基于TVM平台的MEC卷积算法优化
2023-01-13王朝闻李远成
王朝闻,蒋 林,李远成,朱 筠
1.西安科技大学 计算机科学与技术学院,西安 710600
2.西安邮电大学 电子工程学院,西安 710121
近年来,随着深度学习的快速发展,卷积神经网络(convolutional neural network,CNN)[1]在计算机视觉[2]、计算机图形学[3]等传统领域都取得了很大的突破,并且逐渐应用到其他领域,例如自动驾驶、风险评估等。卷积神经网络通常由卷积层、池化层、激活层和全连接层等网络层组成[4],其中卷积层的计算性能几乎决定整个卷积神经网络的性能。以ResNet18[5]为例其网络结构包含17个卷积层和1个全连接层。因此,针对卷积层计算速度进行优化具有重要意义。
当前,影响卷积层计算速度的主要因素有处理速度和内存占用效率,学者们主要从这两方面对卷积算法展开研究。在处理速度方面,主要的卷积计算方法有Im2col+GEMM[6]。Im2col+GEMM将输入矩阵转换成多个列向量,并重组为中间矩阵,随后调用BLAS中高度优化的GEMM方法进行矩阵乘法运算。该方法的优点在于把卷积计算转换为矩阵乘法,并利用高度优化的GEMM方法对其进行加速;但是,该方法产生的中间矩阵内存占用效率低。为了解决这个问题,学者们在内存占用效率方面提出了新的卷积算法。文献[7]基于Im2col算法提出了卷积算法MEC(memory efficient convolution)。该算法将输入矩阵转换成的多个列向量按行高这一维度进行展开后,再重组为中间矩阵,然后,将中间矩阵划分成小矩阵同卷积核进行矩阵乘法运算。同Im2col相比,MEC算法大幅降低了内存占用。但是,MEC算法因为分段矩阵地址不对齐[8],访问的数据地址不连续,导致其矩阵存储不符合神经网络使用的以行主序进行存储的编程语言存储方式,致使MEC算法存在cache命中率低,内存访问延时长的问题。
针对上述问题,本文提出一种针对MEC的优化算法。首先,该方法将MEC算法中原有的列优先数据访问方式改进为行优先访问方式。其次,修改卷积核矩阵的数据排列方式,减少访问数据的时间。最后,利用线程库对算法并行加速,有效提高了运算速度。实验结果表明,相较于MEC算法,本文提出的优化算法在单个卷积层上平均获得了50%的时间速度提升,在多层神经网络中最低获得了57%以上的速度提升。同空间组合算法相比,最高获得了80%的速度提升。
1 MEC算法分析
本文针对MEC进行优化,MEC算法卷积过程如图1所示,计算过程主要分为两步:中间矩阵转换和矩阵乘法。卷积过程中输入矩阵通常采用四维矩阵存储数据,即批次(batch)、通道(channel)、高度(height)和宽度(weight),分别用N、C、H、W表示。参与运算的矩阵有输入矩阵(input)、中间矩阵(lower)、卷积核矩阵(kernel)和输出矩阵(output),分别用I、L、K和O表示。本章讨论的MEC算法中,输入矩阵采用二维表示,即N=1,C=1,H=1,W=7。使用二维数据可以排除其他维度干扰,更加直观地对MEC算法进行理解,同时分析算法中存在的不足。
