改进YOLOX的轻量级安全帽检测方法
2023-01-13吕志轩马志钢
吕志轩,魏 霞,马志钢
新疆大学 电气工程学院,乌鲁木齐 830000
目前我国建筑行业仍处在一个持续发展的阶段,每年建筑从业人员都在增加,根据国家统计局发布的数据显示,与2016年相比,2020年我国工程监理从业人员增长39%,达到139万人;执业人员增长60%,达到40万人。随着从业人数的增加,每年因为未佩戴安全帽产生的安全事故也随之增加,给建筑行业带来了人员和财产的损失。目前在建筑工地中,仍然采用人工监督的方法判断工作人员是否佩戴安全帽,这种方法存在很大的缺陷,因为工作环境范围大,一人监督的范围有限很可能出现漏检的区域,如果分配多人进行监督则会增加人工成本。因此有研究者从人员安全和工程建设成本两个方面考虑,提出了基于目标检测技术的安全帽检测方法,该方法平衡了人员安全和工程建设成本之间的关系。近几年目标检测技术不断发展,在对安全帽检测方法的研究上也取得了一些成果,虽然基于目标检测的安全帽检测方法还未大范围使用,但作为保障生产安全的一项重要技术,未来在建筑工地、煤矿、变电站等工作环境下需求广泛。
目前对安全帽的检测方法分为传统检测方法和基于卷积神经网络的检测方法。传统的目标检测方法依靠人工构造被检测对象的特征,主要有HOG特征+SVM[1]、Harr特 征+Adaboost[2]、DPM特 征[3]等 算 法。Marayatr等[4]使用霍夫变换(Hough transform)方法检测摩托车行进过程中的头盔形态特征,检测准确率达到77%。这些传统算法仅适用于固定的特征,一旦检测目标的特征发生变化或者特征具有多样性,检测的准确性便会下降,鲁棒性较差。为了解决传统检测算法出现的问题,研究人员提出了基于卷积神经网络的目标检测方法。2014年,Girshick等[5]提出了R-CNN卷积神经网络检测方法,该方法将目标检测分为两阶段(two-stage),第一阶段使用一个网络模型生成预选框(proposal),第二阶段使用另一个网络模型对预选框进
行检测与判别来得到物体的类别和位置信息。2016年,Redmon等[6]在R-CNN的基础了提出了单阶段(one-stage)检测方法YOLO(you only look once),该方法只使用一个网络来获得物体的类别和位置信息,提高了对物体的检测速度;2018年,Law等[7]对单阶段检测方法进一步改进,提出了无锚框(anchor free)类型网络检测方法CornerNet,该方法对物体关键点进行检测来得到位置信息,大幅减少网络参数,由此基于卷积神经网络的目标检测方法逐渐走向成熟。在目前基于卷积神经网络的方法中,YOLO系列目标检测方法对物体的检测表现较好,被很多研究者用于安全帽检测研究。王雨生等[8]使用YOLOv4与YCbCr颜色空间交叉筛选的方法来检测安全帽;Fu等[9]在YOLOv5上新增了一个特征输出来检测小目标安全帽,并使用聚类方法得到更合适的先验锚框;高明华等[10]改进YOLOv3中的交并比函数和数据增强方法,使得对交通目标的检测精度达到86.3%;蒋润熙等[11]将YOLOv5的主干网络换为Hour-Glass网络,将对安全帽的检测精度提高到了84.3%。
以上安全帽检测方法都有较好的检测精度,但在施工环境下进行实时检测时要求模型不仅需要高检测精度,还需要轻量化参数权重满足较低算力的硬件配置。因此本文使用轻量级网络结构的YOLOX-s作为基线模型,首先设计了分支注意力模块(branch attention,BA),将基线模型的预测端输出按通道承载信息类别不同拆为两部分分别输入BA的上下分支,在提高模型检测精度的同时减少加入注意力模块带来的计算量,接着,用马赛克(Mosaic)方法拼接数据集生成复杂背景模拟施工中的复杂环境,通过在线困难样本挖掘(OHEM)搜索拼接数据里的困难样本进行再训练,提高模型在复杂环境下的鲁棒性,增加施工环境中安全帽的检测精度,然后,设计一种余弦退火算法(cosine decay warm restarts,CDWR)在模型训练中调节学习率,在学习率曲线中加入预热(warm up)使得模型权重逐步稳定,加入重启(restart)增加模型权重跳出局部最优的能力,加快训练收敛的同时使模型达到更小损失值,最后,在safety helmet wearing数据集上进行测试,验证模型的检测性能。
