针对隐匿高危勒索病毒攻击的检测*
2023-01-16陆庭辉饶茜霖
陆庭辉,饶茜霖,薛 质,施 勇
(1.广东电网有限责任公司江门供电局,广东 江门 5 290001;2.上海交通大学,上海 200240)
0 引言
近年来,随着勒索病毒的部分技术细节的公开,以及在暗网中代码交易的出现,勒索病毒的制作和利用勒索病毒进行犯罪的成本不断降低,勒索病毒攻击方式也更加简单,但其赎金收益依然非常可观。随着网络犯罪的组织化、规模化,隐匿行为攻击的复杂化和商业化,目前,隐匿高危勒索病毒呈蔓延之势。已知的勒索病毒家族利用多态、代码混淆等手段,可以快速产生大量新版本,使得勒索病毒数量激增。
随着网络规模的扩大和信息化水平的提高,电力企业对网络的依赖程度不断增强,也在不知不觉中受到隐匿高危行为的威胁。电力企业的敏感数据也容易受到勒索病毒的关注,这些风险影响着电力企业网络安全和稳定。为了保证计算机网络和计算机应用系统的正常运行,电力企业需要对隐匿高危勒索病毒的攻击作出应对。
在过去几年中,已经有许多针对勒索病毒的防御策略,每种策略都实施了几种保护和检测策略,例如,基于欺骗的保护方法(deception-based protection)[1-2]、控制安全随机数发生器(controlling secure random number generator)[3]、应用程序的行为分析(behavioral analysis of applications)[4-6]、密钥托管[7]、网络级防御[8],以及利用机器学习算法的勒索软件程序检测[9]。
按照是否运行软件样本,勒索病毒的检测可以分为静态检测与动态检测两种。其中静态恶意软件特征包括字节序列N-grams、操作码和PE 报头字段等。随着开发技术的发展,恶意软件的作者往往使用压缩、加密、加壳等方法阻止静态特征的提取,但许多反病毒技术和工具已经可以有效实现程序的解包。Wang 等人[10]针对恶意软件通过加壳逃脱检测的问题,提出了一种加壳检测框架以检测可执行文件是否加壳,以提升恶意代码检测效果。在动态检测中,程序运行时调用的API 的序列经常被视作为主要特征,这是因为恶意软件为了减小代码的体积,往往通过调用API 函数来实现文件、注册表、网络、进程等操作行为。
现有的勒索病毒防御方法中,传统的分类算法难以及时响应零日漏洞勒索病毒,而人工逆向分析的方法使得成本显著提高,但是效果提升不明显。随着机器学习等算法的发展,一些启发式检测工具不断出现,但是这些工具普遍存在局限性和滞后性,并且不利于迭代。与此同时,勒索病毒的开发也在不断发展,加壳、代码混淆、反沙盒、内存动态映射等策略的使用也为勒索病毒的防御带来了很大难题。