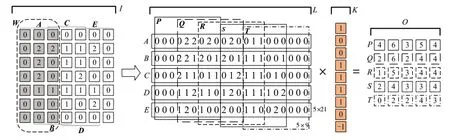
图1 MEC算法计算过程Fig.1 Calculation process of MEC algorithm
1.1 中间矩阵转换过程分析
中间矩阵转换作为MEC算法的第一步,主要负责把原始输入矩阵I转换成中间矩阵L。如图1所示,首先,读取输入矩阵中A=I[0∶7,0∶3]部分的每个值,并将其组织成中间矩阵L的第一行。然后,以步长S(步长为滑窗每次移动的距离,默认步长为1)作为滑动距离,滑动窗口W至矩阵B=I[0∶7,1∶4]处,读取矩阵B中数据,组织成中间矩阵L的第二行。以此类推,完成从输入矩阵到中间矩阵的转换。
如图1所示,MEC算法在读取输入矩阵时,采用分段读取的方式,且每段划分都以列为主。这种划分方式不适应矩阵在内存中行优先的存储方式,每段数据间的地址不连续,导致cache命中率降低,访存延时长。
1.2 矩阵乘法过程分析
MEC算法第二步是矩阵乘法,将中间矩阵与卷积核矩阵相乘得到输出矩阵。首先,把中间矩阵分成{P,Q,R,S,T}五个子矩阵,每个子矩阵的大小由(OW×(KW×KH)=5×9)决定,子矩阵之间的距离由(SH×KW=3)决定;其次,将卷积核矩阵按行展开成列向量;最后,把5个子矩阵分别与列向量相乘,例如,子矩阵P59=L[0∶5,3∶12]与卷积核相乘时,得到输出矩阵O中P行,Q与K相乘得到矩阵O的Q行,以此类推完成矩阵乘法运算,得到输出矩阵O。这种方法很大程度上减少了原始Im2col卷积的内存开销。同时,根据MEC算法的特性,每次只计算输出矩阵中的一个值,可以充分利用并行库进行加速。
在矩阵乘法中,MEC算法读取中间矩阵的方式不符合行优先的存储方式。并且,随着输入通道数IC和输出通道数OC的增加,卷积核矩阵大小也随之增加,如何加快卷积核矩阵的处理速度成为不可忽视的一点。
综上所述,为解决MEC算法中存在的问题,需要充分利用访存模式中空间特征和时间特征,修改计算顺序和数据在内存中的排列方式(即数据布局),以解决访问的数据地址不连续的问题,从而提高cache命中率,降低访存延时。
2 MEC算法访存模式
访存模式是指算法或程序在访问存储器件时所体现出的规律,其规律主要有两种:空间特征和时间特征。时间特征指数据使用的频度和生命期,典型应用是最近最少替换策略,将一段时间内最长时间未被访问的数据块替换出去。空间特征指空间局部性原理,典型应用是数据预读取技术,将所取数据及相近的数据块一同取到缓存中。在下次计算单元需要数据时,从缓存中读取,无需从内存中取数据,从而减少访存延时[9]。
卷积运算过程中所涉及的数据以矩阵形式进行存储,矩阵在内存中有行主序和列主序两种存储方式[10],如图2所示,行主序在存储矩阵时按行写入内存,列主序存储时按列写入内存。矩阵在内存中的存储方式由编程语言决定,C++和Python等神经网络使用的语言,其矩阵的存储方式为行主序。优化算法只针对矩阵存储方式为行主序的编程语言,本文使用的编程语言为Python。
