福建省位于我国东南沿海,山丘区面积占80%以上,且气象条件复杂多变,受台风影响较大,暴雨洪涝灾害频发[5]。为有效应对强降水及其可能带来的洪涝灾害,福建在全省范围内建设了大量的雨量监测站,站网密度达到25 km2/站,居全国前列。研究选用雨量监测站的数据来源于福建省水利厅。按照2020年的统计数据,福建全省发挥雨量监测作用的各类雨量监测站5234个,其中雨量站、河道水文站、水库水文站、河道水位站个数分别为3268、119、1176、671,测站分布如图1所示。气象部门雨量监测站报讯时间间隔为10 min,其余各类测站报讯时间间隔多为1 h。为便于异常站点识别,研究采用的雨量监测数据时间间隔统一为1 h。自2010年山洪灾害防治项目实施以来,福建省雨量监测站数量迅速增加,至2015年数量基本稳定,后续每年仍有新建测站,但数量较少,大部分为更新改造。因此,研究选用福建全省雨量监测站降雨数据的时间序列为2015—2020年。
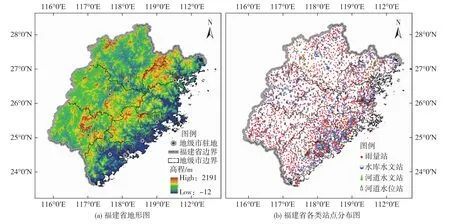
图1 福建省地形及站点分布图
3 异常站点识别方法
递进式异常站点筛查体系由初步判定基准站、周边测站分析和雷达辅助校验三部分构成(见图2)。首先,基于长序列降雨观测资料初步判定基准站,采用Hampel法和改进的格拉布斯准则初步筛选出雨量监测较为稳定、数据质量相对较高的测站,称为基准站,并剔除存在明显问题的测站;再以初步筛选出的基准站为基准,采用周边测站分析法对逐小时的降雨监测数据进行异常识别;最后通过雷达辅助校验,对筛选出的异常站点做进一步验证。
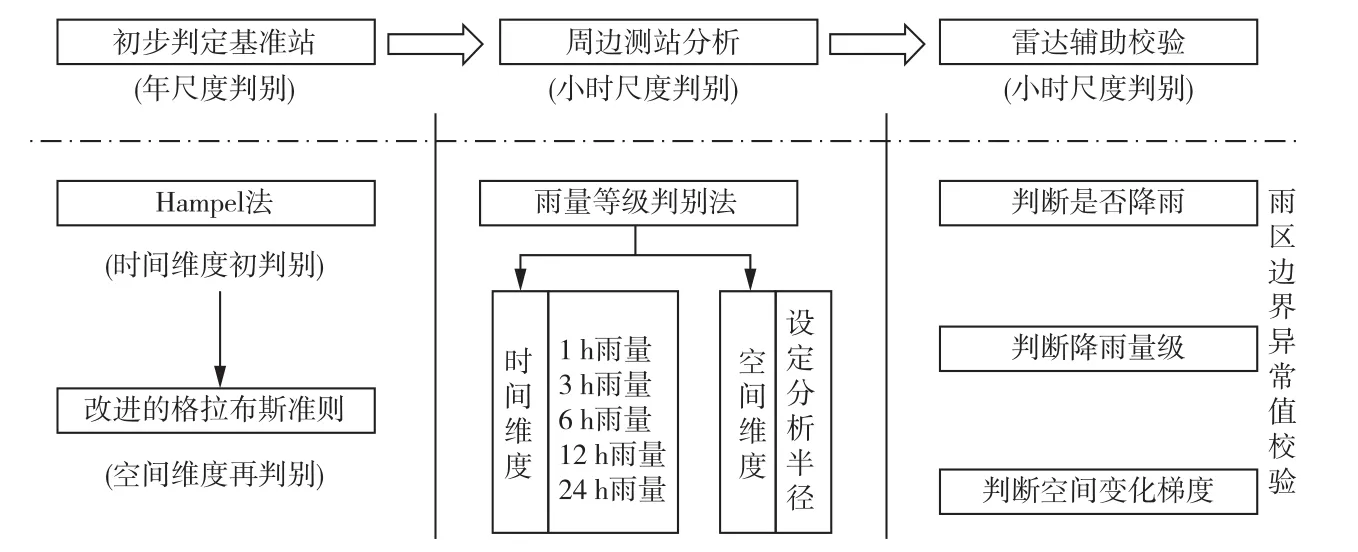
图2 异常识别方法流程图
3.1 初步判定基准站
3.1.1 Hampel法 Hampel法可用于异常极端值的判别,其基本原理是对给定的数据集假设一个分布和概率模型,然后根据假设采用不一致检验对数据系列进行处理[11-13]。基于长序列测站的年雨量值,利用Hampel法对单一测站监测数据的异常年份进行识别,方法如下:

式中:Xi为数据序列X中的某一值;Median为X的中位数;MAD(median absolute deviation)为数据集Y的中位数;X={x1,x2,…,xn},是测站年降雨量数据序列;Y={y1,y2,…,yn}={x1-Median,x2-Median,…,xn-Median}。当 Zi(i=1,2,…,n)值大于 2.24时,则判定 Xi为异常点,i为该测站的异常年份[14]。但考虑到大量测站建设年代较近,数据序列较短,仅通过Hampel法从时间维度上判定测站监测数据的异常年份,可靠性还不够。
3.1.2 改进的格拉布斯准则 格拉布斯准则适用于测量次数较少的情况(3≤n<100),可一次性求出多个异常值。其基本原理是判断可疑值取舍的过程中,将正态分布中平均值和方差这两个最重要的参数引进来,提高判断的准确性[15-17]。考虑到本文单站年累积雨量的时间序列较短,为了提高异常值判定的准确性,需借助周边测站从空间维度再做判断,格拉布斯准则判别法较为适用。改进的格拉布斯准则是将原准则公式中的平均值用中位数代替,可有效消除同侧异常值的屏蔽效应,更为稳健[18]。具体方法如下。
先将通过Hampel法初步判定为某年异常的测站选出,在其周围以20 km为半径划定区域,区域内测站约50个左右,区域内所有站点的年雨量值构成样本,通过从小至大排序为样本序列X=(x1,x2,…,xn),统计临界系数 G(a,n)的值G0(查临界值表获得),a为显著性水平,本文取 a为0.05,并计算 G1、Gn:

式中:n为测站数量;X中为样本中位数;σ为标准差。
若 G1≥Gn且G1>G0,则判定x1为异常值并予以剔除;若Gn≥G1且Gn>G0,则xn为异常值并予以剔除;若G1<G0且Gn<G0,则不存在异常值。若存在异常值,则剔除之后用剩余站点的年雨量值重新计算,重复上述步骤,直到无异常值为止。
