基于AI分析的本地网情聚合系统设计与实现
2023-01-13李学环鲜学丰李娇娇
李学环,鲜学丰,李娇娇
(苏州市职业大学 计算机工程学院,江苏 苏州 215104)
在产学研建设的道路上,学校不断探索与地方政府合作,了解地方政府智慧城市建设中的智慧政务需求。政府为了解社情民意,需要掌握网民关注度高的事件和热门话题,并对大众关注的社会民生问题进行舆情跟踪,做好相关的预警防范工作。近年来,在政务领域的学术研究多集中在平台中的谣言识别引导、传播分析、信任度等[1-5],缺少对多平台属地化民生类数据的汇聚研究,缺少对区域性民生类事件的综合网情分析。同时,大数据、AI技术的深入发展,给基于自然语言处理技术的系统性研究注入了新的生命力。
1 关键技术
1.1 基于WebMagic定制化的分布式爬虫技术
本研究对本地论坛平台、微博平台和微信公众平台的舆情信息进行采集,利用基于开源爬虫框架WebMagic进行定制化开发,采用基于Redis请求消息缓存的分布式调度和具有优先级调度的采集策略。对于论坛、微博的话题以及海量源网页的存储,采用分布式的KV数据库HBase,该数据库能够提供基于主键的快速快照详情查询。考虑RowKey的分布均衡性,本研究设计了一套有效的RowKey生成规则。
数据采集主要包括通用模板数据采集和定制化数据采集。通用模板数据采集需要维护一个可访问采集目标的登录账号和代理IP池。定制化数据采集包括定制化微博数据采集和定制化微信公众号数据采集两种。定制化微博数据采集利用自动化测试技术进行模拟登录,获取浏览器的cookies并进行缓存,接着利用缓存cookies对目标开放搜索接口进行基于兴趣关键词组合的定量采集。定制化微信公众号数据采集基于搜狗微信收录的公众号,对于未收录的公众号使用手机集控软件采集。首先,经过ROOT后的Android手机自动关注目标公众号,如苏州发布、苏州交警等,而后通过微信内置的消息存储数据库查询获得最新的推送消息。综上,采集的数据均通过WebMagic的pipeline模块发送到消息总线Kafka进行消息缓存,供后续处理。
