基于深度学习的生产建设项目扰动图斑自动识别分类
2023-01-12金平伟姜学兵杨胜权林丽萍罗志铖寇馨月
金平伟,黄 俊†,姜学兵,亢 庆,杨胜权,林丽萍,杨 平,罗志铖,李 乐,寇馨月,刘 斌
(1.珠江水利委员会珠江流域水土保持监测中心站, 510611, 广州;2.珠江水利委员会珠江水利科学研究院, 510611, 广州;3.贵州省水土保持科技示范园管理处, 550002, 贵阳)
水土保持信息化监管是水土保持工作的重要内容,是法律赋予水行政主管部门的重要职责,是遏制人为水土流失、保护生态环境的重要行政手段[1-2]。扰动图斑是生产建设项目信息化监管基础数据[3-4]。《生产建设项目水土保持信息化监管技术规定(试行)》明确:“扰动图斑”是具有明确地理信息、带有规定字段属性的空间矢量数据。《中国水土保持公报(2019)》表明:2019年全国生产建设项目信息化监管覆盖国土面积592万km2,共解译扰动图斑60.16万个。可见生产建设项目信息化监管工作任务十分繁重,特别是扰动图斑解译生产。目前扰动图斑解译生产仍以“传统人机交互目视解译”为主,其工作效率低、成果标准不统一,难以满足新时期新形势下水土保持信息化监管需求。突破扰动图斑解译生产的传统工作模式、实现扰动图斑解译生产自动化、批量化,是目前生产建设项目信息化监管中亟待解决的重要问题。
随着计算机科学技术快速发展,以卷积神经网络(convolutional neural network, CNN)为代表的深度学习模型快速发展,在遥感卫星图像分类、地物信息提取等地理信息领域得到广泛应用[5-7]。CNN通过多层卷积和池化逐层提取图像特征,具有权值共享、并行处理等优点,在满足网络层级深度要求的同时还能大幅降低并优化模型训练参数[8-9]。王鑫等[10]提出一种基于CNN和多核学习的高分辨率遥感影像分类方法,测试集准确率、Kappa系数分别达到了96.43%和96.25%。CNN模型也被应用与中国资源3号、高分1号和高分2号卫星遥感影像云检测和去除[11-12]。Yang等[13]构建一种基于CNN模型的中国高分1号遥感影像分类深度学习模型,土地利用分类总体精度达81.52%。马永建等[14]基于U- Net模型,利用中国高分1号遥感影像开展荒漠区耕地分类与提取,与传统的支持向量机、随机森林等机器学习相比,整体识别准确率提高4.67%。