基于关系模式与深度强化学习的DS数据去噪模型*
2023-01-12牙珊珊陈定甲郑宏春
牙珊珊,陈定甲,郑宏春,李 航,覃 晓
(1.南宁师范大学,广西人机交互与智能决策重点实验室,广西南宁 530100;2.广西民族大学人工智能学院,广西南宁 530006)
在文本分类[1]任务中,高精度的关系分类算法是信息分类以及智能问答等任务的关键。基于深度学习的实体关系分类算法,如CNN[2]、RNN[3]、BILSTM[4]和ATT+BILSTM[5]在对文本数据的处理中展现了较好的分类效果,然而使用上述神经网络算法[6,7]解决关系分类问题需要大量的标签数据才能保证模型得到有效的训练。
关系抽取中常用的数据集包括SemEval、Wiki80、FewRel[8]、NYT10等,SemEval、Wiki80和FewRel都是由人工精细标注的数据集,而NYT10数据集是通过远程监督得到的。使用远程监督(Distant Supervision,DS)算法[9,10]可以自动标注数据,极大地降低获取大量标签数据的成本,因而利用DS算法来构建关系分类训练数据集,是目前常用的标注数据集构建方法,而使用DS算法构建的数据集,称为DS数据集。
在DS算法中,对于一个给定的三元组(实体,关系,实体),若在外部文档库的句子中检测出这对实体,则将句子定义为这种关系,否则将关系标注为‘none’。这样的标注方法,使得获取的标注数据集存在大量的噪声数据。如何去除DS数据集的噪声,为文本关系分类模型的训练提供更科学有效的数据集,已经成为文本关系分类领域普遍关注的问题。Zeng等[11]使用卷积DNN算法将神经网络应用于关系分类中,取得了不错的效果;此后,Zeng等[12]提出了利用PCNN+多示例学习(MIL)的方法用于远程监督的实体抽取任务,为远程监督的噪声问题提供了一个很好的解决方案;Ji等[13]对Zeng等[12]的方法进行了优化并提出APCNNs模型,在训练数据中加入了实体的描述信息,从而使实体关系分类效果有了很大提升;Lin等[14]提出了一种基于句子级注意力的卷积神经网络(PCNN+ATT)用于远程监督关系抽取,进一步提高了实体关系分类效果。尽管在许多情况下前述方法是简单且有效的,但是当一个实体对中的句子都是假阳性时,这些方法获得的标注数据仍是噪声数据。因此,Qin等[15]提出将远程监督数据集分成正样例集和负样例集,引入一种基于策略的强化学习方法来去除DS数据集中的噪声。但上述方法并没有考虑DS数据集中的正样例数据(Positive Data,PD)和负样例数据(Negative Data,ND)的均衡问题,也没有充分利用DS数据集中负样例集对训练去噪模型的贡献,导致去噪效果仍达不到目标。