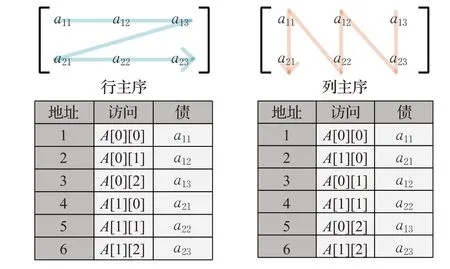
图2 不同设备中内存组织形式Fig.2 Memory organization in different devices
为解决原有算法cache命中率低等问题,本文结合访存模式中两种访存特征,提出一种针对MEC算法的优化思想,主要使用两种方法来解决访问数据地址不连续的问题,进而提高cache命中率。第一种方法利用预读取技术,改变数据在内存中的组织模式,把数据组织成计算单元可以顺序使用计算的形式;第二种方法结合空间特征和时间特征,改变原有算法复杂的计算顺序,将其修改成按行计算的顺序。通过这两种方法可以加快读取速度,提升整体的计算性能。基于此优化思想,本文将在第3章提出针对MEC的优化算法。
3 针对MEC的优化算法
为进一步提升卷积计算性能,本文针对MEC算法,提出了一种能够增加cache命中率,降低内存访问延时的优化算法。这里,使用第2章提出的优化思想对MEC算法进行优化,分成单通道和多通道两小节对优化算法进行说明。对于单通道卷积部分,讨论计算顺序的调整方式,对多通道卷积部分,讨论数据布局优化等操作。
3.1 单通道卷积优化方法
单通道卷积分为矩阵转换和矩阵运算两部分,矩阵转换部分如图3(a)所示,本文重新设计输入矩阵的读取方式,将原有读取方式改为行优先读取。首先,对输入矩阵区域按行进行划分,依次划分成{P,Q,R,S,T,U,V}7个行向量。然后,分别对7个行向量进行处理。例如,对于行向量P=I[1,1∶7],采用核矩阵宽度KW=3作为滑块宽度。具体转换步骤如下:第一步,读取区域PA=P(1∶3),将数据按序填充到中间矩阵P′区域A′行所示部分(P′A′)。第二步,以步长SH=1作为步幅向右滑动滑块,得到{PA,PB,PC,PD,PE}5个子向量,分别填充到中间矩阵L中对应{P′A′,P′B′,P′C′,P′D′,P′E′}部分,完成从输入矩阵P到中间矩阵P′的转换。最后,向量P处理完成后,对输入矩阵中剩余行向量进行处理,重复上述过程得到中间矩阵L。在矩阵转换过程中,行向量的处理过程相互独立,没有数据间依赖关系,可以利用加速库进行加速。
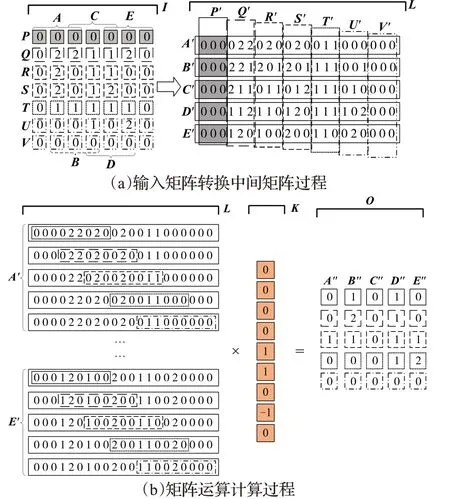
图3 优化算法单通道计算过程Fig.3 Single channel calculation process of optimization algorithm
