时域非填充网络视频行为识别算法研究
2023-01-13司亚中
刘 钊,杨 帆,司亚中
河北工业大学 电子信息工程学院,天津 300401
作为计算机视觉领域的一项基础任务,对行为识别的研究已经进行了很长时间。如今随着移动互联网时代信息的爆炸式增长,来自监控摄像头、自媒体、自动驾驶等系统的视频数据也变得庞大而复杂。对网络或本地视频中人类的行为进行识别与分类在智能监控、视频推荐、辅助驾驶系统等领域都有很大的需求,因此行为识别算法逐渐成为机器视觉中的一个研究热点。
进行行为识别的关键是提取视频中的时空信息,近年来深度学习技术的发展使得研究者可以利用卷积神经网络自动提取图像的空间特征,从而完成目标识别、图像分类、语义分割等不同场景下的任务。与2D的图像任务不同,由于人的动作具有明显的时间连续性,处理视频除了空间信息外还需要关注时间维度的信息。因此视频识别和图像识别的一个重要差别就是对时间的建模,这对识别的效果有很大影响[1]。
分析视频中行为的方法有很多种,最直接的是使用2DCNN进行特征提取,但是这种方式忽略了帧与帧之间的时间关系,在时间关联性强的动作中无法得到准确的结果。另一种方法是使用双流网络,光流是描述物体运动的一种有效表征,它提供了与RGB图像间的正交信息。将视频的光流作为时间建模信息,和空间数据一同输入到网络中可以有效提升行为识别的准确率,但是光流需要进行预计算,耗费计算资源大,同时需要较多存储空间,在速度和实时性方面无法取得理想结果。事实上,将一段视频看作一个具有两个空间维度和一个时间维度的三维张量是最自然的做法。因此,使用3D卷积神经网络同时提取视频中的时空信息受到研究者的欢迎,在2DCNN的基础上,添加时间维度进行时域建模,同时空间维度保持不变,就可以很方便地分析视频片段的时空特征。增加一个维度同样带来了算力的消耗,但是端到端的优势,使3DCNN方法成为了研究的热点。
在过去的十年中,随着网络视频的积累,研究人员制作了各种高质量的行为识别数据集,而且视频数量和行为类别的数量都在快速增长。典型的数据集HMDB51[2]、
UCF101[3]、ActivityNet[4]、Sports1M[5]、Kinetics[6]、You-Tube8M[7]、Something-Something[8]等都有对应的SOTA方法。由于大规模数据集有充分的训练数据,可以在训练时避免过拟合的发生,从而提高测试时的性能,所以往往被看作行为识别的基准。一些通用的行为识别模型在经过预训练后可以在这些数据集上取得很好的效果,但是训练过程十分依赖硬件设施,需要强大的算力支持。此外,完成一次大数据集上的训练,可能需要几周甚至一个月以上的时间。为解决此问题,本文提出了一种适用于小型数据集的3D卷积神经网络模型,在兼顾参数量和计算量的前提下,与一些主流的网络相比有较为明显的精度提升。在某些特定的行为识别场景中,可以在较小算力下(比如性能较差的GPU)进行训练。
