龙芯指令系统架构技术
2023-01-30胡伟武汪文祥吴瑞阳王焕东徐成华张福新
胡伟武 汪文祥 吴瑞阳 王焕东 曾 露 徐成华 高 翔 张福新
1 (中国科学院计算技术研究所 北京 100190)
2 (中国科学院大学 北京 100049)
3 (龙芯中科技术股份有限公司 北京 100095)
4 (处理器芯片全国重点实验室(中国科学院计算技术研究所) 北京 100190) (hww@loongson.cn)
我国的CPU研发应采用兼容指令系统还是自主研发指令系统是学术界和产业界长期争论的一个话题.兼容指令系统的优点是可利用现有的成熟软件生态,缺点是长远发展受制于人且不利于自主软件产业的发展.自主研发指令系统则反之.本文介绍充分考虑兼容需求的龙芯自主研发指令系统架构——龙架构(Loongson instruction set architecture, LoongArch).龙架构[1]包括基础部分、向量扩展、虚拟化和二进制翻译扩展3个扩展部分,共计近2 000条指令.
LoongArch具有自主设计、技术先进、兼容生态3方面特点.LoongArch从整个架构的顶层规划,到各部分的功能定义,再到细节上每条指令和每个寄存器的编码、名称、含义,全部自主重新设计,具有充分的自主性.龙架构摒弃了传统指令系统中部分不适应当前软硬件设计技术发展趋势的陈旧内容,吸纳了近年来指令系统设计领域诸多先进的技术发展成果,易于硬件的高性能低功耗设计和软件的编译优化以及操作系统、虚拟机的开发.龙架构在设计时充分考虑兼容生态需求,融合了包括x86,ARM在内国际主流指令系统的主要功能特性,同时依托龙芯团队在二进制翻译方面十余年的技术积累创新,不仅能够实现现有龙芯电脑上应用二进制的无损迁移,而且能够实现多种国际主流指令系统的高效二进制翻译.
软件生态是龙芯指令系统架构能否成功的基础和关键.除了迁移BIOS和操作系统内核到LoongArch,还需要3+3+3的主要编译系统.第1个“3”是指3个高级语言编译器,包括GCC,LLVM和GoLang.第2个“3”是指 3个重要虚拟机,包括 Java,JavaScript和.NET.第3个“3”是指3个二进制翻译系统,包括从MIPS到LoongArch的二进制翻译系统、从x86到LoongArch的二进制翻译系统和从ARM到LoongArch的二进制翻译系统.在上述“3+3+3”主要编译系统的基础上,能够突破指令系统的壁垒,构建LoongArch的软件生态体系.
支持LoongArch的龙芯3A5000处理器[2]芯片已经成功量产.在3A5000上成功运行了完整的Linux操作系统,并通过二进制翻译技术高效运行原有龙芯计算机上的MIPS应用、x86计算机Linux和Windows系统上的各种应用.实测结果表明,在相同微结构的情况下,LoongArch的应用性能普遍优于MIPS,部分应用的性能提高超过 40%.SPEC CPU2000 从 MIPS到LoongArch的二进制翻译效率达90%以上,从x86到LoongArch的二进制翻译定点和浮点效率分别为QEMU[3]的3.6倍和47.0倍.上述测试结果表明,同时实现兼顾自主和兼容的指令系统是可行的,为建立自主可控的信息技术体系和产业生态打下坚实的基础.
1 LoongArch介绍
LoongArch继承了精简指令集计算机(reduced instruction set computer ,RISC)的设计传统,其指令长度固定且编码格式规整,大多数指令为三操作数,仅有load/store访存指令可以访问内存.龙架构按照地址空间大小可分为32位和64位2个版本,分别简称为LoongArch32和 LoongArch64,LoongArch64应用级向下二进制兼容LoongArch32.下面从指令编码、组成部分和对二进制翻译的支持3个方面对龙架构进行介绍.
1.1 指令编码
LoongArch中的所有指令长度均为32位,且要求指令地址4字节边界对齐,当指令地址不对齐时将触发地址错例外.
LoongArch中指令编码风格规整.所有寄存器操作数域都从第0位开始从低到高依次摆放,操作码都是从第31位开始从高到低依次摆放.如果指令中包含立即数操作数,那么立即数域位于寄存器域和操作码域之间,根据不同指令类型有不同的长度.具体来说, 包含9种典型的指令编码格式,即3种不含立即数的编码格式2R,3R,4R, 以及6种含立即数的编码格式 2RI8,2RI12,2RI14,2RI16,1RI21,I26.图1给出了这9种典型编码格式的具体定义.
1.2 组成部分
LoongArch采用基础部分加扩展部分的模块化组织形式.一个兼容龙架构的CPU,除实现必需的基础部分(Loongson base, LBase)外,可根据实际需求选择实现各扩展部分.目前龙架构已定义的扩展部分包括:虚拟化(Loongson virtualization, LVZ)扩展、二进制翻译(Loongson binary translation, LBT)扩 展、128位向量扩展(Loongson SIMD extension, LSX)和 256位高级向量扩展(Loongson advanced SIMD extension,LASX).

Fig.1 Instruction encoding format of LoongArch图1 LoongArch指令编码格式
LoongArch的基础部分包含用户态和核心态2方面内容.用户态部分定义了常用的整数和浮点数指令,能够充分支持现有各主流编译系统生成高效的目标代码.核心态部分在处理器特权等级、例外和中断处理、存储管理以及配套的控制状态寄存器等方面给出了明确规范,旨在支持目前主流的类Unix操作系统.与龙芯CPU原来实现的MIPS架构相比,龙芯基础架构充分利用后发优势,摒弃了传统指令系统中部分不适应当前软硬件设计技术发展趋势的陈旧内容,同时积极吸纳了近年来指令系统设计领域诸多先进的技术发展成果,主要特点包括:
1)取消传统RISC指令系统中一些过时指令.包括取消陷阱指令和进行溢出判断的运算指令,整数乘除运算的结果将直接写入通用寄存器而非单独的HI/LO寄存器.这些过时指令或者不利于指令流水线的高效实现,或者当前主流编程语言已经很少使用.
2)增加一些便于实现且有利于软件提高性能的指令.引入基于PC的运算指令并为间接跳转指令添加立即数偏移,同时增加相对PC跳转指令的偏移范围,这些调整有利于改善位置无关代码中长跳转和数据访问的指令(序列)的执行效率,并且能够大幅度减小全局偏移表(global offset table,GOT)的规模,从而降低因GOT规模过大带来的维护和访问开销.增加原子访存修改指令,解决传统LL/SC指令在大规模并发执行情况下失效重试开销急剧增加的问题.
3)取消转移指令延迟槽.对于现代多发射的乱序动态流水线,延迟槽无法起到提升性能的作用,还容易成为实现负担.
4)由硬件负责处理所有流水线的冲突,允许普通访存指令的地址非对齐访问,由硬件维护指令和数据缓存之间的数据一致性.这些功能简化了软硬件的界面,降低了应用迁移的成本.
5)优化处理器特权态、例外系统和计时系统.处理器特权等级从MIPS的用户态、监管态和核心态3个状态调整为 PLV0,PLV1,PLV2,PLV3 四个状态.例外系统从多个例外公用入口调整为每个例外独立入口.计时系统的计时频率恒定,不再随处理器核频率变化而变动,消除处理器动态功耗管理带来的问题.
6)取消地址空间的固定分段方式以及地址段与特权等级、映射方式间的固定绑定,代之以单一平整(flat)寻址空间且所有存储管理配置信息软件均可动态调整.
7)支持控制寄存器的原子修改、规范核外控制寄存器且使用独立的寻址空间.增加控制寄存器的原子修改支持以简化系统软件实现.大幅度拓展核内控制寄存器寻址空间,为指令系统核心态部分的后续演进解除束缚.规范核外控制器并使用独立的寻址空间,将各种多核多路系统的底层硬件信息封装为固定统一格式呈现给软件.
LoongArch的虚拟化扩展部分定义了一系列硬件支持特性,旨在提升系统虚拟化实现的性能,涉及处理器虚拟化、内存虚拟化和I/O虚拟化3个方面.其具体内容主要包括客户机专用的运行模式和特权资源、例外分级处理、2级地址翻译加速以及中断虚拟化.
