基于稀疏Transformer 的雷达点云三维目标检测
2023-01-09高永彬史志才
韩 磊,高永彬,史志才,2
(1.上海工程技术大学 电子电气工程学院,上海 201600;2.上海市信息安全综合管理技术研究重点实验室,上海 200240)
0 概述
三维目标检测广泛应用于自动驾驶[1]、增强现实[2]和机器人控制[3-4]领域中。三维目标检测算法根据输入形式的不同,分为基于图像、基于多传感器融合和基于点云的三维目标检测算法。
基于图像的三维目标检测算法根据输入RGB图像中2D/3D 约束、关键点和形状,通过推理目标几何关系解决图像深度信息缺失的问题。文献[5]利用单支路网络检测三维框的多个角点以重构三维中心点,通过二分支关键点检测网络锐化目标辨识能力。文献[6]考虑到2D 投影中的几何推理和未观察到深度信息的维度,通过单目RGB 图像预测3D 对象定位。文献[7]通过视觉深度估计方法从图像中估计像素深度,并将得到的像素深度反投影为3D 点云,利用基于雷达的检测方法进行检测。文献[8]基于左右目视图的潜在关键点构建左右视图关键点一致性损失函数,以提高选取潜在关键点的位置精度,从而提高车辆的检测准确性。
多传感器融合通常将多个传感器获取的特征进行融合。文献[9]提出在两个连续的步骤中检测目标,基于摄像机图像生成区域建议,通过处理感兴趣区域中的激光雷达点以检测目标。文献[10]提出引导式图像融合模块,以基于点的方式建立原始点云数据与相机图像之间的对应关系,并自适应地估计图像语义特征的重要性。这种方式根据高分辨率的图像特征来增强点特征,同时抑制干扰图像的特征。文献[11]结合点云的深度信息与毫米波雷达输出确定目标的优势,采用量纲归一化方法对点云进行预处理,并利用处理后的点云生成特征图。文献[12]基于二维候选区域中的像素过滤激光点云,生成视锥点云,以加快检测速度。
基于点云的检测算法仅通过输入点云学习特征,在检测网络中回归目标类别和包围框[13]。文献[14]将点云编码为体素,采用堆叠体素特征编码层来提取体素特征。文献[15]通过立柱特征网络将点云处理成伪图像,并消除耗时的3D 卷积运算,使得检测速度显著提升。文献[16]将点云编码到一个固定半径的近邻图中,并设计图神经网络,以预测类别和图中每个顶点所属的对象形状。文献[17]利用三维区域生成网络,将多视图生成器模块生成的多角度点云伪图像重新校准与融合,并根据提取的语义特征进行最终的点云目标分类和最优外接包围框回归。