1 YOLOX网络模型介绍
YOLOX是Ge等[12]对YOLOv3网络进行改进后提出的新一代目标检测网络,相较于之前的YOLOv3、YOLOv4[13]、YOLOv5网络,YOLOX最大的改进是取消了在预测端(prediction)使用多个锚框预测物体的位置和类别,使网络检测头处的参数量减少约66%。YOLOX继承了YOLOv5的网络拆分功能,可以将网络按大小划分为:YOLOX-s、YOLOX-m、YOLOX-l、YOLOX-x、YOLOX-Darknet53,其 中 轻 量 级 模 型YOLOX-s的网络深度和宽度最小,网络参数量为9.0 MB,权重文件大小为35 MB,与YOLO系列中最具代表性的YOLOv3相比参数量减小了85.46%,权重减小了85.77%。
YOLOX-s的结构如图1所示,网络结构分为输入端、主干网络、颈部、预测端四个部分。在输入端部分,YOLOX-s可以使用数据增强方法对输入的图像进行预处理;主干网络部分使用CBL模块和SSP[14]模块来增强网络的特征提取能力;颈部使用FPN结构进行特征融合;预测端部分使用解耦头(decoupled head)将经过特征融合后的输出拆分为类别概率、位置、置信度三部分,分别进行计算并拼接后得到预测结果,最后预测端部分会将三个不同尺度大小的预测结果合并,输出预测结果。
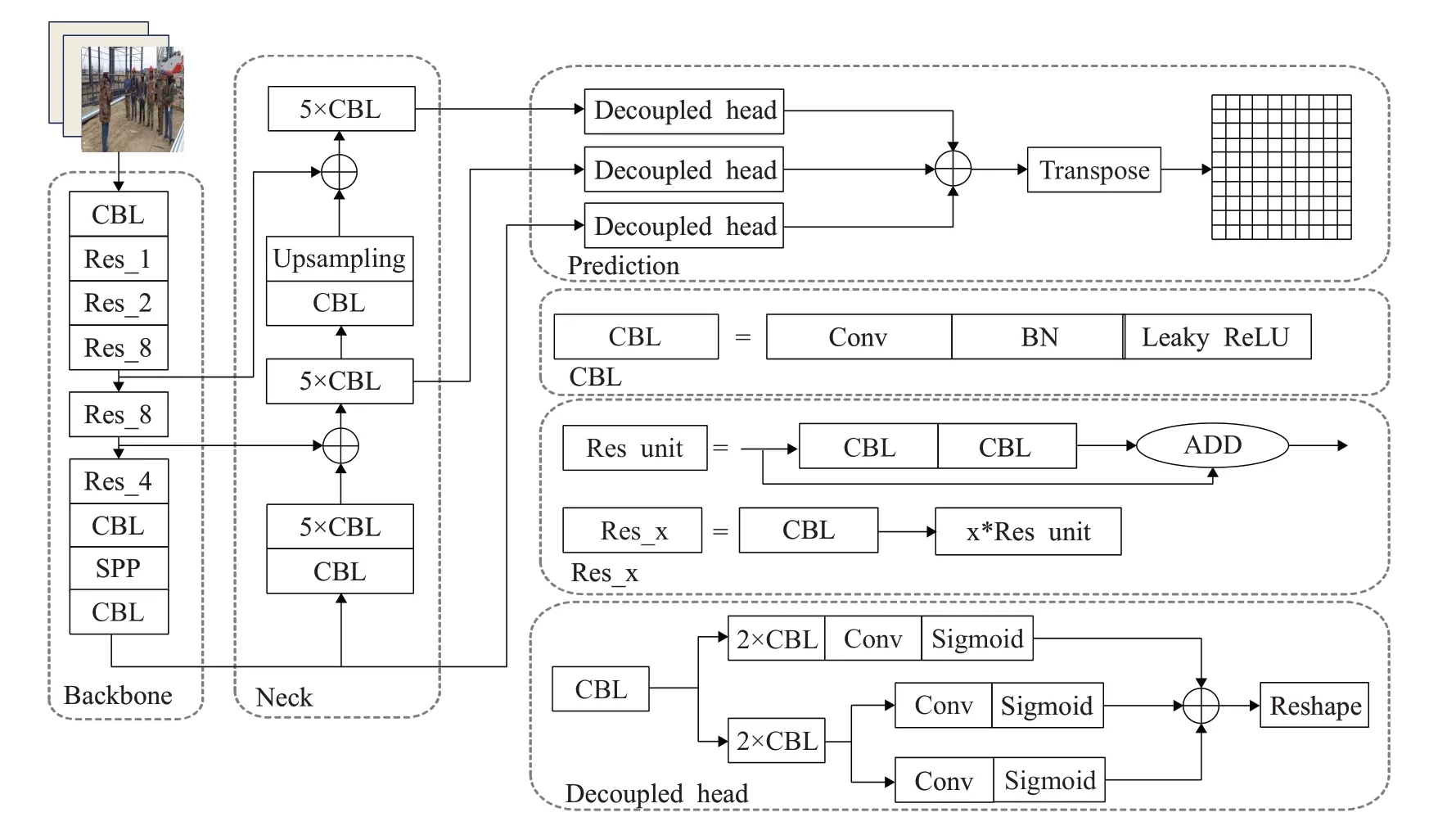
图1 YOLOX-s的网络结构图Fig.1 Network structure diagram of YOLOX-s
2 网络模型改进与创新
2.1 数据增强
在复杂的施工环境下,多变的天气、工作中的尘埃以及密集的工作人员是影响模型检测效果的因素;考虑到数据集中的大部分图像中被检测物体数量少、物体背景清晰、单一,不符合施工复杂环境的要求,这会影响训练模型后的检测性能。因此,本文将在线困难样本挖掘(OHEM)[15]和Mosaic数据增强方法结合来提高数据的多样性以及困难样本的数量。
在进行数据增强前,首先对safety helmet wearing安全帽数据集进行分析,得到如图2所示的安全帽标记框面积分布情况。
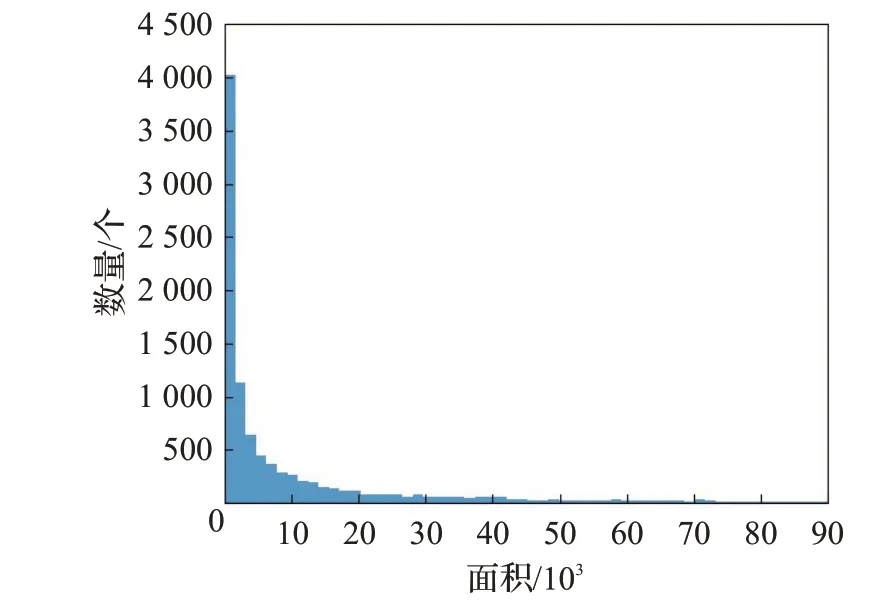
图2 数据集标记框面积分布情况Fig.2 Distribution of dataset true frame size
由分布图可以看出标记框面积集中在10 000以下,在整个数据集中大部分安全帽的标记框宽度和长度集中在50个像素左右,若输入图片大小为416×416像素,标记框面积约占图像总面积的0.029%,因此可以看出数据集中的目标大多属于小目标类型。
在目标检测中,数据集中的图片分辨率不高,小目标物体信息少、噪音多,这些问题是检测小目标实际且常见的困难问题。为了解决模型在检测小目标安全帽时遇到的以上问题,在模型训练过程中加入在线困难目标挖掘方法。每一轮训练周期结束,模型会筛选出10%损失值最高的数据标记为困难样本,在下一轮训练周期被标记为困难样本的数据将被加入到训练集中继续进行训练,直到网络对其的检测损失值低于其余10%数据。加入OHEM后的模型训练流程图如图3所示。
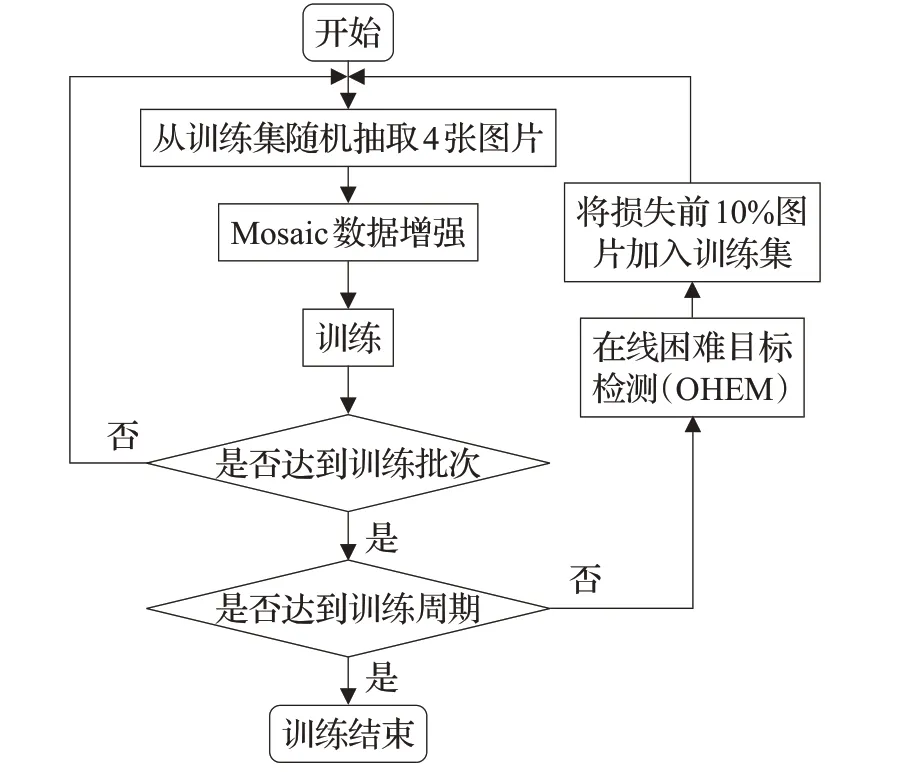
图3 模型训练步骤Fig.3 Model training steps
同时为了提高模型在复杂环境下的检测能力以及鲁棒性,在每一批次训练前使用马赛克(Mosaic)方法进行数据增强。Mosaic将训练集中抽取的4张图片进行随机大小缩放、色域变换、水平翻转,然后将经过变换后的4张图片拼接在一起形成一张初始数据集中没有的图片输入模型进行训练。如图4为经过Mosaic数据增强后的结果,图4(a)由4张单独图片合并为一张安全帽更加密集的图像,模拟施工环境下密集人员工作时佩戴安全帽的情况,图4(b)为多张施工尘埃环境下造成背景模糊的图像被Mosaic合并在一起,形成一张新模糊背景图像,图4(c)将沙尘、晴天、雨天、雪天背景安全帽合并,新形成的图像背景复杂多样,能够避免单张图像背景单一的问题,图4(d)分别选取了尘埃背景、密集人群、不同天气下的图片,使用Mosaic方法合并后的新数据具备了施工中复杂环境的所有情况,并且因为每一批次抽取的图像均不同,所以Mosaic能在提高数据集多样性的同时避免数据训练时出现过拟合状况,同时Mosaic将多张图片合并创造了和复杂环境相似的背景,提高模型训练过程中对复杂环境下安全帽的检测能力。

