申威26010处理器上协程间通信的研究
2023-01-31李少迪吴俊敏周亚伟
李少迪 吴俊敏 张 屹 周亚伟
1(中国科学技术大学软件学院(苏州) 江苏 苏州 215123) 2(中国科学技术大学计算机科学与技术学院 安徽 合肥 230026)
0 引 言
并行程序间的通信是并行程序之间进行相互协作、共同完成任务的基础,随着计算机技术的广泛应用,单纯的计算任务已经不再是制约程序性能的唯一因素,程序之间的通信对程序执行的效率的影响也越来越大。尤其是在互联网、云平台等商业并行环境下,程序间的高效通信对提升系统整体性能有重要意义。
申威26010处理器是由我国上海高性能集成电路设计中心研发的一种异构众核处理器,主要应用于高性能计算领域,是“神威太湖之光”超级计算机[1]的主要组成部分。申威26010处理器在许多高性能计算领域取得了应用[2-3]。但是,由于申威26010处理器存在运行环境复杂、软件开发与底层硬件结构高度相关等特点,申威26010处理器上普通商业应用的开发移植有一些困难。因此,本文利用了协程的思想,在申威26010处理器上实现了协程的运行框架,以协程的方式代替对从核上线程的直接使用,构建了更适合开发的虚拟化环境,并且使申威26010处理器能够实现更高的并发能力。
作为协程运行框架中的一个重要部分,协程间的通信模块需要高效地实现。本文首先设计以循环缓冲区为基础的生产者-消费者模式的通道通信方式,并且基于主核与从核上支持的不同原子操作,在主核与从核上分别设计了通道通信的同步机制来保证在有多个生产者或多个消费者进行竞争时保证通道消息传递的正确性;然后,本文根据协程切换的便捷性,设计了生产者与消费者互相唤醒的机制,减少了由于程序的等待造成的时间浪费;并且,由于协程在从核上的通信性能表现较差,本文基于从核间的寄存器通信方式设计了从核阵列上新的通信方式。
1 研究背景与相关工作
1.1 申威26010众核处理器
申威26010处理器是一种由我国上海高性能集成电路设计中心自主研发设计的一种异构众核处理器,属于申威处理器系列,申威26010处理器采用片上计算阵列集群和分布式共享存储相结合的异构众核体系结构,常用于超级计算机的搭建与高性能计算程序的运行,申威26010众核处理器拥有独特的计算与存储结构,其硬件设计如图1所示。

图1 申威26010处理器
每一个申威26010处理器芯片包含了260个核心,划分为4个核组(CG),每个核组中包含了一个运算控制核心(MPE),称为主核,从属的64个计算核心(CPE),称为从核,主从核的频率都为1.45 GHz。64个从核按照8×8结构组合成一个从核阵列。每个核组通过内存控制器(MC)与一块8 GB内存相连,四个核组之间由片上网络(NoC)连接在一起,申威26010处理器基于alpha指令集设计,其中:主核支持完整的alpha指令集;从核上支持精简的alpha指令集。存储结构上,主从核都能对内存进行访问,主核有两级缓存结构,保证主核对内存的快速读写,而从核没有对内存读写的缓存,但每一个从核包含一块64 KB的局部存储器(LDM),可以存储从核上运行的程序以及从核运行所需的数据。每一个从核可以对自己的LDM进行快速读写,但不能访问其他从核的LDM,从核对主存的访问有两种模式,一种是细粒度的全局读入/读出,这种方式的通信带宽较低;另一种是粗粒度的DMA访问方式,可以将主存上的连续数据传输到从核的局存中,是申威众核处理器完成高性能计算主要的数据I/O方式。单处理器的峰值双精度浮点计算性能为3.06 Tflops。
申威26010处理器支持Linux操作系统,在支持的语言类型上,主核上支持C/C++、FORTRAN程序的运行,在从核上支持C、FORTRAN语言程序的运行。由于申威26010处理器上的主核与从核有不同的运行环境,所以对主核与从核上的程序需要分别编写与编译,最后通过混合编译将主核与从核上的运行程序打包在一个可执行文件中,通过作业提交命令提交给系统执行。
