基于UV 贴图优化人体特征的行人重识别
2023-01-09徐智明
徐智明,戚 湧
(南京理工大学计算机科学与工程学院,南京 210094)
0 概述
行人重识别是智能交通、计算机视觉等领域的研究热点,其目标是在不同拍摄环境下通过对行人身份进行精确匹配,判断不同角度、不同时刻所拍摄的行人图像与给定行人是否为同一目标,从而有效节省检索特定行人所需的时间。
现有行人重识别主要包括基于度量学习、基于深度特征学习的方法。基于度量学习的方法首先使用卷积神经网络(Convolutional Neural Network,CNN)从图像中提取特征图,通过优化特征图之间的特征距离来增强行人之间的判别性,通常使用余弦距离、欧式距离[1]或马氏距离[2]计算特征图的相似度,使用Triplet Loss[3]、Focal Loss[4]、Circle Loss[5]等损失函数优化特征图之间的特征距离,使得特征图之间实现类类聚合且类间分离。
随着深度学习的快速发展,许多研究人员开始将深度学习方法应用于行人重识别任务中。基于深度特征学习的行人重识别主要分为基于局部特征学习、基于注意力机制学习、基于生成对抗网络(Generative Adversarial Network,GAN)学习这三类。
早期的研究工作主要关注全局特征,由于通过全局特征无法针对性地学习到行人的细粒度特征,因此学者们开始聚焦于局部特征。PCB[6]将行人特征按照水平方向均匀切分,然后在每一个切分的特征图上进行表征学习,并设计RPP 模块,计算各个像素的特征向量和局部平均特征向量之间的相似度,从而调整各个像素的区域归属。MGN[7]提出一种多分支网络架构,该架构由一个用于全局特征表示的分支和两个用于局部特征表示的分支组成,通过分割区域与构造分支结构的方法获得全局特征和更加细粒度的局部特征,然后对各个分支进行特征提取,将区分度较好的多粒度细节信息与行人整体信息进行融合,但是,由于构造的分支数目较多,导致MGN训练出的模型参数量庞大。
基于局部特征学习的方法有效地推进了行人重识别的发展,增强了对图片中人体不完整部分和遮挡部分的特征鲁棒性,并进一步通过引入注意力机制加强了对这些特征的学习。STA(Spatial-Temporal Attention)[8]网络中加入时空注意力机制,将特征图按照长度划分为4 个局部区域,分别提取每个部分中注意力分值最高的分区得到判别性信息。