针对上述问题,本研究构建了一种新型的DS数据集去噪模型——Positive Reinforcement Learning Model (PRL模型)。首先,利用基于关系模式的正样例抽取算法(Pattern_Based Data Extraction Agorithm,PDEA)剔除正样例集中的假正例,获得一个高质量的正样例数据集;然后,使用高质量的正样例数据集辅助抽取高质量的负样例数据集,并利用Focal Loss替代传统交叉熵解决分类过程中正负样例数据不平衡的问题,从而得到高质量的负样例数据集;最后,用深度强化学习的方法进一步去噪,得到更纯净的远程监督数据集,同时通过实验验证模型的有效性。
1 相关工作
1.1 远程监督(DS)算法
使用远程监督算法可以快速且轻松地获取大量的带标签数据。远程监督算法可以基于一个标注好的小型知识图谱[16],给外部文档库中的句子标注关系标签,相当于做了样本的自动标注,因此是一种半监督的算法。然而DS算法的自动标注不能真实涵盖实际句子的所有关系,因而在对实际文档的句子进行关系标注时,容易出现错误标注的情况,导致数据集中存在着大量的噪声。
如图1所示,知识库中已有三元组(中国,首都,北京),根据远程监督自动标注原则,外部文档的句子中若出现“中国”“北京”两个实体,则认为该句子所表达的是首都的关系,表示这种句子的关系类型都为首都。然而,在这样的弱假设下进行实体类型标注会带来大量的错误数据,例如在某些句子中,“中国”“北京”两个实体间不一定是首都的关系,可能是方位的关系,如句子“北京在中国的北方”。因此,对DS数据集进行去噪,提取纯度更高的数据集,更有利于关系分类模型的训练。
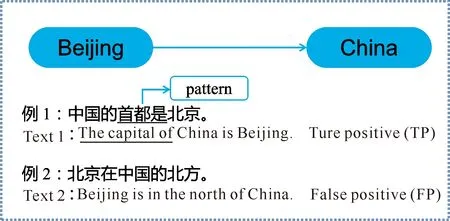
图1 三元组实例Fig.1 Example of triples
1.2 强化学习
