基于表征学习的地理空间收入分异探测
——以深圳市为例
2023-01-29张燕旋
钱 佩 黄 威 张燕旋
(广东省国土资源测绘院,广东 广州 510500)
0.引言
空间分异是城市空间中社会要素不均衡分布的体现,引起城市地理学、社会学、人口学领域的广泛关注[1]。经济不断发展,引发了包括收入水平、贫富差距等资源配置方面不平衡的问题,进而导致了居民的收入分异问题[2]。国内外研究主要局限于居住空间的静态分异,而在交通出行不断发展的今天,活动空间下的分异研究显得尤为必要,并且传统模型难以对海量数据进行高效计算,从而难以准确挖掘活动空间下的居民分异规律。
本文提出一种基于表征学习的地理空间收入分异探测方法,通过深圳市POI数据、公交出行数据构造属性相似矩阵、区域间接触度、均质度矩阵,并通过图嵌入方法得到每个区域的低维向量表达,最后以层次聚类方法得到不同尺度下深圳市居民收入分异程度。本文的贡献包括:(1)基于人群出行的分异指数提出区域间分异强度矩阵的构建方法;(2)改进了异构信息图嵌入模型,能够结合静态的属性信息和动态的属性信息。
1.相关理论
1.1 空间接触度与空间均质度
空间分异是城市社会学与城市地理学的经典研究议题,也是当前我国社会所面临的现实问题。Reardon在2004年的一篇文章中,Massey在1988年提出的表示分异的五个维度重新归类成两个维度:空间接触度与空间均质度[3]。
空间接触度常常被用来表示群体与个体之间的关系,定义为个体所接触到其他群体的人口与接触到总人口的占比[4]。Schnell提出了个体分异程度的分异指数[4],该指数分为两部分,一部分反映了个体与其他群体的孤立程度,另一部分反映了个体与其他群体的接触程度,计算人群中不同群体的比例且按照个体所接触的空间与时间进行加权。传统的接触度方法只考虑群体各自所在单元内的直接接触,而未考虑群体在其他单元内的间接接触。
空间均质度在早期使用D指数来进行描述,它能够很好地探测居住空间的分异程度,但并不能反映群体所在空间的关系,也并不能像接触度那样反映出研究群体的人口占比等特性。学者们尝试对D指数进行修正,Morgan提出的基于多群体计算的差异性指数被广泛认可,能测算多群体空间的社会分异,如式(1)所示:

其中,式(1)中,ti与pi代表的含义为i单元内总人口数以及研究群体的占比;T为整个研究区域内的总人口数;P为研究群体占比;n代表的含义为不同的研究区域。
1.2 图嵌入
图嵌入(也叫网络嵌入)模型包括链路预测、节点分类和社区检测,它以高维真实网络或图形处理为核心,生成节点的低维矢量表示,从而对网络进行下游计算。图嵌入可归纳为三大类:基于因子分解的方法、基于随机游走的方法和基于深度学习的方法。基于因子分解的方法是将图转换成矩阵的形式,对这些矩阵进行因式分解,从而保持节点之间的相似度;基于随机游走的方法核心思想是在网络中不断重复地随机漫游,最终形成一条完整地通过网络的路径,隐式地保留节点间的相似度,获取图中局部上下文信息;基于深度学习的方法主要是将深度神经网络应用于图的表示中。
2.活动空间分异度量测
2.1 相关定义
定义1:属性相似度图Ga(V,Ea)是通过对两节点之间的自身属性的相似程度进行描述,Ea={Wa,ij}表示的是两节点相似度,其值越大相似度越高。如式(2)所示:

式(2)中,||Hi-Hj||22代表相似性的量测值,γ是一个可选择的参数。
定义2:空间接触度图GE={V,EExp,WExp},V为城市中单元的集合,EExp为单元之间基于可达性的接触程度,接触度越大,两个单元间联系越密切,WExp为单元间的接触度集合,其子集WExp,i,j=Expij。M为各经济层次的集合,M={Rich,Middle,Poor},区域i与区域j的之间的可达性Acci→j,如式(3)所示:

式(3)中,ti→j为i区域到j区域的时间,tj表示其他区域到j区域的平均时间,duri→j表示i区域在j区域的逗留时间,表示其他区域到j区域后在j区域的逗留平均时间。i区域到j区域行程时间越久,意味着j区域对i区域的吸引力越大;在某个区域逗留的时间越久,与这个区域人口的接触可能性就越大。定义i到j区域的局部接触水平,如式(4)所示:

其中,

式(4)中,Trj,g表示j区域的g群体的数量;Acci→j表示i区域到j区域的可达性;Tri→j,k表示i区域到j区域的k群体数量;Trj→t,g表示j区域到t区域的g群体数量;Tri→t,k表示i区域到t区域的k群体数量。
定义3:空间均质度图,GEv={V,EEv,WEv},如式(7)所示:

式(7)中,Acci,j为i区域和j区域与其他区域的累积可达性,I为辛普森系数,Acci,j→cm为i区域和j区域流出到m群体的可达性,Acccm→i,j为m群体从其他区域流入到i,j区域的可达性;Rij→cm为i,j区域流出到m群体占整个区域流出的比例,Rcm→ij是指m群体流入到i,j区域与整个流入流量的比值。
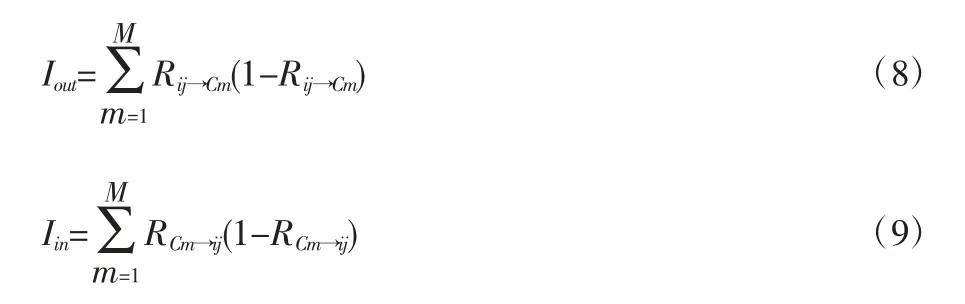
Rj,m为j区域内m群体占整个区域m群体的比例,Ri→j,m是指i区域流向j区域m群体数量与i区域m群体数量的比值;Rm表示整个城市中m群体人口占比。
2.2 联合嵌入
上文已经定义了三类图,为了得到公交出行的日常活动数据特征信息,需把三类图嵌入一个相同的空间,本文引入了一种全局的联合嵌入方法。以自编码模型基础模型,并加以改进。自编码模型分为编码和解码,整体框架,如图1所示。

图1 联合嵌入框架
编码部分如式(10)所示:
式(10)中,Yk表示第K层表达;Wk、bk分别为第K层的权重和偏移量;σ为激活函数。
解码部分如式(11)所示:
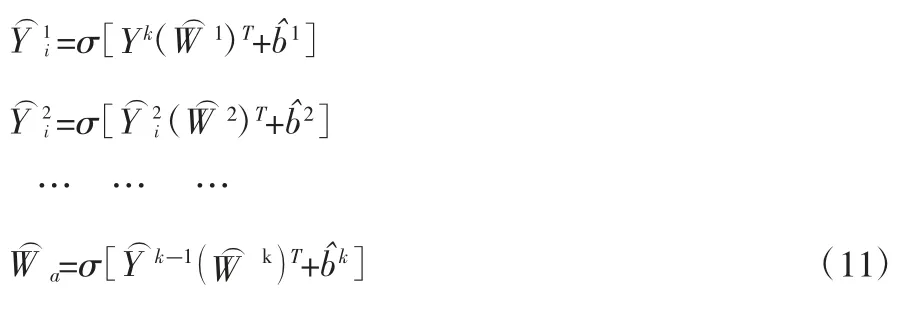
2.3 损失函数
(1)损失函数的重建
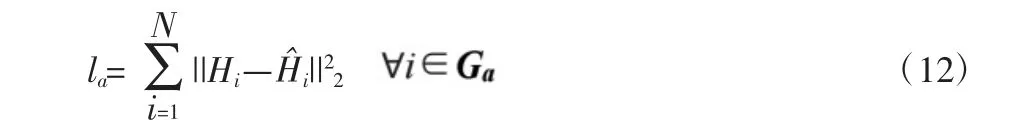
目的是使输入向量与输出向量的误差值最小,来维持属性相似图节点之间的相似性,属性相似图中的原始结构应该保持不变。
(2)接触度属性图近似
要使得节点在低维空间具有接触度图的特征,损失函数可以被定义为:
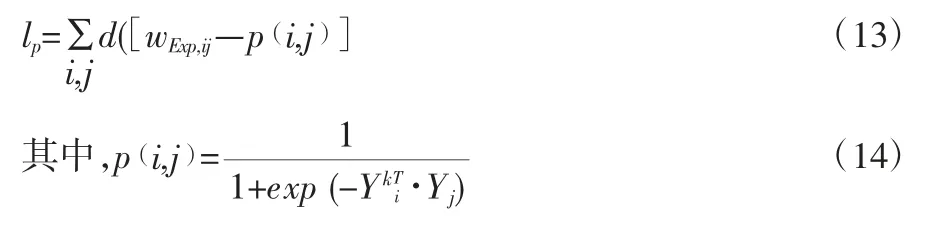
(3)均质度属性图近似
两节点在均质度方面表现十分相似,在重建加权误差中它也是最小的。