ABDNet[9]网络中加入复合注意力机制,提出将通道注意力和局部注意力相结合的行人重识别方法,其中,通道注意力机制促进了信道级、特征级的信息聚合,局部注意力捕获了身体和部分位置的有效信息,从而高效地进行深层次的特征学习。还有一些行人重识别方法,如DG-Net[10]基 于GAN 生成训练数据以提升数据量,通过生成大量数据提高模型精度,但是,由于行人重识别数据集中图像像素较低,导致生成的图像过于模糊,对模型精度提升并不明显。
现有的行人重识别研究大多学习人体在二维平面上的特征表示,往往忽略了人体自身的拓扑约束以及人体外形信息,这导致现有方法对特征学习比较局限。在现实中,人体以一种对称的三维形式存在,三维人体结构相较二维平面像素含有更多的体型、取向、外观等特征,本文认为学习有效且可扩展的行人特征的关键是要考虑人体特征在三维空间中的特征表现。例如,事先给孩子看过一张熊猫的图片,孩子在动物园中就可以立刻判别出哪种动物是熊猫,原因在于,当孩子看到一张熊猫图片时,已经在脑海中通过先验知识重构了熊猫的三维刚体模型,在动物园中看到熊猫就能立刻判别出是否为同一对象。因此,让计算机学习人体特征在三维空间中的特征表示,是当前行人重识别研究中的一项重要任务。
基于网格重构的三维人体建模方法[11-14]在近些年发展迅速,HMR[15]网络实现了端到端恢复人体三维mesh 的模型,通过输入含有人体的RGB 图片建立人体三维模型,对于三维模型的生成,主要借助SMPL 方法,将shape 和三维关节点(joints)的角度(angles)作为输入,建立三维人体模型。DecoMR[16]提出一种三维人体网格估计框架,建立三维人体模型单元网格与图像特征在UV 空间中的映射关系。OG-NET[17]网络中最早使用3D 点云数据开展行人重识别研究,在三维空间中通过生成的点云数据来实现人体匹配,利用三维空间的人体结构化信息和二维平面的外观RGB 信息来学习行人特征表示,具体地,OG-NET 首先估计三维人体模型的姿态信息,然后与二维平面中的RGB 信息进行匹配,将原始图像数据集转换为点云数据后进一步设计网络来学习点云特征。但是,OG-NET 使用3D 点云数据作为输入,3D 点云数据包含人体姿态、背景等信息,虽能大幅提高精度,但是无法提升行人重识别算法的鲁棒性。
