融合注意力机制和情感词位置的情感分析
2023-01-31周晓雯王晓晔孙嘉琪
周晓雯 王晓晔 孙嘉琪 于 青
(天津理工大学天津市智能计算及软件新技术重点实验室 天津 300384)
0 引 言
随着电子商务的快速发展,越来越多的用户将电商平台的评论信息作为消费选择的重要参考标准。据统计,评论信息的数量每天正以千万级的速率在增长,这为人们从评论中获取有用信息增加了难度。
属性级情感分析(Aspect-Based Sentiment Analysis,ABSA)旨在对句子中出现的情感目标和对应的情感词进行分类。例如,“餐厅里面的环境还不错,但是菜品真的是很难吃”,对于情感目标“餐厅环境”来说,情感分类是积极的,而对情感目标“菜品”来说,情感分类则是消极的。在真正的分类任务中,容易对二者的情感极性混淆,因此很难得到正确的情感极性判断。属性级情感分析任务主要包括两个方面:(1) 出于情感目标的提取要求;(2) 需要对情感目标对应的情感词进行提取和分类。情感目标可能是一个实体,也可能是实体的一个属性,本文统称为情感目标(aspect)。
近年来,深度学习在自然语言处理任务中得到了广泛应用,并在问答系统、机器翻译等方面都取得了令人瞩目的成绩。目前,结合卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)的模型在情感分析任务中也取得了很好的效果。Kim[1]利用卷积神经网络(CNN)提取文本中的语义关系,实现高效的情感分类。Zhu等[2]提出使用长短时记忆网络(Long Short-Term Memory Network,LSTM)构建句子的长期记忆,再利用卷积神经网络(CNN)从隐层状态中获得更具体的句子表示,获得了更好的分类效果。但此类模型无法获取长文本句子中所有单词的依赖关系,而且在处理长序列文本时,网络容易产生梯度消失问题。由于注意力机制在建模全局依赖关系上表现出的良好性能,因此有的学者将注意力机制应用到属性级情感分析任务中。例如,AEN-BERT[3]和IAN[4]利用注意力机制学习情感目标与上下文中的目标词之间的关联性,但仍无法捕获上下文中的情感目标信息,而且额外参数的消耗也加大了情感目标和上下文文本之间的建模难度。
对于情感词的提取,最常用的是基于情感词典的方法。例如,Perera等[5]利用SentiWordNet词典和句法分析器对情感词进行提取和分类。彭云等[6]提出基于情感词典和LDA的方式对情感目标和情感词进行建模。现已整理好的中文情感词典主要包括:中国台湾大学的NTUSD、知网HowNet和大连理工信息检索实验室的情感词库。上述情感词典中都存在一定的问题:(1) 情感词典中不能实时更新最新的网络用语,使得情感词分类不准确;(2) 在分类时不能考虑情感词在不同领域上的差异,容易造成歧义的问题;(3) 在情感词提取的方法中,往往都忽略了情感词在文本中的位置信息。研究发现,在大量的口语化文本中,情感目标与情感词之间的位置存在一定的相关性,因此有必要对情感词的位置信息进行提取。