强化学习(Reinforcement Learning,RL)是机器学习的方法之一,其特征为在机器学习的过程中,通过交互的方式取得更好的学习效果。强化学习方法常常被用于解决远程监督中的噪声数据问题,Feng等[17]在示例选择器中使用强化学习方法选择高质量的句子并将其输入到关系分类器中,关系分类器则进行分类预测并将结果返回给示例选择器,这两个模块联合训练可以降低远程监督关系抽取中的噪声数据问题;Zeng等[18]应用强化学习方法,把关系抽取器看作是强化学习智能体,目标是获得更高的长期奖励,以此来解决远程监督中的噪声数据问题。Qin等[15]基于强化学习提出了一种新的去噪方法,即通过动态选择策略(Dynamic selection strategy)来增强远程监督关系抽取,通过预训练策略训练一小部分标签数据,用于加速强化学习的训练;之后使用深度强化学习智能体用于学习,使得每一个智能体都具有识别相应关系类型中的错误标注样例的能力,利用这些智能体作为分类器来选择是否删除或保留远程监督的候选实例,从而获得较好的降噪效果。
上述强化学习方法(图2)均使用交叉熵作为最终分类的损失函数。由于DS数据集天然带有大量的噪声数据,正负样例比例极度不均衡,而交叉熵函数采用类间竞争机制,只关心正确标签预测的准确性,而忽略了其他非正确标签的差异。在使用交叉熵作为损失函数时无法拟合其数据分布,从而导致最终的分类错误。因而用带有噪声数据的样本不平衡数据集训练的RL模型,性能并不可靠。
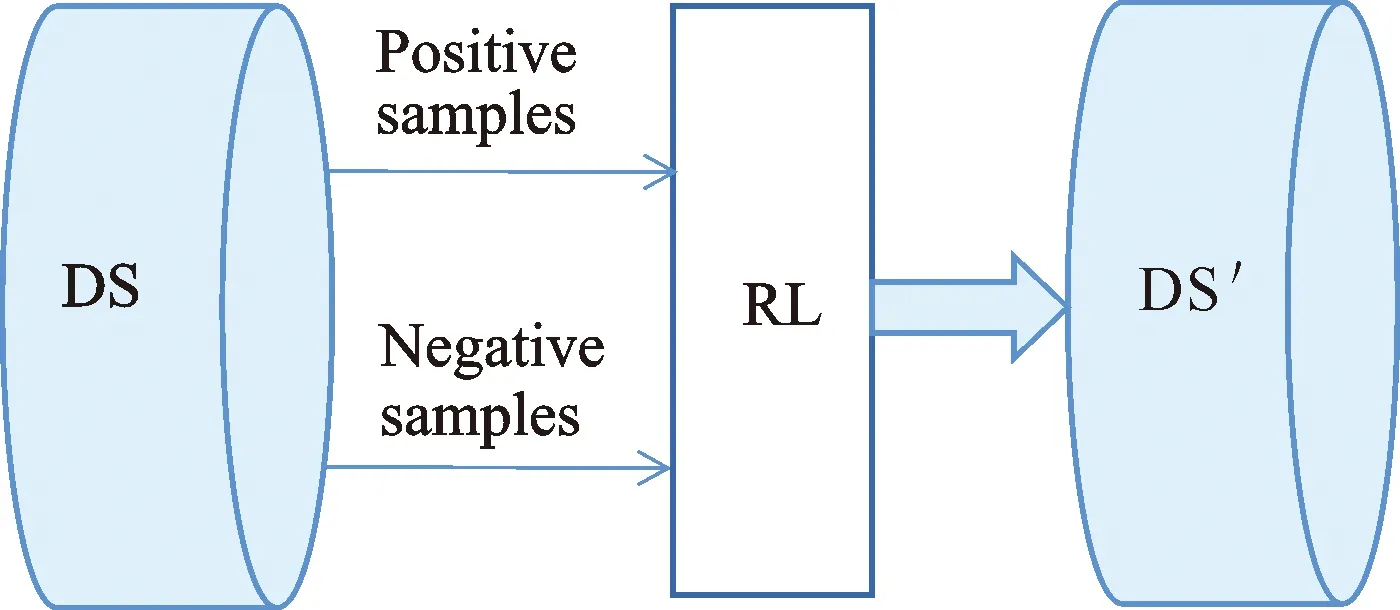
图2 RL模型架构图Fig.2 RL model architecture diagram
1.3 关系模式
关系模式(pattern) 最早由Hearst等[19]提出,表示两个实体之间的文本。Jia等[20]提出关系模式是远程监督中鉴别噪声数据的关键。如图3中句子“Bill Lockyer was born in California”和 “Bill Lockyer is an attorney general of California”都包含两个实体“Bill Lockyer”和“California”,知识库中所有的关系是 place_of_birth (出生地),两个句子的关系模式分别是“Was born in (出生于,与关系标签语义相同)”和“Is an attorney general of (是司法部部长,与关系标签截然不同)”,可知第一个句子的实体关系能够正确地打上标签,而第二个句子的实体关系则被打上错误的标签。可见在判断句子标签是否正确时,其中的关系模式起到关键的作用。利用关系模式,可以更好地识别标注正确的关系数据。在本研究的算法模型中,将利用关系模式提取DS数据集中的高质量标注数据。