1 研究现状
首先将3D CNN用于行为识别的是Ji等人[9],他们设计的网络包含1个硬线层、3个卷积层、2个下采样层和1个全连接层。硬线层生成灰度通道、梯度通道和光流通道。在每个通道中应用卷积和下采样,最后通过结合所有通道的信息计算得到行为识别的结果。此开创性工作的成功使得更多的研究者开始探索3D CNN的潜力。最直接的工作是对经典2D卷积的拓展,即将2D卷积核以及对应的输入输出映射到3D。Tran等人[10]提出了一个更深的3D卷积网络,称之为C3D。C3D网络实际上是将VGG[11]网络扩展到了3D,可以看作是3D版本的VGG16。Hara等人[12]直接使用3D卷积核来代替2D ResNet[13]中的卷积核,并尝试使用大规模数据集Kinetics来训练此3D ResNet,希望可以达到2D CNN在ImageNet[14]上的效果。
对于3D卷积网络,增加时间维度的长度可能捕获到更多的时间关联信息。为了进行长时间建模,Varol等人[15]开发了一种长时间卷积结构(LTC),该结构使用较多的视频帧(比如60或者100帧)作为输入,但与此同时带来了更多的计算量。为了减少网络参数的数量,缓解高复杂度和训练视频数据不足的多种困难,Sun等人[16]提出了一种分解时空卷积网络FstCN,将原始的三维卷积核学习分解为先学习低层的二维空间卷积核,然后再学习上层的一维时间卷积核。
为了降低训练时的复杂度,一些研究者考虑对3D卷积核进行分解。比如,一个3D卷积核(尺寸为3×3×3)可以看作是为一个2D的空间卷积核(1×3×3)与一个1D时间卷积核(3×1×1)的组合。如图1展示了这个分解的过程。
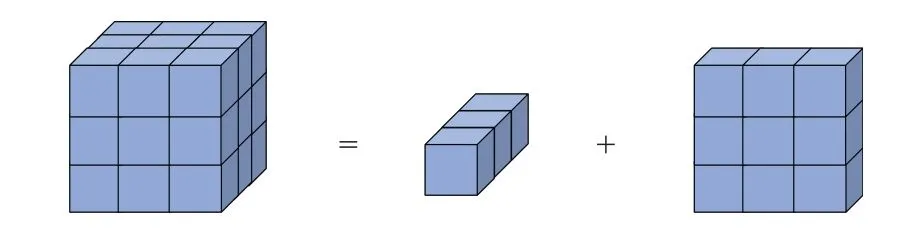
图1 3D卷积核的分解Fig.1 Decomposition of 3D convolution kernel
Qiu等人[17]提出了一种名为P3D的类似3D Resnet50的结构,使用2D和1D卷积核的组合来替代ResNet中的连接部分。R2+1D[18]也采用了这种分解方式,它与P3D的不同之处在于残差块的构建方式。
