面向水稻穗上谷粒原位计数与遮挡还原的轻量级I2I深度学习方法
2023-01-08范圣哲杨智宇王文杰刘成良
范圣哲,贡 亮,杨智宇,王文杰,刘成良
(上海交通大学 机械与动力工程学院, 上海 200240)
水稻是世界上最重要的农作物之一[1-2]。在水稻生产和育种过程中,使用适当方法对水稻性状进行表型学分析具有重要的指导价值。现代化表型学分析主要由自动考种系统完成[3-4]。其中穗上谷粒原位计数是一件基础、重要而又困难的工作。由于穗上谷粒数量巨大,且图片中通常夹杂穗杆等杂物,存在严重的遮挡现象,因此是一件极具挑战性的工作。
遮挡谷粒的还原对于精准计算谷粒的几何特征具有重要意义。在现有的视觉算法中,物体遮挡会极大影响算法准确性[5-6],且缺乏有效的解决方案。
近年来,计算机视觉已在多个领域取得落地成果:如作业目标检测[7]、叶绿素含量预测[8]、植物病害检测[9]等。这些成果得益于深度学习技术的发展。在视觉领域中,深度学习的主要工具是卷积神经网络,其所能完成的任务主要可分为图像分类[10]、目标检测[11]、语义分割[12]3大类。深度学习技术在上述3大领域的出色表现使其在复杂的图像中对穗上谷粒计数成为可能。近年来,已有部分学者对使用深度学习算法进行目标计数进行了初步探索。
目前主流的目标计数方法可以分为“基于目标检测”和“基于语义分割”2大类。前者需要利用网络在图像中准确标出每个目标的位置和尺寸,故广泛应用于交通场景的检测和计数[13-14]。但现阶段在密集、模糊的场景下对各类目标进行精确检测仍是计算机视觉领域前沿的一大难题,且目标检测网络通常结构复杂,难以轻量化部署。因此,使用目标检测网络完成穗上谷粒的计数并非理想的方法。相比之下,使用语义分割网络解决谷粒计数问题仅需将图像逐像素预测为属于谷粒或背景,是一类由图像到图像 (Image to image,I2I)的二分类问题,且语义分割网络相对简单,更便于轻量化部署。目前已有多种利用语义分割算法完成颗粒计数的成功案例,其计数对象包括人类胚胎细胞[15]、植物叶片上的蚜虫[16]及高粱[17]等农作物。由此可见,使用语义分割算法实现复杂穗上场景的颗粒计数问题更具有可行性。
而被遮挡谷粒的还原问题类似于图像的语义分割,本质上也可归为I2I的映射问题。近年来,一系列学者也将语义分割的相关算法应用于RGB[18]和深度图[19]的修复任务。因此,将图像分割网络应用于遮挡谷粒的还原任务也具有可行性。
除此之外,深度模型对存储空间和算力的过高要求一直是其落地的一大阻碍。早期的大型网络如 AlexNet[20]、VGG-16[21]、ResNet-152[10]无法在移动设备有限的算力条件下部署。近年来出现了一系列针对移动端的轻量级深度学习网络和计算框架。网络架构方面,如MobileNet[22-24]使用深度可分离卷积替代传统卷积,大大降低了计算量和参数量。其V3版本结合神经架构搜索(Neural architecture search,NAS)[25]和元学习 (Meta learning)[26]技术,进一步优化了模型性能、降低了计算量和参数量。除此之外,MobileNet V3与 DeepLab系列的ASPP[27]技术结合,便可在轻量级设备上完成语义分割。计算框架方面,在TensorFlow框架中,开发人员针对边缘计算设备设计了TensorFlow Lite runtime (TF Lite)解释器,以便在边缘设备上完成轻量级模型的调用。