深度学习技术的快速发展使得行人重识别的精度得到显著提升,但其仍面临由身体错位、遮挡、背景扰动、姿势不同所带来的众多挑战,且算法在不同数据集上表现出延伸性差、鲁棒性低等问题。本文提出一种基于UV 贴图优化人体特征的行人重识别方法。借助三维重构技术与人体几何信息先验知识,从含有人体图像的RGB 图片中恢复人体三维模型,以研究行人特征在三维空间中的表示为目标,建立二维图像与三维人体模型的映射关系。从特征优化角度出发,通过研究人体不变的特征,从数据中提取人体的外观、体型、视角等参数,重构出固定姿态(T-pose[18])的三维人体模型,并将三维人体模型展开到二维UV 空间中对行人特征进行优化,使得计算机可以学习到更多在二维图像中看不到的行人特征,从而提高行人重识别模型在不同数据集上的性能表现。
1 本文行人重识别方法
本文基于UV 贴图优化人体特征的行人重识别方法分为特征优化和行人重识别这2 个过程。
1.1 特征优化过程
特征优化过程分为2 个阶段,具体如下:
1)第一阶段,如图1 所示,首先对二维图像I∈R3×W×H进行特征提取,提取出形状β∈R10、姿 态θ∈R72、视角P∈R3的特征向量;然后通过姿态θ、形状β、视角P以及二维图像中的行人RGB 像素特征重构SMPL 三维人体模型M∈R6890×6,三维人体模型M由6 890 个网格顶点G∈R6890×3与RGB 像素点C∈R6890×3组成,表示相对于对应的三维人体模版上端点的偏移量与色彩像素值大小。在重构三维人体模型时,首先通过对SMPL 模型进行调整生成三维人体网格(mesh)图,然后利用视角P将二维图像中的RGB 信息映射到三维人体网格图中,生成三维人体模型。
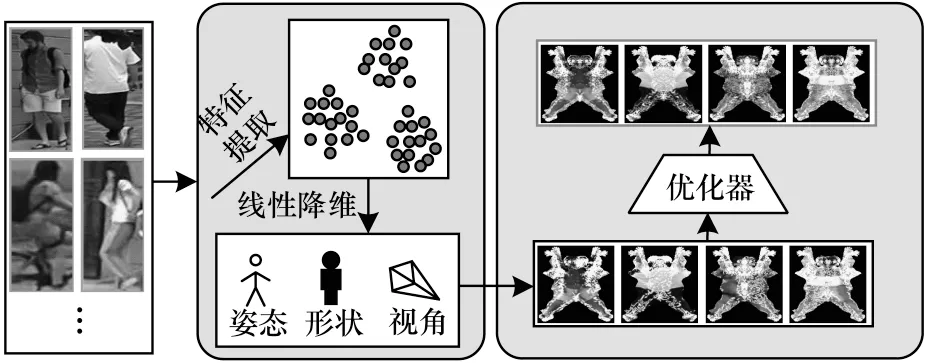
图1 UV 贴图生成过程Fig.1 UV map generation process
本文主要研究人体不变特征,由于二维图像中各个行人的姿态不同,因此通过式(1)将三维人体模型转化为统一姿态的人体模型T-pose:
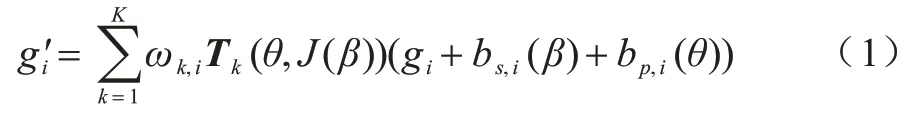
其中:gi是网格顶点G中的一个元素;bs,i(β)、bp,i(θ)分别为形状参数β的线性矩阵、姿态参数θ的线性矩阵中的元素;Tk为第k个关节点的转换矩阵。
2)第二阶段,将重构后的三维人体模型转化到UV 空间中进行优化,建立三维人体模型与UV 空间的映射关系,生成相对应的UV 贴图A,映射关系如下:
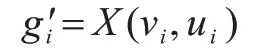