由于3D卷积网络参数量较大,为了追求训练速度,降低部署难度,大部分研究者开始探索高效的视频模型。Lin等人[19]引入了一种新的方法,称为时域移位模块(TSM),TSM将移位操作扩展到视频理解中。它将部分通道沿时间维度移动,从而促进相邻帧之间的信息交换以获取更完整的时间信息。还有一些方法使用注意力机制来对时域建模,STM方法[20]提出了一个基于通道的时空模块来提取时空特征以及一个基于通道的运动模块来高效地编码运动特征。TEA方法[21]与STM类似,但TEA使用运动特征重新校准时空特征以增强运动模式。
以上提到的方法中主要关注点都是网络的输入或者网络本身:要么是对2D卷积的扩展,要么单纯地降低模型复杂度。考虑到在卷积计算过程中不同的padding方式会对3D卷积中的时域信息进行不同的处理,而其中有些处理方法会带来时间维度上的误差,本文对时域上的padding方式进行了调整,并根据此结构提出了一种新的网络模型,可以充分利用到特征图中的时空信息。
2 基于时域非填充卷积的行为识别模型
在3D卷积行为识别模型中,时间信息的提取和有效利用是保证识别准确率的重要因素。而网络的轻量化需要从网络深度,卷积形式以及节点尺寸等方面考虑。为了在不降低模型准确率的前提下减少参数量,我们提出了一种新型的网络结构。设计思路主要包括:
(1)改变在3D卷积过程中时间维度的填充方法,不引入可能影响时间信息的无关元素,即使用不填充的卷积方式。
(2)适当降低网络深度并拆分3D卷积核来降低参数量。
(3)为了最大限度地利用提取到的时空信息,将时间3D卷积重组为2D卷积。
将此网络命名为时域非填充网络(temporal none padding network,TNP-Net)。网络的整体结构如图2所示。
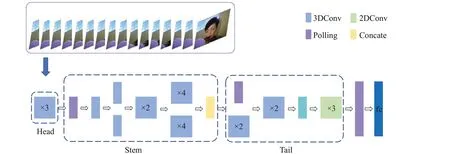
图2 整体结构图Fig.2 Overall structure
对于原始的不定时长的视频信息,使用TSN方法[22]提出的稀疏时间采样策略进行采样。首先将视频的所有帧等分为T个片段,然后在每个片段中随机取一个视频帧,并按照片段的时间顺序组合这些帧,这样就得到了时长为T的输入视频序列。在Head以及Stem模块中堆叠时域非填充结构的3D卷积层和下采样层,由于时域非填充结构可以自然地缩小时间域上的尺度,因此可以令时间维度的步长一直保持为1。最后在Tail模块中对网络进行重组:将原有的空间维度合并为一个维度,从而得到一个2D的卷积神经网络。之后在此2D网络中继续卷积以完成特征的提取。整体的行为识别过程如图3所示。