为提高计算效率,缩短判断待评估测站与周边站点距离关系时程序的运行时长,在使用格拉布斯准则对疑似异常站点进行判断时,根据面积、测站分布、降雨空间分布情况等因素,将福建省分为7个区域,程序在查找20 km范围内测站时,仅在其中一个区域内查找[19-20]。已经判断为异常的测站在后续判别待测站时不作为周边测站参与比较,减少部分异常值对判别效果的不良影响。通过Hampel法和格拉布斯准则共同判断后,则完成基准站初步判定。
3.2 周边测站分析采用周边测站分析时,优先选用基准站与待评估测站进行同时段雨量比较,基准站距离较远的(超过某一阈值),则选用距离待评估测站较近且经基准站评估后已确定为正常站点的非基准站,与待评估测站进行同时段雨量比较。为了避免初步确定的基准站在某一时刻降雨监测出现问题,在采用基准站评估待评估测站时,待评估测站也包括基准站。通过比较待评估测站雨量与同时段周边基准站(或已评估合格的非基准站)的平均雨量,判断待评估测站是否异常。周边测站分析仅对1 h(或3 h、6 h)雨量超过10 mm、12 h雨量超过15 mm、24 h雨量超过25 mm的测站进行评估。评估时分别比较待测站不同时间段(1 h、3 h、6 h、12 h、24 h)雨量值与周边站点相应时段的平均雨量值,当雨量值相差超过一个等级时,则判定为异常站点。参考气象部门对降雨等级的划分规范,结合福建省的降雨特点,将雨量等级划分如表1所示。

表1 雨量等级表
为选取合适的评估范围,计算距离待评估测站5 km、10 km、15 km、20 km、25 km、30 km时,待评估测站的周边站点平均数量分别为4个、13个、30个、50个、78个、115个,分析了距离选取对异常站点识别准确率及计算时长的影响,具体见图3。考虑到福建省雨量监测站网密度约为25 km2/站,且准确率在15 km时达到最大,计算时长相对适中,故采用周边测站分析时,分析范围的半径设为15 km,分析范围内站点平均数量30个。

图3 距离与计算时长/准确率的对应关系
