基于LDA模型的旅游市场需求分析
2023-01-10关海桢包莞晖罗正禤世丽
文/关海桢,包莞晖,罗正,禤世丽
本文以茂名市旅游产品为对象采集了样本数据,并运用TF-IDF算法和LDA主题模型求得样本数据的样本相似度,进行文本分类和数据预处理;运用TextRank算法提取了微信公众号等平台有关旅游产品的数据;采用关联性规则Apriori算法对提取的数据进行关联度分析,进而明确旅游产品之间的联系。
随着互联网的发展,国内旅游产业逐渐进入“大智慧旅游”和“智慧旅游2.0”时代,网络评论成为游客表达旅游感想的新形式。但网络评论数量庞大、内容繁杂,游客面对海量的网络评论,很难快速找出适合自己的旅游主题和旅游产品。基于此,本文结合多种数据处理与分析手段,以期明确旅游市场的真实需求。
一、算法与模型简介
(一)TF-IDF算法
TF-IDF算法的主要逻辑是:如果某个词语或短语在一篇文章中出现的频率(TF)高,并且在其他文章中很少出现,则认为该词或者短语具有很好的类别区分能力,适合用来分类。[1]TF-IDF算法表达式如下:
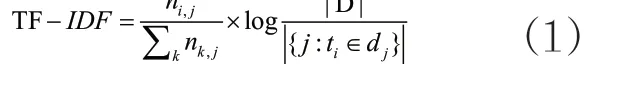
式中,各参数的具体含义如表1所示。
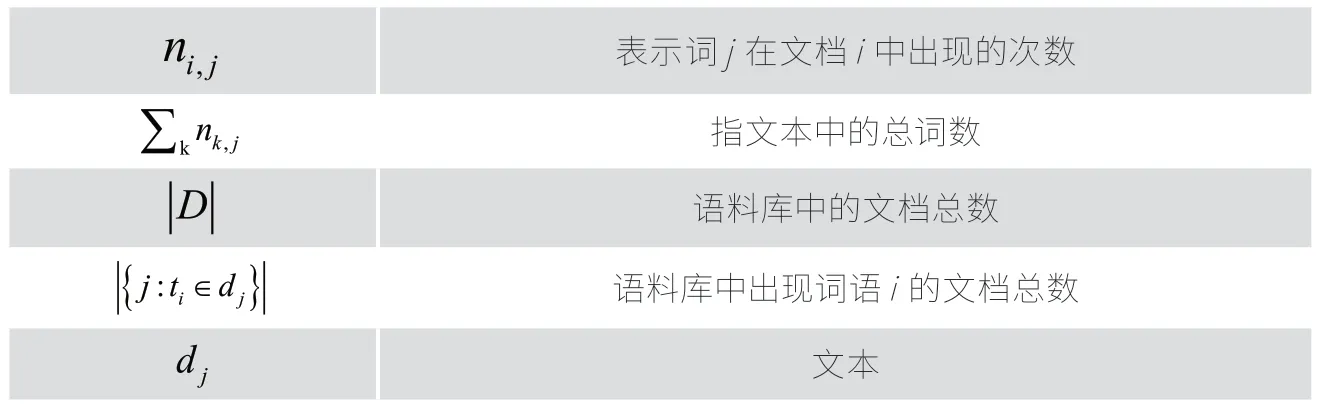
表1 TF-IDF算法中各参数含义
(二)LDA主题模型
LDA主题模型是由布莱(Blei)等人在2003年提出的一种无监督的主题模型,这是一个文档生成概率模型。[2]LDA指的是隐含狄立克雷分布,主题模型则是指基于无监督学习的方法对文档隐含的语义结构进行聚类的一种模型。
(三)TextRank算法
TextRank算法是一种用于文本的基于图的排序算法。[3]TextRank算法的基本逻辑是:通过把文本分割成若干组成单元并建立图模型,利用投票机制对文本中的重要成分进行排序,仅利用单篇文档本身的信息即可实现关键词提取[4],获得比较高分的N个单词作为文本关键词。TextRank算法的计算公式如下:
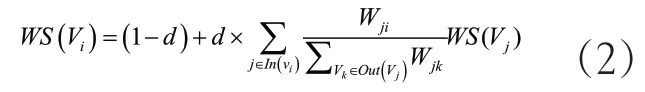
式中,各参数的含义如表2所示。

表2 TextRank算法计算公式各参数含义
(四)Apriori算法
