面向样本扩充的新型风格迁移网络研究
2023-01-13刘名果陈立家韩宗桓兰天翔
田 敏,刘名果,陈立家,韩宗桓,兰天翔,梁 倩
河南大学 物理与电子学院,河南 开封 475000
随着人工智能的发展,全监督语义分割领域发展迅速。全监督语义分割网络是将图像中的每一个像素进行分类,得到像素化密集分类结果的网络。自2007年以来,语义分割一直作为机器视觉中的一部分,直到2015年,Long等人[1]首次使用全卷积网络(fully convolution network,FCN)对图像进行端到端分割,语义分割产生了重大突破,之后一些较好模型的架构都是在此架构的基础上进行的改进;2015年,Ronneberger等人[2]构建了U-Net模型,构建了一套完整的编码解码器。2017年,Badrinarayanan等人[3]提出SegNet模型,将最大池化转换为解码器来提高分辨率;RefineNet[4]使用了残差网络降低了内存的使用量,同年的DeepLabv1和DeepLabv2,再到现在的DeepLab v3+[5-7],语义分割精度在不断地得到提升。随着语义分割网络的快速发展,该网络逐步应用于工业生产中,但在应用过程中,因为标签制作较为困难,用于训练的样本数据较为匮乏等,使得相关研究面临着挑战。一方面,采用传统方法进行样本采集(拍照、手机扫描等手段)和标签的制作,人力、物力成本较高,尤其要花费大量时间制作标签,效率较为低下;另一方面用于训练的数据样本较少,直接进行语义分割训练容易出现过拟合。为了避免在训练过程中出现过拟合现象,往往采用数据增强的方法,变换原有数据生成新的数据来扩大数据集。常用的扩充样本方法[8]有翻转、旋转、裁剪、平移、添加高斯噪声、对比度变换等。虽然这些方法在一定程度上提升了网络的性能,但并不能从根本上解决制作数据集时的人工时间耗费问题。
针对全监督语义分割网络训练样本标签制作困难的问题,尤其是对于特定工业应用场景,无公开的样本库,需要自制标签的情况,提出基于改进型循环生成对抗网络(CycleGAN-AD)的样本扩充方法。利用计算机生成虚拟样本图像,再通过本文提出的网络将虚拟样本迁移成真实样本的风格[9]。由于计算机生成的虚拟样本的标签无需手工标注,所以省去了人工标定的工作量。CycleGAN[10]在生成式对抗网络(generative adversarial network,GAN)[11]基础上实现了图像风格双域转换,解决了生成图片不清晰、训练数据不成对无法训练的问题。但是在特定工业场景中,CycleGAN进行风格迁移时对图片中一些细节处理不足,背景转换能力欠缺。本文中提出的CycleGAN-AD网络针对上述问题做出的改进及创新如下:
(1)在CycleGAN的生成器中添加了注意力机制(attention mechanism)[12]。选用通道注意力机制,通道注意力机制主要由最大池化层、平均池化层与全卷积网络层构成,网络训练过程中通过提取图片中的有效信息,提升了风格迁移结果。
(2)使用密集连接卷积网络(dense convolutional network,DenseNet)[13-14]代替CycleGAN中的残差网络(residual neural network,ResNet)[15]。DenseNet网络中,每一层都由前面几层相加构成,网络层之间连接更为紧密,保证原始图片的细节不因卷积网络层太深而被破坏。
(3)一方面提出将自带标签的计算机模拟图片风格迁移生成真实图片,将生成图片与真实图片一起构成数据集,改善了语义分割效果;另一方面因在有监督训练中,真实图片标签制作困难且耗时长,为了减少制作真实图片标签,即使在少量真实图片标签情况下,利用模拟图片风格迁移生成的图片进行实验也能保证语义分割结果可以用于工业应用当中。
实验结果表明,CycleGAN-AD网络对图像细节处理较好,生成的图片更加清晰。在石墨电极钢印字符语义分割实验中,在原真实样本中加入CycleGAN-AD网络产生的样本,相较于未添加样本前,其MIoU值有了显著提升,最高可达0.826 0。
1 本文方法
本文利用图像风格迁移的方法实现样本扩充,主要分为两部分。如图1所示,第一部分为源域(模拟样本)风格迁移得到目标域(真实样本)。源域图片比较容易获得,并且自带标签,得到的目标域图片标签与源域标签相同。第二部分分为两组:第一组只将生成的目标域图片与自带标签送入语义分割网络,测试其分割结果,属于无监督语义分割;第二组,生成目标域与目标域及标签送入语义分割网络,训练并测试其结果,属于有监督语义分割。文中主要对第一部分中的风格迁移网络进行了改进,提高风格迁移图像质量,第二部分主要用于测试改进网络是否对语义分割结果有所提升。与人工制作标签进行语义分割的原始方法相比较,引入风格迁移网络,节省了人工标注样本的时间,减少了工作量,并且将生成样本与真实样本一起组成训练样本,扩充了数据集,避免了过拟合的发生。
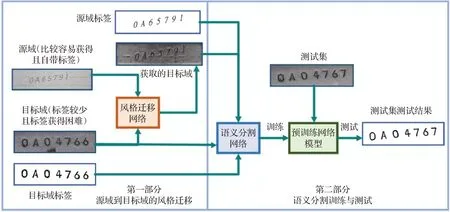