矩阵运算部分如图3(b)所示,根据1.2节可知,对于矩阵运算部分,原有算法读取中间矩阵的方式比较复杂,为简化原有算法读取步骤,加快读取速度,本文更改了参与矩阵运算的顺序。与修改矩阵转换过程类似,按行读取中间矩阵。例如,行向量A′=L[1,1∶21]是矩阵运算读取的第一部分,具体运算步骤如下。首先,读取向量A′中长度为KH×KW=9的数据,将读取的数据与卷积核向量K进行点积,得到输出矩阵O的值O11。其次,取核向量K的长度作为滑块大小,按照步长KW×IC=3的距离向右滑动滑块,得到的数据分别与K相乘,直至滑块到达向量A的末尾,得到输出矩阵O中的A″列。最后,分别对{B,C,D,E}做相同处理,对应得到矩阵O的{B″,C″,D″,E″}列。在矩阵运算过程中,参与矩阵运算的各部分相互独立,可以利用并行加速。
3.2 多通道卷积优化方法
本节介绍优化算法中输入矩阵中间矩阵转换过程,卷积核矩阵数据布局变化以及对卷积计算方式的修改过程。
输入矩阵到中间矩阵的转换过程如图4所示,采用IN×IH×IW×IC(NHWC)作为输入矩阵的数据布局,多通道卷积增加批次(IN)和输入通道(IC)两个维度。如图4中含有3个批次,不同颜色代表不同通道,每个批次内采用二维方式表示三维数据(宽、高以及输入通道)。与3.1节中间矩阵转换类似,优化算法将列优先读取方式修改为行优先。与单通道卷积中间矩阵转换不同的是,多通道卷积需要对批次和通道数进行处理。优化算法使用NHWC作为输入矩阵的数据布局,为使读取输入矩阵的数据地址连续,采用从内到外的顺序进行转换,即按照CWHN的顺序对输入矩阵进行读取转换,优先转换通道数,再依次转换宽、高,最后转换批次,完成从输入矩阵到中间矩阵的转换。
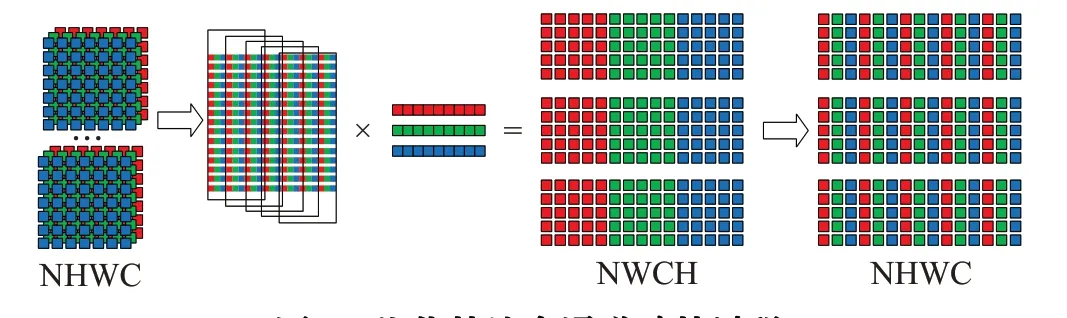
图4 优化算法多通道计算过程Fig.4 Multi-channel calculation process of optimization algorithm
与输入矩阵相同,参与卷积运算的卷积核矩阵同样有4个维度,分别为宽(KW)、高(KH)、输入通道数(IC)和输出通道数(OC)。通常,卷积核大小为KW×KH,一个输入矩阵对应一套卷积核,一套卷积核内包含IC个卷积核,一套卷积核可与输入矩阵进行卷积运算得到一个单通道输出矩阵。OC套卷积核分别与输入矩阵卷积得到OC个输出矩阵,即多通道输出矩阵。与输入矩阵(NHWC)进行运算的卷积核矩阵通常采用KH×KW×IC×OC(HWIO)作为数据布局,将卷积运算转换为矩阵乘法,利用BLAS库中高度优化的gemm函数进行加速。本文使用TVM作为优化算法的实现平台,将卷积核矩阵的数据布局修改为符合MEC算法访存模式的OC×KH×KW×IC(OHWI)布局方式。如图4所示,依次按照输入通道数、宽和高的顺序将一套卷积核展开成行向量,分别对OC套卷积核进行展开,得到行高为OC,列宽为IC×KW×KH的卷积核矩阵。
最后,利用TVM内置计算函数对原有算法运算方式作出改进,具体运算步骤如下:首先,将第一个批次的中间矩阵依次与卷积核矩阵的每一行相乘,得到一个批次的三通道输出矩阵。其次,对剩余批次重复上述步骤,得到完整的结果。最后,对输出结果进行整理,对运算结果进行矩阵变换。这种运算方式中,访问核矩阵的顺序为行优先,符合算法访存模式,加快读取速度。同时,采用分批次对矩阵进行处理,可以利用TVM内置的并行库对卷积运算进行加速。