从申威26010处理器的计算构成可以看出,从核的计算能力占申威26010处理器计算能力的98%以上,所以申威处理器上程序的开发需要发挥出从核的运算能力,一般以主从核并行模式为基础,使用Athread加速线程库,在主核上完成计算任务的分配,将计算任务进行划分并分配给从核来运算执行,主核完成从核所不能完成的计算部分以及通信。主从核并行方式让从核来程序核心计算部分,主核只负责管理,是申威上高性能计算程序开发的必然选择。
1.2 申威26010处理器上协程框架的实现
协程是一种由用户控制的,不需要操作系统调度就能够进行程序的切换运行程序,实现并发的方式,协程的概念并不复杂,基本原理是在程序运行时一个运行程序主动让出自己的运行控制权,这样就能切换到其他的程序运行。由于协程相比于线程消耗的系统资源很少,因此常用于高并发场景中[4-5]。由于申威26010处理器的一个从核上仅有一个线程运行,并且不能进行线程的切换操作,从核上程序的并发受到限制,而使用协程的方式,可以突破从核的并发限制,能够在只有单线程的从核上实现多并发。于是我们团队决定在申威众核处理器上开发一个协程的运行框架。基于申威众核处理器的主从并行结构,设计实现一个集合了调度、执行、通信等模块的协程运行库,将从核上的线程以协程的方式来利用,取代原本对从核线程的直接使用,这样能获得更高的并发度。协程运行框架基于申威26010处理器硬件结构与申威Athread加速线程库,为上层应用提供协程使用接口,上层应用程序使用协程进行并发设计时,能够将计算任务进行更细的划分,从而获得更高的性能实现。协程运行库的层级如图2所示。
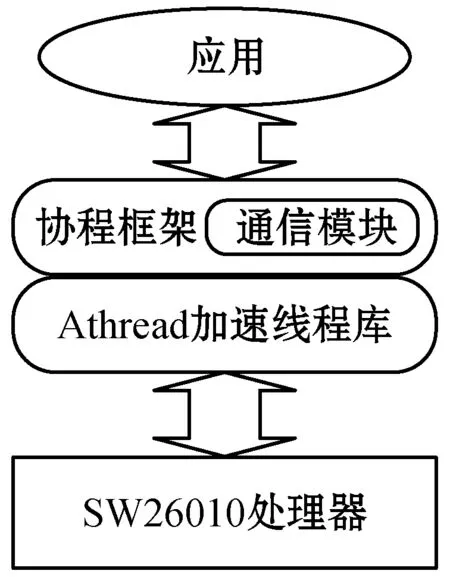
图2 协程运行库的层级
申威众核处理器上协程的实现包含以下几个部分:
(1) 调度器。调度器运行在主核上,负责完成协程的初始化任务,创建协程并根据从核的负载情况将协程分配到不同从核上执行器的执行队列,等待执行器的执行。
(2) 执行器。执行器运行在从核上,每一个从核上只能运行一个执行器,所以每个核组包含64个执行器,能够执行具体的程序,每个执行器包含了两个队列,分别是可运行任务队列与阻塞队列,可运行队列中包含能够直接运行的协程程序,阻塞队列中包含由于通信等原因阻塞的协程任务。
(3) 通信模块。协程间如果想要完成相互协作,则需要在协程间进行数据的通信,本文的主要工作即为实现协程间的通信,包含通道通信方式与基于寄存器通信的方式。
2 通道通信
2.1 通道数据结构设计
通道的设计目标是能够在主核与从核、线程、协程间进行数据的通信。本文以生产者-消费者模式实现消息通信。由于主核与所有的从核都能够访问主存,通道设计中将消息数据保存在主存中,并使用循环缓冲区的结构来存储消息数据。循环缓冲区是一种先进先出的数据结构,相对于队列减少了对地址的反复操作,增加了稳定性,被广泛应用在不同领域中[6-7]。循环缓冲区能够方便地实现生产者-消费者机制的数据交换,并且能够将数据的写入与读取操作分离开来,避免读取线程与写入线程的相互竞争,提高通信效率。本文使用循环缓冲区作为通道的基础结构,循环缓冲区的工作原理如图3所示。

图3 循环缓冲区原理
图3是通道的缓冲区,其中空白的区域代表可以接收消息的空间,实心区域代表已经存放消息的空间,read指针指向缓冲区内下一个能进行读取的数据,write指针指向下一个能存放数据的单元。使用循环缓冲区可以轻松地实现生产者-消费者模式,在一个生产者向一个消费者发送数据的过程中,生产者从通道获取write的值,根据write值获得buffer中将要写入数据的位置,若缓冲区未满,则将数据复制到buffer,同时将write的值加一,就完成了一次消息的发送。同理,当消费者读取时,读取read值并读取数据,将read值加一。当read或write超过缓冲区的容量时,通过除以缓冲区容量获得的余数来获得相应位置。当read与write相等时,说明缓冲区为空,当write与read的差值等于缓冲区容量时,说明缓冲区已满。由于生产者只影响write指针,消费者只影响read指针,所以在只有一个读线程与一个写入线程的情况下,无须对缓冲区进行同步操作,通信的效率较高。基于循环缓冲区的结构,通道的数据结构设计如算法1所示。
