基于深度学习的机器阅读理解研究综述
2023-01-14杜永萍赵以梁阎婧雅郭文阳
杜永萍,赵以梁,阎婧雅,郭文阳
(北京工业大学 信息学部,北京 100124)
认知智能是人工智能发展的最高阶段,其目标是让机器掌握人类的语言和知识体系,并真正理解其内在逻辑,这意味着机器开始具备分析和思考的能力。自然语言是认知科学的一项重要研究内容,用自然语言与计算机进行通信,意味着要使计算机能够理解自然语言文本的意义,以自然语言理解为核心技术的自动问答、人机对话、聊天机器人已经成为产业界和学术界的关注热点。
自动问答是语言理解的重要应用领域,特别是机器阅读理解,赋予了计算机从文本数据中获取知识和回答问题的能力,它是人工智能中一项挑战性的任务,需要深度理解自然语言并具备一定推理能力。
近年来,机器阅读理解领域的研究进入快速发展时期,一方面得益于大规模高质量数据集的发布:包括Facebook Children’s Books Test[1]、SQuAD[2]以及TriviaQA[3]等高质量数据集;另一方面,基于深度学习技术的模型在获取上下文交互信息方面明显优于传统模型,例如基于双向注意力机制的BiDAF 模型[4]、Transformer[5]和基于注意力机制的循环神经网络R-Net[6]。中文问答任务上,基于注意力机制的模型如N-Reader[7]在中文数据集DuReader[8]上取得了较好的成绩。
近期,预训练模型[9-10]与知识推理技术[11-12]在复杂问答任务上取得了优异的表现,特别在多跳问答任务中,问题的答案需要从多个篇章中获取,模型需要通过推理才能得出答案,图神经网络在该类任务上具有较好的适用性,Ding 等[11]使用认知图谱与图神经网络解决复杂数据集的推理任务并取得当时SOTA 的结果。
1 机器阅读理解任务
机器阅读理解任务,从输入信息的角度,可分为两种类型:基于多模态的阅读理解任务和基于文本的阅读理解任务。
基于多模态的阅读理解任务是指使机器能够对文本、图片以及视频等多种来源的信息进行学习,该研究任务更贴近于人类对信息获取的综合感知的学习方式,它是新兴的具有挑战性的研究方向。目前已有一些基于多模态的阅读理解任务的评测任务和数据集,如RecipeQA[13]和TQA[14]等。
本文主要针对基于文本的阅读理解任务进行分析,主要分为四类:完形填空式任务、选择式任务、片段抽取式任务和自由作答式任务。
1)完形填空式任务:对于给定的篇章P,从P中删去词语A。任务要求机器学习到函数F,从Q=P-{A} 中对P中缺少的词语或实体进行补全,即A=F(Q)=F(P-{A})。
完形填空式任务的难点在于,机器需要从不完整的文本中学习上下文语义关系,并且不仅需要对篇章所表达的内容进行理解,还需要把握篇章的语言表达、词语运用的习惯,从而正确地对被删去的内容进行预测。该任务代表性数据集有CNN/DailyMail[15]、Facebook Children’sBooks Test[1]等。
2)选择式任务:对于给定的篇章P和问题Q,以及问题Q的候选答案集合A={A1,A2,···,An},要求机器学习到函数F,根据P、Q、A从A中选择对Q回答正确的一项,即Ai=F(P,Q,A)。
选择式任务的特点在于要求数据集提供问题的候选答案集合。机器在完成选择式任务时,需要对篇章、问题、候选答案之间的语义关系进行理解和分析,给出正确的判断。该任务的代表性数据集有WikiHop[16]、CommonsenseQA[17]等。
3)片段抽取式任务:对于给定的篇章P={w1,w2,···,wn}和 问题Q,机器学习到函数F,根据对P和Q的理解,从P中选取连续片段A作为Q的答案,即A=F(P,Q),A={wi,wi+1,···,wj},A∈P。
片段抽取式任务的特点在于问题的答案可以在篇章中找到,且答案可以是词语、实体或句子等形式。构建数据集时对问题的选取有一定要求,该任务的代表性数据集有SQuAD[2]、NewsQA[18]等。