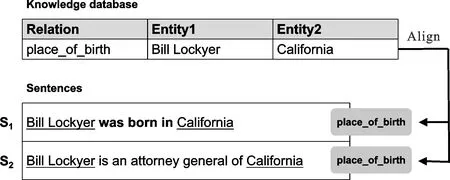
图3 两个关系的实例Fig.3 Example of two relations
2 基于关系模式的DS数据集去噪模型
Qin等[15]简单地将DS数据集中的有标签数据和无标签数据,分别当作正样例和负样例来训练RL分类模型。如前所述,在DS数据集中,使用自动标注方法不可避免地存在许多噪声,而噪声数据是导致深度强化学习方法不能很好地提取DS数据集中的正确标注数据的关键。为此,本研究提出基于关系模式的DS数据集去噪模型(PRL模型),如图4所示。
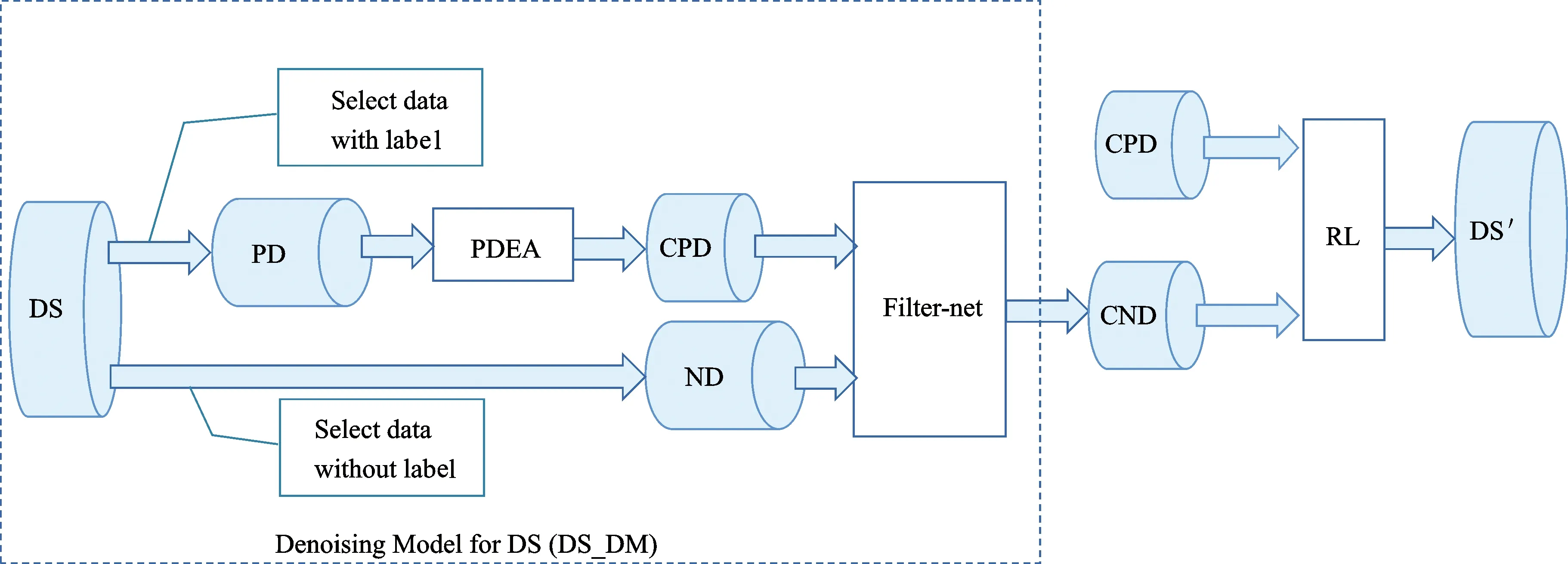
图4 PRL模型Fig.4 PRL model
PRL模型分为两个部分,前半部分是DS数据集预处理模型(Denoising Model for DS,DS-DM),后半部分是深度强化学习(RL)模型。
前半部分DS-DM的功能主要是使用本研究提出的基于关系模式的正样例抽取算法PDEA对DS数据集进行筛选,找出其中的高质量的正样例数据集(Confident Positive Data,CPD),之后再使用优化后的卷积神经网络Filter-net筛选出高质量的负样例数据集(Confident Negative Data,CND)。
后半部分是将前半部分处理后得到的高质量的正样例数据集和高质量的负样例数据集作为新的远程监督数据集,再使用深度强化学习方法进一步去噪,最终得到一个更纯净的远程监督数据集DS′。
2.1 基于关系模式的正样例抽取算法
关系模式是存在于句子实体间的一个词或词组。如果句子的关系模式多次重复出现,那么该关系模式能够更准确地表现句子的关系。PDEA正是要借助高频出现的关系模式,从DS正样例中挑选出高质量的正样例。
定义1(正样例数据集):DS数据集中标签不为‘none’的数据集合。记为
PD={si,tj|si∈DS,tj∈标签,ti≠′none′,
i∈(1,…,n),j∈(1,…,m)},
(1)
式(1)中,si表示DS数据集中的第i个句子,tj表示DS数据集中的第j种关系标签,n为DS数据集中的句子个数,m为DS数据集中的标签数。