陈周等[15]利用WorldView影像,基于DeepLab- v3+模型开展城市绿地提取研究,整体精度达98.01%。胡乃勋等[16]利用我国高分2号遥感影像,基于CNN模型开展露天采场为主的开发占地信息提取,总体精度达91.85%,Kappa系数为0.90,显著高于传统的支持向量机分类方法。此外,以卷积神经网络为代表的深度学习模型在土壤有机质含量估算、农作物病虫害识别、农作物产品分类等领域也得到诸多应用[17-21]。
目前深度学习模型在边界规则、纹理特征明显地物信息分类、识别提取方面开展了大量研究,涉及影像特征更为复杂的生产建设项目扰动图斑识别分类研究成果仍较为鲜见。笔者基于深度学习原理,构建生产建设项目扰动图斑自动识别分类CNN模型,利用已知区域生产建设项目水土保持信息化监管成果数据对模型进行训练和应用效果检验,以期为生产建设项目扰动图斑自动识别分类、提取提供技术支撑。
1 材料与方法
1.1 试验材料及平台
本研究遥感影像数据源为中国高分卫星遥感影像1号,预处理后影像包含红绿蓝3波段,分辨率为2 m;扰动图斑矢量数据来源于2020年某省8个市(县、区)生产建设项目水土保持信息化监管成果数据。为减少正样本- 扰动区域、负样本- 非扰动区域数量比例不协调对模型训练的负面影响,将扰动样本比例较高的5个县(区)用于CNN模型训练,另外3个市(县)用于对模型应用效果检验。
试验平台配置为:Windows10 Professional;Intel(R) Core(TM) i7―8750H @2.20 GHz;GPU:NVIDIA Quadro P1000(4.0G);内存16 GB;Python 3.7.6®(64位);Tensorflow 2.2.0®。
1.2 样本集制作
扰动图斑解译生产第1步是要发现、识别遥感影像中生产建设项目扰动区域,这是深度学习模型图像识别分类任务,这也是本研究预期目标。采用遥感影像瓦片数据样本用于对CNN模型训练和应用效果检验。样本数据制作步骤如下:1)获取扰动图斑矢量文件,使用ArcGIS 10.2®“要素包络矩形转面”将扰动图斑矢量文件中各不规则图形转换为矩形,得到处理后扰动图斑矢量文件(记为“数据1”);2)利用“数据1”裁剪高分遥感影像,得到扰动样本瓦片数据;3)制作项目区渔网矢量数据(250 m×250 m),用“数据1”裁剪渔网矢量数据得到新的渔网矢量数据(记为“数据2”);4)利用“数据2”裁剪高分遥感影像,得到非扰动样本瓦片数据。将扰动样本瓦片数据和非扰动样本瓦片数据合并得到完整的样本数据集,上述各步骤可借助Python 3.7.6编程自动完成。图1和图2是部分扰动和非扰动样本数据实例。