其中:是三维人体模型每个顶点的坐标;X是位置贴图;vi、ui为UV 坐标。
由于行人重识别数据集中人体特征受到不同光照与拍摄角度的影响,因此难以学习到有效的特征表达,本文通过UV 贴图来优化行人特征在三维空间中的特征表现。特征优化网络结构如图2 所示,在每个卷积层中:Conv(i,o,m×m,s)、BN、ReLU 表示输入图像的通道数是i,卷积后产生的通道数为o,卷积核大小是m×m,步长是s,卷积层后添加一个批归一化层BN 和一个激活层(激活函数采用ReLU)。特征优化过程为:对UV 贴图A进行特征提取,经过上采样与下采样后得到深度图d∈R64×64×1与色彩特征图a∈R64×64×3,通过深度图d与 色彩特征图a重构出,其中,=(a/μ+σ)×d×μ-1,μ、σ是实验中设置的权重。将进行水平翻转得到,使用L1损 失函数计算A与、A 与之间的误差,令A ≈?A ≈。损失函数如下:
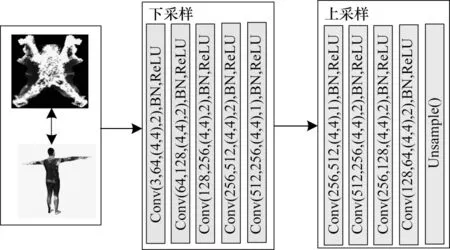
图2 特征优化网络框架Fig.2 Feature optimization network framework
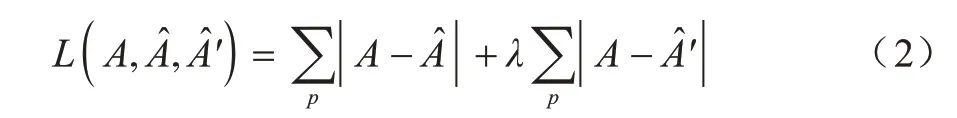
其中:λ是实验中损失函数的权重。
1.2 行人重识别过程
本节介绍行人重识别过程中使用的网络结构以及损失函数。本文通过建立行人在三维空间的特征表示,学习二维图像与三维人体的互补关系,在实验中加入了人体形状参数β进行特征学习,并使用三元组损失函数以及动量的交叉熵损失函数来增强行人特征之间的判别性,同时区分行人身份标签信息。
行人重识别模型结构如图3 所示,采用在ImageNet[19]数据集上进行预训练 的ResNest 网络作为特征提取模块,ResNest网络中加入split-Attention机制,将特征图按照通道(channel)维度分为数个Split-Attention 子块,使用注意力机制对划分的子模块进行特征聚焦,获得需要关注的行人特征信息,抑制其他无用特征,相较ResNet[20]网络,能更精确地提取到更多有用的特征。具体地,本文行人重识别网络基于改进的ResNest-50,在原始ResNest 网络的基础上将其4 层卷积输出的特征矩阵分别添加池化层(最大值池化层、全局平均池化层)与全连接层以进行特征降维,然后融合得到特征图,最后建立损失函数训练该网络。