LoongArch的二进制翻译扩展部分引入了一系列硬件特性,进而以软硬件协同的方式大幅度提升跨指令系统二进制翻译执行效率.有关这部分的详细介绍将在本文的2.2节展开.
LoongArch下的向量扩展部分定义了一系列单指令多数据(SIMD)指令,利用数据级并行性提升程序执行性能.向量扩展部分可进一步分为向量扩展(LSX)和高级向量扩展(LASX),后者在前者基础上将操作向量位宽从128位增至256位并进一步扩展.
上述基础部分加扩展部分的组成形式对于Loong-Arch32和LoongArch64架构均适用.从功能角度而言,各部分中属于LoongArch32的内容均包含在LoongArch64中.各部分中的用户态相关内容,LoongArch64向下二进制兼容LoongArch32.
1.3 LoongArch的ABI优化
LoongArch的应用程序二进制接口(application binary interface, ABI)与龙芯 CPU 原使用 MIPS 相比对寄存器使用约定进行了优化.表1和表2分别是64位MIPS和LoongArch的通用寄存器使用约定.与MIPS相比,LoongArch有5方面差异:
1)取消了汇编暂存器(at).MIPS的一些汇编宏指令由多条硬件指令合成,汇编暂存器用于数据周转.LoongArch指令系统的宏指令可以不用周转寄存器或者显式指定周转寄存器,汇编暂存器不再必要了,这可以增加编译器可用寄存器的数量.
2)取消了预留给内核的专用寄存器(k0/k1).MIPS预留2个寄存器的目的是支持高效异常处理,可以省去异常处理过程中保存上下文到内存中的开销.LoongArch提供了数据保存状态控制寄存器来高效暂存数据,可以在不预留通用寄存器的情况下保持高效实现,给编译器留下了更多的可用寄存器.
3)取消了gp寄存器.MIPS中用gp寄存器指向GOT以协助动态链接器计算可重定位的代码模块的相关符号位置.LoongArch指令集支持基于PC的运算指令,能够用其他高效的方式实现动态链接,不再需要额外花费一个通用寄存器.
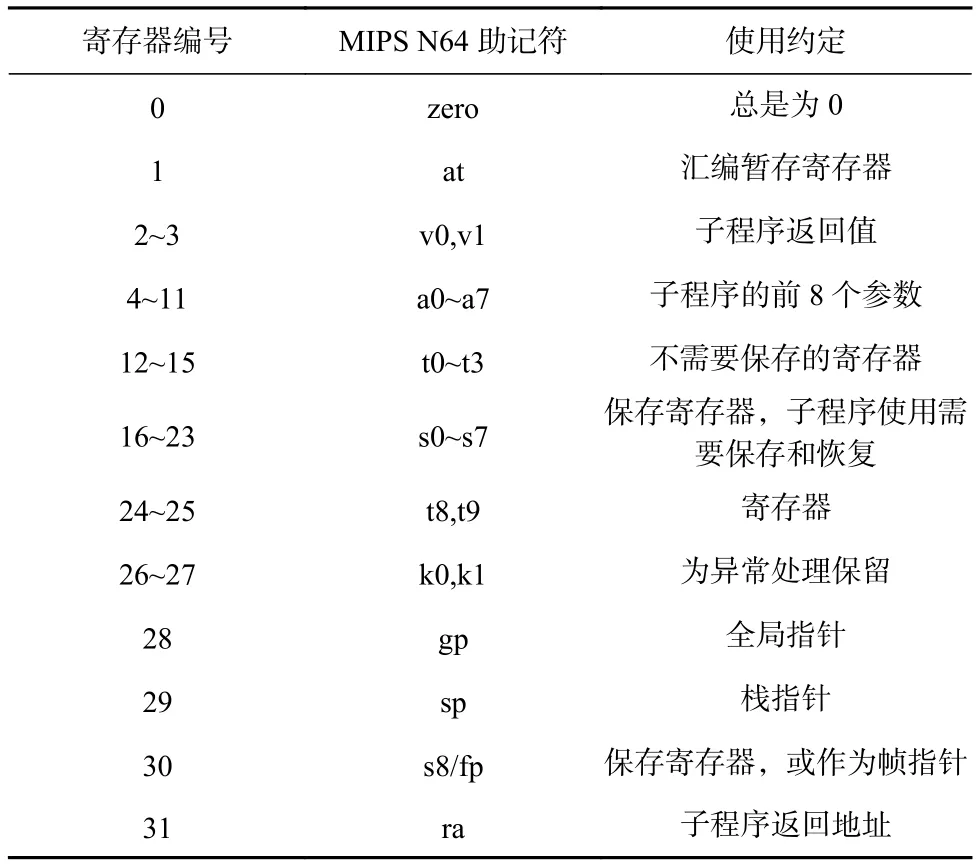
Table 1 MIPS N64 Integer Register Usage Convention表1 MIPS N64 定点寄存器使用约定
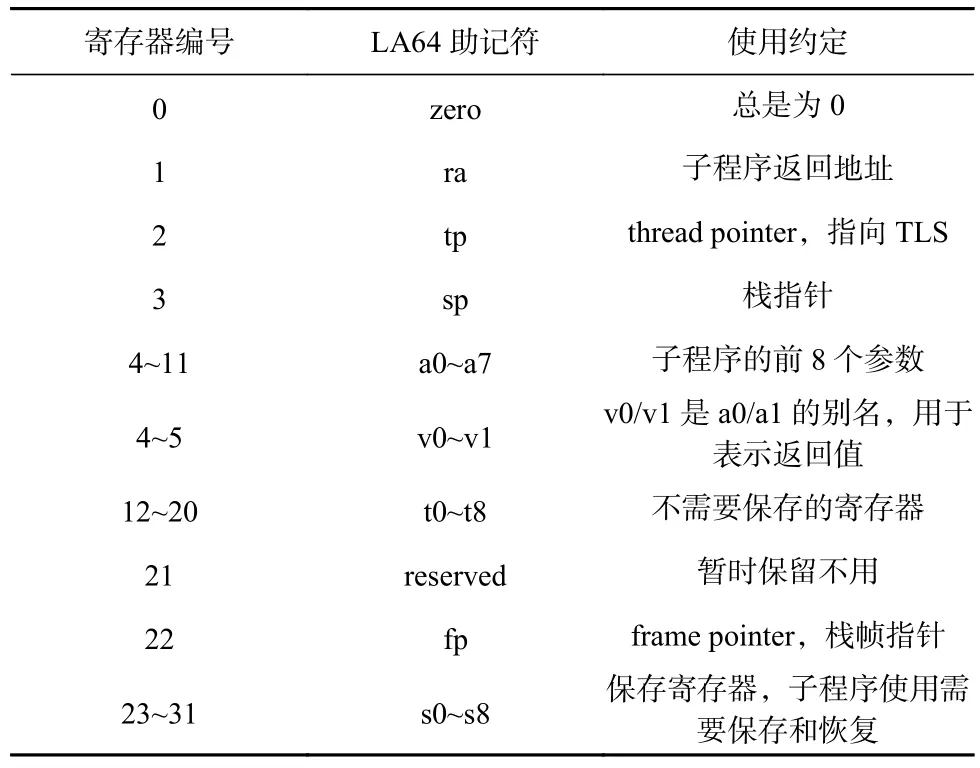
Table 2 LoongArch64 Integer Register Usage Convention表2 LoongArch64 定点寄存器使用约定
4)复用参数寄存器和返回值寄存器,参数寄存器a0/a1也被用作返回值寄存器.这也是现代指令系统比较常见的做法,它进一步增加了编译器可用的通用寄存器的数量.
5)增加了线程指针寄存器tp,用于高效支持多线程实现,它总是指向当前线程私有存储(thread local storage, TLS)区域.
1.4 LoongArch对二进制翻译的支持
二进制翻译技术是实现跨指令系统兼容的重要手段.二进制翻译技术在宿主机(host)上用软件模拟出一个目标机/客户机(guest)指令系统兼容的CPU,从而在宿主机上执行客户机的二进制代码.如在LoongArch计算机上模拟x86指令系统,从而实现与x86兼容.二进制翻译的最大问题是效率问题,用软件模拟的CPU比硬件直接实现的CPU慢很多,一般有数量级的差异.