图1 部分扰动样本数据Fig.1 Data of partial disturbed samples

图2 部分非扰动样本数据Fig.2 Data of partial un-disturbed samples
8个市(县、区)共制作获得2万8 054个样本数据,其中用于模型训练的5个市(县、区)样本总数为5 131个,用于模型应用效果检验的3个市(县)样本总数为2万2 923个(表1)。
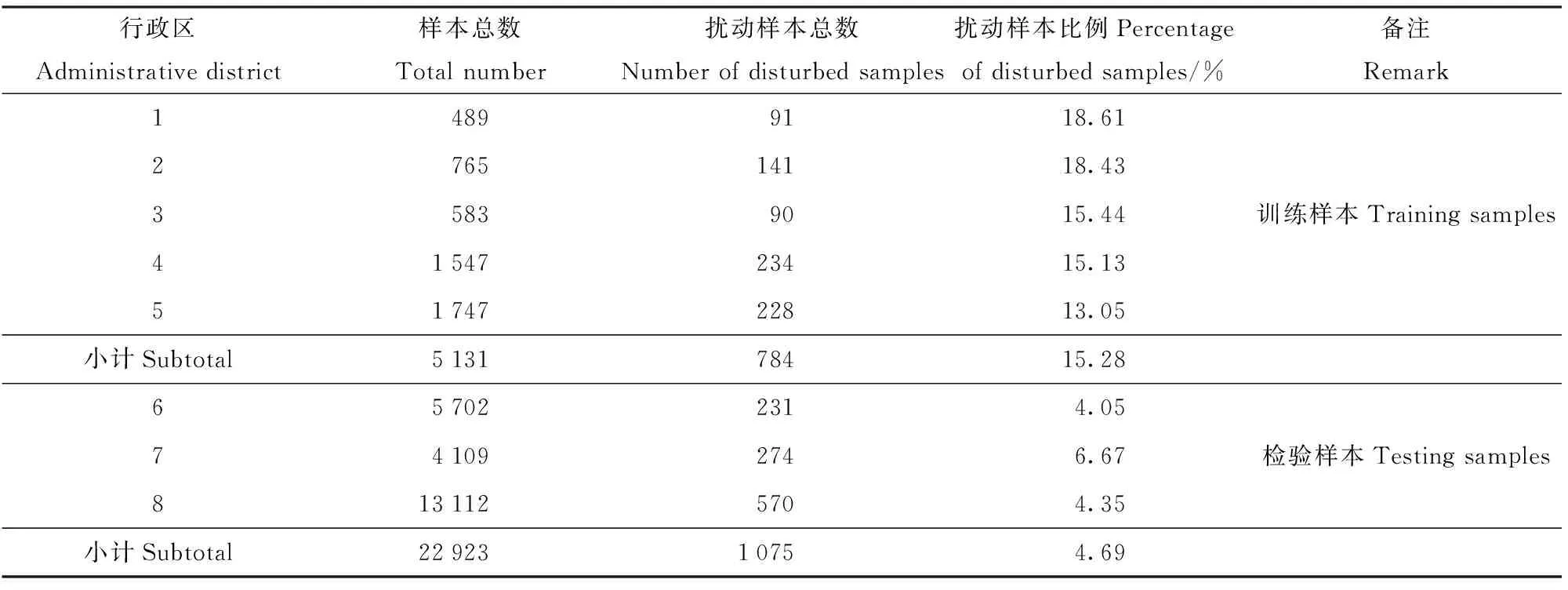
表1 深度学习模型训练和检验样本集
1.3 模型网络构建及参数设置
Caffe、Torch/Pytorch、TensorFlow、Theano、MXNet和1Paddle是目前深度学习广泛应用的主流开源框架。其中TensorFlow是Google Brain于2015年推出的开源机器学习库,能够兼容Scikit-learn接口,实现深度学习以外的机器学习算法。TensorFlow安装简单无需复杂的编译过程,且支持多GPU分布式训练,具有较强的跨平台运行能力,是目前深度学习领域使用最为广泛的开源框架之一。笔者基于Python 3.7.6语言环境,选择Tensorflow为深度学习框架。Sequential是Tensorflow最常用模型构建方法,适用于简单堆叠网络、易于调整网络结构和参数。参照经典深度学习模型VGG16网络架构,采用Sequential模型搭建深度学习模型网络结构,所构建的网络结构有16层,包括13个卷积层和3个全连接层。本研究属于图像识别二分类问题,采用“二分类交叉熵损失函数”表征和记录模型训练过程中的损失。上述深度学习模型网络借助Tensorflow 2.2.0的API库函数搭建完成,模型网络结构及各层参数详见图3。
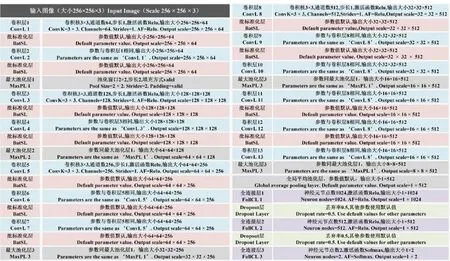