基于上述背景和技术条件,本文提出了一种轻量级I2I穗上谷粒表型分析方法,针对稻穗上谷粒原位计数与被遮挡谷粒还原这2个复杂任务进行阶段分解,将其核心阶段建模为一类I2I问题。在此基础上基于现有的考种机设备,为穗上谷粒计数和遮挡谷粒还原任务分别设计了一套训练集图像增广算法,基于MobileNet V3和ASPP模块建立了一套解决I2I问题的语义分割网络,将其分别应用于上述2个任务。使用TF Lite解释器将算法部署在考种机的树莓派设备上,并为穗上谷粒计数和遮挡谷粒还原任务分别设计了一套模型性能的评估方案。
1 问题建模与数据集制作
1.1 I2I问题与方法
在制作数据集前首先需要对问题加以建模和定义。对自动化考种机而言,进行穗上稻粒原位计数与被遮挡谷粒还原对高效、准确地完成水稻表型学分析具有重要意义。由于原位计数和遮挡还原这2种任务过程十分复杂、需要实现的目标相差较大,在传统的考种机算法框架下,解决这2种任务的方法很难统一。本文通过对任务的拆解,一方面将复杂的、难以实现的任务整体拆分为若干个简单的、容易实现的算法单元,另一方面将上述2种任务的核心阶段统一建模为1种I2I的映射问题。
具体而言,在本文考种机算法的框架下,完成穗上谷粒计数任务的算法被拆解为如下2个阶段:1)由谷粒稻穗图片得到谷粒分布概率图;2)将谷粒分布概率图先进行二值化,再将二值图进行连通域计数,即可得到穗上谷粒的数量。其中第2阶段是1个简单问题:图像二值化可以使用大津法(OTSU)完成,连通域计数可以使用openCV中的findContours函数完成,二者在传统数字图像处理领域中都有十分成熟的解决方案。而第1阶段是1个复杂问题:由复杂的穗上谷粒图像得到谷粒分布概率图目前尚无现成的解决方案。但这一问题本质上是由RGB图像到灰度图的映射,因此可以归纳为I2I问题。
类似地,被遮挡谷粒的还原问题也可被拆解为如下2个阶段:1)提取和移除“相互遮挡谷粒对”中的上层谷粒;2)将残缺的下层谷粒进行补全。其中第1阶段是1个简单问题:由于“相互遮挡谷粒对”中的上层谷粒有清晰明显的轮廓边界,使用分水岭、小波等传统图像分割算法便可以得到非常理想的结果。而第2阶段是1个复杂问题:被遮挡的下层谷粒轮廓残缺不全,部分颜色、纹理细节丢失,因此完成图像恢复是很困难的工作。由被遮挡的谷粒图像得到完整的谷粒图像,其本质上是RGB图像到RGB图像的映射问题,故也可以建模为一种I2I问题。
综上所述,这2种任务中最困难且最核心的阶段都可以建模为一类I2I的映射问题,本文将解决这一类问题的方法定义为I2I方法。由于原位计数和遮挡还原任务中的I2I问题都十分困难,本文为这2种任务设计1种基于卷积神经网络和深度学习的I2I方法。而由于I2I问题均具有“由图像到图像映射”的显著共性,因此,本文为解决原位计数和遮挡还原的深度学习I2I方法设计一种统一网络框架。
1.2 穗上谷粒原位计数数据集的制作
深度学习是一种基于统计学习的方法,其本质是寻找由输入分布至输出分布的一种映射关系,因此使用深度学习方法解决I2I问题,首先需要制作足够的试验样本,以便后续针对数据集特点设计算法。应用于深度学习算法的数据集通常包括训练集和测试集2部分。