通过硬件支持和软硬件协同可以有效提高二进制翻译的效率.LoongArch在认真分析 x86,ARM,MIPS,RISC-V指令系统主要特点的基础上,增加了为提高x86,ARM,MIPS,RISC-V二进制翻译性能至关重要的指令功能.下面举例说明LoongArch对x86二进制翻译的具体支持.
1)增加生成运算标志的运算指令以及根据运算标志生成转移条件的指令.x86定义了独立的运算结果标志寄存器EFLAGS,由运算指令在产生结果数值的同时予以更新,转移指令依据EFLAGS的值进行跳转判断.若采用纯软件方式模拟一条x86运算指令对于EFLAGS的更新需要几十条指令.图2(b)给出了模拟图2(a)中x86指令“SUB ECX,EDX”运算结果及常用的四位标志(SF,ZF,OF,CF)的 LoongArch 基础指令序列所需要的近30条指令.为了降低软件模拟运算结果标志的二进制翻译开销,LoongArch定义了一组专门用于产生x86运算结果标志的指令,这类指令仅将运算结果标志写入到通用寄存器中.同时,LoongArch还定义了根据通用寄存器中的运算结果标志值,生成x86转移指令相对应的转移条件的指令.图2(c)给出了采用二进制翻译扩展的LoongArch翻译图2(a)中x86指令“SUB ECX,EDX”的指令序列,与仅采用基础指令的翻译结果相比指令数大幅度减少.
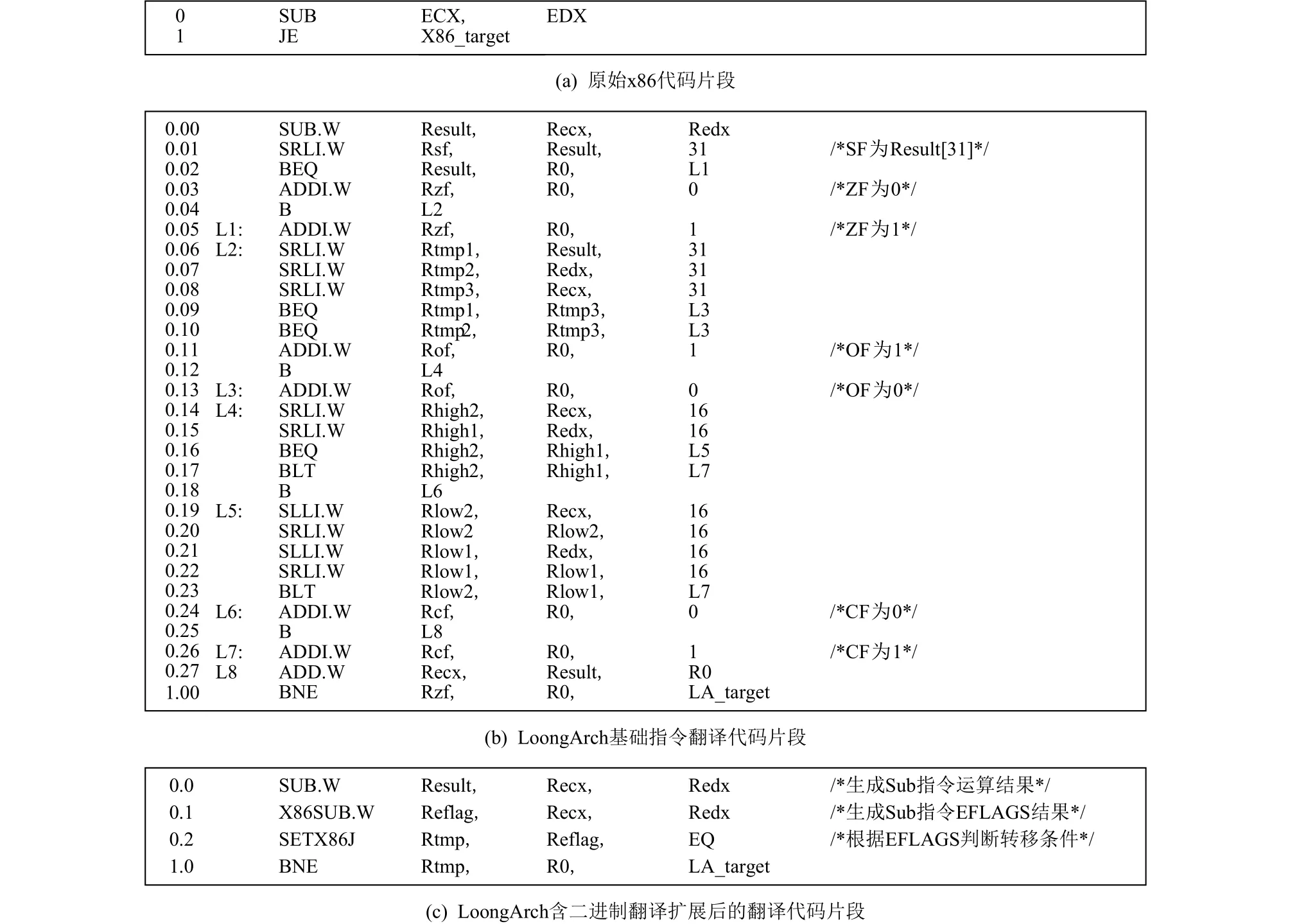
Fig.2 Example of x86 EFLAGS translation图2 x86 EFLAGS 翻译示例
2)增加x86浮点寄存器特殊寻址模式和数据格式的支持.x86架构的x87浮点部件有8个浮点寄存器采用栈寻址模式,即x86浮点指令码中只有所访问寄存器相对于栈顶的偏移值,其加上浮点状态字中的TOP域的值才是要访问的寄存器编号.如果在二进制翻译中动态计算上述浮点寄存器号,每条访问浮点寄存器的浮点指令需额外花费多条指令.为解决这一问题,LoongArch定义了3位的TOP寄存器、浮点寄存器的TOP寻址模式以及用于操作TOP寄存器和切换TOP寻址模式的指令.当处于TOP寻址模式时,普通浮点指令中浮点操作数的寄存器号都是这些域的值与TOP寄存器中的值相加后的结果, 从而省去了软件计算实际寄存器号的翻译开销.此外,x87浮点部件支持40位的扩展单精度和80位的扩展双精度浮点运算,与RISC处理器中32位单精度和64位双精度不同,为此LoongArch定义了将x87的浮点数与LoongArch的浮点数进行格式转换的指令.
3)扩展TLB MMU功能支持客户机虚地址到宿主机实地址的硬件直接翻译.系统级二进制翻译过程中所有客户机访存指令都要2级虚实地址转换,即先把客户机的虚地址翻译成客户机的物理地址,再将客户机的物理地址作为宿主机的虚地址翻译成宿主机的物理地址.在QEMU[1]中,客户机虚地址到客户机物理地址的转换是通过软件模拟完成的.图3(b)中给出模拟图3(a)中x86访存指令时,使用LoongArch基础指令模拟将客户机虚地址转化为客户机物理地址所需的指令序列,共有14条指令且其中包含2条访存.为降低实现开销,LoongArch的TLB可以同时存放“宿主机虚地址=>宿主机物理地址”和“客户机虚地址=>宿主机物理地址”2种类型的页表项,前一类型的页表项由宿主机操作系统中的普通页表提供,后一类型的页表项由二进制翻译虚拟机中维护的影子页表提供.2类页表项在填入TLB的过程中将被标记上不同的页表类型标识.访存指令在查找TLB的过程中,也将根据自身携带的是宿主机虚地址还是客户机虚地址,仅查找页表类型标识与之对应的TLB表项.当查找过程发生异常时,不同页表类型标识所触发的TLB例外类型及其入口也不同.访存指令所携带虚地址的类型判定,可以采用预设地址空间或访存指令前缀指定2种方式.图3(c)中给出了采用前缀指令方式判定的翻译指令序列,只需要2条指令.具体的芯片实现还可以选择用未使用的某些虚拟地址位来表示地址空间,这样可进一步省去前缀指令,只需要一条指令.