基于图像的三维目标检测算法无法提供可靠的三维几何信息;基于多传感器融合的三维目标检测算法输入数据较多,需要较高的算力和较复杂的特征处理与融合算法;点云数据通常极其稀疏,受噪点影响比较大,基于点云的三维目标检测算法鲁棒性较差。因此,在点云稀疏条件下提升检测精度和算法鲁棒性具有一定必要性。
本文提出基于稀疏Transformer 的雷达点云三维目标检测算法。构建稀疏Transformer 模块并将其应用于三维目标检测领域中,通过显式选择Top-t个权重元素,以排除对注意力干扰性较高的权重元素,从而提高检测精度。设计一种粗回归模块,将粗回归模块生成的边界框作为检测头模块的初始锚框,使检测结果生成的边界框更加精细。在此基础上,设计基于体素三维目标检测算法的损失函数,以优化检测结果。
1 网络模型
本文基于PointPillars 在点云特征处理阶段的良好性能,延用了点云特征处理模块和2D 卷积模块,并增加了稀疏Transformer 模块和粗回归模块,在回归阶段使用通用的SSD[18]检测头作为检测模块。本文网络结构如图1 所示。

图1 本文网络结构Fig.1 Structure of the proposed network
首先,将一帧点云图像输入到点云特征处理模块中,由该模块将点云图像划分为H×W的立柱,并对立柱中的点进行采样;然后,经过Pillar 特征网络进行特征学习和特征展开,输出尺寸为(C,H,W)的伪图像,将该伪图像分别送入到2D 卷积模块,经过卷积操作分别产生尺寸为(C,H/2,W/2)、(2C,H/4,W/4)和(4C,H/8,W/8)的特征,通过反卷积操作生成3个尺寸为(2C,H/2,W/2)的特征后,再将这3个特征相连接,输出尺寸为(6C,H/2,W/2)的空间特征;最后,将空间特征送入到粗回归模块,在该模块的区域建议网络(Region Proposal Network,RPN)回归粗略类别和坐标的同时,另一个分支经过卷积操作输出尺寸为(2C,H/2,W/2)的新空间特征。与此同时,本文将Pillar 特征网络中伪图像的特征展开为(H×W)×C的序列形式,输入到稀疏Transformer模块,并根据原始位置对该模块输出的序列特征嵌入重新组合成伪图像特征,进行一次卷积操作,输出尺寸为(2C,H/2,W/2)的稀疏上下文特征。本文将得到的新空间特征与稀疏上下文特征连接后输入到检测模块,在粗回归模块提供的粗略锚框坐标的辅助下更精确地回归目标物体的坐标。