1.2.1 训练集制作试验使用的水稻样品为籼稻品种‘JP69’和‘交源5A’杂交所得的重组近交系群体,种植于上海市闵行区 (N 31.03°、E 121.45°)的试验田中。所使用的试验样本同时包括乳熟期、蜡熟期、完熟期3个阶段。水稻图像由上海交通大学贡亮副研究员所在实验室自制的考种机于2018年3月采集。原始数据集的RGB图像(如图1a所示)共45张,图像中的谷穗经吸铁石压块固定,背景板为塑料材质且略有反光,上方由LED光源照明。

图1 谷粒计数网络训练数据Fig. 1 Training data of grain counting network
在深度监督学习任务中,需要一定数量的人工标记样本作为标签。标注过程中,考虑到完整标注谷粒形状的成本过于昂贵,且难以分辨黏连的谷粒,因此仅采用绿色圆点标记对谷粒进行大致标注。标记点的尺寸也需适中:过大的标记易导致标记间相互重叠,从而影响分割算法的精度;过小的标记会造成模型对于标记的位置过于敏感,且加剧样本不均问题。经试验测定,使用谷粒平均面积的30%,即直径约4 mm的标记,效果为佳。标注后的训练图像如图1b所示,其中单独提取的标签图像如图1c所示。标签图像是单通道二值图像,属于谷粒的像素位置被标注为1,其余位置被标注为0。对于用于语义分割的神经网络,模型的输出应当与该标签图像保持尽量小的误差。
数据集中图像的像素分辨率高达 2 448×3 264,不宜直接输入网络:由于图像尺寸过大且需计数的谷粒小而多,若通过缩小尺寸的方式输入网络,将导致谷粒细节丢失、难以分辨,从而大大影响计数的精度;而如果保持图像的尺寸不变但增加网络的输入尺寸,将引起网络的参数急剧增加,不仅容易发生过拟合,还会急剧提升所需的存储空间和计算量,致使模型过度臃肿而难以在移动端部署。
为解决输入尺寸过大的问题,图像输入网络前将进行预切块操作。为保证样本切块的随机性和前景、背景像素数量的均衡性,切块策略被设计为2个交替执行的阶段:第1阶段使用完全随机的策略在原尺寸的图像中采集像素为 4 89×652的图像块若干,第2阶段将丢弃谷粒标注面积占比小于全图面积0.01%的图像块。经过第2阶段的筛选,不含谷粒的图像块将被过滤,这将保证训练集中的前景、背景像素所占比例与实际情况相差不大。2个阶段将反复执行,直至每张原始图像中均已采集20张不含纯背景的图像块,最终得到900张图像块用于深度网络的训练。
为使训练集中的图像样本能够尽可能逼近复杂的真实情况,同时提升深度模型的泛化能力以及降低过拟合的风险,需要对已生成的训练集图像进行样本增强:采用TensorFlow提供的tf.data模块将图像通过随机翻转、随机放缩、随机亮度、随机对比度、随机饱和度等方式进行增广。除此之外为方便运算,将所有图像块尺寸取整缩放至 4 90×650。得到的训练图像块样本如图2所示。

图2 经分块后的图像块样本Fig. 2 Image block samples after slicing
1.2.2 测试集制作 测试集用来测试模型训练后的性能,因此在模型预测时需保证图像各分块的相对位置不变,故图像块不再随机采样,而是将图像按顺序切块。测试的图像块尺寸与训练集保持一致,即490像素×650像素。当图像块的尺寸不足490×650时,直接缩放至该尺寸。模型推理完成后,将各个结果的图像块按顺序恢复至原大小和位置,即可得到模型预测的完整谷粒分布概率图。