图4 经过数据增强后的图片Fig.4 Data enhanced pictures
OHEM与Mosaic相结合的数据增强方法能提高模型对小目标安全帽的检测能力,避免数据集反复训练产生过拟合情况。因为safety helmet wearing数据集中大部分安全帽都为小目标,而小目标物体检测难度高产生的损失值大,因此使用OHEM搜索时小目标安全帽数量越多的图像越容易被标记困难样本反复训练,从更多次训练中提高对小目标特征的检测能力;同时为了避免OHEM搜索困难样本时标记同一批图片造成过拟合,在训练时使用Mosaic方法从训练集中随机抽取图片拼接,OHEM根据比较拼接图片的损失值来标记样本,若第一次拼接的4张图片被标记,则下一次训练这4张仍被拼接在一起的概率仅为0.152%,且经过Mosaic随机大小缩放、色域变换、水平翻转后,每一次训练图片的大小颜色都与之前不同,极大降低了反复训练相同图片过拟合的可能。
2.2 分支注意力模块
轻量级网络模型YOLOX-s参数量少,但相对YOLOX的其他结构网络检测精度较低,为弥补精度方面的不足,在模型中加入分支注意力模块(branch attention,BA)。
注意力模块包括通道注意力模块(channel attention,CA)和空间注意力模块(special attention,SA)。CA的作用是计算出输入特征每个通道对应的权重,模块结构如图5所示,首先对输入特征F进行通道间的最大池化和平均池化得到特征描述Favg和Fmax,将特征描述输入三层全连接层构成的多层感知器MLP,结果相加使用激活函数Sigmoid处理,得到一维通道注意力权重MC∈RC×1×1。MC的计算公式如下:
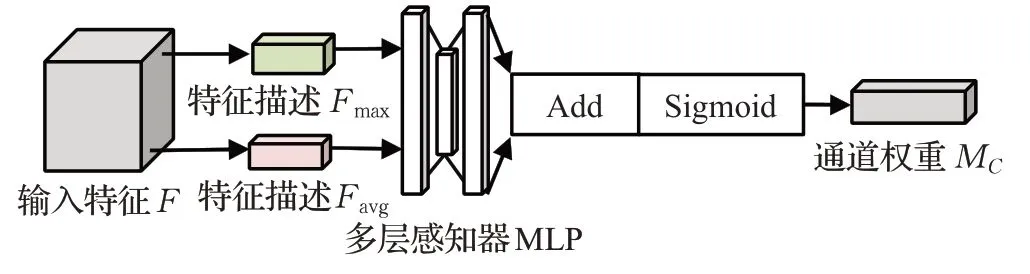
图5 通道注意力模块结构Fig.5 Structure of channel attention module
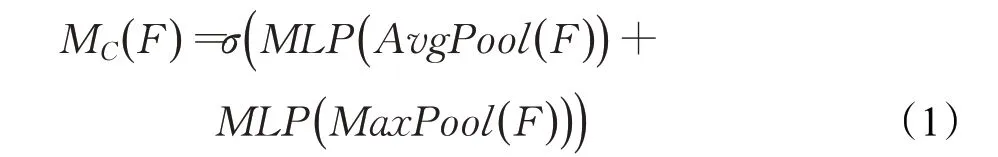
式中F是图片经过YOLOX-s模型处理后的输出特征,AvgPool是通道间的平均池化函数,MaxPool是通道间的最大池化函数,MLP是多层感知器,σ表示Sigmoid[16]函数。
SA的作用是计算出每个特征点对应的权重。模块结构如图6所示,首先对输入特征F进行全局最大池化和平均池化,并对得到的两个特征描述Fmax、Favg进行拼接、卷积和激活函数处理,得到二维空间注意力权重MS∈。MS的计算公式如下:
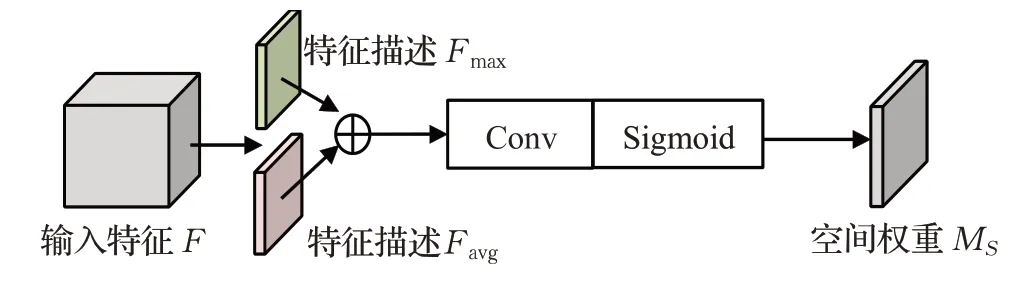
图6 空间注意力模块结构Fig.6 Structure of special attention module

式中AvgPool是空间上的平均池化函数,MaxPool是空间上的最大池化函数,Conv是卷积函数,⊕表示特征合并操作,其余符号均与公式(1)相同。
普通注意力模块(CBAM)[17]中通道注意力模块和空间注意力模块为串联连接,训练过程中预测端输出的所有通道都经过CA和SA的处理,但预测端输出的通道有一部分对空间信息敏感,另一部分对通道信息敏感,因此将所有通道输入普通注意力模块增加了计算量,并且CA中使用全连接层来提取空间特征效率不高的同时增加了网络的计算量。为了解决以上两点问题,对注意力模块进行改进。首先,图像特征在经过解耦头(decoupled head)后会被分成三部分:第一部分是物体位置通道Freg∈R4×H×W,第二部分是置信度通道Fcof∈R1×H×W,第三部分是物体的类别通道Fcls∈RC×H×W,Freg上的特征点记录着预测框中心点相较于当前特征点的偏移量信息(x,y)与预测框的宽高信息(w,h),对应4个通道,Fcof上的每个特征点代表对应预测框内存在被检测物体的概率信息,Fcls的各个通道内容代表模型所要检测的各个类别的概率信息。将类别通道仅输入CA模块计算得到通道权重,将物体位置通道和置信度通道仅输入SA模块进行计算得到空间权重;其次,将CA模块中的多层感知器结构换成滤波器大小为1×1的卷积层,通过以上操作来减小计算量。改进后的通道注意力权重M′C计算公式为公式(3),空间注意力权重MS的计算公式为公式(2),注意力模块对输入特征的总体计算公式为公式(4)。