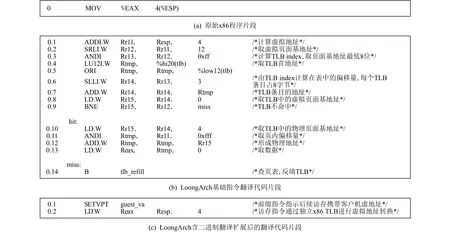
Fig.3 Example of x86 memory access instruction translation图3 x86访存指令翻译示例
4)增加宿主机寄存器数量,避免用宿主机的内存模拟客户机的寄存器.对客户机寄存器的高效模拟是提高二进制翻译性能的关键.如果宿主机没有足够的寄存器,用内存单元来模拟目标机器的寄存器,就会大幅度降低性能.x86有8个通用寄存器、8个浮点寄存器和16个256位的浮点/向量混用寄存器,少于RISC架构下通用寄存器、浮点/向量寄存器的个数,可以采用一一对应的模拟方式.在MIPS等RISC架构中,采用一一对应的模拟方式极容易出现翻译过程中无临时寄存器可用的情况.为此LoongArch定义了若干便签寄存器,用于二进制翻译系统临时存储数据.
2 龙芯3A5000及其软件生态建设
2.1 龙芯3A5000处理器及其计算机系统
龙芯3A5000是实现LoongArch的第一款龙芯处理器.龙芯3A5000通过片上交叉开关集成4个64位的四发射超标量LA464处理器核、16 MB共享三级缓存、2个64位DDR4内存接口、2个16位Hyper-Transport3.0接口.3A5000使用12 nm工艺实现,主频2.3~2.5 GHz,内存控制器接口速率为 DDR4-3200,Hyper-Transport接口速率为6.4 Gbps.3A5000通过HyperTransport接口连接龙芯7A1000或7A2000桥片,并通过桥片连接硬盘、网络、显示器等组成计算机系统.龙芯3A5000四核处理器结构如图4所示,其中左半边为LA464处理器核结构,右半边为3A5000处理器顶层结构.
LA464处理器核采用四发射乱序执行结构.基本流水线包括PC、取指、预译码、译码I、译码II、寄存器重命名、调度、发射、读寄存器、执行、提交I和提交II共12级.具有4个定点运算部件、2个全功能浮点运算部件、2个访存部件.重排序缓存为128项,定点、浮点、访存3个发射队列各为32项.定点和浮点物理寄存器堆各128项.一级指令缓存和一级数据缓存均为 4路组相联,各 64 KB,二级牺牲(Victim)缓存为 16 路组相联,共 256 KB,缓存行大小均为 64 B.支持非阻塞存储访问的访存部件的Load队列64项,Store队列48项,每个处理器核具有16项失效队列,用于处理核内缓存失效访问的访存请求.LA464使用基于目录(directory)的 MESI缓存一致性(cache coherency)协议.
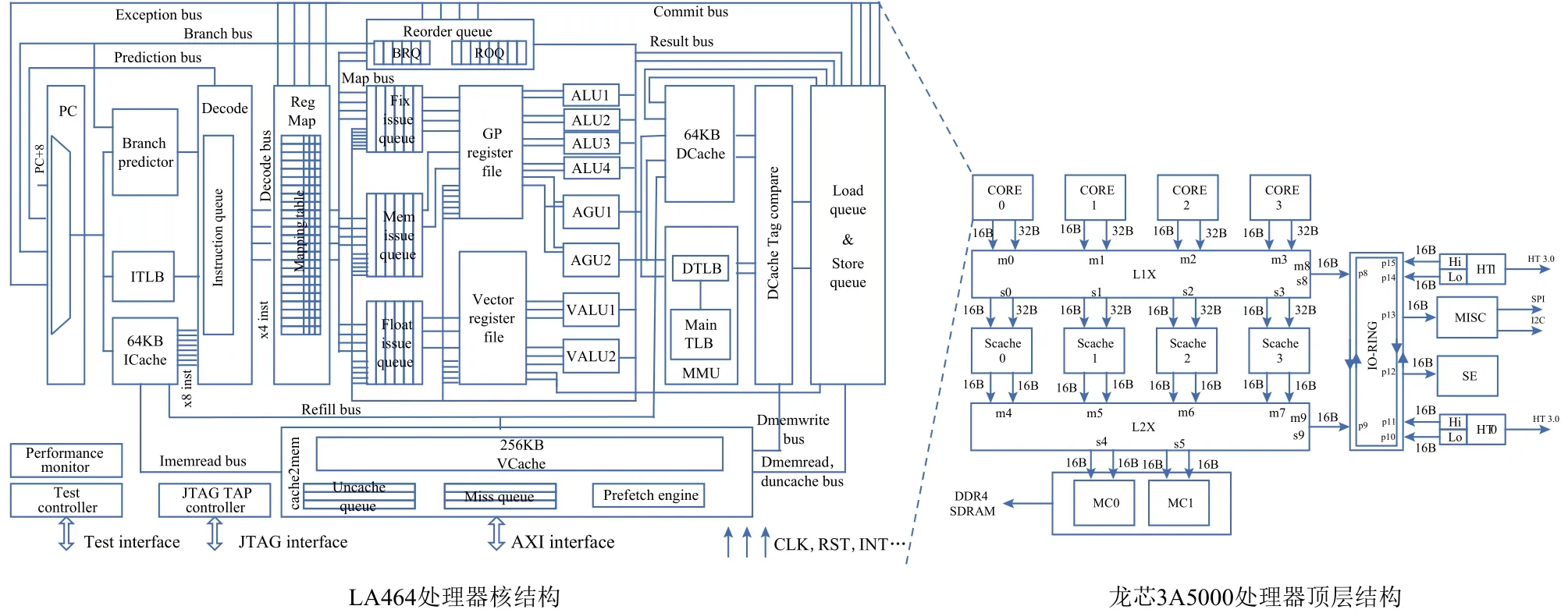
Fig.4 Architecture of 3A5000 and LA464 processor core图4 3A5000及LA464处理器核架构
2.2 龙芯3A5000的软件生态建设
软件生态是龙LoongArch能否成功的基础和关键.龙芯3A5000的软件生态建设以Loongnix Linux社区发行版[4]构建为抓手,以前述“3+3+3”的主要编译系统为核心,经过约3年的时间构建了LoongArch架构的基础软件生态.
Loongnix是支持LoongArch架构的开源社区版Linux操作系统.基于开源的debian 10发行版[5]移植适配的Loongnix在构建过程中共计完成24 300多个操作系统源码包、58 100多个操作系统二进制包,与架构相关的适配源码量超过40万行.
“3+3+3”的主要编译系统是生态建设的核心.GCC,LLVM和GoLang三个编译器,以及Java,JavaScript和.NET三个虚拟机能够基本满足典型Linux发行版中软件包迁移以及新应用开发的需求.而3个二进制翻译系统则为复用已有主流架构的软件提供了有效渠道.
3A5000基础生态构建大致可分为4个阶段:第1个阶段是GCC交叉编译工具链与模拟器研发,达到可生成LoongArch架构代码并在模拟器上运行相关代码的目标;第2个阶段是构建最小Linux系统,完成BIOS、内核开发,迁移常见的Linux命令行工具,生成初始根文件系统;第3个阶段是更多软件的移植,包括GCC之外的各编译系统以及Chrome浏览器、KVM和Docker等关键基础软件;第4个阶段是上游社区建设与第三方软件适配.前3个阶段分别耗时约6个月,初步形成了一个较为完整的基于开源软件的生态体系.第4个阶段在大约18个月的时间内,使得LoongArch生态基本达到了龙芯原有MIPS生态的成熟程度:进行了大量软硬件磨合优化工作,通过二进制翻译系统实现了一批常见Windows应用的高效兼容运行,完成了常用的国产操作系统、办公软件、云和安全软件等重要商业软件的适配,实现了基于LoongArch的产品批量销售.
