基于改进的YOLOv3和Facenet的无人机影像人脸识别*
2023-01-11高锦风陈玉魏永明李剑南
高锦风,陈玉,魏永明†,李剑南
(1 中国科学院空天信息创新研究院, 北京 100094; 2 中国科学院大学, 北京 100049)
人脸识别作为一种重要的非接触身份获取技术,在安检安防、用户认证、疑犯追踪以及电子商务等多领域具有重要意义[1]。当前对于人脸识别的研究已相对成熟,但大多是基于固定摄像头采集的静态图片。在无人机嫌疑人员实时跟踪这样的动态场景中由于受无人机飞行高度调整、角度变换等的影响,识别精度被大幅度降低。随着无人机的迅速发展,无人机因其小巧易控在工农业及军事领域得到广泛使用,基于无人机平台的人脸识别研究具有重要意义。
人脸识别过程由人脸检测和人脸匹配[2]两个阶段构成。人脸检测就是通过一些基于统计或者知识的方法预测人脸是否存在并定位人脸位置;人脸匹配是通过一对一或者一对多地对检测出的人脸进行判定[3]。当前人脸识别的方法主要有基于人脸整体的识别方法和基于人脸部件的特征分析方法[4]。近几年,随着软硬件技术的快速发展,深度学习已经成为基于整体人脸识别方法中炙手可热的选择。深度学习卷积神经网络通过多卷积层自动学习人脸整体特征,不仅实现人脸的自动检测以及识别,而且受专家经验影响小,精度以及检测速度都可以很好地支持实际应用。
当前深度学习目标检测主流的网络可分为单步式基于回归网络和两步式基于候选区域的网络。其中两步式网络以Fast-RCNN[5]、Faster-RCNN[6]、Mask-RCNN[7]等典型网络为代表;单步式网络以经典的YOLO[8-10](you only look once)系列为代表。单步式网络由于将整个检测过程视为回归问题而大大缩短了检测时间。虽然精度相对于两步式网络有所下降,但实时性更强,精度也足以满足实际应用需要。YOLOv3[10]是YOLO系列中广泛使用的网络,高刘雅等[11]在YOLOv3的基础上提出轻量级注意力机制的网络实现了人脸的准确检测,准确率达到94.08%。潘浩然[12]通过改进YOLOv3的损失函数改善YOLOv3的错检漏检问题,实现了人脸的高精度检测。Facenet[13]是如今主流的人脸识别算法,通过在欧式空间中对比人脸特征之间的距离来判定二者之间的相似度以完成人脸匹配。Facenet与MTCNN[14](multi-task convolutional neural network)的结合使用是经典的人脸识别组合。刘长伟[15]利用MTCNN结合Facenet进行人脸识别,在LFW(labled faces in the wild)数据集上实现了99%的准确率。李林峰等[16]结合MTCNN和Facenet设计实现了人脸识别考勤系统。这些研究主要识别静态正面人脸,能较好发挥MTCNN关键点检测的优势。对于本文的无人机应用场景,MTCNN受无人机的拍摄角度影响很难发挥正脸检测的优势,YOLOv3基于回归的检测方式能更好应对这种应用场景。但YOLOv3存在的低召回率以及边框位置回归不准的问题[11-12]仍有待进一步改进。