图1 本文方法主要流程Fig.1 Main process of proposed method
1.1 改进风格迁移网络(CycleGAN-AD)
进行风格迁移的网络采用改进的循环生成式对抗网络CycleGAN-AD。CycleGAN结构如图2所示,本质上是两个镜像对称的生成式对抗网络GAN构成的一个环形网络,GAN网络由生成器(generator)与判别器(discriminator)组成。模拟图像Input_X经过生成器GeneratorX2Y生成图像Generated_Y,Generated_Y与真实图像Input_Y共同输入判别器Discriminator_Y。判别器判别输入图像真假,同时生成器也在不断优化,两者通过博弈,图片Generated_Y与真实图像Input_Y越来越相似,同时再经过生成器GeneratorY2X生成与Input_X相似的图片Cyclic_X。Input_X与Cyclic_X之间存在循环重构损失函数,通过网络训练与优化,两者之间图像数据分布越来越接近,由Input_Y到Input_X亦是如此。CycleGAN作为图像风格迁移网络,生成的风格图像已满足基本需求,但本文需要将模拟图像风格迁移生成的图像应用于语义分割网络,对细节的处理要求较高。为此,需对CycleGAN进行改进,提高图像生成质量。
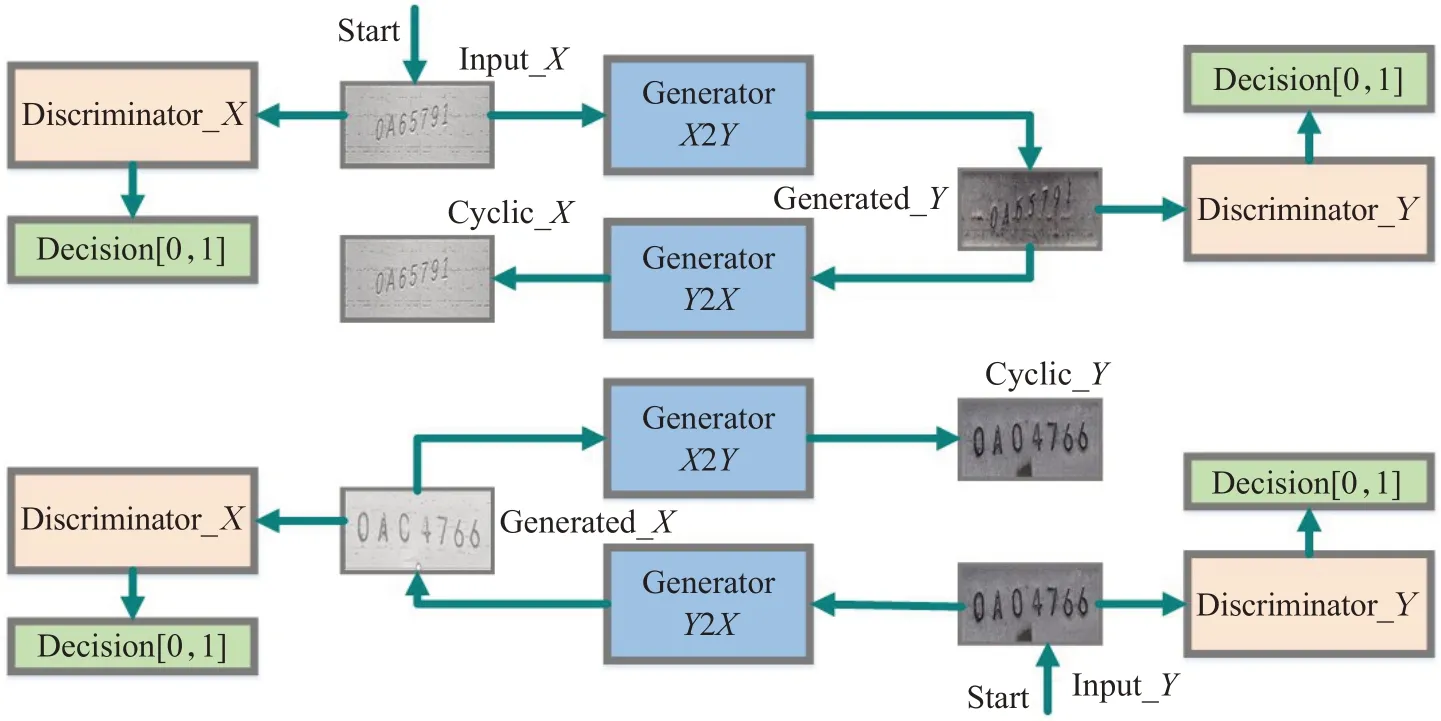
图2 CycleGAN结构图Fig.2 CycleGAN structure diagram
1.1.1 生成器结构
生成器整体结构如图3所示,主要由编码器、转换器、解码器三部分构成。其中,编码器由卷积网络层构成,转换器由残差网络构成,解码器由反卷积网络层构成。本文主要对生成器进行了两点改进:
(1)引入注意力机制。为了保持模拟图像中的重要细节,提高生成图像质量,将注意力机制加入到编码器中。图4中,注意力机制选用通道注意力[16],通道方向的注意力建模的是各个特征通道的重要程度,针对不同任务抑制或增强不同的通道。经过编码器生成的特征图输入到通道注意力网络,它同时使用最大池化(MaxPooling)和均值池化(AvgPooling)算法,然后经过多层感知机(multilayer perceptron,MLP)[17]获得变换结果,将结果分别应用于两个通道,使用Sigmoid函数得到通道注意力特征图,最后将通道注意力特征图与原输入特征图进行元素相乘的卷积操作。
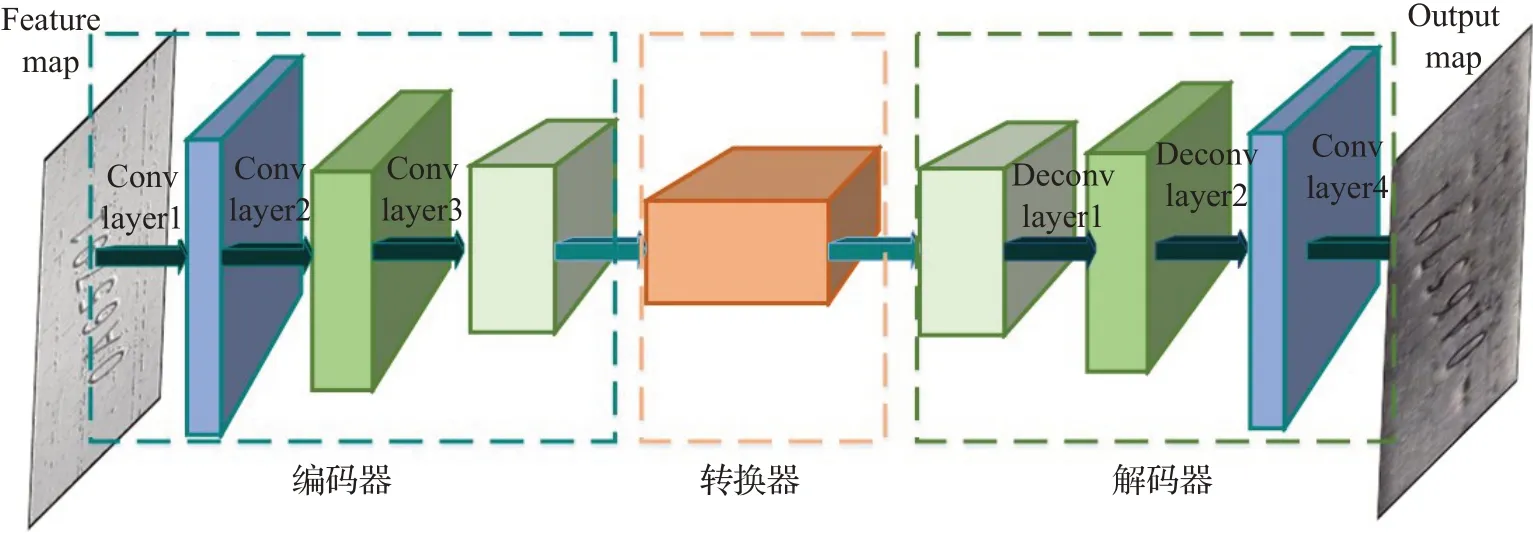