这4个阶段总体上应用了3个策略:先模拟后真机、先开源后商业、开源开放.在实现新指令系统的CPU产品化之前,只能通过模拟器进行基础软件栈的研发和技术验证.前2个阶段和第3个阶段的一部分都是在模拟环境中进行的,我们设计了能够精确模拟真实硬件的模拟环境,并采用二进制翻译优化技术提升其运行效率以满足大规模软件开发的需求.而蓬勃发展的开源软件运动,则极大地降低了构建基础生态的门槛,使得LoongArch能够在较短时间内初步形成软件基础生态.龙芯团队采用开源开放的模式维护LoongArch的软件基础生态,有效促进了第三方商业软件的迁移适配.
龙芯3A5000的软件生态构建实践表明,在深入掌握“3+3+3”的主要编译系统技术的基础上,充分利用开源软件生态,在较短的时间内构建一个新指令系统的生态是可行的.
3 龙芯体系结构翻译器
通过跨指令系统的二进制翻译来丰富宿主机的生态是业界常用的手段.自20世纪90年代开始,伴随着体系结构的多样化浪潮,多种宿主机指令系统均针对x86目标机提出了各自的二进制翻译平台,例如,Digital FX!32[5]用于 Alpha 宿主机系统,IA-32 EL[6]用 于 安 腾(Itanium)宿 主 机 , Transmeta CMS[7]用 于Transmeta VLIW指令系统.此外,IBM公司以 Power体系结构为目标机,提出了DAISY[8]二进制翻译系统,以支持其IBM VLIW指令系统的推广.上述二进制翻译系统能够实现较高的执行效率,例如,FX!32在 500 MHz Alpha 处理器上达到了 200 MHz x86 处理的性能,IA32 EL 在执行部分 SPEC CPU2000 定点测试时能够平均达到本地编译执行效率的60%.
移动计算和云计算使得计算平台由传统的单一指令系统向多指令系统发展,催生了计算机系统对多种目标机的适应性的新需求.QEMU是一种广泛应用的可移植二进制翻译系统,能够适用于多种目标机(如 x86, PowerPC, ARM, Sparc and MIPS)和宿主机.然而,QEMU的可移植性以大量牺牲模拟效率为代价,未经优化的QEMU模拟执行速度经常不到本地编译执行速度的10%.其根本原因是QEMU为实现对多目标机和多宿主机的兼容,使用体系结构无关的中间代码,从而无法利用宿主机体系结构特征,难以对翻译代码进行深入优化.为此,文献[9-11]的研究工作针对特定目标机,利用宿主机特性来优化二进制翻译性能.在推出LoongArch之前,龙芯平台曾通过 MIPS 指令系统的 UDI(user defined interface)接口扩展指令, 弥补x86和MIPS指令的语义差距, 加速x86目标机程序的翻译执行效率, 基于SPEC CPU2000测试实现了5~10倍的性能提升[12-14],其中部分技术被应用于LoongArch中.
作为一种新型指令系统,在其原生软件生态成熟之前,LoongArch将借助二进制翻译实现与x86,ARM,MIPS等指令系统的软件二进制兼容来弥补其早期软件生态的不足,构建从MIPS到LoongArch的体系结构翻译器 LATM(Loongson architecture translator from MIPS)、从x86到LoongArch的体系结构翻译器LATX(Loongson architecture translator from x86)、 从ARM到LoongArch的体系结构翻译器LATA(Loongson architecture translator from ARM).这些翻译器支持同一操作系统的用户程序翻译(如Linux/LoongArch上运行Linux/x86的应用)、不同操作系统的应用翻译(Linux/LoongArch上运行Windows或者安卓应用),以及操作系统本身(直接运行Windows或者安卓系统),以达到消除单一指令系统壁垒的效果.这不仅要考虑普通用户程序指令的翻译,还要考虑各种体系结构资源的翻译(如特权资源模拟、虚拟地址转化等),因此我们称之为体系结构翻译器.LoongArch体系结构翻译器和前人工作的区别在于LoongArch定义时就充分考虑多种指令系统二进制翻译的需求,强调更加紧密的软硬件协同,大幅提高了跨指令系统二进制翻译的效率.图5给出了支持应用级二进制翻译的LoongArch软件生态结构.
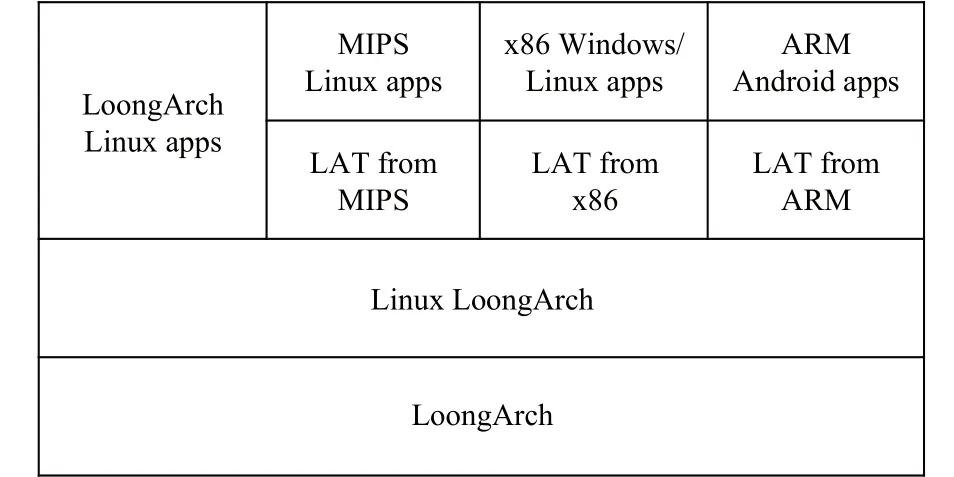
Fig.5 LoongArch software eco-system图5 LoongArch软件生态结构
3.1 从MIPS到LoongArch的翻译
由于MIPS与LoongArch都是RISC指令集,绝大多数常见指令都可以实现一对一翻译或者二对二翻译(例如装载32位立即数,由于2者立即数域大小不同无法保证一对一翻译,但可以把2条MIPS指令翻译为等效的2条LoongArch指令),仅有少数指令由于架构差异(如LoongArch取消了MIPS中转移指令延迟槽)需要多条指令翻译.LATM实现了MIPS到LoongArch的寄存器一一映射,并利用LBT扩展提供的便签寄存器处理延迟槽中寄存器依赖以及管理运行时环境,避免不必要的寄存器保存恢复.
对于直接跳转的分支指令,通过运行时的翻译块链接可实现高效翻译,采用热点路径探测、基本块代码重排等技术进一步消除额外的跳转翻译开销.而间接跳转的翻译相对复杂,LATM对函数调用、函数返回以及switch语句中的跳转指令进行分别优化.采用跳转目标地址内联技术、多级跳转目标缓存等技术优化函数调用;采用影子栈、返回块预翻译等基础实现函数返回的跳转指令翻译;采用跳转表预翻译技术优化switch语句中的跳转指令.
在运行时环境方面,LATM实现了高效的系统调用支持,减少翻译系统调用的上下文切换开销,以及多架构库调用等优化,进一步提高翻译效率.
3.2 从x86到LoongArch的翻译
LATX在LATM的基础上,需要额外处理EFLAG、浮点栈等问题.LATX利用了LBT扩展的x86运算模拟指令、分支模拟指令以及浮点栈模式,大幅降低了对应指令的翻译开销.此外,LATX通过指令流分析消除不必要的EFLAG计算,并针对指令序列中的特定组合按照语义进行二对一的翻译,进一步提高翻译效率.
3.3 不同操作系统应用的翻译
大多数商业二进制翻译系统只支持相同操作系统不同指令集的应用程序,这限制了它们的适用范围.例如,目前产业界对在国产Linux操作系统上支持Windows应用和驱动程序有强烈的需求,但这类技术无法满足这些需求.支持不同操作系统的应用翻译需要同时支持2个层次的翻译:指令集翻译和操作系统API翻译.开源软件Wine[15]是一个操作系统API翻译软件,它可以在Linux上用Linux的系统调用来模拟实现Windows的系统调用,从而实现在Linux/x86上运行Windows/x86的应用程序.我们通过结合二进制翻译器和Wine来实现在Linux/LoongArch上运行Windows/x86的应用程序.在此基础上,我们还通过Wine的本地化提高API翻译效率,通过扩充Wine实现了部分Windows驱动程序的支持,使得大批缺乏Linux驱动的打印机能够被用于国产电脑.