为了解决上述问题,本文提出一种基于注意力编码机制和情感词位置的交互感知网络(Attentional Encoder and Position of Sentiment Polarity,AEPSP),主要贡献如下:
(1) 本文提出一种注意力编码机制对全局的语义关系进行建模,拟解决无法捕获上下文中的情感目标的问题。该模型将给定情感目标类别的信息与上下文的隐藏状态相结合,来捕获情感目标的特定表示。此外,还利用预训练的BERT模型训练动态词向量作为模型的初始输入。
(2) 本文利用短语结构文法(Context-Free Grammars,CFGs)对实验文本进行分析,提取特定领域的情感词来扩充现有的情感词典,用来解决现有情感词典不能及时包含现有的网络用语的问题。此外,在提取情感词时,本文也提取了情感词的位置信息,将情感目标和情感词的位置信息相结合,形成<情感目标,情感词>二元组用于情感分类。
1 相关工作
1.1 情感目标提取
在以往的研究中,属性级情感分析主要基于情感字典和机器学习等传统方法。研究人员大都利用语法语义的关联性和情感目标的出现频率来检测情感目标。Hu等[7]利用关联规则的方法检测情感目标,将单个复合词和复合名词作为情感目标。文献[8-9]等基于依赖分析器的方法都使用句法分析器提取情感目标。上述方法需要从大量预处理文本中获得先验知识,还依赖依存关系树的外部知识,不仅耗费大量人力,而且准确率不高。
近年来,诸多深度学习模型被应用于属性级情感分析任务中。Wang等[10]将主题建模与支持向量机(SVM)结合,识别情感目标信息。Wang等[11]提出了基于注意力机制的ATAE-LSTM模型,将注意力机制和LSTM结合对情感目标与上下文内容进行学习,然后使用注意力机制对隐层信息分配权重。Ma等[4]提出了IAN网络,设计两个注意力机制网络分别对情感目标和上下文的文本信息进行学习,同时关注句子中的重要部分和情感目标。Chauhan等[12]结合上下文信息与领域的特定信息来识别情感目标。上述方法虽然对提取情感目标有一定的作用,但是难以提取复杂文本中相对较远的情感词与情感目标之间的潜在关系。
Devlin等[13]提出BERT模型引发热烈讨论,利用transformer机制解决了自然语言处理中长文本中依赖的问题,还能够捕捉文本语句的双向关系。Liu等[14]将预训练的BERT模型和多任务文本结合进行学习。Sun等[15]通过对输入文本进行改进,将单文本改成BERT模型最擅长的双句文本进行处理。Song等[3]提出了AEN-BERT模型,利用多头注意力机制和特殊的卷积层进行结合,对情感目标的信息进行有效的提取。然而上述的模型没有更深层次挖掘给定的情感目标与上下文语句之间的关系,因此难以获得全局信息。