ConvL、BatSL、MaxPL、FullCL、ConvK和AF分别表示卷积层、批标准化层、最大池化层、全连接层、卷积核、激活函数。ConvL, BatSL, MaxPL, FullCL, ConvK and AF refers to convolutional layer, batch standardization layer, max pooling layer, fully connected layer, convolution kernel and activation function, respectively.图3 卷积神经网络深度学习模型网络结构及关键参数值Fig.3 Convolutional neural network deep learning model network structure and key parameter values
1.4 模型训练方案及评价指标
优化器算法、学习速率、激活函数及批大小等是影响CNN模型训练的关键超参数。常用优化器算法包括Adagrad、Adam、Adamax、Nadam和RMSprop等[22-24],Adagrad适用于离散稀疏数据图像分类问题;RMSprop适用于处理非平稳目标,可缓解梯度急速下降的问题;Adam可获得较为平稳的梯度变化过程,适合高维数据空间;Nadam强化对学习速率的约束。此外,学习速率和批大小也对深度学习模型产生重要影响。笔者利用“训练样本”分别研究上述5种优化器算法、6种学习速率(10-2、10-3、10-4、10-5和10-6)、4个批大小(2、4、8和16)对深度学习模型训练结果的影响。每1次训练轮次设置为50,固定分配80%“训练样本”用于模型训练,另外20%“训练样本”用于模型验证和模型综合性能评价指标计算。
模型综合性能评价指标包括模型精度(model accuracy,MA)和模型损失(model loss,ML),利用Tensorflow 2.2.0的API库函数model.evaluate计算得到,该函数用于检查模型是否最适合给定的问题和相应的数据。对比分析不同优化器算法、学习速率和批大小训练得到模型的MA和ML值,确定优化器算法、学习速率和批大小超参数最优值。
基于上述最优超参数值,将训练轮次增加到150次,最终完成模型训练和建立。模型“卷积层”、“全连接层1”和“全连接层2”激活函数均为Relu,该激活函数能有效抑制模型过拟合和避免梯度爆炸消失等问题;本研究属于多分类中最简单的二分类问题,因此“全连接层3”激活函数采用Softmax。