4)自由作答式任务:对于给定的篇章P和问题Q,机器学习到函数F,根据对P和Q的理解得出答案A,且A不一定在P中出现,可以为任意形式,即A=F(P,Q)。
自由作答式任务在答案的选取上最为灵活,答案的形式也无限制,且答案范围不局限于给定篇章。这类任务往往要求机器具有一定的分析、推理能力。该任务的代表性数据集有DuReader[8]、DROP[19]等。
2 机器阅读理解技术
2.1 基于端到端神经网络的机器阅读理解技术
传统的机器阅读理解方法通常是基于规则或者统计学规律,但随着该任务数据集的规模和质量的提升,深度学习方法表现出了良好的性能。如今机器阅读理解模型的构建大多采用双向循环神经网络对问题和篇章进行编码,并在问题-篇章交互层中使用注意力机制。
机器阅读理解模型的输入通常为问题和篇章,最终的输出是问题的答案。常见的基于深度学习的机器阅读理解模型主要包括4 个层次:词嵌入层、编码层、问题-篇章交互层以及答案预测层,如图1 所示。

图1 基于深度学习方法的机器阅读理解通用模型结构Fig.1 Generic architecture of machine reading comprehension model based on deep learning
1)词嵌入层:问题和篇章输入模型后,将输入的自然语言文字转换为定长向量。可以通过独热编码、分布式词向量表示等多种方式分别得到问题和篇章的嵌入表示。采用大规模语料库预训练得到的词表示会包含丰富的上下文信息。例如QANet[20]中使用预训练词表GloVe[21]作为词的初始化表示,为后续模型正确预测答案提供支撑。
2)编码层:词嵌入层的输出作为编码层的输入,分别对问题和篇章进行建模。一些典型的深度神经网络,例如循环神经网络,具有能够处理时间序列预测问题的特性,它通常被应用在编码层来挖掘问题和篇章的上下文信息。R-Net[6]采用多层的双向循环神经网络构建模型,并利用自注意力机制进一步捕获更加丰富的上下文信息。循环神经网络的优点是隐藏层的神经元之间可以进行交互,使得信息具有传递性。Attentive Reader[15]中的编码层部分由双向循环神经网络正向和反向的输出拼接得到篇章中第t个位置词的表示,并计算该位置词的权重。
3)问题-篇章交互层:问题和篇章之间的关联对答案的预测有着重要的作用。注意力机制被广泛应用于问题-篇章交互层中,包括单向注意力机制、双向注意力机制以及自注意力机制,用于增强与问题相关的篇章部分的表示。如图2 所示,将问题Q={x1,x2,x3,x4,x5} 融入到篇章C中,若要得到C中的词y的表示,首先计算Q中每个词的权重w1,w2,w3,w4,w5=softmax(QT,y),由y与Q中每个词点乘并使用行向 softmax进行归一化得到;然后对Q中每个词进行加权求和得到融入问题信息的词y的表示,即=w1x1+w2x2+w3x3+w4x4+w5x5。以此类推,计算得到篇章C中每个词的新的表示,记作A(Q,C)。

图2 注意力机制的原理示意Fig.2 Structure of attention mechanism
BiDAF[4]提出的双向注意力机制不仅计算融入问题信息的篇章表示,也计算了融入篇章信息的问题表示,从而进一步提高了模型对问题和篇章的理解能力。注意力机制相比于循环神经网络,其复杂度更小,参数量也更少,解决了循环神经网络不能并行计算和短期记忆的问题。自注意力机制在机器阅读理解任务中常被用来关注篇章自身的内容,即 Att(C,C),目的是计算篇章中各个词的相似度,以学习到篇章自身词与词之间的关系,R-Net[6]、T-Reader[22]、HQACL[23]模型均采用自注意力机制提高了模型对篇章的理解能力。
4)答案预测层:答案预测层用于输出问题的答案。机器阅读理解的任务类型不同,答案形式也不同。完形填空式任务的输出是篇章中的一个单词或实体;选择式任务的输出是从候选答案中选出正确答案;片段抽取式任务需要从篇章中抽取连续子序列作为输出;对于自由作答式的任务,文本生成技术通常被用于该层来生成问题的答案。
2.2 基于预训练语言模型的机器阅读理解技术