定义2(高质量的正样例集):由含有高频关系模式的正样例数据组成的集合,记为
CPD={(ci,pj)Ppatterni|i∈(1,…,pn),j∈(1,…,m),Ppatterni>r},
(2)

PDEA如算法1所示。对于DS数据集中的正样例集的任意一个句子si,抽取其关系模式,记为mi,若mi首次出现(在模式集M中不存在),则将其存入模式集中,否则mi的计数加一。如果mi的频数大于指定的阈值,则将mi记为一个高频模式,而含有高频关系模式的句子构成高质量的正样例数据集CPD。
算法1:PDEA
Input:DS数据集D={PD,ND},阈值γ
Output:高质量的正样例数据集CPD
1. forsi∈PD do:
2. Extract words between two entities as a patternmi
3. ifminot inM:
4. Add tuple (mi:1) intoM
5. else:
6.M[mi]=+1
7. End for
8. formi∈Mdo
9. ifM[mi]>=γ:
10. AddmiintoMhigh
11. selectMhighfrom PD to CPD
12. return CPD
2.2 卷积神经网络Filter-net
利用PDEA获取到的高质量的正样例数据集,加上DS数据集中的负样例,作为卷积神经网络Filter-net的训练数据集,训练Filter-net筛选出高质量的负样例数据集。图5即是本研究提出的Filter-net模型,采用CNN为基础网络。
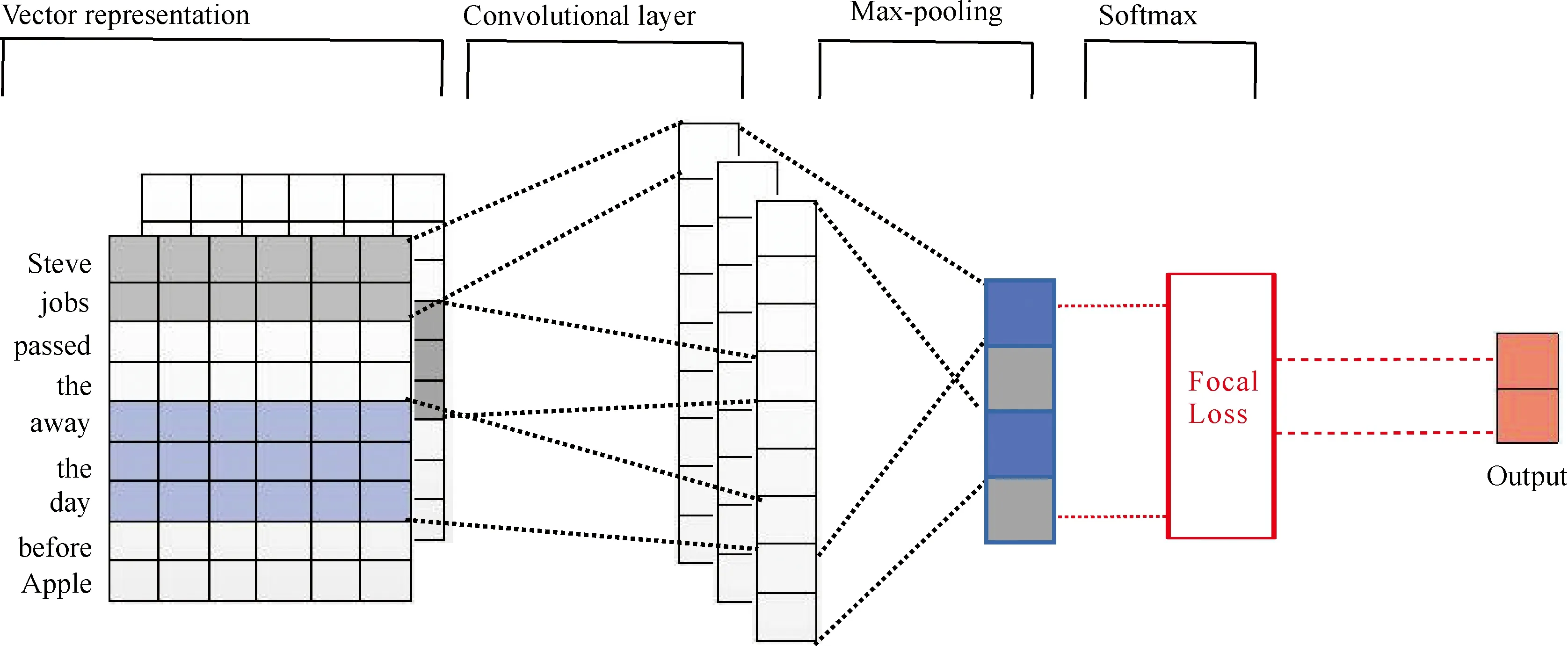
图5 Filter-net的网络架构Fig.5 Network architecture of Filter-net
由于DS数据集本身所含有的负样例数据量非常大,而经过PDEA筛选得到的高质量正样例数据量比较少,这就导致如果在卷积神经网络中使用传统交叉熵作为损失函数时很容易产生数据不均衡现象,进而导致分类错误。
为解决这一问题,本研究在卷积神经网络中使用Focal Loss作为损失函数。具体公式如下:
FL(Pt)=-(1-Pt)γlogPt,
(3)
式(3)中,Pt为数据x标注为标签y的分类概率,γ为缩放因子。