最终的损失函数为:

式(16)中,α和β是可学习的参数,用于对损失函数lp和ls进行加权计算。从公交出行模型中的三个独立方面构建的图进行模拟和近似计算损失函数。在后面的实验中把损失函数的最终公式中的可变的加权参数设置为α=1和β=0.2。
2.4 分异探测
分层的社区结构由两个等级构成:(1)比较低级的社区结构是由K均值聚类得到;(2)比较高级的社区结构是由低级社区结构聚类而成。
低级社区结构通过间隔统计来确定最佳的簇数,当间隔统计量G(k)取到最大值时得到了最佳的聚类数k,如式(17)所示:

式(17)中N是生成的数据集的个数,这些数据集在图嵌入向量的时候获得;Dkn是第n个数据集与其他数据集之间的距离之和,用蒙特卡罗抽样法来计算这些距离;Dk是所有K个聚类之间的距离之和。
通过K均值聚类方法,在最佳的聚类数k已经确定的情况之下生成低级社区结构。在低级的社区结构中,对组成的嵌入向量进行平均值计算来提取嵌入向量;通过层次聚类,根据各个簇之间的平均距离生成高级社区结构。通过使用树状图对高级社区的结构进行描述,最终完成不同尺度的收入分异探测。
3.实验结果与分析
3.1 数据描述
根据国家统计局统计资料,2019年深圳市人均GDP达3万美元,其中收入水平较高的南山区人均GDP为5.93万美元,这只是一个市区级的粗略比较,在更加精确的区域划分内,人均GDP的差距会进一步拉大。在这样一个人均GDP位于国内前列的城市,其内部存在的收入分异值得去分析研究。更高的收入往往意味着能够买得起更贵的房子,收入与房价之间存在正相关关系。通过深圳市房价分布反映收入分异,如图2所示。
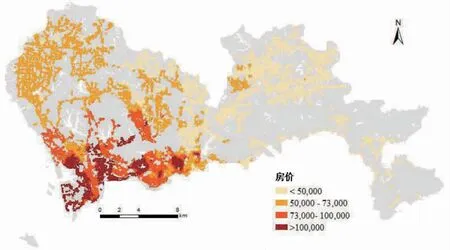
图2 研究区分异情况
收入等级划分为三个:高收入、中等收入以及低收入。且中等收入的上限与下限分别是高收入的下限以及低收入的上限。按照人均GDP来设置中等收入的下限,按照平均的人均GDP两倍来设置中等收入的上限。
深圳市有8条地铁线路、808条公交线路以及6425个公交以及地铁站点。这些庞大而复杂的交通路线与节点共同构成了支撑深圳市日常公共交通出行的交通网络。在这些公共交通出行数据中,使用了开始时间、结束时间、上下车站台、交通路线等数据项。交通数据类型如表1所示。

表1 公交数据示例
3.2 结果与分析
根据聚类方法对社区进行检测,以工作日早晚高峰交通出行数据为数据源,对早晚高峰的社区类型进行提取与分析。当K=14时聚类最为明显,因此将早晚高峰的嵌入结果分为14类。
(1)低级社区结构
在所有的类别中,类别0(蓝色框内)和类别6(红色框内)所占的比重最大。通过与经济分区图相对比再综合交通流量数据发现:类别0处于低收入水平单元且表现出交通流出比例远大于流入比例;类别6处于中高收入水平单元且表现出交通流入比例远大于流出比例。再进一步结合居住、办公、游玩等社会功能性区域划分信息,在类别0中:多数单元位于距离市中心商业办公区2.5千米内的居住区,而剩下的多数位于距离市中心商业办公区5千米以上的市郊。在类别0中的流出群体大多在类别6中聚集,类别6中的一个普遍情况是:处于较为发达的深圳市中心地区,几乎囊括了所有的中高收入单元,区域内集中了大量的办公区、交通枢纽、商业中心、娱乐场所、金融中心。与类别0相比,类别1虽然也是属于高流出低流入类型,但是类别1主要为短距离出行,类别0则是中长距离出行。如图3所示。