算法1通道的数据结构
struct channel {
unsigned char *buffer;
unsigned int elem_size;
unsigned int capacity;
unsigned int read;
unsigned int to_read;
unsigned int write;
unsigned int to_write;
list read_wait;
list write_wait;
};
其中buffer指向存放数据的缓冲区,elem_size代表一条消息数据的大小,capacity代表缓冲区的容量,write是缓冲区写入下标,read是缓冲区读取下标,to_read与to_write作为read与write的对照,用于在多生产者或多消费者并发地进行通道的发送与接收时保证数据同步。两个list是为了存放因不能向通道发送或接收消息而进入阻塞的生产者或消费者协程的队列,是通道上生产者协程与消费者协程互相唤醒机制的一部分。
2.2 通道同步机制实现
利用循环缓冲区,可以在单生产者单消费者的情况下不需要同步机制就能安全地进行消息的传递。但是在有多个生产者或多个消费者时,多个线程对同一个数据的争夺可能会产生数据被覆盖的情况,在多线程竞争时,使用同步机制是有必要的[8]。在申威26010处理器中,主核上可以有多个线程运行,每个从核上有一个线程运行,当主核或从核上运行的程序间进行通道通信时,有可能产生竞争,必须使用同步机制来保证通信的正确性。在申威异构众核处理器中,主核与从核有不同程度的指令支持,所以在主核与从核上有不同的同步机制实现。
2.2.1主核上通道同步的实现
在多线程同步机制中,可以使用CAS(compare-and-swap)原子操作对多线程竞争的情况进行处理,CAS操作能在一条指令中完成数据的比较与交换,常用于无锁算法的实现[9]。GCC中的CAS接口如下:
bool__sync_bool_compare_and_swap(type*ptr,type oldval,type newval,…)
这是返回原子操作是否成功的一个CAS接口,输入参数分别为:需要更新的变量的地址ptr,与变量进行对比的值oldval,变量要更新为的值newval。当读取到变量地址上的数据值与进行对比的值oldval相等时,就能成功地将变量的值更新为新的值newval,此时返回true,若从变量地址读取到的值与所认为的值不等,则不进行数据的更新,返回false。
当两个线程同时使用CAS指令时,只有一个线程能够成功,其他的线程将会失败,从而保证了只有一个线程能够继续对数据的处理。利用CAS操作构建通道消息发送的一致性保护机制如算法2所示。
算法2主核上的通信同步实现
do {
if(full(chan))
continue;
temp=chan->write;
if(temp !=chan->to_write)
continue;
ok=CAS(&chan->write,temp,temp+1);
} while (!ok);
//复制数据到缓冲区
CAS(&chan->to_write,temp,temp+1);