1.3 谷粒去遮挡任务数据集的制作
在制作被遮挡谷粒还原任务的数据集时,若使用考种机采集真实的“相互遮挡谷粒对”图像,将存在下列问题:1)需要大量的试验操作,数据采集工作量大、周期长;2)在由“相互遮挡谷粒对”采集下层被遮挡谷粒图像时,需要手动移除上层谷粒,不可避免地会触碰到下层谷粒,从而引入位置误差,数据集的精度将难以保证。
为解决上述2点问题,本文采用计算机生成的模拟数据集完成谷粒去遮挡任务。具体而言,使用空白谷粒形状遮挡单个谷粒的图像作为被遮挡谷粒的图像样本,即模拟经第1阶段处理后已去除上层谷粒后的图像,如图3所示。该数据集原始的图像尺寸为64像素×64像素,由于尺寸太小会影响模型的计算,输入模型前将图像缩放至1 2 8×128。原始数据集由100张图片构成,通过随机旋转、随机亮度等方式,数据集被增广至8 000张。

图3 遮挡还原图像样本示例Fig. 3 Samples of occlusion restoration images
2 解决I2I问题的轻量级网络
穗上谷粒原位计数的第1阶段“由谷粒稻穗图片得到谷粒分布概率图”及被遮挡谷粒还原任务的第2阶段“将残缺的下层谷粒进行补全”均为I2I问题,而深度学习中的语义分割网络可以解决I2I问题。此外,由于算法部署在考种机的树莓派开发板上,需要严格控制所需算力和模型体积,故选用带有ASPP模块的MobileNet V3轻量级网络。该网络保持了MobileNet系列深度可分离卷积的传统,大大压缩了计算量、提高了运算效率。除此之外,MobileNet V3网络在前代的基础上引入了Squeese-and-Excite结构,在前代Swish函数[28]的基础上提出了h-Swish激活函数:
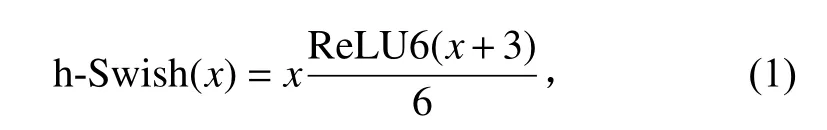
式中:x代表激活函数输入的自变量,ReLU6[22]是对ReLU激活函数的优化。
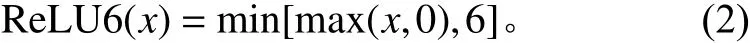
MobileNet V3使用神经架构搜索技术进行网络结构的搜索,从而进一步优化网络的性能。MobileNet V3有 Large和 Small 2个版本,为了尽可能地提升在边缘设备的计算性能,本文选用文献[24]提出的Small版本的网络。在此网络基础上,针对穗上谷粒计数和遮挡谷粒还原任务的不同特点,将算法设计如下。
2.1 穗上谷粒计数网络设计
在该任务中,网络需要预测每个像素点属于谷粒标记(前景)还是背景,所以是分类问题。完成这一任务的网络结构如图4所示。网络的输出是分别对应于正样本(谷粒标记)和负样本(背景)的2张概率图。由于最后一层前logits值被Softmax函数激活,得到的2张概率图对应位置的概率加和等于1。

图4 用于谷粒分割的MobileNet V3网络Fig. 4 MobileNet V3 network used for grain segmentation
由于该问题被建模为分类问题,根据极大似然估计原理,该模型的损失函数使用交叉熵(Cross entropy loss,CE Loss),即对于每个像素点的损失(l)可计算如下:
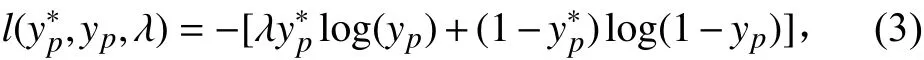
对于每个训练批次(Mini-batch)而言,损失可计算如下:
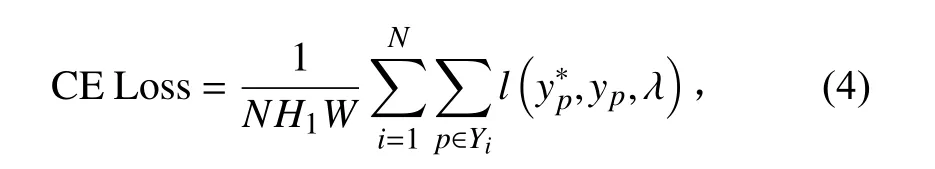
为在宏观尺度衡量语义分割的准确度,本文使用交并比 (Intersection over union,IoU)作为评估指标。以0.5为阈值对模型的输出概率图做二值化后,按下式与真实标签图像求IoU:
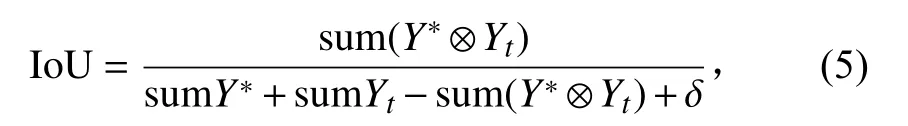
为了避免大量繁复的调参工作,本文选用初始学习率为0.001的Adam优化器[29],对比了带重启的余弦学习率衰减策略[30]以及指数衰减策略。这2种学习率衰减策略的情况如图5a所示。经过50轮的训练,2种学习率衰减策略在训练集上的损失函数如图5b所示。由此可见,在该任务中指数衰减策略的表现优于余弦衰减策略。故使用指数衰减策略完成网络的训练。
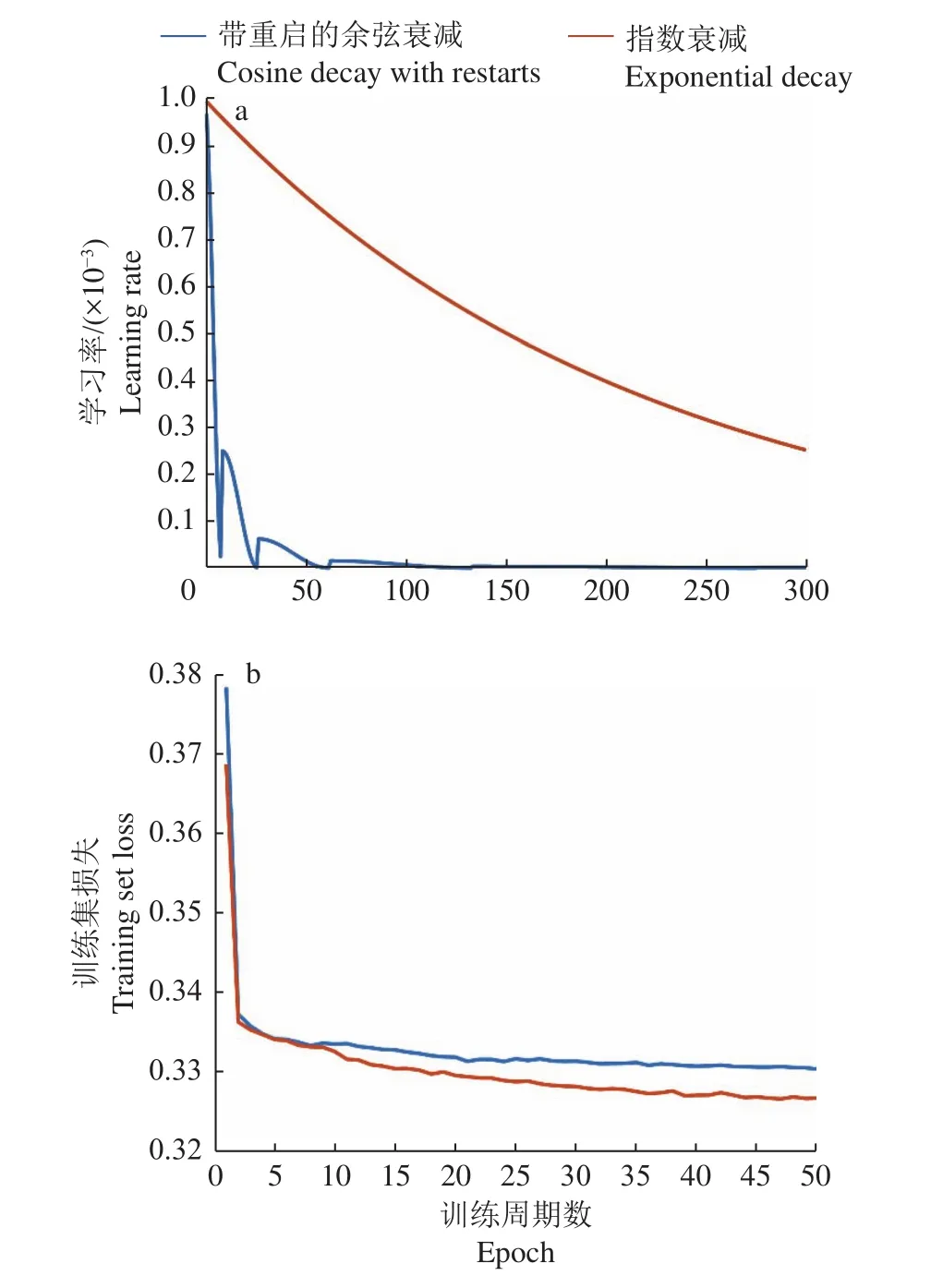
图5 2种学习率衰减策略Fig. 5 Two strategies of learning rate decay
2.2 遮挡谷粒还原网络设计
该任务本质上是一种回归问题,完成被遮挡谷粒还原任务的网络结构如图6所示。模型的输入为被遮挡的谷粒图像,模型的输出是完整的谷粒图像。遮挡还原任务中,网络不仅需要保持输入图像中未被遮挡的部分,还需要还原已被遮挡的部分。

图6 遮挡谷粒还原的网络架构Fig. 6 Network structure for occluded grain restoration
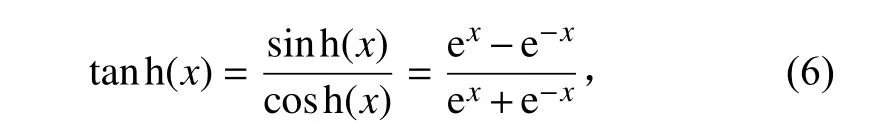
式中:x表示激活函数输入的自变量。
除此之外,由于该模型完成回归任务,故采用均方误差损失函数 (Mean square error loss,MSE Loss)。对于每个Mini-batch,其计算式如下:
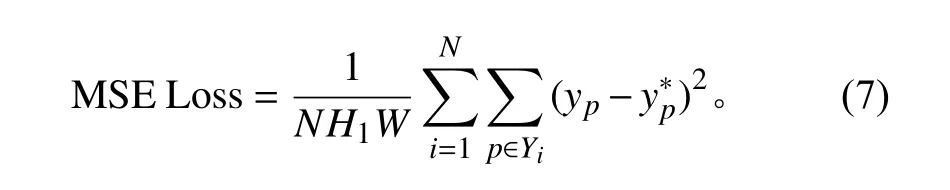
3 计数网络的训练、测试和部署
在建立训练集、测试集和确定网络结构后,需对网络进行训练。为在多个训练模型中挑选最优的模型,需在验证集中对网络的性能进行评估。在验证集中表现最优的模型将被选择为最终部署的模型,通过TensorFlow导出并使用TF Lite解释器在考种机的开发板-树莓派端进行部署。最终,为测试模型在树莓派上运行的性能,将整个测试集在树莓派上进行推理,与人工标注的结果进行比对,得到模型的准确率和运行效率。
3.1 谷粒计数网络的训练
按照“1 问题建模与数据集制作”所述的方法分别建立容量为900的训练集和验证集,每轮的训练阶段使用全部的训练集数据,验证阶段在验证集中抽取10个Mini-batch完成验证。该模型训练过程中的各个超参数为初始学习率0.001、衰减步数2 000、衰减率 0.96、批容量 4、总轮数 300。
将每轮训练在训练集和验证集上的平均损失和IoU绘制成折线图(图7)。随着训练过程的不断推进,模型在训练集和验证集的损失和IoU虽有小幅波动,但最终趋于收敛。模型在验证集的损失降至0.33以下,IoU上升至0.98以上。