1.2 情感词抽取及分类
利用情感词典进行情感分类是一种无监督学习的方法。由于各个领域对情感词的倾向不同,而情感词典也没有对特定领域进行分类,因此会造成情感分类的错误。
基于词典的情感分析方法[16-18]中,利用情感词典对情感词进行提取,均取得了不错的效果。Kamal等[16]基于语义分析设计相关规则以实现<情感目标,情感词>的抽取。Desai等[17]将情感词典和浅层分析句法的方法相结合,提取语料中的情感词。顾正甲等[18]使用句法分析对情感词进行提取,从语法分析、词义理解等多角度分析语义间的关系。而上述方法未将情感词与情感目标之间的关系进行建模,因此无法有效地提取情感词。
Perera等[5]结合POS标记、SentiWordNet词典和依赖分析器,通过对情感词与情感目标建模来提取情感词信息。Qian等[19]在句子级的LSTM情感分类模型中加入情感词典的相关特征信息,有效利用语言规则,并通过改变模型的损失函数更好地理解句子与情感极性的关系。Mauro等[20]为情感词极性建立了模糊的逻辑模型,结合SentiWordNet和WordNet两种英文词典,解决了情感词在不同领域中情感极性的不确定性问题。刘亚桥等[21]指出在同一个领域的不同文本中,情感词可能会有不同的情感倾向,如手机领域,“长”在描述相机聚焦时间和电池续航时间上的情感极性是相反的。Appel等[22]对情感目标和情感词同时进行扩展,使用句法依存分析抽取情感词与情感目标之间的关系,扩展情感词库和情感目标库进行情感分类。上述的利用情感词典的知识对情感词进行抽取并分类,但未考虑情感词适用的领域,容易造成情感分类错误,而且也没有提取相关的位置信息,容易引起情感目标匹配不当的问题。
1.3 相关工作总结
本文提出AEPSP模型,通过对注意力编码机制进行改进,使情感目标与上下文信息进行更好的语义交互,对情感目标提取准确度的提升有很好的成效。在情感词的查找过程中,结合短语结构文法对现有语料进行分析,并对现有的情感词典进行扩充,在情感词的提取上取得了很好的效果。在进行情感分类时,本文基于位置信息将情感目标与情感词进行结合,解决文本歧义的问题,利用<情感目标,情感词>二元组对情感词进行分类,使得分类效果更准确。
2 AEPSP模型
图1给出了所提出的AEPSP模型的总体框架,主要由词嵌入层、特征提取层、位置融合层、输出层等方面组成。
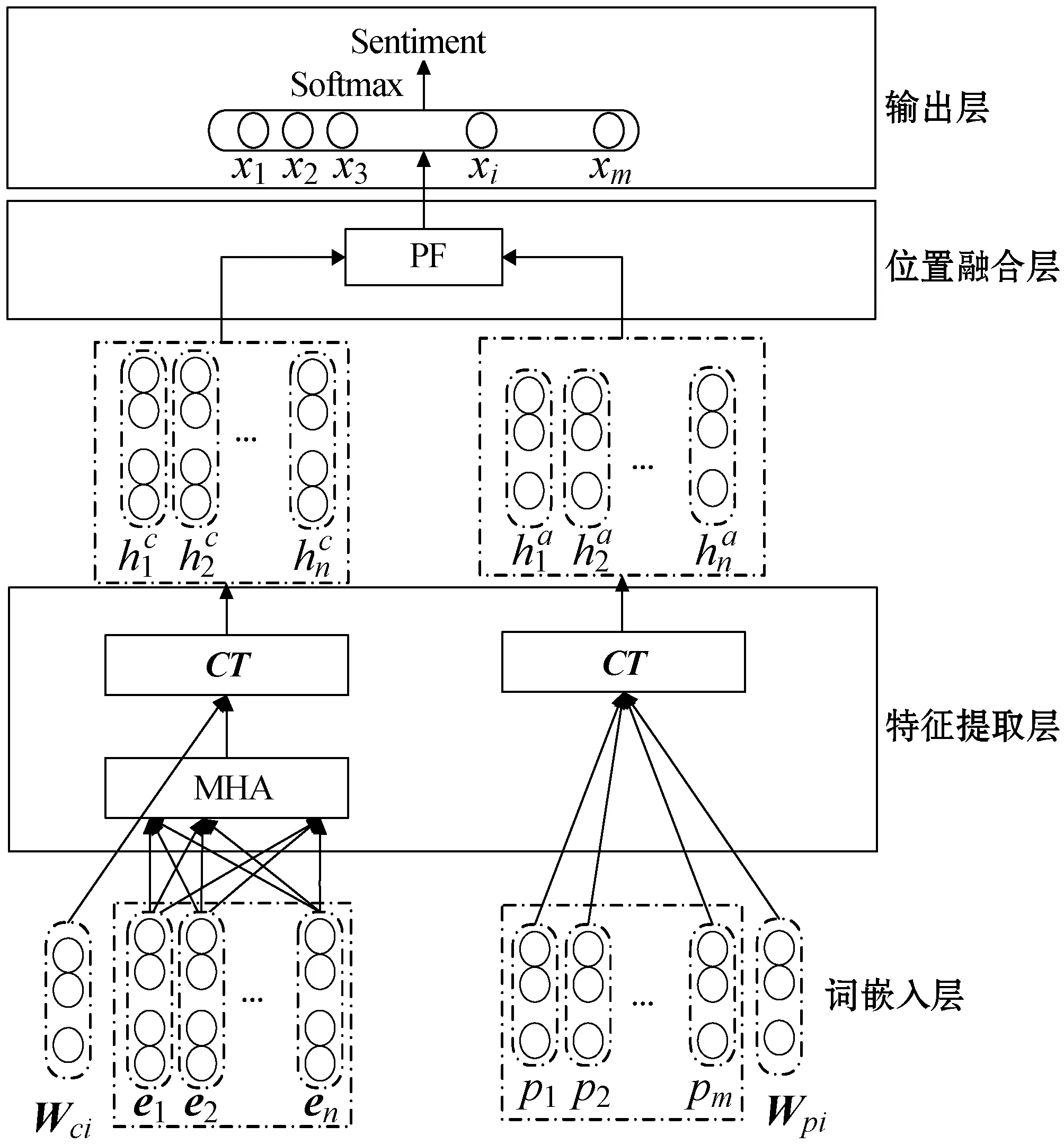
图1 AEPSP网络整体框架
2.1 词嵌入