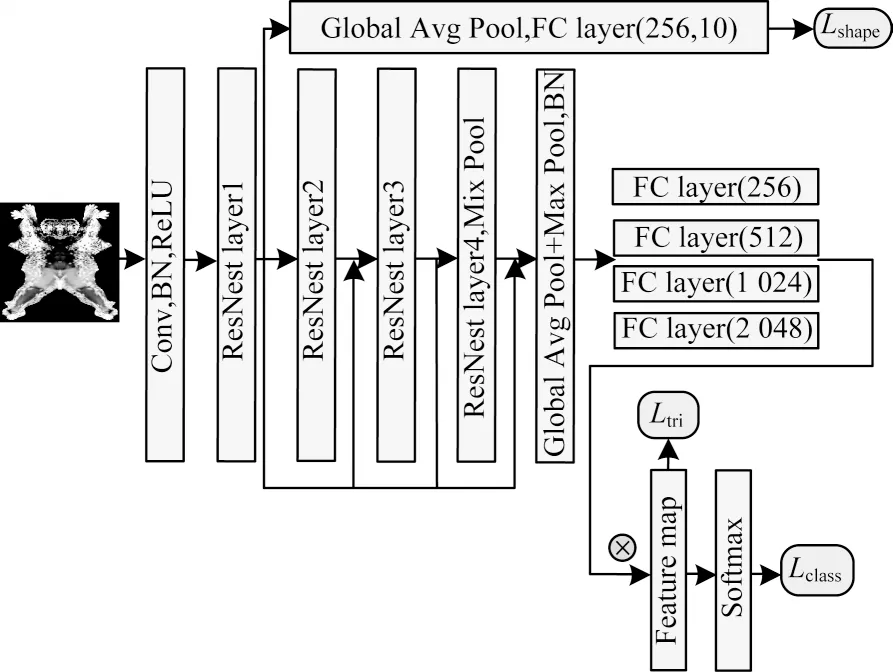
图3 行人重识别模型结构Fig.3 Person re-identification model structure
首先使用三元组损失法对特征图进行细节区分,当2 个特征图很相似时,使用三元组损失法对这2 个差异性较小的输入向量进行优化,从而学习到更优的特征表示。设样本为x,f()为正样本映射函数,f()为负样本映射函数,将正样本和负样本分开,即实现类类聚合、类间分离。三元组损失表示为:
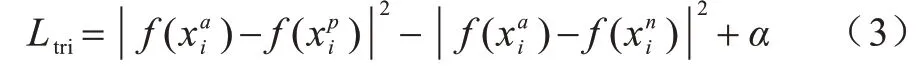
使用加入label smooth 的交叉熵损失函数来增强行人之间的判别性,计算行人图片信息之间的身份标签损失,将其记为Lid,交叉熵损失函数如下:
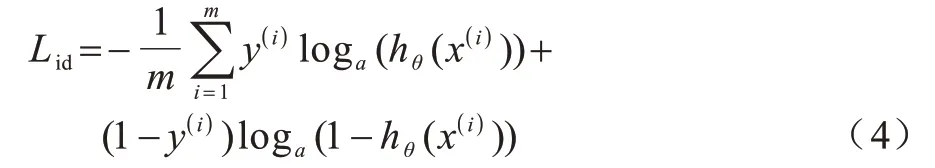
其中:hθ(x(i))是对图片信息的标签进行Softmax 操作;y(i)为对应的行人身份标签信息。
如图2 所示,由ResNest layer1 提取后的特征图经过池化层(Mix Pool)、全连接层、一个ReLU 激活层后,得到预测人体的形状参数β。在本文实验中观察到,由于人体形状参数β中的每一个参数对人体作用部位不同,因此每个参数对应的权重对网络的影响不同,通过马氏距离来构建人体形状损失函数能进一步增强行人重识别网络的判别性,该损失函数如下:
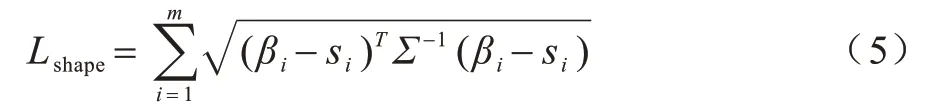
其中:βi为提取的人体形状参数样本信息;si为对应的人体形状参数标签信息。
行人重识别网络整体损失函数表示为:
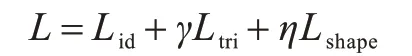
其中:γ、η为损失函数的权重。
2 实验结果与分析
2.1 实验设置
本次实验设置具体如下:
1)数据集。在Market-1501[21]、DukeMTMC-reID[22]、MSMT17[23]等行人重识别数据集上进行大量实验,以验证所提方法的有效性。
2)数据预处理:
(1)由于图像底库中图片的分辨率大小不同,因此将图片调整为统一大小的图像。
(2)在深度学习模型的训练过程中,数据量的大小将严重影响模型的准确率,因此,通过Rand Augment数据增广方法生成大量的训练数据,对输入图像进行随机裁剪、水平翻转、应用仿射变换、平移、旋转、剪切等变换方式来扩充训练数据,从而在训练过程中减小参数空间,同时保持图像数据的多样性,有助于防止数据过拟合现象的发生。