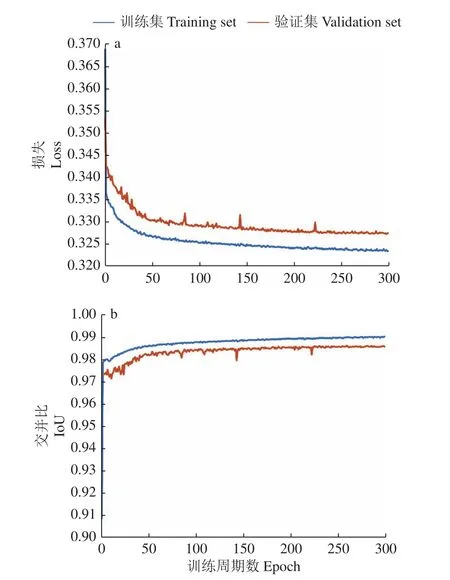
图7 损失(a)和交并比(b)的可视化Fig. 7 Visualization of loss (a) and IoU (b)
为更加直观地考察模型的性能,将最优的模型参数保存,部分预测结果可视化如图8所示。该模型对于谷粒相对稀疏的位置能够比较精确地预测,而对于谷粒较为密集位置预测的置信度相对欠佳,但准确率尚可。这是由于谷粒密集处谷粒间相互遮挡和变形严重,识别难度将大大增加。
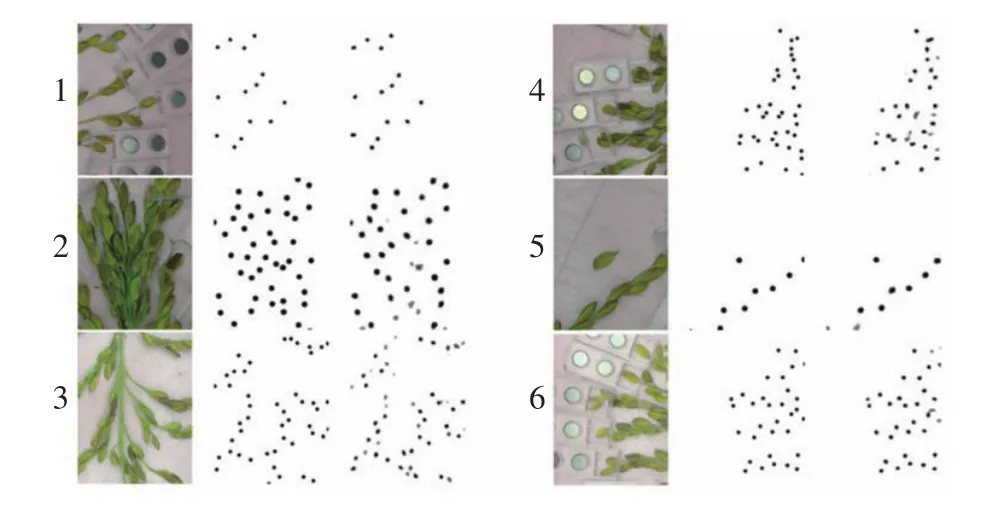
图8 6组遮挡还原图像样本Fig. 8 Samples of six sets of occlusion restoration image
3.2 部署、测试与评估
3.2.1 模型部署该模型在树莓派4B开发板的部署使用TF Lite解释器完成。经优化后的MobileNet V3模型文件仅占1.7 MB,在PC端前向推理1次需7 s左右,在树莓派4B开发板运行1次前向推理耗时约19 s。本文提出的算法模型的体积(1.7 MB)低于文献[31]提出的算法模型的体积(H=48、K=10:8.8 MB、H=80、K=16:22.5 MB,H=112、K=24:50.5 MB,H=160、K=32:89.8 MB),本文提出的算法具有明显的轻量级特点。
为了使本文算法与多种分辨率的移动设备相兼容,在进行前向推理时,完整的图片将被按照490×650的大小切分成40块,对于尺寸不足该大小的块,使用双线性插值算法上采样到该尺寸。若图像被切分的块数不足40,将补0至40块。为充分发挥并行计算的优势,该40个图像块将被打包成1个 Batch size为 40的 Mini-batch 输入 TF Lite解释器,进行前向推理得到40个结果图像。该40张结果图像将按照原来的尺寸和位置被拼成1张完整图片。将模型输出的2张概率图使用大津法进行二值化,二值图中为1的部分将被标记为谷粒,且使用蓝色被标注在原图像上,得到的结果如图9所示。

图9 穗上谷粒计数结果的可视化Fig. 9 Visualization of on-panicle grain counting results
3.2.2 常规测试集下的评估采集45张与训练集背景、光照条件完全一致的图像作为测试集,如图9a所示。由图9b结果可见,该算法对于穗上谷粒的计数总体上较为精确。考虑到训练时模型对于谷粒相对密集区域的预测难度较大,故将该测试图像谷粒最密集的区域放大,如图10所示。

图10 谷粒计数结果及其局部放大图像Fig. 10 Grain counting result and its local magnification image
由图10可以看出,该算法在谷粒相对密集的区域也有不俗的标记效果,对于饱满粒的识别较为精确,对于瘪粒和遮挡粒仅有少量遗漏。在45张测试样本上测试该模型的性能,得到模型的平均准确率为96.81%,超过了文献[32]中小波方法的准确率(94%)及文献[33]中P-TRAP算法的准确率(86%)。