1.1 稀疏Transformer 模块
基于自注意力的Transformer[19]在一些自然语言处理和二维目标检测任务中具有较优的性能。自注意力能够模拟长期的依赖关系,但易受上下文中无关信息的影响。为解决该问题,本文引入稀疏Transformer 模块[20]。稀疏Transformer 模块通过显式选择最相关的片段来提高对全局上下文的关注,增强模型的鲁棒性。
稀疏Transformer 模块是基于Transformer 架构,通过Top-t选择将注意力退化为稀疏注意力,有助于保留注意力的成分,而去除其他无关的信息。本文提出的稀疏Transformer 模块中注意力可以集中在最有贡献的元素上。这种选择方法在保留重要信息和去除噪声方面具有有效性。稀疏Transformer 模块结构如图2 所示。

图2 稀疏Transformer 模块结构Fig.2 Structure of sparse Transformer module
对于单头自注意力,将点柱特征xi经线性层变换后变为值向量V[lV,d]、关键向量K[lK,d]和查询向量Q[lQ,d]。线性变换过程如式(1)所示:

其中:WP为对应向量的线性变换矩阵;查询向量Q与关键向量K的相似性通过点乘计算。注意力得分计算如式(2)所示:

由注意力机制可知,注意力得分S越高,特征相关性越强。因此,本文在S上实现稀疏注意力操作,以便选择注意力矩阵中每行的前t个有贡献的元素。本文选择S中每行的t个最大元素,并记录它们在矩阵中的位置(i,j),其中t是一个超参数。假设第i行的第t个最大值是ti,如果第j个分量的值大于ti,则记录位置(i,j),连接每行的阈值以形成向量t=[t1,t2,…,tn],n为查询向量的长度。稀疏注意力SSA(·,·)函数如式(3)所示:
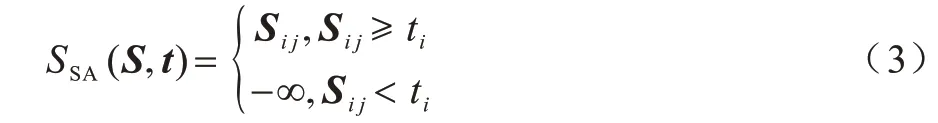
稀疏注意力模块的输出计算过程如式(4)所示:
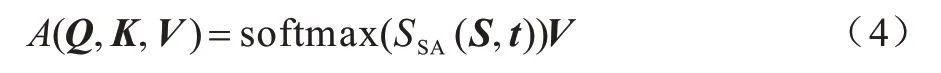