为了便于BERT模型的训练和微调,我们将给定的上下文文本和aspect转化为“[CLS]+context+[SEP]+aspect+[SEP]”格式。假设一个句子包含了n个单词,表示为Wc={w1,w2,…,wn},一个情感目标包含m个单词,表示成Wt={wt1,wt2,…,wtm}。
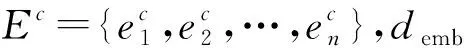
2.2 MHA机制
在情感目标提取方面,Song等[3]提出两种基于多头注意力机制的方法,其中:Intra-MHA目的是为上下文的文本进行建模;Inter-MHA是结合情感目标与上下文文本建模。本文将这两种方式进行结合,利用上下文与情感目标结合进行建模,解决了之前两种方式不能准确提取情感目标的问题。
(1) 多头注意力机制。在注意力机制中,将词向量矩阵L通过与权重矩阵结合形成了三种词向量权重矩阵Q、K、V。通过Q、K矩阵的映射学习新的映射结果。再把更高维的映射结果与V矩阵进行一次拼接,得到最后的输出结果。在更高维的映射结果中,词向量权重矩阵结合上下文的信息对权重进行重新分配。
(1)
式中:dk是输入向量的维度。
MHA可以学习n次同等运算中的不同结果,将n_heads次输出连接起来并投影到指定的隐藏维数dhid中,如式(2)和式(3)所示。
MultiHead(Q,K,V)=Concat(head1,head2,…,headn_heads)W0
(2)
Oh=Attentionh(Q,K,V)
(3)
式中:Concat是连接函数;headi是第i次计算的结果;W0是学习参数;h∈[1,n_heads]是映射的次数。

Tc=InAtt(Ec)
(4)
Ta=InAtt(Ec,Ea)
(5)
Hc([Tc;Ta])=tanh(Wc[Tc,Ta]+bc)
(6)
式中:InAtt表示交互注意力机制。
2.3 情感词提取
本文先将评论语料输入到句法分析器中进行短语结构文法分析。然后通过分词、句法的分析及情感词的提取等步骤,完成对情感词的提取工作。
(1) 扩充情感词典步骤。第一步分词,将标点符号、连词和停用词等进行处理。
第二步句法分析,抽取句子中的形容词性短语(VA)。具体的句法分析树如图2所示。本文将句法分析中为VA的词语认定为情感词。对于VA中可能存在的程度副词、否定词,例如“很”、“就是”、“不”和“不怎么”等,本文会进行保留。

图2 句法分析树
第三步情感词提取,对VA短语进行提取,按照图3的流程对情感词典进行扩充。

图3 扩充情感词典流程
(2) 情感词提取。本文利用扩充的情感词典对情感词进行提取。基本思想是对文本中的每个词语进行遍历,利用情感词典提取情感词。最终,形成一个情感词矩阵P={p1,p2,…,pm}∈Rdp×|D|,其中:dp是情感词矩阵的维度,|D|是情感词表的大小。在构建情感词矩阵的同时,本文对情感词的位置信息进行提取。情感词位置嵌入Wpi∈Rdps与2.1节中情感目标Wci∈Rdpc的位置矩阵维度相同。