3.3 优化算法代价分析
优化算法在多通道卷积中通过修改了卷积核的数据布局和矩阵运算的计算方式加快运算速度,但是,优化过程中存在一定程度上的不足。进行卷积时,需要将中间矩阵和卷积核矩阵经过计算得到输出结果,但由于输出结果的数据布局同输入矩阵的数据布局不匹配,需要进行布局转换,在优化算法中,进行布局转换的方式为矩阵转置。
矩阵转置过程如图5所示,优化算法主要对宽、高和批次3个维度进行转置,取N=1,W=3,H=3,C=3,不同颜色代表不同通道数。在转置过程中,首先,依次读取结果矩阵中各通道的第一列第一个值,排列成输出矩阵中第一行相邻的3个值,即图中1、2、3号值的位置变化。其次,对各通道的第一列上的其余值进行转换,排列成输出矩阵的一行。最后,对各通道的其他列依次重复上述过程,得到完整的输出矩阵。在转置过程中可以看出,在读取结果矩阵时,顺序读取的两个值之间通常相隔的长度为H,由第二章提到的数据预读取技术可知,读取数据时会将相邻数据存入cache中,但是读取结果矩阵时数据跨度大,导致cache命中率降低,转置时间增加,对优化算法的计算速度造成了一定的影响,这也是算法以后需要改进的地方。
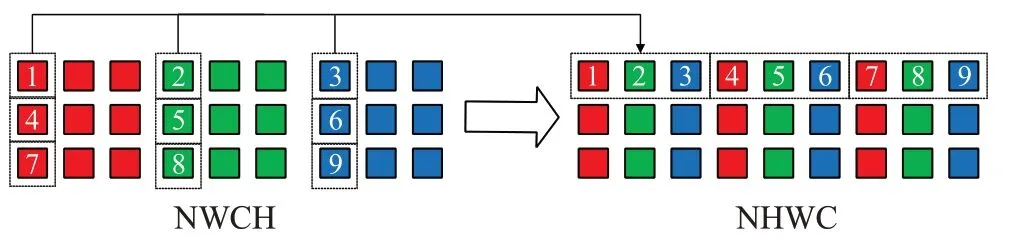
图5 输入矩阵转置过程Fig.5 Input matrix transpose process
4 实验和结果分析
4.1 实验平台
本文使用x86架构CPU,基于TVM[11]编译器对MEC算法进行优化,通过设计多组实验验证该算法的计算性能。TVM针对多样的硬件体系结构与模型定义,在模型定义和后端代码实现之间的转换部分进行了高度优化,使模型可以更好地部署到各个硬件平台[12]。硬件平台CPU型号为Intel Core i5-10400CPU@2.90 GHz,支持AVX2[13]矢量指令集,可以更好地对计算进行加速。
4.2 测试集及实验方案
4.2.1 测试集
本文使用单个卷积层和3个多层神经网络模型对优化算法进行测试。对于单个卷积层,这里从当前流行的神经网络模型中选取了11个不同规模的卷积层作为优化算法的测试集,测试集规模如表1所示。分别对MEC算法、优化算法以及空间组合算法(spatial pack)进行测试。文献[14]中使用了空间组合算法,采用分治的思想,将输入矩阵的高和宽均匀分成若干份,分别对每一部分进行卷积运算,作为一种高效的卷积算法。空间组合算法同优化算法类似,对输入矩阵进行划分,只需在填充(padding)时增加额外的存储空间,减少了存储空间占用,同时也采用修改读取顺序的方式对卷积算法进行优化。
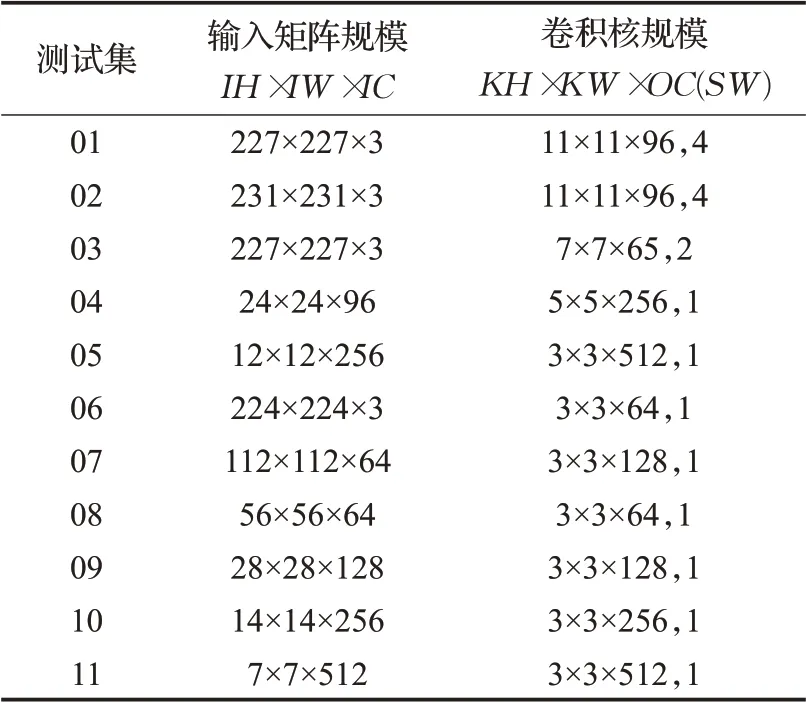
表1 测试集规模Table 1 Test sets size