3)评价指标。本文使用平均正确率均值(mAP)和匹配率(rank-i)这2 个指标来衡量行人重识别方法的性能。
4)实验环境。使用Pytorch1.6 深度学习框架进行代码编写,在配置64 GB 内存、Hygon C86 7185 32-core 处理器和NVIDIA Tesla V100 GPU 的服务器上进行实验。
5)训练策略。本文使用apex 混合精度方法加速神经网络训练,该网络每个批次输入图像为256 张,输入图像大小为384×128 像素。采用SGD 损失函数优化器优化整个行人重识别网络,其中,动量、衰减率和初始学习率分别设置为0.5、0.000 5 和0.000 35。设计相应的训练策略加速神经网络收敛,从而提高模型精度,具体为:
(1)由于数据集各类别的图像数据量差别较大,因此本文使用均衡采样器(Balance Sampler)均匀采样不同类别中的图片,使得每一个批次中各类别图像数目相等,从而提高模型参数在训练过程中的稳定性。
(2)结合预热学习率与余弦退火动态调整学习率,通过先预热模型,即以一个较小学习率开始逐步上升到特定的学习率,使模型收敛效果更佳,且当损失函数接近全局最小值时学习率可以随着余弦函数动态减小。
(3)通过冻结骨干网络(Backbone Freeze)的训练,如冻结5 个批次的训练,将更多的资源放在训练后续部分的网络参数,使得时间和资源利用都能得到很大改善。待后续网络参数训练一段时间后再解冻这些被冻结的部分,然后所有批次一起进行训练。
6)测试过程。给定一张查询图像,提取经过批归一化模块后的特征图,使用余弦距离计算查询图像与查询底库图像间的特征距离,使用重排序(reranking)对查询结果作进一步优化,输出为从高到低排在前十位的查询结果。
2.2 定量评价
行人重识别的目标是在不同摄像头下精确捕捉同一个目标,精准学习图片中行人的特征表示。目前,多数行人重识别方法中加入背景条件,让模型学习到较多的非有效特征,虽然能够提高模型精度,但是在一定程度上对行人重识别结果造成一种误判,这也是行人重识别方法鲁棒性不高的原因。