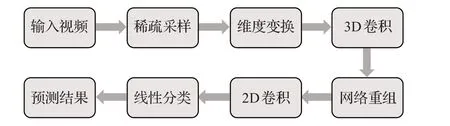
图3 行为识别流程Fig.3 Action recognition flow
2.1 时域非填充结构
在卷积过程中为了保持当前卷积层的前后一致性,通常的做法是对进行卷积的矩阵的边缘部分进行填充[23],填充的方法包括零填充(使用0)和复制填充(使用边界数据)。对于二维的图像特征图,由于整体像素点较多,填充引入的数值并不会带来太大的误差。在处理包含动作的视频片段时,往往会将提取到的表示动作的连续视频帧进行维度变换:由T×C×H×W变为C×T×H×W,其中T、C分别表示时间维度以及特征通道。H和W对应空间的形状。对此四维矩阵进行卷积时,会使用C个三维卷积核对T×W×H维的特征图进行卷积。如上所述,有时为了保证维度不变,可以在空间维度进行填充操作,但是表示动作的视频帧往往是有限的,比如16帧或24帧[24]。如果同样在时间域上进行填充,就会在时间维度的两端添加一整张全零或者与最外侧完全一样的二维特征图,而对于对帧间的时间信息比较敏感的行为识别任务,这会引入较大的误差,从而有可能影响最终的检测精度。
对于网络中正常填充的3D卷积,给定一个输入特征图X∈Rc×t×h×w,当设定卷积的步长step为1时,使用m个3×3×3的3D卷积核计算的过程为:
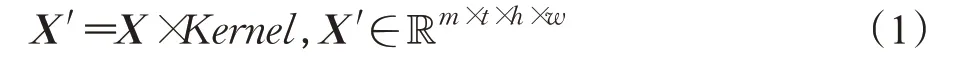
时空维度的变化由公式(2)决定,其中k和p分别代表卷积核大小和填充大小。
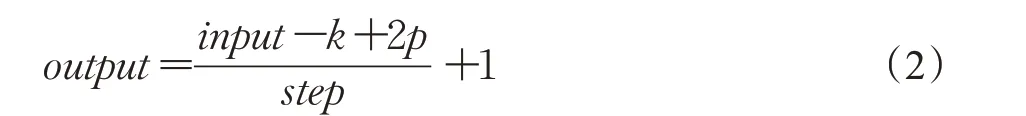
在同样条件下将时域填充变为0就可得到时域非填充结构,此时的计算过程为:
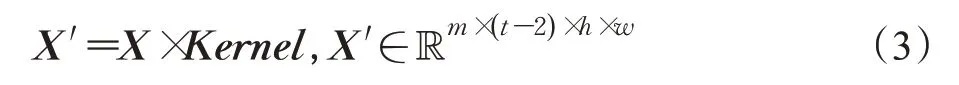
本网络的时域非填充层全部集中在Head和Stem模块,且这两个模块中的所有3D卷积在时间维度都不进行填充。其中Head模块的结构如图4所示。
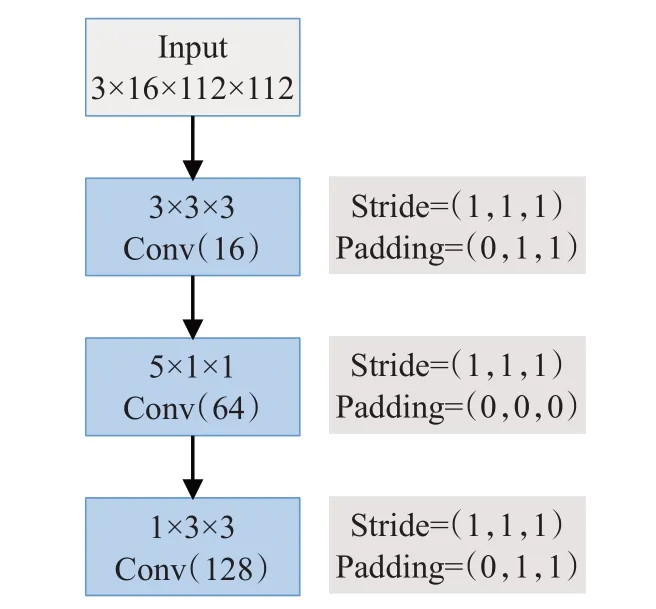
图4 Head模块结构Fig.4 Head module structure
Head模块由三个卷积层组成,首先在时间和空间维度都进行卷积计算,然后分别提取时间和空间信息。由于低层层特征图包含的时间特征相对较少,为了获取较多未经过处理的时间信息,在第二层单独进行时间卷积并使用维度为5的卷积核。如此便在网络的底层进行了两次空间和时间上的特征提取。