1.5 模型应用效果检验
利用“检验样本”对建立的深度学习模型进行应用效果检验,通过计算模型识别分类结果的整体准确率(overall accuracy,OA)、扰动样本查准率(precision rate of disturbance sample data,PR)、扰动样本查全率(recall rate of disturbance sample data,RR)和F1得分值(F1score,该值为PR和RR的调和平均数,其值越大表明模型泛化能力越强、精度越高)4个指标对模型应用效果进行定量评价,上述4个指标值越大越好。各指标计算公式如下:
OA=(TP+TN)/(TP+TN+FP+FN)×100%;
(1)
PR=TN/(TN+FP)×100%;
(2)
RR=TN/(TN+FN)×100%;
(3)
F1=2PRRR/(PR+RR)×100%。
(4)
式中:TP为实际为扰动样本,且模型识别为扰动样本(识别分类正确);TN为实际为非扰动样本,且模型识别为非扰动样本(识别分类正确);FP为实际为非扰动样本,但模型识别为扰动样本(识别分类错误);FN为实际为扰动样本,但模型识别为非扰动样本(识别分类错误)。
2 结果与分析
2.1 模型关键超参数最优值确定
在固定学习速率为10-5、批大小为16、训练轮次为50的条件下,使用“训练样本”分别完成5种优化器算法深度学习模型训练。图4为不同优化器算法模型训练及验证过程精度变化曲线。5种优化器算法模型训练耗时基本相当,平均耗时为(1.334±0.056) h。但不同优化器算法训练模型综合性能评价差异较大,其中Adagrad模型综合性能最优,其MA=0.898、ML=0.258;RMSprop模型综合性能最差;其余优化算法训练得到模型综合性能基本相当。除Adagrad优化器算法外,其余4个优化器算法训练得到的模型均存在不同程度过拟合现象,导致模型鲁棒性差、泛化能力不足,特别是Adam、Nadam和RMSprop优化器算法训练模型过拟合问题十分严重。
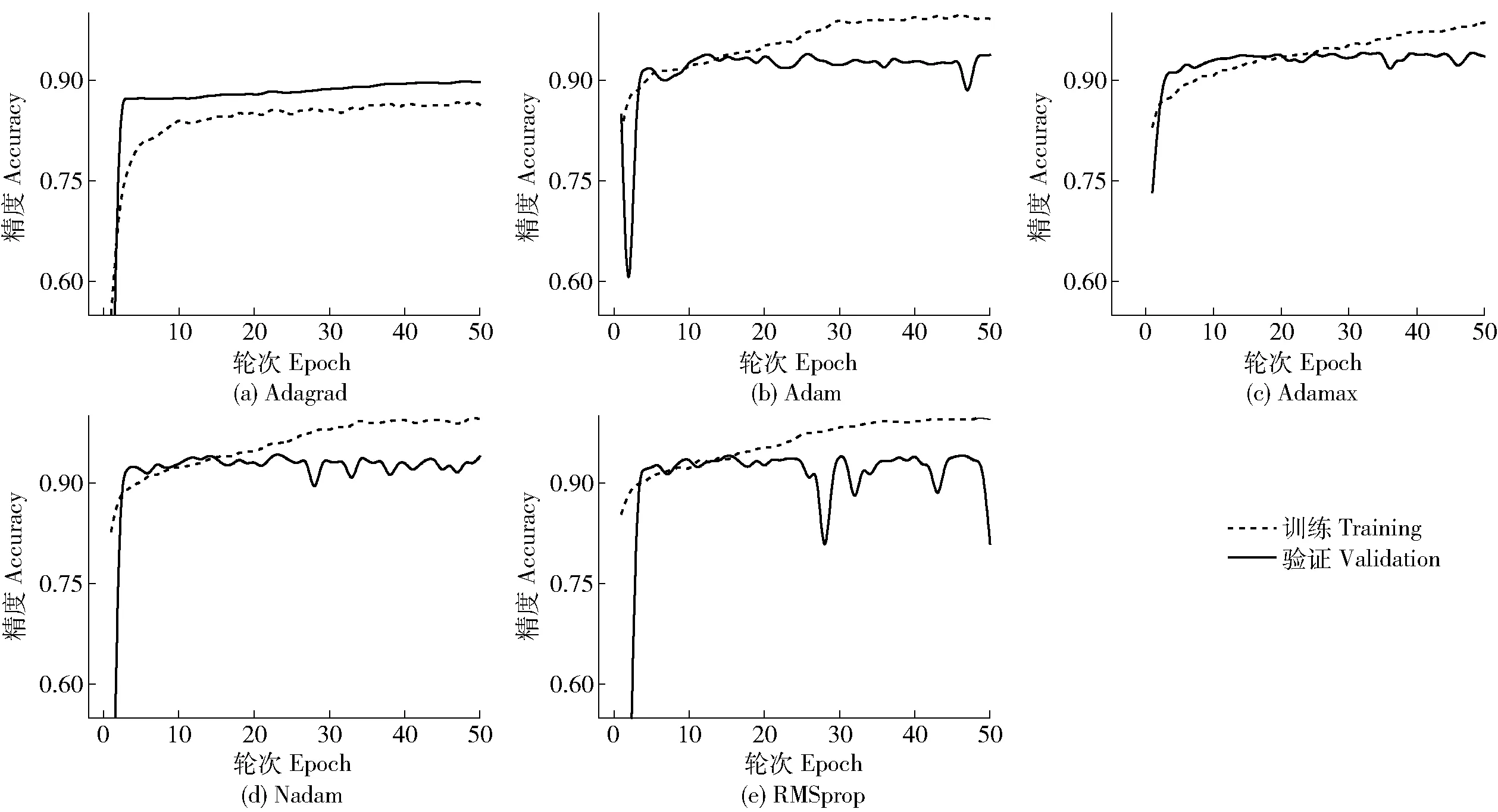
图4 不同优化器算法深度学习模型训练及验证精度变化曲线Fig.4 Training and validation accuracy curves of the deep learning model under different optimizer algorithms