另外,为了评估模型在不同切片大小情况下的性能,选取6种不同尺寸但长宽比相同的切片,测试结果如表1所示。可以看到,所选用的650×490是使得模型性能最优的切片尺寸,其余尺寸均会一定程度上损伤性能,且过大的切片会严重影响模型性能。
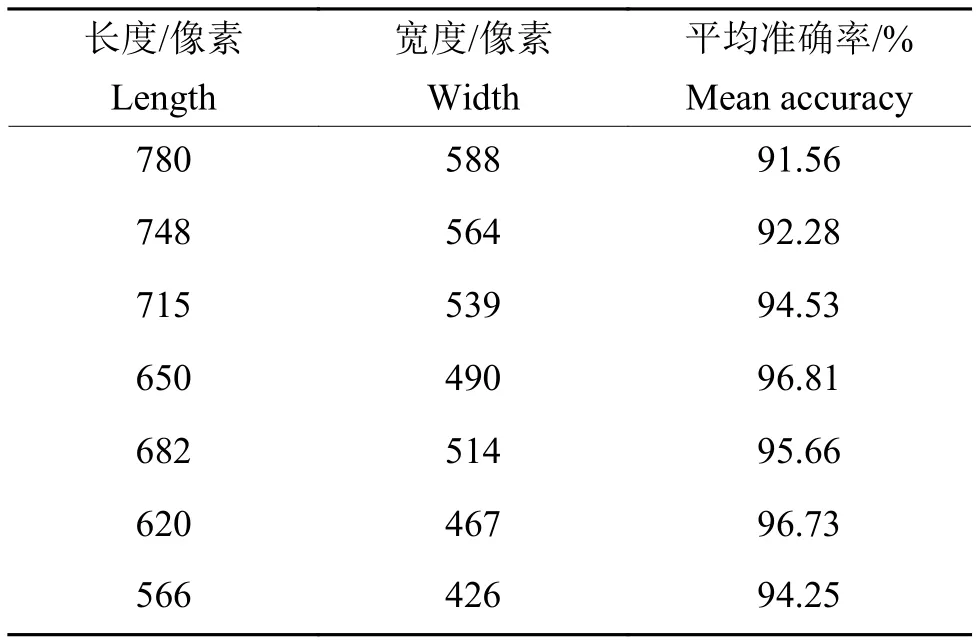
表1 不同切片尺寸下算法的准确率对比Table 1 Accuracy comparison of algorithms for different slicing sizes
3.2.3 域偏移测试集下的评估常规测试集中测得的准确率能够体现该模型的基本性能,但却无法衡量模型的泛化性能。模型的泛化性能是模型投入实际应用所需要的一项重要指标,它体现了算法对环境的鲁棒性。在存在域偏移的测试集下测试模型性能能够很好地体现模型的泛化性。
在统计学中,传统测试集的数据分布应当与训练集数据分布共同服从于总体分布,而存在域偏移的数据集中,测试集与训练集的数据分布服从各自的总体,具有明显的区别。由于其违背训练集、测试集共同服从于总体分布的统计假设,深度学习模型在域偏移数据集下的准确率往往会大幅下降[34]。
为采集具有域偏移的图像样本,使用来自五常市古农水稻种植专业合作社的稻花香‘五优稻4号’水稻,在新一代考种机平台上以不同的背景和光照条件采集50张如图11所示的图像。新版本的考种机将原有的顶光灯拍照更改为背光灯拍照,且将图像的背景由白色塑料板更改为蓝色背景板。除此之外,由于图像采集的季节并非水稻收获季节,用于采集图像的稻穗样本是枯黄的陈年样本。以上诸多因素导致新采集的图像已经与原图像相差甚远,为算法的泛化能力和鲁棒性带来了很大挑战。
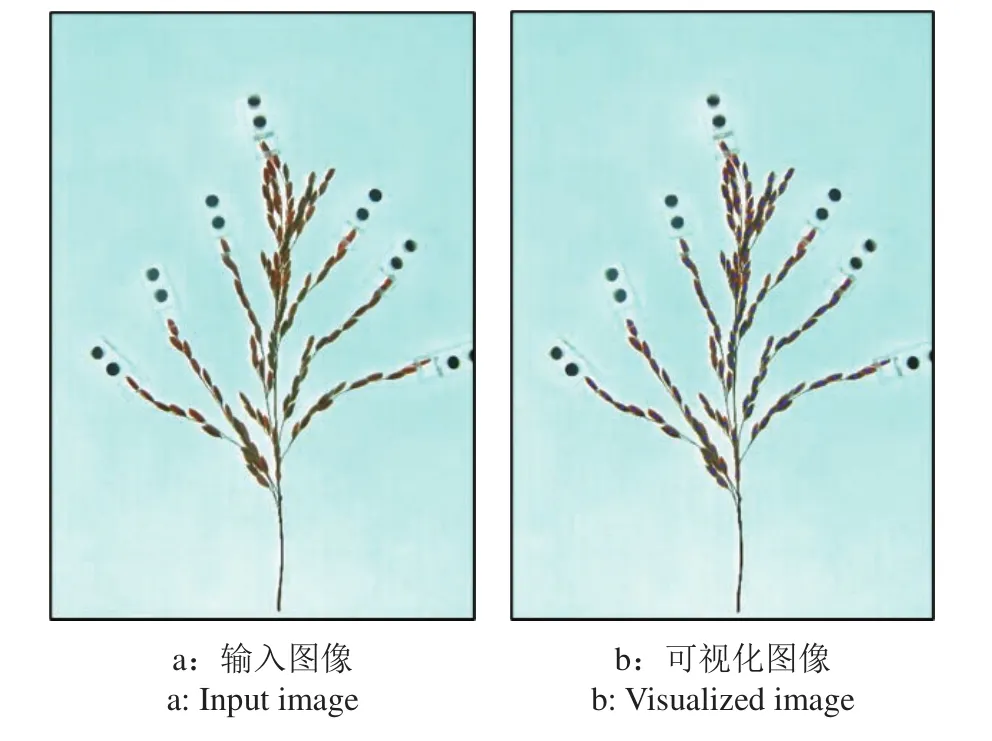
图11 新采集样本的计数结果Fig. 11 Counting results on newly collected samples
从图11可以看出,该算法对于新采集的图像样本总体上也有较好的识别效果。为进一步考量算法的性能,将图像中谷粒较为密集的区域放大,如图12所示。
如图12所示,在该区域内算法能够标记出绝大部分谷粒,个别谷粒的标记较小但仍有标记。按照连通域计数算法的要求,图像中所有出现标记的连续区域无论大小都会被标记为谷粒,因此这些谷粒也会被计算在其中。总体而言,在该区域仅有小部分被遮挡严重的谷粒未能被标记,该算法在新采集的图像中表现良好。
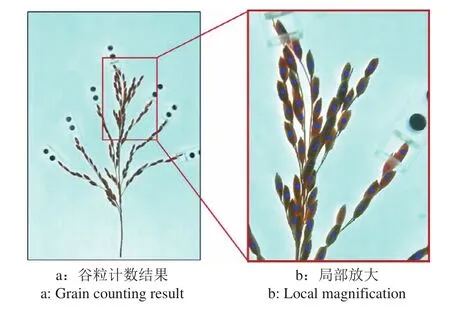
图12 域偏移数据集下的谷粒计数结果及其局部放大图像Fig. 12 Grain counting result and its local magnification image under domain shift data set
为不失一般性,在新采集的50张图像中对谷粒计数算法进行准确率计算,结果为76.17%,相比常规测试集下降20.64%。如文献[34]所述,大多深度学习模型在存在域偏移的数据集下性能将下跌30%以上,相比较而言,本文的算法在新采集的样本集上也有一定的泛化性能,且未来通过域适应的方法,性能有进一步提升的空间。
4 遮挡还原网络的训练和测试
4.1 遮挡还原网络的训练
由于训练的过程与谷粒计数的网络别无二致,此处不再赘述。训练使用的超参数为初始学习率0.01,学习率衰减策略为带重启的余弦衰减策略,批容量为8,总轮数为300。