本文从Virus Total 等开源网站上收集了勒索病毒等恶意软件样本,利用动态分析方法提取软件的应用程序编程接口(Application Programming Interface,API)函数调用特征,在此基础上训练了勒索病毒检测器和勒索病毒家族分类器。
1 背景介绍
1.1 隐匿高危勒索病毒
勒索病毒,或称勒索软件,是一种特殊的恶意软件,其主要通过锁定受害者主机的操作系统或者使用密码学加密受害者主机上的某些文件的方式,使得受害者无法获得对其主机或主机上的文件的访问控制权限,并威胁受害者向指定的账户支付赎金以解锁文件。为了防止在感染受害者机器的初期就被察觉,隐匿勒索病毒往往在进行加密等核心操作前先模仿正常软件活动一段时间。
随着各种新型网络攻击的出现,企业信息安全形势变得不容乐观,特别是银行、电力、大型国企等机构,正在成为受攻击的主要对象。当前,隐匿高危行为是企业面临的最严重的威胁之一,其中,高级持续性威胁(Advanced Persistent Threat,APT)是最主要的表现手段之一。所谓APT 攻击就是针对特定的目标,进行长期持续性的网络攻击的攻击方式,其对企业造成了非常严重的困扰,而结合了APT 的勒索病毒攻击则更是为企业的数据安全带来了极大的威胁。
对抗隐匿高危勒索病毒攻击,保护用户数据的关键措施在于预防,即在勒索软件攻入受害者主机但尚未造成实质性破坏前及时检测并拦截攻击。目前,针对勒索病毒的防护主要采用分层次防护措施,即提倡同时部署多种独立、领域互相重叠的安全措施以创建稳固的安全防护架构,并且各安全层被设计为和其他安全层互补,使得威胁不易穿透重重防护。
勒索病毒的家族分类指的是根据勒索病毒产生的变种来源对勒索病毒进行分类。同属一个家族的勒索病毒往往会共享一些通用模块,因此会有相似的勒索行为。近年来,家族内的勒索病毒的技术不断更新迭代,可以更好地逃避现有工具的检测。此外,可以对勒索病毒的结构进行转换,从而迅速产生大量变种。
此外,近年来勒索软件即服务(Ransomware as a Service,RaaS)的商业模型的规模化发展使得勒索病毒家族中的病毒变种出现得更加频繁,Cerber家族的出现和发展就是其中的典型。据报道,恶意代码工厂软件生成使用代码混淆技术且拥有独特Hash 的恶意代码变种所需时间仅仅只有15 s[11],而这些恶意软件的变种可以绕过传统的静态签名匹配的恶意软件检测技术的检测。
1.2 Cuckoo 沙盒
Cuckoo 沙盒是一个开源的恶意软件分析工具,用户可以提交待分析样本或待检测统一资源定位符(Uniform Resource Locator,URL),快速获得它的行为分析报告。Cuckoo 沙盒的主要组件可以分为主机和客户机两部分。其中主机是沙盒的核心控制部分,负责样本的传入、分析报告的生成、客户机的启动和恢复等,而客户机可以有一个或多个,可以是在VirtualBox 等软件上配置的虚拟机,也可以是真实的物理机器。