Hp([Pi])=tanh(Wp[Pi]+bp)
(7)
2.4 卷积融合
卷积融合是将位置信息与提取的信息词进行融合,能够将词的信息和位置的信息进行串联得到总体的表示,如式(8)所示。
CT(h)=σ(h*W)+b
(8)
式中:σ是ReLU激活函数;h是隐层的信息;*是卷积的操作;W∈Rdhid×hid和b∈Rdhid是学习的参数。
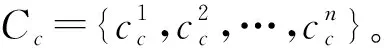
(9)
(10)
式中:Wci是前面第i个情感目标对应的位置信息;Wpi是第i个情感词相对的位置信息。
2.5 位置融合层
在同一条评论中,情感目标的位置向量与情感词的位置向量维度是相同的,其区别在于彼此的权重信息不同,因此本文将二者的隐层信息进行结合,学习二者的位置信息。最终,产生了情感目标和情感词对的最终表示Xi={x1,x2,…,xn,},如式(11)所示。
(11)

2.6 输出层
使用完整的全连接层将向量映射到目标C的空间,如式(12)所示。
(12)
式中:y∈RC是预测情感极性的分布;C是情感分类的类别数。
2.7 损失函数
本文使用交叉熵和L2-正则化作为损失函数,如式(13)定义。
(13)

3 实验与结果分析
3.1 数据集
本实验中使用的是2018年AI Challenge细粒度情感分析的中文数据集[24]。数据集被分为四种情感极性,分别是Positive、Neutral、Negative和Not mentioned。数据集中各个标签数量分布如表1所示。
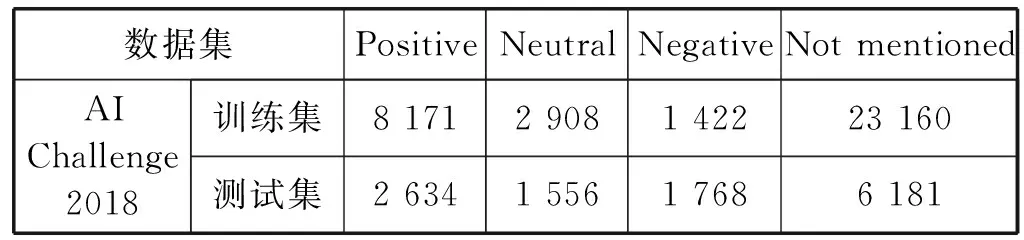
表1 实验数据集分布
2018年AI Challenge数据集[23]按照评价对象的粗粒度属性以及各个粗粒度属性所包含的细粒度属性进行分类,共分为20个类别的情感目标。例如“位置”这一粗粒度情感中包含四个细粒度情感目标,分别是“交通是否便利”“距离商圈远近”“是否容易寻找”和“排队等候时间”。除此之外,还包含该数据对应各个情感目标的情感倾向值,每个情感目标的情感倾向被标记为四种,分别1(Positive)、0(Neutral)、-1(Negative)和-2(Not mentioned)。具体数据格式如表2所示。
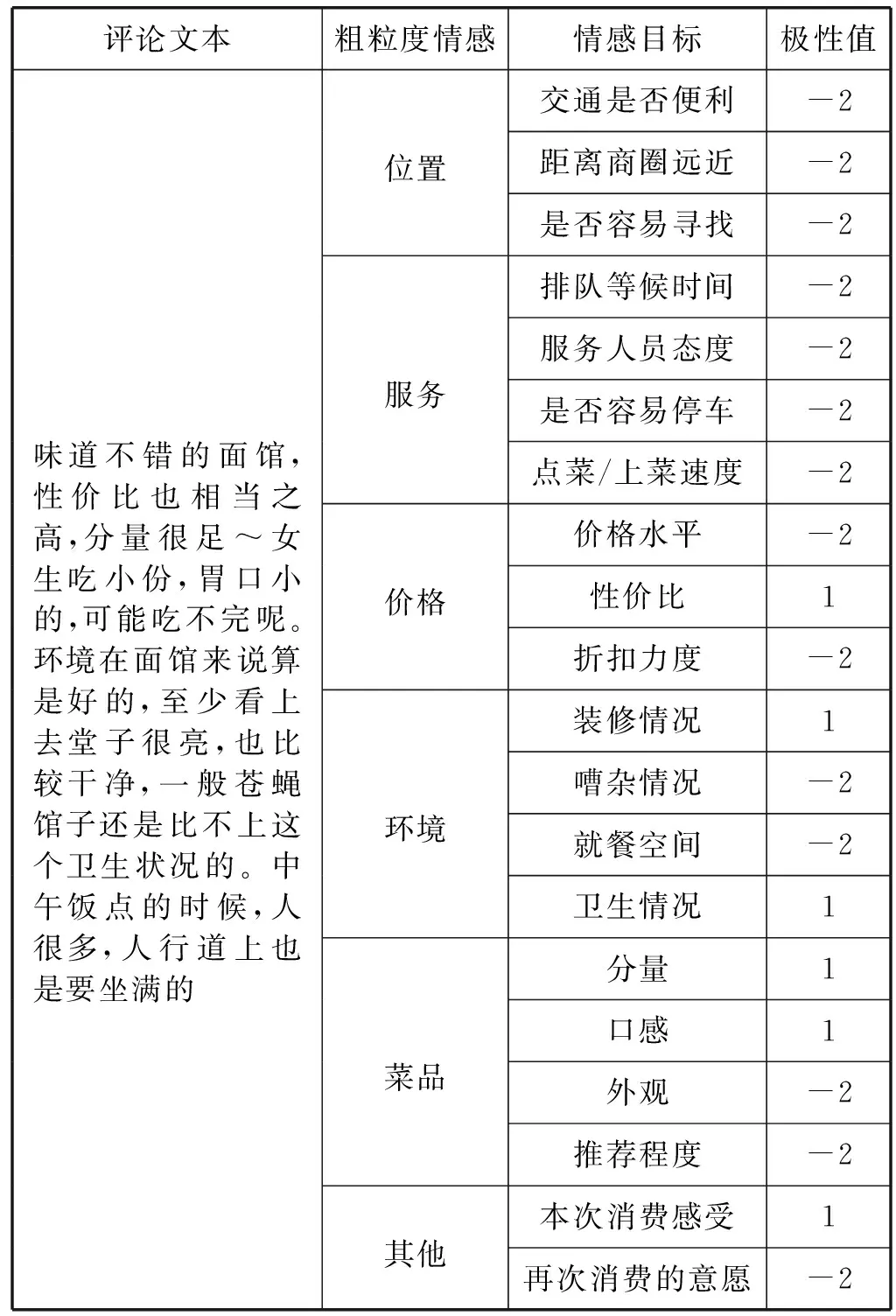
表2 实验数据集体格式
3.2 数据预处理和参数设置