Apriori算法是一种挖掘关联规则的频繁项集算法,其核心逻辑是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。[5]在使用Aprior算法时,使用者需要先找出support≥min_support的 频 繁项集,之后在频繁项集中生成强关联规则。
二、数据分析
(一)数据准备
本次分析的数据来源于5个数据集。其中包括50篇游记攻略,共计采集到450条数据,涉及9个指标;50篇酒店评论,共计采集到300条数据,涉及6个指标;50篇景区评论,共计采集到150条数据,涉及3个指标;50篇餐饮评论,共计采集到200条数据,涉及4个指标;80篇微信公众号文章,共计采集到160条数据,涉及2个指标。
(二)数据预处理
本文首先使用Jieba词库对采集到的数据进行预处理。文本分词结束后,本文利用“哈工大停用词表”去除停用词。随后使用TFIDF相似度模型对处理后的数据进行粗加工,对分词后的文件进行第一遍相似度检验,最后采用LDA主题模型对分词后的数据做精准度更高的第二遍相似度检验。
(三)提取旅游产品数据
本文基于酒店评论、景区评论和餐饮评论,通过直接汇总的方式得出旅游产品。以游记攻略为例,本文主要对攻略中展示的旅游产品进行提取。在此过程中,本文利用python(计算机编程语言)从附件提供的OTA(空中下载技术)、UGC(用户原创内容)数据中提取景区、酒店、民宿、特色餐饮、乡村旅游等旅游产品的实例和其他有用信息;同时利用PandasDataFrame.columns算数运算,使行、列标签上的数据全部预处理,并进行分词、重组之后,最终整理出6286条数据,汇总成一份9469行×5列的表格,部分内容如表3所示。
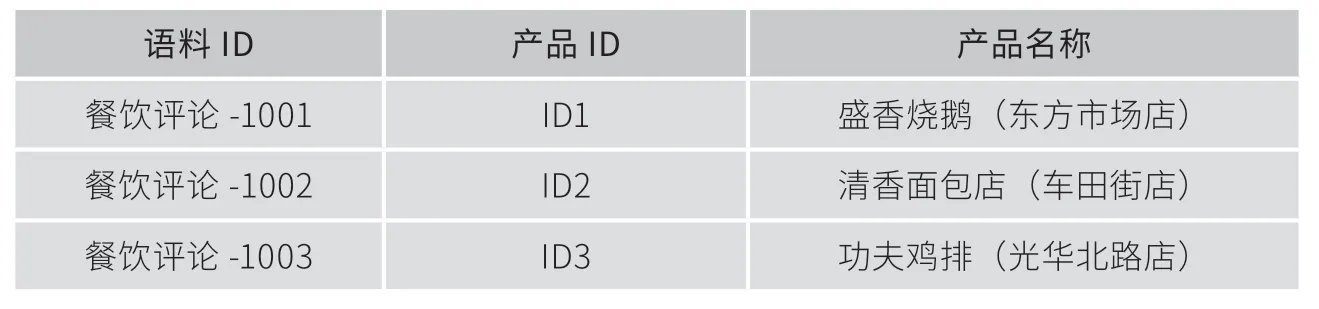
表3 部分餐饮旅游产品提取表
(四)热度分析
1.统计情感得分
考虑到中文情感分析库(cnsenti)能够对文本进行情绪分析、正负情感分析,本文通过其Sentiment正负情感计算类功能进行计算,以统计相关旅游产品的情感得分(正向为1分,负向为-1分,中性为0分)。该功能支持正负情感词典自定义,并且可以利用hownet情感词典对文本中的正、负面词语进行统计。
2.按年份统计旅游产品出现的次数
旅游产品出现的频次在一定程度上反映了该产品的受欢迎程度。本文按年份统计了采集数据中各类旅游产品的出现次数,得出如下结果:2018年980次,2019年1228次,2020年2124次,2021年5137次。在此基础上,本文将旅游产品的情感得分和出现频次相加,最终得出旅游产品热度。根据相关数据可知,热度排名前五的旅游产品均是来自2018年餐饮评论中被多次提及的清香面包店(车田街店),其热度总分为175分。