本文采取改进后的YOLOv3进行人脸检测,检测结果经过人脸对齐后以160×160大小输入Facenet网络中进行人脸匹配。研究针对YOLOv3漏检以及预测框定位精度差的问题,对YOLOv3的特征提取网络以及损失函数进行改进。同时还对基于Widerface[17]数据集以及自制数据集进行了改进前后模型的训练和测试,通过与MTCNN算法进行对比从而验证改进模型的有效性以及准确性。
1 数据集
Widerface[17]是人脸识别研究中最常用的开源人脸基准数据集,其中涉及61个事件类别。对于每个事件类别,训练数据占40%,验证数据占10%,测试数据占50%。Widerface数据集中场景丰富,人脸在大小、光照、位置、表情等方面具有多样性。但该数据集以欧美人脸为主,单独使用该数据集无法满足国内人脸检测需求。因此实验中还使用无人机获取的视频数据,通过提取帧、含重叠裁剪等预处理操作获得4 334张416×416的人脸图片,并对其进一步划分为训练、验证及测试集。具体每部分数据见表1。

表1 人脸检测所用数据集Table 1 Datasets used in face detection
实验还使用了中国科学院自动化所制作的开源人脸数据集CASIA-FaceV5,该数据集由2 500张480×640的图片构成,共有500个人物目标。只包含一个室内场景,并在照明、是否佩戴眼镜、表情等方面有变化。
2 研究方法
2.1 YOLOv3及其改进
YOLOv3[10]是YOLO(you only look once)系列中比较经典的网络,因其速度快、精度高被广泛应用于各类目标检测任务中。YOLOv3以Darknet53作为特征提取网络,性能相对于采用Darknet19的YOLOv2[9]有较大提升。YOLOv3用5个步长为2的卷积实现5次下采样获得在13×13尺度上的预测。同时通过类似特征金字塔的上采样方式实现2次上采样并结合融合策略得到26×26以及52×52尺度的预测,实现多尺度预测。此外YOLOv3采用逻辑回归预测对象类别。虽然YOLOv3在目标检测任务中优势明显,但存在召回率低以及预测框定位不准确等问题。
针对召回率低的问题,采用SE-ResNeXt[18]代替Darknet53中的ResNet[19],通过引入“基数”维度增加操作数,同时保证模型复杂度不会增加。避免采用加深或者增加通道数提升模型性能所带来的传播梯度问题。此外,模型中还通过加入SEnet[18](squeeze-and-excitation networks)引入注意力机制,有选择性地利用学到的特征,在充分利用有用特征的基础上抑制无用特征。改进后的模型将SEnet置于ResNeXt[20]的跳层连接之前,并且“基数”维度选用16。改进后的模型的详细结构见图1。