预训练模型已经在自然语言处理的多项下游任务中取得了优秀的性能,包括OpenAI GPT[24]、BERT[9]、XLNet[10]等,可以有效获取句法和语义信息,并进行文本表示。预训练方法通常用于机器阅读理解任务的词嵌入层,将自然语言文本编码成固定长度的向量。词的表示方法中,独热编码无法体现词与词之间的关系;分布式词向量表示方法虽然可以在低维空间中编码并通过距离度量词与词之间的相关性,但并没有包含上下文信息,为了解决这个问题,基于预训练的词表示方法被提出并应用。
Transformer[5]是第一个完全基于注意力机制的序列生成模型,BERT[9]提出利用双向Transformer 预训练得到上下文级别的词表示。XLNet[10]以自回归语言模型为基础融合自编码语言模型的优点,克服了自回归语言模型无法对双向上下文信息进行建模的缺点。XLNet[10]引入双流自注意力机制以解决目标位置信息融入的问题,同时使得模型能够处理更长的输出长度。但是,常规的预训练方法无法对文本中的实体及关系建模,ERICA[25]框架被提出用于解决该问题,实现深度理解,它可以提升典型的预训练模型BERT[9]与RoBERTa[26]在多个自然语言理解任务上的性能,包括机器阅读理解。
此外,在面向中文的预训练语言模型中,ChineseBERT[27]将具有中文特性的字形和拼音融入预训练过程中,在机器阅读理解等多项中文自然语言处理任务中达到了SOTA,该模型在训练数据较少的情况下优于常规的预训练模型。
尽管预训练语言模型的上下文表示已经包含了句法、语义等知识,但挖掘上下文表示所蕴含的常识的工作较少,它对于机器阅读理解是非常重要的。Zhou 等[28]在不同具有挑战性的测试中检验GPT[24]、BERT[9]、XLNet[10]和RoBERTa[26]的常识获取能力,发现模型在需要更多深入推理的任务上表现不佳,这也表明常识获取依然是一个巨大挑战。
2.3 基于知识推理的机器阅读理解技术
如何提高系统的可解释性是人工智能领域一项重要挑战,对于机器阅读理解等自动问答任务,特别是复杂问题回答,机器需要具备通过推理来获取答案的能力,而目前的深度学习方法可解释性较差是一个普遍现象,无法将推理过程进行显示地表达。常见的基于知识推理的机器阅读理解技术包括语义蕴含推理、知识图谱推理以及基于检索的多跳推理,如图3 所示。

图3 基于知识推理的机器阅读理解技术Fig.3 Technologies of machine reading comprehension model based on knowledge inference
基于语义蕴涵推理的问答方法:问题回答可转换为文本蕴涵任务,将问题和候选答案组成假设,系统决定候选知识库是否能推出假设。Shi等[29]研究一种神经符号问答方法,将自然逻辑推理集成到深度学习体系结构中,建立推理路径,计算中间假设和候选前提的蕴含分值,提升模型性能并具有可解释性。Dalvi 等[30]以语义蕴涵树的方式来生成解释,并创建了首个包含多阶蕴涵树的数据集EntailmentBank,逐步从已知事实逼近由问题和答案构成的最终假设,为自动问答任务生成更加丰富的和系统的解释,通过一系列的推理链来支撑正确答案的获取。同时,也出现了无效蕴涵推理等问题,有待优化,但该方法在进一步提高模型的可解释性方面进行了有效尝试。
基于知识推理的问答方法:知识图谱是一种以关系有向图形式存储人类知识的资源,与无结构的文本数据相比,结构化的知识图谱以一种更加清晰准确的方式表示人类知识,从而为高质量问答系统的构建带来了前所未有的发展机遇,有代表性的大规模知识图谱包括ConceptNet[31]、DBpedia[32]、YAGO[33]等。常识问答数据集CommonsenseQA[17]是通过从ConceptNet[31]中抽取出具有相同语义关系的知识,构建问题和答案。
