基于NIRs与深度森林的不同产地秦艽的定性分析*
2023-01-31丁跃武杨友陈方方李四海
丁跃武 杨友 陈方方 李四海
甘肃中医药大学 信息工程学院 甘肃 兰州 730000
引言
秦艽在植物属性上属于龙胆科多年生草本植物,历代本草家认为秦艽性味辛苦而微寒,能入胃、肝、胆三经,以根入药,具有祛风湿、清湿热、止痹痛、退虚热的功效,常用于治疗风湿痹痛、筋脉拘挛、骨蒸潮热、湿热黄疸等病症[1-2]。
近些年,随着对秦艽药材的不断深入研究,越来越多的定性分析方法如化学和分子生物学等技术被广大研究人员应用于秦艽的分类与鉴定,大大提高了秦艽用药的准确性[3],近红外光谱(NIRs)分析技术即是其中之一。
深度森林是一种基于随机森林的深度学习算法,目前已经应用于癌症基因组图谱(TCGA)分类[4]、流量分类[5]、文本分类[6]、森林树种分类[7]等定性分析研究领域,其特有的多粒度扫描阶段可以更全面地扫描输入的特征,更大程度地获取特征信息,保障模型获取更高的准确度,同时该算法相较其他机器学习算法,因参数少所以调参简单,同时构建的模型鲁棒性也很好,因此在多个领域的分类问题均取得不错的效果[8]。本文尝试用近红外光谱分析技术结合深度森林算法鉴定甘肃不同产地的秦艽样品,再将此方法在秦艽样本数据集上的预测结果与XGBoost(极限梯度提升算法,eXtreme Gradient Boosting)、LightGBM(轻量梯度提升算法,Light Gradient Boosting Machine)、RF(随机森林,Random Forest)3种算法进行对比,验证方法的有效性。
1 深度森林原理与方法
深度森林(Deep forest,DF)是2017年Zhou等在深度学习领域提出的一种不同于深度神经网络(Deep Neural Networks,DNN)思想的算法探索[9]。深度森林不同于深度神经网络由可微的神经元组成,深度森林的基础构件是不可微的决策树,其训练过程不基于BP(Back Propagation)算法,甚至不依赖于梯度计算。它初步验证了关于深度学习奏效原因的猜想,即只要能够做到逐层加工处理、内置特征变换、模型复杂度,就能构建出有效的深度学习模型,并非必须使用深度神经网络。
1.1 多粒度扫描阶段
受深度神经网络结构的启发,Zhou提出通过对输入的数据特征进行多粒度扫描来更有效地挖掘特征间的联系,进而增强级联森林。多粒度扫描参考卷积神经网络结构应用了一个滑动窗口来扫描原始特征,窗口在原始特征向量上滑动,从相同大小的窗口提取的实例将用于训练完全随机树森林(CompletelyRandom Tree Forests)模型和随机森林(Random Forests)模型,然后生成类向量并连接为转换后的类概率向量,最后将不同模型输出的类概率向量进行拼接,最终生成转换特征向量,作为级联森林的输入向量。
1.2 级联森林阶段
级联森林阶段是深度森林学习样本数据特征的内在联系规律和表示层次的过程。级联森林阶段首先分别将多粒度扫描阶段得到的数据输入到级联随机森林中,之后将经过不同的森林模型处理后得到类向量与原先的转换特征向量进行拼接后输出,最后通过对最后一层生成的类向量进行回归取平均值作为模型的最终预测结果。整个多粒度级联森林即深度森林的层数是自适应调节的,只要经过交叉验证的验证准确率相比于前一层没有提升,那么级联森林的构造就此停止。
1.3 模型评价指标
在评价一个定性分析模型优劣的时候,我们通常选择借助评价指标来反映模型的精度和泛化能力,常用的评价指标有准确率(Accuracy)、召回率(Recall)、F-Score、由受试者工作特征曲线(Receiver Operating Characteristic,ROC)得到的AUC(Arear Under Curve)分数等。本文中选取准确率(Accuracy)、召回率(Recall)的调和指标F-Score和AUC分数作为模型评价指标。
2 方法
2.1 光谱采集