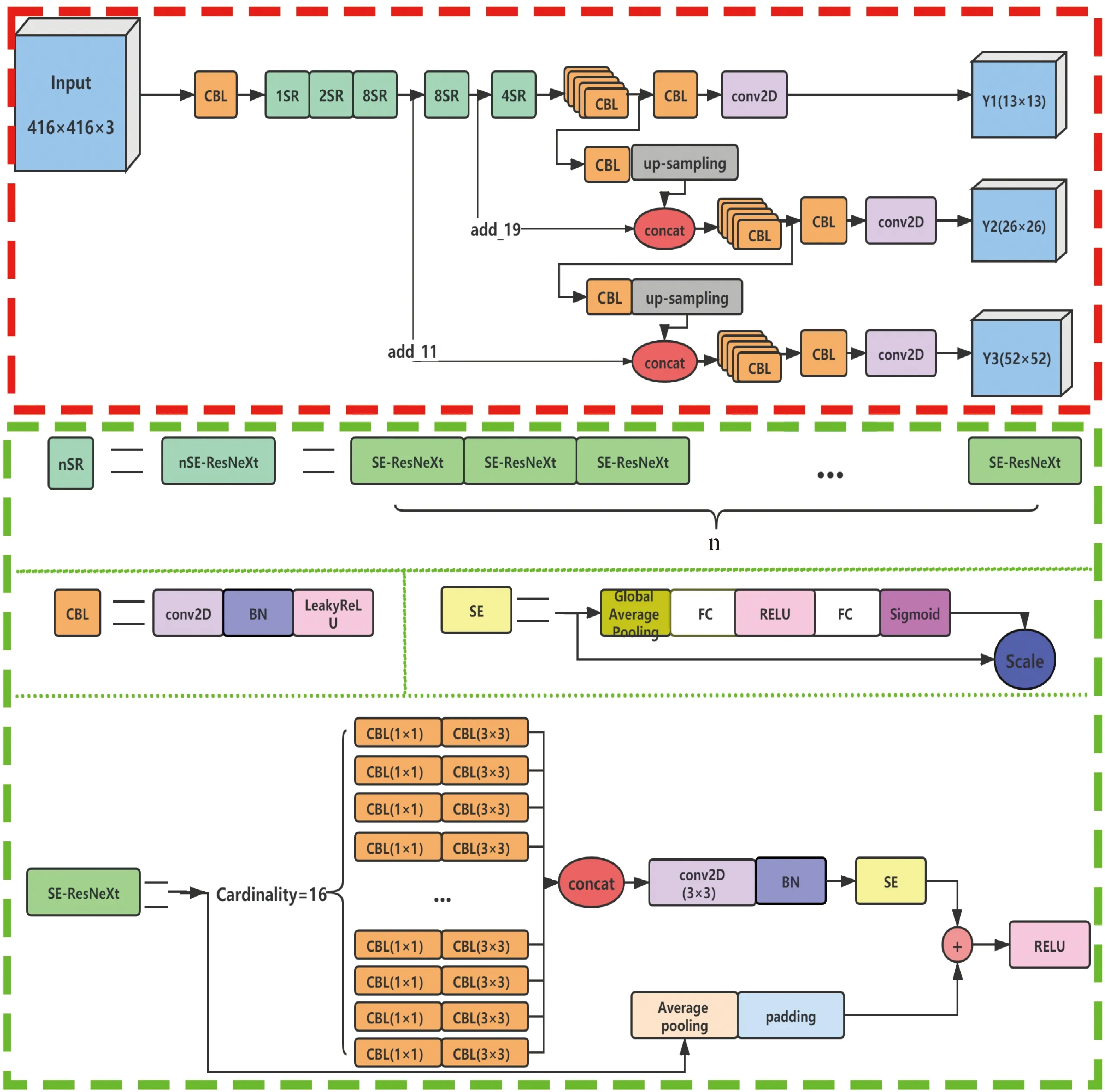
图1 改进后YOLOv3的结构Fig.1 The structure of the improved YOLOv3
YOLOv3的损失函数由位置损失、类别损失及置信度损失3部分组成。位置损失主要针对预测框和真值框中心点坐标及长宽的差距进行惩罚。预测框使用交并比(intersection over union,IOU)指导回归,虽然这个指标比较经典,但当预测框和真值框存在包围关系或者不相交时,无法提供优化方向。CIOU[21](complete-IoU loss)在IOU、GIOU[22](generalized intersection over union)和DIOU[21](distance-IoU loss)的基础上综合考虑预测框和真值框之间的重叠面积、中心点间的距离、长宽比的一致性,在两框的各种位置关系情况下都可以提供优化方向。CIOU的计算如下
(1)
式中:Op和Ol分别表示预测框和真值框的中心点,l表示两框中心点之间的欧式距离,c表示包含两框的最小外接矩形对角线的长度。α是平衡比例的系数,υ用于衡量预测框与真值框长宽比的一致性,计算公式如下:
(2)
(3)
其中:wt,ht为真值框的长宽,wp,hp为预测框的长宽。已有研究表明[22],回归损失可以直接作为YOLOv3的位置损失,从而取代二值交叉熵及均方根误差等方法。改进后的位置损失如下
CIOUloss=Confidence(2-w×h)(1-CIOU).
(4)
2.2 Facenet模型
Facenet[13]是Google提出的常用的人脸匹配方法,采用端对端的方式直接对输入图像进行判定。其摒弃了通过Softmax进行分类的方式,而是采用三元组在Triplet Loss的指导下直接对比图像特征向量之间的欧式距离,从而判定人脸图像的相似性。该模型可用于对比两张人脸是否属于同一个人、确定输入人脸身份以及聚类输入人脸找出属于同一个人的人脸。模型详细结构见图2,本文采用输入为160×160的Inception ResNet v1网络做为主体网络。在Triplet Loss的指导下不断减小类内人脸特征向量之间的欧式距离,扩大类间人脸特征向量之间的距离,最终得到人脸的特征向量(embeddings)。
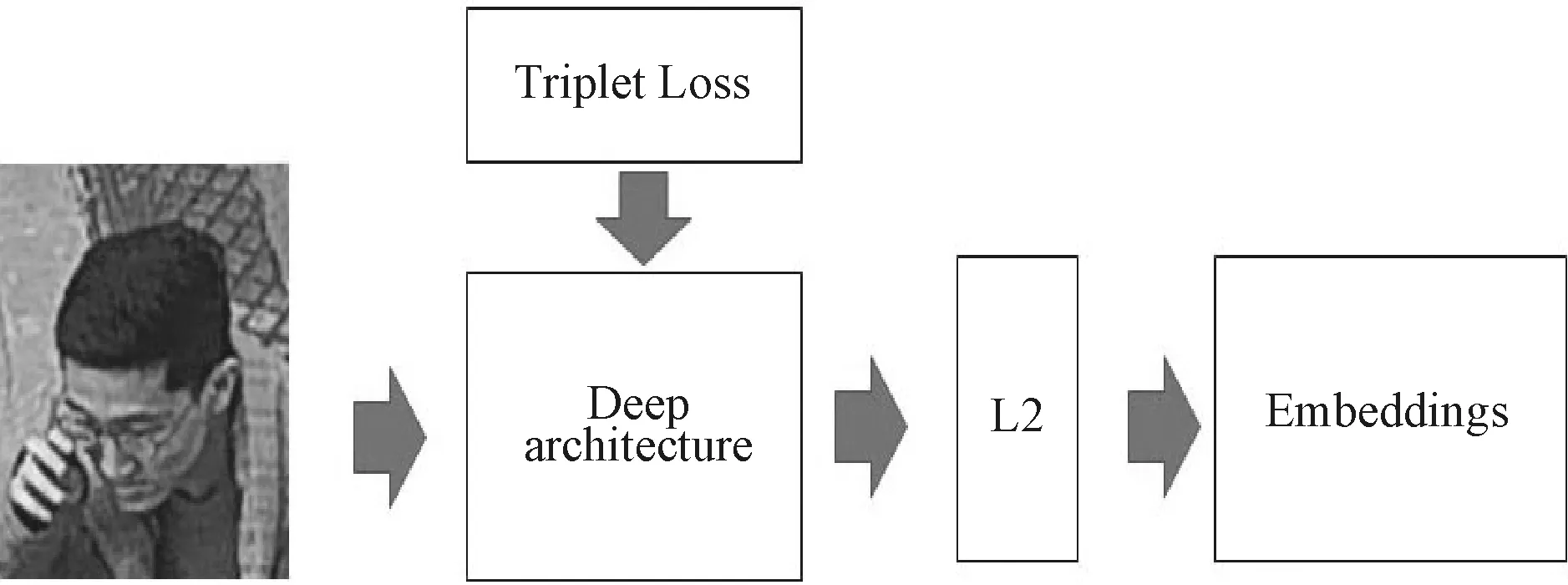
图2 Facenet的结构Fig.2 The structure of Facenet
3 实验与结果分析
3.1 实验环境与设置