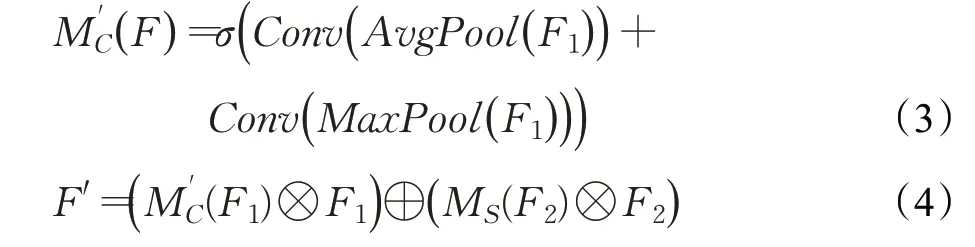
式中F1是类别通道,F2是位置与置信度合并后的通道,MS是空间注意力模块,M′C是经过改进的通道注意力模块。改进后的分支注意力模块(BA)结构如图7所示。
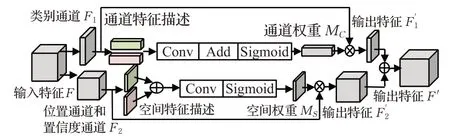
图7 分支注意力模块结构Fig.7 Structure of branch channel attention module
特征F∈R(C+5)×H×W(C是输入特征的类别数,H、W是输入特征的高和宽)输入分支注意力模块后将分为类别通道F1∈RC×H×W与位置、置信度合并后的通道F2∈R5×H×W。F1经过通道注意力模块由公式(3)计算得到通道权重MC∈RC×1×1,通道权重MC被定义为一个由检测类别数量(C)个1×1张量组成的张量矩阵,其中第Ci∈{ }1,2,…,C个张量的数值大小代表当前图片对应第Ci∈{ }1,2,…,C个类别的权重,将所有张量的权重合并形成矩阵权重,矩阵权重中数值最高的一个张量值对应的类别最有可能为输入图片的类别。F2通道处理过程与F1类似,通过公式(2)计算得到空间权重MS∈R1×H×W,MS权重矩阵是1个高为H宽为W的二维张量,由H×W个张量元素Cij∈{{1,2,…,W},{1,2,…,H}}组成,每个张量元素对应的权重越大代表该位置的信息越重要。计算权重MS时置信度通道Fcof起到了决定位置权重大小的作用,因为Fcof上的每个特征点的数值大小代表存在被检测物体的概率,因此Fcof中特征值越接近1的特征点存在物体的可能性越大,该特征点对应Freg越精确,同理Fcof特征值越趋近0的特征点存在物体的概率越小,对应位置处的Freg值也趋近于0,计算得到的权重越小,因此在计算MS过程中,高特征值对应的Fcof位置更有可能获得高注意力权重。将权重与对应通道相乘得到输出特征,对经过注意力模块处理的输出特征F′1与F′2进行合并得到对图片一次训练后的结果F′。
类别通道F1与位置、置信度通道F2在输入注意力模块后要经过Sigmoid函数处理,将原本值域在的空间权重和通道权重值变换到(0,1)区间内,当一张图片上的物体类别与位置特征被检测出来,对应的通道权重与通道上特征点的权重将接近于1,错误类别和位置的特征点权重向0靠近。
2.3 学习率控制算法
在训练模型过程中使用随机梯度下降(stochastic gradient descent,SGD)[18]作为优化器(optimizer),使用指数下降算法(exponential LR,ELR)[19]控制optimizer学习率的大小,改变模型权重更新时的迭代步长。ELR作为学习率控制器下降曲线如图8(a)所示,随着训练batch次数的增加ELR控制的学习率按指数减少,更新步长逐渐趋近于0,符合梯度下降算法在初始时用大步长寻找最小值范围,逐步减小步长向最小点靠近的寻优规律;但由于目标优化函数曲线上可能分布着多个局部最小值(local minima),仅有一个全局最小值(global minima),ELR算法控制的SGD优化器很容易陷入局部最优,如图9所示,初始时较大学习率下的大步长让模型很容易跳过前两个local minima,之后学习率持续减小,到达第三个local minima时模型权重更新步长太小而陷入局部最小点。
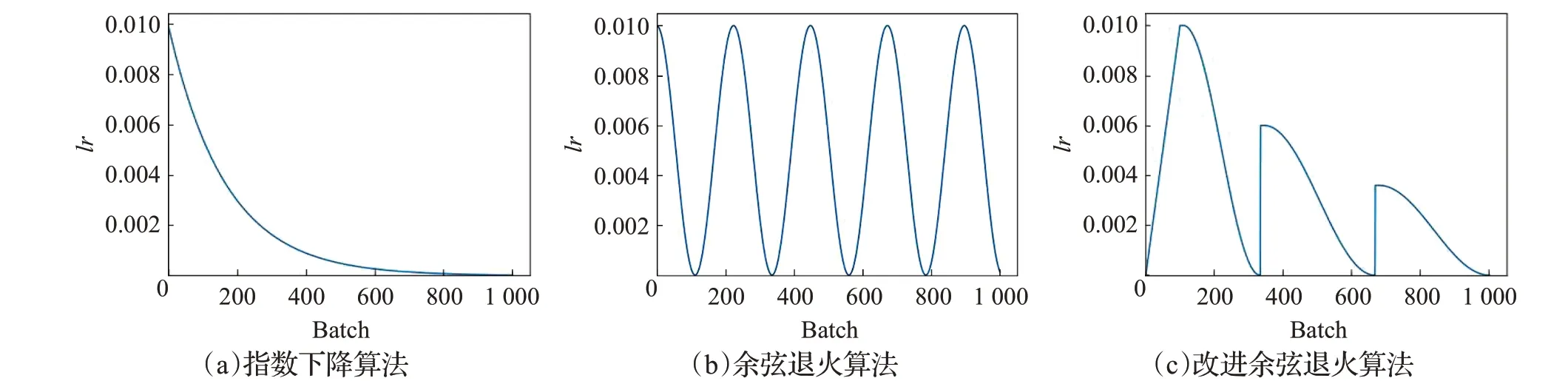
图8 三种不同的学习率下降曲线Fig.8 Decline curves of three different learning rates
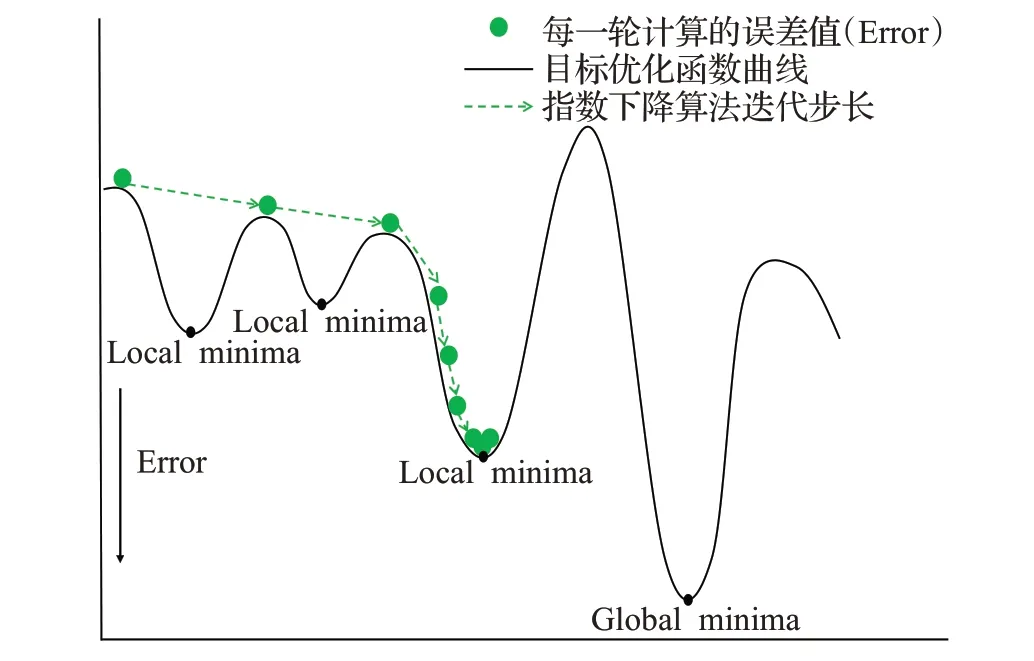