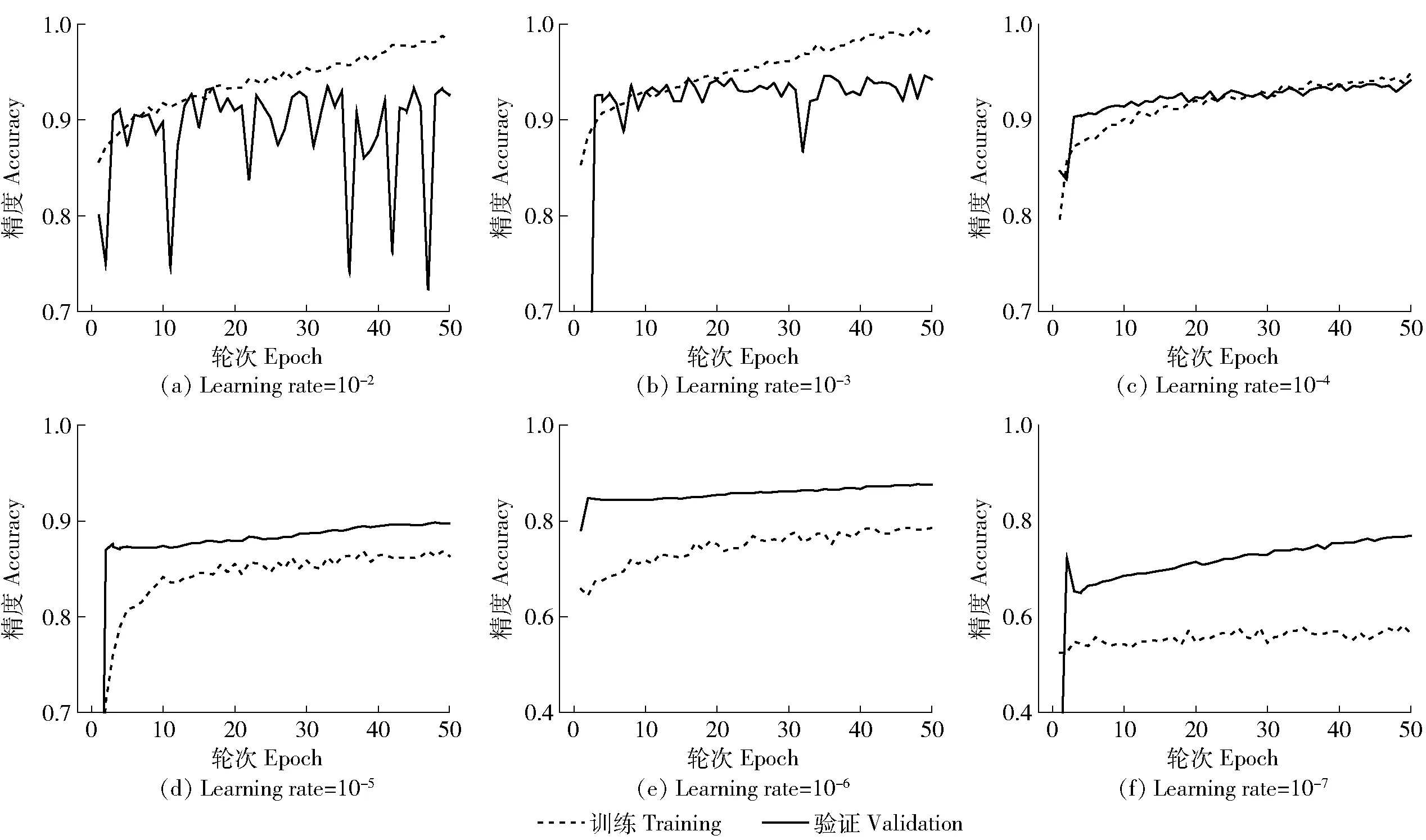
图5 不同学习速率深度学习模型训练及验证精度变化曲线Fig.5 Training and validation accuracy curves of the deep learning model under different learning rates
在固定优化器算法为Adagrad和批大小为16、训练轮次为50的条件下,使用“训练样本”分别完成6种学习速率深度学习模型训练。图5为不同学习速率模型训练及验证过程精度变化曲线。整体而言,随着学习速率降低,模型训练耗时逐渐增加,6个不同学习速率模型训练耗时平均为(1.217±0.027) h。当学习速率较大时(10-2和10-3),模型出现一定程度的损失函数爆炸,导致验证精度曲线大幅度震荡;当学习速率过小时(10-6和10-7),模型收敛速度过慢,训练轮次达到最大时模型训练和验证精度均相对较差,且出现明显的过拟合现象;只有当学习速率适中(10-4和10-5)模型过拟合现象得到抑制,且一定轮次后模型逐渐趋于收敛。本研究学习速率10-4为最优,训练和验证精度曲线十分接近,模型综合性能最优,其MA=0.942、ML=0.179。
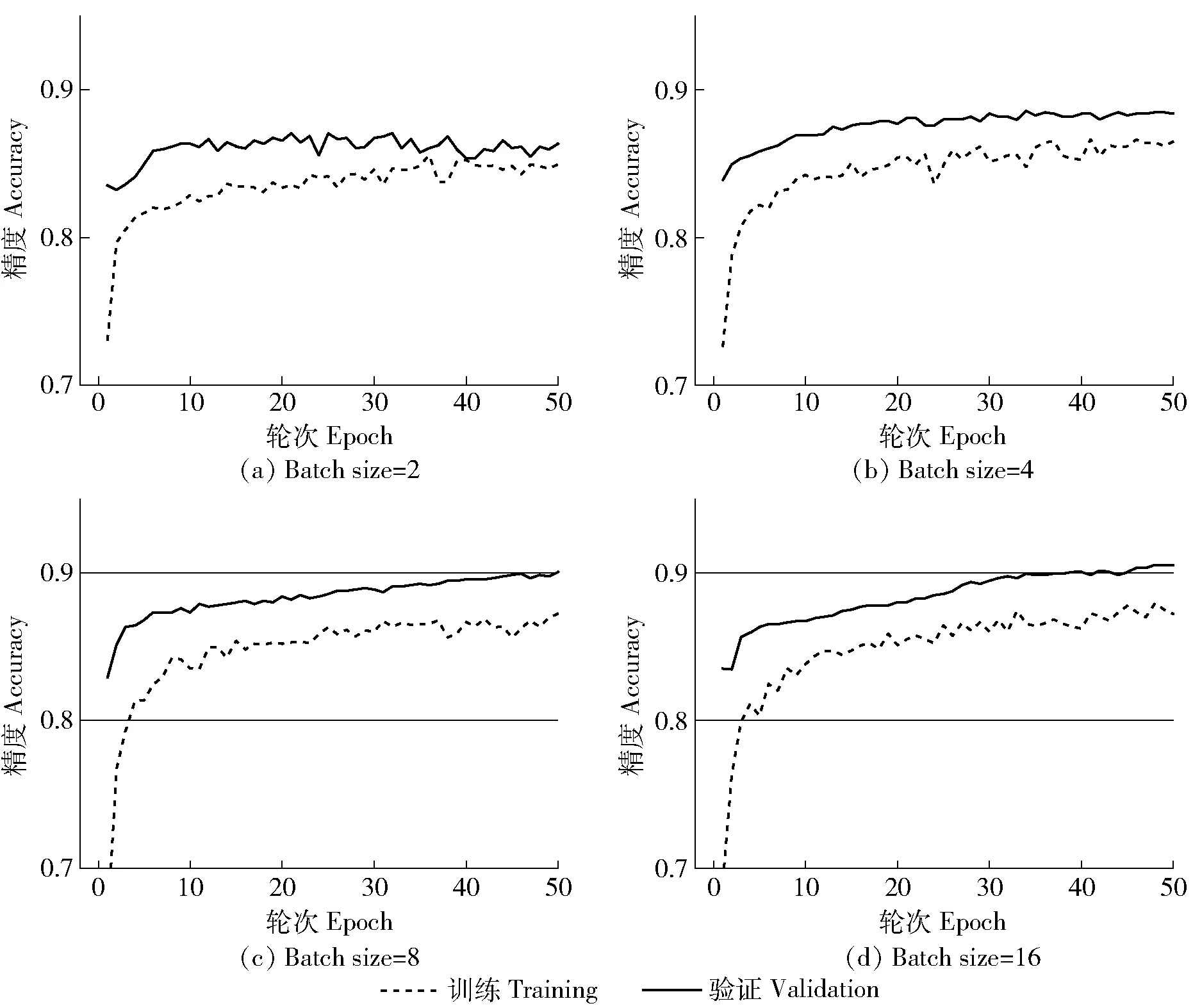
图6 不同批大小深度学习模型训练及验证精度变化曲线Fig.6 Training and validation accuracy curves of the deep learning model under different batch sizes
受计算平台性能限制,本研究批大小最大值为16。选择优化器算法为Adagrad、学习速率为10-4、训练轮次为50的条件下,使用“训练样本”分别完成4个批大小深度学习模型训练。图6为不同学习速率模型训练及验证过程精度变化曲线。批大小越大训练耗时越短,内存利用率越高、相同数据量处理速度更快、模型梯度下降方向越准确、模型训练精度损失曲线震荡越小。当批大小从2增加到16,模型训练耗时从1.992 h递减到1.237 h,训练模型综合性能也总体呈现逐渐增加变化趋势,MA值从0.864增加到0.898、ML值从0.362递减到0.258。