图3生成器结构图Fig.3 Generator structure diagram

图4通道注意力机制Fig.4 Channel attention mechanism
(2)替换转换器。转换器由原残差网ResNet结构改进为具有密集连接的卷积神经网络DenseNet。由图5可以看出,DenseNet任两层之间都有直接的连接,每一层的输入都是前面所有层输出的并集并且该层所学习的特征图也会被直接传给其他后面所有层作为输入。DenseNet相较于ResNet来说,在一定程度上缓解了梯度消失,加强了特征传递,更有效地利用了特征,在模拟样本特征得到有效保留的前提下学习到了真实样本的风格。
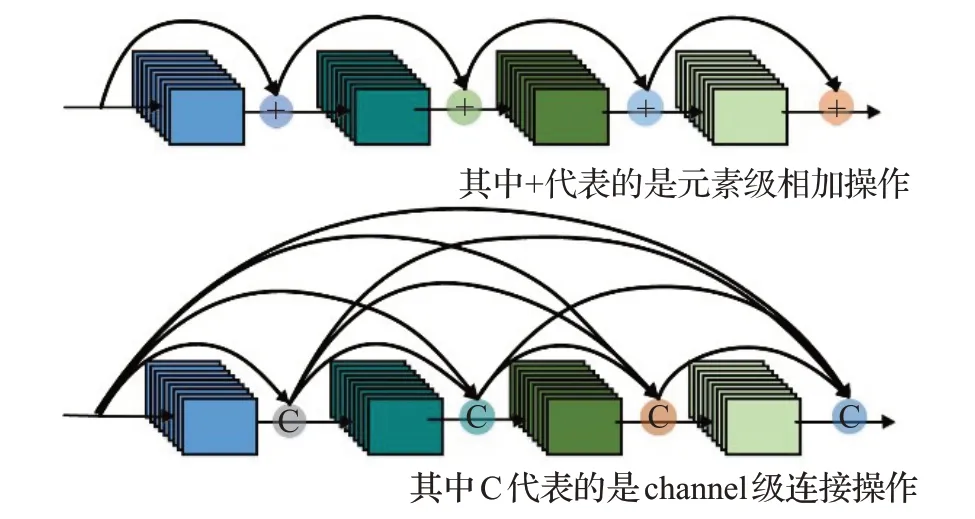
图5 ResNet与DenseNet连接机制对比Fig.5 Comparison of connection mechanism between ResNet and DenseNet
1.1.2 判别器
判别器由一值输出改进为矩阵输出。图6中,判别器采用PatchGAN[18]结构,原始GAN中的判别器的输出值只有一个,单值判定输入判别器的图像是真实图像还是生成图像。但是本文中PatchGAN的输出为一个N×N的矩阵,矩阵中的每个点都需要做出判断,一个点代表原始输入图像中的一个区域,将矩阵中判断得到的值取平均值。由原来的一个值去判定输入图像真假变成现在N×N的矩阵来判定图像真假,后者可以判定更多的区域,得到关键区域信息,提升训练速度。
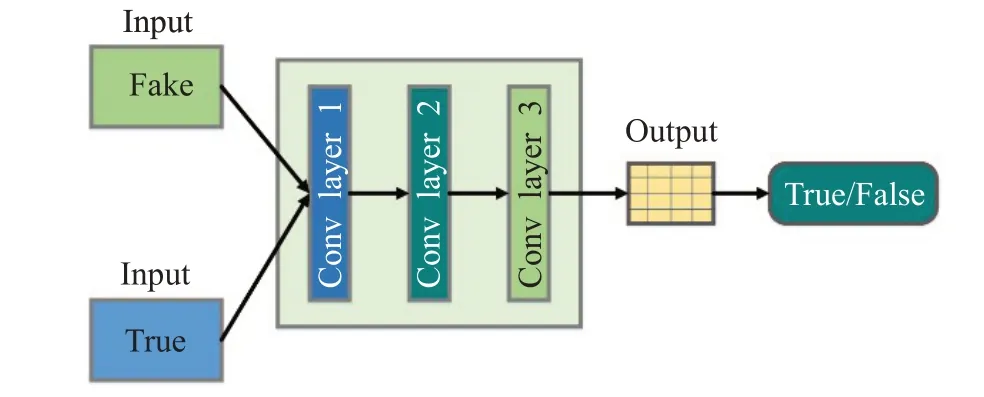
图6 判别器结构图Fig.6 Discriminator structure diagram
1.2 CycleGAN-AD中的损失函数
GAN作为CycleGAN的基础,GAN工作的过程可以看作是生成器和判别器相互博弈的过程,生成器G负责生成假的图片,假图与真图输入到判别器D中,判别器D判断输入图片的真假,生成器G生成越来越接近真图的假图,判别器D逐渐不能判断输入图片的真假,通过两者的相互博弈,达到纳什均衡。GAN中的对抗损失函数如式(1):
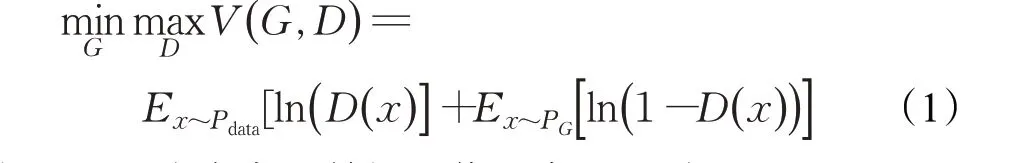
其中Pdata为真实的数据图像分布,PG为生成器生成的数据图像分布,E为数学期望。固定生成器G,训练判别器D,对于真实分布,D()x尽可能大,接近于1,对于生成式分布,D()x要接近于0;固定判别器D,训练生成器G,G在训练过程中,来自于生成分布中的x变化使得D()