图9 指数下降算法控制下的寻优过程Fig.9 Optimization process controlled by exponential LR
文献[20]将模拟退火算法与正余弦算法结合,提出的余弦退火算法(cosine annealing warm restarts,CAWR)解决了模型陷入局部最优的问题,学习率下降曲线如图8(b)所示。CAWR算法中加入了重启(restart)机制,在学习率下降到一个较低点时重启返回到原点,通过这种方法增大步长跳出局部最小点,但由于CAWR每次重启时均回到初始值,初始较大的步长可能导致模型跳出global minima。如图10中CAWR控制的优化器在到达第三个local minima后学习率降为最小值,这时restart学习率增大步长使模型跳出了局部最小点继续寻优,但global minima处的再一次的restart让模型跳出了全局最小点;因此余弦退火算法优化器可以找到目标优化函数的最优值,但很难在最优值点处达到稳定,增加了模型训练达到收敛的时间。
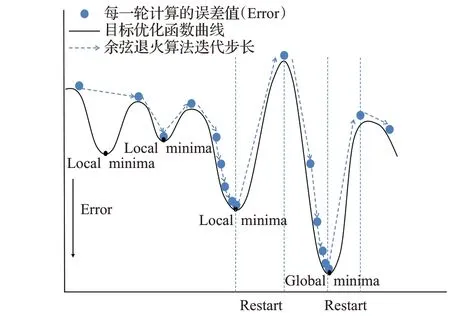
图10 余弦退火算法控制下的寻优过程Fig.10 Optimization process controlled by cosine annealing warm restarts
为了解决指数下降算法的局部最优问题和余弦退火算法重启机制造成的模型训练收敛时间慢的问题,将指数下降算法的逐步下降规律与余弦退火算法的重启机制结合,设计一种新的余弦退火算法(CDWR)。首先,在算法中加入重启机制,将restart次数减小为3次,同时增加每个restart后的batch数量来保证模型重启跳出局部最优后能达到下一个稳定值,然后,每次restart后降低学习率最大值为前一峰值的2/3,总体上逐步减小权重更新步长,在保持模型有跳出局部最优能力的情况下逐渐变得稳定,最后,在算法中加入预热[21](warm up)机制,学习率在训练开始时设置为0逐渐增大,模型在学习率增大过程中进行预热训练,直到达到设定值后开始正式训练,因为初始时模型权重是随机值,较大的学习率让权重大幅度振荡,而warm up使权重达到稳定之后再开始正式训练,模型收敛速度会变得更快,CDWR算法的下降曲线如图8(c)所示。CDWR算法的寻优过程如图11所示,在初始warm up阶段权重步长逐渐变大,在到达第三个local minima处陷入局部最小,此时经过restart后跳出局部最小点逐步到达global minima,这时模型再次restart后学习率仅能达到第一次的2/3,此学习率下优化器的步长已经不能跳出当前全局最小点,之后模型权重在global minima左右摆动直到到达全局最小点。
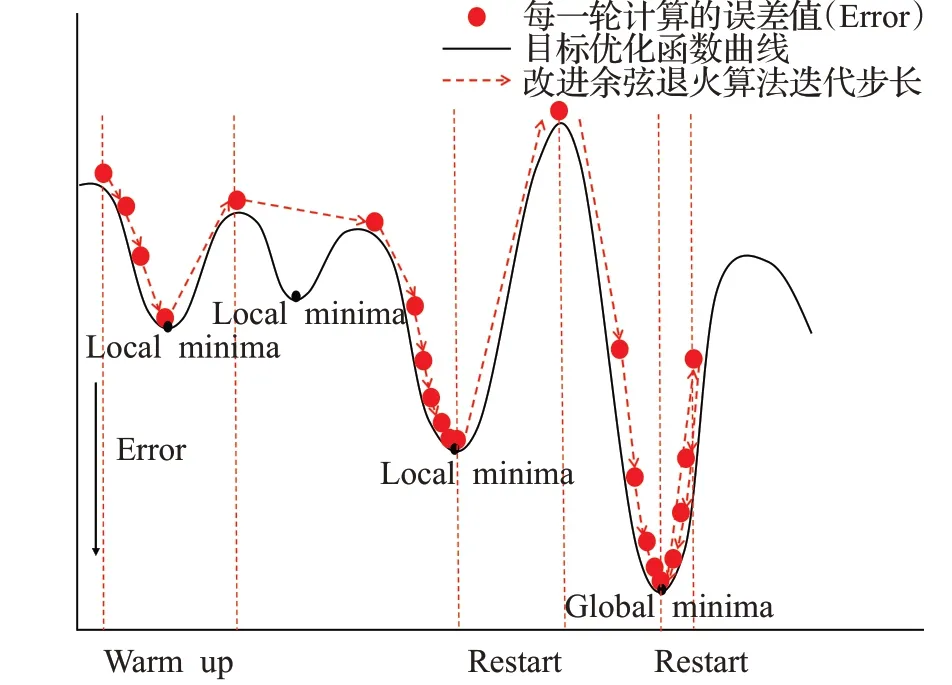
图11 改进余弦退火算法控制下的寻优过程Fig.11 Optimization process controlled by cosine decay warm restarts
CDWR算法的计算公式如下:

式中Ti是当前训练批次数,T是总训练批次数,Twarm是预热批次数,Thold是学习率维持不变批次数,μmax是学习率最大值,μmin是学习率最小值,φ是幅度变化常数,lr是当前学习率大小,count是跳出局部最优次数。
3 实验
3.1 实验数据集
实验数据使用的是safety helmet wearing数据集共7 581张图片,数据集中的图片来自谷歌和百度,并且使用Labelimg对图片进行了标定,符合实验训练要求。使用其中3 241张图片进行实验,训练集和测试集的比例设置为9∶1,训练集图片数量为2 624张,验证集数量293张,测试集数量324张。
3.2 实验环境
实验在Win10操作系统上进行训练和测试,显卡使用NVIDIA Tesla K80,深度学习框架为Pytorch,使用GPU进行运算,使用CUDA并行架构来提高计算能力,在训练过程中训练批次大小(batch size)设置为32,初始学习率(learning rate)设置为0.01,实验所需的具体运行环境如表1所示。

表1 实验训练环境配置Table 1 Experimental training environment configuration