2.2 基于最优超参数的模型建立
由图5c可以看出,当优化器为Adagrad、学习速率为10-4、批大小为16、训练轮次为50条件下,模型训练和验证精度变化曲线仍呈现递增变化趋势。为了进一步增强模型鲁棒性、提升模型泛化能力,将训练轮次增加至150次,获得生产建设项目扰动图斑自动识别分类CNN模型。累积训练耗时4.632 h,模型综合性能评价指标MA和ML分别为0.952 6和0.167 0。图7为模型训练及验证过程精度、损失变化曲线,120个训练轮次后模型训练和验证精度损失变化逐渐趋于稳定,模型未出现过拟合或欠拟合问题,表现出较强的泛化能力和较高的鲁棒性。

图7 深度学习模型训练及测试精度变化曲线Fig.7 Training and validation accuracy curves of the deep learning model
2.3 模型应用效果检验
利用“检验样本”对模型应用效果检验(表2)。总体而言,模型在3个行政区应用效果较为理想,识别分类总体精度超过95.00%,平均为97.52%,其中“行政区6”样本数据识别分类总体精度最大为98.58%。扰动样本查准率和查全率是本研究重点关注内容,3个行政区扰动样本查准率均值为72.44%,但仍有不到30%的样本识别分类错误,错误来源主要是非扰动样本识别分类为扰动样本。“行政区6”扰动样本查准率最大为78.63%,而“行政区8”扰动样本查准率最小为68.25%。“行政区7”扰动样本查全率最低约为80%,另外2个行政区扰动样本查全率均超过83%,总体少于20%的扰动样本被模型漏判为非扰动样本。3个行政区识别分类F1得分值也较为理想,均超过75%。总体而言,利用CNN深度学习模型开展生产建设扰动图斑自动识别分类具有较强的可行性和实用性。

表2 模型应用效果检验结果
3 讨论
笔者基于深度学习开源框架Tensorflow,构建生产建设项目扰动图斑自动识别分类CNN模型,发现本研究深度学习模型优化器算法、学习速率和批大小3个超参数最优值分别为Adagrad、10-4和16。基于上述超参数最优值,训练得到最终的生产建设项目扰动图斑自动识别分类CNN模型,模型识别分类整体准确率超过95.00%。这说明CNN模型用于生产建设项目扰动图斑自动识别分类是实际可行的。单张遥感影像瓦片数据识别分类约耗时10 ms,结合扰动图斑自动矢量化技术,扰动图斑解译生产可实现自动化、批量化,将大大提工作效率。