3.4 体系结构资源的翻译
要实现不同指令系统的操作系统等系统软件的兼容,就需要实现体系结构资源的翻译或者虚拟.随着云计算技术的发展,现代指令系统大都已经支持将一台计算设备虚拟成多台虚拟设备,而且能够实现很高的虚拟效率.但是高效的异构虚拟化仍然是一个很大的挑战.例如,一个近年来比较活跃的异构虚拟化研究系统Captive[16],其效率大约只有原生执行的1/7.目前在LoongArch上,我们已经实现了LATXSys的原型系统,并在关键的内存虚拟化等环节进行了一些研究[17],有效地提升了翻译效率.同时,我们正在探索直接在裸机上构建虚拟机管理器,通过消除不必要的宿主机系统软件开销来进一步提升体系结构翻译的效率.
4 性能测试与分析
4.1 基础性能测试
我们用3个常见的基准程序来测试LoongArch架构首款处理器龙芯3A5000的基础性能表现,包括广泛用于衡量CPU计算性能的SPEC CPU2006[18]、用来测试内存带宽的Stream程序[19]、测试系统综合性能的UnixBench[20].
为了方便比较,同时对比测试了采用MIPS架构的3A4000.3A4000和3A5000的处理器核均采用相同的四发射 64 位微结构.3A4000 的主频为 1.8 GHz,三级缓存容量为8 MB,内存速率为DDR4-2133.3A5000的主频为 2.5 GHz,三级缓存容量为 16 MB,内存速率为DDR4-3200.2款机器的软件版本保持基本一致,其中编译器版本均为GCC 8.3.
表3给出了3A4000和3A5000的SPEC CPU2006 Speed模式(单核)和Throughput模式(四核)下的分值情况,2款机器的编译器均为GCC 8.3,采用对所有程序一致的基础优化选项,无条件使能向量优化(对部分程序产生负优化),未使能自动并行化.3A4000的编译选项为:-Ofast -mabi=64 -march=loongson3a -mtune=loongson3a -mloongson -sx -mloongson -asx -static -flto,3A5000 的选项为-Ofast -mabi=lp64 -march=loongarch64-mtune=loongarch64 -mlsx -mlasx -ftree -vectorize -static-flto.可以看到,3A5000的定点和浮点性能均大幅度高于3A4000,而且平均提升幅度大于频率的提升幅度(后者约39%).
表4给出了3A4000和3A5000的Stream带宽测试结果.从表4可以看到,3A5000测试机的Stream带宽显著高于3A4000,这主要得益于更高的内存频率和内存控制器的一些优化措施.
表5是3A4000和3A5000的UnixBench分值比较,3A5000单线程和四线程提升均超过100%.可以看出,在微结构相似的情况下,3A5000比3A4000的UnixBench性能提升不仅远超过主频提升的幅度,也超过了SPEC CPU性能的提升幅度,一个重要原因是LoongArch提供了更多的软硬件协同优化空间,使得Linux操作系统能够得到更好的优化.
4.2 LoongArch和MIPS的直接性能比较
4.1节中3A4000和3A5000的性能比较结果受到指令系统以及其他差异因素(如主频、内存频率等)的影响,无法直接反映指令系统的性能差异.为此,我们通过3A5000的FPGA平台来实现指令系统的直接对比分析.3A5000的FPGA平台在保持微结构及主要接口速率不变的情况下分别实现了LoongArch和MIPS2 套指令系统,主频为 20 MHz.在 FPGA 平台上运行SPEC CPU2006的train数据集,使用GCC-8.3版编译器,编译选项同4.1节.表6列出了指令系统为LoongArch和MIPS时所花费的处理器流水线周期数和指令数,以及MIPS相对LoongArch的周期数和指令数的比例.

Table 3 SPEC CPU2006 Performance Comparison of 3A4000 and 3A5000表3 3A4000和3A5000的SPEC CPU2006性能对比

Table 4 Stream Bandwidth Comparison of 3A4000 and 3A5000表4 3A4000和3A5000的Stream带宽对比

Table 5 UnixBench Comparison of 3A4000 and 3A5000表5 3A4000和3A5000的UnixBench对比
从表6可以看出,MIPS比LoongArch的SPEC CPU2006定点程序平均动态指令数和周期数分别多12.35%和8.02%,浮点则分别多5.57%和7.53%.差距最大的定点程序483.xalancbmk MIPS比LoongArch的指令数和周期数分别多45.20%和45.16%,浮点程序481.wrf则分别是30.45%和23.40%.定点程序中,仅有一个程序456.hmmer的动态指令数LoongArch略多于MIPS,而且它的性能依然高于MIPS.浮点程序有5个LoongArch动态指令数多于MIPS,其中2个性能略低于MIPS.经分析,这些程序表现不如MIPS的一个主要原因是LoongArch编译器还没有充分利用乘加指令,在一些能够用乘加指令的地方生成了乘法和加法的组合指令.
在完全相同的微结构情况下,LoongArch能够有这样的优势要归功于其更合理的指令设计和更高效的ABI约定.目前,LoongArch的编译器尚未得到充分的优化,后续LoongArch相对MIPS的性能优势还可能进一步增加.
4.3 Loongnix操作系统性能优化
Loongnix操作系统针对LoongArch架构设计的特点进行了一些优化.例如,避免上下文切换时不必要的保存和恢复操作以降低上下文切换的开销;利用LoongArch向量指令优化memcpy等函数;利用LoongArch提供的更丰富的原子指令支持优化锁和各种同步原语,有助于降低上下文切换和系统调用等开销;利用LoongArch进入内核态自动关闭中断的特点省略软件关中断的处理;等等.
表7给出了结合LoongArch特点优化前后的Unix-Bench分值,优化前3A5000平台的UnixBench初始分值为单线程 1 438.8,四线程 3 698.4,经过一轮优化后分别提升到 1 743.9和 4 432.9,提升幅度均为 20% 左右.测试数据表明,LoongArch指令系统的设计能够有效提升操作系统性能.
4.4 LoongArch体系结构翻译器性能
4.4.1 LATM 应用翻译性能
表8显示了 20MHz FPGA 上 SPEC CINT2000的LATM应用翻译性能,其中第2列为采用MIPS指令系统原生运行的运行时间,第3列为采用LoongArch指令系统翻译运行MIPS二进制的时间,第4列为采用LoongArch指令系统原生运行的时间.Perlbmk和eon运行时包括几个不同的输入子集,程序的每一次运行都被当做一个单独的测试.表8中数据为运行时间,与速度成反比,可以看出,在LoongArch上翻译运行MIPS二进制的平均速度达到了原生LoongArch的91%,超过了原生MIPS.
LoongArch能够比较高效地翻译运行MIPS二进制,主要有2方面的原因:1)两者均为RISC指令系统,比较相似.SPEC CPU2000中,90%以上的MIPS指令都能一对一翻译为一条LoongArch指令,还有部分指令可以成对翻译为一对LoongArch指令.2)LoongArch为二进制翻译提供的便签寄存器等硬件支持能够有效降低翻译开销.
4.4.2 LATX应用翻译性能
LATX的初步性能数据如表9所示,在3A5000上翻译运行SPEC CPU2000定点和浮点效率分别是65.5%和70.3%,分别是QEMU-4.2.1的3.6倍和40.7倍.表9中输入数据集为ref,编译优化采用对所有程序一致的基础优化(-O3 -static).