Stem模块中的所有卷积层都使用了时域非填充的设计,同时采用了大量的卷积分解操作来降低参数量,图5为此模块的结构。
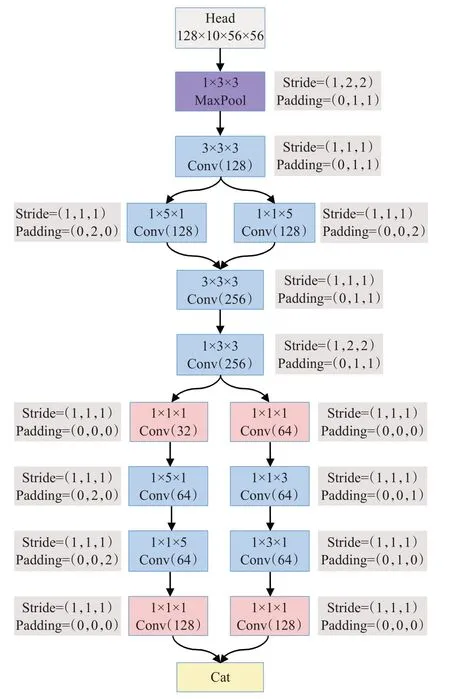
图5 Stem模块结构Fig.5 Stem module structure
2.2 网络重组结构
如上所述,使用时域非填充结构后时间域尺度会自然地下降至4,同时空间维度也随着卷积的进行而变为14×14。此时常规的做法是继续在这个三维结构中实施3D卷积。为了融合网络学习到的时空特征,获得更好的模型表现,对这部分的3D特征图做了结构上的调整:保持时间维度不变,将空间维度转换成一维,即把14×14的二维空间展平为196的一维空间。变换过程以及元素排列如图6所示。
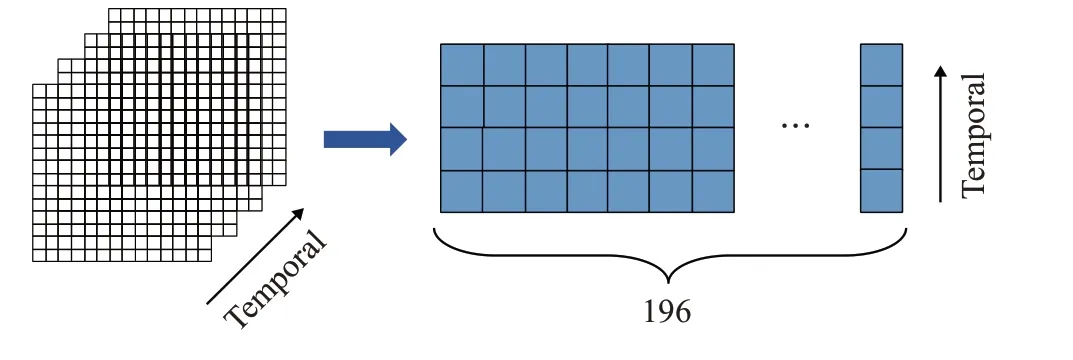
图6 3D特征图到2D特征图的转换Fig.6 Conversion from 3D to 2D feature map
Tail模块中网络重组之前也使用时域非填充来降低时间维度,为了在网络重组前后找到最合适的通道数,设置了planes以调整相关的卷积核,planes是一个包含4个元素的列表,4个元素分别对应4个卷积核的数量(即其后面特征图的通道数)。Tail模块的细节如图7所示。
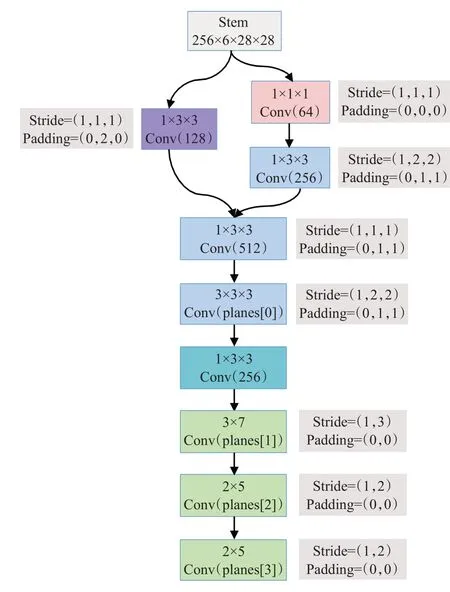
图7 Tail模块结构Fig.7 Tail module structure
3 实验
3.1 数据集
本文致力于在较小数据集上提高行为识别的性能,从而减小在某些特定场景下的任务对硬件设备的依赖。目前较流行的Kinetics、Something-Something系列数据集包含较多的动作类别以及视频数量,适合通用行为识别模型的训练。庞大的数据使其可以较好地拟合模型,但同时也带来了训练时算力的大量消耗。但在特定的场景下(比如驾驶员行为检测),往往只需要在特定的数据集上训练,因此本文使用较小的UCF-101以及HMDB51数据集,希望可以接近某些真实场景下的数据量。其中UCF-101数据集包含101个动作类别,共13 320个视频,HMDB51数据集包含51个动作类别,大约有7 000个视频片段。
3.2 训练及结果