同步的消息发送中,此算法使用CAS操作并利用to_write作为write值的对照,通过比较write与to_write的值是否相等来判断是否进行发送操作,如果不相等,说明有其他的生产者正在对通道发送数据,需要等待另一个生产者完成操作;若write的值与to_write相等,说明没有其他的生产者在进行操作,就可以对通道进行消息发送;使用CAS操作更新write的值,若成功,说明没有其他的协程成功改变write值,就能根据write将要发送的数据复制到缓冲区相应位置;最后,对to_write的值进行CAS操作,使其加一,就完成了一次消息的发送。由于write与to_write的初值相等,每一次的消息发送操作对两个变量都加一,所以在没有生产者正在进行消息发送时,write的值与to_write的值一定相等,若发现两个变量的值不等时,说明有生产者在对通道进行消息的发送。从通道中接收消息时也同理,对read与to_read进行CAS操作来保证在有多个消费者进行竞争时,缓冲区内的数据不会被重复读取。这样,此算法就实现了主核上向通道发送消息以及从通道读取消息的同步。
2.2.2从核上通道同步的实现
在主核上,可以使用CAS原子操作实现通道消息发送与接收的同步,保证通信的正确性。但是在从核上,由于指令支持不同,并不支持CAS操作,仅支持对数据直接修改的原子操作,如下:
updt_addw(_n_,_addr_)
参数_n_是需要让变量增加的数值,_addr_是变量的地址。从核上的原子操作直接改变数据的值,而不进行比较,因此相比于CAS操作,同步实现更加复杂。从核上利用原子操作来实现通道的同步如算法3所示。
算法3从核上的通信同步实现
while(1) {
if(full(chan))
co_swap_out();
temp=chan->write;
if(temp==chan->to_write)
updt_addw(1,&(chan->write));
else
continue;
if(chan->write==temp+1){
//复制数据到缓冲区
updt_addw(1,&chan->to_write);
return 0;
}else{
updt_addw(-1,&chan->write);
continue;
}
}
与主核上的同步实现类似,从核上的同步使用to_write作为write的对照。不同的是,在对write值使用原子操作进行更新后,由于没有判断write的值是否曾被其他的生产者修改,依然有可能发生比较和修改操作被两条线程以比较->比较->修改->修改的方式分别执行,导致write的值并不一定为修改前加一。因此需要再次判断更新后write的值是否为预期值,若相等,说明没有其他的生产者修改write值,可以进行消息发送并修改to_write,若不等,说明其他的生产者也修改了write值,此时需要使用原子操作将write恢复为被此生产者访问前的状态,重新请求消息的发送。这样,在多个生产者访问时,最多只有一个生产者能够向通道发送消息,保证了通道消息发送的同步。但是,在多个生产者进行原子操作后对数据进行对比时,也有可能出现没有生产者读取到更新后的write值为更新前的值加一,导致所有的生产者都将write值进行回退,没有一个生产者完成对通道的消息发送,这会导致运行时间的极大浪费,也使得在同样数量的生产者或消费者互相竞争的条件下,从核上对通道的发送与接收效率可能会低于主核。
2.3 生产者与消费者之间的互相唤醒机制
在通道通信中,想要进行通信的线程有时无法进行消息通信,如通道已满时的生产者或通道为空时的消费者,这时程序只能进行等待。当以多线程方式实现时,可以选择循环访问或线程切换的机制,但是由于线程的切换消耗的系统资源较多,会导致程序的性能下降,而协程的切换完全在用户空间内进行,所消耗的资源很少,所以在协程间的通信无法进行时,我们选择让当前协程直接进入阻塞,让其他协程运行,来减少等待造成的时间占用。