对于多层神经网络,采用PyTorch官方提供的预训练模型,包含ResNet18、ResNet101以及DenseNet121网络。分别使用MEC算法和优化算法作为神经网络模型的卷积层算法,对3种模型进行前向推理测试。ResNet网络由何凯明提出,使用残差学习解决了神经网络因深度过深导致过拟合的问题;DenseNet由刘壮提出,优点在于缓解了梯度消失问题,加强了特征传播,极大地减少了参数量[15]。预训练模型由网络上公开的数据集ImageNet[16]对网络模型进行训练后得到,包含完整的模型参数[17],可以直接使用预训练模型进行推理测试,本文选用ImageNet中推理子集作为多层神经网络的测试集。
4.2.2 实验方案
对于单个卷积层,11个测试集采用0~1之间的随机浮点数作为输入矩阵和卷积核矩阵的数据,使用TVM平台自带的优化库对MEC算法、优化算法和空间组合算法进行加速优化,其中,对空间组合算法中输入矩阵的划分,由TVM给出最佳划分方法。对3种算法进行相同批次下前向计算性能测试,分别统计在不同测试集上的计算时间,连续测试100次取平均值。
文献[8]中的算法同样是对MEC算法进行优化,称为MFCA算法,该算法针对GPU架构,针对内存进行优化,本文的算法针对CPU中x86架构,针对速度进行优化。因此,本文未同MFCA算法进行对比。
对于多层神经网络,使用TVM加载预训练模型,从ImageNet测试集中取6张图片分别对MEC算法和优化算法进行推理测试,每张图片重复推理10次取平均值。
4.3 实验结果
4.3.1 单个卷积层时间性能比较
对于11个测试集100组输入的测试,优化算法相比于MEC算法的加速效果如图6所示,分别获取中间矩阵转换、中间矩阵读取和整个卷积过程的运行时间,图中使用的公式如下,设MEC运行时间为Tmec,优化算法运行时间为Topt,速度提升为Tspeedup,则计算公式为:
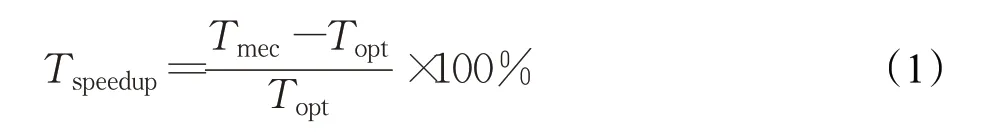
从图6中可以看出,优化算法中间矩阵转换的性能比MEC算法平均提升10%以上,其中,测试集1、3、6和7提升效果明显优于其他测试集,结合表1中数据规模可知,在处理较大规模的矩阵时,MEC算法中一次所需处理的行数增多,根据程序访存特性可知,增加了访存时间。优化算法采用按行读取策略,充分利用访存特性,使得cache命中率明显提升,加快转换速度。
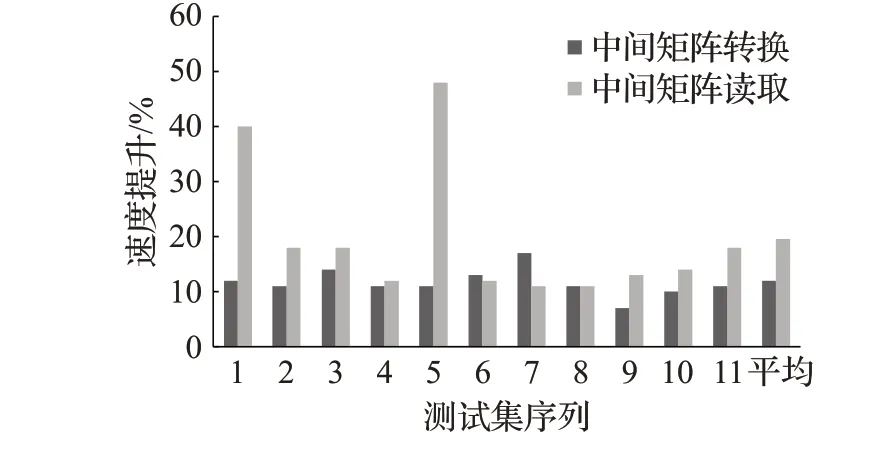
图6 优化算法中间矩阵转换速度和读取速度提升Fig.6 Improvement of intermediate matrix conversion and reading speed of optimization algorithm
如表2和图6所示,本文分别获取每个测试用例中间矩阵的规模以及两个算法的数据读取时间进行对比。由于步长的存在,把中间矩阵的规模修改成参与运算的规模,数据读取时间的获取方式为单独访问矩阵,不进行与核函数的乘法运算。