Cuckoo 沙盒记录的待检测样本的行为信息主要有软件执行期间调用的所有进程,创建、删除、修改的文件及其信息,网络连接与流量信息,客户机运行期间的屏幕截图,软件运行期间的内存转储记录。这些信息由客户机内的监控脚本(agent.py)获取,并将所有信息发回主机,样本运行完成后,再由主机生成名为report.json 的行为分析日志。
1.3 机器学习算法
决策树算法的雏形最早由Hunt 等人[12]在1966年提出。该算法对整个决策空间进行划分,认为位于同一块空间内的样本就属于同一类别。决策树的结构是一种树形的有向图结构,分为决策结点与叶子结点。在决策结点,决策树会根据样本特征做出决策;当到达叶子结点时,根据叶子结点被划分的空间就完成了对样本的分类。
随机森林[13]是一种集成的、基本单元是决策树的机器学习算法,使用了bagging 方法集成学习。随机森林将训练集分为多个子集,每个子集独立训练一个决策树模型。在模型预测时,随机森林会收集每个决策树的模型结果,依据算法进行整合,得到最终的预测结果。
卷积神经网络(Convolutional Neural Network,CNN)[14]是用卷积核代替参数的多层感知器(Multilayer Perceptron,MLP)的一种变体,属于一种前馈神经网络,其利用卷积核构建学习模型。卷积神经网络的模型构成通常有多个卷积层、池化层和全连接层。
在自然语言处理方面,Kim[15]提出使用卷积神经网络对句子的情感进行分类,如图1 所示,其模型由卷积层、池化层和全连接层构成。

图1 API 序列分类模型架构
用xi∈Rk表示API 序列中第i个API 函数的k维特征向量,API 序列的长度为n,则整个API 序列特征表示就可以用n个API 函数的特征向量拼接得到,即:

同样的,可以用xi:i+j表示从xi到xi+j的特征向量的拼接。对拼接后得到的x1:n∈Rnk进行矩阵卷积操作,卷积核设置为w∈Rhk,即1 次对API 函数调用序列中的h个连续API 函数进行特征提取。如对xi:i+h-1卷积得到一个新特征ci,该过程可以表示为:

式中:b为偏移参数;f为非线性函数。对1 个长度为n的API 函数调用序列中间每一个大小为h的子序列{x1:h,x2:h+1,…,xn-h+1:n}进行卷积操作,就可以得到整个序列的特征映射为:

整个模型的卷积层有多个卷积核,每个卷积核经过卷积、池化后都可以得到一个特征。将这些特征一起传入全连接层,就可以输出一个类别的概率分布,其中概率最大的类别就作为输入API 函数序列的类别。
2 动态分析与行为特征提取
在本节中,将介绍本文勒索病毒数据集的构建与软件特征提取的过程和结果。