当一个消息生产者协程向通道发送数据时,首先会判断通道缓冲区是否已满,若未满,则发送消息并继续运行;若已满,则此消息无法发送,通道会进入阻塞,并由协程执行器调度其他的协程来运行。阻塞的协程将被记录在通道的等待队列read_wait上。被阻塞的协程不会自动唤醒,也不是由协程执行器唤醒,而是当一个消费者协程从通道取出消息,使通道不再为满时,会唤醒一个等待发送的生产者,此时阻塞的生产者协程重新进入运行队列继续运行,并有较大概率成功向通道内发送消息。同理,消费者协程在通道为空时也会进入阻塞,记录在队列write_wait上,并被一个向通道发送数据的生产者协程唤醒。这种互相唤醒的机制,让一个协程在不能进行通信的情况下直接让出执行权,让其他的协程运行,而不是进行循环等待,也没有像线程切换那样消耗大量的系统资源,更有效地利用了处理器核心的运算能力。生产者与消费者互相唤醒的流程如图4所示。
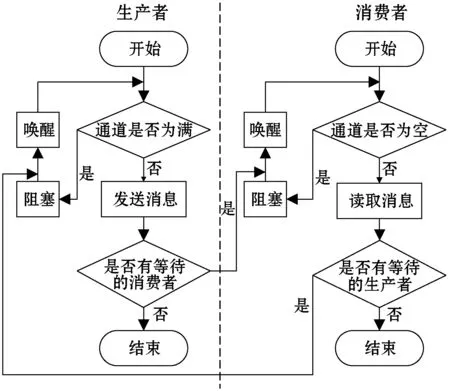
图4 生产者与消费者的互相唤醒
互相唤醒的机制保证了一个协程因为不能进行发送或接收操作而进入阻塞,当它被唤醒时,通道的状态能够让这个协程进行消息发送或接收。相比于轮询或者线程的切换,协程之间的互相唤醒的方式消耗系统资源更少,因此程序运行的效率更高。
3 从核间基于寄存器通信的通信方式
3.1 寄存器通信
在进一步的实验测试中,我们发现,从核上通道通信的效率远低于主核,原因是:(1) 由于从核访问主存的性能较低;(2) 由于从核间多生产者或多消费者竞争时同步机制产生的性能损失大于主核。由于申威26010众核处理器的主要计算能力来源于从核,因此提高从核上的通信效率对提高整个系统的性能有重要意义。于是,本文结合申威众核处理器上独特的从核间寄存器通信机制,在从核上实现更高效的数据通信。寄存器通信是一种申威众核平台上独特的通信机制,可以在一个从核阵列上同行或同列的从核间高效地传输数据。同行间寄存器通信的接口如下:
LONG_PUTR(var,dest)
LONG_GETR(var)
LONG_PUTR用于向同行的从核发送数据,其中:参数var代表进行交换的数据,dest指示目标从核,dest低四位有效,当最高位为1时向整行进行广播,最高位为0时,低三位代表目标从核在行或列中的位置。寄存器通信每次发送数据的大小为256位,并且延迟很低。LONG_GETR用于接收发送到本从核的通信缓冲中的数据,当通信缓冲为空时,会等待直到接收到数据。使用寄存器通信可以为申威26010处理器上的程序带来很大的性能提升[10-11]。
3.2 基于寄存器通信的生产者-消费者通信实现
从寄存器通信的接口中可以看到,使用一次寄存器通信只能与同行或同列的其他从核进行通信,不能向不同行且不同列的从核发送数据。所以,如果想要向一个不同行且不同列的从核发送数据时,需要一个从核作为中转,如图5所示。
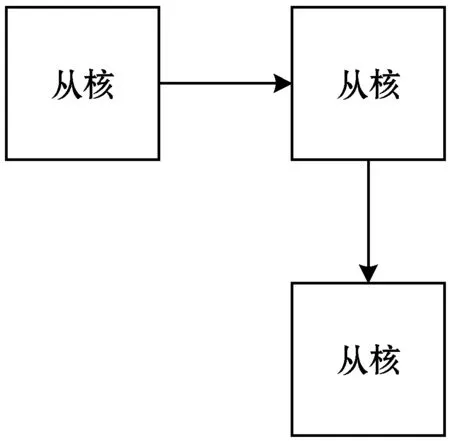
图5 向不同行也不同列的从核发送数据
以图5中的方式就形成了一个单生产者-单消费者的消息通信。只是一个从核需要作为中转而无法执行计算任务。并且这个从核与两个从核中的其中一个在同一行,与另一个在同一列。从阵列的结构中可以轻松地看出,可以作为中转核的从核有两个。作为中转的从核从生产者从核由寄存器通信接收消息数据,再通过寄存器通信发送到消费者从核。
利用从核进行中转可以让任意位置的生产者与消费者之间进行快速的消息传递,但是中转的从核不能执行计算任务,这会导致计算资源的浪费。为了在整个从核阵列上最大化用于计算的从核的数量,减少中转导致的计算能力损失,应当尽可能减少中转的从核数量。由于一行上的从核如果需要向其他行发送数据,至少需要一个核向外发送数据,所以使用8个从核作为中转,就能完成整个阵列上从核之间的数据传递。整个从核阵列上生产者-消费者的通信设计如图6所示。

图6 整个从核阵列上生产者-消费者的通信
图6中第一列的8个核作为中转核,随机向后四行的从核发送消息,前四行其他列的从核作为生产者,进行消息数据的生产,后四行其他列的从核作为消费者,接收消息并处理。通过这种方式,在从核阵列的64个从核中,形成了28个生产者与28个消费者的生产者-消费者模式通信,并且每一个生产者生产的消息都有可能被任意一个消费者接收,在一个从核阵列上实现了最大规模的生产者与消费者的随机配对。