本文使用多头注意力机制将特征映射到不同的特征空间,以学习不同子空间的相关特征。不同的注意力头可以独立地进行特征学习,互不干扰。最后,将每个头部的结果拼接再进行一次线性变换得到的值作为多头注意力的结果。将结果与点柱特征xi进行残差连接,再用层归一化[21]对其进行归一化操作,层归一化操作后得到的结果即为所求。
1.2 粗回归模块
本文使用一个粗回归模块,该模块有两个分支,卷积分支用于调整特征尺度,RPN 分支用于粗略回归目标类别和边界框,回归结果用于指导后续检测头进行精细回归操作。粗回归模块结构如图3所示。
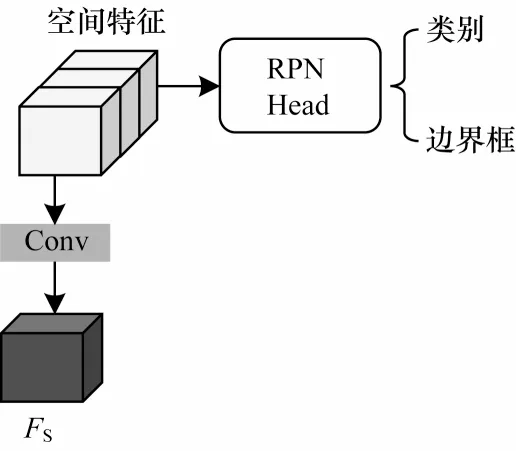
图3 粗回归模块结构Fig.3 Structure of coarse regression module
从图3 可以看出,空间特征是骨干网络进行多尺度特征串联后得到的特征,特征大小为(6C,H/2,W/2),该骨干网络与PointPillars 算法中的骨干网络相同。在卷积分支中主要进行1×1 的卷积操作,将骨干网络输出的空间特征降维,降维后的特征大小为(2C,H/2,W/2),将该特征与Transformer 模块生成的全局上下文特征串联。与此同时,将空间特征送入RPN 分支,输出类别和边界框。RPN 分支的回归结果为检测头模块提供粗略的锚框,用于后续边界框的精确回归操作。
1.3 损失函数
本文在SECOND[22]损失函数的基础上提出一种新的损失函数,以更好地优化粗回归和检测头模块。真值框和锚框由(x,y,z,w,l,h,θ)表示,其中(x,y,z)表示框的中心点坐标,(w,h,l)表示框的宽、高、长,θ表示框的方向角。边界框的偏移由真值框和锚框计算,如式(5)所示:

其中:gt 表示真值框;a 表示锚框。位置回归损失函数如式(6)所示:

其中:pre 表示预测值。对于角度回归,这种减少角度损失的方法解决了0 和π 方向的冲突问题。为解决该损失函数将方向相反的边界框视为相同的问题,本文在离散方向上使用交叉熵损失函数,使网络能够区分目标的正反方向。方向分类损失函数定义为Ldir。本文使用Focal Loss 定义物体分类损失,如式(7)所示:

其 中:pa表示模型预测的锚框类别概率;α和γ表 示Focal Loss 的参数。
该检测网络总的损失函数如式(8)所示:
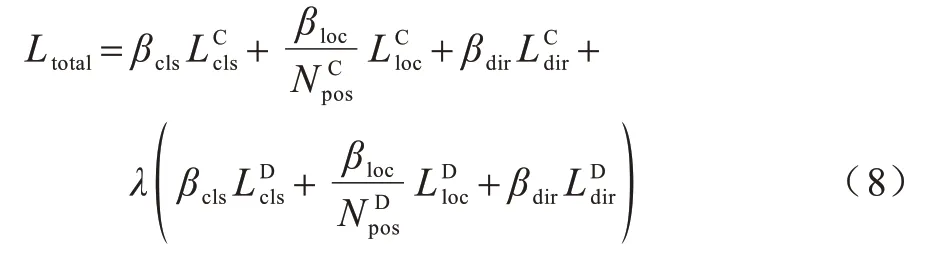
其中:上标C 和D 分别表示粗回归模块和检测头模块;表示粗回归框的正锚框数目表示细回归框的正锚框数目;βcls、βloc和βdir表示用于平衡类别损失、位置回归损失和方向损失的权重参数;λ表示用于平衡粗回归模块和检测头模块的权重。
2 实验结果与分析
2.1 实验数据集
本文在KITTI 数据集上进行实验,该自动驾驶数据集是目前在三维目标检测和分割领域中使用最广泛的数据集。该数据集包含7 481 个训练样本,本文按大约1∶1 的比例将训练样本分为训练集和测试集,其中训练集包含3 712 个样本数据,测试集包含3 769 个样本数据。本文在测试集上对模型训练的汽车、行人和骑行者这3 个类别进行评估。对于每个类别,本文根据3D 对象的大小和遮挡程度分为简单、中等、困难3 个级别。平均精度均值(mean Average Precision,mAP)作为实验结果的评估度量。本文采用官方评估建议,将汽车的交并比(Intersection Over Union,IOU)阈值设置为0.7,将行人和骑行者的IOU 阈值设置为0.5。
2.2 实验环境与对比实验
本文实验的模型训练部分选用的设备信息:一台运行系统为Ubuntu18.04、显卡为NVIDIA RTX 8000 的服务器,算法由python3.7 和pytorch1.4 框 架实现,使用Adam 优化器训练100 轮,批尺寸设置为6,学习率设置为0.003。
不同算法的三维检测结果对比如图4 所示,检测的阈值均设置为0.5。在场景1 中,PointPillars 存在不同程度的误检,将环境中的噪点或者路灯杆检测为行人或骑行者。在场景2 中,PointPillars 仍存在不同程度的误检和漏检,将道闸的立柱检测为行人,把并排行走或靠近的两个人检测为一个人。
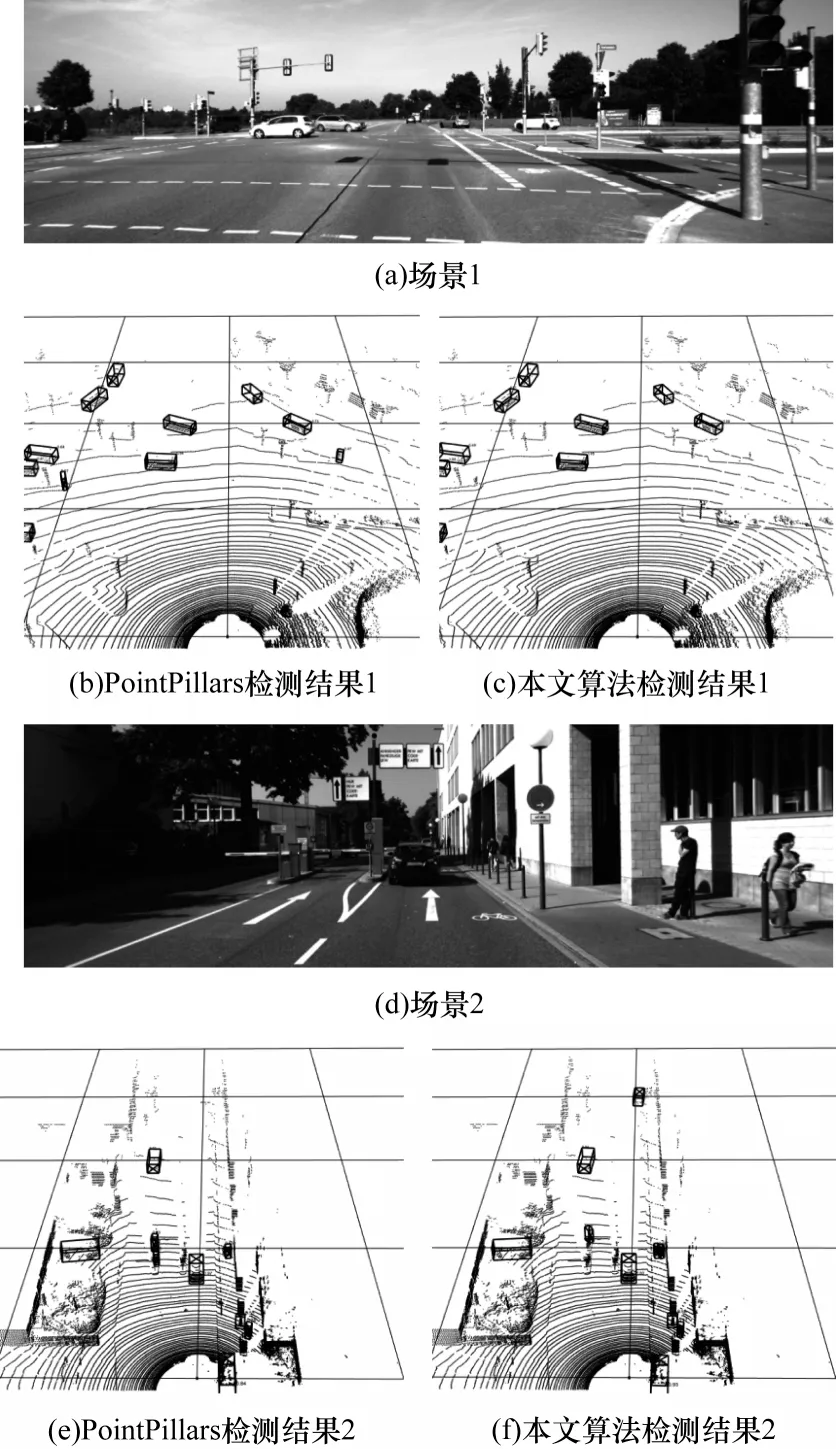
图4 不同算法的三维检测结果对比Fig.4 Three-dimensional detection results comparison among different algorithms
鸟瞰视角下不同算法的检测结果对比如图5 所示,图中边为白色的矩形框说明预测的边界框与实际真值框未完全重合。