3.3 模型训练
实验中训练集图片数量2 624张,1个训练批次(batch size)包含32张图片,1个训练周期(epoch)包含82个训练批次,本次实验总共训练100个周期,8 200个批次,262 400张图片。在训练过程中,每完成1个训练批次(batch size)调节1次学习率,实验总共调节8 200次学习率,学习率由改进余弦退火算法(CDWR)调节。
3.4 评价指标
能反映网络模型性能的因素主要有网络模型的检测精度、检测速度和模型的权重大小,对以上因素进行评价需要恰当的评价指标。本文使用召回率(recall)、精确率(precision)、平均精度(average precision,AP)、平均精度均值(mean average precision,mAP)指标来评价模型的检测精度,使用帧率(frame per second,FPS)指标来评价模型的检测速度,使用模型参数量(parameter)指标来评价模型的权重大小,使用损失值(loss)指标来评价模型的训练情况。
3.4.1 召回率和准确率
召回率和准确率的计算方法为公式(6)和(7):
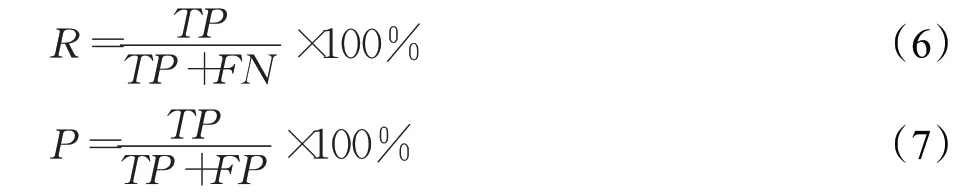
式中,R表示召回率,P表示准确率;TP为预测正确的正样本数,FN为预测错误的负样本数,FP为预测错误的正样本数。
3.4.2 平均精度和平均精度均值
平均精度和平均精度均值的计算方法为公式(8)和(9):

式中,AP为平均精度,mAP为平均精度均值,PA为不同检测类别均精度的计算需要用到召回率和准确率;在模型实验结束后会得到所有数据的召回率和准确率值,将这两个值作为横纵坐标轴,可以绘制出模型的PR曲线图,使用积分计算出曲线图的面积,就可以得到模型的平均精度AP,AP值用于评估模型在单个检测类别上的表现;所有类别的AP的平均值就是mAP值,模型的mAP值越高,其检测性能越好。
3.4.3 帧率
帧率(FPS)表示模型每秒处理图片的数量,模型的帧率越大处理图片的速度越快,模型的检测速度也越快。
3.4.4 参数量
模型参数量和计算量的计算如公式(10):
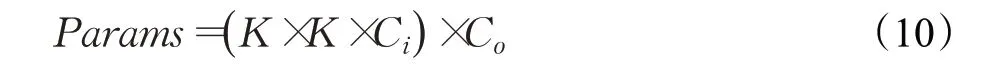
其中,Params表示在一个卷积层且不考虑偏置条件下的参数量,公式中K为卷积核大小,Ci、Co为输入输出通道数量,H、W为输入特征的大小。
3.4.5 损失值
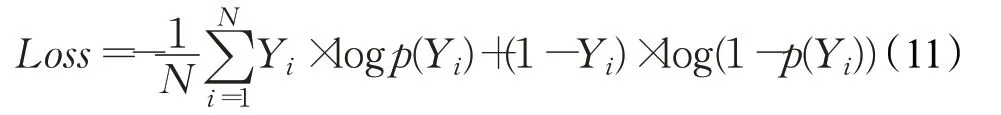
在训练中使用二值交叉熵损失函数来计算损失值,式中Yi为类别标签,p(Yi)为目标被预测为该类别的概率,N为被预测为该类别的目标数量。将模型训练过程中的所有损失值绘制成曲线图,可以得到模型训练时的损失下降情况和收敛情况。
3.5 实验结果及分析
3.5.1 消融实验
为了验证各个模块对YOLOX-s2检测效果的影响,在safety helmet waring数据集上进行消融实验,实验以YOLOX-s作为基线模型,逐渐增加模块测试模型的性能结果,消融实验结果如表2所示。

表2 消融实验结果Table 2 Ablation experimental results
对比YOLOX-s和YOLOX-s+OHEM的性能,加入在线困难样本挖掘方法的模型比基线模型mAP提升了0.88个百分点,recall提升了2.35个百分点,表明使用OHEM方法对难识别图像反复检测能在一定程度上提高对安全帽特征的提取能力,增加样本中检测到安全帽的数量。加入Mosaic的YOLOX-s+OHEM模型与YOLOX-s+OHEM相比mAP提升了3.39个百分点,F1提升0.3,precision提升2.65个百分点,recall提升3.58个百分点,证明对经过Mosaic预处理后的数据集训练可以增强网络识别定位物体的能力,提高模型在多数量小目标场景下及复杂环境下判别安全帽的能力。对比YOLOX-s+OHEM+Mosaic+CDWR和YOLOX-s+OHEM+Mosaic的性能,加入CDWR后的模型mAP仅提升了0.06个百分点,因为学习率控制器对模型的检测效果影响较小,其最主要的作用是控制模型在更少的时间里达到收敛,模型收敛时间对比结果详见3.5.3小节。