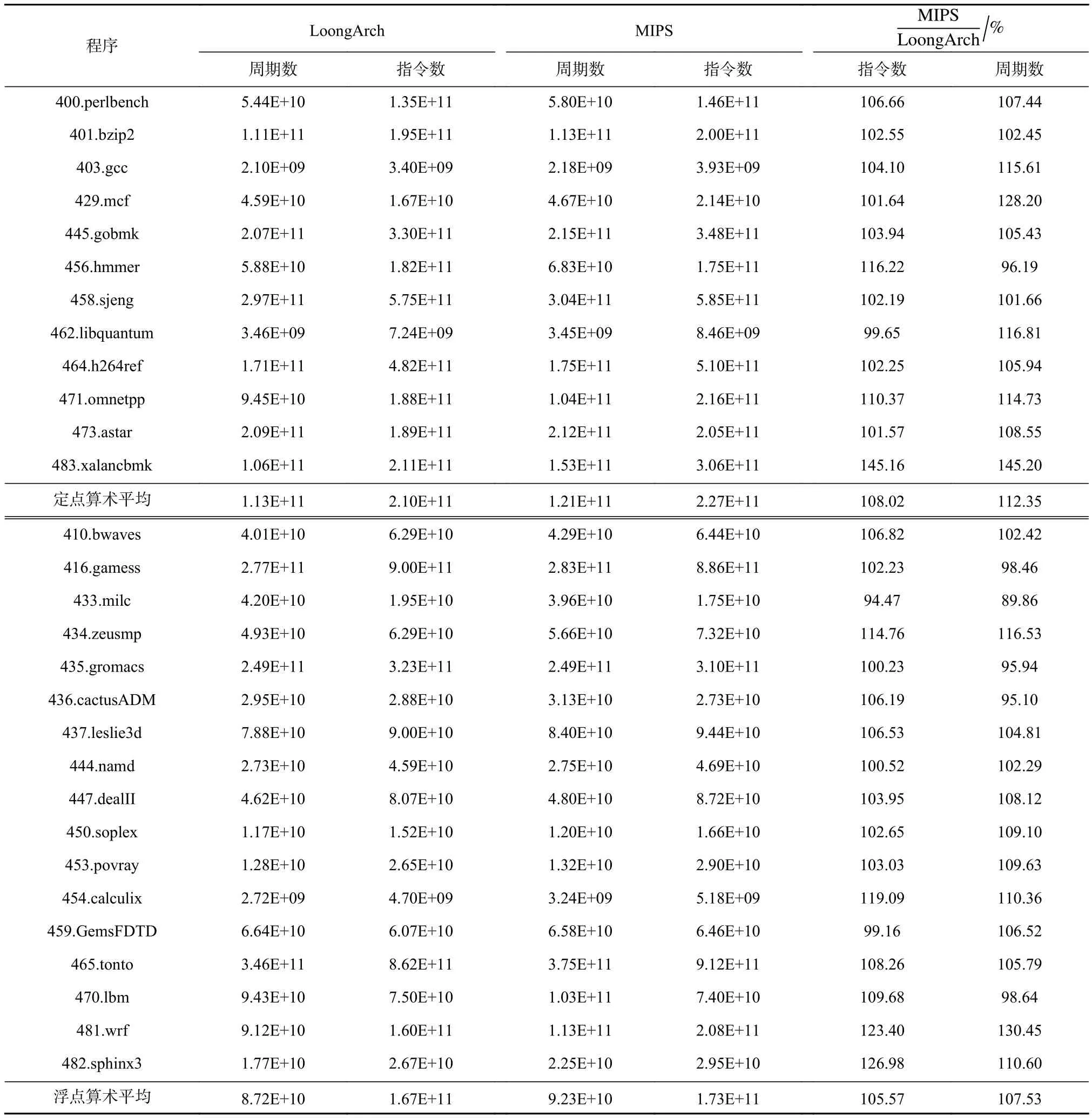
Table 6 Performance Comparison of LoongArch and MIPS SPEC CPU2006表6 LoongArch和MIPS的SPEC CPU2006性能比较
5 结论及未来工作
本文介绍了龙芯指令系统架构LoongArch的设计及其生态建设实践经验.测试结果表明,由于吸纳了近年来指令系统设计领域诸多先进的技术发展成果,Loong-Arch比龙芯CPU原实现的MIPS指令系统性能更好;通过软硬结合的二进制翻译,可以大幅度提高二进制翻译性能,高效兼容已有软件生态.实践证明,在掌握三大 C编译器(GCC,LLVM,GoLang)、三大虚拟机(Java,JavaScript,.NET)和三大指令系统(MIPS,x86,ARM)的二进制翻译系统的基础上,可以在较短时间内构建良好的软件生态.
CPU性能的改进和软件生态的优化都需要持续改进.本文后续的工作包括:对LoongArch指令系统进行更加细致的实验分析,验证相关指令扩展及设计优化的量化效果;针对LoongArch指令系统的特点进一步优化基础软件来提升性能;根据进一步测试和应用的结果发现新的性能瓶颈,持续完善指令系统;实现基于Android的从ARM到LoongArch的二进制翻译