本文首先比较二维整体特征、二维人体部分特征、三维人体部分特征、三维人体部分特征加上背景特征的输出结果。由人体与背景构成不同组合的输入数据,将其输入到模型中,对4 种数据进行相同配置的实验,得到结果如表1~表3 所示,从中可以看出,三维人体部分特征输入的检索结果不如二维整体特征,原因是:一方面人体特征从二维映射到三维时存在误差,如图2 所示,头发、衣服、背包等重要的判别信息并未完全重构;另一方面是由于三维人体部分输入没有加入背景信息,三维人体部分与二维人体部分特征(mAP 为6.75%)结果相比,mAP 达到62.21%,这表明三维位置信息与二维颜色信息互补,三维空间可以降低匹配难度,突出几何结构。
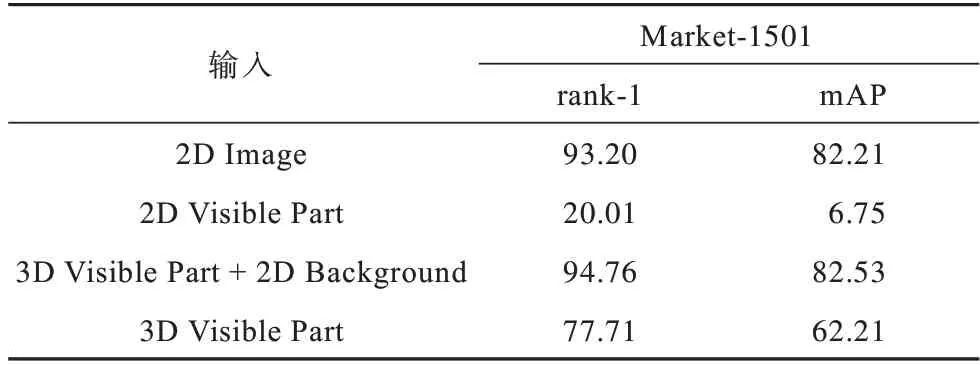
表1 Market-1501 数据集下的模型性能对比结果Table 1 Comparison results of models performance under Market-1501 dataset %
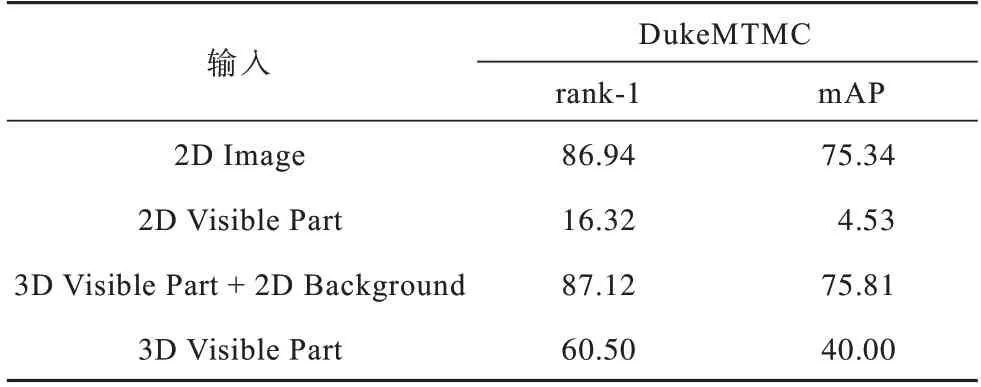
表2 DukeMTMC 数据集下的模型性能对比结果Table 2 Comparison results of models performance under DukeMTMC dataset %
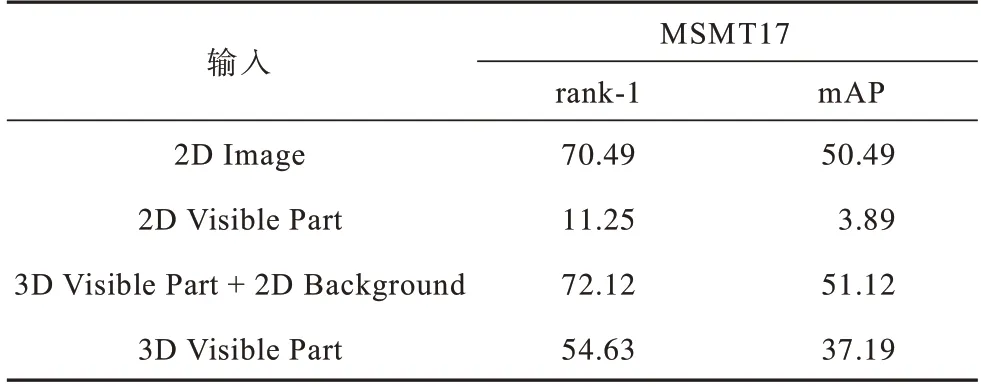
表3 MSMT17 数据集下的模型性能对比结果Table 3 Comparison results of models performance under MSMT17 dataset %
2.3 定性评价
本文通过将给定行人重识别数据集中的每一张图像转化为UV 贴图,对查询图像进行特征提取,计算其与查询底库中图像的特征距离以得到查询结果。图4 所示为查询图像、相应的UV贴图转化结果和检索到的前5 名候选人查询结果,其中,虚线框内表示错误的检索结果,其余为正确的检索结果。
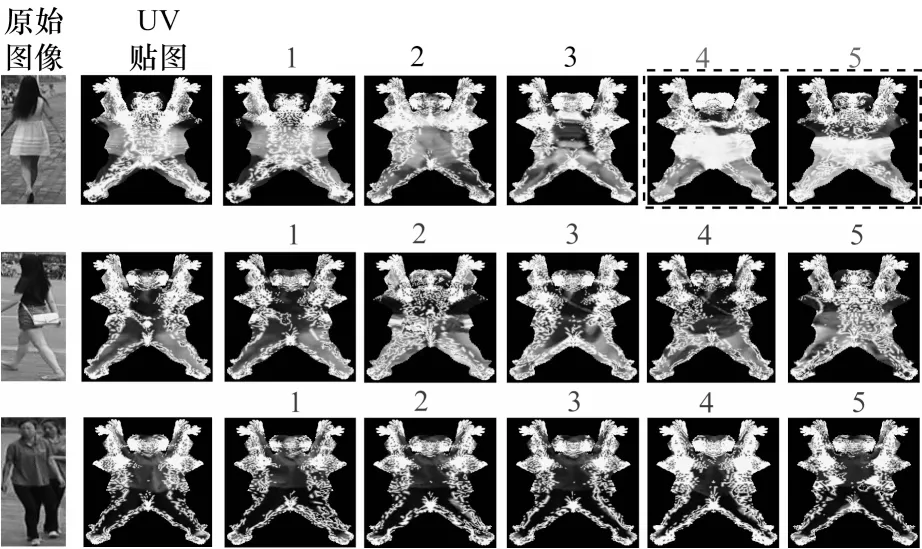
图4 检索结果可视化Fig.4 Visualization of search results
2.4 方法对比
将本文方法与先进的行人重识别方法进行比较,对比方法包括基于点云特征的学习方法(DGCNN、PointNet++、OG-Net)、基于二维图像的行人重识别方法(MGN、ABD-NET、M3-reid、VA-NET)。