采集自甘肃临洮和玛曲两个产地的秦艽,药品样本由甘肃中医药大学药学院中药资源教研室鉴定,确定为龙胆科Gentiana scabra Bunge、龙胆属Gentiana(Tourn.)L植物秦艽Gentiana macrophylla。
将采集到的秦艽药材样品干燥粉碎,过5号筛,压片前放入干燥器中放置48h。每份样品取10g左右,混合均匀后压平放入石英样品杯中,通过近红外光谱仪采集光谱图,秦艽样本数据原始光谱图如图1所示。
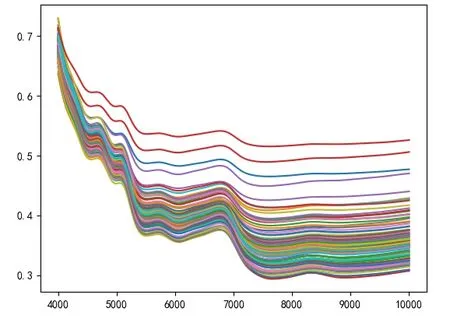
图1 秦艽原始近红外光谱图
2.2 模型的建立
在采集到的207个秦艽样本中,其中107个来自于甘肃玛曲县,100个来自于甘肃临洮县。测得的近红外光谱数据波长范围为4000~10000-1cm,每个样本包含1557个光谱波数变量。测得实验所需的样本数据后首先利用标准正态变化(Standard Normal Variate,SNV)等预处理方法对数据进行预处理,之后将数据集随机划分为训练集、测试集两类,利用训练集数据训练模型进行调参,确定模型中的未知参数,利用测试集对模型进行性能评估。
首先,将秦艽样本训练集数据代入到深度森林模型中进行训练。在多粒度扫描阶段,对特征进行扫描提取的滑动窗口个数设置为3,窗口长度分别设置为1、2、3,滑动步长为1,森林模型采用普通随机森林和完全随机森林两种森林模型。在级联森林阶段采用多层级结构,每层由4个随机森林组成,2个随机森林模型和2个完全随机森林模型,森林模型树的数量和深度、层数设置与多粒度扫描阶段相同,只要构造当前层时,经过交叉验证的模型准确率相比于前一层没有提升,那么停止构造级联森林。
3 秦艽定性鉴定与分析
为了对深度森林定性分析模型进行综合的评价,本文利用准确率(Accuracy)、召回率(Recall)的调和指标FLScore和AUC分数对模型进行性能评估的同时建立了XGBoost分类预测模型、随机森林分类预测模型和Lightgbm分类预测模型,3种模型与深度森林的样本划分方法相同。深度森林主要的参数有决策树最大深度、每个森林模型中的决策树个数、级联森林级数,其中级联森林级数可以通过深度森林算法自行确定,这里对决策树最大深度和决策树个数进行调参。根据调参结果,当森林深度为4,每个森林模型决策树个数为200时,深度森林在数据集上的准确率Acc最高。此时从4个预测模型在数据集上的评价指标F-Score来看,Xgboost分类模型为0.943,随机森林分类模型和Lightgbm分类模型均为0.963,深度森林分类模型则为0.982,F-Score作为准确率(Accuracy)和召回率(Recall)的调和指标,深度森林模型有着最高的F-Score,说明深度森林分类模型是3个模型中性能最好的模型。图2为两个产地秦艽测试集样本预测结果的ROC曲线图,AUC是ROC曲线与横轴构成的面积。AUC越大,模型效果越好。从图2可以看出,所建立的基于深度森林的秦艽分类模型效果很好,能够对两个产地的秦艽实现有效区分,由此可以看出,深度森林算法是一种有效的秦艽样本分类鉴别方法,将近红外光谱与深度森林算法结合鉴定不同产地秦艽是可行的。
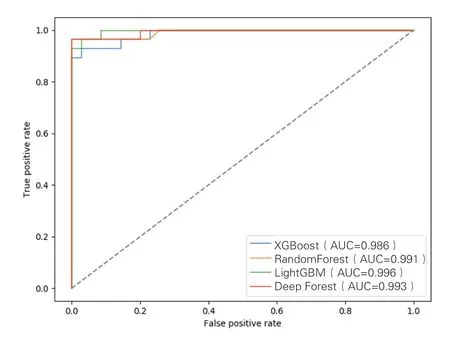
图2 不同分类模型的ROC曲线图
4 结束语
建立了基于深度森林算法的甘肃不同产地秦艽样本的分类鉴别方法,预测结果表明深度森林算法建立的分类鉴定模型对秦艽测试集样本的鉴定正确率为93%,模型评价指标F-Score可达0.982,AUC可达0.993。综合分析四项模型评价指标可知,与传统的Xgboost、随机森林和Lightgbm等机器学习算法相比,深度森林算法能够更全面地提取特征信息,同时预测结果更准确,由此可以表明近红外光谱分析技术与深度森林算法结合能够有效鉴定甘肃不同产地的秦艽样品,方法测试便捷效率高、仪器成本低,该方法能够为其他植物类中药的定性分析工作提供一定的参考。

