作者来稿中医学统计学常见问题分析
2023-01-11黄晓红韦挥德潘洪平吕文娟蓝斯琪
余 军, 黄晓红, 韦挥德, 潘洪平, 吕文娟, 韦 颖, 蓝斯琪, 刘 慧
医学统计学是应用概率论和数理统计的基本原理和方法,研究医学领域中数据的收集、整理、分析和推断的一门应用科学[1],已广泛地应用到医学科研中。统计学方法的正确应用是医学论文具有科学性和可靠性的重要保证,论文中误用、错用统计学方法,直接影响研究结果的可信度,导致论文质量不高或者结论错误,甚至会对临床实践造成严重的后果[2-5]。有研究显示,在应用统计学方法的作者投稿文章中,有92.0%存在着统计学相关问题[6]。2012年中华医学会系列杂志专家组在对496篇文章进行统计学审读时发现,统计描述错误38处(7.7%),统计方法及分析错误78处(15.7%)[7]。可见,医学论文中的统计学错误问题是普遍且严重的,对论文的科学性产生较大影响。本文总结了《中国临床新医学》杂志作者来稿中常见的统计学相关问题,并结合期刊编辑的工作体会对其进行分析,以期引起作者、编辑和审稿专家对统计学问题的关注,共同提高论文质量。
1 统计学方法描述不完整

2 统计学方法的误用
统计分析方法需要根据研究目的、设计方案、资料类型及样本含量大小来进行选择。医学科研人员在撰写论文时若未能较好掌握医学统计学专业知识,盲目套用统计学方法,往往会造成统计学方法误用。鉴此,笔者现对医学期刊中几种常见的统计学方法误用情况进行分析,以期医学科研工作者能更合理地将统计学方法应用于医学研究。
2.1两独立样本t检验与配对t检验的误用 在医学论文中,t检验是常用的统计学方法,但作者往往未能较好地区分两独立样本t检验与配对t检验,甚至在统计学方法描述时将两者均模糊地描述为t检验。两独立样本t检验适用于完全随机设计(成组设计)计量资料,而配对t检验适用于配对设计计量资料。在医学论文中,两独立样本t检验常用于两组间某个观察计量指标的比较,而配对t检验常用于观察指标在同组内两个时点间的比较(一般为同组治疗前后的比较)。见表1。两独立样本t检验的数据条件是:(1)符合正态分布;(2)独立性;(3)方差齐性。配对t检验的条件是两组数据差值呈正态分布。而在实际分析过程中,数据的正态性分布和方差齐性情况往往被研究者忽视。在成组设计中,若两组数据的总体方差不齐,则推荐采用近似t检验(t′检验)。对于不符合正态分布的数据资料,则推荐使用秩和检验。
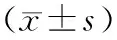
表1 两组指标1治疗前后比较
2.2单因素方差分析误用两独立样本t检验 在医学研究中,组别的设计往往不止两组,对于三组或三组以上的计量资料比较,研究者往往错误地使用两独立样本t检验进行多组间的两两比较。以表2的资料数据为例,若组1与组2、组1与组3,或者组2与组3的比较采用两独立样本t检验,则会增加犯Ⅰ类错误(当零假设为真时,假设检验结论拒绝零假设而接受备择假设)的概率。对于这种典型的多组独立样本资料比较宜选用单因素方差分析,其对计量资料的要求与两独立样本t检验相同,即数据需符合正态分布、具有独立性、方差齐性。这种类型资料的分析思路一般是先进行多组间的整体比较,若差异有统计学意义,再进一步进行组间两两比较。在此,笔者推荐使用LSD-t检验和SNK检验进行组间的两两比较。如表2所示,对于组间比较有统计学意义的指标,在表格制作中可采用上标的方式进行标注,这样展示表格结果信息更简洁、明了。对于不符合正态分布的计量资料,其多组间比较则推荐采用秩和检验进行,组间两两比较可采用Bonferroni法进行校正检验水准。
表2 三组指标2、指标3比较结果
