语音识别在语音增强中的应用
2023-01-06张国峰
张国峰,丁 波
(珠海医凯电子科技有限公司,广东 珠海 519041)
通信系统中传输的语音通常都会受到外部环境噪声和系统内部噪声的影响,这会影响通信系统的性能。语音增强是抑制噪声干扰的重要手段,其目的是增强含噪语音中的有用信号,提高含噪语音的信噪比。在实际应用中,语音增强系统的输入通道可以分为单通道[1]、双通道[2]和多通道[3]。一般来说,输入通道越多,语音增强的效果就越好,所以基于麦克风阵列的多通道语音增强技术优于只有一个麦克风的单通道语音增强。但是,麦克风阵列算法的计算较为复杂,而且在很多场合中,只有一路输入语音可用,此时仍然需要用到单通道语音增强技术。因此,对以谱减法[1]为代表的单通道语音增强进行研究,仍然具有重要的意义。
语音增强技术不仅用于提高语音的可懂度,而且广泛应用于语音识别、语音合成等语音处理系统的前端[4-5]。直接对含噪语音进行去噪处理,虽然可以提高含噪语音的信噪比,但是会导致语音失真,使待识别语音与训练语音的失配更加严重,从而影响语音识别系统的识别率,难以取得理想的识别效果。因此,在目前的鲁棒语音识别技术中,对语音的增强都会结合后端识别器进行,调整待识别语音的特征参数,使其与后端识别器匹配;或者调整后端识别器的参数,使其与待识别语音的特征参数匹配。目前,鲁棒语音识别技术已经取得了较好的效果,可以从含噪语音中实时提取背景噪声的参数[5]。将语音识别系统实时提取的噪声参数用于语音增强,可以提高语音增强系统中噪声均值估计的实时性,从而提高语音增强系统对非平稳噪声的实时跟踪性能。本文研究语音识别在谱减法语音增强技术中的应用,包括在实时噪声估计中的应用和在谱减系数估计中的应用。
在传统的谱减法语音增强中,噪声的均值只在语音间隙期(非语音段)估计。但是,实际生活中的噪声往往是非平稳的,在语音存续期间(语音段)也可能发生变化。如果不及时更新噪声的均值,就会给语音增强带来较大的误差。基于最优平滑和最小统计的噪声估计[6-7]是一种常见的连续噪声估计方法,其基本思想是用一段时间内含噪语音功率谱最小值的变化代表含噪语音功率谱的变化,对这段时间内含噪语音功率谱的最小值进行补偿,得到含噪语音功率谱的均值。该方法的主要缺点是延迟较大,实时跟踪性能较差,在延迟期间,语音增强的效果较差。在基于矢量泰勒级数的特征补偿或模型补偿[5]中,加性背景噪声和乘性卷积噪声的参数可以用期望最大(Expectation-Maximization,EM)算法[8]从含噪语音中实时提取。用语音识别系统提取的噪声参数属于倒谱特征向量,无法将其恢复为线性频谱,不能直接用于语音增强。但是,可以用逆离散余弦变换将其变换到对数谱域,用每个通道对数谱能量的变化表示该通道噪声电平的变化,从而求出该通道每个数字频率处噪声频谱的均值。将估得噪声频谱的均值用于谱减法语音增强,可以提高噪声估计的实时性,增强噪声估计对非平稳噪声的跟踪能力,从而取得更好的增强效果。
谱减法语音增强的另一项关键技术是谱减系数估计。语音和噪声都是典型的随机信号,其时域信号和频谱都是不可再现的。噪声的随机性很大,其频谱的最大值可以达到平均值的6~7倍。在语音段,研究者无法得到每一帧含噪语音中噪声的准确频谱,因而只能在含噪语音频谱中减去噪声频谱的平均值。如果噪声频谱的实际值比平均值大得多,就会导致增强后的语音存在较多的残留噪声,严重影响语音增强的效果。如果噪声频谱的实际值比平均值小得多,就会损伤语音,导致增强后的语音存在较大的失真,严重影响增强后语音的可懂度。因此,在谱减法语音增强中,谱减系数不能设置为常数1,而是根据含噪语音的局部信噪比动态调整谱减系数。如果在某个频段上,语音的能量较大,即信噪比较高,可以设置较小的谱减系数。这是因为较小的谱减系数可以避免语音的损伤,而且语音的能量远远大于噪声的能量,即使残留较多的噪声,对语音可懂度的影响也较小。如果在某个频段上,语音的能量较小,即信噪比较低,可以设置较大的谱减系数。因为该频段语音的能量占语音总能量的比例较小,即使有所损失,对语音可懂度的影响也不大;而且,在该频段信号的频谱中,大部分是噪声,设置较大的谱减系数,可以最大可能地去除噪声,提高增强后语音的信噪比。
谱减系数的设置除了与信噪比有关外,还与语音在每个频段上存在的概率有关。语音可以划分为若干个音节,而每个音节语音的频谱在每个频段上的分布是不一样的。有的音节主要分布在低频段,有的音节在低频段和中频段都有较高的能量。这可以为谱减系数的设置提供一定的先验知识。如果语音在某个频段上出现的概率较小,那么可以设置较大的谱减系数,尽可能地抑制噪声;如果语音在某个频段上出现的概率较大,那么可以设置较小的谱减系数,尽可能地保留语音。在谱减系数的估计中,引入语音存在的概率,可以减小信噪比估计的误差对谱减系数设置的影响,提高谱减系数设置的精度。语音在每个频带上的存在概率可以用训练语音来计算,只需要统计每个音节语音的频谱在每个频带上的分布,即可得到该音节语音在每个频带上的存在概率。在语音增强时,先用语音识别系统识别出当前语音属于哪个音节,即可得到当前语音在每个频带上存在的概率;然后将语音存在概率用于对谱减系数的加权,得到更加准确的谱减系数;最后,利用得到的谱减系数对含噪语音的幅度谱进行谱减运算,得到纯净语音幅度谱的估计值,并用逆傅里叶变换将其变换到时域,用重叠相加法连接各帧,得到完整的增强语音。
1 噪声均值的实时估计
1.1 基于高斯混合模型的噪声估计
为了使语音的每个数字频率k隶属于一个唯一的美尔(Mel)子带,首先在美尔频域将语音的有效频率范围划分为D个互不重叠的Mel子带,然后对每一帧信号进行声学预处理,快速傅里叶变换,Mel滤波,取对数和离散余弦变换,得到每一帧信号的美尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC),并以MFCC为语音识别系统的倒谱特征向量。
在训练阶段,用一个含有M个高斯单元的高斯混合模型(Gaussian Mixture Model,GMM)描述纯净语音MFCC的概率分布