1.2 基于Spark on YARN的可靠计算技术
为了解决单机清洗和指标运算的性能瓶颈和系统可靠性问题,本系统的计算层采用开源大数据处理平台CDH套件,数据处理的计算层将Spark框架运行在大数据处理平台的YARN上,利用Spark on YARN架构解决了单机的内存、CPU的瓶颈问题[6]。架构本身的分布式、高吞吐、高容错等特征,增强了本系统计算层的可靠性和稳定性。将Spark-Streaming 与消息队列Kafka相结合可以实现秒级的可靠计算。计算层以Kafka为消息总线,对流入消息队列的数据进行清洗、分词、索引、关键词提取、窗口统计等,在此基础上,再结合下游存储库设计的存储幂等特性,实现exactly-once 语义计算。
1.3 基于AI预训练模型的自然处理技术
利用业界流行的Transformer预训练模型[7],结合本地网情数据及政务的实际需求,构建10个主题类别对本地网情的论坛数据特征进行预训练处理。对每个类别进行语料收集并标注,标出1 000~2 000条典型的数据语料。利用PyTorch机器学习框架,加载中文语料的预训练模型bert-base-chinese进行模型训练。通过数轮的迭代,训练出效果较好的文本分类和信息抽取模型,主要包括情感分类、主题分类等,在此基础上,再进行模型部署和API结构封装。
2 系统设计
目前,系统在校园网内运行,并准备向政府推介,垂直架构总体可分为4个层次:数据采集层、数据存储层、机器学习层和应用层。其中,应用层又分为对外提供应用数据的API层和展示层。
2.1 数据采集层
数据采集层是整个本地网情分析系统的基石,该层主要涉及分布式爬虫框架WebMagic的二次开发和使用。WebMagic高度模块化结构为爬虫系统开发提供了便利,主要包括爬虫下载模块、调度模块、解析模块等技术组件。爬虫平台涵盖了海量模板采集、JS逆向分析采集、App逆向分析采集等多个采集渠道。系统以本地民生数据为切入点,并不断扩展信息源,对新闻事件、论坛和微博话题、评论数据,以及微信公众号内容等目标进行定制化全量和增量采集。网情系统采集层架构如图1所示。