3.3 雷达辅助校验经过基准站初步判定和周边测站分析后,已完成异常站点的筛查,但人工校验时发现,雨区与非雨区边界、雨强差异较大的雨区边界处,报讯正常的测站也容易被误认为异常站点,因此仍需进一步验证筛查结果。尽管雷达降雨反演的精度受反演算法等因素的影响大,但利用雷达反射率仍能有效判定雷达探测覆盖范围是否产生降雨或判断降雨量级,能够充分反映某一时段降雨的空间分布特征[21-23]。雷达辅助校验方法包括:一是利用雷达低层仰角反射率超过20 dBZ阈值时即发生降雨的条件,验证雨区与非雨区边界处测站判定结果;二是通过雷达基数据反演降雨强度,并与测站降雨量级进行对比,验证测站是否异常;三是通过反射率的空间变化梯度,验证雨强差异较大的雨区边界处测站的判定结果。
3.4 大规模降雨监测数据处理算法福建省雨量监测站数量多、密度大。为了能够达到实时计算并判断异常站点的目的,研究采用K-d tree高级数据结构和并行计算方法,大幅提高计算效率。经测试,全省站点进行一次异常识别,计算时长约5~8 min。
3.4.1 K-d tree高级数据结构 K-d tree高级数据结构主要用于优化一定范围内周边站点的筛选过程。K-d tree是对数据点在 k维空间(如二维(x,y),三维(x,y,z),k维(x,y,z,…))中划分的一种数据结构。为了能有效的找到最近邻,K-d tree将整个空间划分为几个小部分,且K-d tree索引的空间划分不会出现区域重叠现象,更适合作为计算环境中的上层全局索引,从而在多维查询过程中快速发现包含查询结果的局部数据节点[24-25]。
3.4.2 并行计算 针对多个测站同时进行异常值识别这一问题,研究采用 CUDA(Compute Unified Device Architecture)平台,使用支持CUDA的GPU(Graphics Processing Unit)进行并行编程,与传统的GPU相比,CUDA的GPU能获得相比同期CPU(Central Processing Unit)高几倍乃至十几倍的提速,大幅缩短计算时长[26-29]。