基于知识增强的常识类问题回答中,首先面临的问题是,知识图谱与自然语言文本表达的异构性。Bian 等[34]提出一种将知识转化为文本的框架,用于为常识问答提供评测基准,在CommonsenseQA[17]上取得最优性能,同时也表明知识的潜力在常识问答任务上未得到充分利用,在上下文相关的高质量知识选择、异构知识的利用等方面有待继续深入。知识表达通常采用基于图的方法,但该方法关注于拓扑结构,忽略了节点和边所蕴含的文本信息。Yan 等[35]提出基于BERT[9]的关系学习任务,将自然语言文本与知识库对齐进行推理,并证明了关系学习方法的有效性。
更进一步,针对生成式常识推理这一更具有挑战性的任务,现有模型很难生成正确的句子,其中一个重要原因是没有有效结合知识图谱中常识知识之间的关系信息。Liu 等[36]研究知识图谱增强的KG-BART 模型,结合知识图谱生成更有逻辑性更自然的句子表达,通过图注意力聚合概念语义,增强对新概念集的泛化能力。该方法的实验结果证明,结合知识图谱后,模型可以生成质量更高的语句。KG-BART 模型可以迁移到常识问答等以常识为中心的下游任务。
基于检索与知识融合的多跳推理方法:多跳问答是一项需要多层推理的挑战性任务,在实际应用中十分普遍。该任务需要从大规模语料库中发现回答问题的支撑证据,分析分散的证据片段,进行多跳推理实现对问题的回答。多跳问答通常使用实体关系进行分步推理,已有方法通过预测序列关系路径(较难优化)或汇聚隐藏的图特征进行答案推理(可解释性差)。Shi 等[37]提出了TransferNet,TransferNet 使用同一框架支持实体标签和文本关系的表示,推理的每一环节关注问题的不同部分,传递实体信息,取得优秀性能表现。Li 等[38]提出新的检索目标“hop”来发现维基百科中的隐藏证据,将hop 定义为含有超链接的文本和链接到的文档,检索维基百科回答复杂问题。
针对现有基于单跳的图推理方法会遗漏部分重要的非连续依赖关系的难题,Jiang 等[39]定义高阶动态切比雪夫近似图卷积网络,将直接依赖和长期依赖的信息融合到一个卷积层来增强多跳图推理,在文本分类、多跳图推理等多个任务上进行实验,取得了最优性能。Feng 等[40]提出一种适合多跳关系推理的模型MHGRN,结合图神经网络和关系网络,通过多跳信息传递,在长度最多为k的关系路径上传递信息,赋予图神经网络直接建模路径的能力。
3 数据集与评价指标
3.1 数据集
大规模高质量数据集的发布是推动机器阅读理解快速发展的重要因素,根据不同任务类型,代表性数据集如表1 所示,发布时间轴如图4 所示。其中,完形填空式问答任务数据集中Book-Test[14]的问题规模最大,在2015 年以后片段抽取式的数据集规模均在万级以上。

图4 机器阅读理解数据集发布时间轴Fig.4 Time axis of machine reading comprehension datasets

表1 机器阅读理解主要数据集统计Table 1 Statistics of machine reading comprehension datasets

续表 1
其中,规模较大的数据集如SQuAD 2.0[46]、BookTest[14]和NewsQA[18],推动了BiDAF[4]、RNet[6]等经典模型的发展。
在片段抽取式数据集中应用广泛的数据集有SQuAD[2],模型QANet[20]与BERT[9]在该数据集上表现尚佳,且BERT[9]在两个评测指标上首次超越了人类水平,在此基础上预训练语言模型与微调的方法成为主流。在自由式问答数据集DROP[19]中,仍然与人类F1值为0.964 2 的水平存在一定距离。在需要推理的任务中,在选择式数据集CommonsenseQA[17]性能表现优异的模型中用到了知识图谱和图神经网络,评测排名第一的DEKCOR[54]模型还引入了辅助的篇章信息,但与人类水平仍有差距。
3.2 评价指标
3.2.1 准确率
准确率是最常用的评价指标,它表示机器阅读理解模型正确回答的问题占所有问题的百分比。设机器阅读理解任务包含n个问题,其中模型正确回答了m个问题[55],则准确率a的计算为