图5 鸟瞰视角下不同算法的检测结果对比Fig.5 Detection results comparison among different algorithms from aerial view
本文选择VoxelNet、SECOND、PointPillars、3DGIoU[23]、Part-A2[24]、PointRCNN[25]、Point-GNN 和TANet[26]作为对比算法。表1、表2 和表3 分别表示在KITTI 测试集上汽车、行人和骑行者类别下本文算法与其他算法的mAP 对比。3D mAP 是3 种难度类别的平均精度均值。从表1~表3 可以看出,当检测行人和骑行者类别时,本文算法相较于其他算法具有较优的平均精度均值。
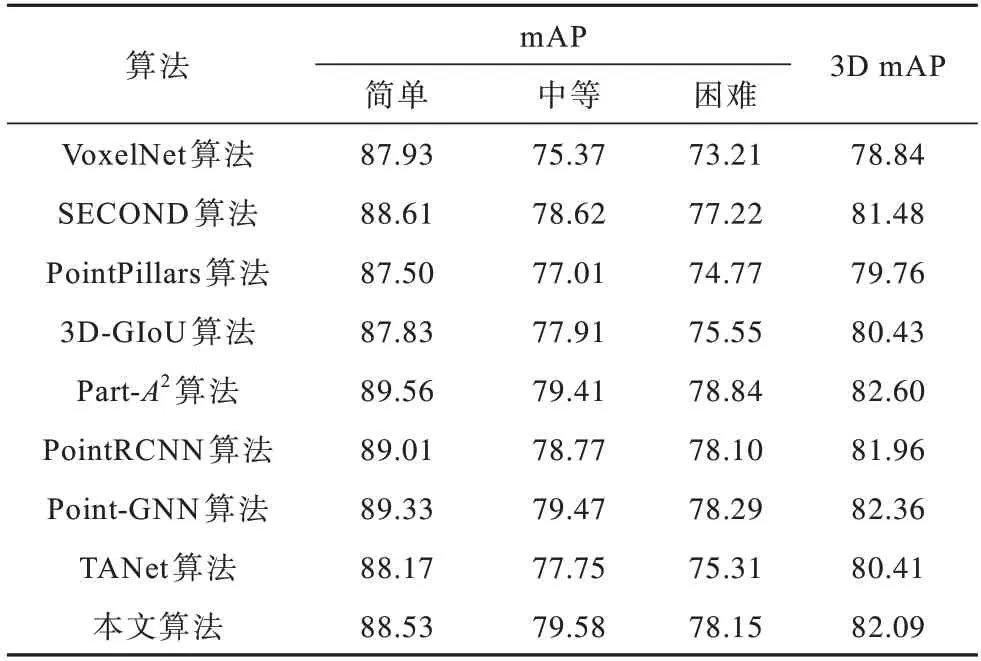
表1 在汽车类别下不同算法的mAP 对比Table 1 mAP comparison among different algorithms under car category %
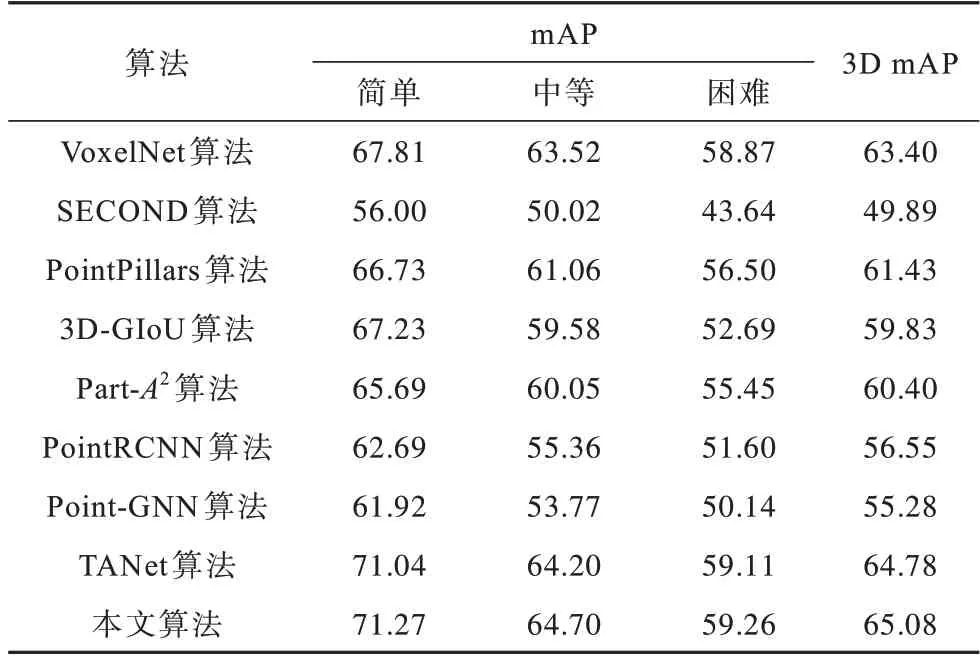
表2 在行人类别下不同算法的mAP 对比Table 2 mAP comparison among different algorithms under pedestrian category %
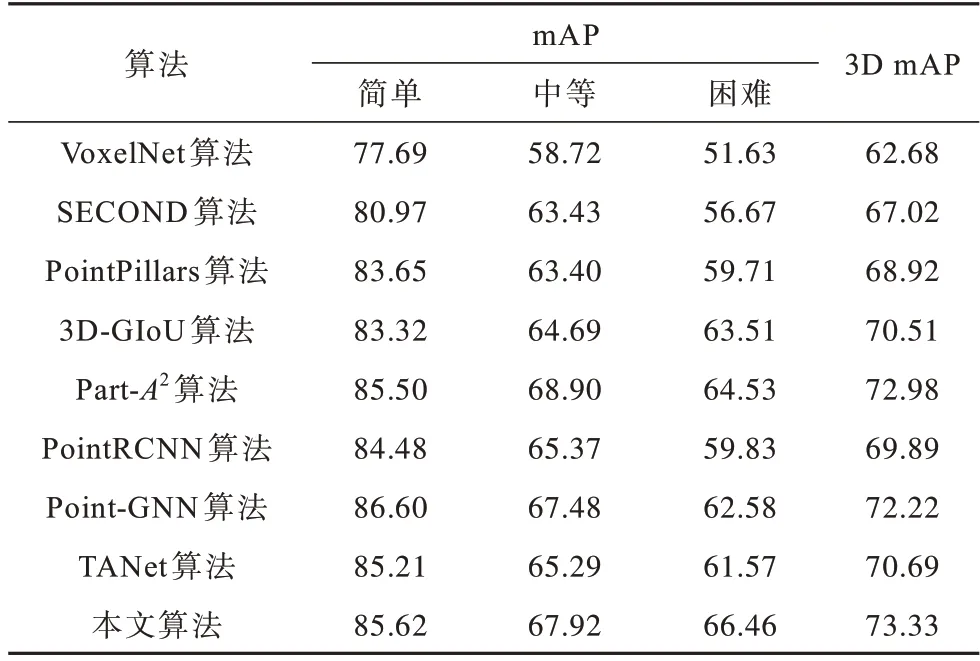
表3 在骑行者类别下不同算法的mAP 对比Table 3 mAP comparison among different algorithms under cyclist category %
本文算法与现有执行速度表现优异算法的推理速度对比如表4 所示。从表4 可以看出,本文算法在提高平均精度均值的同时,推理速度平均加快了0.535 8 frame/s。

表4 不同算法的推理速度对比Table 4 Inference speed comparison among different algorithms
2.3 消融实验
2.3.1t值的选择