该方法是对多个独立站点同时进行异常识别,把来自不同站点的指令在不同的处理器上同时执行,提高计算效率[30]。Hampel法和格拉布斯准则所用数据为年尺度,不进行实时计算,计算量相对较小,对计算的时效性要求不高,仅在格拉布斯准则法分区计算时采用并行算法。周边测站法所用数据为逐小时降雨数据,数据量大且需要实时计算,对计算的时效性要求很高,因此周边测站法全程采用并行计算将不同站点分配到不同的处理器进行同时计算。雷达辅助校验的计算量取决于筛查出的异常站点数量,尽管时效性要求高,但计算量较小,未采用并行计算。
目前福建全省发挥雨量监测作用的各类雨量监测站5234个,某一时刻站点降雨数据量最多有5234条,以计算量最大的周边测站分析法为例,按分析范围15 km计,某一待检测站周边站点降雨数据约30条,采用支持CUDA的GPU并行计算可将计算时长控制在5~8 min。
4 结果分析
4.1 基准站初步判定结果经过Hampel法和格拉布斯准则判别法对2015—2020年异常站点进行判定发现,2015年的异常站点数量最多,占比11.5%,之后异常站点逐年减少,至2020年,异常站点数量占比仅5.18%。主要原因是汛后逐年加强了测站的运行维护,测站监测数据的质量有所提升。异常站点中雨量站、水库站的比例偏高,2015—2020年雨量站异常站点在所有异常站点中的占比分别为42.83%、44.13%、48.25%、47.83%、50.84%、47.97%,水库水文站异常站点在所有异常站点中的占比分别为 35.33%、35.20%、31.88%、29.83%、25.18%、34.69%。分析计算 2015—2020年每年各类异常站点在全省相应类型站点中的占比,发现水库水文站、河道水位站的占比更高,各类异常站点的空间分布情况见图5,异常站点数量及占比见图6。为检验基准站初步判定结果,将2015—2020年每年判定的异常站点与实际异常站点进行对比,基准站判定的准确率为95.4%,详见表2,其中异常站点的类型主要有三种:一是年降雨总量为0的站点(站点不报数);二是年降雨总量远小于周边测站的站点(站点年内长时期不报数);三是年降雨总量极大且远高于周边测站的站点。典型实例如图7所示。