x接近于1。CycleGAN在原始GAN的基础上做出了一个逆向过程,即由X转换为Y后再从Y转换回X,损失函数也是在原始GAN的损失函数基础上多了逆向的GANloss,此外还添加了针对X和Y的L1loss,整体损失函数为式(2):
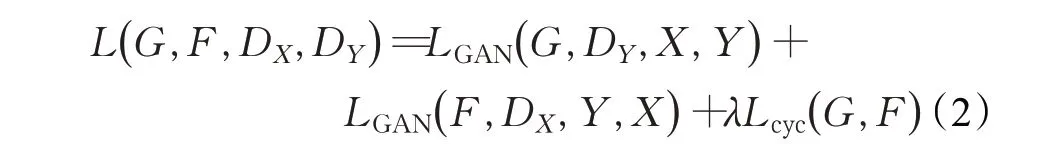
式中LGAN(G,DY,X,Y)表示生成器G和判别器DY的生成对抗损失函数,LGAN( F,DX,Y,X)表示生成器F和判别器DX的生成对抗损失函数,在本文中生成器F与生成器G结构相同。Lcyc( G ,F)表示重构损失中的循环重构损失函数,λ为循环重构损失相对于对抗损失的权重比例超参数。原始生成对抗损失函数表达式如式(3)、(4):
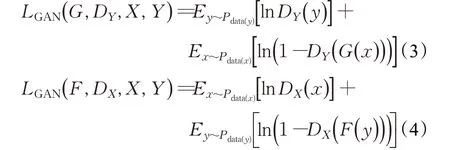
但因为采用对数作为损失函数会导致判别器训练不稳定,影响生成效果,所以最终的对抗损失函数为均方误差损失函数,表达式为式(5)、(6):
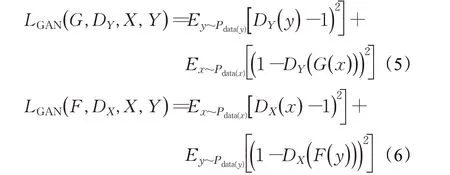
在无监督图像风格迁移的任务中,需要保留源域图像特征和目标域图像风格,仅存在对抗损失函数不能保证两者特性共同存在,所以在此基础上添加循环损失函数。目标变量与预测变量之间的绝对误差,保证源域特征结构不发生变化,循环损失函数如下式:

2 实验结果及分析
实验在服务器中进行,使用语言为Python3.7.3,深度学习框架为tensorflow1.13,服务器系统为Windows sever 2012,内存为32 GB,GPU为Tesla K40,显存为12 GB。实验数据集分为模拟样本数据集和真实样本数据集。模拟数据集为计算机制作SG-1500数据集,制作过程简单,并且自带标签,共有1 500张。真实数据集为采集的石墨电极钢印字符图片,GE-1650数据集,共有1 650张。其中,训练集1 300张,测试集350张,标签为人工标注标签。
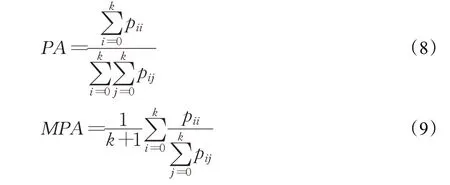