由于注意力矩阵A与查询向量Q、关键向量K有关,因此t值的大小与系数k和关键向量K的长度相关。本文1.2 节中t=k×lK,lK是关键向量K的长度,也是注意力矩阵的列数。本文选取k={0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0}进行实验。实验设备的显卡为RTX 2080,批尺寸设置为1。在KITTI 测试集上汽车类别下本文算法的实验结果如图6 所示,以系数k为横坐标表示选择不同的t对本文算法检测精度的影响。
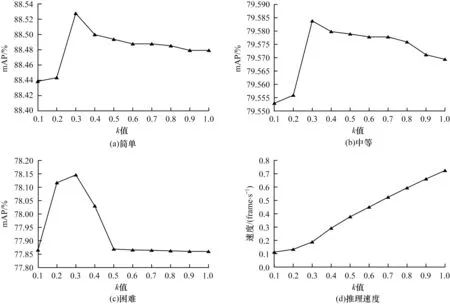
图6 在汽车类别下本文算法的实验结果Fig.6 Experimental results of the proposed algorithm under the car category
从图6 可以看出,随着k值的增加,mAP 逐渐升高,当k=0.3 时,mAP 达到最高,然后开始大幅度降低。其原因为本文的稀疏注意力模块对特征学习和去除噪点是有效的。在k=0.3 之前,原始的注意力同样会注意到除目标以外的无关成分,对检测难度为中等和困难的目标产生的影响较大。在k=0.3 之后,由于过多地过滤了目标的有用特征,因此检测精度明显下降。虽然稀疏注意力模块对检测精度的提升幅度比较微小,但是对推理速度的提升却十分显著。从图6(d)可以看出,相较于原始的Transformer,当k=0.3 时,本文算法的平均推理速度加快了约0.54 frame/s。
2.3.2 稀疏Transformer 模块的作用
由于在KITTI 数据集中噪点数目无法得知,因此本文在每个目标物的真值框内添加相同数量的噪点,模拟实际场景中噪点对模型的负影响,以测试该模块对模型鲁棒性和检测精度的贡献。基于2.3.1 节的实验结果,本文将k值设置为0.3,在不改变其他模块的情况下,在KITTI 测试集上汽车类别下本文算法(稀疏Transformer 模块)与PointPillars算法(普通Transformer 模块)的mAP 对比如表5 所示。手动在每个目标物真值框内随机添加100 个噪点,本文算法的mAP 仅下降1.60%,优于PointPillars算法。
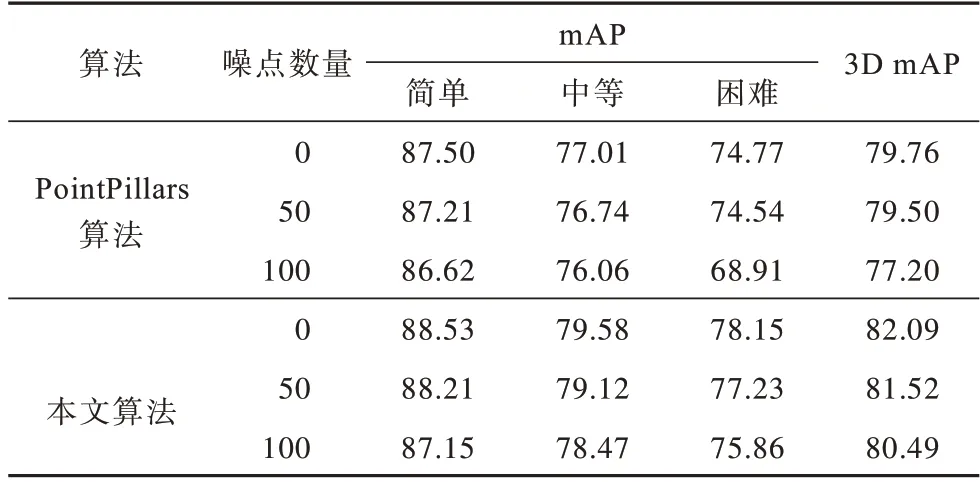
表5 在不同噪点数量下PointPillars 和本文算法的mAP 对比Table 5 mAP comparison among PointPillars and the proposed algorithms with different number of noises %