对于每个原始的视频序列,分别从时间和空间维度处理,以进行数据增强并得到适合网络训练的样本。如上所述,首先使用稀疏时间采样的方法抽取16帧图像,如果视频长度不足16帧,则循环此视频以满足帧长的要求;接下来使用数据增强,由于每个样本是连续的帧,因此应保证对这16帧图像做同样的处理:将所有图像进行中心裁剪后以0.5的概率在水平方向翻转,同时实施归一化并调整图像大小为112×112像素;最后转置通道和时间维度就得到了尺寸为3×16×112×112的输入样本。为了准确地进行归一化,对所有的训练数据做了数据分析并得到了所有数据的标准差以及方差。本文使用交叉熵损失来作为实验的误差函数,训练时使用带动量的批处理随机梯度下降优化算法,批处理大小为32。设置初始学习率为0.01,学习率衰减因子为0.1。在训练epoch为80、140、180时进行学习率衰减,优化器的具体参数设置为:Momentum:0.9;Weight_decay:0.001;Dampening:0。
为验证本文方法的有效性,与当前主流3D卷积行为识别方法进行对比,包括C3D[10](ICCV’15)、3DResnet[12](ICPR’18)、R2P1D[18](CVPR’18)、P3D[17](ICCV’17)等。涉及到的实验使用了相同的数据处理方法,且在相同的环境下进行,本文所有实验都基于Ubuntu20.04系统,配备2块1080Ti显卡,软件环境为Pytorch 1.3。表1展示了在UCF101和HMDB51数据集中不同模型的对比结果,所有模型均使用RGB图像作为输入,不使用光流信息。
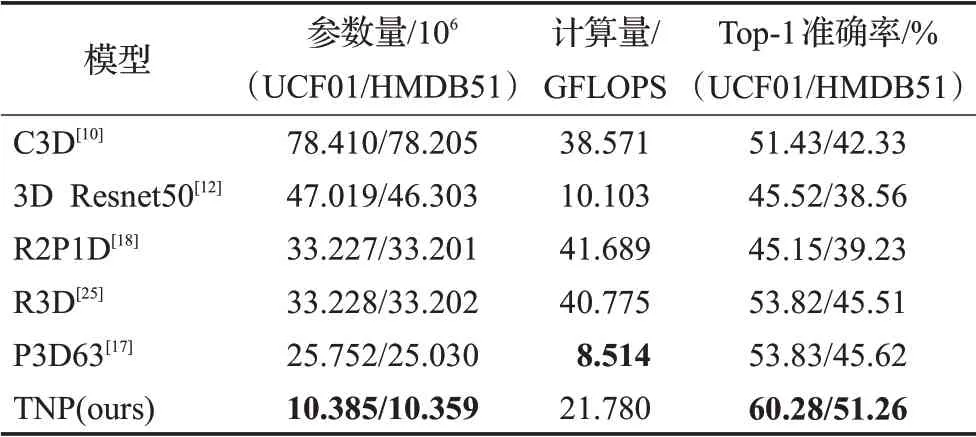
表1 不同算法性能对比Table 1 Performance comparison of different algorithms
表1中的实验除了C3D模型都采取同样的实验配置,以保证比较的公平性。为了能正常进行反向传播过程,将C3D模型训练时的初始学习率设置为0.1。同时,所有模型都未使用预训练权重,即都从零开始训练。可以看到,在其他条件基本相同的情况下,在两个数据集上TNP网络可以获得最高的Top-1准确率。同时TNP网络在牺牲了一定计算量的条件下,拥有最少的参数量,这使得它在训练时不需要占用过多的计算资源,同时节约计算时存储成本。虽然其他网络也使用了3D卷积,但得益于时域非填充和网络重组结构,TNP网络较为充分地提取并利用了视频中的时空信息,从而在参数量较少的情况下获得了较好的性能。图8给出了部分视频采样后的视频帧的预测结果。

图8 部分视频的采样及预测结果Fig.8 Sampling and prediction results of part video
3.3 消融实验