2.1 实验数据
本文研究的软件样本类别是Windows 平台上的可执行软件样本(exe),其可以分为恶意软件样本和良性样本两大类。在恶意软件样本的选择上结合了电力系统的实际情况,包含了隐匿高危勒索病毒样本。课题使用的恶意软件样本主要来自Virus Total 等恶意样本开源网站。课题使用的良性软件样本来自360 应用商店,样本均经过360 恶意软件检测确认。本课题总共收集到1 000 个恶意软件样本(不包括勒索病毒家族样本)、100 个良性软件样本。
由于目前尚没有根据勒索病毒家族分类的公开的数据集,因此勒索病毒样本及其所属家族只能通过其在Virus Total、VirusShare 等开源网站上的分析信息判断,将反病毒厂商检测引擎给出的占比最大的家族定为该病毒样本的所属家族。最终获得的勒索病毒家族名称与样本数量分布如表1 所示。

表1 数据集勒索病毒家族构成
2.2 Cuckoo 动态行为分析
本文搭建的Cuckoo Sandbox 环境中主机使用的是Ubuntu 18.04.1 LTS 操作系统,在主机上安装了Cuckoo Sandbox 2.0.7、VirtualBox 5.2 等软件。客户机使用的操作系统是Windows 7 专业版并以虚拟机的形式通过VirtualBox 5.2 安装在主机上。
为了便于主机对客户机的控制和软件样本的运行,客户机关闭了防火墙、系统自动更新、用户账户控制,并安装了Python、pip、pillow 等软件用于运行agent.py 脚本。
2.3 行为特征提取
软件在与操作系统进行交互时通常使用API 函数。为了使文件大小更小、更加隐蔽、传播更迅速,勒索病毒往往利用系统API 函数实现文件管理、网络连接、注册表访问等行为。本小节在Cuckoo Sandbox 提供的分析报告的基础上,提取了勒索病毒等软件样本的API 调用信息,并在提取的行为信息中分析了勒索病毒的部分典型行为。
从软件行为分析报告中提取API 函数调用行为信息的流程如图2 所示。提取的行为报告位置是[“behavior”][“process”]字段,该字段记录软件运行期间每个进程的API 函数调用情况。
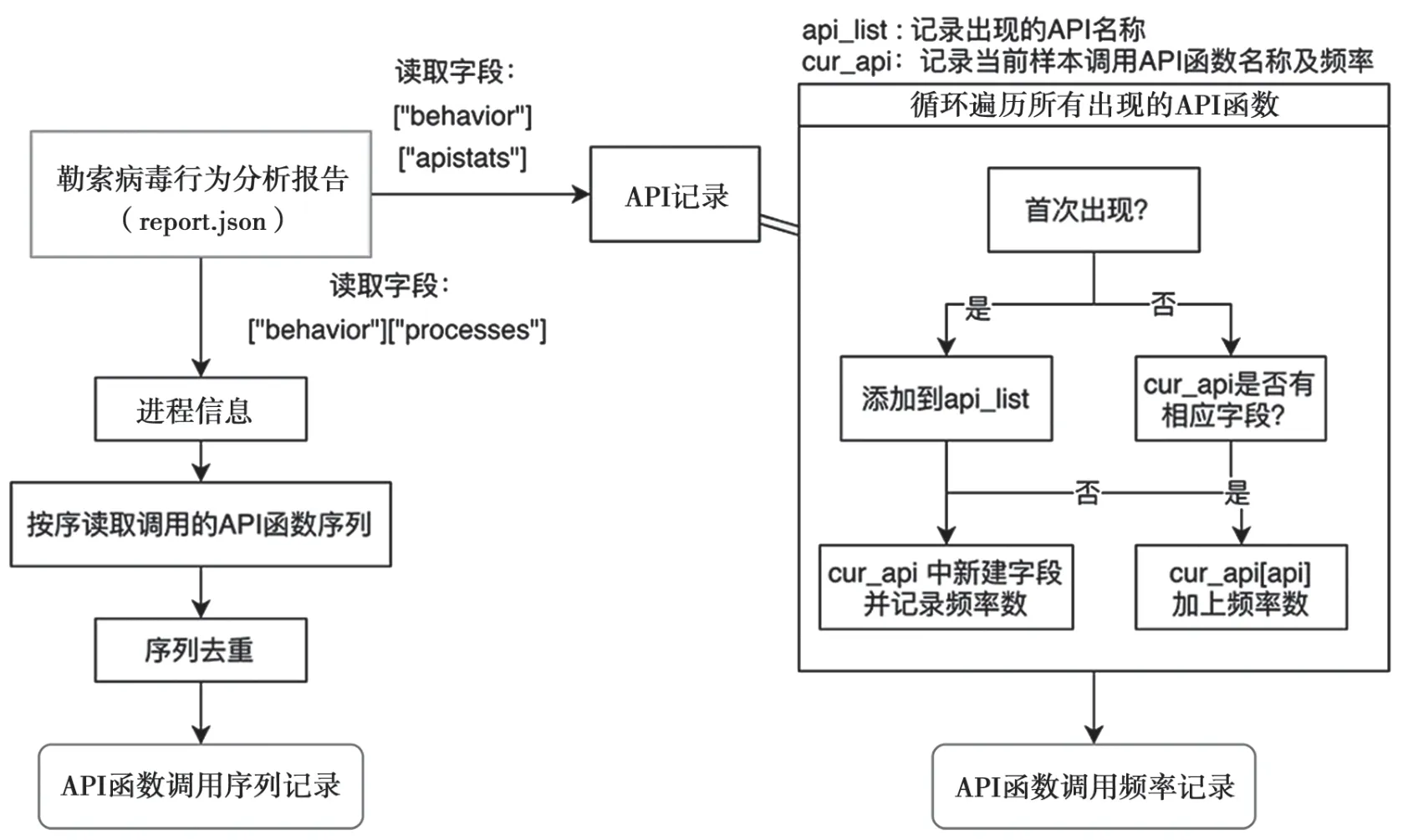
图2 API 函数调用信息提取流程
3 勒索病毒检测器训练
本节在2.3 节特征提取的基础上,训练了勒索病毒检测器与家族分类器。
3.1 API 函数特征选择
本节中,训练勒索病毒家族分类器使用的特征是软件样本调用的API 函数名称及相应的频率。如果将全部出现过的API 函数名称作为特征直接进行分类器的训练,不仅会增加模型训练的时间消耗,还会因为无效或者干扰特征的保留使模型的分类效果下降。