与现有遥感影像地物信息识别提取中常用的语义分割模型相比,笔者参考VGG16经典深度学习模型,通过多层卷积神经网络提取扰动图斑在遥感影像特征值,构建生产建设项目扰动图斑自动识别分类CNN模型,用以实现扰动样本的自动识别分类,在样本集制作、模型搭建方面更为简单,且能够获得较为理想的识别分类效果。这在推广到实际应用中是有益的。
由于扰动图斑边界不规则、区域模糊、无明显建构筑物特征,且随着建设周期差异,相同区域扰动区域遥感影像特征也存在显著差异(图8);此外,部分非扰动区域影像特征与扰动区域影像特征十分相像(图9),导致本文所构建的生产建设项目扰动图斑自动识别分类CNN模型精度仍需进一步提升。今后在提升样本集制作质量的同时,还应开展不同遥感影像数据源、不同区域生产建设项目扰动图斑自动识别分类CNN模型的建模与验证。

图8 相同区域不同建设周期扰动区域影像特征Fig.8 Image characteristics of the samedisturbance area with different construction periods

图a、c、e和g均为扰动样本,b、d、f和h为非扰动样本。Figure a, c,e and g are all disturbed samples, and b,d,f and h are un-disturbed samples.图9 误判为扰动区域样本影像特征与扰动区域影像特征对比图Fig.9 Image features comparison betweendisturbance sample and un-disturbance samples misjudged as the disturbance sample
4 结论
利用已知区域水土保持生产建设项目信息化监管成果数据,基于卷积神经网络深度学习原理,构建生产建设项目扰动图斑自动识别分类CNN模型。1)通过多层卷积神经网络挖掘扰动图斑遥感图像特征,实现对遥感影像瓦片数据的扰动和非扰动区域自动识别分类;2)模型应用效果表明识别分类整体准确率超过95.00%,扰动图斑查准率和查全率均值达到72.00%和83.00%,这表明CNN模型用于生产建设项目扰动图斑自动识别分类是实际可行的。