为评估时域非填充和网络重组方法对模型性能的影响,分别改变部分卷积层的时域填充方式和Tail部分的卷积方式,对比前后的识别准确率来进行可行性分析。
3.3.1 时域填充对结果的影响
分别将Stem模块中的2、4、6个卷积的时域填充方式转换为0填充来验证非填充方法的有效性,填充卷积层为0时表示全部使用时域非填充结构。表2展示了在两个数据集上实验的结果。
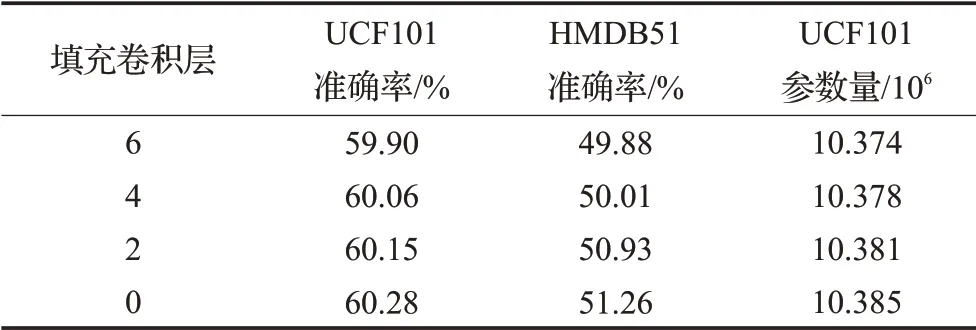
表2 不同填充卷积层的性能对比Table 2 Performance comparison of different padding layers
应用了0填充方式的网络模型由于改变了降低时间维度的方式,使得网络的参数量有所降低;然而随着使用0填充卷积层数量的减少,对应的准确率呈上升趋势。此现象可以证明时域非填充结构确实可以提高3D卷积网络行为识别任务的准确率。
3.3.2 重组网络对结果的影响
在Tail模块中,将3D卷积核重新组合成2D卷积核来充分利用时空信息,为对比其与不使用此种方式的结构的差别,直接利用3D卷积完成了Tail部分的训练。同时改变了Planes列表的元素组合以找到最佳的通道数设置,Planes的不同组合如表3所示。
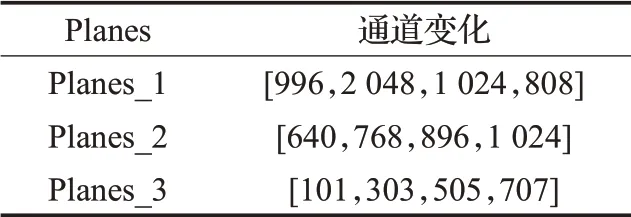
表3 Planes的组合Table 3 Combination of Planes
最后将测试的结果总结到表4。
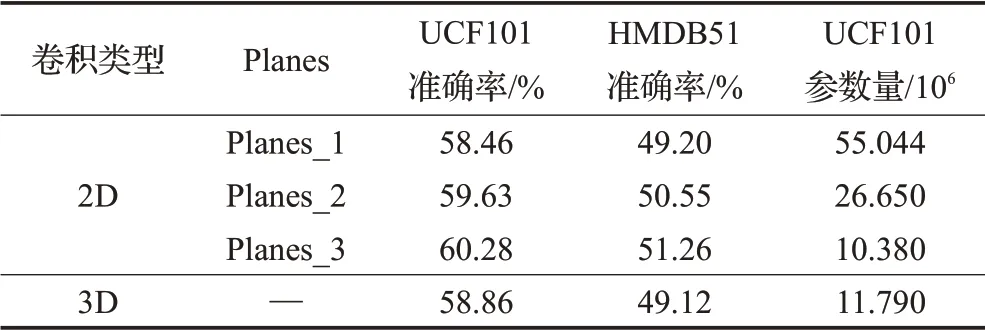
表4 不同卷积类型性能对比Table 4 Performance comparison of different convolution types
在Tail模块中全部使用3D卷积核时,相比于使用3D卷积核虽然获得了参数量的降低,但是会损失较多的精度,由此可证明将网络最后的3D特征图转换为2D特征图可以在一定程度上提高行为识别的准确率。而在进行网络重组的条件下,使用不同的卷积核数量也会影响识别的速度和精度,在卷积核数量较少时可以达到最好效果。
4 结束语
本文针对3D卷积过程中的填充方式设计了一种在时间维度不进行填充的3DCNN网络,还根据此种填充方式提出了3D网络到2D网络的网络重组结构,可以有效地提取并利用视频中的时空信息,提高行为识别的准确率。由于轻量化的结构设计,使得网络训练不需要依赖强大的算力,适用于特定的行为识别场景。在公开数据集UCF-101上的实验表明,本文设计的时域非填充卷积神经网络在准确率以及参数量方面优于一些主流的算法。