利用2.3 节获得的软件API 函数调用频率信息,并利用R 语言的Boruta 算法包对API 函数进行特征选择。由于分类任务分为勒索病毒检测的二分类和勒索病毒家族分类的多分类,两种分类数据集不同、数据标签不同,因此需要分别进行特征筛选,保留与各自分类任务相关的API 函数特征。
3.2 API 函数特征向量预训练
第2 节获得的API 函数的调用序列可以看作软件的“句子”的文本分析和分类,但是序列长度基本在3 万以上,这给后续的分析带来了极大的数据读取和存储压力,也会影响卷积神经网络分类勒索病毒的效果,因此需要对API 序列进行去重处理。对软件样本的API 函数调用序列进行去重的算法结合软件的API 函数调用的现实情况,设置重复序列的长度范围为[1,15],遍历一遍序列后删去所有重复子序列。
利用全部样本的API 函数调用序列构成了一个文档输入Word2vec 模型,获得API 函数的特征表示。特征向量预训练使用了Skip-gram 模型结构,设置API 函数的特征向量的维数为50 维,迭代次数为10 轮,模型训练结束后将特征向量保存为“APIvec.bin”文件,用于后续的分类器训练。
3.3 分类器测试效果
在本节中,分别使用传统的机器学习算法决策树、随机森林模型和卷积神经网络的方法训练勒索病毒的检测器与家族分类器。
3.3.1 决策树模型
决策树模型设定勒索病毒检测与分类的训练集与测试集的划分比例为9 ∶1。使用决策树算法训练勒索病毒检测器与勒索病毒分类器,其中勒索病毒检测器的模型测试混淆矩阵如图3 所示,勒索病毒检测器的准确率为94.56%,分类精度为97.05%,召回率为89.18%。勒索病毒家族分类器的模型测试混淆矩阵如图4 所示,勒索病毒检测器的准确率为82.35%。

图3 决策树算法检测器测试混淆矩阵

图4 决策树算法家族分类器测试混淆矩阵
3.3.2 随机森林算法
随机森林算法设定勒索病毒检测与分类的训练集与测试集的划分比例为9 ∶1,设置随机森林中的决策树数量为150,训练勒索病毒检测器与勒索病毒分类器。其中勒索病毒检测器的模型测试混淆矩阵如图5 所示,勒索病毒检测器的准确率为96.73%,分类精度为94.72%,召回率为97.29%。勒索病毒家族分类器的模型测试混淆矩阵如图6 所示,勒索病毒检测器的准确率为90.19%。
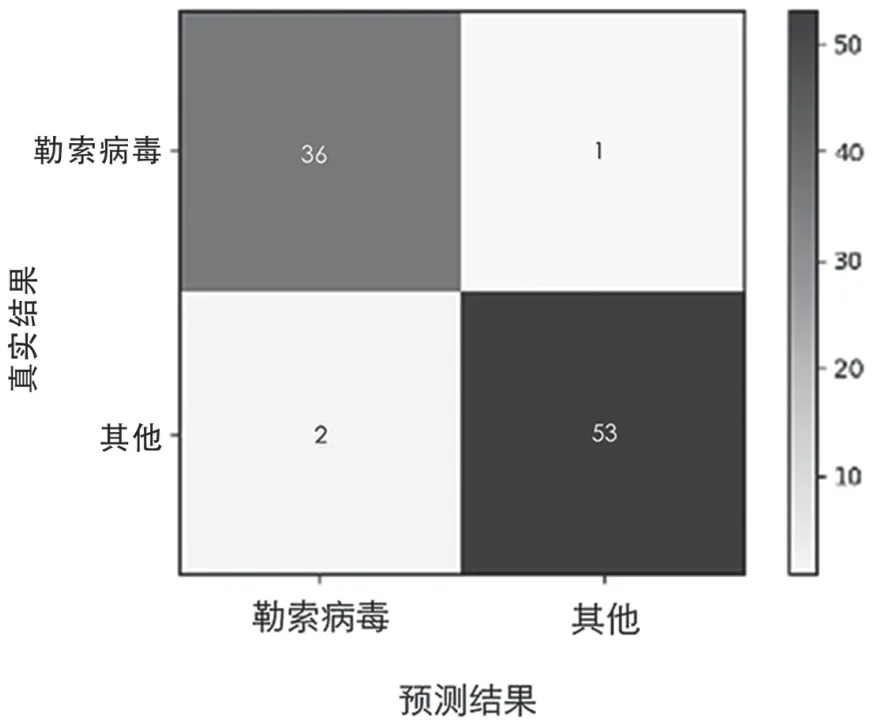
图5 随机森林算法检测器测试混淆矩阵

图6 随机森林算法家族分类器测试混淆矩阵
3.3.3 卷积神经网络模型
设置卷积神经网络模型训练集与测试集的比例划分为8 ∶2。模型训练时设定平均序列长度为5 000,batchsize 为10,丢弃概率为0.5,学习率为0.001。设置序列的最大长度为5 000。预训练得到的API函数名称特征向量维度为50 维,结合软件的API函数调用的现实情况设置卷积核大小为2×50,3×50,4×50,5×50。