实验在一台搭载了RTX2080Ti独立显卡(运行内存11 GB),i9-9900k处理器的Windows10操作系统上进行。并采用Tensorflow和Keras框架。实验分为人脸检测和人脸匹配2部分,其中人脸检测中YOLOv3以及改进后的模型采用adam优化器,批处理量为8,初始学习率为10-3。学习率在验证损失20期(epochs)不变时下降为1/10,直到变为10-6。当实验达到500期或者验证损失在50期内不变时,学习将停止。人脸检测图片的输入大小为416×416。人脸匹配图片的输入为160×160,批处理为1 000。
3.2 实验评估指标
为了测试模型效果,实验中使用评估指标召回率[23](recall,R,指在所有确实为真的样本中,被判为的真的占比),精度[23](precision,P,指在所有系统判定的真的样本中,确实是真的的占比),F1分数,平均精确度(average precision,PA)[24]及FPS(指每秒传输的帧数,当FPS达到30时可以认为接近实时处理)对实验用到的模型进行评估。其中P,R,F1计算见下式:
(5)
(6)
(7)
3.3 人脸检测模型训练及测试
深度卷积神经网络需要大量数据支撑训练,模型首先采用数据量充足的Widerface数据集进行预训练,后又基于自制的无人机人脸数据集进行优化训练,并对训练好的模型进行测试。从表2可以看出改进后的YOLOv3的召回率,F1分数及平均精确度(PA)相对原始YOLOv3都有提升,但参数量反而有所下降。实现了在不增加模型参数量的同时提升模型检测性能。虽然检测速度相比原始YOLOv3有所下降,但实时性仍能较好满足实际应用需要。此外,虽然改进后的YOLOv3的参数相比MTCNN较多,但PA提升9.49%,且检测速度约是MTCNN的3倍。为了更直观地测试3个模型,图3显示了3个模型对无人机影像上人脸的检测结果。其中红色框为模型检测框,黄色框与绿色框分别对应漏检和错检的人脸,可见改进后的YOLOv3的错检和漏检情况更少,检测能力及对人脸的鲁棒性更强。
表2 3个模型人脸检测的指标评估Table 2 Face detection index evaluation of the three models
3.4 人脸匹配
Facenet提供CASIA-WebFace和VGGFace2两种预训练模型,本文结合迁移学习的思想,采用VGGFace2预训练模型。目标人脸经过检测得到人脸的预测边框,基于这个边框进行人脸对齐,并统一归一化为160×160大小,输入Facenet后对比目标人脸与模板人脸的特征向量以确定人脸对象的身份。为了反映改进后的YOLOv3对不同人脸图像的可区分性,实验对比了改进后的YOLOv3,YOLOv3及经典的MTCNN计算得到的A,B 2个目标的不同图片的欧氏距离。以1为不同目标人物人脸欧氏距离的阈值(2张人脸的欧氏距离高于该阈值,则认为2张人脸属于2个不同的人;低于该阈值则认为2张人脸属于同一个人)。表3显示改进后的YOLOv3与MTCNN对清晰的正脸图像均可以实现很好的区分(见图4(a)、4(b)、4(e)、4(f)),但YOLOv3计算的A_1和B_1的欧式距离异常。对于人脸模糊以及拍摄角度较大产生的非正脸图像(见图4(c)、4(d)、4(f)、4(g)),改进后的YOLOv3及YOLOv3仅有一对欧氏距离异常,但MTCNN有3对异常值。这表明改进后的YOLOv3的检测性能、区分能力及鲁棒性更强。