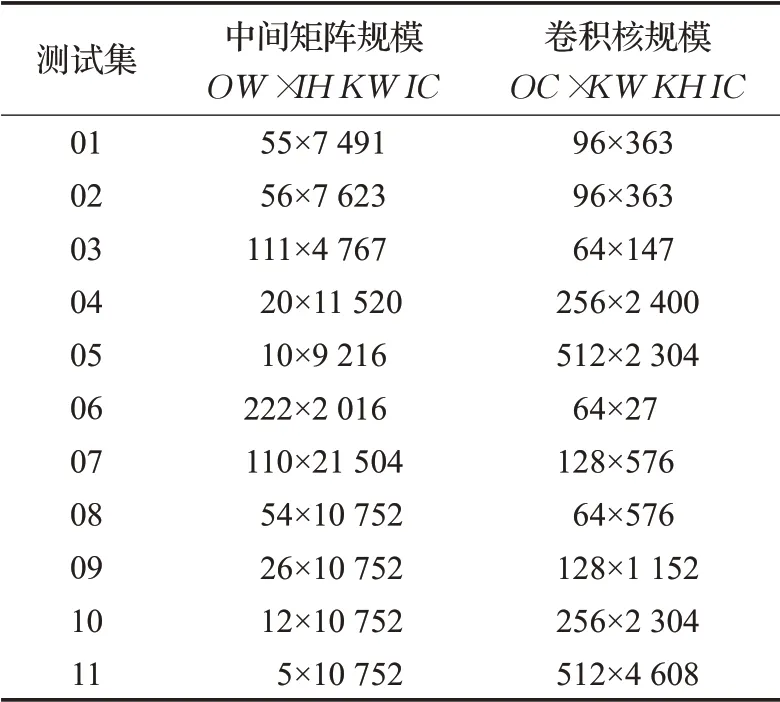
表2 中间矩阵数据规模Table 2 Data size of intermediate matrix
由表2可知,与原有MEC算法相比,优化算法访问中间矩阵数据的速度明显加快,较原有算法平均提升了20%。表中8~11测试数据中,在中间矩阵列宽不变,行宽较小时,优化算法的访问速度提升不明显,但随着行宽的增加,优化算法的访问速度提升更加明显,最高时访问速度提升了40%,这符合本文对优化算法的分析。最后,本文获取了卷积计算的整体时间,如图7所示。
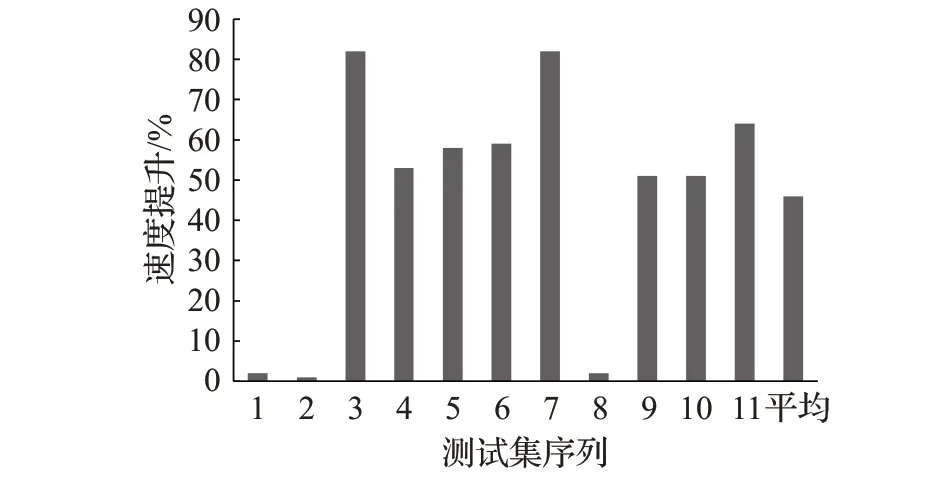
图7 优化算法总体卷积速度提升Fig.7 Improvement of overall convolution speed of optimization algorithm
结合表1可以发现,在输入矩阵的宽高较小且通道数较多时,优化算法都能取得50%以上的提升。这是因为中间矩阵L的行高由OW决定,列宽大小由IH×KW×IC决定。随着通道数IC的增加,中间矩阵的列宽也会跟着增加,通常会增加到行高OW的几十倍。再加上本文对卷积核矩阵数据的重新排列,使得优化算法符合程序的访存特性,增加cache命中率,从而降内存访问延时,提高整体的计算性能。
但是,优化算法也有明显不足,如图7中1、2和图8所示,优化算法的速度提升不明显,甚至有些许下降。这里获取了优化算法转置所耗时间(Tt)同优化算法整体时间的时间比,计算公式为:

图8 转置时间占比Fig.8 Ratio of transpose time
本文在3.3节提到,得到输出矩阵之前,需要对计算得到的结果矩阵进行转置操作,对于较大规模矩阵,需要读取的数据间隔较大,造成转置时间一定程度增加,这是速度提升不明显的主要因素。从图7和图8对比可以看出,转置时间占用较大的测试序列速度提升不明显,转置时间占用较小的测试序列速度提升明显,呈负相关关系,证明了转置过程一定程度上影响了优化算法的运算速度。
将优化算法同MEC算法进行对比之后,对空间组合算法和优化算法的运行时间进行了对比,其中,Tspatial表示空间组合算法所用时间,Topt为优化算法所用时间,计算公式如下:
从对比结果可以看出,优化算法整体上的运算速度明显优于空间组合算法(如图9),除测试序列6外,其余均有30%以上的速度提升。其中测试序列4~5、9~11的速度提升都在60%以上,结合表1可以看出,这些测试序列采用的高H和宽W都较小,而通道数C较大,根据第3章优化算法介绍得知,此种情况下,中间矩阵的宽会增加,更有利于增加优化算法的cache命中率,使得优化算法速度提升明显。而在1~3、6~8中,优化算法速度提升略低,这是因为随着矩阵宽和高的增加,空间组合算法可以发挥分治的优势,将矩阵切分成合适的数量进行卷积。最后,测试序列6出现了空间组合算法速度提升优于优化算法的现象,这是因为优化算法不适合处理宽高较大,通道数较少的矩阵,同时,空间组合算法适合处理此种情况。因此,从实验数据可以看出,优化算法整体上优于空间组合算法。