图1 网情系统采集层架构
2.2 数据存储层
数据存储层涉及采集消息的存储,以及业务处理过程中数据的可靠流转。数据存储和查询是本系统的另一个重要模块,该模块可为上层应用提供可靠的存储。存储层包括进行元数据管理的关系型数据库MySQL和基于HDFS的HBase KV网页存储系统。业务中间数据的流转采用Kafka消息系统,以及提供全文检索和统计聚合能力的SolrCloud系统。数据存储层主要涉及存储系统的机器资源规划、部署、调优、维护等。
2.3 机器学习层
机器学习层主要利用标注语料对预训练模型进行微调,再利用训练后的模型进行模型部署。其中,基于PyTorch机器学习框架的分类模型定义和训练代码示例如下:

2.4 应用层
应用层主要是对计算层处理后的数据进行条件检索,对机器学习后的指标进行大屏展示,以及对订阅的消息进行条件预警。网情系统应用层架构如图2所示。
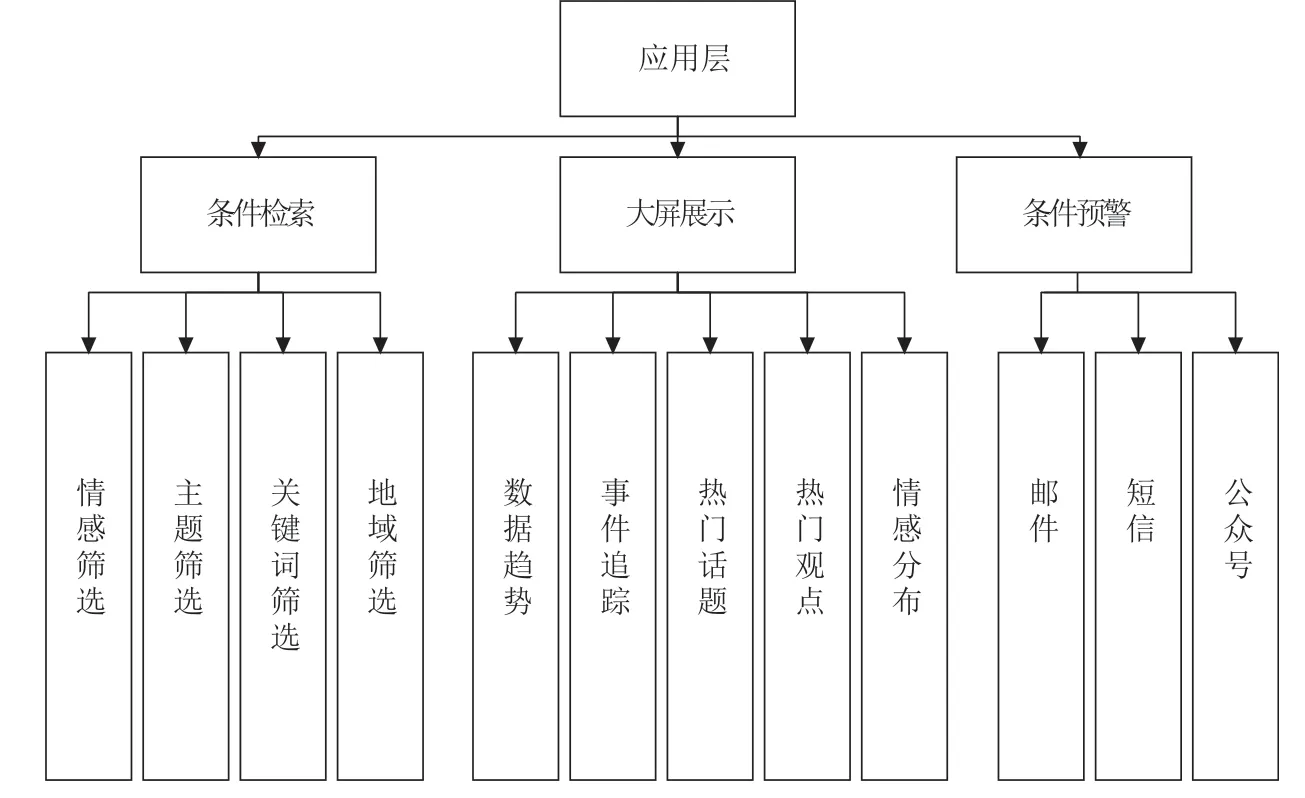
图2 网情系统应用层架构
2.4.1 条件检索与大屏展示
政务人员可根据情感、主题、关键词、地域等主题检索,获得自己关注的数据。ECharts的大屏展示技术能够为政务人员提供直观、可视化的网情监控手段,并能够显示每日实时采集的数据。聚合数据条件检索与指标展示大屏如图3所示。
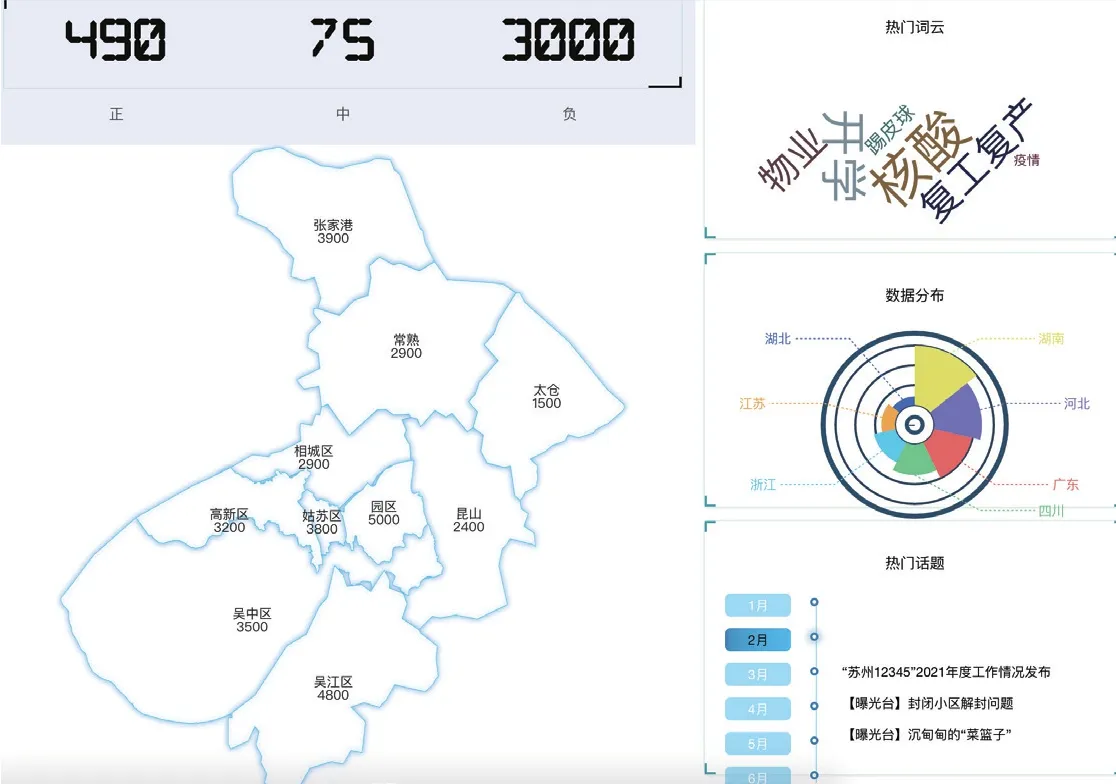
图3 聚合数据条件检索与指标展示大屏
2.4.2 条件预警
条件预警为政务人员感兴趣的主题和关键词,提供邮件、企业微信推送等衍生服务。系统根据用户配置的兴趣主题和感兴趣的关键词进行个性化的数据过滤。用户发布感兴趣的帖子,当帖子的转发、评论达到一定次数后,系统将进行多渠道预警。
3 结论
本研究利用分布式爬虫技术、大数据存储计算技术、AI自然语言处理技术、大屏展示技术,完成了用于辅助政务的网情监控系统的设计,并通过可视化的平台展示重要指标数据,为政务服务提供了一个直观的地域内网情数据的监控手段。后续本研究将进一步提升数据采集的时效性,利用更多的AI技术,更好的模型,充分挖掘数据的潜在价值。