从表4 可以看出:1)相比点云特征学习方法,如DGCNN、PointNet++、OG-Net,本文方法的识别性能大幅提升,从而验证了该方法的正确性;2)在不添加背景条件的情况下,在3 个不同数据集上本文方法的表现与现有基于深度特征学习的方法[7-10]相近,并且可以结合现有行人重识别方法来对训练精度作进一步提升。实验结果表明,本文方法对行人重识别效果具有较好的提升作用,为行人重识别研究提供了一种新思路,其可以有效优化训练数据并提高模型的鲁棒性。在Market-1501 数据集下进行消融实验,结果如表5 所示,该结果验证了本文方法的有效性。
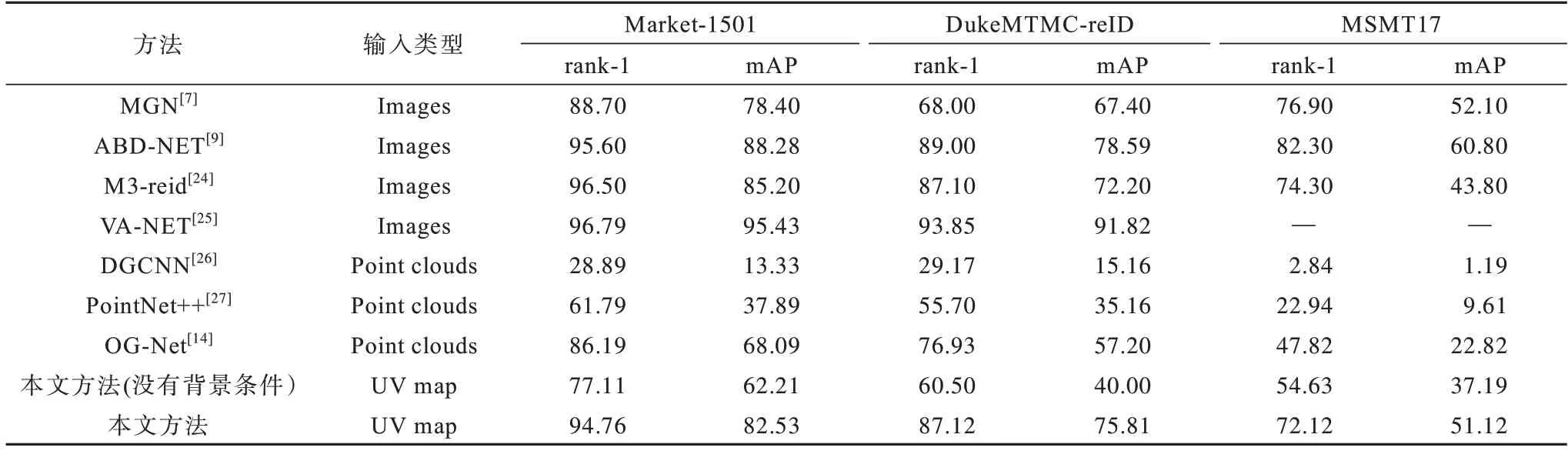
表4 各方法在3 种数据集上的性能对比结果Table 4 Performance comparison results of each method on three datasets %
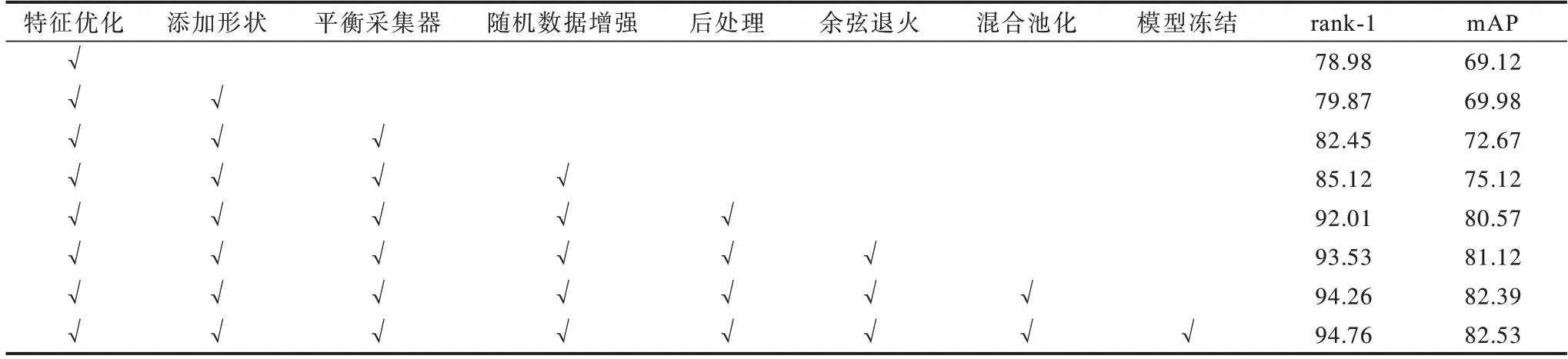
表5 Market-1501 数据集下的消融实验结果Table 5 Ablation experimental results under Market-1501 dataset %
3 结束语
本文将行人重识别研究从二维平面拓展到三维空间,提出一种基于UV 贴图优化人体特征的行人重识别方法。利用人体是一种三维对称的刚体结构这一先验事实,将图片中的部分行人特征从二维平面重构到三维空间中,从而有效扩展特征维度并提高行人特征的可优化性。将重构后的三维人体模型转化为UV 贴图,即将人体特征从三维空间映射到二维平面,从而大幅降低模型参数量,同时设计损失函数使得模型自主优化UV 贴图。为了更好地学习UV 贴图中的特征表示,设计相对应的损失函数与相关的训练策略以提高训练精度。行人重识别数据集上的实验结果表明,相较OGNset 模型,在添加背景的条件下,本文方法在Market-1501 数据集中的行人重识别rank-1 检测准确率提高13.82%,mAP 准确率提高22.56%;在不添加背景的条件下,行人重识别rank-1 检测准确率提高5.26%,mAP准确率提高13.66%。
本文方法的行人重识别性能得到一定提升,但是仍然存在以下不足:1)使用固定的三维人体模板对人体信息进行三维重构,头发、衣服、背包等具有重要判别信息的行人特征未得到具体显现;2)在行人特征优化方面,优化粒度欠佳。下一步将在三维空间中优化人体细粒度特征,增强行人特征之间的判别性,进而提高行人重识别网络的精度与鲁棒性。