4 测试结果与分析
4.1 通道通信测试
为了了解通道通信的效率,需要在不同的条件下对通道通信的性能进行测试。由于通道的同步机制,需要在不同的生产者/消费者数量条件下,在主核与从核上进行通道通信效率的测试。本文按照以下步骤来进行通信性能的测试:(1) 创建通道,通道的消息数据类型设置为整型,通道的容量设为能够容纳所有生产者发送的消息的容量,以避免通道充满而产生生产者协程的阻塞从而导致消息发送的性能下降。(2) 模拟消息数据的生产,使用随机生成的整型数据作为生产者要发送的消息数据,然后经过多次向通道发送获得总时间,取平均值作为一条消息发送的时间。(3) 模拟消费者接收消息,消费者从已有足够数据的通道内获取消息数据,多次获取消息的总时间取平均值作为一条消息获取的时间。在不同条件下处理一条消息的平均时间如表1所示。
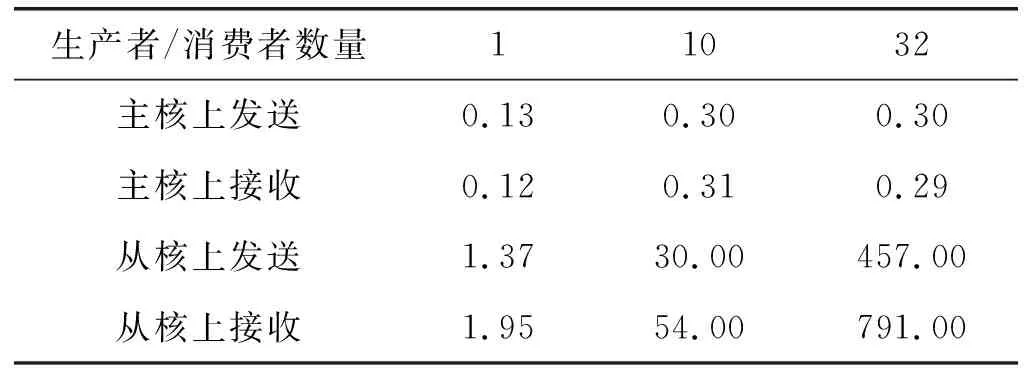
表1 不同条件下处理一条消息的平均时间 单位:μs
可以看出,从核上通道的通信效率低于主核,并且在有多个生产者或多个消费者进行竞争时,通道通信的时间明显增加,并且从核上通信时间增加的幅度远高于主核。
从核上的通信效率低于主核有两方面的原因,(1) 从核访问主存的性能低于主核;(2) 从核上的同步机制相比于主核上的同步机制会造成更高的性能损失,当并行的生产者/消费者之间发生竞争时,从核上的同步机制会产生更多的回滚操作,从而使得通信的平均时间增加。
4.2 基于寄存器通信的从核间通信测试
需要将基于寄存器通信的通信方式与从核间的通道通信进行比较,以观察新的通信方式相比于通道通信获得的性能提升。本文将测试单生产者-单消费者情况下的性能与使用了整个从核阵列进行通信的整体性能。同样使用随机生成的整型数据作为消息数据,使用多次发送的平均值作为一条消息处理时间。结果如表2所示。

表2 基于寄存器通信的通信方式平均一条消息处理时间 单位:μs
将表2中的结果与表1中从核间通道通信的平均时间进行对比可以看出,基于寄存器通信的方式处理一条消息的时间远低于通道通信,并且在有多个生产者相互竞争的情况下,单条消息的发送时间相比于只有一个生产者的情况下也大幅增加,说明寄存器通信同样存在着同步导致通信时间增加的情况。由于基于寄存器通信的方式使用了部分从核作为中转核,不参与消息的生产与接收,所以为了更准确地描述整体通信性能与使用从核数量的关系,本文使用基于寄存器通信方式的单个从核提供的平均带宽与通道通信单个从核提供的平均带宽进行对比,结果如表3所示。

表3 单个从核提供的平均带宽 单位:GB/s
可以看出,在单生产者-单消费者的情况下,基于寄存器通信的方式相比于通道通信单个从核能提供的带宽提升了82倍,而使用了整个从核阵列进行生产者-消费者通信的情况下,基于寄存器通信的方式下单个从核提供的带宽相比于通道通信方式下有658倍的提升。这说明基于寄存器通信的方式有效地提高了从核间通信的性能。
5 结 语
本文为申威26010处理器的协程运行框架设计了生产者-消费者模式的通信,在适用于主核与从核的通道通信的设计中,本文基于循环缓冲区设计了通道的数据结构,并基于主核与从核上不同的原子操作设计了主核与从核上通道消息收发的同步机制,保证了通信的正确性,还设计了生产者与消费者的互相唤醒机制,避免等待造成的计算能力损失。为了进一步提高从核间通信的效率,本文基于申威26010处理器独特的寄存器通信机制,设计一种从核阵列上的从核间相互通信的方式,极大地提高了从核之间进行消息通信的效率。本文的研究为申威26010处理器上的协程运行提供了有效的通信模块,为上层应用开发提供了高效的通信接口,也为申威26010处理器提供了一种低粒度的通信实现。