本实验中,使用预训练BERT模型进行词嵌入的训练,在训练时模型会进行fine-tune。设置词向量的维度demb是768,隐藏层的维度dhid设置为300。按照中文文本的行文规则,本文将位置矩阵dpc、dps的维度设置为64。在实验过程中,batch size设置为64,学习率设置5E-5,将L2正则化项的系数λ设置为10-5。将AI Challenge 2018数据集中与训练集和测试集不相交的2 000个样本作为验证集验证模型的有效性。本文使用Accuracy和Macro-F1指标来评估模型。
3.3 数据增广
在表1中,发现各个极性的数据标签不均衡,因此我们采用EDA数据增广的模型,对标签较少的数据进行数据增广。本文对数据标签较少的语料,以同义词替换、随机替换等方式对文本进行扩增。增广后的标签如图4所示。

图4 数据增广前后标签数量对比
3.4 比较方法
为了全面评估AEPSP模型的性能,对以下10种基准模型进行实验对比。
(1) FastText[24]:主要是通过将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做Softmax多分类。
(2) AE-LSTM[11]:将情感目标映射到词向量嵌入,然后将其作用于训练的一部分。
(3) ATAE-LSTM[11]:为了增强目标嵌入的效果,将情感目标嵌入和每个文本的词嵌入结合,使用LSTM结合注意力机制得到最终的分类标述。
(4) IAN[4]:通过两个注意力编码机制的交互,学习情感目标与上下文的信息,从而生成情感目标与上下文的最终表示。
(5) AEN-Glove[3]:使用Glove转换词向量,提出注意力编码网络,将情感目标与上下文文本结合,进行情感目标提取和情感词的分类。
(6) AEN-BERT[3]:使用pre-trained BERT转换词向量并进行微调,结合注意力编码网络,将情感目标与上下文文本结合,进行情感目标提取和情感词的分类。
(7) BERT[13]:使用的是原BERT分类模型直接进行分类。
(8) BERT-SPC[15]:将序列转换成“[CLS]+context+[SEP]+target+[SEP]”的格式,利用原始的BERT模型训练。
(9) LCF-ATEPC[25]:是基于MHA注意力机制,融合了预训练的BERT和局部上下文注意力机制。该方法提出了SRD的概念,利用情感目标与情感词之间的距离提取<情感目标,情感词>二元组。
(10) AEPSP:使用BERT转换词向量,使用注意力机制抽取情感目标,利用情感词典提取情感词,计算二者的位置信息,生成<情感目标,情感词>二元组,然后进行分类。
3.5 情感分类结果分析
表3给出了AEPSP与其他模型性能的比较结果。分别从两个方面,(1) 基于注意力机制的模型;(2) 基于BERT模型。表3中的实验结果显示,BERT、BERT-SPC和AEN-BERT等模型在准确度上有明显提升,充分说明BERT预处理模型在词嵌入处理方面确实对情感分类任务存在明显的改善。