本文选用U-Net与DeepLabv3+作为语义分割训练网络,因本实验是对字符进行二分类语义分割,与其他语义分割网络相比,选用U-Net与DeepLabv3+网络作为训练网络,其训练速度较快,生成结果较好,常用于工业生产当中。使用像素精度(pixel accuracy,PA)、均相素精度(mean pixel accuracy,MPA)、均交并比(mean intersection over union,MIoU)作为实验中语义分割结果的评价指标。像素精度是图像分割中评价分割网络好坏的最简单的评价指标,计算被正确分类的像素个数和总像素数之间的比例,式(8)中,表示正确分类像素数,表示总像素数;均像素精度是像素精度的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均,在式(9)中,pii为每一类中的正确分类像素数为每一类的像素总数,然后各个类相加,最后取平均值。
均交并比为语义分割的标准度量,计算两个集合的交集和并集,在语义分割问题中,这两个集合为真实值(ground truth)和预测值(predictedseg mentation)。这个比例可以变形为正真数(intersection)比上真正、假负、假正(并集)之和,在每个类上计算IoU,之后平均,在式(10)中,G表示真实值,P为预测值,pii为正真像素数,表示真正与假负的像素数之和,-pii表示假正像素数。
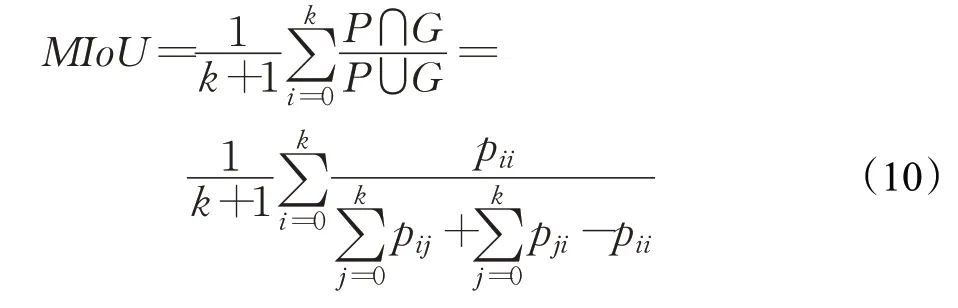
2.1 风格迁移实验
风格迁移实验共两个,一个选用CycleGAN常用horse2zebra数据集进行实验,另一个为本文中的石墨电极钢印字符实验。实验中批量大小batchsize设置为1,训练过程中,每100个epoch变化一次学习率,基础学习率为2E-4,采用Adam算法进行梯度下降训练优化,Adam中的参数beta1为0.5,循环一致性损失函数中的λ大小为15。选用图像质量评估指标FID(fréchet inception distance)来判断图像生成质量。FID从原始图像的计算机视觉特征的统计方面来衡量两组图像的相似性,计算真实图像与生成图像特征向量之间的距离。FID数值越小代表生成图片与目标图像更相似,生成图像质量越高。
实验1为了验证改进网络CycleGAN-AD对风格迁移结果有所提升,选用horse2zebra数据集,将马风格迁移成为斑马。其中,训练集,马图片有1 067张,斑马图片有1 334张;测试集,马图片122张,斑马图片140张。输入输出图像大小设置为256×256。实验结果如图7所示。
图7中,CycleGAN生成的斑马图片仍保留一些马的特征,其背景也保留原图片的色彩;改进网络CycleGAN-AD生成的图片中,斑马轮廓与条纹更加明显,背景也更接近于目标图片风格。