图3 早高峰低层次社区结构
与早高峰类似,通过对晚高峰的低级社区结构进行分析,得出了与早高峰类似的结果。在晚高峰的14个低级社区结构当中,类别3(与早高峰类别0相对应)与类别5、7(与早高峰类别6、2)占了研究总单元的大部分。
在类别3中,群体在通过中长途的公交出行之后流入到低收入的居住区。
早晚高峰交通出行数据体现了高度的对称性,市民在早高峰阶段从居住区流向办公场所,结束了一天忙碌的工作之后,在晚高峰由办公场所流向居住区,然而这只是低收入群体在工作日的流动情况,中高收入群体在这方面则表现得不如低收入群体明显。几个比较合理的解释是:中高收入群体居住区域原本就位于市中心办公场所附近,上班过程中无需使用交通工具;中高收入群体对公共交通的依赖程度较低;中高收入群体上下班时间相对来说不是十分地固定。
在对早晚高峰的低层次社区结构分析中发现,分异现象在不同的类别和表现的程度上也不同。以早高峰为例,在类别0、10、12中,分异现象十分明显,类别0前文已作解释,而类别10、12都有一个共同的特点:位于城市边缘的郊区或城市中心之间的低收入地区。而在类别1、4、9中,分异现象则表现得不是那么明显,这几个类别交错散落在城市较发达的高收入地区。
(2)高级社区结构
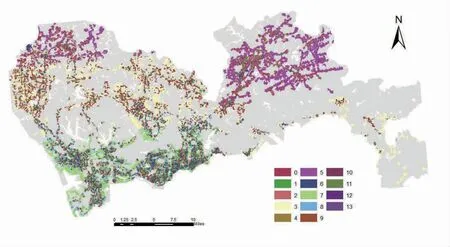
图4 晚高峰低层次社区结构图

图5 早高峰高级社区结构树状图

表2 高级社区统计
通过使用层次聚类的方法,对上面的14个低级社区结构重新生成了6个高级社区结构。以早高峰为例对这6个高级社区结构进行了统计:
对这6个类别的模式进行分析得到:
类别Ⅰ:由低级类别2组成,占比为6.06%,主要的模式是低收入区域与中高收入区域之间的中短距离出行,流入比例高于流出,范围较为分散。
类别Ⅱ:由低级类别4、9、12、13组成,占比为18.16%,主要的模式是低收入区域与中高收入区域内部的短距离出行,流入比例高于流入,范围十分集中。
类别Ⅲ:由低级类别0、6组成,占比为35.42%,主要模式是低收入区域与中高收入区域之间的中长距离出行,流入与流出比例差别较大,范围较为集中。
类别Ⅳ:由低级类别3、7、10组成,占比为17.75%,主要模式是中高收入区域内部之间的中距离出行,流入比例大于流出,范围较为集中。
类别Ⅴ:由低级类别1组成,占比为6.06%,主要模式是低收入区域与中高收入区域之间的中短距离出行,流出比例大于流入,范围较为集中。

图6 早高峰高级社区结构图
类别Ⅵ:由低级类别5、8、11组成,占比为13.22%,主要模式是低收入区域与高收入区域之间的中段距离出行,流出比例大于流入,范围较为集中。
在对6个高级类别的所在区域的分异情况可视化后,发现在蓝色框内的区域存在着较强的分异现象,这与低级社区的情况相吻合。这些区域内的单元大多都是低收入单元,且离办公场所有一段较远的距离,所以在早高峰出行中表现出中长距离的流出模式。而在类别Ⅰ、Ⅴ较为集中的区域,可以明显地发现分异水平较低。
由此得出:分异在低收入区域的强度高于高收入区域,即位于低收入区域的群体往往更容易感受到分异现象。原因是:办公场所往往位于城市中心地区,而城市中心地区承载着大量的金融中心、娱乐场所、商业中心,所以办公场所与高收入区域有着紧密的联系,当来自不同群体的个体聚集到办公场所时,高收入区域将会表现出不同群体的流入模式。同时,低收入区域通常位于城市的住宅区,所以低收入区域表现的只是低收入群体的流出模式,因此低收入区域更容易感受分异现象。位于城市偏远地区的低收入区域,距离高收入区域较为遥远且缺乏对高收入群体的吸引,导致分异现象尤其明显,而这类区域在早高峰的出行过程中一般表现为中长距离的流出模式。
4.结束语
本文利用公共交通出行数据、POI数据提出了构建城市节点之间局部接触度和均质度的矩阵构建方法,通过数据驱动的方式对城市内部的收入分异情况进行探测,为空间分异的研究提供了一种新思路;在图嵌入过程中,融合了静态的属性特征和动态的出行特征,并将出行信息抽象为接触度图和均质度图;最后以非监督的聚类方法完成了深圳市地理空间的收入分异探测,可为城市管理与建设、公交线路优化等提供决策参考。