对比YOLOX-s+OHEM+Mosaic+CDWR和YOLOX-s+OHEM+Mosaic+CDWR+BA性能,加入分支注意力模块后模型mAP提升2.36个百分点,F1提升0.4,precision提升5.29个百分点,recall提升2.34个百分点,表明分支注意力模块可以对每层通道和通道特征点合理分配权重,提升网络对存在物体区域的关注程度,获得关键区域的类别与位置信息。
对比消融实验的所有模型,向基线模型逐渐增加模块后各改进模型的detection time和FPS变化幅度较小,证明在实验中增加模块提升模型准确率和召回率的同时,并没有较大增加对图片的检测时间,改进模型的检测速度仍然符合实时检测要求。
3.5.2 注意力模块可视化实验
对加入分支注意力(BA)的仿真结果与未使用注意力模块的仿真结果进行可视化处理,可视化处理结果如图12所示,对比两者的可视化图可以发现使用BA的模型结果比原模型结果覆盖了更多包含安全帽的面积。因为未加入注意力模块的方法过于关注图片中特征明显的物体,容易检测到带有明显特征的目标,但经常漏检错检小目标与特征不明显的目标。实验中带有BA的方法不仅关注主要特征,对较为次要的特征也给予了关注权重,因此可以提取到更多信息,仿真结果中也能检测到更多的物体。

图12 可视化处理结果Fig.12 Visual simulation results
BA模块的两个分支分别给类别通道的通道、位置与置信度通道的空间点分配不同大小的权重,根据权重大小反应通道和空间点的重要性,为了证明BA模块的每个分支都有效果,将经过上分支的类别通道和经过下分支的位置与置信度通道进行像素值分布可视化。
实验设置两个类别通道,第一个通道为正确类别safety helmet,第二个通道设置为数据集中不存在的类别book,将模型训练40个epoch后按通道像素值绘制直方图,每个通道的像素值分布如图13所示。图13(a)为所要检测物体正确类别通道的像素值分布情况,其像素点有多半像素值大于0,表明该通道极有可能是正确类别,对照组图13(b)为第二个通道的像素值分布情况,由直方图发现二通道的所有像素值均小于0,表明在检测图片中不存在该通道类别的物体。
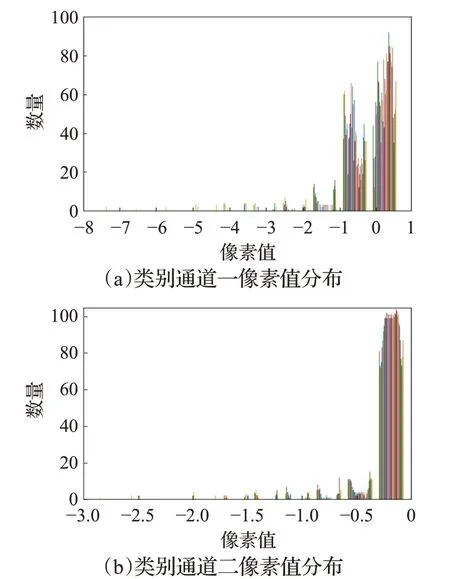
图13 类别通道像素值可视化Fig.13 Visualization of category channel pixel value
初始时位置与置信度通道的像素值分布情况如图14(a)所示,通道上的像素值集中在0附近,存在较多像素值大于0.5的像素点(像素值大于0.5表示该特征点有很大概率存在物体)表明这时通道空间点的像素值为随机分布,对图像中物体位置、置信度信息描述仍不准确。经过40个epoch训练后,位置与置信度通道的像素值的分布情况为14(b)所示,此时大部分空间点的像素值小于0,对应图像中大多数不存在物体的特征点,只有少数像素值处于(0,1)之间,此时位置与置信度输出特征包含了图像中接近真实物体数量的位置与置信度信息。
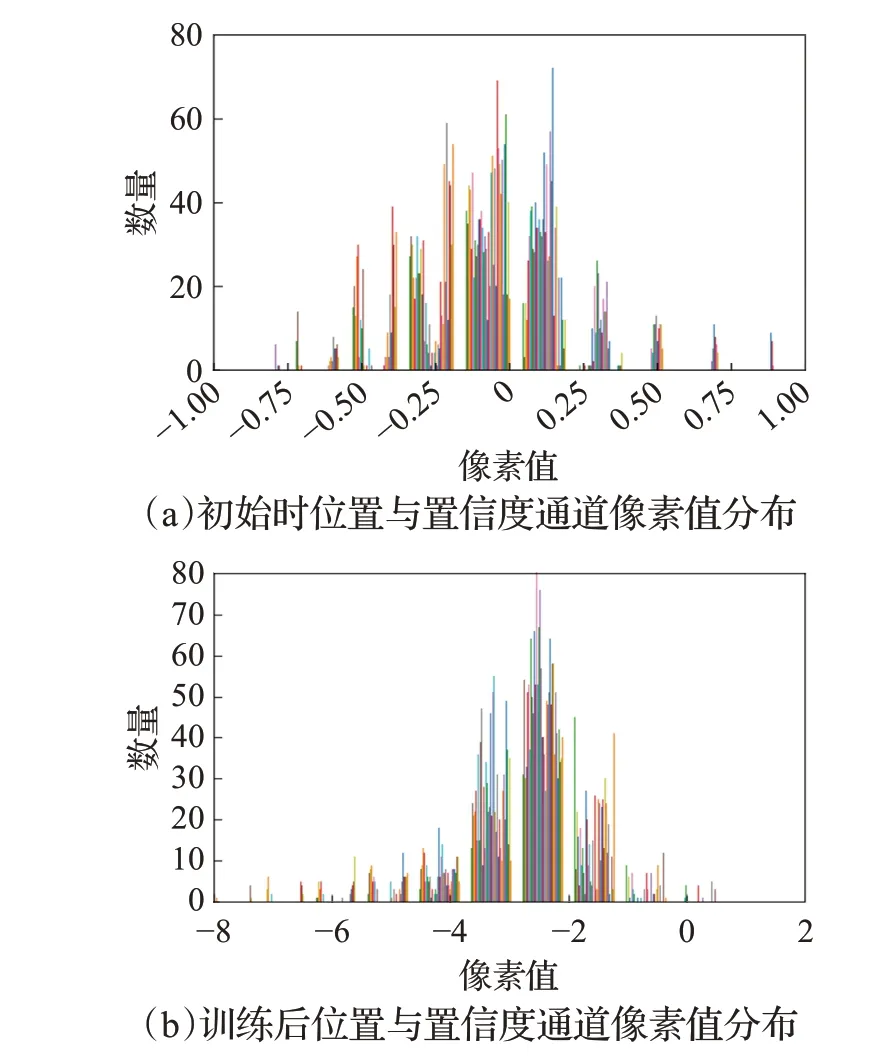
图14 位置与置信度通道像素值可视化Fig.14 Visualization of position-confidence channel pixel value
3.5.3 模型训练结果
使用CDWR控制模型学习率并进行100个周期(epoch)的训练后,YOLOX-s2模型的损失值变化情况如图15所示。训练到30个周期时模型的损失值逐渐趋于稳定但仍处于一个较高值,可以基本确定此时模型陷入局部最优;此时将学习率升高使模型训练到60个周期时达到了更低点,证明模型跳出了局部最优点,同理当模型训练到90个周期时损失再次达到更低点,在此之后损失值基本不再变化,从模型损失值的下降情况来看模型训练结果较为理想。
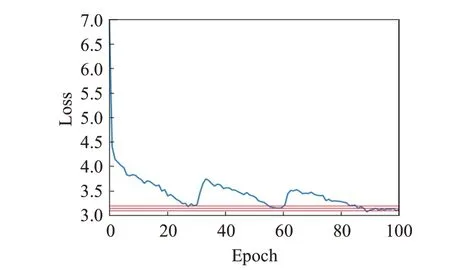
图15 模型在训练过程中的损失变化情况Fig.15 Loss change of model during training