图7 马与斑马风格迁移结果Fig.7 Results of style transfer between horse and zebra
实验2将计算机模拟样本生成石墨电极钢印字符的风格迁移实验中,输入输出图片大小设置为128×512。
由图8石墨电极风格迁移结果可知,本文改进的CycleGAN-AD生成的目标域图像与原始CycleGAN生成图像相比较,图像背景更加清晰,颜色更接近于目标域背景。目标字符模拟真实自然场景(光照、对比度等)有所提高,并且CycleGAN生成的图像出现较多复杂线条噪点,改进网络后,线条噪点得到了减少。

图8 石墨电极风格迁移结果Fig.8 Results of style transfer of graphite electrode
由表1可知,改进网络的FID数值在两个数据集上相较于CycleGAN都有所减小,说明改进网络生成的图像质量更好,改进网络更优。

表1 FID指标数值对比Table 1 Comparison of FID index values
将实验2中的CycleGAN生成样本与CycleGAN-AD生成样本作为语义分割网络训练样本,对照语义分割结果是否有所提升,验证改进网络是否有效。
2.2 语义分割实验
实验分为两组,第一组,将风格迁移生成的图片样本和其标签送入语义分割网络进行训练,用真实测试集图片进行测试,原CycleGAN与改进的CycleGAN-AD测试结果进行比较。图9中,U-Net与DeepLab v3+为原网络测试结果,AD-U-Net与AD-DeepLabv3+为改进网络测试结果。
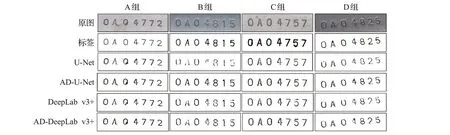
图9 语义分割测试结果对比Fig.9 Comparison of semantic segmentation test results
由图9可以看出,CycleGAN生成图片进行语义分割,字符不够清晰,存在无法分辨的字符;改进网络生成图片语义分割后,网络字符清晰度有所提升,尤其是利用U-Net网络训练测试产生的语义分割字符,清晰度提高明显。
对比表2中的各项指标,除了U-Net测试中的PA指标改进后的网络比改进前的有所下降外,另外两种指标都得到了提高,并且改进网络再进行U-Net语义分割结果最好。说明改进网络在一定程度上提高了语义分割精度。
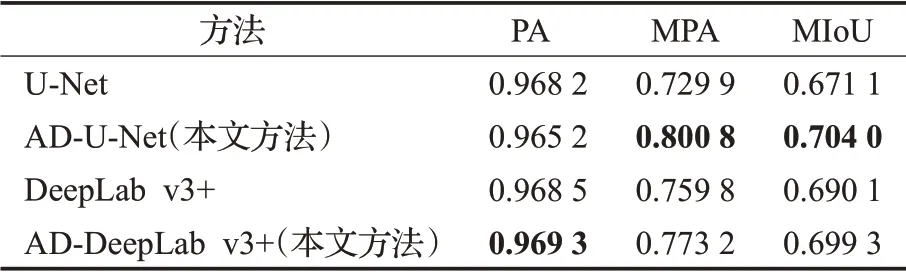