(五)分析产品的类型
为了进一步提高旅游产品热度的准确度,本文还做了如下处理。(1)对旅游产品热度得分表的文本进行分词和去停用词处理;(2)对旅游产品热度得分表的文本进行排列;(3)根据不同的年份去除旅游产品热度得分表中的重复项。经过处理后,本次旅游产品(部分)的类型如表4所示(部分)。
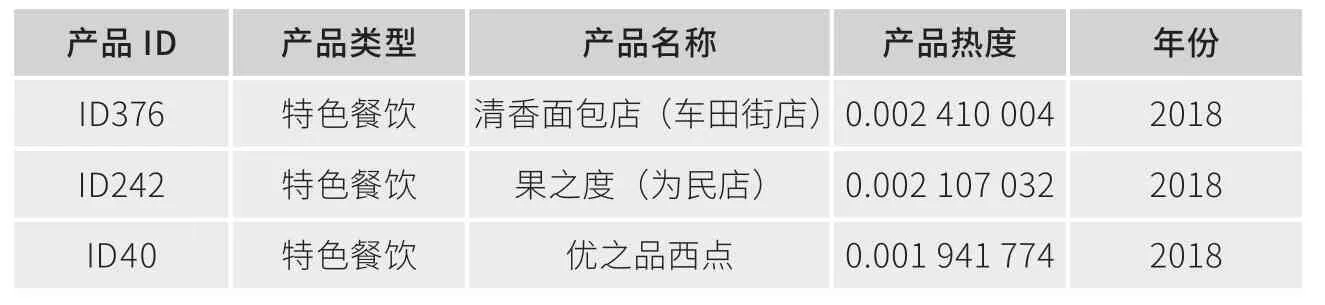
表4 部分旅游产品类型表
(六)计算相关度和关联度
1.计算相关度
在相关度计算过程中,本文借助TF-IDF(词频与逆向文件频率)模型和LDA(聚类分析)主题模型对微信公众号文章进行分类,并根据其内容与文旅的相关性把微信公众号文章划分为“相关”和“不相关”两类(见表5)。

表5 部分微信公众号文章相关与不相关结果分析表
2.计算关联度
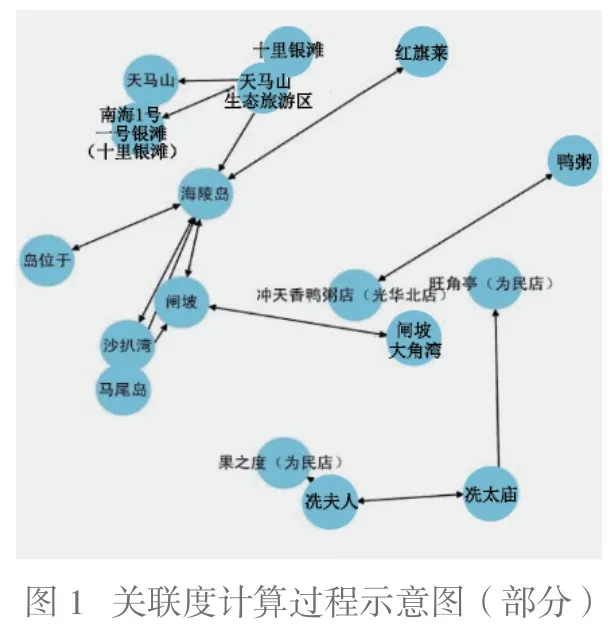
在计算相似度的基础上,本文以样本集的旅游产品为基础进行one-hot编码(狂热编码),并将编码转化为字符串,通过“支持度(数据集D中观测到的含有A所有项的比例,其表示的是项集{X,Y}在总项集里出现的概率)乘以10作为关联度”这一公式计算关联度,(部分)计算过程如图1所示。图中,每一个蓝色圆圈都代表一个旅游点,圆圈与圆圈间的连线则代表不同旅游点之间的关联性。连接线越多,说明该旅游点的支持度总和越大、置信度越高、关联规则越强。
三、结论与建议
(一)结论
本文基于Python和大数据分析了茂名市旅游产品之间的关联度,结果显示,茂名市景点和景区之间相互带动,酒店和特色餐饮之间相互促成,游客对于某种旅游产品的选择和喜爱会间接影响对另一种旅游产品的选择。在这各种关联性的影响下,茂名市的旅游产业蓬勃发展。
(二)建议
当下,旅游行业需要打破常规开辟新思路。旅游产品之间普遍存在关联性,一个有特色的景点可以带动周边旅游产品的发展,进而提升景区的知名度。从长远角度来看,景区可以推出特色游览价格,让利于民;酒店可与本地特色餐饮店联合,共同推出优惠套餐,吸引游客体验;特色的旅游产品可以通过连带关系带动着小众旅游产品吸引游客关注,从而促使当地旅游产业平衡发展。