其中关于余弦衰减的参数为学习率衰减步数1 000,学习率衰减率 0.96,t_mul参数 2.0,m_mul参数 0.25,alpha参数 0.000 1。
4.2 测试与评估
使用部分新图像测试模型的性能,可视化结果如图13所示。从图13可以看出,该遮挡还原网络能够比较好地还原谷粒缺失区域的大致形状和颜色,但是网络恢复的区域相对比较模糊,纹理等细节也随之丢失,细节方面相较于计算机视觉图像恢复领域中主流的Conditional GAN[35]虽有一定的距离,但对于几何特征能够比较好地还原,已经可以满足考种机对集合形状测量的要求。

图13 遮挡还原结果示例Fig. 13 Example of occlusion restoration result
为准确量化模型的效果,使用100张图像组成的测试集对该遮挡还原模型的性能进行评估。使用面积、周长、长度、宽度、颜色分数5个指标进行评估。其中颜色分数指标定义为下式:
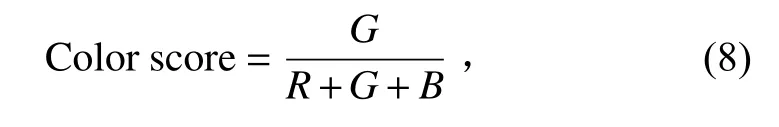
式中:R、G、B分别表示红色、绿色、蓝色的像素点数。
本文提出的遮挡还原算法与文献[31]提出的遮挡还原算法的平均准确率对比如表2所示。从统计结果可以看出,本文提出的算法在大部分指标中均超过文献[31]所提出的算法。对于考种机的使用需求而言,该模型能够十分准确地恢复谷粒图像的几何特征,且保持了模型的轻量级特点。
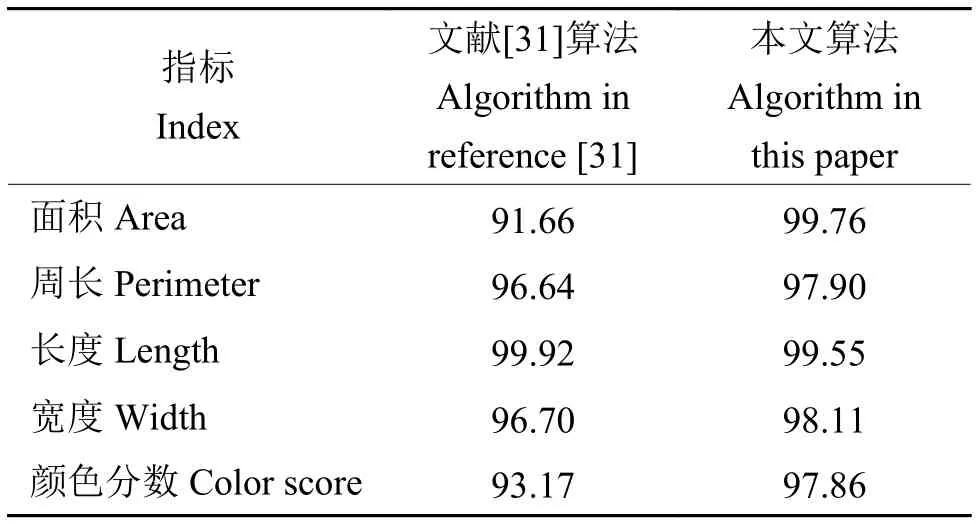
表2 遮挡还原模型的平均准确率对比Table 2 Comparison of average accuracy of occlusion restoring model%
5 结论
本文针对自动化考种机设计了一种基于深度学习的轻量级I2I水稻穗上谷粒表型分析算法框架。针对水稻考种机的穗上谷粒原位计数任务和被遮挡谷粒还原任务,本文将复杂的、难以实现的任务整体拆分为若干个简单的、容易实现的算法单元,并将上述2种任务的核心阶段统一建模为I2I的映射问题。针对这2种I2I问题,本文根据任务特点分别设计了样本集的制作方法,改造了轻量级卷积神经网络MobileNet V3,使其适用于I2I问题,选择了合理的优化器和超参数对其进行训练,并使用TF Lite将其部署在考种机的树莓派4B开发板上。
为了验证模型的效果,分别为原位计数和遮挡还原任务建立相应的测试集。经测试,该算法在穗上谷粒原位计数任务中平均准确率为96.81%,明显优于现有方法;该算法模型体积仅为1.7 MB,能够在树莓派4B开发板上以每次前向推理耗时约19 s的速度运行,具有轻量级和快速性的特点;该模型于存在域偏移的样本集上准确率为76.17%,相比原测试集下降20.64%,低于大部分模型的下降比例,说明该模型具有一定的泛化能力,且未来通过域适应的方法准确率还有进一步提升的空间。该算法在遮挡谷粒的还原任务中,谷粒恢复图像在面积、周长、长度、宽度和颜色分数5个指标的准确率均高于97%,明显优于现有方法,说明本文提出的方法能够良好地还原被遮挡谷粒的几何形状。
综上所述,本文提出的基于深度学习的I2I方法能够较好地解决穗上谷粒原位计数与被遮挡谷粒还原任务,且具有轻量级的优点。