2.3重复测量方差分析误用两独立样本t检验或单因素方差分析 重复测量设计是指在给予干预处理后,在多个时间上对同一研究对象重复检测观察指标,以期探讨研究对象在不同时间点上指标的变化情况。以表3数据资料为例,作者往往错误地采用两独立样本t检验对两组同时间点的指标数据进行比较,或误将横向数据比较(同组不同时间点的比较)应用单因素方差分析来处理,增加了Ⅰ类错误的发生概率。而对于此种重复测量设计的资料数据,由于加入了时间因素,产生了时间交互效应,应采用重复测量方差分析。
表3 两组不同时间点指标4的比较
2.4χ2检验使用不当χ2检验是医学论文中常用的统计学方法,常用于组间率或者构成比的比较,如有效率、发生率、阳性率等。但是,在研究者使用χ2检验的过程中往往忽视了其适用条件,即对于完全随机设计的四格表资料应满足:(1)总样本含量(n)≥40;(2)每个单元格的理论频数(T)≥5;(3)当n≥40,但有1个或多个单元格出现1≤T<5时,应计算校正χ2值;(4)而当n<40,或者存在1个以上单元格T<1时,则应选用Fisher确切概率法。对于R×C(行×列)表资料,采用χ2检验时应注意:不应有1/5以上的格子出现1≤T<5,或不应有格子出现T<1,否则导致分析结果产生偏倚。遇到这种情况可考虑采取以下几种措施:(1)增加样本量;(2)对相邻频数进行合理归并;(3)舍弃部分数据;(4)采用Fisher确切概率法。
2.5秩和检验误用χ2检验 对于单向有序行列表资料,如表4资料示例,作者期望比较两组间疗效的差异情况,以“优”“良”“无效”等对疗效情况加以分类。在此例中,“优”“良”“无效”为单向有序分类变量,亦称作等级资料。如使用χ2检验则只能分析两组数据频数的分布差异是否有统计学意义,而忽略了资料本身的强度等级意义,降低检验效能。故当处理单向有序分类变量时,比较组1和组2疗效有无差异,应当使用秩和检验。

表4 两组疗效比较(n)
2.6McNemar′s检验或Kappa一致性检验误用χ2检验 在临床诊断试验中,研究者常通过配对设计探讨两种检查方法的诊出情况。例如:某试验纳入100例患者为研究对象,对其同时采用方法A和方法B进行检查,检查结果见表5。这是配对设计四格表资料,若研究者想探讨两种检查方法的结果有无差异,则推荐使用McNemar′s检验(又称配对χ2检验);若研究者是想探讨两种方法检查结果的一致性情况,则推荐使用Kappa一致性检验。

表5 A、B两种检查方法检查结果(n)
2.7Pearson积差相关与Spearman秩相关的误用
在临床研究中常研究两个指标之间的相关性,但研究者常常在未能正确了解数据类型的情况下盲目套用Pearson积差相关进行分析,造成统计差错。需要注意的是,Pearson积差相关的应用需满足以下几个条件:(1)研究指标为计量资料;(2)两个变量均为随机变量;(3)两变量均呈正态分布;(4)各观察值相对独立;(5)两指标散点图有线性趋势。对于资料不满足正态分布或为等级资料时,应采用Spearman秩相关分析方法。值得注意的是,Pearson积差相关是简单相关分析,分析结果往往不能正确说明两个变量之间的关系,要采用偏相关或者多重线性回归分析来补充。
2.8受试者工作特征(receiver operator characteristic,ROC)曲线分析使用不当 对于临床诊断试验研究,研究者常需探讨某个检测指标诊断疾病的效能。当诊断指标为计量资料或有序资料时,可通过ROC曲线分析该指标用于诊断目标疾病的效能,并获得检测指标的最佳诊断界值及其对应的灵敏度和特异度。但在研究设计中,对于疾病的诊断结局(有疾病,或无疾病),一些研究者并未能通过金标准进行判断,导致针对研究指标所得的分析结果不准确。另外,在研究设计时,要注意估计样本含量;如果是两个或多个诊断指标诊断效能的比较,应该进行假设检验。