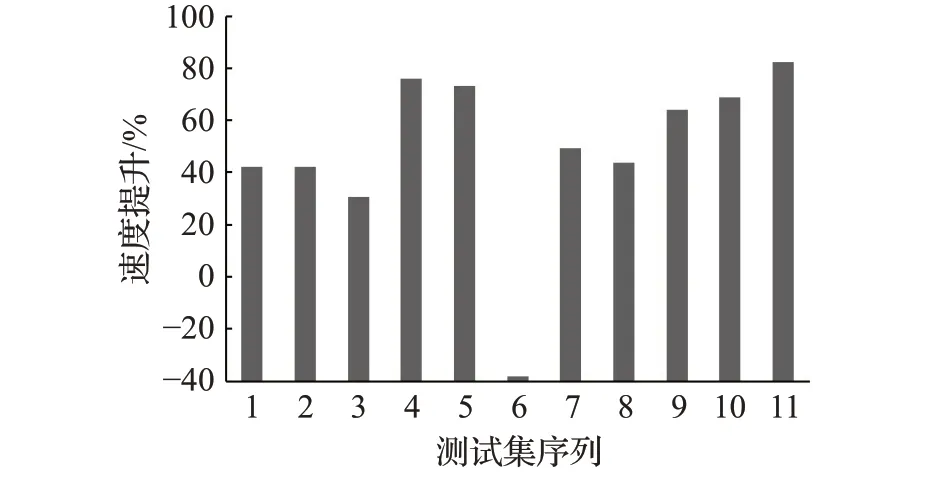
图9 优化算法卷积同空间组合算法速度提升Fig.9 Optimization algorithm convolution and spatial combination algorithm speed improvement
4.3.2 多层卷积网络时间性能比较
在TVM平台中实现MEC卷积算法和优化算法,分别替换卷积层中的卷积算法为MEC和优化算法,使用ResNet18、ResNet101和DenseNet121这3种神经网络模型作为推理测试模型的实验结果如图10所示。这里设使用MEC算法作为卷积的神经网络运算时间为Tmecnn,使用优化算法作为卷积的神经网络运算时间为Toptnn,则速度提升Tsunn计算公式为:
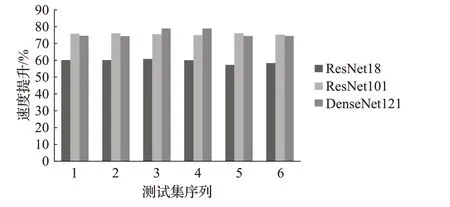
图10 不同网络模型性能对比Fig.10 Performance comparison of different network models
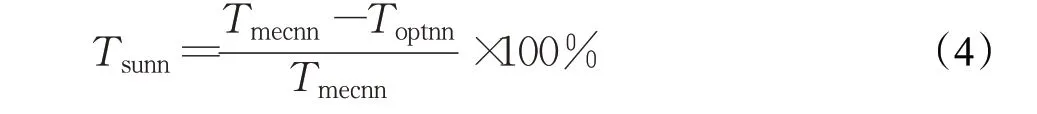
本次实验分别获取不同网络模型下两种算法的时间比,如图10所示,在ResNet18网络中,相比MEC算法,优化算法的速度提升了57%以上。在更深层的ResNet101网络中,优化算法的性能提升平均在75%以上。两者对比可以发现,随着网络层数加深,速度提升更明显,这是因为ResNet101中含有更多卷积层,每个卷积层都得到不同程度的加速,使得优化算法对性能提升更加明显。最后,在近几年新兴的神经网络DenseNet中,优化算法获得了75%的速度提升。由此可以看出,相较于使用MEC作为卷积算法的神经网络模型,使用优化算法作为卷积算法的网络模型有更加良好的性能提升。
5 结束语
MEC卷积算法是处理内存占用过高的选择之一,但是,MEC算法的运算速度同样重要。因此,本文提出一种针对MEC的卷积优化算法。优化方法采用两种,首先,对输入矩阵和中间矩阵的处理方式进行优化,将原有的访问方式修改为行优先访问,使得访问顺序符合程序访存模式。然后,本文更改了卷积核的数据布局,使用TVM封装的计算函数对卷积的计算方式进行优化,修改卷积计算方式为行乘以行。此外,本文还利用TVM平台的优化方法对算法进行优化加速,达到提高卷积计算性能的目的。实验结果表明,优化算法相较于MEC算法,获得不同程度的性能加速。在测试不同规模的单层卷积时获得了平均50%的性能提升,此外,本文将优化算法和MEC算法集成到TVM平台中,使用ResNet18、ResNet101和DenseNet121神经网络模型作为测试模型,分别获得57%、75%和75%的速度提升。同时,本文将优化算法同空间组合算法进行对比,获得了最高80%的速度提升,进一步验证了本文提出的优化算法的有效性。