式中:xt表示第t帧纯净语音的MFCC;b(xt)表示xt的概率密度函数;cm,μx,m和Σx,m分别表示第m个高斯单元的高斯混合系数、均值向量和协方差矩阵;D表示特征向量(MFCC)的维数,即Mel通道的数量;上标T表示矩阵或向量的转置。
在测试阶段,将含噪语音的特征向量(MFCC)代入GMM,通过EM算法反复迭代,即可得到噪声均值μn的最大似然估计[5],即

式中:γm(t)=P(kt=m|yt,λ)表示给定先验参数λ时,第t帧含噪语音特征向量(MFCC)yt属于第m个高斯单元的后验概率;Um和φm的表达式分别为

式中:C表示离散余弦变换矩阵;C-1表示矩阵C的逆矩阵;μn0表示噪声的初始均值,是上一次迭代的结果;diag()表示以括号中的向量为对角元素生成的对角矩阵。
1.2 用于语音增强的噪声估计
因为MFCC的提取属于不可逆变换,无法将其还原为线性频谱,所以用GMM提取的倒谱噪声均值μn无法直接用于谱减法语音增强。为了得到噪声的线性频谱的实时估计,首先将噪声的倒谱均值向量变换倒对数谱域

式中:un表示噪声的对数谱均值向量,维数为D,每个元素对应一个Mel通道。设在当前语音段的前一个非语音段得到的噪声的对数谱均值向量和线性谱均值向量分别为un和N,且数字频率k属于第i个Mel通道,则语音段噪声的线性谱均值向量N的第k个元素N(k)通过下式估计

式中:un(i)和un(i)分别表示向量un和的第i个元素表示向量N的第k个元素。得到N后,即可将其用于谱减法语音增强。
2 基于语音存在概率的语音增强
2.1 语音存在概率的计算
在语音识别系统中,以音节为基本语音单元,用每个音节的所有训练语音生成一个隐马尔可夫模型,作为语音识别系统的声学模型。第n个音节的语音在第i个Mel通道上存在的概率Pn(i)通过下式计算

式中:Mn,i表示第n个音节的语音在第i个Mel通道上存在语音的帧数;Mn表示第n个音节语音的总帧数。
2.2 含噪语音的幅度增强
在幅度增强中,先用语音识别系统对当前语音进行识别。设当前语音被识别为第n个音节的语音,则对第i个Mel通道上的每个数字频率k,用加权谱减法对含噪语音进行幅度增强
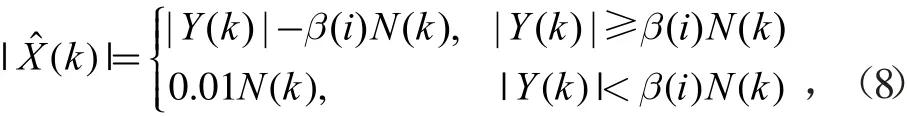

式中:E(i)表示第i个Mel通道的对数能量;Emin和Emax分别表示E(i)的最小值和最大值。在谱减系数β(i)的计算中,β(i)的最小值设置为1,最大值设置为6。由式(9)可知,第i个Mel通道上的谱减系数β(i)与该通道上语音存在的概率Pn(i)成反比,较大的语音存在概率对应较小的谱减系数,较小的语音存在概率对应较大的谱减系数。这是因为,较大的语音存在概率意味着当前Mel通道语音的能量较大,设置较小的谱减系数一方面可以避免损伤语音;另一方面能量较高的语音对噪声的抑制能力较强,即使保留较多的噪声,人耳也不易察觉。较小的语音存在概率意味着当前Mel通道的频谱中大部分是噪声,设置较大的谱减系数,可以尽可能地消除噪声,提高增强后语音的信噪比;此外,即使当前Mel通道存在少量语音,将其当作噪声去除,对语音可懂度的影响也较小,因为其在语音总能量中的比例较小。
得到纯净语音幅度谱的估计值|X^(k)|后,首先将其与含噪语音的相位谱相乘,得到纯净语音的频谱;然后对每帧语音的频谱进行逆傅里叶变换,得到该帧语音的时域信号;最后,对所有帧语音的时域信号用重叠相加法连接,得到增强后的数字语音。
3 结束语
谱减法是一种重要的单通道语音增强技术,通过对含噪语音的幅度谱减去噪声幅度谱的均值,达到增强语音的目的。谱减法的关键技术包括噪声的实时估计和谱减系数的计算。将语音识别用于谱减法语音增强,一方面可以通过GMM实时估计噪声的均值,另一方面可以利用语音在每个Mel通道上存在的概率计算谱减法的过减系数,提高语音增强的信噪比和可懂度。