2.3.3 粗回归模块对结果的影响
在不改动其余模块的情况下,本文去掉粗回归模块的回归分支,以验证粗回归模块的有效性。本文算法1 不包含粗回归模块,本文算法2 包含粗回归模块。本文算法在KITTI 测试集上汽车、行人和骑行者类别下的实验结果分别如表6、表7 和表8 所示。从表中可以看出,相比不包含粗回归模块算法的测试结果,在不同检测难度下有粗回归模块算法的mAP 分别提升了0.61、1.01 和0.95 个百分点。因此,包含粗回归模块的算法能够更精确地回归目标物体的坐标。
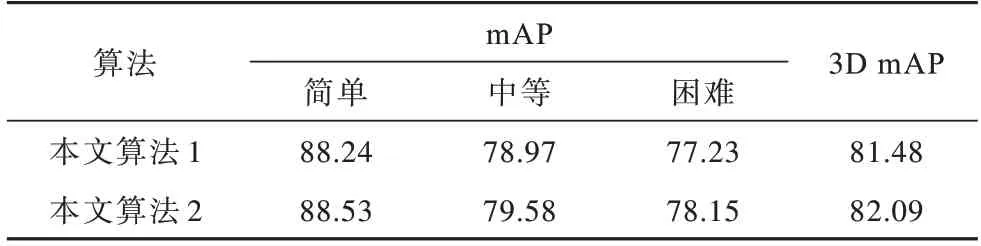
表6 在汽车类别下粗回归模块对检测精度的影响Table 6 Influence of coarse regression module on detection accuracy under car category %
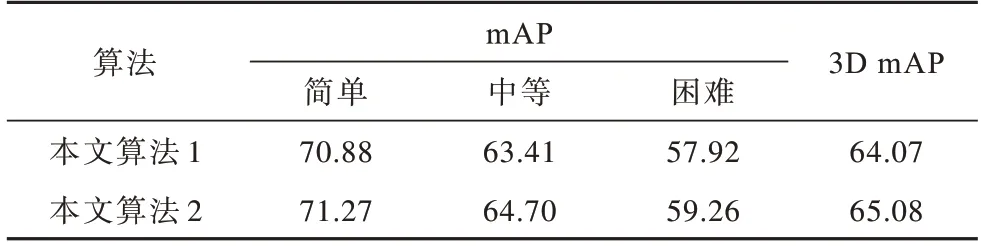
表7 在行人类别下粗回归模块对检测精度的影响Table 7 Influence of coarse regression module on detection accuracy under pedestrian category %
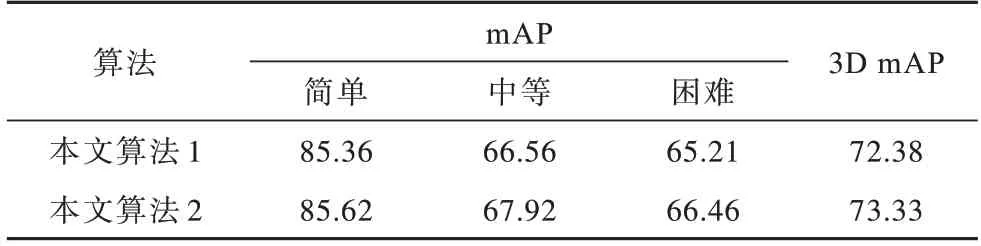
表8 在骑行者类别下粗回归模块对检测精度的影响Table 8 Influence of coarse regression module on detection accuracy under cyclist category %
3 结束语
本文提出基于稀疏Transformer 的点云三维目标检测算法。通过稀疏Transformer 模块显示选择与注意力相关的信息,以学习点云的全局上下文特征,从而提高模型的精确度。设计基于空间特征的粗回归模块,将其生成的初始锚框作为后续回归精确操作的边界框。在KITTI 数据集上的实验结果表明,本文算法具有较优的检测精度和鲁棒性。下一步将在点云处理阶段引入点云关键点的采样信息,结合基于关键点和基于体素点云处理算法的优点,设计一种融合特征提取与体素关键点的目标检测算法,以扩大检测网络的感受野并提高定位精度。