表2 判定异常站和实际异常站点数量 (单位:个)

图5 2015—2020年异常站点分布图

图6 2015—2020年异常站点数量及占比情况

图7 异常站点类型
4.2 基于周边测站分析的异常站点识别结果由于每年的基准站会发生一定的变化,因此在周边测站分析时取前一年的基准站为基准开展周边测站分析,如对2017年逐小时降雨数据进行异常识别时,选取基于2016年降雨资料判定的基准站。分别选取2016—2020年每年的6月、7月和8月的1日8点、10日14点、30日20点的异常值识别结果进行人工验证,异常识别正确率绝大多数超过了90%(见表3)。为进一步验证方法的可用性,以2021年6月27—28日福建全省的雨量监测站进行了异常站点实时判别,结果如图8和图9所示。
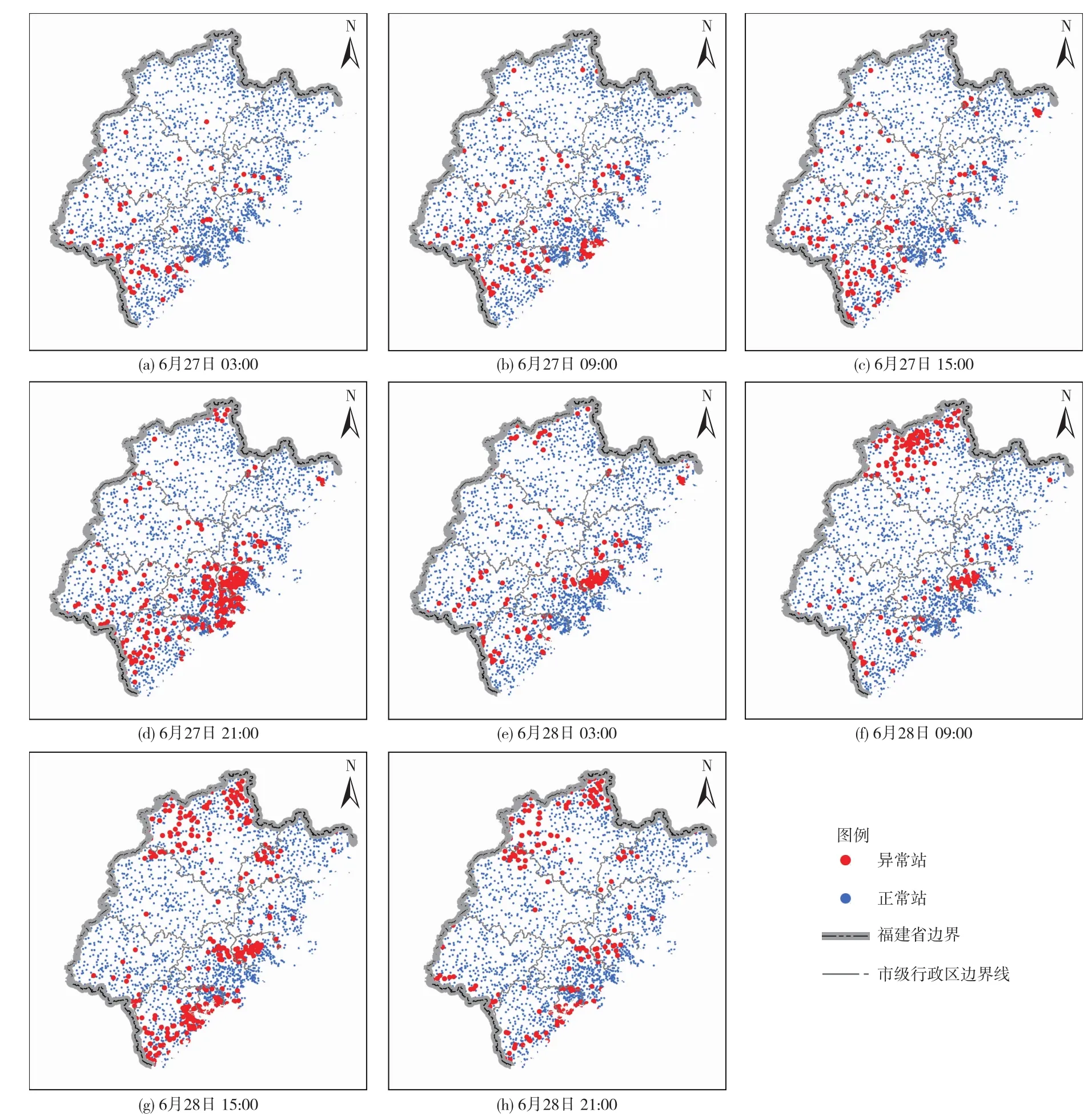
图8 6月27日、28日4个时刻异常站点分布情况
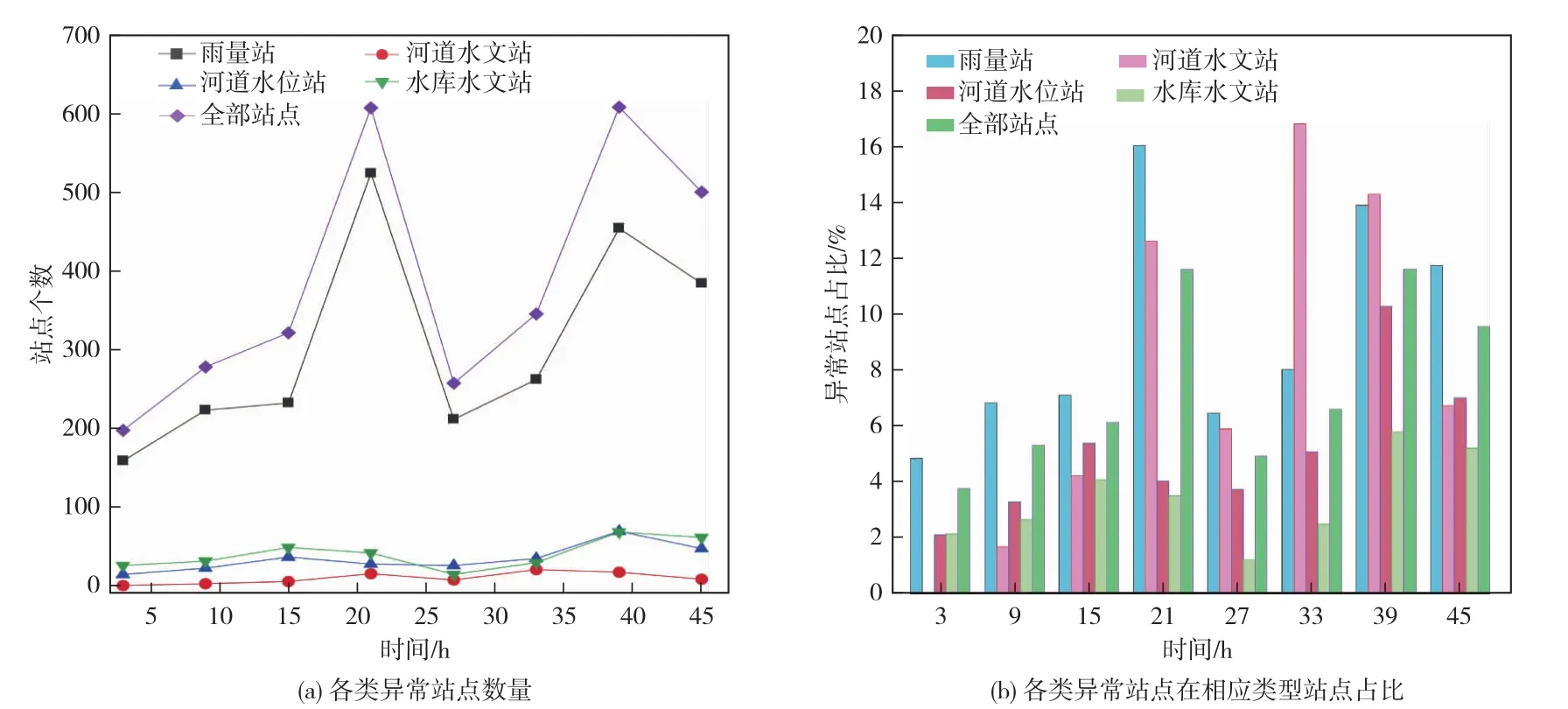
图9 6月27日、28日4个时刻异常站点数量及占比情况
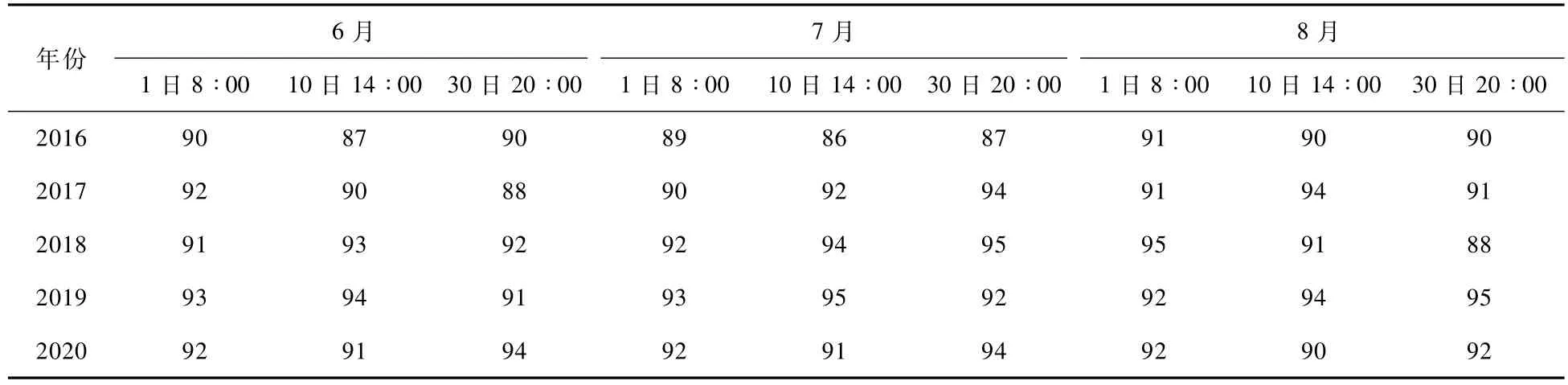
表3 雨量异常值识别正确率 (单位:%)
通过周边测站分析法对2021年6月27日和28日的逐小时降雨数据进行判定并选取共计8个时刻的结果进行统计分析。结果表明6月28日15∶00的异常站点数量最多,占全省站点的11.6%,6月27日3∶00的异常站点数量最少,占全省站点的3.8%,6月27日和28日21点的异常站点数量均较多,主要原因是福建全省在6月 27日19∶00—21∶00和6月 28日9∶00—15∶00降雨范围较广,报讯站较多,更容易发现异常站点。对于不同类型测站,雨量站异常站点占全部异常站点比例依然最大,其次是水库水文站、河道水位站,占比最小的是河道水文站,各类异常雨量监测站的数量情况见图9(a)。分析计算8个时刻各类异常站点在全省相应类型站点中的占比,发现雨量站、河道水文站的占比相对较高,具体情况见图9(b)。