Focal Loss在传统交叉熵的基础上加入了调节因子(1-Pt)。当对负样例分类时,因为负样例数量大,Pt的值趋向于1,调节因子(1-Pt)趋近于0,则负样例的损失就会增大,从而抑制对负样例的分类操作。当模型对正样例分类时,由于正样本数量较少,Pt的值趋向于0,(1-Pt)趋向于1,整体损失值不变,因而不影响正样例分类效果。简单地说,Focal Loss调节因子(1-Pt)能有效解决训练数据不均衡问题。
Filter-net的整体算法如算法2所示,把DS数据集的正负样例数据Dij输入到网络中,先经过矢量表示法(Vector representations)将Dij集合转化为更低维度的词向量x′,这个步骤在算法中设为VP(x)。对词向量同时进行三层卷积,网络会把三层卷积的结果拼接成新的特征向量x″,特征向量x″代入损失函数Focal Loss计算,最终得到对应的预测标签y(Dij)。
算法2:Filter-net算法
Input:CPD,ND
Output:预测标签y(Dij)
1.x′=VP(Dij)
2.x3=Conv_3×k(x′)
3.x4=Conv_4×k(x′)
4.x5=Conv_5×k(x′)
5.x″=cat(x3,x4,x5)
6.P(Dij)=soft maxfocalloss(x″)
Returny(Dij)
在预测标签y(Dij)中,标签为0的表示负样例,标签为1的表示正样例,标签为0的负样例集合即为高质量的负样例数据集CND。
最后将由DS-DM模型获得的新的远程监督数据集(包括CND和CPD)作为深度强化学习方法的训练数据,并最终得到一个高质量的远程监督数据集DS′。
3 验证实验
3.1 数据集
本研究采用的DS数据集是NYT10数据集,它是通过将来自freebase的实体对与纽约时报语料库对齐而生成的,训练集是由2005年和2006年的文本数据对齐生成,测试集是2007年的。该数据集共包含52种事实关系和1种特殊关系NA(表示头部实体和尾部实体间不存在任何关系),有694 491个句子实例,在远程监督关系抽取任务中通常用此数据集作为实验数据。本研究将此数据集定义为原始数据集(origin_data),同时使用Qin等[15]通过深度强化学习方法获得新的数据集,定义为强化学习数据集(RL_data)。