勒索病毒检测器的模型测试混淆矩阵如图7 所示,勒索病毒检测器的准确率为97%,分类精度为95.62%,召回率为95.09%,F1-score 为96.03%。勒索病毒家族分类器的模型测试混淆矩阵如图8 所示,勒索病毒检测器的准确率为94%,分类精度为89.1%,召回率为82.04%,F1-score 为76.42%。
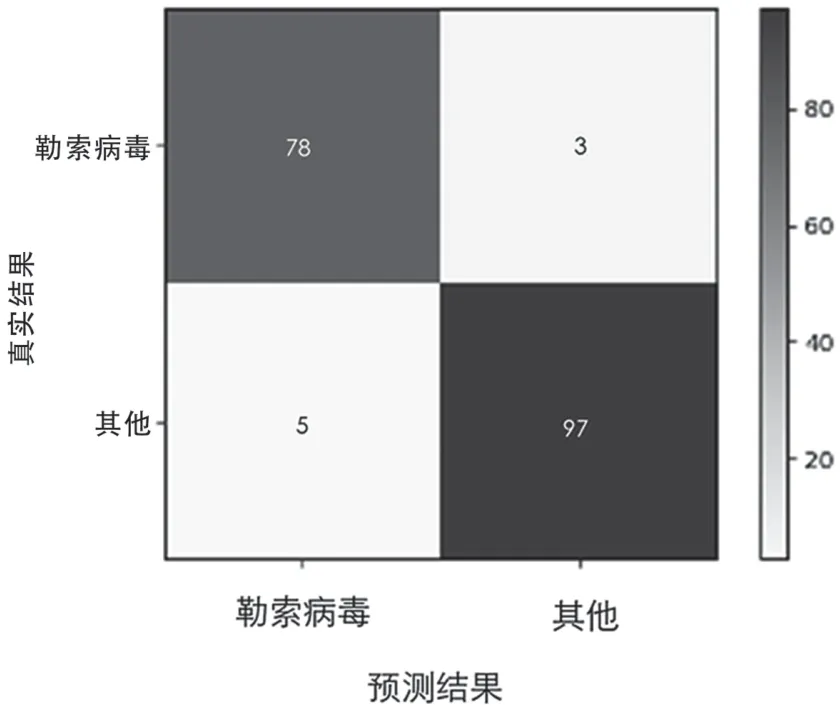
图7 卷积神经网络检测器测试混淆矩阵

图8 卷积神经网络家族分类器测试混淆矩阵
综上,无论是使用决策树算法还是随机森林算法,都可以有效实现对勒索病毒的检测与家族分类。其中,随机森林模型的勒索病毒检测和家族分类测试效果都明显优于决策树算法。使用卷积神经网络的方法对勒索病毒的检测和家族分类效果都有提升,其中检测准确率高达97%。在家族分类方面,卷积神经网络的提升更加明显,模型测试准确率为94%。
此外,可以发现勒索病毒的检测效果明显优于勒索病毒家族分类效果。虽然使用卷积神经网络方法的分类器模型准确率较高,但是部分家族的分类精度、召回率不高。勒索病毒家族分类效果不佳可能是因为家族数据集的不完善,数据集内有的家族的样本较少,这使得模型不能充分学习该家族的特征,导致模型对部分勒索病毒家族的分类效果不好。
4 结语
近年来,勒索病毒攻击给企业和个人带来了很大困扰,隐匿高危勒索病毒的肆虐也为勒索病毒的防御带来了新的挑战。本文从电力系统的实际情况出发,以Windows 平台的可执行文件格式的勒索病毒为研究对象,研究其及其所属各勒索病毒家族的行为特征,并利用Cuckoo Sandbox 软件获取勒索病毒软件的行为分析报告,从中提取中样本的行为特征。针对获得的勒索病毒行为特征,分别采用了决策树、随机森林的方法和基于卷积神经网络的深度学习算法训练了分类器实现了勒索病毒的检测与家族分类。本文的勒索病毒检测与家族分类直接对API 函数调用序列进行分析,对勒索病毒的应急防护有积极意义,能够帮助企业或个人在受到勒索病毒威胁时快速反应,即针对勒索病毒所属家族做出针对性防御,也可以与动态行为分析结合用于除勒索病毒外其他种类恶意软件的分析。
本文的勒索病毒检测器准确率达到了97%,勒索病毒家族分类准确率达到94%。
本文主要的贡献有3 项:
(1)收集了13 个勒索病毒家族共507 个样本,并对其进行了动态行为分析,从中总结出其典型的API 函数特征;
(2)搭建了卷积神经网络模型,结合文本分类思路训练了勒索病毒分类器;
(3)训练了勒索病毒检测器与勒索病毒家族分类器,准确率超过90%。