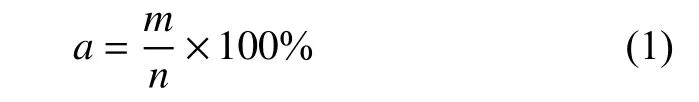
准确率一般用于评价完形填空式和选择式问答任务,例如Facebook Children’s Books Test[1]、CommonsenseQA[17]等。片段抽取式问答数据集中的SearchQA[45]和自由式问答数据集中的DROP[19]也使用了该指标。
EM(exact match)值与准确率的计算相同,EM 值要求式(1)中的m为所有问题中模型输出答案与正确答案完全相同的个数,即模型输出答案与正确答案中的每个单词和位置都必须相同。在片段抽取式问答任务中,EM 值与准确度相同,且使用EM 值作为它们的评价指标,例如SQuAD[2]、TriviaQA[3]、HotpotQA[49]等。
3.2.2F1值
F1值评价指标,表示数据集中标准答案与模型预测的答案之间平均单词的覆盖率,将精确率P(precision)和召回率R(recall)折中。其中,精确率为预测正确的答案占所有预测答案的百分比,召回率则是预测正确的答案占所有标准答案的百分比,而F1值是将这两个指标综合在一起,即

F1值通常是片段抽取式问答任务采用的评价指标,例如SQuAD[2]、HotpotQA[49]等。自由式问答任务中的Natural Questions-Short[53]也使用了F1值。相比于EM,F1值允许模型预测答案和正确答案之间有一定范围偏差,因此,数据的类别分布不平衡时,F1值更适用。
3.2.3 其他评价指标
ROUGE-L[56]相比于EM 值和F1值更灵活,其值用于评价预测答案和真实答案之间的相似度,但候选答案的长度会影响ROUGE-L 的值;BLEU[57]最初用于机器翻译任务中,不仅可以评价预测答案和真实答案之间的相似度,还可以考察候选答案语言表达流畅性,但BLEU 对词重复和短句现象不利。因此这两个指标通常用于不受原语境限制的任务中。一般在自由式问答中使用ROUGE-L[56]和BLEU[57]作为评价指标,例如DuReader[8]、DROP[19]等。
4 机器阅读理解领域的挑战和发展趋势
目前,在大规模高质量数据集的推动下,机器阅读理解领域的研究取得了快速发展,甚至在部分评测任务上已经超过了人类的表现。但是,在一些新提出的任务或研究方向上,机器目前的性能远未达到人类的理解水平。该领域目前的主要挑战和发展趋势概括如下。
知识驱动与推理技术提升可解释性:将知识融入机器阅读理解任务中来实现复杂的问题回答是基于人类的思考方式提出的一种策略[58]。知识驱动的阅读理解模型通过引入外部知识,辅助理解篇章内容并回答问题。大规模知识库的构建也需要考虑知识的获取方式、多模态资源中知识的获取、不同来源的知识的融合。同时,知识驱动与推理技术的运用可以较好地解决基于神经网络模型可解释性差的问题。
对话式问答任务中的语义理解:对话式问答同样是根据人类获取知识的习惯而提出的任务,让机器根据已有的一系列问答序列,对当前问题进行回答。其中,问答序列具有时序性和前后关联性,如何理解当前问题与历史问答记录的关系是该任务的一大难点。此外,指代消解技术在该任务中非常重要,机器需要根据历史问答记录,准确理解篇章、问题中的指代实体,进行补全。
机器阅读理解模型的健壮性:目前的机器阅读理解模型往往过于依赖文本表面的信息,而缺乏深入的理解。在篇章中引入干扰数据,生成对抗样本,结果表明,多数现有模型性能明显下降。如何生成有效的对抗样本,通过对抗训练提升模型的健壮性成为研究的重点。
5 结束语
机器阅读理解是自然语言处理领域的难点问题,它是评价和度量机器理解自然语言程度的重要任务。近年来基于深度学习技术的机器阅读理解模型研究发展迅速。本文介绍了机器阅读理解任务划分,对机器阅读理解相关技术进行了分析,包括端到端的神经网络模型、预训练语言模型以及知识推理等方法,并选取了各个任务中有代表性的数据集进行统计分析,介绍了不同机器阅读理解任务中常用的评价指标。目前机器的语言理解能力距离人类的理解水平还有较大差距,我们对该领域面临的挑战和发展趋势进行了分析。