经周边测站分析法检测出的异常站点主要分为三类:一是实际发生降雨但未报数(降雨值为0)的站点;二是雨量值明显小于周边测站的站点;三是降雨值极大且明显高于周边测站的站点(冒大数)。在三类异常站点中,处于不同等级降雨区域分界处的站点较难识别,典型实例如图10所示。
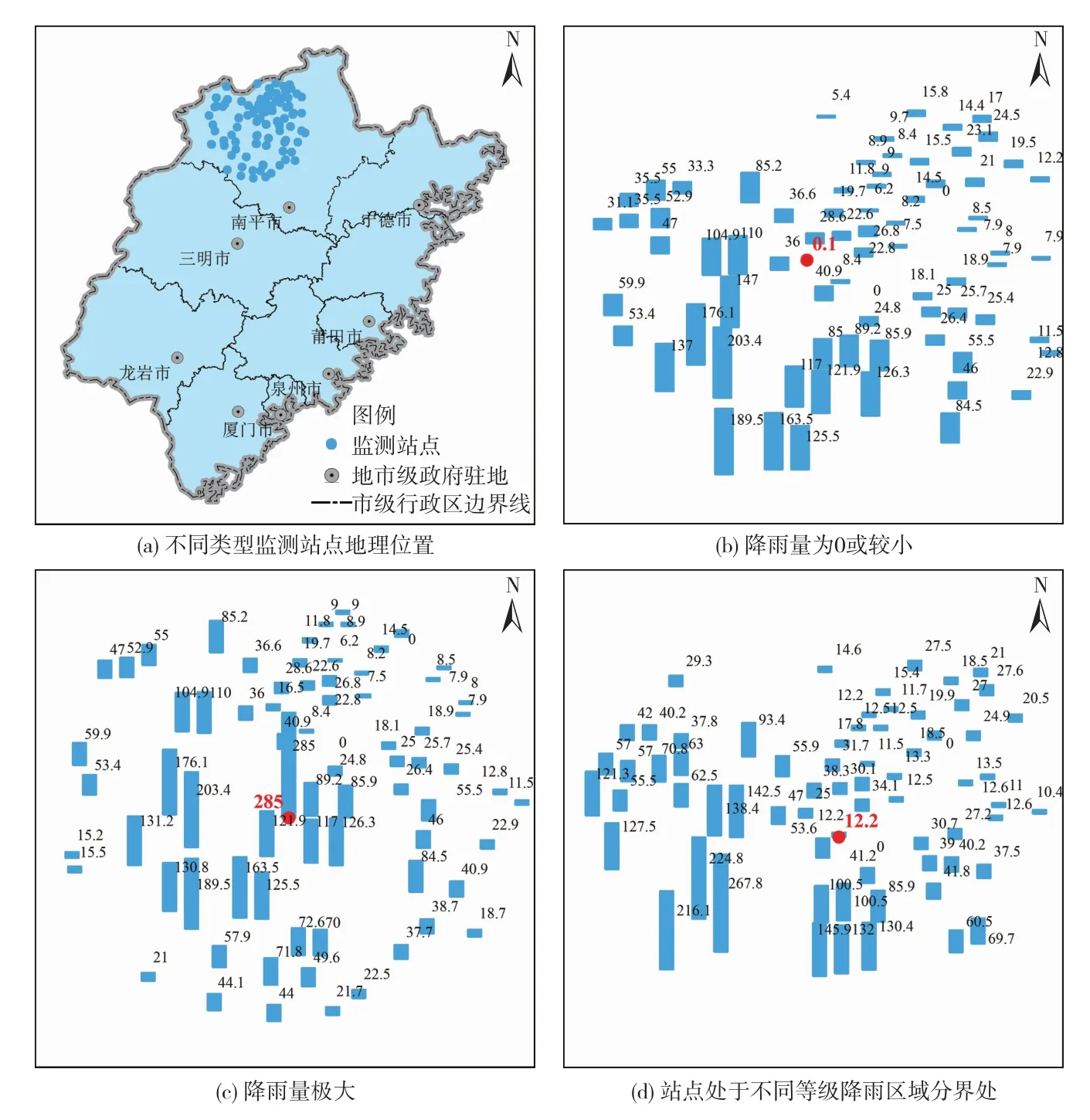
图10 异常站点类型
4.3 异常站点识别结果校验与准确率经过基准站初步判定和周边测站分析后,已初步完成异常站点的筛查,但人工校验时发现,处于雨区与非雨区边界、雨强差异较大的雨区边界的正常站点也容易被判定为异常值,因此仍需借助雷达反射率进一步验证。在2021年6月28日11点的异常结果中选取属于这类情况的4个站点,将站点雨量图与雷达回波图叠加进行人工判断,具体情况见图11。尽管通过上述方法将该4个站点判定为异常,但经过雷达回波图校验发现,10∶00—11∶00,川里村站1 h雨量为0.4 mm,光泽西关站1 h雨量为1.5 mm,枫林村站1 h雨量为0.5 mm,王村站1h雨量为22.2 mm。10∶00—11∶00每间隔6 m in完成一次提扫并获得一次雷达反射率,计算1 h内4个站点位置处对应的雷达反射率均值分别为14 dBz、25 dBz、27 dBz、20 dBz。对比雷达反射率和站点小时雨量可知,川里村站、光泽西关站无异常,枫林村站的雨量值偏小,而王村站的雨量值偏大。

图11 异常站点识别结果校验
考虑到福建全省在6月27日19∶00—21∶00和6月28日09∶00—15∶00降雨范围较广,报讯站较多,所以选择如下6个时刻的异常结果进行雷达回波的校验,具体情况如下表4所示。雷达校验前异常识别结果的平均准确率为89%,经雷达校验后平均准确率提升至95%,这表明雷达辅助校验方法非常适用于应对处于雨区与非雨区边界、雨强差异较大的雨区边界的正常站点被错误判断为异常站点的情况。