本研究对训练集和测试集做了处理。为使得模型更关注数据集的实体关系,本研究删除了测试集和训练集中有相同实体对的句子,再经过PRL模型处理得到了新的数据集PRL_data(即高质量的远程监督数据集DS′),其中训练集570 088个,测试集172 448个。表1表示其中10种关系类型在数据集中的统计数据。

表1 数据集的统计数据Table 1 Statistics of datasets
表2表示这10种关系类型中抽取的高频关系模式,含有这类高频关系模式的句子构成了高质量的正样例数据集。

表2 高频关系模式Table 2 High frequency patterns
3.2 模型验证
本研究采用了在远程监督数据集中最常用且效果较好的3个模型对原始的NYT10数据集(origin_data)、使用强化学习方法处理后的NYT10数据集(RL_data)以及经过本研究提出的PRL模型处理后的数据集(PRL_data)进行关系分类,以分类效果来验证去噪情况。
PCNN+ONE:Zeng等[12]提出的,结合示例学习的方法,在CNN中将卷积结果分成三部分,并且分段返回每一次池化的最大值来提取更多的关系特征。
CNN+ATT:Lin等[14]提出的,使用CNN来嵌入句子语义获得输入实体对的相对位置,通过注意力机制对新的句子进行加权处理,可以降低噪声数据的权重。
PCNN+ATT:Lin等[14]提出的,使用注意力机制来代替多实例学习。
为了更系统地评估模型的分类性能,本研究使用精确率(Precision)和召回率(Recall)作为评估指标。计算公式如下:
(4)
(5)
式(4)和(5)中,TP表示模型中被正确分类的正样例数量,FP表示模型中的假正例数量,FN表示模型中的假负例数量。
3.3 PR曲线
从图6-8的结果可以看出,将经过本研究所提出的PRL模型处理后的PRL_data数据集用于对远程监督关系抽取的各类模型,模型的性能均有所提升,证明本研究提出的去噪模型对关系抽取是有益的。
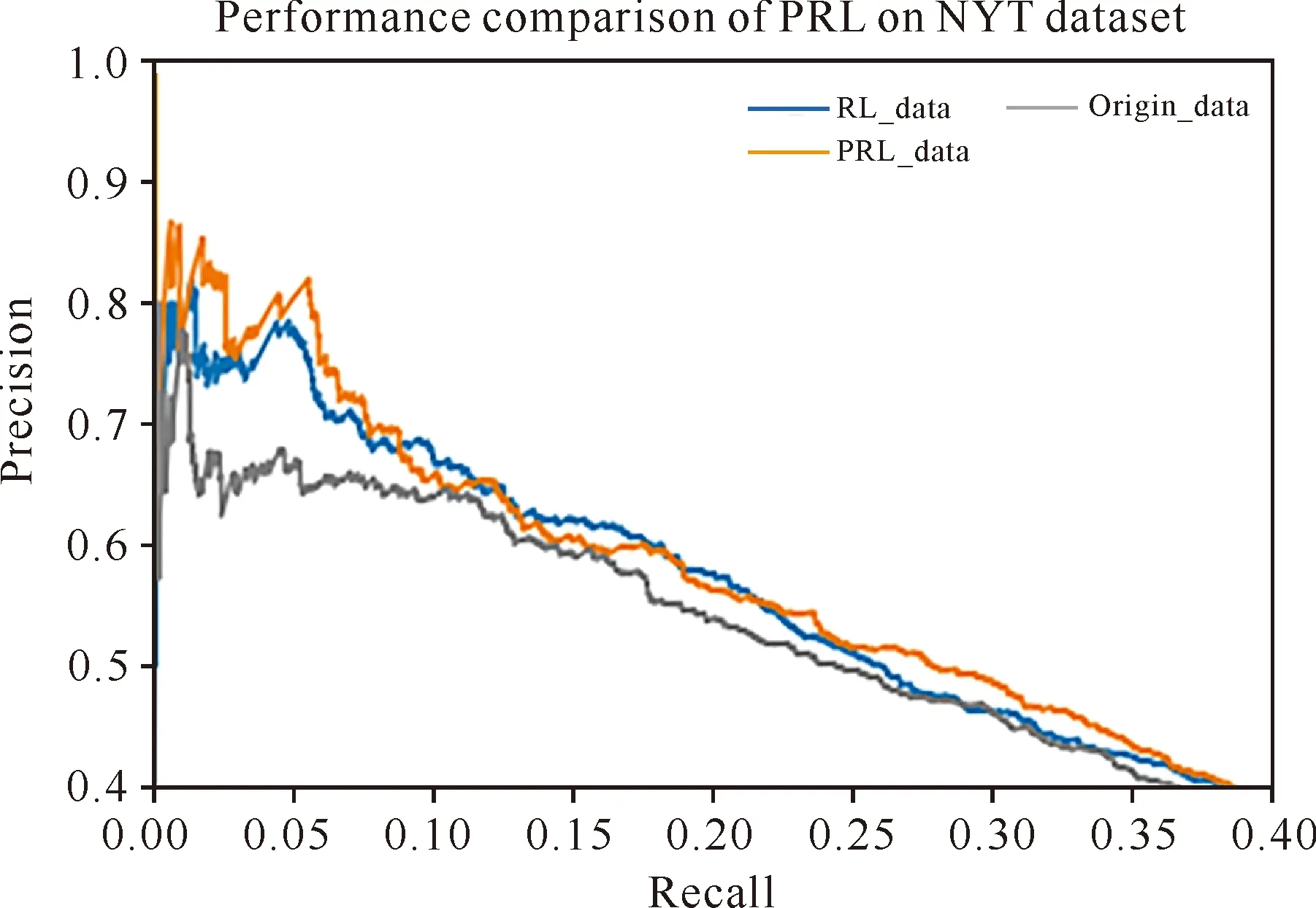
图6 3种数据集在PCNN+ONE模型中的PR曲线对比Fig.6 Comparison of PR curves of three datasets in PCNN+ONE model
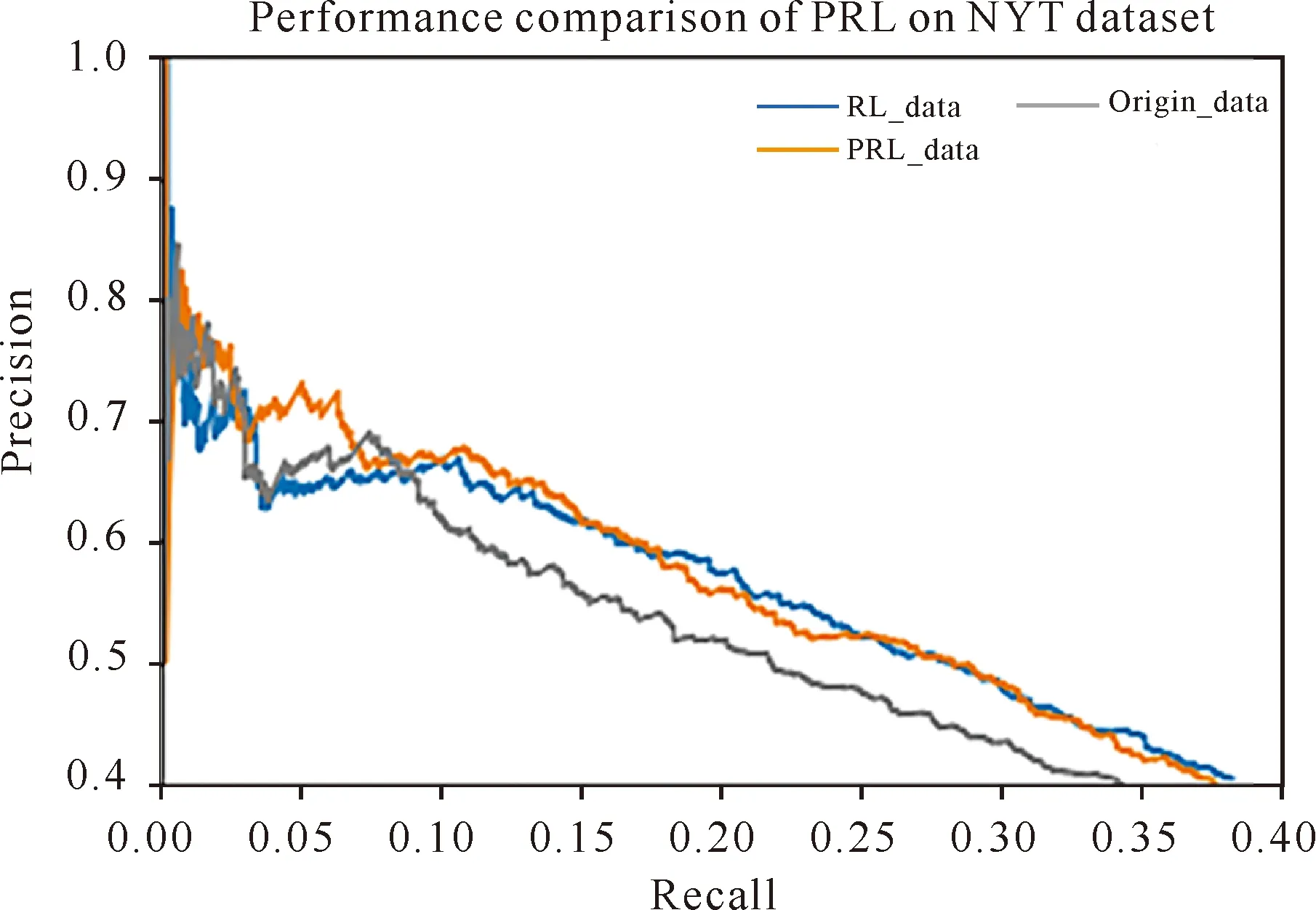
图7 3种数据集在CNN+ATT模型中的PR曲线对比Fig.7 Comparison of PR curves of three datasets in CNN+ATT model