图4 与欧氏距离计算相关的图像Fig.4 Images related to Euclidean distance calculation
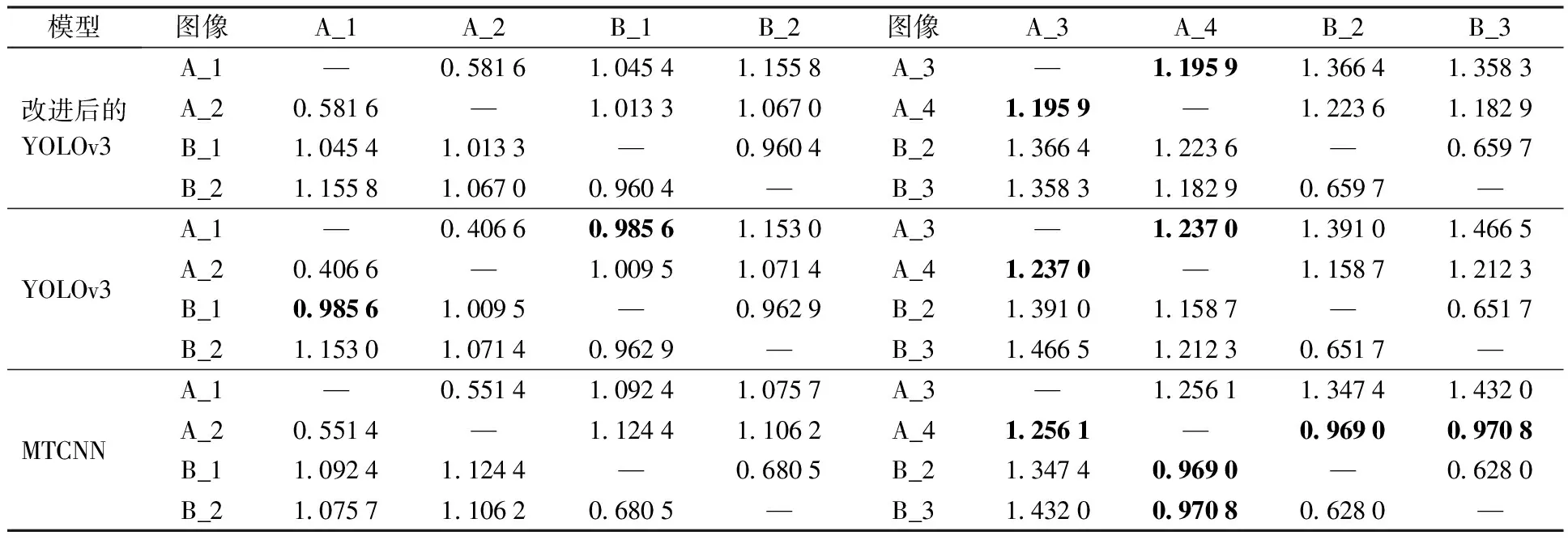
表3 3个模型计算得到的A、B目标不同人脸图像的欧式距离(加粗数字表明异常)Table 3 Euclidean distance between different face images of people A and B calculated by three models(Bold values indicate values that are not in the normal range)
为了反映改进后的YOLOv3结合Facenet的人脸识别效果,利用亚洲人脸图像数据集CASIA-FaceV5测试改进后的YOLOv3,YOLOv3及MTCNN分别与Facenet结合的人脸识别性能。实验共测试了CASIA-FaceV5数据集中2 500张人脸图像,其中改进后的YOLOv3+Facenet实现了全部图像正确检测和对齐,并正确识别了其中1 863张人脸,得到74.52%的准确率(表4)。相对YOLOv3+Facenet的71.16% 的准确率和MTCNN+Facenet的66.2%的准确率,改进后的YOLOv3+Facenet的准确率均有提升。表明改进后的YOLOv3结合Facenet的组合在人脸识别任务中性能更优。除此之外,YOLOv3+Facenet和MTCNN+Facenet在对齐率上也低于改进后的YOLOv3+Facenet,这也反映出改进后的YOLOv3的检测能力更强。为了更直观地反映3个模型组合在无人机影像上的人脸识别效果,图5显示了3个模型组合对图3放大区域的人脸识别结果。通过与正确目标身份对比可知,改进后的YOLOv3+Facenet实现了两张图像中目标身份的正确识别,而YOLOv3+Facenet对C的身份识别有误,MTCNN+Facenet对D的身份识别有误。可见改进后的YOLOv3与Facenet结合的识别效果最好。

图5 3个模型结合Facenet对无人机影像的人脸识别结果Fig.5 Face recognition results of UAV images based on the three models combined with Facenet

表4 3个模型组合对CASIA-FaceV5数据集人脸的识别结果对比Table 4 Comparison of face recognition results of the three model combinations on CASIA-FaceV5 dataset