表2 语义分割各项指标Table 2 Semantic segmentation indicators
第二组,对真实样本数据集进行样本扩充。改进的CycleGAN-AD生成图片与真实图片共同送入语义分割网络进行训练,与只有真实样本进行训练的分割结果进行比较,测试评价指标是否有所提升。图10与表3中,U-Net与DeepLabv3+为未扩充样本的结果,RG-U-Net与RG-DeepLabv3+为扩充样本结果。其中,1∶1是指将模拟生成样本与采集的全部真实样本共同作为数据集,两者比例为1∶1;逐渐减少真实样本数量,两者比例为2∶1、3∶1、4∶1。
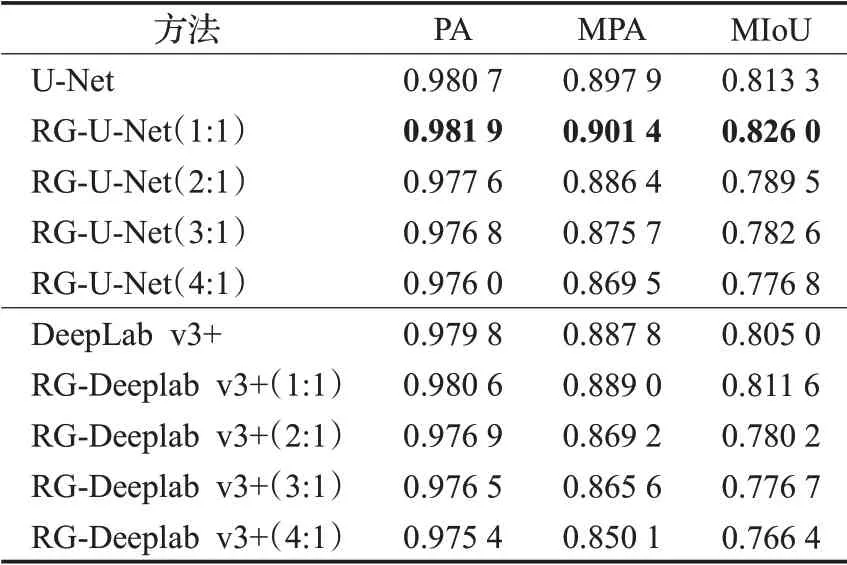
表3 样本扩充后语义分割各项指标Table 3 Indicators of semantic segmentation after sample expansion
通过图10可以看出,未扩充数据集的两种方法中,U-Net对字符5、9分割不够清晰,存在噪点,字符发生了变形,DeepLabv3+对字符5、8分割不够清晰完整;对全部真实样本扩充后,字符分割较为完整清晰;逐渐减少真实样本后,虽然整体清晰度有所下降,但每个字符分割完整,未出现变形现象。
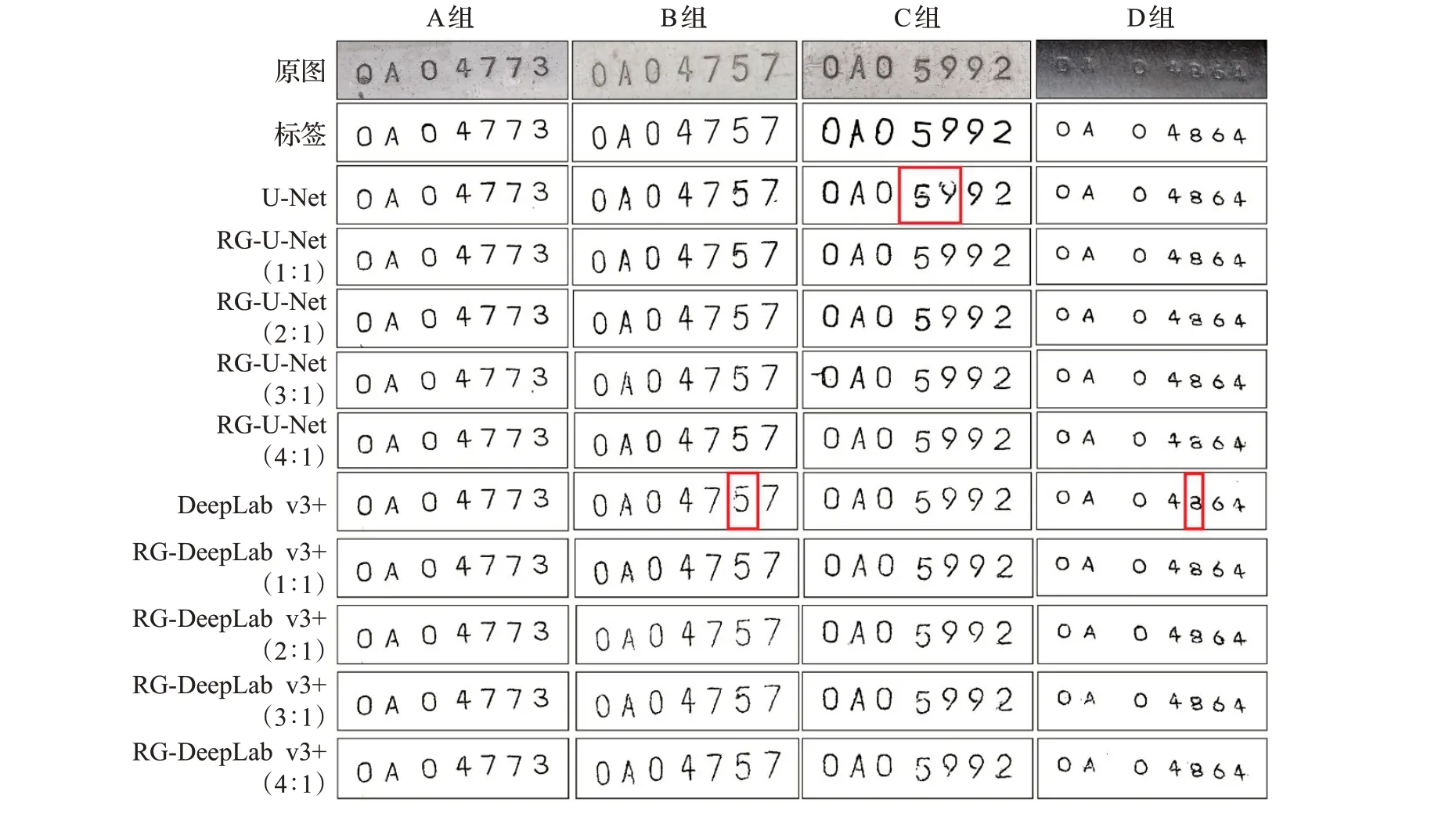
图10 样本扩充后语义分割结果对比Fig.10 Comparison of semantic segmentation results after sample expansion
表3中,经过扩充样本后,两种语义分割网络测试结果的各项评价指标都得到了提高。其中样本扩充后的U-Net分割结果的各项指标为最高,MIoU值最高达到了0.826 0。虽然减少数据集中的真实样本后,各项指标有所下降,但结合表中数据与分割结果图,分析发现,分割字符清晰完整,未出现字符变形,适当减少真实样本数量可以应用于工业生产当中。
经过上面几组实验可以得出结论,将图像风格迁移用于样本扩充,不仅在构建数据集方面减少了人力,节约了时间,并且在一定程度上提升了语义分割结果的质量,更有利于语义分割网络应用于工业生产当中。
3 结束语
本文对基本CycleGAN网络进行改进,提出了CycleGAN-AD网络。通过所提出的网络,将计算机生成的虚拟样本迁移成真实样本风格,对原始样本进行扩充。实验结果表明,使用风格迁移扩充后的训练样本,能够显著提升语义分割的精度,表明本文所提方法有望为无监督语义分割提供新的解决思路和方案。