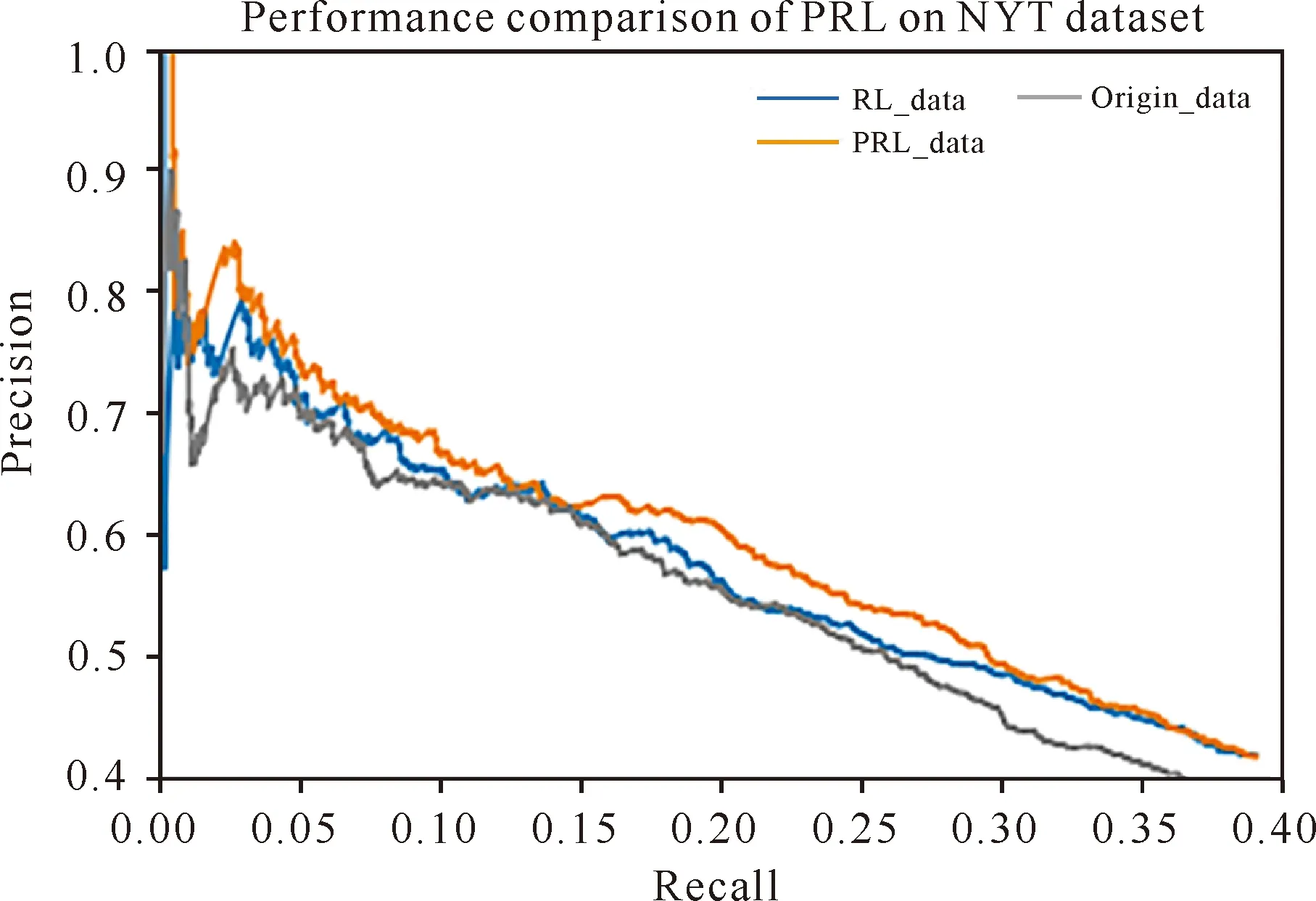
图8 3种数据集在PCNN+ATT模型中的PR曲线对比Fig.8 Comparison of PR curves of three datasets in PCNN+ATT model
3.4 AUC值
为了给出更直观的比较,本研究计算了每条PR曲线的AUC值,它表示这些曲线下的面积大小,模型的分类性能是否有提升主要看AUC值是否有增长。表3结果显示,使用PRL模型去噪后的远程监督数据集PRL-data作为关系抽取模型的训练数据集,与使用深度强化学习方法获得的数据集RL_data和原始数据集origin_data相比,其能明显提升关系抽取的各种模型性能,证明本研究方法是有效的。
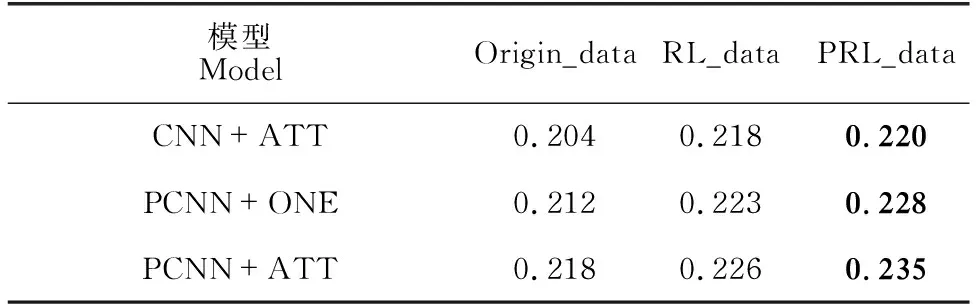
表3 实验结果Table 3 Experimental results
4 结论
本研究中提出的PRL模型是一种DS数据集预处理模型,可以对远程监督数据集进一步去噪。模型首先利用PDEA从远程监督数据集的标签数据中提取高质量的正样例数据集;然后利用DS数据集中正样例特征对负样例的指导作用来获取高质量的负样例集,其中用Focal Loss代替传统交叉熵解决正负样例数据不均衡问题;最后使用深度强化学习方法对DS数据集再一次进行去噪,并最终获得一个高质量的远程监督数据集。此外,选用在远程监督关系抽取研究中最具代表性的NYT10数据集,通过本文的PRL模型处理后,用于PCNN+ONE、CNN+ATT、PCNN+ATT 3种关系分类模型的训练来进行关系分类准确度验证,结果表明将经PRL模型处理后的DS′数据集用于对远程监督关系抽取的各类模型,各模型的性能均有所提升。PRL模型是一种轻量的数据去噪模型,对基于深度神经网络的模型如CNN+ATT、PCNN、PCNN+MIL、PCNN+ATT等都能带来性能上的提升。
目前,研究只是单纯地使用高频的关系模式来获取高质量的关系模式集,这种方法虽然有效,但是也会遗漏部分高质量的关系模式,有些关系模式虽然频次低,但是和高频关系模式有着极高的语义相似性,单纯的计数会让人忽略这些低频关系模式,将来可研究更好的关系模式提取器,以获取更高质量的数据来训练模型。