2.9logistic回归分析使用不当 在医学研究中常采用logistic回归分析某疾病的影响因素,其一般统计逻辑是先通过单因素分析筛选有统计学意义的指标变量纳入到logistic回归模型中,以筛选出影响因素。logistic回归适用于研究以分类因变量与一组自变量的关系,分类因变量可以是二项分类因变量(如患病/未患病、有效/无效),也可以是有序或无序多项分类因变量(如低体重、正常体重、肥胖;学生、工人、农民),而自变量可以是计量资料也可以是分类资料。值得注意的是,在论文中常见以下问题:(1)研究样本量不足,logistic回归需要有较大的样本量,且一般要求样本量是自变量个数的10~15倍;(2)盲目纳入自变量导致回归结果不稳定,在回归分析中应对自变量进行筛选并进行共线性判断,对于无序多分类自变量应设哑变量进行赋值;(3)对结果分析和解释不当,未能正确理解logistic回归模型,盲目地将比值比(odd ratio,OR)>1的因素认为是危险因素,OR<1的因素认为是保护因素,未注意在实际统计软件操作过程中因变量的赋值方式;(4)混淆logistic回归分析与多重线性回归,当因变量为计量资料时应考虑使用多重线性回归进行分析。
2.10误用χ2检验或logistic回归分析处理生存资料 在医学随访研究或队列研究中,获得的研究资料内容除了终点事件(如是否存活或是否复发)、干预方式以及相关变量因素(如年龄、性别、民族等)外,还包括了生存时间(随访时间)。若盲目使用一般χ2检验或logistic回归分析处理生存资料只是对事件的结局情况进行分析,而忽视了终点事件发生所经历的时间这一重要信息。生存分析是将终点事件的出现与否和出现终点事件所经历的时间相结合起来分析的一种统计分析方法。对于随访研究收集的资料要采用生存分析的方法进行分析。生存分析主要内容有:生存率的估计、生存曲线的绘制、中位生存时间的估计以及生存曲线(生存率)的比较。在一般临床研究中,笔者推荐使用Kaplan-Meier法绘制不同组的生存曲线,并采用log-rank检验比较各组的生存曲线差异是否具有统计学意义,以评估各组生存情况差异。另外,可通过Cox回归模型分析各变量因素对结局及结局发生时间的影响。
3 对统计结果的表述及解释不当
(1)以P值大小对指标差异大小性进行比较。在医学论文中,假设检验的检验水准一般取α=0.05,即以P<0.05认为差异有统计学意义,说明两样本来自同一总体的可能性小于0.05,代表犯Ⅰ类错误的概率小于0.05。但是,许多作者将P值越小误解为指标的差异越大,P值越小只能说明零假设成立的可能性越小,而越有理由拒绝零假设和接受备择假设。(2)忽视实际临床意义。对于样本量比较大的临床研究而言,两指标的比较会更容易获得有统计学意义的结果,但在进行结果解释时需要注意该差异是否具有实际的临床意义[10]。而在相关性分析以及回归分析中,常常也会出现相关系数(r)较小或OR值、风险比(hazard ratio,HR)值十分接近于1,但P<0.05的情况,此时更应结合临床实际,客观地对统计结果进行评价,谨慎下结论。
4 统计学符号使用不当
5 小结
在医学科研论文中,正确的统计学分析方法是保证论文质量的重要条件,直接关系到科研成果的准确性、科学性。统计学分析方法的选择要考虑研究分析的目的、研究的设计类型、数据资料的类型以及统计学方法的应用条件,切勿盲目套用统计学方法。而医学统计学作为一门应用科学,其在实践应用中不能脱离医学背景,应紧密结合医学专业的实际问题对结果进行分析判断,对于有统计学意义的结果也要辨析其是否有临床实际意义,从而科学合理地推导结论。医学科研论文中的统计学问题是比较常见的,对于医学科研工作者而言,要在平时的工作中加强医学统计学的学习,科学地进行试验设计,在试验之初就应知晓试验的设计类型、数据的收集和处理方法,做到心中有数。而对于期刊编辑而言,亦应加强自己的统计学素养,能主动发现论文中的统计学错误,积极与外审专家、作者进行沟通交流,改正文章错误,保证刊发论文的正确性和科学性,共同提高科研和论文质量。