表4 6个时刻雷达校验前后福建省雨量监测站异常识别结果准确率 (单位:%)
5 结论
本研究利用福建省5234个雨量站2015—2021年实测降雨资料,基于Hampel法、格拉布斯准则、周边测站分析法和雷达辅助校验等方法构建了递进式异常站点筛查体系,对降雨监测数据进行了异常识别。主要结论如下:
(1)基于测站年累积雨量,采用Hampel法和格拉布斯准则对异常站点进行识别,结果表明异常站点类型主要有测站全年不报数、测站年内长时期不报数、年降雨总量远高于周边测站3类。在2015—2020年,福建省雨量监测站数据质量不断提升,异常站点数量逐年减少。其中,2015年异常站点数量最多,占比为11.5%;2020年异常站点数量最少,占比为5.18%。此外,福建省内雨量站和水库数量较其他类型站点明显偏多,异常站点数量也较其他类型异常站点更多,2015—2020年雨量站异常站点占全部异常站点比例为42.83%~50.84%,水库水文站异常站点占全部异常站点比例为25.18%~35.33%。
(2)采用周边测站分析法对2016—2020年间9个时刻全省雨量监测站进行异常识别,异常识别正确率超过90%,并以2021年6月27日和28日逐小时降雨监测数据进行了进一步验证,结果表明异常站点类型主要有实际发生降雨但未报数、明显小于实际雨量、冒大数3类,处于不同等级降雨区域分界处更难准确识别。当降雨范围较大时,更容易发现异常站点,雨量站异常站点占全部异常站点的比例最高,各类异常站点在全省相应类型站点中,雨量站异常站点的占比也最高。
(3)通过雷达辅助校验,6个典型时刻的异常识别平均准确率由雷达校验前的89%提升至95%,表明雷达辅助校验方法非常适用于应对处于雨区与非雨区边界、雨强差异较大的雨区边界的正常站点被错误判断为异常站点的情况。
(4)本研究采用K-d tree高级数据结构和并行计算方法,大幅提高了计算效率。经测试,全省站点进行一次异常识别,计算时长约5~8 min。