为检测改进学习率对模型训练时间的影响,分别将YOLOX-s2模型的学习率下降算法设置为指数下降算法(ELR)、余弦退火算法(CAWR)和本文提出的CDWR算法,在相同实验环境下进行三次训练。实验结果如图16所示,可以看出使用改进余弦退火控制学习率的曲线在第十个训练周期时已经达到稳定,和另外两个算法相比收敛时间较快,与原余弦退火算法相比收敛时间减少50%以上,并且在同样的训练周期下模型损失值能下降到一个更低点,与指数下降算法相同训练周期下的损失值下降了1左右,与余弦退火算法相比损失值下降了0.5左右。
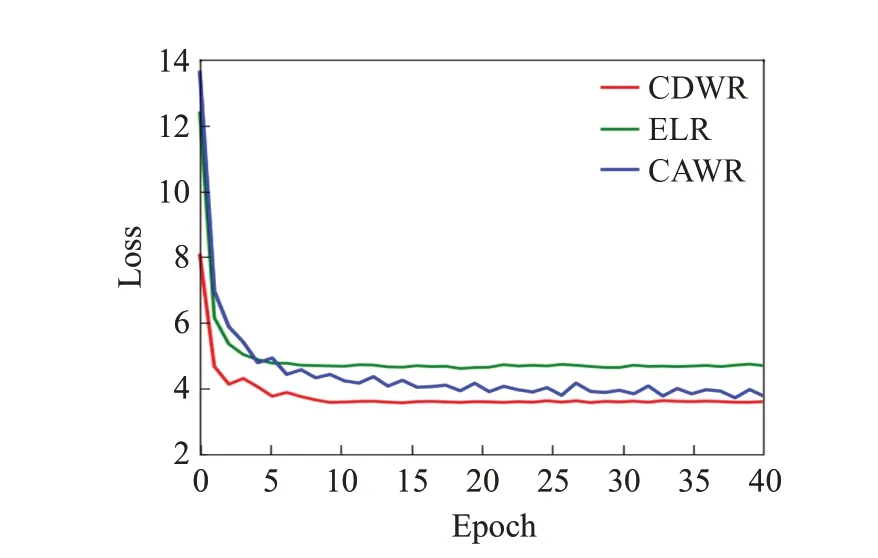
图16 训练中的模型损失变化曲线Fig.16 Model loss variation curve in training
3.5.4 对比实验
实验选择目前目标检测领域主流方法SSD、CenterNet、YOLOv3、YOLOv4、YOLOv5-s、YOLOX-s与本文方法进行比较,其中SSD、YOLOv3、YOLOv4[22]、YOLOv5-s是基于锚框的单阶段类型检测方法,Center-Net、YOLOX-s是无锚框(anchor free)类型检测方法,YOLOv5-s、YOLOX-s、YOLOX-s2是轻量级检测方法。对以上方法实验后的性能结果,如表3所示。
从表3中可以看出,SSD、YOLOv3、YOLOv4作为基于锚框单阶段检测方法的准确率(precision)和召回率(recall)均达到60%以上,但参数量(params)较大模型权重(weight)均在100 MB以上,检测时间(detection time)长,不适合配置在移动端且不满足实时检测要求。无锚框检测方法CenterNet的precision为99.72%,在所有方法中领先,但recall仅为44.13%,表明该方法几乎可以正确识别出检测到的安全帽,但很难检测到所有安全帽,同时params与weight太大,也不适合配置在移动端。对比轻量级网络检测方法YOLOv5-s、YOLOX-s和YOLOX-s2,YOLOv5-s的params与weight最小,仅为7.1×106和27.9 MB,但平均精度均值(mAP)在三者中最低,检测效果相对较差,本文算法YOLOX-s2在略微增加params和weight的条件下,模型的mAP值达到95.11%,precision值为95.18%,recall值为90.23%,检测性能领先于其他轻量级检测方法,且较低的params和weight适合布置在移动端进行实时检测。
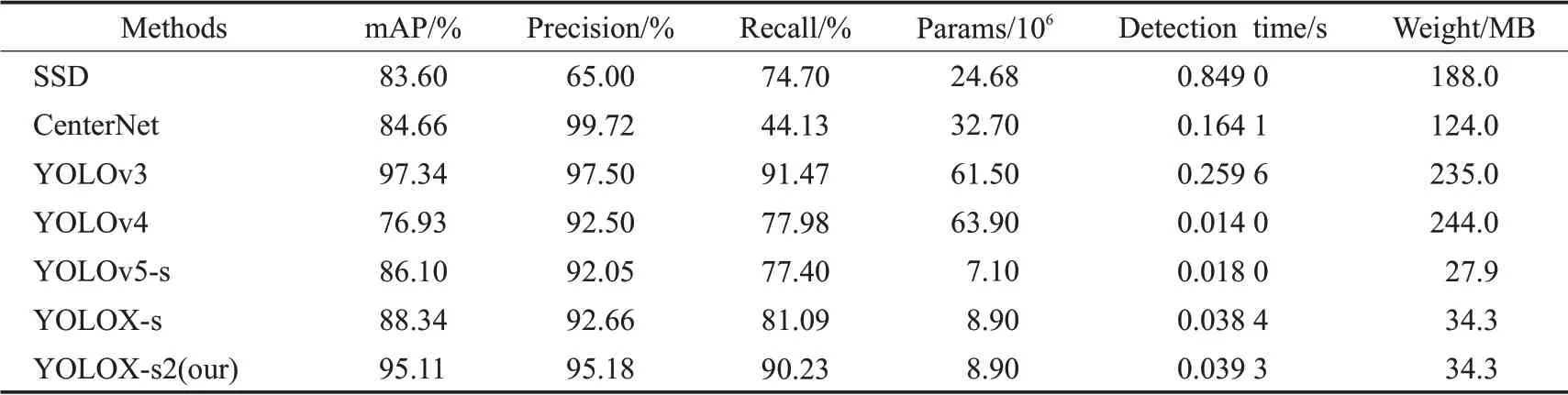
表3 本文方法与现有方法性能比较Table 3 Performance of proposed method compared with existing methods
为对比本文方法YOLOX-s2与原方法YOLOX-s对施工场景下安全帽的检测效果,选取多张施工场景下的图像进行检测。图17(a)为YOLOX-s方法的检测结果,图17(b)为本文方法的检测结果。从图中可以看出,使用YOLOX-s对安全帽进行检测存在错检和漏检,而在YOLOX-s2中错检漏检问题出现得更少,因此可以证明在YOLOX-s中加入经过改进的注意力模块提高了模型特征提取和分析能力,使得模型对目标的预测准确率更高,在训练过程中使用在OHEM与Mosaic结合的数据增强方法提高了模型对困难目标的检测能力,让YOLOX-s2模型能检测到一些难以发现的小目标。

图17 两种模型检测结果对比Fig.17 Comparison of test results of two models
4 结束语
本文对YOLOX网络进行改进,使用在线困难样本挖掘和Mosaic数据增强的方法重点训练困难样本,在模型预测端加入分支注意力模块提高模型在复杂环境下的检测精度,在训练中使用CDWR算法替代指数下降算法控制学习率来减少模型训练收敛时间。消融实验结果表明对原始模型进行以上方法改进均在不同程度上提高了检测性能。本文通过实验证明YOLOX-s2方法的检测精度和检测时间符合施工环境下实时检测安全帽的需求,并且适合移植到低算力平台进行实验。在后续研究中将继续完善YOLOX-s2方法来提高检测精度和检测速度,同时将模型移植到移动端来进行测试。