图3 3个模型对无人机影像人脸检测结果Fig.3 UAV image face detection results of the three models
CASIA-FaceV5数据集是正面拍摄的人脸关键点清晰的数据集,实际应用中无人机影像由于拍摄高度、遮挡及飞行速度等一系列因素的影响会存在面部遮挡,人脸模糊以及关键点不明显的俯视人脸情况的存在。为测试3个模型组合对遮挡及模糊情况的鲁棒性,图6显示了3个模型组合对人脸清晰,存在遮挡和存在模糊情况的无人机影像的人脸识别效果。从图中可以看出,对于面部清晰的人脸,如图6(a)和6(d)所示,3个模型组合都可以实现正确的识别;但对于面部有遮挡、部分模糊以及人脸关键点不清晰的情况,分别如图6(b)、6(c)和6(e)所示,改进后的YOLOv3+Facenet可以实现正确识别,而MTCNN+Facenet均无法正确识别,YOLOv3+Facenet对模糊情况的识别错误。可见改进后的YOLOv3+Facenet对实际无人机应用面临的模糊及遮挡情况具有更强的鲁棒性。

图6 3个模型组合对不同质量的无人机影像的人脸识别结果Fig.6 Face recognition results of the three model combinations on UAV images with different qualities
4 讨论与总结
无人机因其小巧易控以及飞行可调等优点在应急救援以及嫌疑人员追踪等应用场景发挥着重要作用,应用于无人机影像的高精度人脸识别技术能更好地发挥无人机的作用。随着软硬件性能的提升,深度学习得到了快速发展,卷积神经网络以其较高的精度和较少的人为干扰成为目标检测领域的热门研究方法。
Facenet与MTCNN的结合是比较经典也比较常用的人脸检测识别组合,但在无人机应用场景下拍摄高度造成的影像非正脸的情况难以发挥MTCNN关键点检测的优势,导致错检漏检现象严重,难以满足实际应用需要。本文探究在无人机应用场景下的高精度人脸识别方法,以改进的YOLOv3进行人脸检测,再结合Facenet实现人脸识别。实验证明改进YOLOv3结合Facenet对人脸的区分能力更强,检测及识别精度更高,同时对于无人机影像存在的遮挡、模糊等情况的鲁棒性也更高。除此之外,改进后的YOLOv3相对原始YOLOv3不仅精度和召回率得到提升,而且模型参数量有所减少。在无人机影像人脸检测中的漏检和错检现象也轻于原始YOLOv3,因此对于YOLOv3的改进也是有效的。
本文既采用了数据量丰富的公开数据集,也结合了基于无人机影像的自制数据集,不仅避免了过拟合问题,也丰富了当前的开源人脸数据集。此外,随着今后自制数据集容量的不断积累扩充,模型的训练还将实现进一步完善,检测以及识别性能也将得到进一步提升。