表3 情感分类的实验结果(%)
基于注意力机制的模型相较与传统多分类模型FastText来说,分类结果有较高的提升。由于基于注意力机制的模型对于长文本信息挖掘不足,因此难以提取情感目标与情感词之间的潜在关系。BERT模型对比基于注意力机制的模型分别在Accuracy和F1值都有所提升,但是BERT并没有针对某一个特定的领域进行调整,需要将先验知识加入网络中,对网络进行一定的微调,才能够对模型有整体的提升。
通过表3中实验结果的比较,AEPSP模型在特征提取方面,对情感目标和情感词的位置信息进行了考虑,对于情感目标和情感词的匹配效果更佳,分类结果也更加准确。通过对实验结果的比较,我们发现AEPSP模型在Accuracy和Macro-F1的结果上都有了提升,相较于AEN-BERT模型在Accuracy和Macro-F1分别提升了0.35百分点和1.05百分点。整体来说本文的模型较其他模型对情感目标的提取有了提升,以及集合<情感目标,情感词>二元组的情感分类能力也有了较大的提升。
3.6 结果分析
为了观察位置融合对模型性能的影响,将一条中文评论的实验数据进行提取,具体示例如图5所示。注意力编码机制结合上下文文本和情感目标的信息对文本中的情感目标进行提取,主要的权重分配如图5(a)所示。我们可以发现针对“装修环境”这个方面,在文本中提取出来的情感目标是“环境布局”,权重分配比重合理,能够合理地提取出情感目标。利用情感词典对情感词提取的效果如图5(b)所示。模型对情感词的权重合理分配,能把情感词精准提取,如“不错”“外松脆嫩”和“一般”。利用位置信息将情感目标和对应的情感词进行结合如图5(c)所示,我们发现模型能够提取出较为准确的<情感目标,情感词>二元组,如<环境布局,不错>。我们结合“装修情况”“环境布局”和“不错”,三者共同决定情感词的极性。由此我们可以看出AEPSP模型确实能够有效地对属性级情感分析进行情感分类。

(a) 情感目标权重分配

(b) 情感词权重分配

(c) 位置融合后权重分析图5 实验示例
4 结 语
本文针对多属性情感分类的任务提出一种将注意力编码机制与情感词典相结合的AEPSP网络。模型中使用注意力编码机制进行情感目标提取,并使用情感词典提取情感词,根据计算二者的位置信息提取<情感目标,情感词>二元组,进而进行情感分类。本文解决了由于多个情感目标和多个情感词易造成混淆的问题,使多属性的情感分类取得了更准确的效果。我们还将BERT预处理模型用于模型的词向量转换,并获得了最新的实验结果。实验结果充分证明了模型的准确性和有效性。在未来的工作中,我们将对情感词典进行一定的扩充,使得应用领域更加广泛。