系统;争取再经过1~2轮的软硬件磨合迭代,到2025年前后通过技术手段消除单一指令系统的壁垒,使得不同指令集的系统及应用软件能够融合到统一的LoongArch平台上,不加区别地运行;对外开放LoongArch,鼓励更多学术界和产业界人士参与架构的持续改进.
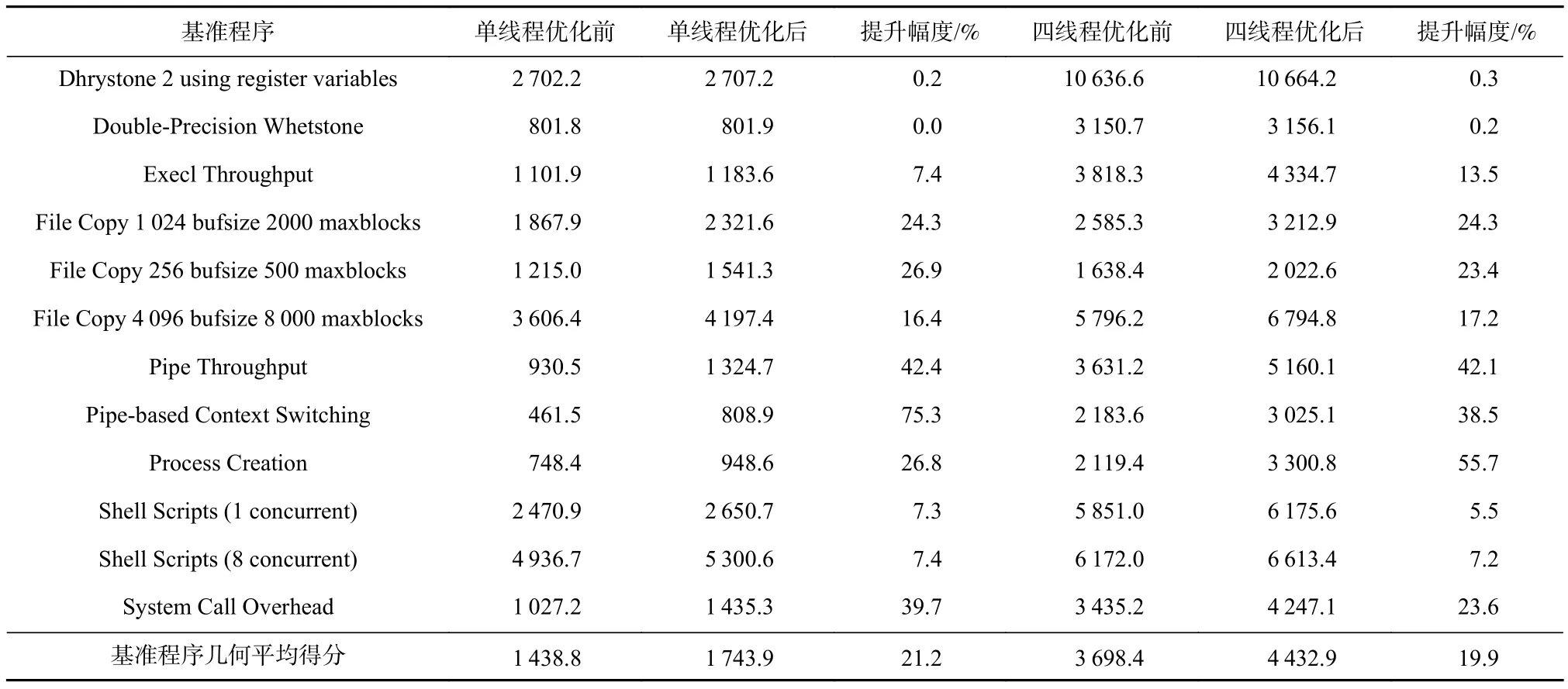
Table 7 Optimization of 3A5000 UnixBench表7 3A5000的UnixBench优化
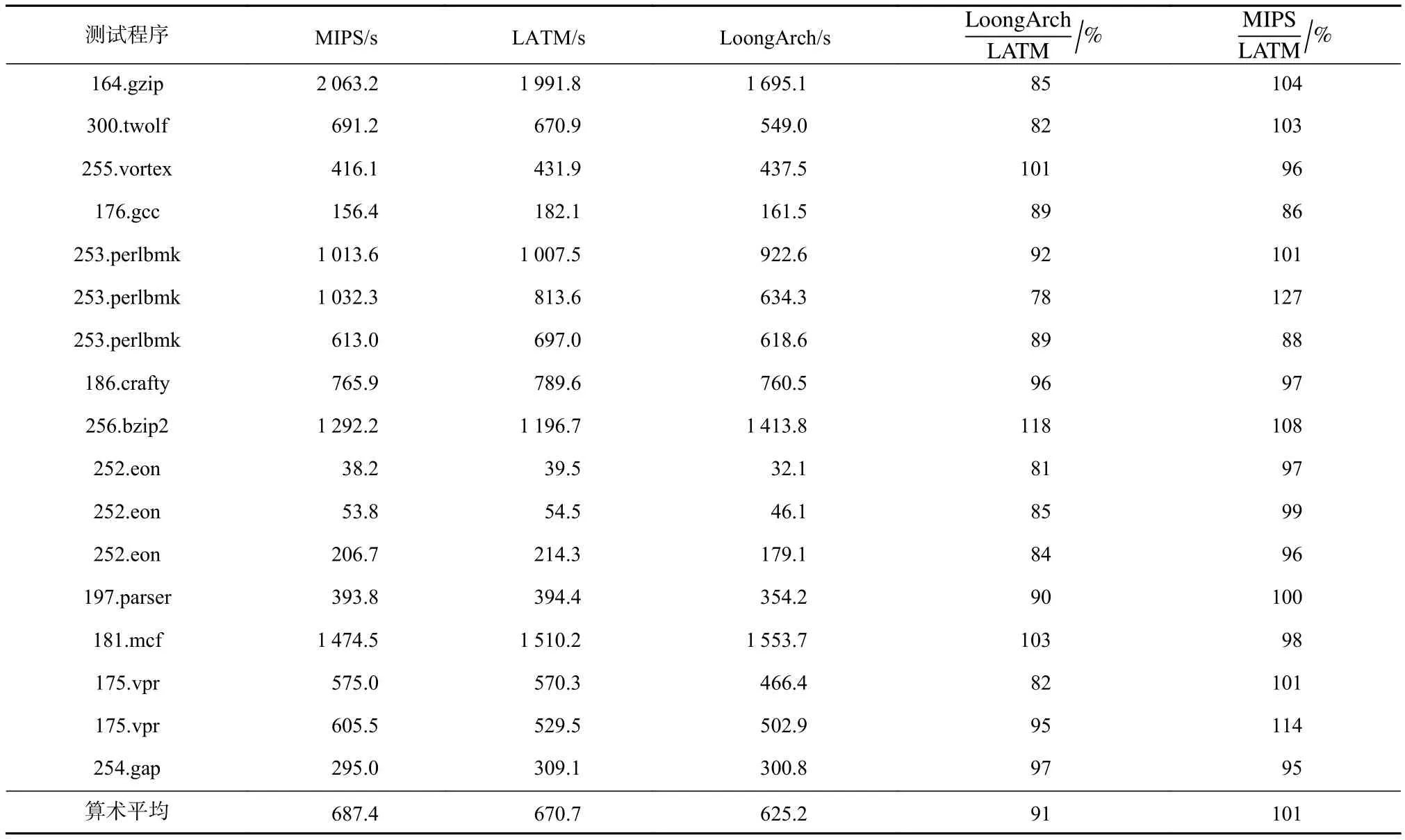
Table 8 Runtime Comparison of SPEC CINT2000 Train表8 SPEC CINT2000 Train的运行时间比较
作者贡献声明:胡伟武提出了主要思路,撰写了论文整体框架;汪文祥撰写了第1节部分内容;吴瑞阳和王焕东撰写了第2节部分内容;曾露撰写了第3节部分内容;徐成华、曾露和高翔撰写了第4节部分内容;张福新负责论文组织和统稿.
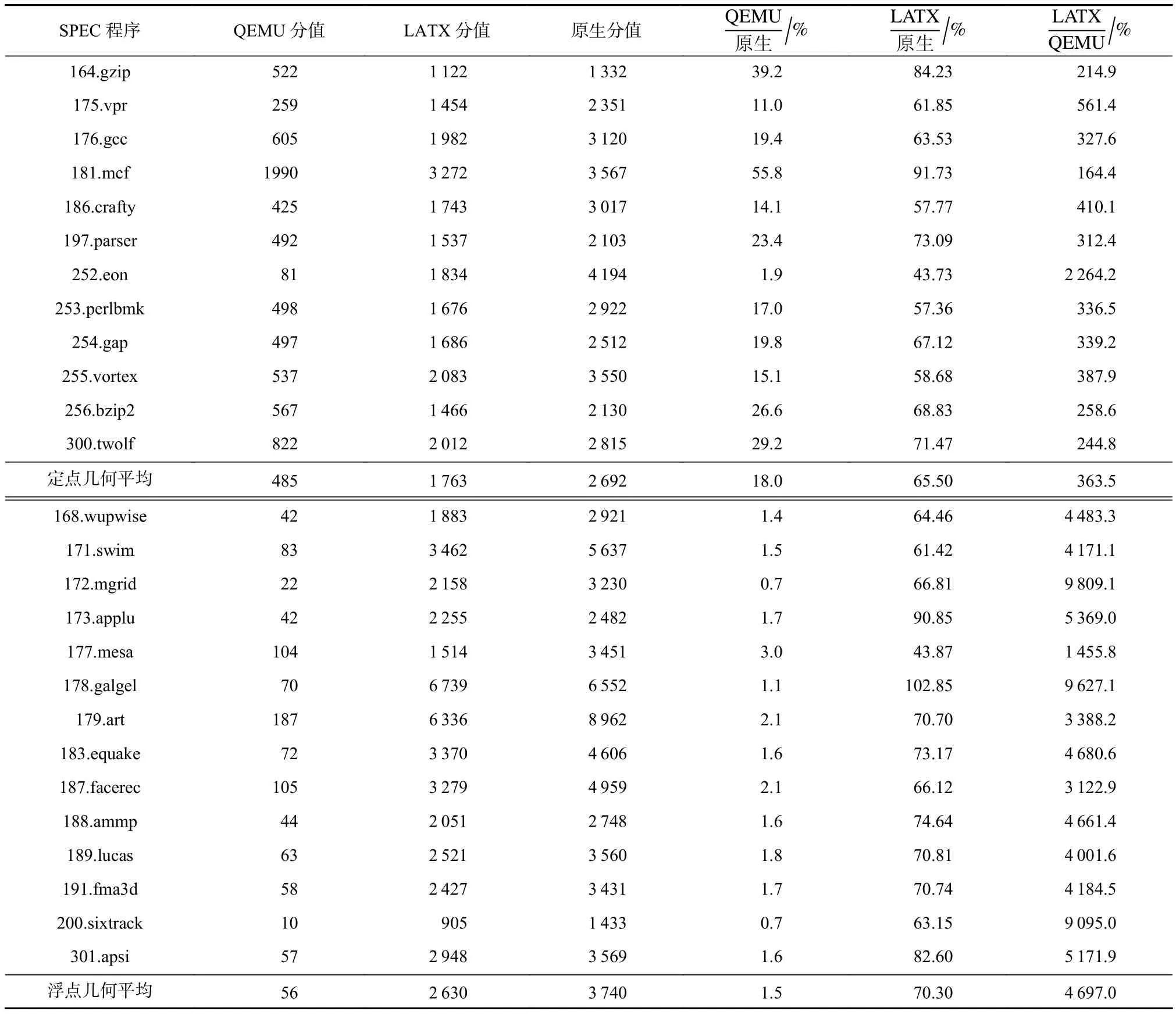
Table 9 QEMU and LATX Performance of SPEC CPU2000表9 QEMU和LATX翻译运行SPEC CPU2000的性能
